








1、架构的演变
1.2、单体/库架构
90年代开始,当时主流的技术是JSP/HTML+Servlet+JDBC。那个时候,网站的基本网站访问量都不会太大,所以单机数据库就已经完全胜任。
架构的瓶颈:
数据量太大怎么办?
数据访问量太大怎么办? – (读写混合)
当数据库单表数据超出千万级别,就必须需要创建索引,内存放不下怎么办?
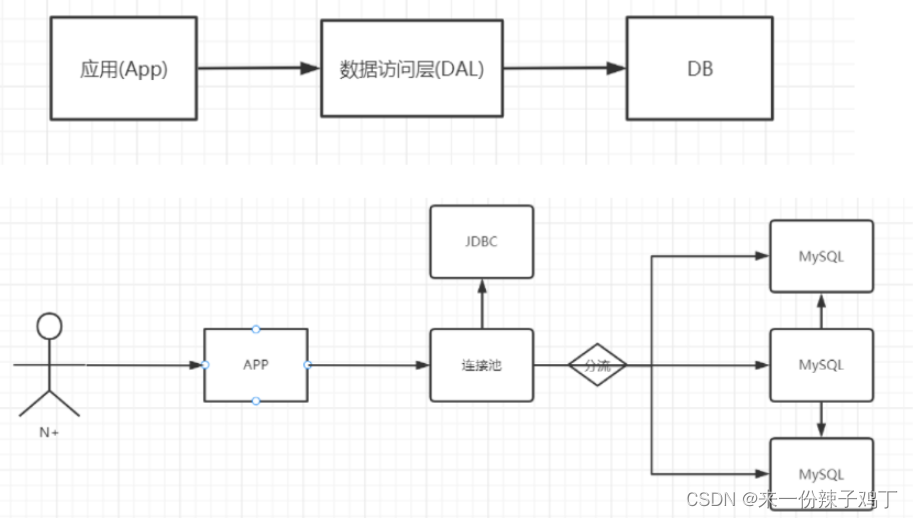
1.2、缓存+读写分离+垂直拆分
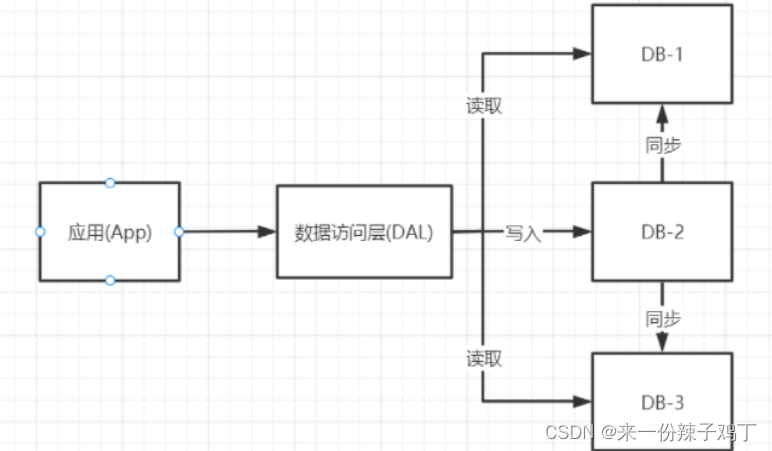
单纯的实现了读写分离,确实也解决了服务器压力,但是不足以胜任日益增长的访问量,然后我们将矛头指向了架构优化,如何优化?
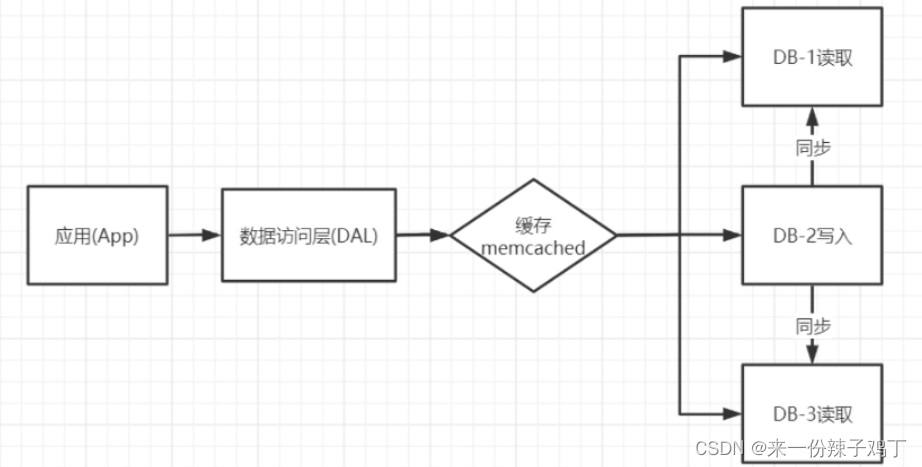
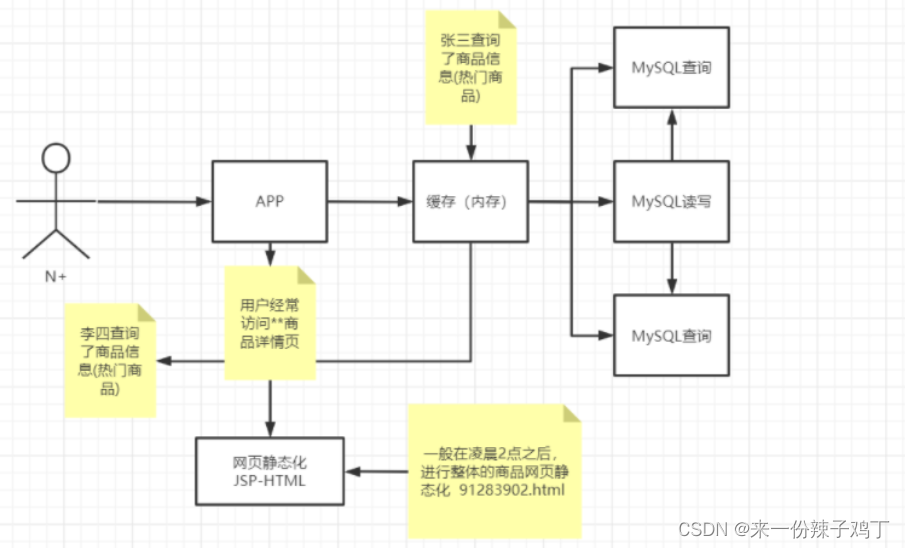
瓶颈:
用户量和数据量越来越大,即使我们通过读写分离和分库分表也不足以支撑的时候,单表数据量已经爆炸了。
1.3、分库分表+水平拆分(MySQL集群)
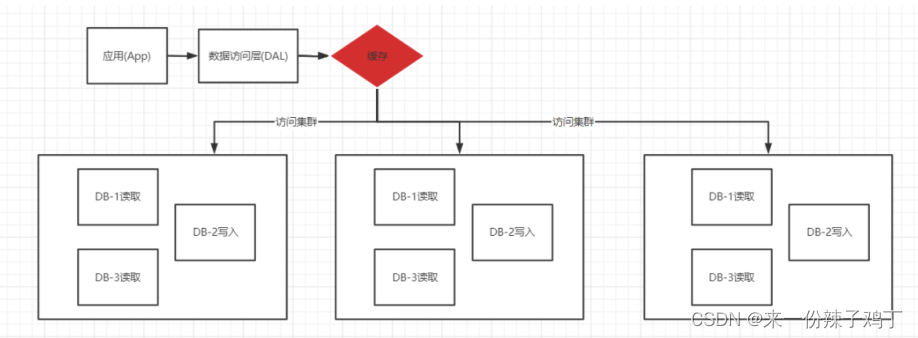
瓶颈:
近10年,是历史上科技发展最迅速的10年,我们的数据从简单的文字、图片也已经转变为各式各样的数据类型,那么传统的关系型数据库MySQL已经不能满足我们现在发展的需求。图片、热点数据、大篇幅文章、定位信息等各式各样的数据扑面而来,那么就需要我们一 一进行解决,如果有一个数据库能帮助我们分担这种特殊的数据,那么关系型数据库(MySQL、Orae)的压力也就会变小了。
同时数据的存储也从IO 1+1 变成了 IO 1+N。
1.4、当前互联网公司架构
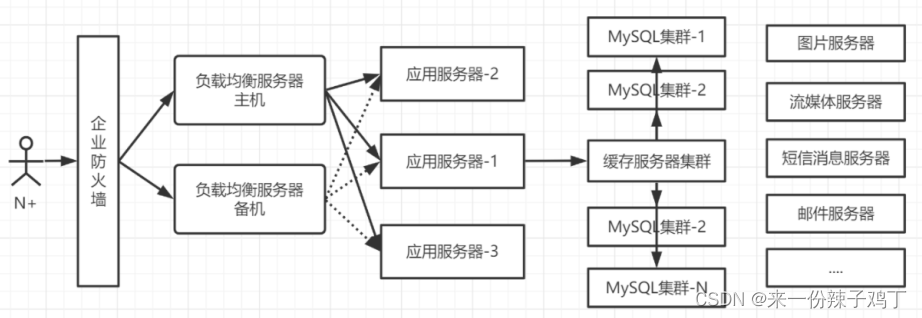
那么我们对架构的分析,大家也已经了解到了,目前互联网项目面对各式各样的数据,我们MySQL这种关系型数据库存储数据就显得特别疲惫,那么这个时候NoSQL (非关系型) 数据库就随之而来。
2、关于NOSQL
NoSQL —— 错误翻译 没有SQL
正确翻译:Not Only SQL (不仅仅是SQL) 泛指这些非关系数据库,主要适用于web2.0 时代。
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型
的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NOSOL
数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
2.1、区别
关系型数据库:
表 - 行 - 列
非关系型数据库:
典型的就是key-value形式进行存储数据,而且存储的数据类型也变得多样化,不再是单一的文字结构。
2.2、NOSQL的特点
- 扩展方便,数据与数据之间没有必然联系,0耦合。
- 大数据量和高性能 (redis => 单秒写10万次,读取11万次) QPS
- 数据类型的多样化 (5+3) String、 List、 Set、 Hash、Zset geo(地理位置信息)、hyperloglog (访客信息)、bitmap 位图(常用计算活跃粉丝和不活跃粉丝、登录和未登录、是否打卡等)。
- 不需要提前设计数据库,随取随用。
2.3、淘宝架构分析
商品基本信息 id、名称、分类基本信息
- MySQL | oracle 淘宝是对MySQL进行了开发,虽然都叫MySQL,但是内容完全不同。
2012年5月,淘宝做了一个艰难的决定,实行去IOE运动。这里的I是指IBM小型机,O是指oracle数据库,E是指EMC2,它是数据库的存储设备。
而这一次的去IOE运动却恰恰是将亚洲最成功,也是最大的oracle RAC应用的典范转换为MYSOL + PC server,当然需要mysgl的hadoop集群的架构。
商品的描述信息、评论等文字量较多的信息。
- MongoDB 文档型数据库
图片
- 淘宝 —— TFS 自主研发
- 分布式系统 —— FastDFS
- Google —— GFS 自主研发
- Hadoop —— HDFS
- 阿里云 —— OSS
商品的关键字(搜索功能)
- 搜索引擎 solr —— elasticsearch 比较火
- 淘宝自己使用 ISearch
热门的波段信息 (秒杀)
- Redis
- Tair
- memacached
订单交易
- 第三方应用 MQ消息中间件
- RabbitMQ
- ActiveMQ
- Kafka
- RocketMQ
阿里的框架发展史(强烈建议阅读): 点击查看
所以看似平凡的网页背后所需的技术支撑是多个复杂与庞大才能适用于我们现在。赠送大家一句话:所有牛逼的人都有一段苦逼的岁月!但是你只需要像SB一样的坚持,终将NB!!!
2.4、NOSQL的四大类
# KV类型
- 新浪 Redis
- 美团 Redis + Tair
- 阿里、百度 redis + memcached
# 文档类型数据库(BSON 和 JSON一样)
- MongoDB (目前企业需求也是比较大的) 是一个给予分布式存储的数据库,主要用于处理大量的文档,是一个介于关系型数据库和非关系型数据库的
中间产品,本身属于非关系型数据库。
# 列存储的数据库
- 大数据的HBase
- 分布式文件系统(一个业务拆分成多个子业务,部署在不同的服务器上)
#图形关系数据库
- 图示 存储的是图形关系,类似与朋友圈或社交平台。
- Neo4J InfoGrid
3、redis的介绍与安装
4、redis入门
5、redis的数据类型
5.1、String类型
应用场景:分布式锁、Session相关、验证码相关、计数相关(点击量/阅读量/关注)等单一的值。
5.1.1、取值赋值
关键词:set、get、append、strlen
# 设置值
set name zhangsan
# 获取值
get name
# 追加值
append name shigehaoren
# 获取某个字符串长度
strlen name
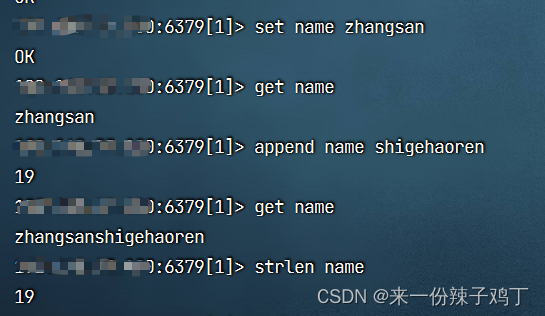
5.1.2、加减值操作
incr(increment的简写)key 每次自增1
decr(decrement的简写)key 每次自减1
incrby key n 每次固定增量n 这个可以自定义
decrby key n 每次固定减量n 这个也可以自定义
set num1 10
incr num1 # num1 11
decr num1 # num1 10
incrby num1 10 # num1 20
decrby num1 5 # num1 15
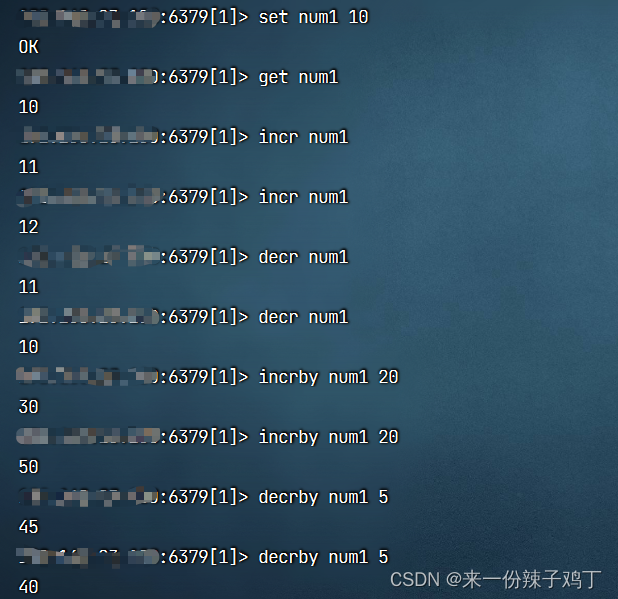
5.1.3、范围操作 getrange
getrange key index1(开始索引) index2(结束索引) 获取当前指定范围内容。
如果需要获取最大索引,index2可以写成 -1。
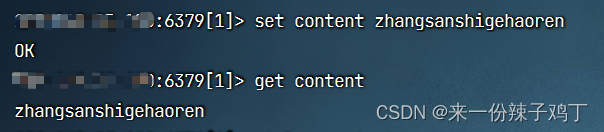
# 设置字符串content
set content zhangsanshigehaoren
# 获取字符串content
get content
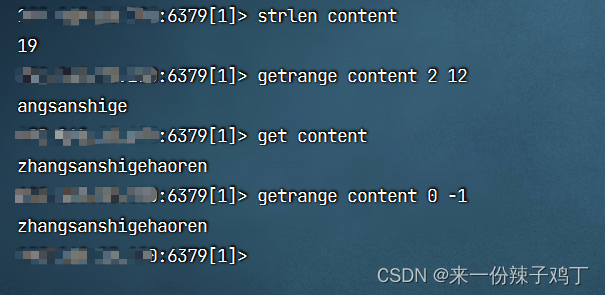
# 获取字符串content的长度
strlen content
# 获取从索引2到索引12这个范围内的字符串
getrange content 2 12
# 获取字符串content
get content
# 获取全部字符串
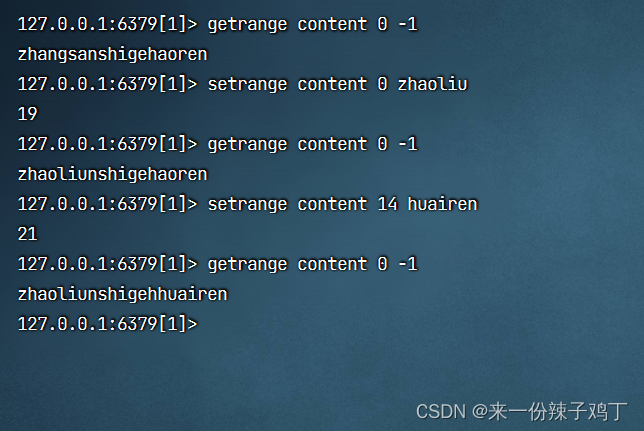
getrange content 0 -1
5.1.4、替换操作 setrange
setrange key offset 内容 # offset 偏移量 就是索引 指定位置开始替换,返回替换后的字符串的长度
# 获取从索引0到索引-1这个范围内的字符串
getrange content 0 -1
# 从索引0开始替换字符串content的内容,替换内容为zhaoliu
setrange content 0 zhaoliu
# 获取从索引0到索引-1这个范围内的字符串
getrange content 0 -1
# 从索引14开始替换字符串content的内容,替换内容为huairen
setrange content 14 huairen
# 获取从索引0到索引-1这个范围内的字符串
getrange content 0 -1
5.1.5、exists setex setnx
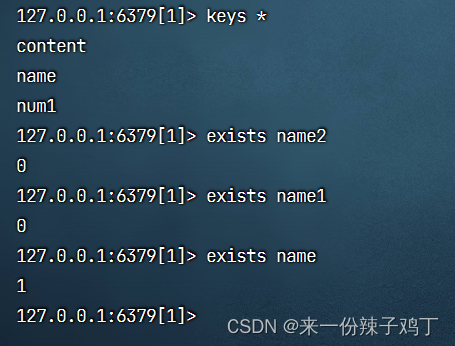
exists key 判断name2这个key是否存在,不存在返回0,存在返回1
# 判断name2这个key是否存在
exists name2
# 判断name1这个key是否存在
exists name1
# 判断name这个key是否存在
exists name
setex key time value (setex是set with expire的简写)
如果当前key存在的话,就是给当前key重新指定新的值并指定过期时间。
如果当前key不存在的话,就是创建一个新的key以及值并指定过期时间。
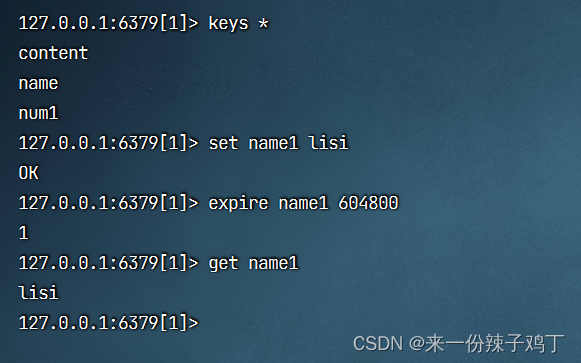
# 获取所有的key
keys *
# 添加新的key name1并指定值
set name1 lisi
# 给name1这个key 指定过期时间
expire name1 604800
# 获取name1这个key
get name1
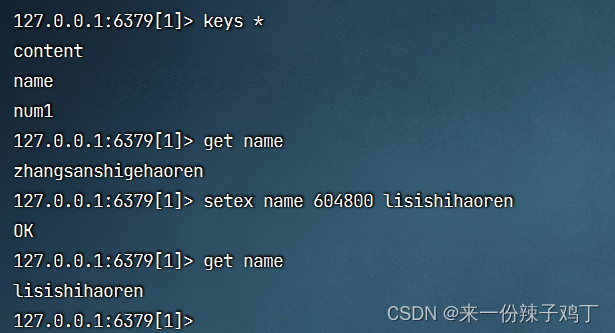
# 获取所有的key
keys *
# 获取name这个key
get name
# 由于name这个key存在 那就是指定新的值并指定过期时间
setex name 604800 lisishihaoren
# 获取name这个key
get name
setnx key value(set if not expire)如果key不存在,默认会创建一个新的key,存在不做任何操作。
即判断key存在不存在的同时,也能根据结果进行下一步操作。
# 如果key存在,不做任何操作
setnx name1 eqweqweqeqwe
# 如果key不存在,就创建一个新的key
setnx name3 eqweqweqeqwe
5.1.6、批量值操作
mset是more set的简写,就是批量添加多个key的同时并给key指定值。
mget是more get的简写,就是批量获取多个key的值。
mset k1 v1 k2 v2 …
mget k1 k2 k3 k4 …
# 批量添加stu1,stu2,stu3并给stu1,stu2,stu3指定值
mset stu1 tom stu2 jack stu3 jackson
# 批量获取stu1,stu2,stu3
mget stu1 stu2 stu3
5.1.7、关于对象的存储
#普通的json对象
{"id":1,"name":"zhangsan","age":40}
#redis存储的对象
{class:[{},{}]}
{id:1,name:zhangsan,age:43}
{id:2,name:lisi,age:16}
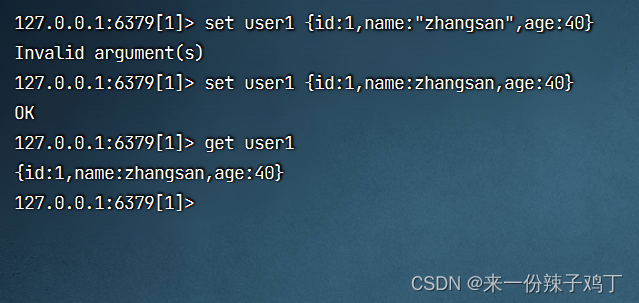
注意:字符串需要去掉引号。
建议:组合键(这个组合键的目的就是将对象中的属性和值打散,通过组合不同的key到redis中读取不同的值)
方式1:可能后面根据id读取某一个对象的情况
6、redis事务
7、压测工具
8、redis配置详解
9、redis持久化
9.1、概念
9.2、RDB(redis database)
9.3、AOF
10、redis发布订阅
11、redis集群
11.1、概念
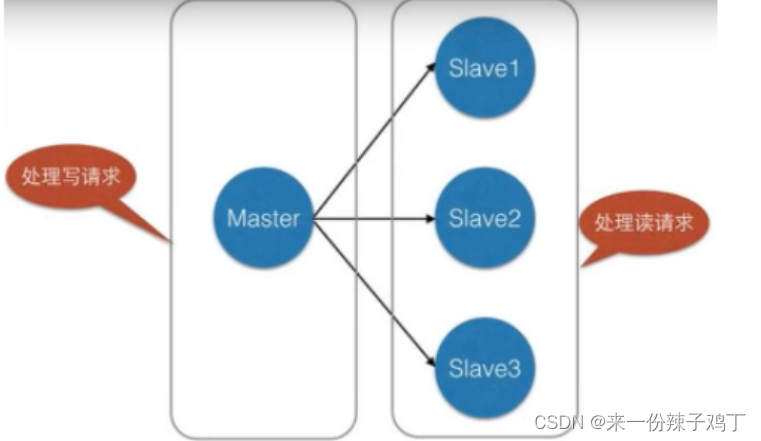
使用 redis 的复制功能创建主机和从机 (一对多) ,主从机支持多个数据库之间的数据同步。一类是主数据库 (master主机),一类是从数据库 (slave从机) (主从复制)
主数据库可以进行读写操作,当发生写操作的时候,自动将数据同步到从数据库,而从数据库一般是只读的 (读写分离)
从机接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库(只有一个老大)。
通过 redis 的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
一般情况下,80%的操作都是读取数据,所以在之前给大家介绍的架构图中,读写分离的方式,从而减轻服务器压力,这样就是集群的环境了。
一般推荐搭建方式为 1主2从 为最低配。
主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
在大数据领域,冗余一般是指一模一样的数据存储多于一份的情况。 - 数据灾备(故障恢复):当主节点出现问题时,可以由从节点提供服务,实现快速的故障服务。
- 负载均衡:主从复制的基础之上,可以实现读写分离,提高了并发量。
- 高可用(集群)基础:主从复制是哨兵和集群实施的基础,因此说 redis 的主从复制是高可用的基础(集群环境的基础)。
所以在真实的项目中,我们不可能是单机模式,基本都是搭建 redis 集群,实现高可用和高并发。
11.2、集群基础搭建(单机多集群)
11.2.1、基础命令
# 查看所有配置信息,信息太多
info
# 查看服务器的配置信息
info server
# 查看已连接客户端的配置信息
info clients
# CPU计算量统计信息
info cpu
# 主从复制信息
info replication
首先查看当前环境信息
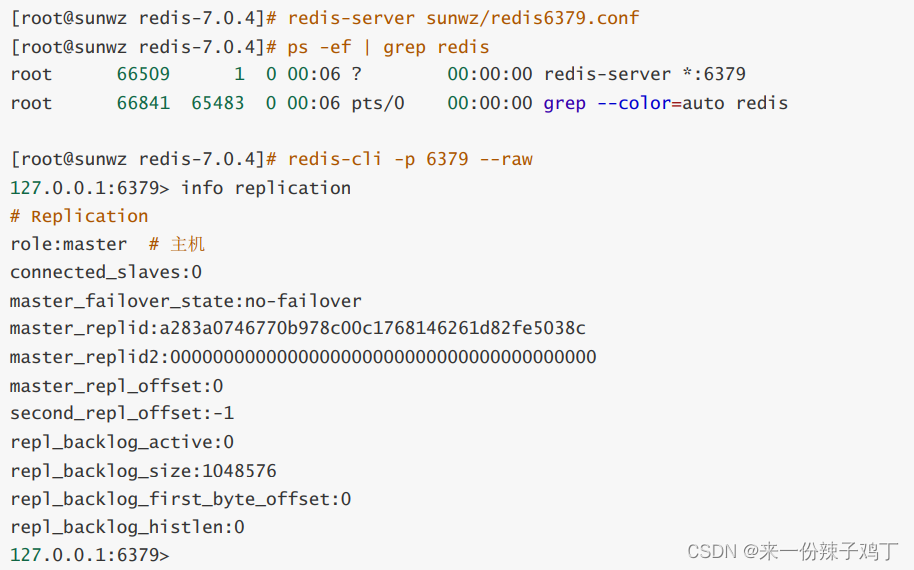
127.0.0.1:6379> info replication
# Replication
# 表示当前环境为主机
role:master
# 集群从机的连接数量
connected_slaves:0
master_failover_state:no-failover
master_replid:06e36f11d5d5ccc4f1cd20eae0f75e1bdacb478a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
11.2.2、准备工作
# 将存储方式改为rdb
# 搭建1主2从集群 6379 6380 6381
# 多复制2份 redis-config 文件,并修改对应的端口号和dump6379.rdb,dump6380.rdb,dump6381.rdb
# 修改pidfile记录文件
# 修改启动日志文件名
# 主机配置 - 6379
# 主机端口port --> 6379 不用修改
# pidfile --> 守护进程产生的文件,默认redis_6379,主机也不用改。
# 日志logfile --> 改成"6379.1og"
# 数据库文件dbfilename --> dump6379.rdb
#从机配置-1 6380
# 主机端口port --> 6380
# pidfile --> 守护进程产生的文件,默认redis_6380
# 日志logfile --> 改成"6380.1og"
# 数据库文件dbfilename --> dump6380.rdb
# 从机配置-2 6381
# 主机端口port --> 6381
# pidfile --> 守护进程产生的文件,默认redis_6381
# 日志logfile --> 改成"6381.1og"
# 数据库文件dbfilename--> dump6381.rdb
11.2.3、启动集群
启动6379
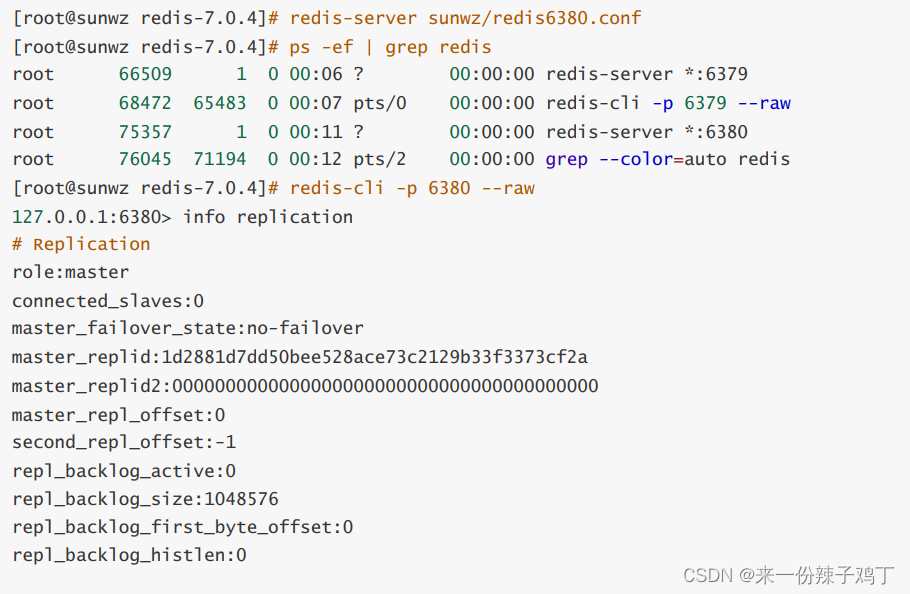
启动6380
启动6381
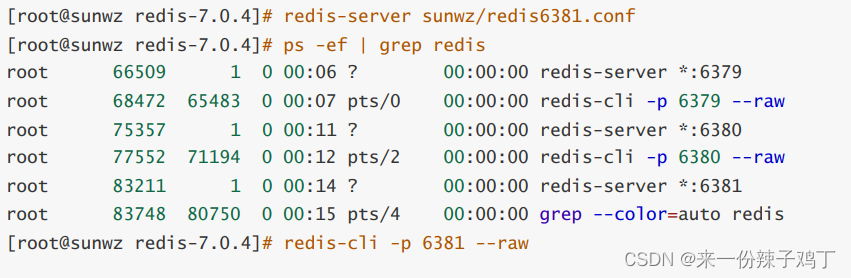
11.2.4、一主二从配置
默认情况下,每一台 redis 服务器都是主节点,所以我们只要配置从机就可以了!!!
分别连接客户端(使用对应端口号登录),通过 info replication 查看情况(默认都是主机)
# 查看主从复制的信息
info replication
配置策略 – 小弟找大哥(认老大,认主)
主(6379) 从(6380,6381)
配置命令:slaveof ip port
slaveof ip port
# 比如:
slaveof 127.0.0.1 6379

测试一下数据是否同步
注意:我们这里使用的是命令配置的,如果服务器重启就会消失配置,真是的企业环境都配置到配置文件中,这样就是永久配置了。















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









