







截图来自李宏毅2020机器学习深度学习。
- 有监督学习supervised learning需要提供一些有目标值的数据给机器去学习。用loss来判断函数的好坏,loss越小函数越符合我们的期待。
- reinforcement learning强化学习,机器自主进行学习。(Alpha Go是supervised learning + reinforcement learning)
- unsupervised learning无监督学习,给机器提供一些无目标值的数据去学习。
- meta learning:让机器学习如何去学习
文章目录
一、Regression
- Regression应用:股票预测、无人驾驶、推荐系统。
(一)建模过程
- 步骤:
(1)构建模型(函数的集合,即同一函数式,但是有不同的权重和偏置);
(2)收集训练数据;有了训练数据然后通过一个Loss function(参数为函数,用于判断函数的好坏程度,而函数又是由权重和偏置来决定的,所以其实也是用来判断一组参数的好坏程度)
Loss function能够自己定义,常使用的一种定义如下:给定一个函数,即给定一个线性函数的权重和偏置,计算每一个训练数据根据该函数计算出来的y值与实际y值之间的偏差再求和。(最小二乘法)(w和b就是权重和偏置,y^就是实际值,n代表第n个值,并不是n次方,cp不用管,是题目里的一个下标)

(3)从函数集合中挑选出最好的一个函数,即Loss值最小的函数,也即找到使得Loss值最小的一组权重和偏置。

求解最好的一组权重和偏置的一种好方法是Gradient Descent,梯度下降,只要Loss函数是可微分的,Gradient Descent就能够帮助找到较好的参数。
比如Loss函数是一个参数的,可以穷举Loss函数的所有可能的情况,然后取随机值(取Loss函数上某一个点),计算微分(其实就是计算导数),根据计算结果大小即正负决定下一个值取在哪(事先规定一个η决定移动距离的远近),迭代多次,当导数结果为0时,则求得较好的参数,但可能是局部最优解(在线性回归中不会出现局部最优解这种情况,不会因为取随机值的不同而产生结果不同)。

当Loss函数是两个参数时,其实也差不多,仍然取随机的一组参数,然后分别计算对每个参数的偏微分(偏导数),然后再更新着两个参数,迭代多次找到较好的一组参数。

Gradient其实就是将求得的偏微分排成一个列向量。
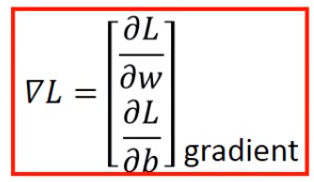
实际例子:

(4)找出一组较好的参数后,也即确定了我们的模型,利用测试集来测试模型的效果,然后根据测试的效果再对模型进行调整优化,甚至是重新设计。(并不一定要设计过于复杂的模型,过于复杂的模型可能会导致过拟合现象,在训练集的表现很好,到测试集的表现就拉跨)因此我们要重新回到第一步,根据前面得到的模型,重新设置我们的函数集合。
(5)有了新的函数集合后,也要重新设计Loss函数,比如在原先的基础上加上用于Regularization(正则化)的一项用于平滑函数(λ后期要进行调整,平滑函数一般都只跟权重wi有关,跟偏置b无关,因为偏置b只是让函数上下移动0)。(比较平滑的函数在收到非正常输入的时候会受到较少的影响,在测试集上的表现可能会更好,但注意不能过于平滑)

(二)误差来源
- 我们构建出来的模型与实际存在误差的主要原因来源于偏差bias和方差variance。我们比较喜欢的模型就是低偏差和低方差的模型,偏差越小点距离中心就越近,方差越小数据就越集中。


较简单的模型的方差一般会比较小,因为不容易受到样本数据的影响,模型越复杂,方差就可能越大。

较简单的模型的偏差一般会比较大,而较复杂的模型偏差可能会比较小。较简单的模型包含的结果范围会比较小,可能并没有把中心值(实际值)包含进去,而较复杂的模型包含的结果范围会比较大,把中心值(实际值)包含进去的可能性更大。

可以看到,偏差随着模型的复杂程度上升而下降,方差随着模型的复杂程度上升而上升,由方差过大所引起的错误就是过拟合现象,由偏差过大所引起的错误就是欠拟合现象。

如果你的模型无法拟合你的训练集,那么可能你的模型的bias是大的,代表是欠拟合的,与正确的模型还存在着一定的距离。bias大说明目前你的模型可能并不包含实际值(实际的模型计算出来的值),那么接下来需要做的就是重新设计模型的式子(考虑更高方次或者更多的特征),模型不好收集更多的数据也没有作用。
如果你的模型可以拟合训练集,但是在测试集上表现并不好,那么可能你的模型的variance是较大的,代表是过拟合的。接下来要做的就是收集更多的数据(往往有困难,但不会对偏差bias造成影响),也可以对Loss函数进行Regularization,那么最终得到的模型也会变得平滑一点(多次训练得到的模型会相对集中一点,variance就会降低一点,但是可能会对bias产生影响,因为调整后每次训练后得到的模型会偏向于平滑的模型,可能没有办法包含实际的模型,这时候就需要在variance和bias做一下权衡)。
- 如果现在有训练集跟测试集的话,如果通过训练集得到几个模型后,然后通过测试集来选择最终的模型,那么这个模型对于实际数据来说可能效果并没有想象中那么好。较可靠的做法应该是这样,将训练集分成训练集和验证集,分出来的训练集拿来训练模型,验证集拿来选择最终的模型(如果觉得分成训练集和验证集后会导致原有训练集数据减少的话,那么也可以在利用验证集选择了最终的模型后,再拿原先整个训练集对这个模型进行再次训练),这样得到的最终模型在测试集上的表现,跟真实数据的表现才应该是差不多的。
如果觉得利用上面这种做法可信度不高的话,那么可以进行n折交叉验证得到最终模型。比如采用三折交叉验证的话,将原先的训练集分为三份,依次让三份中的两份当训练集,另一份当验证集,然后对利用上面这种做法得到的几个模型重新训练并计算平均错误率,然后找到一个最好的模型,再将原先完整的训练集在这个模型上进行训练。

(三)Gradient Descent
- Gradient Descent:前面提到用Gradient Descent来求解函数集中较好的一组参数,这里补充一些在进行Gradient Descent时的细节。

在进行Gradient Descent时,在选取随机的一组参数之后,需要对这组参数进行不断更新,在参数进行更新的时候,除了要计算参数的偏微分之外,还涉及到一个参数η(学习率),对这个参数的设置不能太大或太小,因为太小了的话更新参数每次走的步伐会比较小,loss值的下降比较慢;太大的话每次更新参数的步伐又太大,可能会跳过最优的那组参数,也可能卡在某处出现loss不变化的情况。很多时候当参数的个数变多之后,就无法将参数的变化跟loss值的变化可视化出来,但是可以将loss值的变化跟η的变化可视化出来,来判断η值的好坏。进行Gradient Descent的时候往往需要将画出loss随η变化而变化的图。

调整学习率η是一件比较麻烦的事情,通常学习率η是会随着参数的更新而越来越小的,在一开始的时候学习率较大能够方便快速接近目标,但是越靠近目标的话,应该要减小学习率η,以便最后能够收敛到最优解的地方。最好的情况是每一个不同的参数都给定不同的学习率。
- 调整学习率最简单的方式就是Adagrad,使用Adagrad,每个参数的学习率的一部分是ηt。每一个参数的学习率都要用ηt除以这个参数之前算出来的所有微分值的root mean square(均方根)来得到,在使用Adagrad的时候,每一个参数都有不同的学习率。
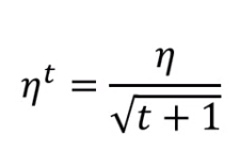

实际例子:

可以得到使用Adagrad,参数的学习率的公式是这样的:(Adagrad的公式为何要这么规定视频有讲但听不太懂,之后回看Gradient Descent_1 19:00-31:18)

- 另一种Gradient Descent是Stochastic Gradient Descent(随机梯度下降),能够让training更加快速一点。普通的梯度下降所使用的Loss函数是要通过训练集中所有的数据来判断这组参数的好坏;而随机梯度下降使用的Loss函数不考虑训练集中的所有数据,而是随机取一个数据,Loss函数只考虑这个数据,并且在做梯度下降时进行的参数更新也只考虑这个数据。

如果训练集中有20个数据,那么普通的梯度下降,每次进行参数更新都需要查看20个数据,而随机梯度下降每次进行参数更新只需要查看1个数据,因此会比普通的梯度下降快将近二十倍。

- 如果函数模型涉及到多个特征,且这些分布范围比例相差较大(比如特征x1的范围是0-10,而特征x2的范围是1000-100000),那么在进行Gradient Descent之前需要进行Feature scaling(特征缩放),因为如果特征之间的比例相差过大,那么Loss函数对于比例较小的特征的改变就可能不那么敏感,而对于比例较大的特征的改变就可能显得很敏感。并且如果特征之间的比例相差太大的话,进行Gradient Descent的参数更新时,学习率的调整也会比较麻烦(因为不同的方向上步长相差太大,必须使用一些适应性的学习率,比如Adagrad);在进行特征缩放之后,学习率的调整就会相对简单,并且效率也会有所提升(特征之间比例相差不大时,进行Gradient Descent的参数调整时,更容易往最优解走)。

特征缩放的方法有很多种,常见的一种是这样的:假设有R组数据,取出这R组数据中属于同一种特征的数据,然后对这些数据种每个数据减去这些数据的均值,然后再除以这些数据的标准差,得到的结果赋值给各个数据。这样的话,这些数据的均值就会变为0且方差变为1。

-
对于Gradient Descent的数学原理,在视频Gradient Descent_1中44:00 - 59:00有解释,需要时回看。
-
Gradient Descent的一个局限是可能会卡在局部最优的地方,但是还有可能会卡在一些微分值为零但又不是局部最优的地方,比如鞍点。
二、Classification
- 分类问题如果当作回归问题来解决的话,往往得不到好的结果。
(一)建模过程
- 收集训练数据
- 构建模型(函数的集合,这些函数应该内嵌一个函数能够帮我们根据计算出来的数值进行分类,这些函数的不同跟我们选择的概率分布相关,不同的概率分布就会有不同的函数,求解同一种概率分布的参数使用的方法不同会得到不同的函数,使用不同种的概率分布也会得到不同的函数)
- 然后根据Loss函数来判断函数的好坏,Loss函数应该定义为在训练集上预测错误的次数和。当真实值跟预测值不相等时δ函数就取1。判断一个函数的好坏,就是要判断上一步中根据选择的概率分布而得到的函数的好坏,看看其中的概率分布函数的参数能否让训练集得到一个较好的准确率。
- 根据Loss函数挑选最好的一个函数。


- 例子:
假如是一个二元分类问题,并且有图中四个红框的数据的话,那么当给定一个数据时,可以根据这四个数据,利用贝叶斯公式计算出这个给定数据属于两个类别的概率是多少;并且有了这四个数据,还可以得到一个生成模型Generative Model,即可以得到某一个x的概率。

其中P(C1)和P(C2)称为先验概率,比较好计算。

然后要计算P(x|C1)和P(x|C2),跟多元高斯分布有关(假设选择的概率分布是高斯分布),要根据训练集中属于C1的数据的特征去找到对应的高斯分布函数,根据训练集中属于C2的数据的特征去找到对应的高斯分布函数,(找高斯分布函数所需要的期望μ跟协方差矩阵Σ需要用到极大似然估计法,极大似然估计法可以求出最贴合训练集的高斯分布函数),然后利用这两个高斯分布函数就能够分别算出P(x|C1)和P(x|C2)。(这一部分听不懂,Classification_1 24:00 - 38:36,有空回看)
有了这四个数据之后,相当于我们得到了函数集的一个函数(后验概率),就能够进行分类了(这只是函数集的一个函数,如果选择的概率分布是其他的话,会得到其他的函数,或者求得高斯分布函数的参数的方法不同,也会得到其他的函数,函数集就是这么来的)。可以算出P(C1|x)之后,假设P(C1|x)大于某个数值就属于C1,否则就属于C2,然后用测试集来看看这个函数的预测效果如何。如果效果不好的话可以考虑增加训练集的一些特征,有可能高维的效果更好一点。

如果增加了训练集的特征之后函数的预测效果仍然不太理想的话,可以考虑这样做调整:前面所说到给类别C1和类别C2找它们的高斯分布函数,也就是说要给C1和C2分别找到一个自己的μ和Σ;这种做法其实比较少,常见的做法是不同的类别分享同一个Σ(因为Σ的大小是随输入的特征数量的多少而增长的,如果每个类别都给一个Σ,那么函数的参数就可能会很多,从而导致函数的方差过大,造成过拟合现象),能够有效减少参数的数量,让求得的函数的预测效果变好。利用极大似然估计法求得的μ跟之前的做法得到的μ是一样的,得到的Σ其实就是之前的做法得到的Σ1和Σ2加权平均所得到的结果。
(改进方法在Classification_1 39:00-52:00有提到,也听不太懂,有空回看)
- 前面在求得函数的时候,需要涉及到贝叶斯公式,如果对贝叶斯公司进行化简的话,可以将其化简为一个sigmoid函数。

然后再经过一系列化简,能够将函数的式子化简的十分简单:

(二)Logistic Regression
- 前面讲求函数的时候可以讲函数的式子化简到非常简单,那么如何求这些简单的参数而避免去求像高斯分布函数那种复杂的参数呢?逻辑回归就是用来做这事情的。
- 逻辑回归的函数集是这样的:把所有的w跟b集合起来就组成了逻辑回归的函数集,其中w是一个向量,b是常数。因为逻辑回归的函数还经过了一个sigmoid函数,所以输出值介于0到1之间。

- 如何判断一个函数(后验概率)的好坏?给定一个w向量和一个常量b,我们就可以计算这个函数产生我们所使用的训练集的概率,有最大概率产生我们所使用的训练集的w和b就是最好的一个函数。

上面的L(w,b)并不是Loss函数,而是用来计算一组w和b产生训练集的概率的函数,函数值越大则概率越大,概率越大则函数越好。由于训练集的目标值是类别,所以要对它进行一些数学转换,然后把求让L(w,b)最大的w,b的公式转化成求让-lnL(w,b)最小的w,b的公式,这个-ln(w,b)就是Loss公式了,这个公式经过化简是两个伯努利分布的交叉熵公式的形式(交叉熵cross entropy代表的是两个伯努利分布有多接近,如果两个伯努利分布是一样的,算出来的交叉熵就是0)。


这样的话,Loss函数的形式就是这样的:如果将函数的输出f(xn)和训练集的目标值y^n看作是伯努利分布的话,它们越接近越好,也就是算出来的交叉熵越接近0越好。(这里其实不太懂什么意思 Logistic Regression 11:00-13:30)。

显然这个Loss函数比起线性回归的Loss函数要复杂得多,但是为什么逻辑回归的Loss函数不能定义成像线性回归的Loss函数那样简单的形式呢?
如果使用了线性回归那种Loss函数的话,那么到想要使用Gradient Descent求得函数集中较好的函数时,就会出现效果不好的情况,在进行参数更新的时候,可能在距离目标值较远的地方就算出偏微分等于0,导致把不好的参数当前好的参数。(比如下面这种情况,真实值为1,在预测值为0的时候,偏微分也为0,显然这种情况是不好的)

如果对参数的变化和total Loss作图的话,能够发现如果是使用逻辑回归那种Loss函数(Cross Entropy)的话,在距离最低点较远的地方微分值会较大,更新参数的变化量会较大,而使用线性回归那种Loss函数(Square Error 均方误差),在距离最低点较远的地方微分值也很小,更新参数的变化量很小,可能在较远的地方就停住了,当停住的时候还不知道是处于什么位置,这样效果必然就不太好。

- 有了Loss函数,如何求最好的函数?通过Gradient Descent,进行一些数学运算,下面是计算过程。
w参数的更新,先求偏微分:



- 逻辑回归跟线性回归的区别:

- 逻辑回归这种直接找w和b的方法称为Discriminative Model,而之前那种通过高斯分布函数来求函数的方法称为Generative Model,实际上如果Generative在求高斯分布函数的时候共享一个协方差矩阵的话,那么两种方法找到的函数集应该是一样的,但是在函数集中挑选较好的函数时,结果就并不是一样的。(不太懂什么意思, Logistic Regression 30:00-35:00)
哪种方式比较好?在数据量较多时,Discriminative Model会比Generative Model的效果好一点,因为Discriminative Model并不像Generative Model那样做出假设(像之前假设训练集是从高斯分布中抽样出来的),是用数据来说话的;而在数据量较少时,Generative Model的效果可能会好一点,因为Generative Model会有自己的假设,可能预测出这少量数据没体现出来的情况,而且构建出来的模型可能会健壮一些,对噪音数据不敏感。
- 多个类别(大于2)的分类。每个类别都有自己的一组w和b,x为输入值,zi可以是任何值,后面求出来的yi就是x属于这个类别的概率。

让求出来的yi组成一个向量,与真实值进行计算交叉熵,能够使得交叉熵最小的时候,这几个类别的几组w和b就是最好的。

(这部分也不是很懂,Logistic Regression 47:30 - 56:24)
- 有些数据如果想要采用逻辑回归的方法来进行分类可能会做不到,如果要想用逻辑回归来做的话需要经过特征转换,但是往往很难去找到好的特征转换方法。这个时候可以利用其它的逻辑回归模型来进行特征转换。(听不懂,Logistic Regression 56:33 - 1:07:13)



将多个逻辑回归的模型连接在一起,形成的网络叫类神经网络。

三、Deep Learning
(一)深度学习步骤
(1)定义一个神经网络(由不同的逻辑回归模型连接起来),在这个神经网络中由很多哥逻辑回归模型,每个逻辑回归模型都有自己的weight和bias(根据训练集找出),这些weight和bias集合起来就是这个神经网络的参数。
各个逻辑回归的模型的连接方式有很多种,最常见的一种方式是Fully Connect Feedforward Network(全连接前馈网络),就像是下面这种,每个球都是一个逻辑回归模型。


一个神经网络,如果已经知道各个逻辑回归模型的参数以及连接方式的话,其实这个神经网络就相当于一个函数,有输入就有相应的输出。如果还未知道各个逻辑回归模型的参数,只设定好各个逻辑回归模型的连接方式的话,其实就相当于我们定义好了函数集,给这些逻辑回归模型加上可能的参数,把这些可能的情况都集合起来,就得到了函数集。
一个神经网络的运作,常常会用矩阵运算来表示,将矩阵运算的结果丢进一个逻辑回归模型中(sigmoid函数,现在常用的是其他的函数比如activation function激活函数)。一个神经网络做的事情,其实就是一连串的向量乘上矩阵再加上向量,这些矩阵运算可以让GPU来做,会比CPU更快。



(Output Layer的ppt不是很懂 Brief Introduction of Deep Learning 26:50 - 28:29)

(2)定义一个函数的好坏,也就是一个神经网络的好坏。如果训练集的数据经过神经网络之后的输出数据,与真实值的交叉熵越小的话,那么这个函数就是越好的。计算一个函数对训练集的总的Loss值,越小的话这个函数就越好。


(3)利用Gradient Descent来找到让total Loss最小的参数,即最好的一个神经网络。这里用Gradient Descent跟线性回归用Gradient Descent是一样的,除了函数变复杂之外,其他做的事情都是一样的。

- 在做线性回归和逻辑回归时,对模型的结构其实是没什么好设计的,但是对于神经网络来说,设计模型的结构是很重要的,这决定了函数集,决定了后期能否构建一个好的神经网络。
- 在相同数量参数的情况下,多层次的神经网络更好还是一层的神经网络更好?数据表明是多层次的神经网络更好,并且往往多层次的神经网络能够在更少的参数情况下获得更低的错误率,多层次的神经网络其实并不仅仅只是靠模型的规模来获得低错误率。做深度学习其实就是在做模块化的事情(类似于编写程序时,将程序的部分逻辑抽象出来封装成一个个函数,可以减少重复代码的编写),这样做的话能够在训练集的数据相对较少时也能得到较好的效果,比如如果要做分类,直接对训练集的数据进行训练的话,可能会由于训练集中某些训练样本数量太少而导致训练效果不好,而如果采用深度学习,将分类问题拆解成多个小的问题,然后一层一层进行训练,往往效果会比较好,因为拆解出来的每个问题都是一个小的分类,所以会有足够的训练集。

(关于模块化有一个语音识别的例子,在Why Deep- 11:49 - 29:11,听不懂)
(还有逻辑电路的例子,在Why Deep- 31:06 - 35:48,听不懂)
(二)BackPropogation
- Backpropogation(反向传播)是一种在神经网络中计算微分值的有效的方法,让神经网络的训练变得更加有效。Backpropogation是一种演算法,让进行Gradient Descent时计算Gradient更有效。

- Backpropagation的运作:(视频Backpropagation,不是很懂)

(三)卷积神经网络CNN
- 假如现在要用一般的全连接前馈网络去做图像分类的话,往往需要太多的参数,而CNN做的事情就是简化神经网络的架构,删去某些不必要的参数。那么为什么可以删去某些参数?因为比如在做图像识别的时候,可能并不需要整张图片就能完成识别,这样的话神经网络中的神经元可能只需要链接到图片的较小部分就可以,相应的参数也会减少;或者在进行图像识别时,有时候识别不同但是很相似的东西,可以用一个神经元来完成,并不需要专门训练两个神经元来解决这个问题,这也能减少参数;将图像的像素变小,对识别效果不会产生太多的影响,这也可以减少参数。
- CNN的架构:


在每一卷积层(Convolution)中有一组Filter(相当于全连接前馈网络中的一个Neuron,是一个矩阵,矩阵中的值必须由训练集学习而来),每个Filter用于侦测图片的一小部分。
(卷积层做了什么事情可以看Convolutional Neural Network 9:15 - 23:30,听不太懂)
(Max Pooling做了什么事可以看Convolutional Neural Network 23:44 - 25:18)

(CNN在学习什么东西?Convolutional Neural Network 35:53 - 54:20,听不懂)
(四)Tips for Traning DNN
- 通过深度学习三个步骤得到一个神经网络,应该先看这个神经网络能否在训练集上有好的结果,如果不行的话再对前面三个步骤进行调整,如果可以的话才看这个神经网络能否在测试集上有好的结果,如果再测试集上没有好的结果的话,说明这个神经网络出现了过拟合现象,也需要对前面三个步骤进行调整。

- 如果经过三个步骤得出来的神经网络效果不好,不能直接说是因为这个神经网络过拟合导致的。假如一个更多层的神经网络在测试集上的效果比一个较少层的神经网络在测试集上的效果差的话,不能直接得出是因为更多层的神经网络过拟合的结论,而是应该看看它们在训练集上的效果如何,有可能在训练集上,更多层的神经网络的表现本来就比更少层的神经网络表现的好,这说明更多层的神经网络训练的不好,导致了在测试集上表现也不好的现象,而并不是过拟合现象导致了在测试集上表现不好。
在神经网络的构建过程中,如果使用的是sigmoid函数的话,可能会导致这种在训练集上表现不好的现象,因为sigmoid函数的特性,即使输入数据的变化再大,反映在输出上的变化也是很小的,并且经过越多个sigmoid函数,这个变化就会更加衰减,以至于在越靠近输入的地方进行偏微分更新参数的时候,参数的变化很慢,最终导致得到的神经网络的表现不好。
要解决这个问题的话可以使用一些其他的activation function,比如ReLU(Rectified Linear Unit,线性整流函数),使用ReLU更方便计算,且其实ReLU是由无穷多个带有不同参数的sigmoid函数叠加而成,还能够解决上述提到的计算gradient更新参数不理想的问题。

ReLU的一些变形:

由于又有了为什么非要用ReLU的问题,所以出现了Maxout Network,能够自己学习激活函数。本来输入经过一些计算之后要经过一个activation function或一个sigmoid或一个ReLU函数然后成为下一层的输入,但是在Maxout Network中,这里不这么做,而是像下面这么做。

MaxOut完全可以模拟ReLU做ReLU能做的事情,也可以做到其他事情,每一个Neuron根据输入的数据的不同的权重,会有不同的activation function。在MaxOut Network中,Activation function可以是任何的piecewise linear convex funciton(分段线性凸函数)。


(MaxOut Network的训练 Tips for Training DNN 32:36 - 35:46,不太懂)
- 之前所提到的Adagrad是在进行Gradient Descent时用来调整学习率的,对于Loss函数中影响Loss函数较大的参数给它较小的学习率,对于影响Loss函数较小的参数给它较大的学习率。但在做深度学习的时候,Loss函数可以是各种奇怪的形状,对于一个参数,可能一会对Loss函数影响大一会对Loss函数影响小(表现在图形上就是在这个参数方向上,Loss函数一会平坦一会陡峭),这样的话Adagrad对学习率的调整是不够的,需要更加的动态地调整学习率,因此有一个Adagrad的升级版RMSProp。
RMSProp更新参数是这样的:跟Adagrad很像,但是引入了α,可以自行调整,如果α是一个比较小的值,那么在更新参数的时候就说明更相信目前计算出来的gradient(因为权重更大)。

- 在做深度学习时,做Gradient Descent找最佳参数的时候,可能会卡在局部最优值的地方、甚至是鞍点或其他比较平缓的地方,要解决这个问题可以在做Gradient Descent的时候加上Momentum,在做变量更新时,每一次变量移动的方向不再是只考虑gradient,而是考虑现在的gradient加上前一个时间点移动的方向。(相当于在移动时有一个惯性)虽然说加上Momentum后不一定就能够走到全局最优值的地方,但增大了这个可能性。


如果把RMSProp + Momentum,就得到了Adam。
- 前面所提到的东西都是用来解决神经网络在训练集上表现不好的问题,下面要说的东西是用来解决神经网络在测试集(这里的测试集指的不是真正的测试集,而是验证集或其他)上表现不好的问题。
- Early Stopping。有可能神经网络在进行Gradient Descent时的Total Loss对于训练集来说是下降的时候,对于测试集来说正在逐渐下降,如果可以在适当的时候停下来,就能够让测试集的Total Loss较小。但通常我们都不会知道真正的测试集对于total Loss的变化,所以会从训练集中取一部分数据作为验证集来做这件事。

- Regularization正则化。重新定义Loss函数,在原先的Loss函数上再加上一个正则化项Regularization term,可以有不同的正则化项。(在Tips for Traning DNN,57:40 - 1:20:23,听不懂)



- Dropout。在训练的时候,在进行每一次参数更新之前,每一个神经元包括输入都有p的概率被丢掉,这样神经网络的结构就会发生改变,然后再对这个改变了的神经网络进行训练。(在Tips for Traning DNN,1:10:25 - 1:26:02不太懂)

对于测试集,这样操作:

(五)PyTorch
(六)图神经网络GNN
- 一般的神经网络的输入是一个向量,而GNN的输入是一个图,比如在做分类的时候,有些时候不仅要考虑这个待分类的东西的一些特征,还需要考虑这个待分类的东西与其他东西之间的关系。
- 在做GNN时存在着一些问题。当我们的数据集是一个包含很多结点的图,那么应该如何训练我们的神经网络?而且在这么多结点中,可能有些结点是unlabeled的(可能unlabeled结点比labeled结点多得多),也就是只有特征但是没有标签的结点,那么应该如何利用有限的labeled结点和图来训练神经网络?

(这部分听不懂,后面再补)
(七)循环神经网络RNN
- 如果要做Slot Filling(插槽填充,将句子中的词汇自动填到某个槽中),如果要用全连接前馈网络,将句子中每个词汇作为输入,然后输出这个词汇对于各个槽的概率分布。但是用全连接前馈网络的话会有一些问题,有一些词汇需要根据前后的词汇才能判断应该填入哪个槽,这样的话全连接前馈网络就无法解决这个问题。如果我们的神经网络能够记得之前看过的词汇,那么就能够解决这个问题,这种有记忆力的神经网络就称为循环神经网络RNN(Recurrent Neural Network)。RNN会有一块地方用于存储上一次某个神经元的输出(第一次的话这块地方会存有初始值),然后这些存储的数据会对下一次的输入产生一定的影响,这样的话如果输入的数据顺序发生改变的话,那输出的结果可能也是不一样的。


- 上面所提到的RNN的类型是Elman Network,将某一隐含层中的数据存储起来,等到下一个时间结点再拿出来;还有一种RNN类型叫Jordan Network,是将输出层的数据存储起来,等到下一个时间结点再拿出来。

RNN的类型还有Bidirectional RNN(双向RNN),同时训练出一个正向的RNN和一个逆向的RNN,然后将两个RNN的隐含层接在一起共同连接到一个输出层。双向RNN的好处是在产生输出时,这个神经网络考虑的范围较大,比如前面提到的将句子中的词汇自动填到某个槽中,使用双向RNN的话,不仅会考虑到当前词汇前面的词汇,还会考虑到当前词汇后面的词汇,这样效果往往会更好。

- 前面提到的RNN使用的memory(存储空间)是最普通的,随时可以从memory中取出数据,随时可以将数据存储到memory中去。现在比较常用的memory是Long Short-term Memory(LSTM,较长的短期记忆),当某个神经元的输入要写入LSTM时,必须要经过一个Input Gate,打开时才能写入,何时打开何时关闭由神经网络学习得到;LSTM中的数据要输出要经过一个Ouput Gate,决定其他神经元能否从LSTM中读取数据,打开时才能读取,何时打开何时关闭也由神经网络自己学习得到;还有一个Forget Gate,决定LSTM什么时候将数据忘掉或什么时候将数据保留下来,这也由神经网络自己学习得到。

在几个Gate处有几个数值作为输入(一般都跟要写入的数据有关,但是各个Gate权重可能不一样,权重也是由训练得来),每个Gate处都会有各自的activation function(通常是sigmoid function,因为计算结果会映射到0和1之间,代表每个Gate打开的程度),假设原先存在memory中的数值位c,那么输入的数值经过一个activation function后再乘上input Gate的输出,再加上c乘以forget Gate的输出(forget Gate的输出比较特别,输出越接近1则表示越要记住memory原来的数值,也就是开着反而代表要记住),就得到了新的要存储在memory中的值c’;如果要输出的话,存储在memory中的c’要经过一个activation function,然后将结果乘上Output Gate的输出得到最后的输出。

有了LSTM之后,其实就是把之前的全连接前馈网络中的神经元换成LSTM,这样一个输入会乘上不同的权重变成4个输入,其中三个输入用于控制三个门,最后一个输入是输入数据,然后通过LSTM得到输出。

上面提到的LSTM是简化版的,真正的LSTM中,每一个输入会考虑上一次输出的结果,还会考虑上一次存在memory中的数据。并且LSTM通常都不会只有一层。

-
那么RNN这种架构要如何做学习,如何训练得来呢?又要如何设计Loss函数呢?假设现在要做slot Filling,训练集是一些句子(句子中的每个词汇都要转化成向量然后作为RNN的输入),那么Loss函数就是通过RNN的输出跟各个槽对应的向量计算交叉熵来判断RNN的好坏。在有了Loss函数之后,要找出最好的参数,也是要进行Gradient Descent来计算,这里进行Gradient Descent的一个有效的演算法是Backpropagation through time(BPTT,BP的进阶版),因为RNN跟时间序列有关,所以在计算Gradient的时候,使用的演算法也要跟时间有关,所以就使用BPTT。
-
RNN的训练通常会比较难,因为RNN的error surface(RNN的total Loss对参数的变化)通常会比较崎岖(有的地方比较陡峭,有的地方比较平坦),因为RNN是跟时间序列有关的,总是要把前面存储在memory中的数调出来使用。这样的话在进行计算Gradient的时候,学习率就不好调整,并且通常在很小的一部分区域,Gradient就会可能变化很大。解决这个问题的一个好方法就是通过LSTM,LSTM可以解决gradient vanishing的问题(在平坦的地方计算gradient结束的现象,可以解决这个问题的原因是在使用LSTM的RNN中,如果输入会影响memory中的值,这个影响会一直存在,除非forget Gate要将memory中的值洗掉,而普通RNN的话对memory中的值都是很快地覆盖掉,所以能够解决gradient vanishing的问题),但不能解决gradient explode(某个地方计算gradient比较大)的问题,但使用了LSTM的话,gradient相对较大,就可以把学习率稍微设置大一点。如果觉得训练出来的使用了LSTM的RNN过拟合的话,可以试试看使用GRU(Gated Recurrent unit,门控循环单元,比LSTM少一个门,将原来LSTM中的Input Gate和Forget Gate联动起来,当Input Gate被打开的时候,Forget Gate就会自动关闭,把memory中的值清掉)。
-
RNN的应用有很多。比如情感分析(Sentiment Analysis,分析一些文字是正向的还是负向的)、关键词提取(Key Term Extraction,输入一篇文章得到文章的关键词)、语音识别、翻译、句法分析(通过一个句子,得到句子的句法树)、语音搜寻、聊天机器人(Chat-bot)。
(在Recurrent Neural Network partⅡ,听不太懂) -
除了RNN外,另一个使用了memory的神经网络叫Attention-based Model,这种模型会有属于自己的一个数据库,通过一个中央处理器来操控读头控制器读取数据,操控写头控制器写数据,使用这种神经网络的有比如Neural Turing Machine。Attention-based Model的应用有阅读理解(问机器一个问题,机器会找出在自己的数据库中哪些数据与这个问题有关,读取到中央处理器后再给出答案)、可视化问答(Visual Question Answering,给机器一张图片及问题,机器会将将图片的很多个小区域转化成向量,然后机器会操控一个中央处理器取读取那些与问题有关的位置,最后给出答案)、语音答疑(Speech Question Answering,给机器一段语音以及问题,对语音进行语音识别然后进行语义分析,对问题进行语义分析,然后找出答案)。
-
RNN与Structured learning的区别?
(Recurrent Neural Network partⅡ1:07:26到之后的部分,听不懂,Structured learning?弹幕说在2017年的课程有)
四、Semi-supervised Learning半监督学习
- 监督学习是训练集中的数据是带有特征值以及目标值的;而半监督学习中,训练集中的数据除了带有特征值以及目标值的数据,还有只有特征值的数据,并且糖厂这些只有特征值的数据的数量是远大于带有特征值及目标值的数据的数量。半监督学习又氛围Transductive learning(直推式学习,就是将这些只带有特征值的数据作为测试数据,在训练模型的时候把这些测试数据的特征值考虑进来)和Inductive learning(归纳式学习,不把这些只带有特征值的数据作为测试数据,在训练的时候不考虑这些数据)。
- 为什么要做半监督学习?因为搜集数据很简单,但是搜集带有标签的数据很难。不带标签的数据的分布往往能够说明一些事情,半监督学习使用这些不带标签的数据往往伴随着一些假设,半监督学习有没有用往往就取决于这些假设符不符合实际情况。
- 之前在说到监督学习的Generative Model时,在计算后验概率时,有假设训练集中某一个类别中的数据是由高斯分布得来的,并由此计算出对应的参数跟式子;但是在半监督学习中,由于训练集中加入了一些unlabeled data,会对计算出来的参数和式子产生一定的影响,同时还会影响先验概率的计算。


- 半监督学习的步骤。
(1)先初始化一组参数。也就是先利用带有标签的数据先训练一个模型,得到一组参数。
(2)然后利用这个模型计算不带有标签的数据的后验概率。
(3)更新模型,先验概率和后验概率的计算都会有所差别。然后返回第一步,一直反复下去,最终参数会收敛到某个值,这个值收敛到哪会受到初始值的影响。

为什么半监督学习的步骤是上面那样的?原先在监督学习里,只有带标签的训练集,用极大似然估计法得到最可能产生训练集的高斯分布函数的参数,它的计算式子是封闭形式的
函数,可以直接计算得到解;而在半监督学习里,既有带标签的训练集,也有不带标签的数据,在使用极大似然估计法时,得到的计算式子就不是封闭形式的函数,需要迭代求解。

- 前面说的半监督学习基于的假设是高斯分布(Generative Model)。现在说一种基于Low-density Separation假设(低密度分离,这个假设是非黑即白的,即两个类别之间有明显的分界线,在两个类别的分界线处基本是不会出现数据的)的半监督学习。
这种基于Low-density Separation假设的半监督学习中,最具有代表性的简单方法就是Self-training。
Self-training的步骤是这样的:
(1)先从Labeled Data利用之前所提到的某种方法训练出一个模型。
(2)根据训练出来的模型,给unlabeled data添加上pseudo label(伪标签)
(3)从unlabeled data set中拿出一些unlabeled data加入到labeled data中,如何拿要自己决定。然后回到前面重新训练模型。

要注意Self-training如果用到回归模型上是没有作用的,因为给unlabeled data加上标签后再拿去训练回归模型,对回归模型是没有影响的,毕竟这些刚加上标签的unlabeled data就是拟合刚刚那个回归模型的。
前面提到的Generative Model使用的是Soft label,也就是在利用unlabeled data更新模型的时候,会考虑这个unlabeled data属于各个类别的情况;而上面这种Self-training的方法使用的是Hard label,利用labeled data训练出来的模型,给unlabeled data加上标签(视为某个类别),然后去更新模型,而其实这个unlabeled data只是有较高概率是属于这个类别。

- 前面Self-training中给unlabelled data加上标签的步骤还可能替换成Entropy-based Regularization(基于熵的正则化)。在做神经网络的时候,unlabelled data经过一开始利用labeled data训练好的神经网络后,得到的是一个概率分布,我们现在不直接按照哪个概率高就给unlaelled data贴上它的标签,而是计算这个概率分布的entropy(entropy越小说明概率分布越集中,就越满足Low-density Separation的假设),然后去重新设计Loss function,得到模型的新的参数进而更新模型。
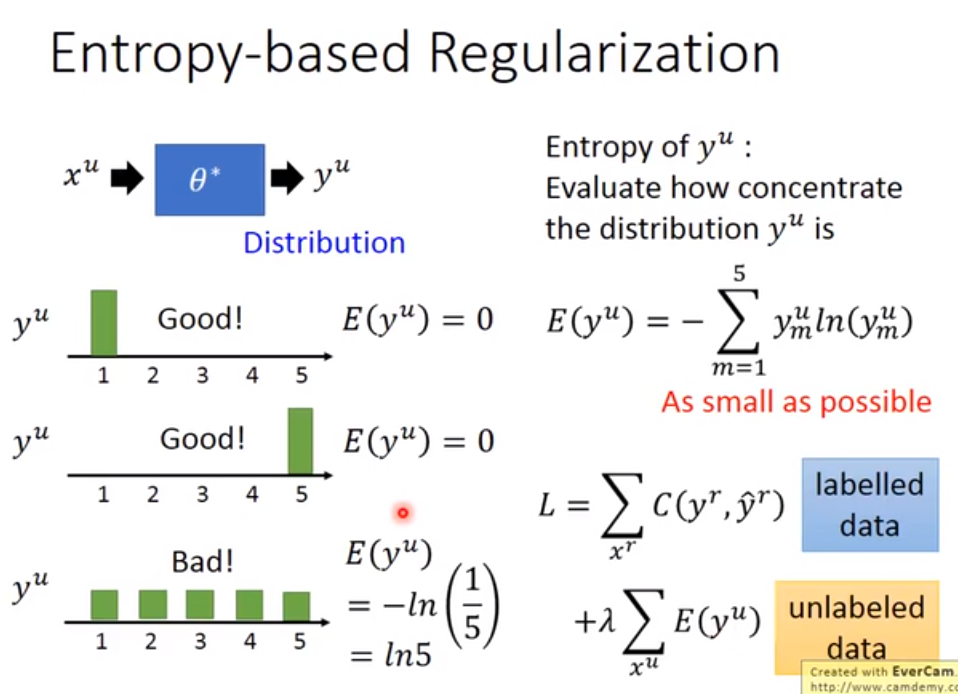
- 半监督学习还有基于Smoothness Assumption(平滑性假设,近朱者赤近墨者黑),平滑性假设是假设数据的分布是不平均的,在高密度区域中如果两个数据比较接近的话,那么这两个数据对应的标签应该是一样的,因为两个数据如果在高密度区域接近的话,那么它们之间会有很多过渡数据,所以它们两个的标签有很大概率是一样的。

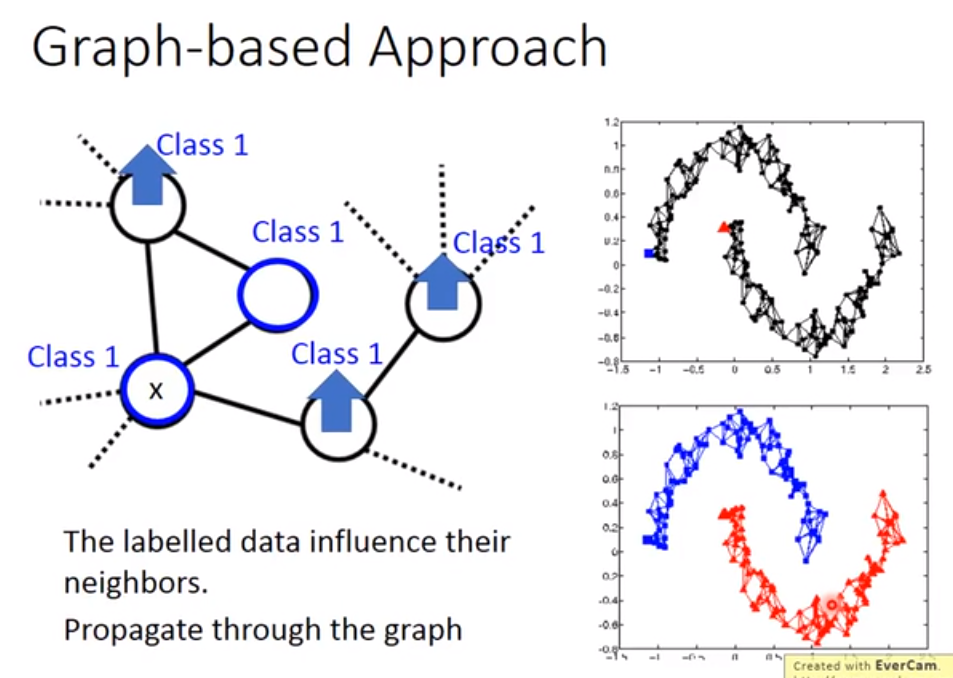
那么如何判断数据是否在一个高密度区域相近呢?可以做聚类Cluster;也可以使用基于图的方法(Graph-based Approach),把所有的数据点都建成一个图,然后去计算各个数据之间的相似度和边界,如果两个数据之间能通过图到达的话,那么它们就属于同一个标签,否则就不属于。
如何构建一个图?(不太懂,Semi-supervised 44:22 - 47:52)

在基于图的方法中,跟带标签的数据相连的数据,它们的标签相同的几率就很大,并且这种现象会在图上传播开来,要让这种方法有效的话,收集到的数据要够多。
给构建好的图定义一个式子用于计算图的平滑程度(有多符合我们的平滑性假设),计算结果越小意味着图越平滑。(这里也不太懂,Semi-supervised 50:15- 58:40)

五、Unsupervised Learning无监督学习
(一)聚类Clustering
- 聚类就是将一大堆的数据(比如图片)分成几部分。最常用的聚类方法是K-means,Kmeans的步骤如下:假设要将一大堆数据分成k个簇,那么先随机从这些数据中找出k个数据作为每个簇的中心,然后计算其余数据与这些簇中心的距离,并不断地更新簇中心。
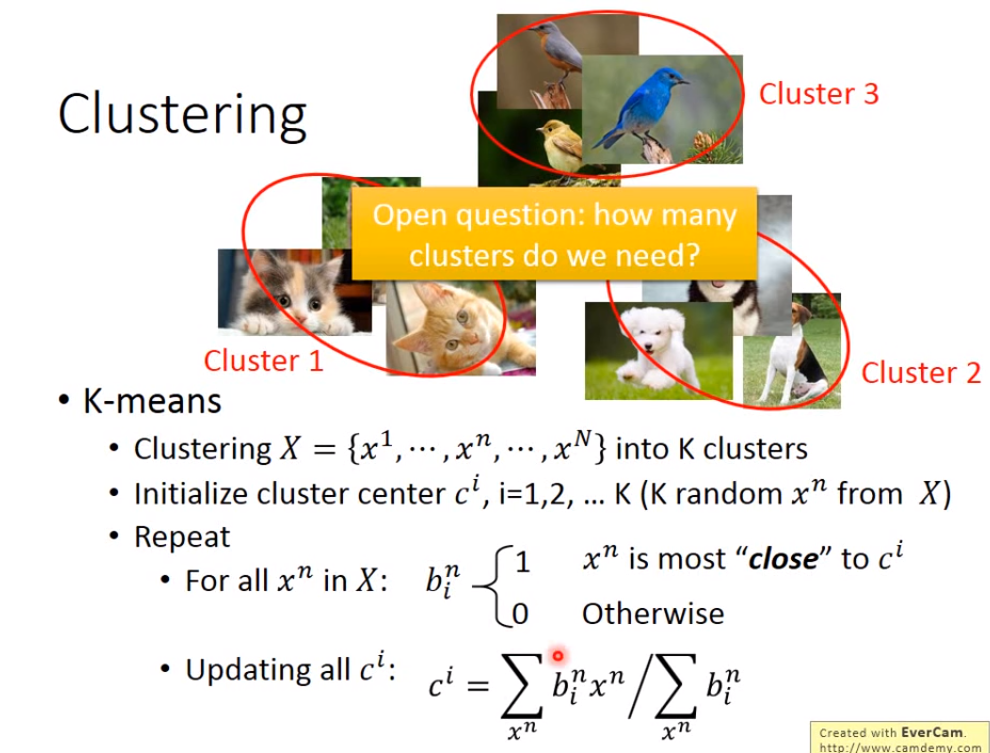
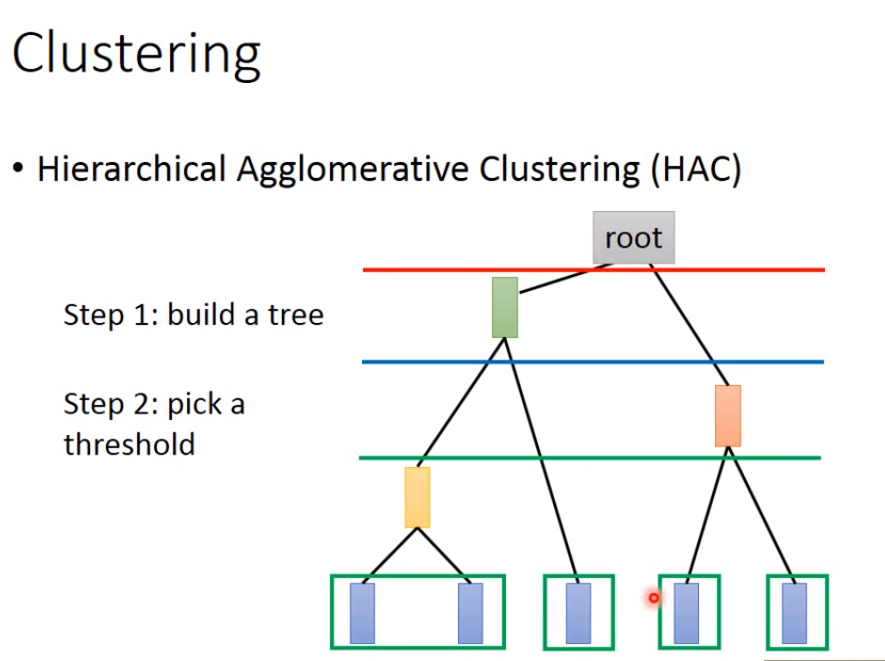
还有一种聚类的方法叫做Hierarchical Agglomerative Clustering(HAC,层次聚类),通过计算各个数据之间的相似度来建立一颗树,然后决定一个阈值对树进行分割,分割后链接在一起的数据就属于同一类的数据,整棵树的数据就被分为了多个部分。
(二)Dimension Reduction降维
- 做聚类的时候每一个对象都必须是属于某个簇(比如一堆图片会被分为几小堆图片),但属于不同簇的对象可能相互之间也有一点联系,只是联系不够深而已,这样的话聚簇后的结果就会掩盖掉这些小的联系,应该将这些对象用向量来表示,这些向量的每个维度代表了某种属性,这种用向量来表示对象叫做Distributed representation,也叫做Dimension Reduction。除了聚类这种问题,有些高纬度的数据,可能用低纬度就可以表示,这样如果进行降维后,问题可能会变得简单一些。
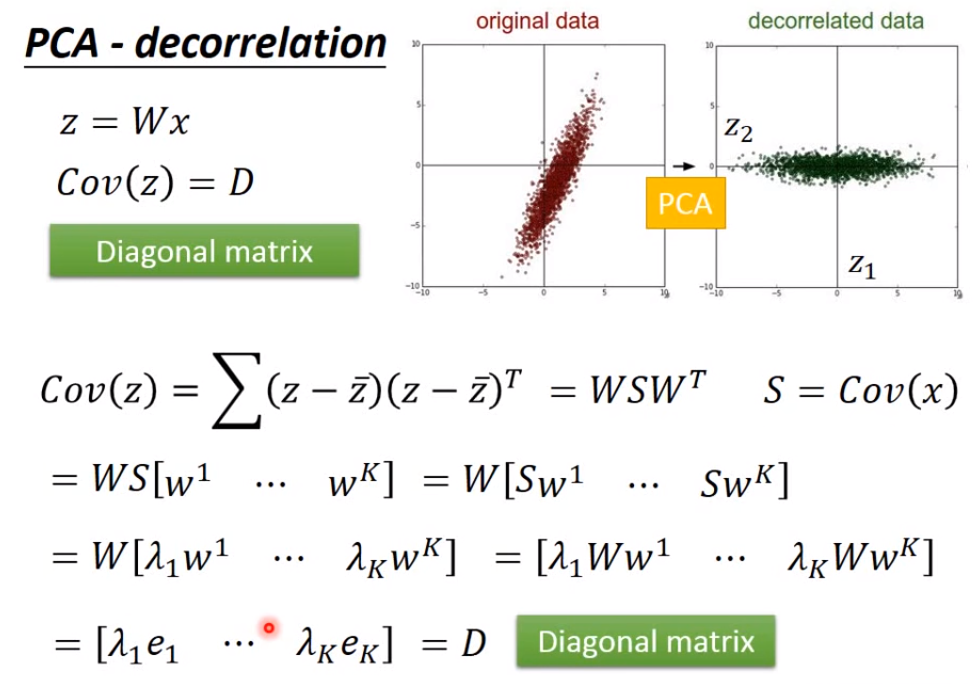
- 如何做降维呢?找一个函数,输入是原来的数据,输出是降维后的数据,降维后的数据的维度要比原先的数据小很多。最简单的降维方法是Feature selection,根据数据的分部将某些维度给丢掉,这种方法有些时候可能不管用;另外一种常见的方法就Principle component analysis(PCA,主成分分析),根据输入找出一个合适的矩阵或向量W乘上输入得到输出。
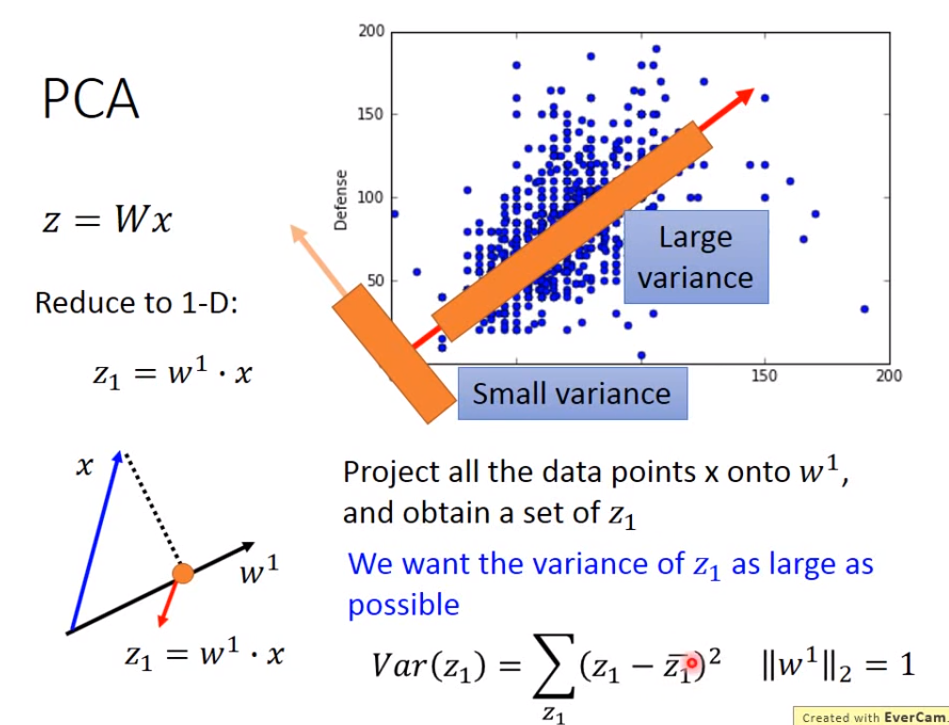
这里讲一下PCA。假设要将输入数据转化成一维的数据,就是要找到一个w1,假设w1的长度为1,使得z1 = w1 * x ,其中z1是一维的数据,即x在w1的投影;我们要选择的w1,是能够让输入投影到w1上得到的z1的方差越大越好,即z1越分散越好,因为我们希望我们的输入在降维之后它们之间的区别还能够看得到。
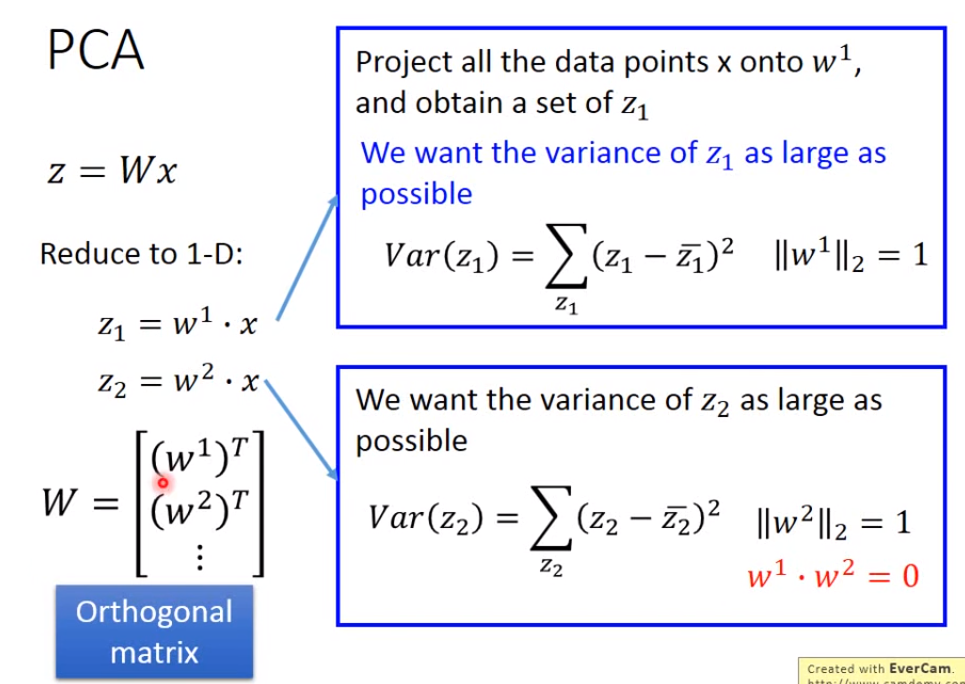
如果要将输入数据转化为更高维的数据,比如要投影到二维的话,要多找一个w2去跟输入相乘,使得z2 = w2 * x,然后z1和z2组成z,w1和w2组成W,我们希望找到的w2也要使得z2的方差越大越好,由于w2要求的条件跟w1是一样的,所以为了避免w2跟w1是完全一样的,还要加上一个限制,就w1跟w2的内积是0。如果要转化成更高维的话,那么步骤也是一样的。这样找出很多个w组成的W矩阵,是一个正交矩阵Orthogonal matrix,因为任意的一个w的模都是1,并且任意两个w之间的内积都为0。
那么如何去找w1和w2呢?可以通过拉格朗日乘子法来算。我们要找的w1和w2是能够使得输出z1和z2的方差最大的向量,对计算方差的公式进行化简得到Var(z1) = (w1) T * Cov(x)* w1,也就是要找到w1,使得这个式子值最大,由于有之前w1的模为1的限制,才不会使得计算出来的w1的每个元素都是无穷大。

上面得到的协方差矩阵给它一个符号S,S是一个对称矩阵,同时还是一个半正定矩阵(所有特征值都是非负的),经过拉格朗日乘子法(Lagrange multiplier)计算可以得到w1是S最大的特征值对应的特征向量。

同样可以计算出来w2是S的第二大特征值对应的特征向量,因为经过计算可以得到w2也是S的特征向量,但是又由于w2要跟w1的内积为0,所以它们的特征值不能是一样的(实对称矩阵不同特征值对应的特征向量相互正交)。

经过PCA后得到的输出,能够发现用这个输出计算协方差矩阵的话会得到一个对角矩阵,也就代表这个输出不同维度之间没有联系,因此在用这些输出作为其他模型的输入的时候,可以假设不同维度之间是没有联系的,这样做出来的模型的参数也不会过多,也不容易产生过拟合现象。
-
视频(Unsupervised Learning - Linear Methods 40:50 - 1:17:46,不太懂)后面还有从另外的角度来理解PCA,涉及到SVD(奇异值分解),并且改进涉及到NMF(non-negative matrix factorization,非负矩阵分解)。
-
视频Unsupervised Learning - Linear Methods还有提到Matrix Factorization矩阵分解,不是很懂 1:17:47 - 1:40:20。
-
PCA的缺点:
由于PCA是无监督的,假设要将一堆数据投影到一维上,但是有可能这堆数据本来就属于两个类别,投影到一维上反而混合在一起了,为了要解决这种现象可能要引入labeled data,LDA是考虑labeled data的降维方法,是有监督的supervised的。
PCA是线性的,对于某些数据的降维效果并不是很好。

-
在上面从另一个角度说明PCA的例子中,PCA可以表示成一个神经网络的形式,然后用Gradient Descent的方法去求得W(这种方法称为Autoencoder),用Gradient Descent的方法求得的W不会比用拉格朗日乘子法求得的W更好,但是由于表示成神经网络的形式,它可以做的更深,也就是可以做成Deep Autoencoder。(不太明白)
(三)word embeding词嵌入向量
- 如果想要用一个向量来表示一个词的话,可能会用1-of-N Encoding(one-hot编码)来表示一个词,但是使用这种编码方式的话,每个向量都是完全不一样的,没办法体现出两个词之间有什么关系;为了解决这个问题可以将这些词汇进行分类,然后用每个词汇所属的类别来表示这个词汇,但是这种方法虽然可以表现一些词之间的关系,但是不同类别的词之间有什么关系也无法体现出来;为了解决以上的问题,就要用到word embedding,把所有的词汇都投影到一个高纬度的空间上,每个维度可能都有特别的含义。
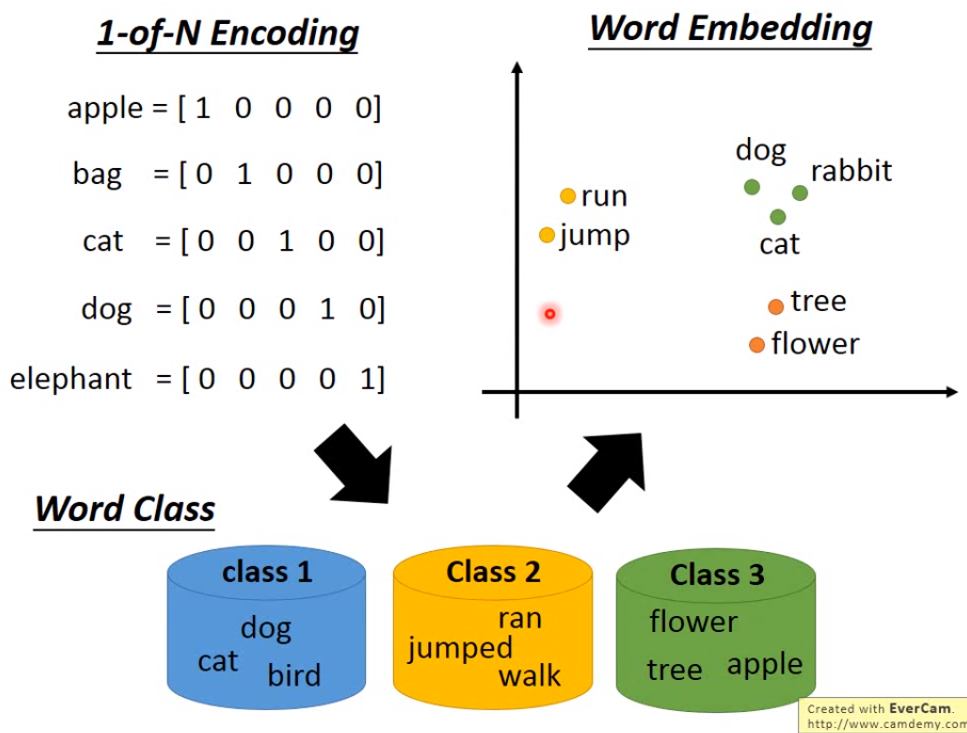
- 如何做word embedding呢?word embedding是一个无监督的方法,让机器学习大量的文章,了解每个词的上下文信息,然后构建出一个神经网络来将一个词转化成向量。
那么机器如何将词汇转换成向量呢?有两种做法。
一种是Count based的方法;如果两个词经常同时出现,那么这两个词就会比较接近。这种方法的一种比较代表性的方法是Glove Vector,这个方法是统计两个词语同时出现的次数,然后为这两个词语找到两个向量,使得计算这两个向量的内积越接近这个次数越好。
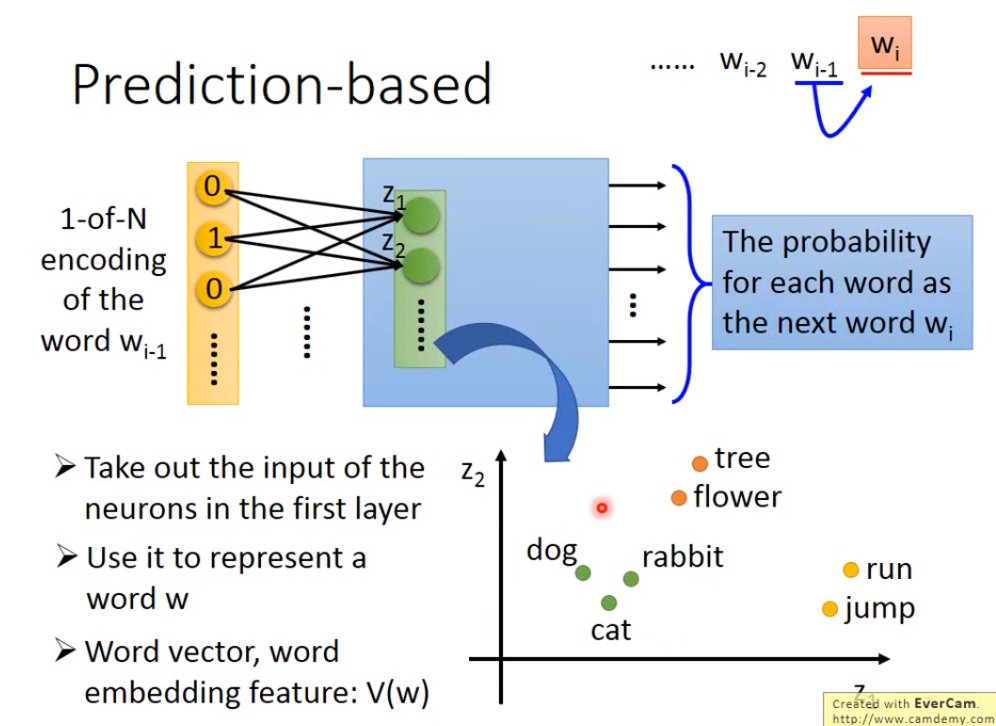
另一种是prediction based的方法;训练一个神经网络用于通过句子前一个词预测后一个词是什么,它的输入是前一个词的1-of-N Encoding,输出是下一个词是某一个词的概率(维度等于词汇表中有多少个词语),然后将第一个隐含层的输入(输入层的数据乘上权重)拿出来当作这个词汇对应的向量。为什么可以这样呢?因为模型在构建的时候就自动把根据上下文理解词汇意思考虑进去了(这里我也不太懂什么意思,Prediction-based 14::2 0 - 16:25)。
如果觉得只根据前面一个词汇来预测后面一个词汇不太好的话,可以拓展到前面n个词汇,通常拓展到10个,这样才能得到合理的结果。让前n个词的1-of-N Encoding使用同样的权重作为第一个隐含层的输入(如果使用不同的权重的话,那么这n个词调换位置的话之后就会产生不同的向量),因此要得到第一个隐含层的输入z的话,可以先将这个n个词的1-of-N Encoding相加然后再乘上权重。
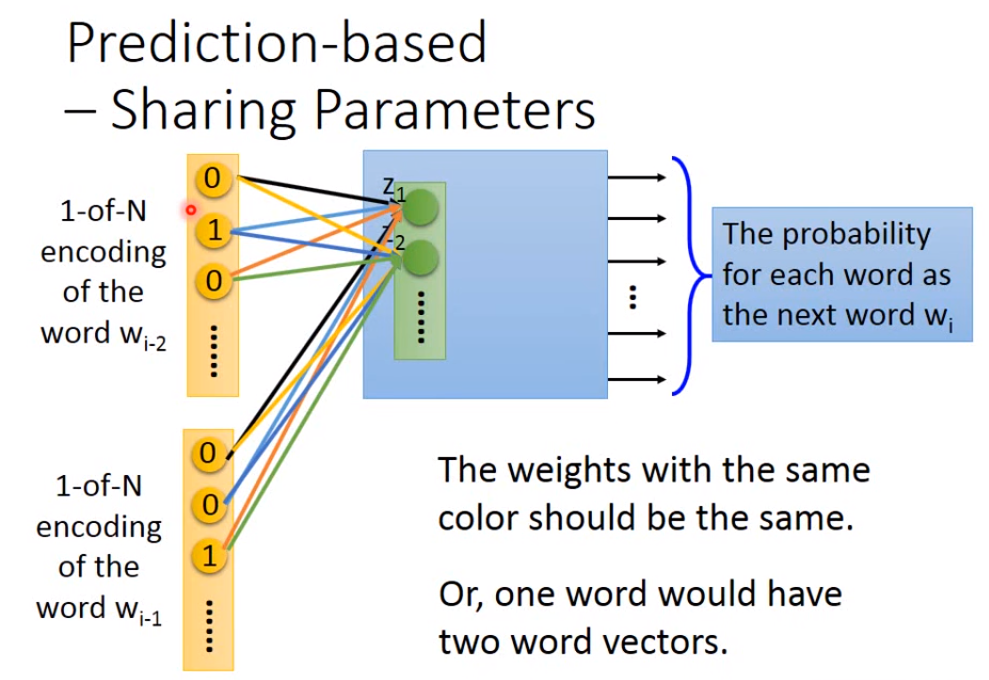
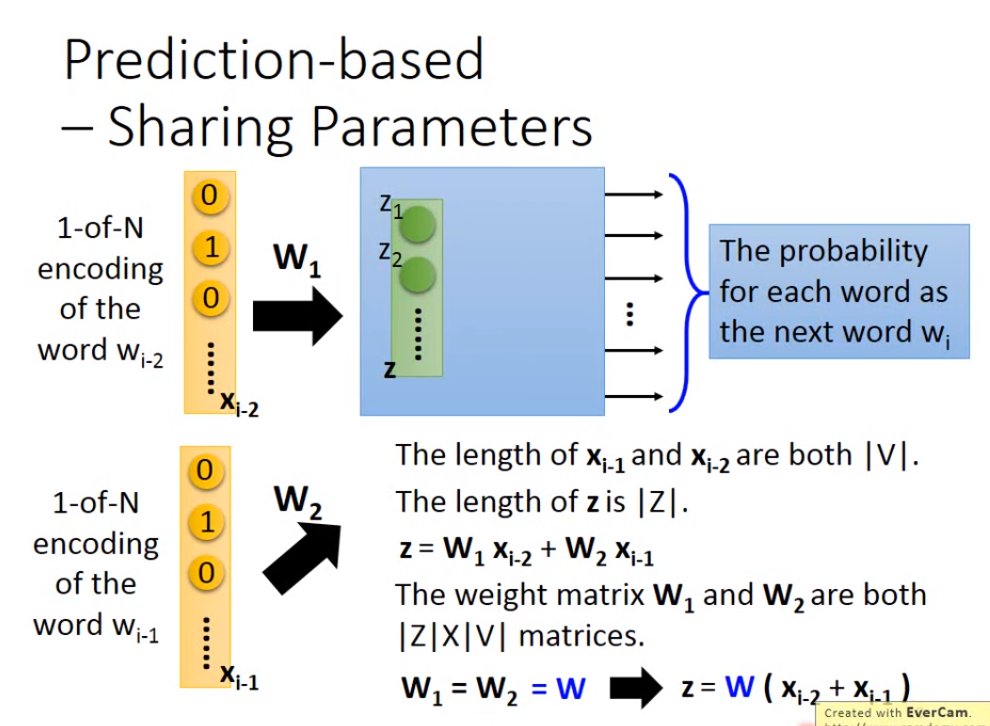
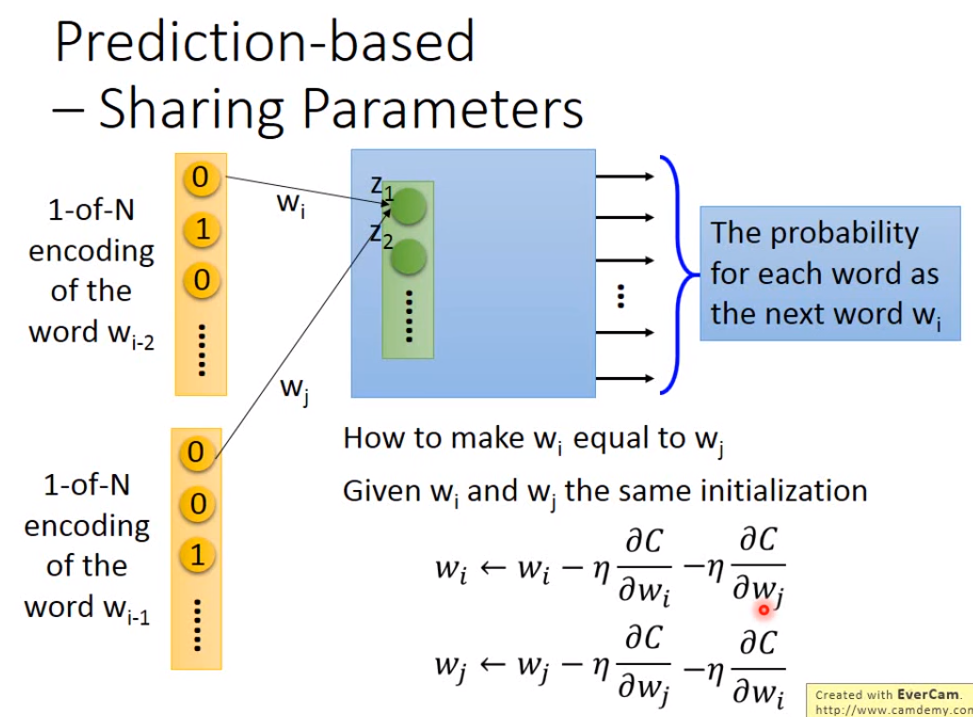
那么如何让n个词的权重保持一样呢,需要给这些权重相同的初始值,并且在做gradient descent更新参数的时候,相互减去各自算出来的偏微分。
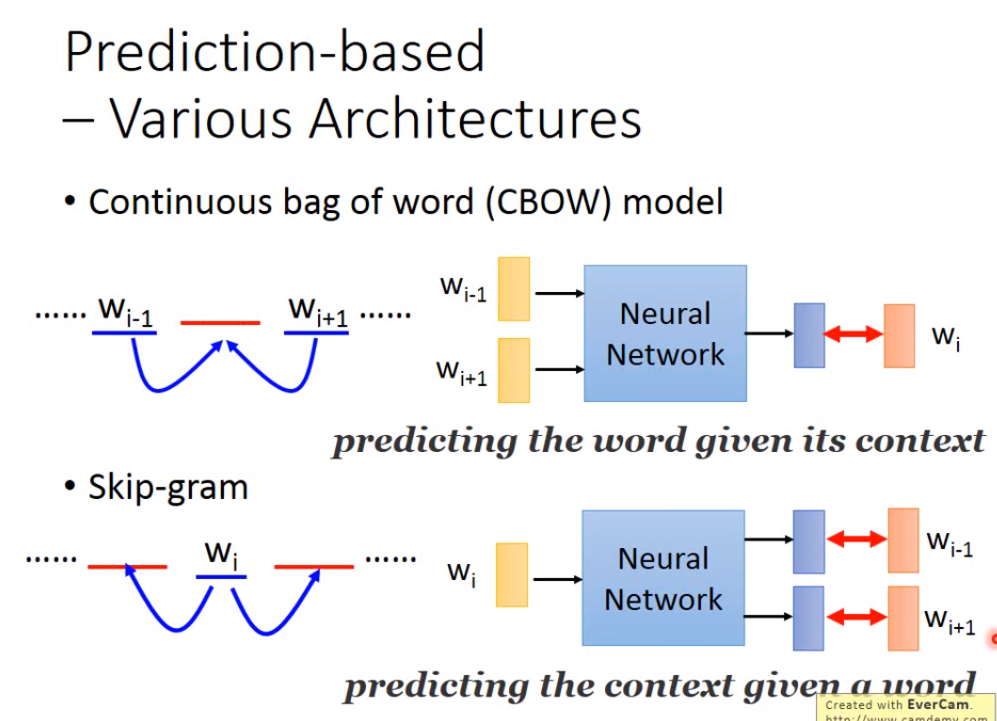
这种Prediction-based的方法还有不同的变形,比如CBOW model(拿前后的词汇去预测中间的词汇)和Skip-gram(拿中间的词汇去预测前后的词汇)。
(视频后面还有word embeding的一些应用,不太懂)
(四)Neighbor Embeding邻域嵌入方法
- Manifold Learning流形学习。我们的data points数据点可能是分布在高维的一个manifold,也就是说这些data points其实是分布在低维的一些数据点,然后被扭曲了放在了高维上,比如一个球,它的表面是二维的,但是整个却被放在三维的空间上。由于这些点分布在高维空间,那么要计算它们的相似度,如果直接用Euclidean distance欧式距离来计算的,很可能得到错误的结果;我们做manifold learning就是为了将高维的空间摊平后在进行计算,这样得到的结果就会正确许多。

Manifold Learning的方法有很多。有一个方法叫做Locally Linear Embedinng(LLE,局部线性嵌入)。
先在原来的点的分部空间中,选出某个点xi的邻近点xj,假设每个xi都可以由它的邻近点xj进行线性组合而成,然后找出一组权重wij(wij代表xi和xj之间的关系)使得邻近点xj进行线性组合之后与xi的距离越小越好。然后在进行降维,把所有的xi和xj都基于wij转化成zi和zj。


LLE需要好好调整邻近点的数目,太大或太小都会导致不好的结果。
另外一种方法是Laplacian Eigenmaps(拉普拉斯特征映射,听不懂,Unsupervised Learning-Neighbor Embedding 10:00 - 17:22),如果两个点在高密度区域相近的话,那么降维后得到的点也一样很相近。
还有一种方法是T-distributed Stochastic Neighbor Embedding(T分布随机邻域嵌入,t-SNE)。前面的方法都是假设相近的点降维后要仍然相近,但没有假设不相近的点在降维后要分开,而T-SNE就把这种情况考虑进去了。T-SNE在原来数据点的分布空间中,会计算所有点之间的相似度S(xi,xj),然后会进行归一化,也就是计算P(xj|xi),得到一个概率分布;然后要找到一组z使得同样进行计算相似度和归一化后得到的概率分布能够与之前的概率分布越近越好(衡量两个概率分布之间的相似度就是通过计算KL散度,找到一组z使得这两个分布之间的KL散度越小越好,怎么计算没听懂)。

在做t-SNE的时候由于要计算所有点之间的相似度,可能计算量会很大,所以通常会用一些比较简单的降维方法比如PCA把维度降下来之后,再做t-SNE进行第二次降维。一般t-SNE不是用在为训练模型所需的数据做准备,而是通常用来进行可视化,看看高维的数据在低维上的分布是什么样子的。
(t-SNE在计算点的相似度的比较特别的地方在视频后面有提到 Unsupervised Learning - Neighbor Embedding 25:00 - 30:58)
(五)Auto-encoder
- encoder其实就是一个neural network,可以将某一个输入转码成某一个输出,通常这个输出就是输出的一种压缩表示,输出的维度通常是要比输入的维度小的。但是由于现在是无监督学习,我们只有输入,并且不知道输出的样子是什么样的,那么假设我们现在有一个decoder(也是一个neural network),这个decoder可以将encoder得到的输出进行重构回原来的输入;这样的话,如果将encoder和decoder连接在一起的话,就既有输出(目标值)又有输入了,那么可以通过训练来同时得到encoder和decoder这两个neural network。

在PCA中也有做类似的事情,让输入和输出之间的差距尽可能小,然后取隐含层的输出作为降维后的结果。

PCA只有一个隐含层,如果变成更多隐含层的话就得到了deep auto-encoder。其中各层的权重不一定是要对称的,通常都是直接用Backpropagation来直接训练这个神经网络。deep antuo-encoder重构出输出的效果显然是要PCA好的。

- auto-encoder可以用在文字检索text retrieval上,将文件通过auto-encoder得到输出,然后把要检索的词也通过auto-encoder,如果这个词在文件中有出现的话,那么这个词在编码后得到的输出一定会跟文件编码后得到的输出的某一部分很相似。

auto-encoder还能用在图像检索上,将图片先通过auto-encoder后在进行检索结果会比直接拿图片进行搜索得到的效果要好很多。
auto-encoder也能用来做DNN的pre-training,用来找DNN的参数的较好的一个初始值。每一层对应的参数都通过训练一个auto-encoder来找到。然后之后在训练一个DNN的时候,再通过backpropagation来fine-tune微调一下这些参数,就能得到较好的一个DNN了。pre-training用在当有大量的unlabeled data和少量的labeled data的时候比较好用,可以通过大量的unlabeled data和auto-encoder来将参数的初始值找好,然后通过labeled data来调整这些参数。
- auto-encoder还能变得更好,比如De-nosing auto-encoder。跟原来的步骤其实差不多,不过增加了一步,给原来的输入加上一些噪音数据再进行encode,这样得到的encoder会更加健壮一点,因为encoder不仅可以编码还能去取噪音。

- 前面通过auto-encoder对输入编码后得到的输出我们通常叫他embedding或Latent Representation或Latent Code,得到这个embedding的方法就是同时构建一个decoder,并使得decoder的输出跟原来encoder的输入之间越相近越好,也就是让reconstruction error越小越好。现在从另外一个角度看如何构建一个encoder。
首先我们应该如何评估一个encoder的好坏? 假设现在已经有了一个encoder,那么输入通过encoder后可以得到一个embedding,然后我们去训练一个神经网络叫做Discriminator,将原来encoder的输入和embedding一起当作discriminator的输入,可以判断它们两是否属于同一组。要训练一个神经网络即通过训练得到一组能够使得Loss函数值最小的参数;如果已经找到了能够使得Loss函数值最小的参数,然后此时的Loss函数值很小的话就说明这些embeddings是具有代表性的,如果此时的Loss函数值很大的话就说明这些embeddings不具有代表性。
知道如何评估encoder的好坏之后,也就能够得出一种新的构建encoder的方法,也就是找一组参数,使得经过encoder得到的embedding和经过encoder的输入在作为Discriminator的输入时,能够得到较小的Loss函数值。也就是说这种新的构建encoder的方法是同时训练encoder和discriminator来得到一个较小的Loss函数值。

其实一开始讲的求得encoder的方法,是这种方法的一个特例,因为完全可以对Discriminator的结构进行设计,在discriminator中让embedding经过一个decoder得到重构后的输入,然后将这个重构后的输入与encoder的输入进行比对后判断它们是否是一组的,这跟一开始讲的求encoder的方法是一模一样的。

-
(More about Auto-encoder 2_4, Skip thought, Quick thought)
(More about Auto-encoder 3_4, Feature Disentangle特征分离, Voice Conversion变声, Adversarial Training对抗性训练,instance normalization, adaptive instance normalization) -
encoder通常将输入转化成的输出是continous vector,如果现在encoder的输出是discrete representation离散表示法的话,比如one-hot编码,就能够更容易被人理解或者更容易做分类。要让encoder输出是discrete representation的话,就在训练encoder中间加上一步,通过某些规则将embedding转化成discrete representation,然后再将discrete representation丢到decoder中去重构成原来的输入。虽然将embedding按照某种规则转化成discrete representation通常是没有办法微分的,但仍然有某种方法能够将这个模型训练起来。

这类让encoder的输出是discrete representation的一种比较有名的方法叫做Vector Quantized Variational Auto-encoder(VQVAE),原来的encoder会输出一个continuous的向量,然后用这个向量跟一个codebook(包含很多向量,也是学习而来)里面的向量进行计算相似度,然后找出一个codebook中相似度最高的向量作为decoder的输入,然后重构成原来encoder的输入,这个重构出来的东西要跟原来的输入越相近越好。

如果将这种输出是discrete representation的encoder应用到语音识别中,encoder的输出通常就是语音中的内容部分,因为这个discrete representation的输出更容易存储discrete 的东西,其他的部分就可能会被过滤掉,比如音色、噪音等。
这些auto-encoder的输入除了是向量之外,也可以是sequence,比如一大堆的文件,这样encoder后得到的结果可能是文章的摘要。

但是可能效果不太好,如果要得到好的结果需要额外训练一个discriminator用来判断输入的东西是否是人写的,然后在训练encoder的时候,要让encoder的输出骗过discriminator,让discriminator觉得这是人写的东西,这样的话得到的结果就会比较好。

六、Explainable ML
- Explainable machine learning不仅能够给我们提供答案,还能为为何做出这样的解答提供解释。比如在做分类时,给机器一张图片,它不仅可以告诉你这是一只猫,还能告诉你为什么。explaination可以分为Local Explanation和Global Explanation,Local Explanation就是告诉你为什么机器认为这张图片是一只猫的图片。而Global Explanation就是告诉你机器内心中猫是长什么样的。Explainable ML可以用在很多地方,比如让机器来判断简历好坏的同时让机器告诉我们为什么,这样我们才能知道机器判断简历好坏是否公平;或者用在判断罪犯是否可以假释、判断是否可以给某人贷款、模型诊断(看看机器学习到了什么东西,用于修正或增强机器学习到的模型)。
- Local Explanation(Explain the decision)的精神是这样的。对于一个输入对象,它由很多部分组成,比如一个图片由很多个像素或者很多个部分组成,一段文本由很多个词语组成。那么我们要如何知道哪个部分对机器做出决定来说的很重要的部分呢?只需要对每个部分轮流做改动或删除(如何做改动和删除需要自己做决定,需要调参),然后看看这个改动对机器做出决策的影响,如果影响很大的话这个部分就是很重要的部分。举例来说,在做图像识别的时候每次用一个灰色的像素去遮掉图片的一部分看看对机器做出判断的影响;或者从另外一个例子来说,输入给机器一张图片对应的向量,然后输出这种图片是某种动物的概率,然后给这个输入的向量中的某一个像素加上小小的变动,然后看看这个变动对输出造成了多大的影响,计算变动对输出造成了多大影响其实就是计算输出对这个变动的像素的偏微分的绝对值,对每个像素都进行变动并计算偏微分后能够得到一张saliency map显著图,这个图能够告诉我们哪一些部分是比较重要的,越重要图中的点越亮。
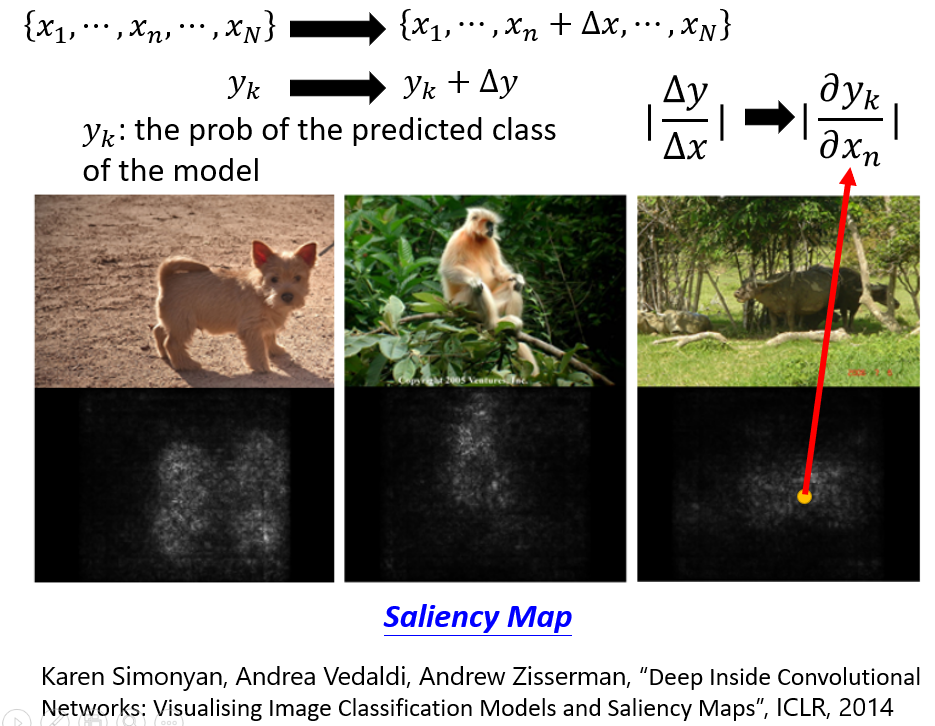
不过这种计算偏微分的方法有一个局限就是Gradient Saturation梯度饱和,比如当某个部分的值在比较小的时候,它的变动对机器的决策变动影响是比较大的;但是当它大到一定程度后,它的变动对机器的决策变动的影响就不那么大了,这个时候如果我们计算偏微分的话偏微分就会很小甚至接近0,那么我们反而会觉得这个部分不是那么重要了。为了解决这种现象可以用Integrated gradient或DeepLIFT。
不过这种机器解释的方法也可能受到攻击,比如给要分类的图片加上一些噪音点,这些噪音点对图片的分类结果没有影响,但是却能让机器错误地以为看到这些噪音点才做出的决策,在做Explainable ML的时候要注意这样的问题。
- Global Explanation:Explain the whole model。(听不懂,Explainable ML4_8、5_8)
- 用一个模型去解释另一个模型(Explaniable ML6_8 、7_8,不太懂,LIME)(Explaniable ML8_8,Decision Tree)
七、Attack ML Models
- 我们通过机器学习来构建的模型,不仅仅需要能够应对一些噪音数据,还需要能够应对一些恶意攻击(用一些恶意的输入来骗过机器学习产生的模型,进而达到不好的目的)。
- 如何对模型进行攻击?在原始的输入上加上一些特别的杂讯,让机器的输出变得完全不一样;
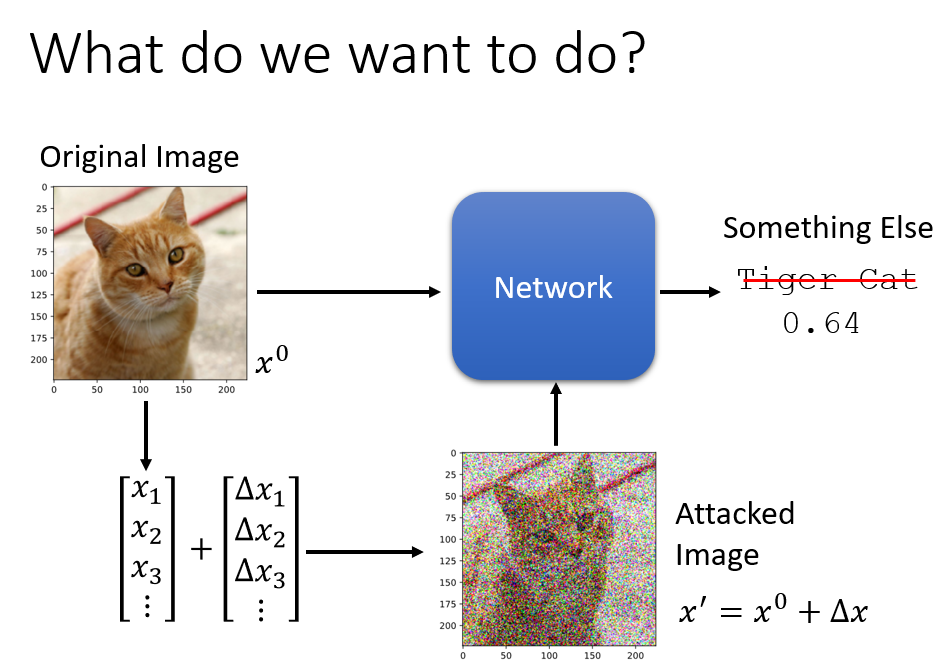
那么如何找到这些杂讯呢?或者说如何找到这些带有攻击性的输入呢?
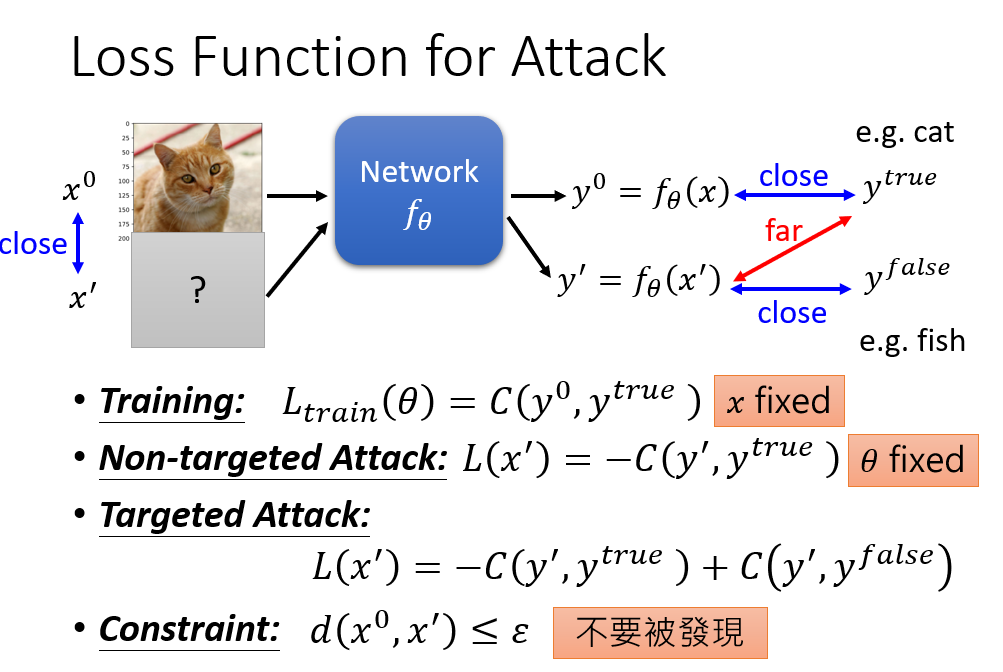
攻击可以分为Non-targeted Attack和Targeted Attack,即没有目标的攻击和有目标的攻击。正常情况下我们希望训练出来的模型的输出与真实值之间越接近越好,而没有目标的攻击就是找一个输入,让已经训练好的模型的输出与真实值之间越远越好;有目标的攻击就是找一个输入,让已经训练好的模型的输出与真实值之间越远越好,并且同时要让这个输出与某个错误值之间越近越好。在找出攻击的输入的前提下,我们还要加上一个限制,就是让这个输入跟原本要输入到模型中的数据越接近越好,达到一种伪装的效果。
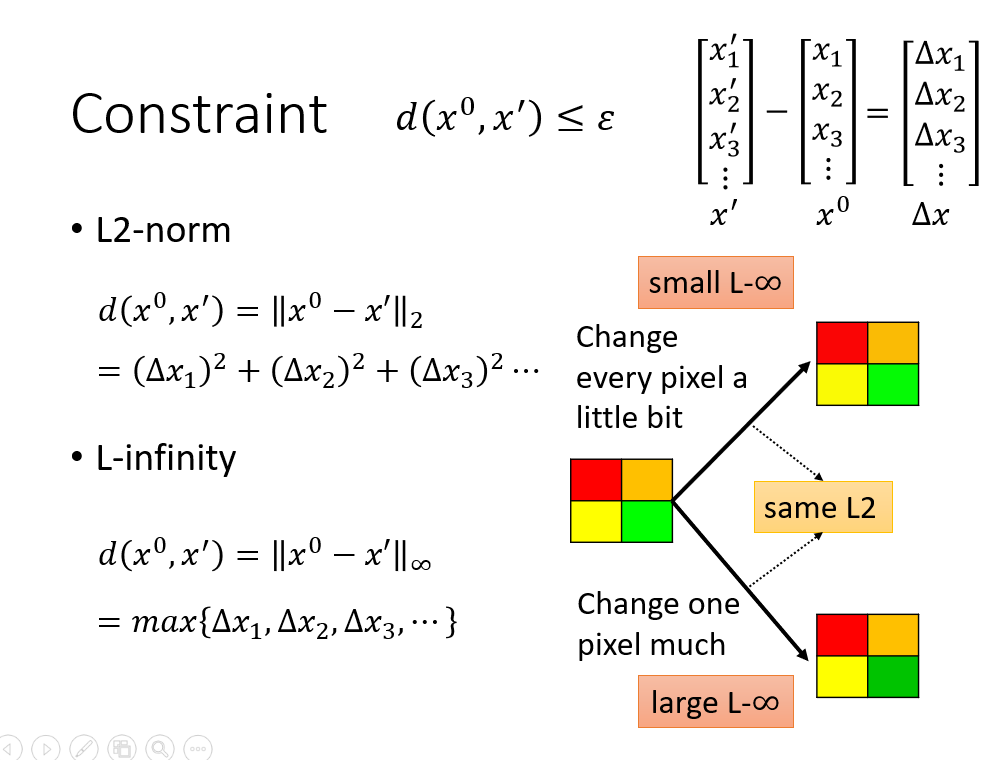
那么如何判断带有攻击的输入跟原本的输入之间的相近程度?这里有两种做法,不过更多的时候要根据具体情况来设计。相比于L2-norm,在图片识别上用L-infinity来衡量相近程度相对比较好,因为可能会有这样的情况:两个带有攻击性的输入,在相同L2的基础上,有较小的L-∞的攻击性输入比有较大L-∞的攻击性输入更难被分辨出来。
找这些带有攻击性输入的方法其实跟训练一个神经网络的过程差不多,只不过现在是要把输入当成参数,然后去训练找到使得Loss函数最小的那个输入,同时还要加上限制。找这个攻击性输入也是要通过gradient descent去找,将原本的输入作为初始值,然后计算gradient descent去更新这个输入,并且由于有要跟原本的输入相接近的限制,所以在更新了输入之后,如果不满足限制的话还要进行修正(对所有满足限制的输入进行穷举,返回最接近这个不满足限制的输入的输入)。

-
找攻击性输入的不同方法之间的差别往往在于计算攻击性输入与原先输入之间的接近程度的方式不同,以及让Loss函数最小化的方式不同。这里再提供一种比较简单的找攻击性输入的方法,FGSM(Fast Gradient Sign Method),只需要计算一次就能找到攻击性输入。

-
前面的找带有攻击性的输出的方式其实都是White Box Attack,需要在知道原先神经网络的参数的情况下才能去找到这个带有攻击性的输出。那是否只要保护好模型的参数不被知道就能够防止攻击了?答案是否定了,在不知道模型参数的情况下也能够找到带有攻击性的输出,即Black Box Attack是可能的。
假如我们拥有训练原先模型的训练数据的话,我们可以用这些训练数据自己训练一个新的网络,称为proxy network,然后利用这个proxy network来找到带有攻击性的输入,再用这个带有攻击性的输入去攻击原先的神经网络,这样做往往能够成功。那么如果保护好训练数据的话呢?也是不行的,因为只要往原先的模型中投入大量的输入得到输出,然后将这些大量的输入和输出当成训练数据去训练proxy network,同样是可以的。
- 防御这种攻击的手段有两种。一种是passive defense被动地防御,不改变原有的模型,而是给输入加上一些东西用于抵御攻击;另一种是Proactive defense主动地防御,在训练模型时就把防御攻击的内容加到模型中。
passive defense的例子,让输入的图片通过一个filter,filter做一些比如平滑的事情,然后对没有杂讯的图片不会造成很大影响,对有杂讯的图片能够让杂讯变得不那么有攻击性。
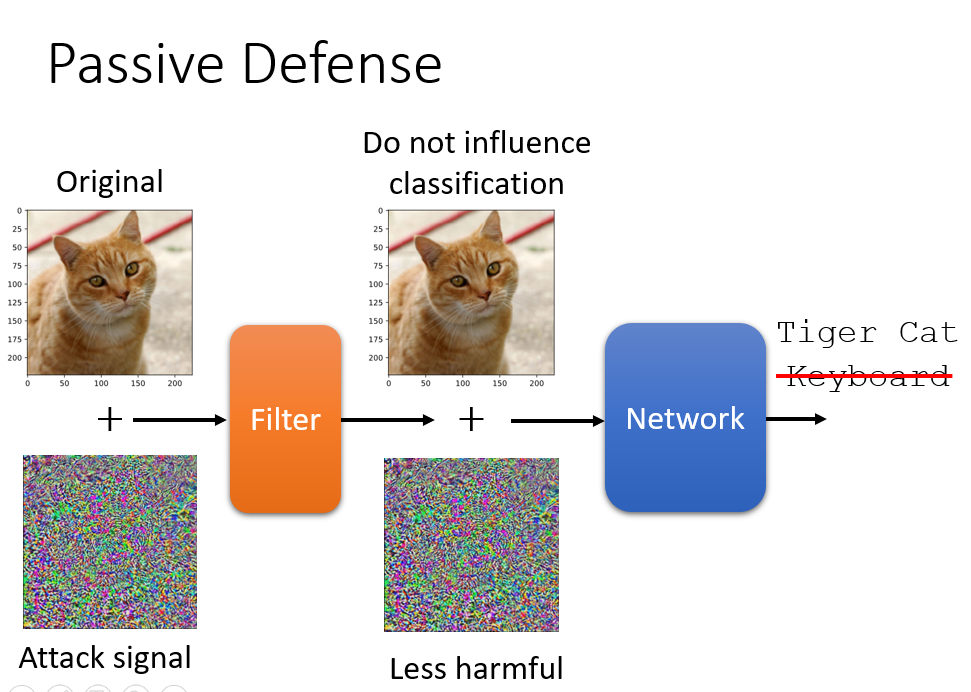
还有passive defense的方法叫feature squeeze的方法,让输入经过模型后得出预测,然后再让输入经过一个squeezer后再到达模型得出预测结果,如果它们相差很大的话,就可以判断这个输入可能带有杂讯。
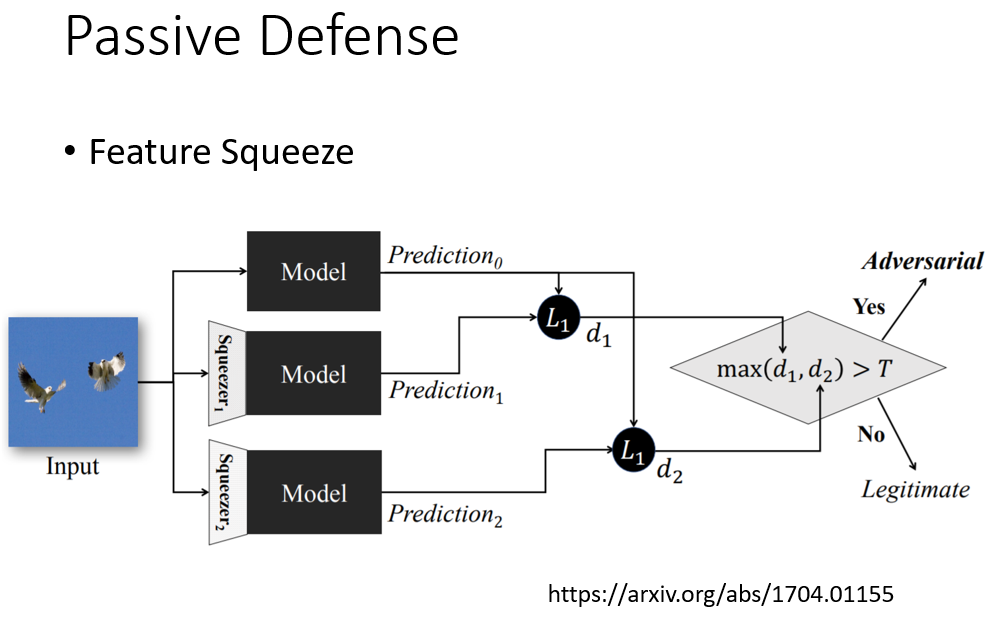
或者是Randomization at Inference Phase,对输入进行随机缩放和加上不会影响输出的一些东西。
proactive defense的精神是在训练模型时找出模型的漏洞后补起来。在普通训练完一个模型之后,通过攻击算法和训练集找出带有攻击性的输入,然后再利用这些带有攻击性的输入去训练模型。这个过程要重复很多次,这样构建起来的模型才会足够强健。

八、Network Compression
- 我们希望我们的模型能够放在一些移动设备中,这些移动设备可能存储空间有限,计算能力有限,因此网络不能够太深太大,参数不能够太多,否则就可能无法应用到移动设备当中。所以我们希望我们所训练的神经网络能够缩小从而应用到移动设备上。
- 让神经网络缩小的一种方法叫network pruning网络剪枝,把神经网络中的某些权重或者神经元剪掉来达到缩小神经网络的目的。先利用大量的数据训练一个神经网络,然后评估weight(如果比较接近0,那么就不够重要)和neuron的重要性(如果一个neuron的输出总是接近0,那么这个neuron就不那么重要),然后移除那些不重要的weight和neuron,再把得到的较小的新的神经网络利用原先的训练集来更新参数(能够降低移除weight或neuron对神经网络的损伤)。通常每次移除weight或neuron的数量不会太多,而是多次地进行移除和修复来达到缩小的目的,一次性移除太多weight或neuron通常会得不到好的效果。
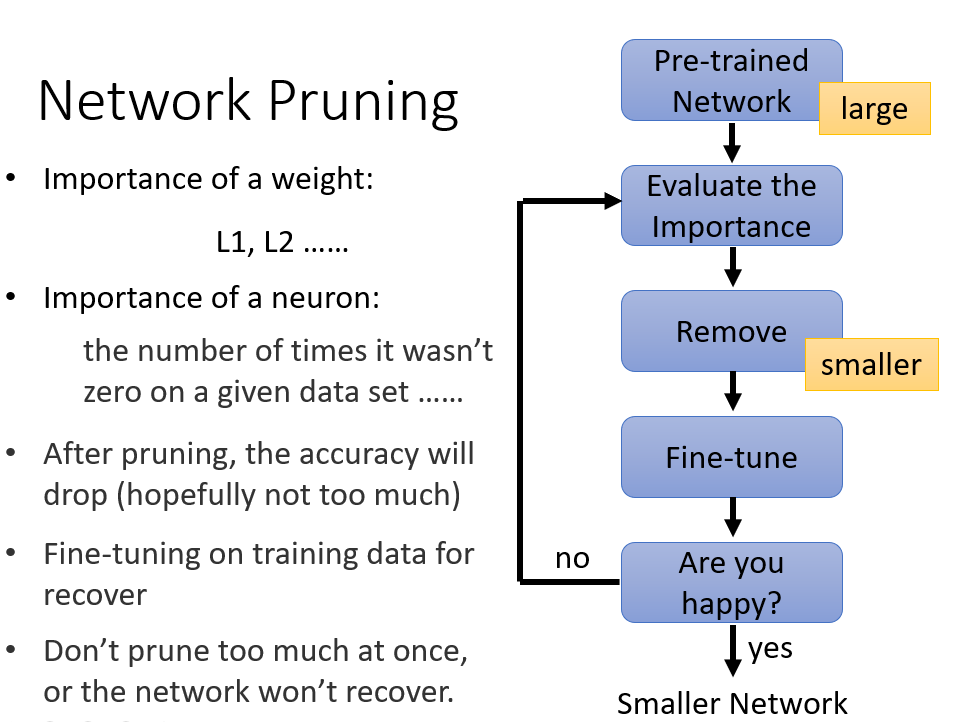
那么为什么我们不在一开始的时候就训练一个较小的神经网络,而要在训练一个大的神经网络后再进行剪枝呢?一个说法是小的神经网络比较难以训练,在训练神经网络的时候,进行gradient descent的时候常常会卡在saddle point或者local optima,而较大的神经网络相对来说遇到这种情况的概率较小,并且只要网络够大,就有办法能够解决这些问题。
剪枝会产生的问题就是网络变得不规则,这样这个网络就会比较难以实现,并且通过GPU来加速网络的执行也比较难,因为GPU加速网络执行是加速矩阵运算,但是如果网络变得不规则的话进行矩阵运算就会变得很麻烦。所以通常移除neuron比移除weight要好很多,因为移除neuron后网络仍然是规则的。
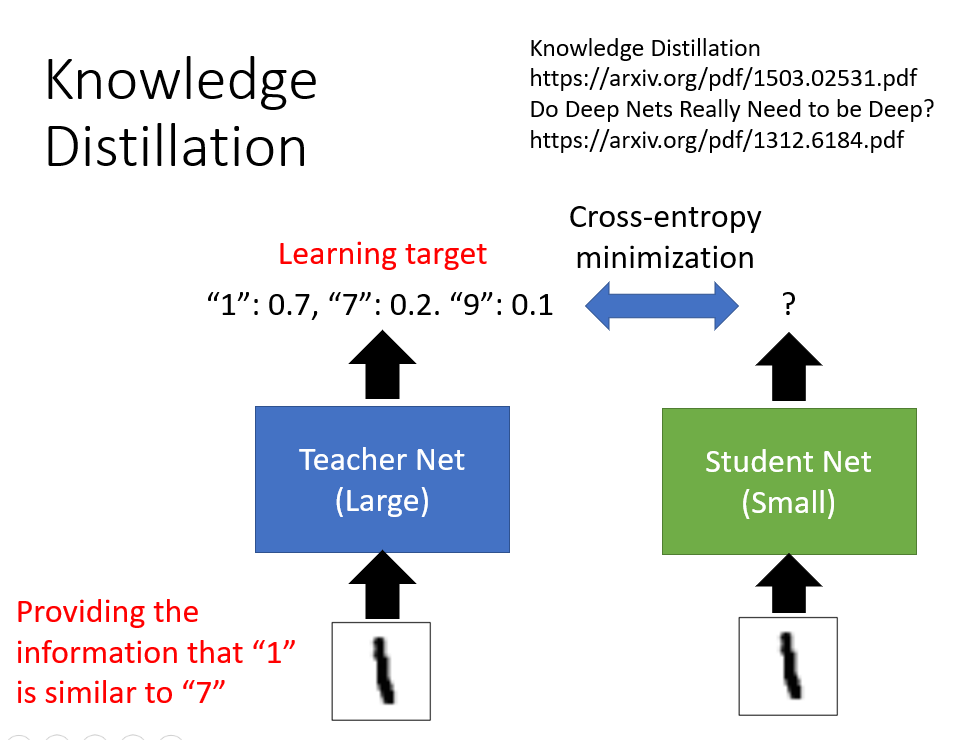
- 另一种缩小神经网络的方法叫做Knowledge Distillation知识蒸馏。先训练一个大的网络,然后再训练一个小的网络去学习大的网络的行为(小的网络跟大的网络学习会比直接训练小的网络有用的原因是,大的网络的输出往往能够提供更多的信息)。知识蒸馏的一个妙用在于可以将多个网络合成一个小的网络,就是让多个网络的输出平均,然后训练一个小的网络去模仿这多个网络在干的事情。
- 另一种缩小网络的方法叫做Parameter Quantization量化参数。可以通过用更少的比特去存储一个参数进而缩小网络;也可以通过对参数进行聚类,聚到一起的参数都用一个值来表示,这也能够缩小网络;还可以用哈夫曼编码来表示上面聚类所得到的类,比较常见的类用较少的比特来表示。
- 另一种缩小网络的方法叫做Architecture Design结构设计,调整网络的架构让它只需要较少的参数来实现缩小网络的目的。
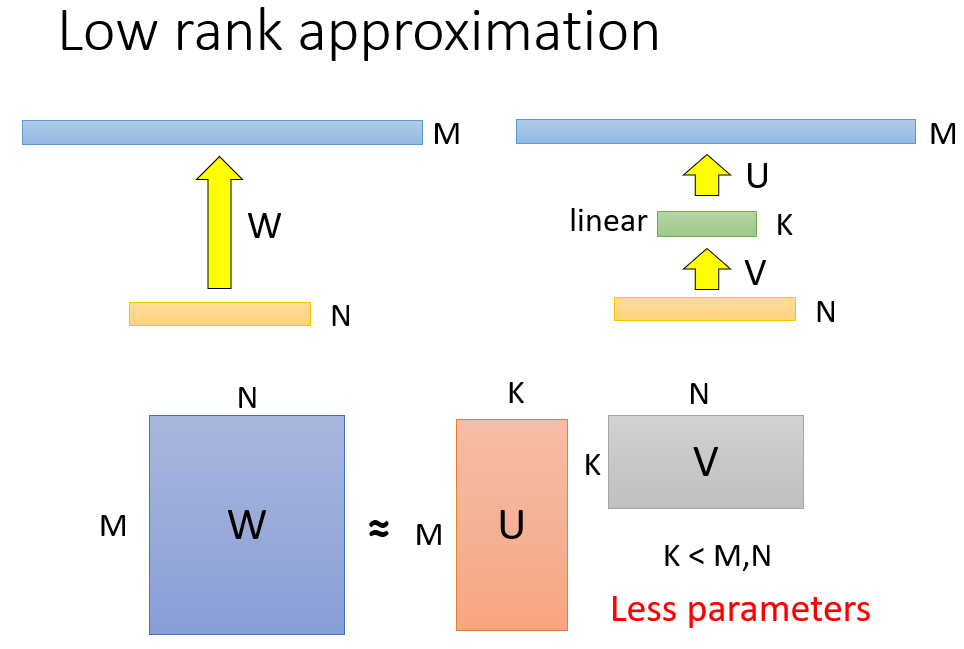
比如在原先的网络中的某两层插入一层线性的隐含层,这隐含层的神经元不要太多,这样可以减少神经网络的参数,由于原先网络对应的参数矩阵的秩会大于等于插入隐含层后得到的网络对应的两个矩阵相乘的秩,所以这种方法叫做Low rank approximation低秩近似,但是这样做可能会限制到原先网络可以做到的事情。
减少卷积神经网络的参数的一个方法叫Depthwise Separable Convolution深度可分离卷积,不太懂,见Network Comptession 5_6 6_6。















 4056
4056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









