在
t
o
r
c
h
v
i
s
i
o
n
.
t
r
a
n
s
f
o
r
m
s
.
T
o
P
I
L
I
m
a
g
e
\rm torchvision.transforms.ToPILImage
torchvision.transforms.ToPILImage 的官方描述中,它可以将以
[
c
,
h
,
w
]
[c,h,w]
[c,h,w] 形式组织的
T
e
n
s
o
r
\rm Tensor
Tensor 和以
[
h
,
w
,
c
]
[h,w,c]
[h,w,c] 形式组织的
n
u
m
p
y
n
d
a
r
r
a
y
\rm numpy~ndarray
numpyndarray 转换为
P
I
L
.
I
m
a
g
e
.
\rm PIL.Image.
PIL.Image.
但平时我们提到的图片分辨率,如
1920
×
1080
1920\times1080
1920×1080,是
w
×
h
w\times h
w×h 的形式。通常深度学习中会将图片大小统一,例如常见的
256
×
256
256\times256
256×256,但如果遇到长宽不相同的图片,需要注意
T
o
P
I
L
I
m
a
g
e
\rm ToPILImage
ToPILImage 函数中的要求与日常使用是有区别的。
torchvision.transforms.ToPILImage(mode=None)
Converts a torch.*Tensor of shape C x H x W or
a numpy ndarray of shape H x W x C to a PIL Image
while preserving the value range.
我们在《交换图片通道》中说过
P
I
L
.
I
m
a
g
e
.
o
p
e
n
(
)
\rm PIL.Image.open()
PIL.Image.open() 函数加载图片是以
R
G
B
\rm RGB
RGB 通道加载的,并且图片尺寸为
w
×
h
w\times h
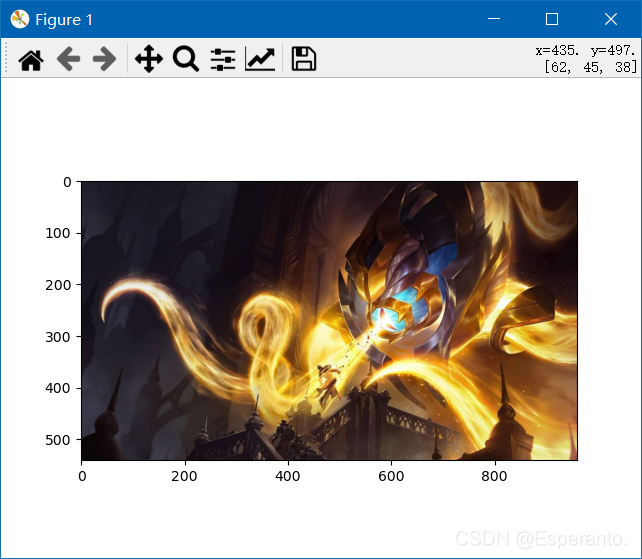
w×h,展示如下:
在进行
t
o
r
c
h
v
i
s
i
o
n
.
t
r
a
n
s
f
o
r
m
s
.
T
o
T
e
n
s
o
r
\rm torchvision.transforms.ToTensor
torchvision.transforms.ToTensor 转换后,会将图片组织成我们开篇所说的
[
c
,
h
,
w
]
[c,h,w]
[c,h,w] 张量形式,代码如下:
最后是关于
m
a
t
p
l
o
t
l
i
b
.
p
y
p
l
o
t
.
i
m
s
h
o
w
(
)
\rm matplotlib.pyplot.imshow()
matplotlib.pyplot.imshow() 方法可视化时对于图片的要求,对于使用
P
I
L
.
I
m
a
g
e
.
o
p
e
n
(
)
\rm PIL.Image.open()
PIL.Image.open() 方法读入的
I
m
a
g
e
\rm Image
Image 类型,
i
m
s
h
o
w
\rm imshow
imshow 是能够直接进行显示的:
# In[]import matplotlib.pyplot as plt
plt.imshow(im)
但对于转换为
[
c
,
h
,
w
]
[c,h,w]
[c,h,w] 形式的张量,则需要对其进行维度的交换,否则会报如下错误:
TypeError: Invalid shape (3,540,960)for image data
其中
p
e
r
m
u
t
e
(
)
\rm permute()
permute() 函数能够实现张量维度的交换,将
[
c
,
h
,
w
]
[c,h,w]
[c,h,w] 重新组织为
[
h
,
w
,
c
]
[h,w,c]
[h,w,c] 形式,用于可视化展示。另一种方式就是使用开篇时介绍的
T
o
P
I
L
I
m
a
g
e
\rm ToPILImage
ToPILImage 方法对张量进行变换:



























 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









