






1 .list 可以根据索引赋值
a = [1, 23, 33]
print(a)
b = a.index(23) # 找到值为23的索引
print(b)
a[b] = 999 # 根据索引赋值
print(a)
结果
[1, 23, 33]
1
[1, 999, 33]
2 .闭包
"""2 .闭包"""
如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
闭包的定义
1 在一个外函数中定义了一个内函数。
2 内函数里运用了外函数的临时变量。
3 并且外函数的返回值是内函数的引用。
是闭包
def foo():
a = []
def func(num): # 符合定义1 在一个外函数中定义了一个内函数
a.append(num) # 符合定义2 内函数里运用了外函数的临时变量 a
print(a)
print(func.__closure__)
return func # 符合定义3 并且外函数的返回值是内函数的引用。
x = foo()
x(1)
x(2)
x(3)
非闭包
def foo():
a = []
def func(num): # 符合定义1 在一个外函数中定义了一个内函数
print(num) # 不符合定义2 内函数里没有运用了外函数的临时变量 a
print(func.__closure__) # 有值就是闭包
return func # 符合定义3 并且外函数的返回值是内函数的引用。
x = foo()
x(1)
x(2)
x(3)
3.装饰器
3.1 函数或方法加不加括号的区别
3.1.1 函数或方法 不 加括号是指函数或方法的地址
地址里面存的就是
def add(first, second):
res = first + second
return res
不加括号 不会执行函数 只是获得地址
3.1.2 函数或方法 加 括号
获得函数的返回值 如果此函数没有返回值(如没有写 return 或只写了return ) 函数或方法加括号就返回None
def add(first, second):
res = first + second
return res
print(add) # 不加括号 <function add at 0x00000214EF27E0D0>
print(add(1, 2)) # 加括号 3
"""3.2 装饰器历流程"""
def outer(origin):
print("传进来的", origin) # 传进来的 <function func at 0x000002889008B550> 和原生def func地址一致
def inner():
print("前置")
origin()
print("后置")
return inner
def func():
print(1)
return 2
print("原生def func:", func) # 原生def func: <function func at 0x000002889008B550>
func = outer(func) # func = inner func不是原生func了 只是名字未变
print("赋值后的func", func) # 赋值后的func <function outer.<locals>.inner at 0x000002889008BA60>
func() # 相当于inner(origin)
来个标准的装饰器
def outer(origin):
print("传进来的", origin) # 传进来的 <function func at 0x000002889008B550> 和原生func地址一致
def inner():
print("前置")
origin()
print("后置")
return inner
@outer # @ + 函数名 相当于 func = outer(func)
def func():
print(1)
return 2
"""*3""
4. # 栈 先进后出 弹匣 队列先进先出 排队
5.生成器
7.深浅拷贝
8."+"号
在 Python 中,除了之外,还有数字和字符串一些其他数据类型也支持使用 + 运算符进行合并操作。以下是一些主要的支持 + 运算符的数据类型:
列表
a = [{"a": 1}]
b = [{"a": 2}]
c =[{"a":1}]
print(a+b+c) #[{'a': 1}, {'a': 2}, {'a': 1}] 非常好用
字符串 (str)
str1 = "Hello"
str2 = " World"
result_str = str1 + str2
print(result_str) # Hello World
元组 (tuple):
tuple1 = (1, 2, 3)
tuple2 = (1, 5, 6)
result_tuple = tuple1 + tuple2
print(result_tuple) # ((1, 2, 3, 1, 5, 6)
集合 (set):
set1 = {1, 2, 3}
set2 = {3, 4, 5}
result_set = set1.union(set2)
print(result_set) # {1, 2, 3, 4, 5}
9 枚举
""" `point_type` int(11) NOT NULL DEFAULT '0' COMMENT '点位类型 1 省站 2 国站 3 道路站点 4 子站 5 微站 6 工地站点' 拼接文本可以使用枚举法"""
class PointType(Enum):
# name value
PROVINCE = (1, "省站")
NATION = (2, "国站")
ROAD = (3, "道路站点")
SUB = (4, "子站")
MICRO = (5, "微站")
BUILD = (6, "工地站点")
# 取值
print(PointType.PROVINCE.value) # (1, '省站')
a = 3
for i in PointType:
if a == i.value[0]:
print(i.value[1]) # 道路站点
10 字典的get方法
只要dealed_tex的值是假的 如0、”“、{}、()等或者不存在这个键都会是false
a={"dealed_tex":()}
if a.get("dealed_text"):
print(1)
else:
print(2) # 2
- 也可以取出相应的键值对
a={"dealed_tex":(),"process":"good"}
print(a.get("process")) # good
此外dict类型还有个setdefault方法
语法
setdefault()方法语法:
dict.setdefault(key, default=None)
key – 查找的键值。 default – 键不存在时,设置的默认键值。 返回值
如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。 item.setdefault(“Folding type”,
None)
dict.get(“key”,0) 存在返回值0但是原始字典值不会变, dict.setdefault(“Folding type”,0) 存在返回值0而且同时把字典中的相应键的值设置为0
11 可变(mutable)和不可变(immutable)
在 Python 中,对象可以分为可变(mutable)和不可变(immutable)两种类型。以下是一些常见的可变和不可变对象:
不可变对象(Immutable):
- 整数(int)
- 浮点数(float)
- 字符串(str)
- 元组(tuple)
- 冻结集合(frozenset)
- 布尔值(bool)
- 不可变集合(immutable set)
- 函数对象
可变对象(Mutable)
列表(list)
字典(dict)
集合(set)
自定义类的实例(如果实现了可变行为)
可变对象可以在创建后进行修改,而不可变对象在创建后其值是无法修改的。当对不可变对象进行操作时,实际上是创建了一个新的对象。可变对象则允许直接修改其内容,而不需要创建新的对象。
例子
- b = a 指向同一个引用 修改a或b的值都会影响到a和b;若重新赋值 则会创建新的对象
a = [1]
b = a # 或者 b = list(a)
b.append(1)
print(a) # [1, 1]
print(b) # [1, 1]
# 若重新赋值 则会创建新的对象
b = 3 # [] 置为空也是
print(a)
print(b) #3
- -b = a 指向同一个引用 修改a或b的值只影响a或b
a=1
b=a
b=b+1
print(a) # 1
print(b) # 2
11 函数对象是不可变的(链表常见)
pre=1
current = pre
current = current+1
print(pre) # 1
print(current) # 2
12 元组与字符串bug陷阱
“a” 与 "a",
a = "a",
print(a,type(a)) # ('a',) <class 'tuple'>
13 set的妙用 比较元素是否相等
a={1,2,3}
b={2,3,1}
if a==b:
print(1) #1
在Python中,集合(set)是一种无序的数据结构,因此集合中的元素的顺序不影响集合的相等性。即使两个集合中的元素顺序不同,只要两个集合包含相同的元素,它们就被认为是相等的
14 split与join
split() 和 join() 是 Python 字符串的两个常用方法,用于字符串的拆分和合并。
- split() 方法:
split() 方法用于将字符串按照指定的分隔符拆分成多个子字符串,并返回一个包含这些子字符串的列表。
语法:split(sep=None, maxsplit=-1)
sep:可选参数,指定分隔符,默认为任何空白字符(例如空格、制表符、换行符等)。
maxsplit:可选参数,指定最大分割次数。如果指定了该参数,则最多分割出 maxsplit + 1 个子字符串;如果不指定,则默认为 -1,表示无限制分割。
示例:
s = "apple,banana,orange"
parts = s.split(",")
print(parts) # 输出:['apple', 'banana', 'orange']
- join() 方法:
join() 方法用于将一个包含字符串的可迭代对象(通常是列表)中的字符串连接成一个新的字符串,并返回该新字符串。
语法:join(iterable)
iterable:可迭代对象,包含要连接的字符串。
示例:
parts = ['apple', 'banana', 'orange']
s = ",".join(parts)
print(s) # 输出:'apple,banana,orange'
这两个方法常常搭配使用,例如在将字符串拆分后进行处理,然后再使用 join() 方法将处理后的结果合并成一个字符串
15 深浅拷贝
- 深拷贝就是完全的拷贝和之前的地址没有一点关系
from copy import deepcopyc=deepcopy(a)来进行 - 浅拷贝是指通过切片或
b=a.copy的方式进行,它只拷贝地址
如
a = [[1, 2, 3], 4, 5]
b = a[:]
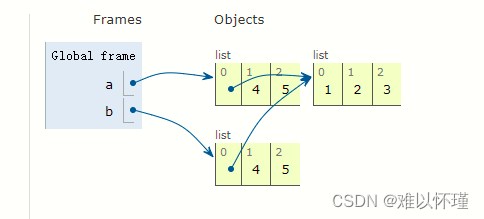
[1,2,3] 与 4 ,5 的地址被拷贝到了b
往下执行a[0].append(-1) 这就与可变类型与不可变类型有关了,列表为可变类型,因此地址不变的情况下可以增加数据
a = [[1, 2, 3], 4, 5]
b = a[:]
a[0].append(-1)
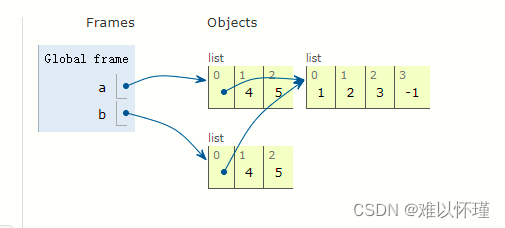
a = [[1, 2, 3], 4, 5]
b = a[:]
a[0].append(-1)
a[1]=99
执行a[1]=99 可变类型 值变了地址也会变
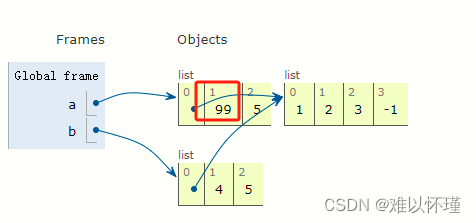
a为[[1, 2, 3, -1], 99, 5]
b为[[1, 2, 3, -1], 4, 5]















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









