1. size()
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
2. isEmpty()
- 当前 map 是否为空,底层调用 sumCount() 进行判断
public boolean isEmpty() {
return sumCount() <= 0L;
}
3. containsKey(Object key)
public boolean containsKey(Object key) {
return get(key) != null;
}
4. containsValue(Object value)
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
Node<K,V>[] t;
if ((t = table) != null) {
Traverser<K,V> it = new Traverser<K,V>(t, t.length, 0, t.length);
for (Node<K,V> p; (p = it.advance()) != null; ) {
V v;
if ((v = p.val) == value || (v != null && value.equals(v)))
return true;
}
}
return false;
}
5. contains(Object value)
- 判断是否存在 value 值,底层调用 containsValue(value)
public boolean contains(Object value) {
return containsValue(value);
}
6. merge()
- 根据key找到的节点 p, remappingFunction(key, value) 返回的 val
- p 为 null,val 为 null:新建节点 Node(key, value)
- p 不为 null,val 为 null:删除 p节点
- p 为 null,val 为 null:新建节点 Node(key, val)
- p 不为 null,val 不为 null:更新 p 节点的value值为 val
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
if (key == null || value == null || remappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int delta = 0;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(h, key, value, null))) {
delta = 1;
val = value;
break;
}
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f, pred = null;; ++binCount) {
K ek;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = remappingFunction.apply(e.val, value);
if (val != null)
e.val = val;
else {
delta = -1;
Node<K,V> en = e.next;
if (pred != null)
pred.next = en;
else
setTabAt(tab, i, en);
}
break;
}
pred = e;
if ((e = e.next) == null) {
delta = 1;
val = value;
pred.next =
new Node<K,V>(h, key, val, null);
break;
}
}
}
else if (f instanceof TreeBin) {
binCount = 2;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r = t.root;
TreeNode<K,V> p = (r == null) ? null :
r.findTreeNode(h, key, null);
val = (p == null) ? value :
remappingFunction.apply(p.val, value);
if (val != null) {
if (p != null)
p.val = val;
else {
delta = 1;
t.putTreeVal(h, key, val);
}
}
else if (p != null) {
delta = -1;
if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
break;
}
}
}
if (delta != 0)
addCount((long)delta, binCount);
return val;
}
7. mappingCount()
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n;
}
8. treeifyBin(Node<K,V>[] tab, int index)
- tab: 存储数据的 table 数组,index:对应的桶位
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
9. Node<K,V> untreeify(Node<K,V> b)
static <K,V> Node<K,V> untreeify(Node<K,V> b) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = b; q != null; q = q.next) {
Node<K,V> p = new Node<K,V>(q.hash, q.key, q.val, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
10. 总结
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest12 {
public static void main(String[] args) {
ConcurrentHashMap<Integer, Integer> concurrentHashMap = new ConcurrentHashMap<>();
for(int i = 1; i <= 10; i++) {
concurrentHashMap.put(i, i);
}
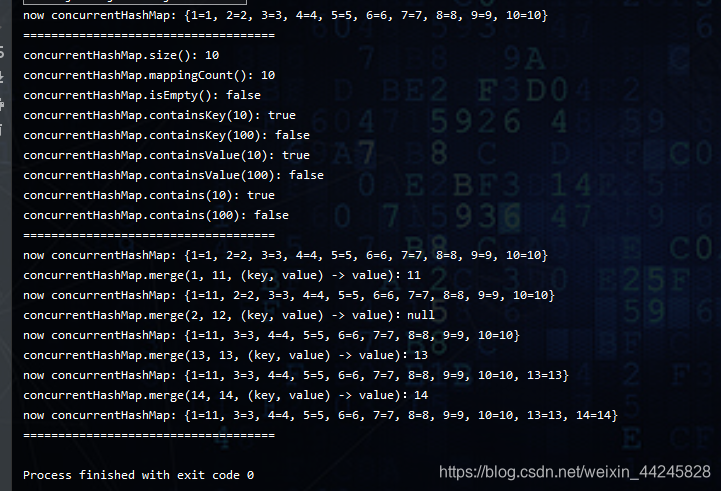
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("====================================");
System.out.println("concurrentHashMap.size(): " + concurrentHashMap.size());
System.out.println("concurrentHashMap.mappingCount(): " + concurrentHashMap.mappingCount());
System.out.println("concurrentHashMap.isEmpty(): " + concurrentHashMap.isEmpty());
System.out.println("concurrentHashMap.containsKey(10): " + concurrentHashMap.containsKey(10));
System.out.println("concurrentHashMap.containsKey(100): " + concurrentHashMap.containsKey(100));
System.out.println("concurrentHashMap.containsValue(10): " + concurrentHashMap.containsValue(10));
System.out.println("concurrentHashMap.containsValue(100): " + concurrentHashMap.containsValue(100));
System.out.println("concurrentHashMap.contains(10): " + concurrentHashMap.contains(10));
System.out.println("concurrentHashMap.contains(100): " + concurrentHashMap.contains(100));
System.out.println("====================================");
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("concurrentHashMap.merge(1, 11, (key, value) -> value):" + concurrentHashMap.merge(1, 11, (key, value) -> value));
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("concurrentHashMap.merge(2, 12, (key, value) -> value):" + concurrentHashMap.merge(2, 12, (key, value) -> null));
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("concurrentHashMap.merge(13, 13, (key, value) -> value):" + concurrentHashMap.merge(13, 13, (key, value) -> value));
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("concurrentHashMap.merge(14, 14, (key, value) -> value):" + concurrentHashMap.merge(14, 14, (key, value) -> null));
System.out.println("now concurrentHashMap: " + concurrentHashMap);
System.out.println("====================================");
}
}
11. ConcurrentHashMap 是否线程安全
- 毫无疑问,肯定是线程安全的。要不然废那么多功夫干嘛。
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadSafeTest {
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<Integer, Integer> hashMap = new ConcurrentHashMap<>();
CountDownLatch countDownLatch = new CountDownLatch(10);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(50, 100, 0L, TimeUnit.SECONDS,
new LinkedBlockingDeque<>());
for(int i = 1; i <= 10; i++) {
int finalI = i;
threadPoolExecutor.execute(() -> {
for(int j = 1; j <= 10; j++) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
hashMap.put(finalI * 10 + j, j);
};
countDownLatch.countDown();
});
}
countDownLatch.await();
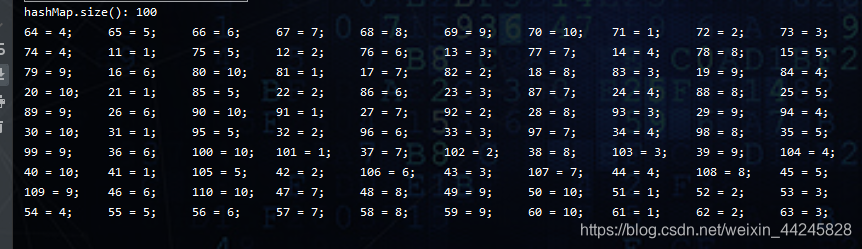
System.out.println("hashMap.size(): " + hashMap.size());
AtomicInteger size = new AtomicInteger();
hashMap.forEach((key, value) -> {
System.out.print(key + " = " + value + "; \t");
if(size.incrementAndGet() >= 10) {
size.set(0);
System.out.println();
}
});
}
}























 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









