






一、分析查看信息类
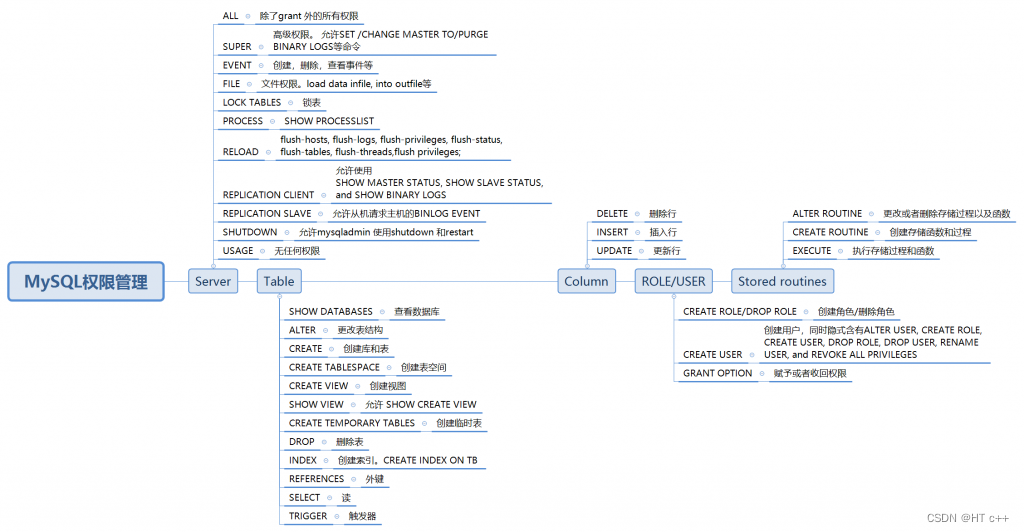
1.用户权限管理
grant all privileges on *.* to 'username'@'ip' identified by 'password';
GRANT SELECT, INSERT, UPDATE, DELETE,CREATE,ALTER (开发权限)
REVOKE privilege ON databasename.tablename FROM 'username'@'host';(回收权限)
RENAME USER 'user'@'%' TO 'dong'@'%';(用户名重命名)
修改密码
update mysql.user set authentication_string=password('新密码') where user='root';
2. 分析sql连接状态
- 批量kill指定连接 导出到sql文件 注释第一行
mysql -uroot -p -e "select concat('KILL ',id,';') from information_schema.processlist where user='root';" > /tmp/a.sql
按运行时间查看进程
SELECT * FROM information_schema.processlist a WHERE a.COMMAND != 'Sleep' ORDER BY a.TIME DESC;
#分析处于Sleep状态的连接分布情况
select substring_index(host,':', 1) as appip ,count(*) as count from information_schema.PROCESSLIST where COMMAND='Sleep' group by appip order by count desc ;
分析哪些DB访问的比较多
select DB ,count(*) as count from information_schema.PROCESSLIST where COMMAND='Sleep' group by DB order by count desc ;
DDL中 查看阻塞会话已经执行过的操作
SELECT
locked_schema,
locked_table,
locked_type,
waiting_processlist_id,
waiting_age,
waiting_query,
waiting_state,
blocking_processlist_id,
blocking_age,
substring_index(sql_text,"transaction_begin;" ,-1) AS blocking_query,
sql_kill_blocking_connection
FROM
(
SELECT
b.OWNER_THREAD_ID AS granted_thread_id,
a.OBJECT_SCHEMA AS locked_schema,
a.OBJECT_NAME AS locked_table,
"Metadata Lock" AS locked_type,
c.PROCESSLIST_ID AS waiting_processlist_id,
c.PROCESSLIST_TIME AS waiting_age,
c.PROCESSLIST_INFO AS waiting_query,
c.PROCESSLIST_STATE AS waiting_state,
d.PROCESSLIST_ID AS blocking_processlist_id,
d.PROCESSLIST_TIME AS blocking_age,
d.PROCESSLIST_INFO AS blocking_query,
concat('KILL ', d.PROCESSLIST_ID) AS sql_kill_blocking_connection
FROM
performance_schema.metadata_locks a
JOIN performance_schema.metadata_locks b ON a.OBJECT_SCHEMA = b.OBJECT_SCHEMA
AND a.OBJECT_NAME = b.OBJECT_NAME
AND a.lock_status = 'PENDING'
AND b.lock_status = 'GRANTED'
AND a.OWNER_THREAD_ID <> b.OWNER_THREAD_ID
AND a.lock_type = 'EXCLUSIVE'
JOIN performance_schema.threads c ON a.OWNER_THREAD_ID = c.THREAD_ID
JOIN performance_schema.threads d ON b.OWNER_THREAD_ID = d.THREAD_ID
) t1,
(
SELECT
thread_id,
group_concat( CASE WHEN EVENT_NAME = 'statement/sql/begin' THEN "transaction_begin" ELSE sql_text END ORDER BY event_id SEPARATOR ";" ) AS sql_text
FROM
performance_schema.events_statements_history
GROUP BY thread_id
) t2
WHERE
t1.granted_thread_id = t2.thread_id \G
定位导致 DDL 被阻塞的会话,常用的方法如下:sys.schema_table_lock_waits
select sql_kill_blocking_connection from sys.schema_table_lock_waits WHERE blocking_lock_type <> 'SHARED_UPGRADABLE' and (waiting_query like 'alter%' OR waiting_query like 'create%' OR waiting_query like 'drop%' OR waiting_query like 'truncate%' OR waiting_query like 'rename%');
查看锁相关信息
select
plist.id, -- 连接的id
trx.trx_id, -- 事务id
trx.trx_started, -- 事务开始的时间
trx.trx_state, -- 事务当前的状态
lk.lock_mode, -- 锁的模式 X | S
lk.lock_type, -- 锁的类型 Recorde | gap | next key
lk.OBJECT_NAME, -- 锁关联到的表
lk.INDEX_NAME, -- 锁关联到的索引
plist.info -- 当前的sql语句
from information_schema.innodb_trx as trx
join information_schema.processlist as plist
on plist.id = trx.trx_mysql_thread_id
join performance_schema.data_locks as lk
on ENGINE_TRANSACTION_ID = trx.trx_id
order by trx.trx_id;
3.slow log 相关
#查看原来慢日志存放的路径
show variables like ‘%slow_query_log_file%’;
#登陆服务器
shell > touch mysql-slow01.log
shell >chown mysql.mysql mysql-slow01.log
mysql> set global slow_query_log=0;
mysql> set global slow_query_log_file='/data1/logs01/mysql-slow01.log'; # 文件要存在
mysql> set global slow_query_log=1;登陆服务器
shell > touch mysql-slow01.log
慢查询分析
pt-query-digest mysql-slow.log --since='10h' --type=slowlog --filter '($event->{user} || "") =~ m/^django/i'>/home/slow_report_0318.log
#指定库名
--filter '($event->{db} || "") =~ m/^dbname/i'
logrotate
#部署脚本
#!/bin/bash
yum install -y logrotate
mv /etc/logrotate.d/mysql /etc/logrotate.d/mysql.bak
mkdir -p /data/log_bak/
USER=""
PASS=""
err_path=`mysql -u${USER} -p${PASS} -Ns -e "show global variables like 'log_error';" |awk '{print $2}'`
slow_path=`mysql -u${USER} -p${PASS} -Ns -e "show global variables like 'slow_query_log_file';" |awk '{print $2}'`
echo "$err_path{
weekly
rotate 8
missingok
dateext
olddir /data/log_bak/
copytruncate
compress
}
$slow_path{
weekly
rotate 12
missingok
dateext
olddir /data/log_bak/
copytruncate
compress
}
" > /etc/logrotate.d/mysql
#手动执行
logrotate -vf /etc/logrotate.d/mysql
4.table信息统计相关
4.1 db中大于10G表
select TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS,ROUND((INDEX_LENGTH+DATA_FREE+DATA_LENGTH)/1024/1024/1024) as size_G from information_schema.tables where ROUND((INDEX_LENGTH+DATA_FREE+DATA_LENGTH)/1024/1024/1024) > 10 order by size_G desc ;
4.2 查询次数最多的sql
select SCHEMA_NAME,DIGEST_TEXT,COUNT_STAR,FIRST_SEEN,LAST_SEEN from performance_schema.events_statements_summary_by_digest where DIGEST_TEXT like 'select%' and DIGEST_TEXT not like '%SESSION%' and SCHEMA_NAME!='NULL' order by COUNT_STAR desc limit 10\G
写入次数最多的sql
select SCHEMA_NAME,DIGEST_TEXT,COUNT_STAR,FIRST_SEEN,LAST_SEEN from performance_schema.events_statements_summary_by_digest where DIGEST_TEXT like 'insert%' or DIGEST_TEXT like 'update%'or DIGEST_TEXT like 'delete%' or DIGEST_TEXT like 'replace%' order by COUNT_STAR desc limit 10\G
4.3查看一个MySQL实例中哪个库的总访问量最大
select OBJECT_SCHEMA,sum(SUM_TIMER_WAIT) as all_time,sum(COUNT_STAR) as all_star,sum(COUNT_read) as all_read ,sum(COUNT_WRITE) as all_write,sum(COUNT_FETCH) as all_fetch,sum(COUNT_INSERT) as all_insert,sum(COUNT_UPDATE) as all_update,sum(COUNT_DELETE) as all_delete from performance_schema.table_io_waits_summary_by_table group by OBJECT_SCHEMA order by all_star desc limit 3
哪个库的write latency时间最大
select OBJECT_SCHEMA,sum(SUM_TIMER_WAIT) as all_time,sum(SUM_TIMER_READ) as all_read_time,sum(SUM_TIMER_WRITE) as all_write_time,sum(COUNT_STAR) as all_star,sum(COUNT_read) as all_read ,sum(COUNT_WRITE) as all_write,sum(COUNT_FETCH) as all_fetch,sum(COUNT_INSERT) as all_insert,sum(COUNT_UPDATE) as all_update,sum(COUNT_DELETE) as all_delete from performance_schema.table_io_waits_summary_by_table group by OBJECT_SCHEMA order by all_write_time desc limit 3;
#查看库中哪些表有该字段类型或者包含某个字段
SELECT table_name FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = 'garena_dts_elite_pass_p2' AND COLUMN_NAME = 'account_id';
select table_name from information_schema.columns where TABLE_SCHEMA = 'garena_dts_elite_pass_p2' and column_type = 'blob';
4.4查看实例中的分区表相关信息
SELECT TABLE_SCHEMA,
TABLE_NAME,
count(PARTITION_NAME) AS PARTITION_COUNT,
sum(TABLE_ROWS) AS TABLE_TOTAL_ROWS,
CONCAT(ROUND(SUM(DATA_LENGTH) / (1024 * 1024), 2),'M') DATA_LENGTH,
CONCAT(ROUND(SUM(INDEX_LENGTH) / (1024 * 1024), 2),'M') INDEX_LENGTH,
CONCAT(ROUND(ROUND(SUM(DATA_LENGTH + INDEX_LENGTH)) / (1024 * 1024),2),'M') TOTAL_SIZE
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME NOT IN ('sys',
'mysql',
'INFORMATION_SCHEMA',
'performance_schema')
AND PARTITION_NAME IS NOT NULL
GROUP BY TABLE_SCHEMA,
TABLE_NAME
ORDER BY sum(DATA_LENGTH + INDEX_LENGTH) DESC ;
4.5长时间未更新的表
SELECT TABLE_SCHEMA,
TABLE_NAME,
UPDATE_TIME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA NOT IN ('SYS',
'MYSQL',
'INFORMATION_SCHEMA',
'PERFORMANCE_SCHEMA')
AND TABLE_TYPE='BASE TABLE'
ORDER BY UPDATE_TIME ;
5.pager
show processlist;
pager grep -v 'system user'
PAGER set to 'grep -v 'system user''
node1>show processlist;
pager grep 'Waiting for an event from Coordinator' | wc -l
PAGER set to 'grep 'Waiting for an event from Coordinator' | wc -l'
node1>show processlist;
16
mysql> pager grep Sleep | wc -l
PAGER set to 'grep Sleep | wc -l'
mysql> show processlist;
337
#查看空闲连接和总连接的数值,了解当前系统的繁忙程度
node1>pager less
PAGER set to 'less'
node1>show engine innodb status\G
node1>pager grep 'TRANSACTION '
PAGER set to 'grep 'TRANSACTION ''
node1>show engine innodb status\G
---TRANSACTION 421345192110096, not started
---TRANSACTION 421345192109176, not started
---TRANSACTION 421345192108256, not started
mysql> pager grep Sleep | wc -l
PAGER set to 'grep Sleep | wc -l'
mysql> show processlist;
337
346 rows in set (0.00 sec)
# 或者可以写的更复杂一些, 统计所有的.
mysql> pager awk -F '|' '{print $6}' | sort | uniq -c | sort -r
PAGER set to 'awk -F '|' '{print $6}' | sort | uniq -c | sort -r'
mysql> show processlist;
309 Sleep
3
2 Query
2 Binlog Dump
1 Command
#!/bin/sh
grep -A 1 'TRX HAS BEEN WAITING'
把这个脚本保存在 /tmp/lock_waits 上, 那么就可以过滤show engine innodb status 里面 trx wait 的
mysql> pager /tmp/lock_waits
PAGER set to '/tmp/lock_waits'
mysql> show innodb status\G
------- TRX HAS BEEN WAITING 50 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 0 page no 52 n bits 72 index `GEN_CLUST_INDEX` of table `test/t` trx id 0 14615 lock_mode X waiting
1 row in set, 1 warning (0.00 sec)
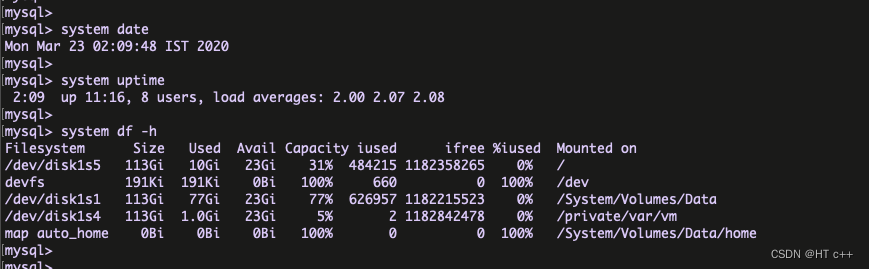
6.Execute the OS commands inside the MySQL client program
syntax : system
7.mysql8.0回收UNDO表空间
- 添加undo003
- 将膨胀的 undo 临时设置为inactive,以及 innodb_undo_log_truncate=on,自动 truncate 释放膨胀的undo空间
- 重新将释放空间之后的undo设置为active,可重新上线使用
create undo tablespace undo003 add datafile '/..../undo003.ibu';
select * from information_schema.INNODB_TABLESPACES where name like '%undo%';
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+-------------+----------------+-----------------+----------------+---------------+------------+--------+
| SPACE | NAME | FLAG | ROW_FORMAT | PAGE_SIZE | ZIP_PAGE_SIZE | SPACE_TYPE | FS_BLOCK_SIZE | FILE_SIZE | ALLOCATED_SIZE | AUTOEXTEND_SIZE | SERVER_VERSION | SPACE_VERSION | ENCRYPTION | STATE |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+-------------+----------------+-----------------+----------------+---------------+------------+--------+
| 4294967279 | innodb_undo_001 | 0 | Undo | 16384 | 0 | Undo | 4096 | 4311744512 | 4311764992 | 0 | 8.0.25 | 1 | N | active |
| 4294967278 | innodb_undo_002 | 0 | Undo | 16384 | 0 | Undo | 4096 | 76067897344 | 76068229120 | 0 | 8.0.25 | 1 | N | active |
| 4294967277 | undo003 | 0 | Undo | 16384 | 0 | Undo | 4096 | 16777216 | 16777216 | 0 | 8.0.25 | 1 | N | active |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+-------------+----------------+-----------------+----------------+---------------+------------+--------+
3 rows in set (0.03 sec)
alter undo tablespace innodb_undo_002 set inactive;
select * from information_schema.INNODB_TABLESPACES where name like '%undo%';
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
| SPACE | NAME | FLAG | ROW_FORMAT | PAGE_SIZE | ZIP_PAGE_SIZE | SPACE_TYPE | FS_BLOCK_SIZE | FILE_SIZE | ALLOCATED_SIZE | AUTOEXTEND_SIZE | SERVER_VERSION | SPACE_VERSION | ENCRYPTION | STATE |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
| 4294967279 | innodb_undo_001 | 0 | Undo | 16384 | 0 | Undo | 4096 | 4311744512 | 4311764992 | 0 | 8.0.25 | 1 | N | active |
| 4294967151 | innodb_undo_002 | 0 | Undo | 16384 | 0 | Undo | 4096 | 16777216 | 2179072 | 0 | 8.0.25 | 1 | N | empty |
| 4294967277 | undo003 | 0 | Undo | 16384 | 0 | Undo | 4096 | 16777216 | 16777216 | 0 | 8.0.25 | 1 | N | active |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
3 rows in set (0.01 sec)
alter undo tablespace innodb_undo_002 set active;
alter undo tablespace undo003 set inactive;
drop undo tablespace undo003;
select * from information_schema.INNODB_TABLESPACES where name like '%undo%';
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
| SPACE | NAME | FLAG | ROW_FORMAT | PAGE_SIZE | ZIP_PAGE_SIZE | SPACE_TYPE | FS_BLOCK_SIZE | FILE_SIZE | ALLOCATED_SIZE | AUTOEXTEND_SIZE | SERVER_VERSION | SPACE_VERSION | ENCRYPTION | STATE |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
| 4294967279 | innodb_undo_001 | 0 | Undo | 16384 | 0 | Undo | 4096 | 4311744512 | 4311764992 | 0 | 8.0.25 | 1 | N | active |
| 4294967151 | innodb_undo_002 | 0 | Undo | 16384 | 0 | Undo | 4096 | 16777216 | 2244608 | 0 | 8.0.25 | 1 | N | active |
+------------+-----------------+------+------------+-----------+---------------+------------+---------------+------------+----------------+-----------------+----------------+---------------+------------+--------+
2 rows in set (0.01 sec)
截断 UNDO 表空间文件对数据库性能是有一定的影响的,尽量在相对空闲时间进行
当UNDO表空间被截断时,UNDO表空间中的回滚段将被停用。其他UNDO表空间中的活动回滚段负责整个系统负载,这可能会导致性能略有下降。性能受影响的程度取决于许多因素:
1、UNDO表空间的数量
2、UNDO记录日志的数据量
3、UNDO表空间大小
4、磁盘I/O系统的速度
5、现有长期运行的事务、
那么避免潜在性能影响的最简单的方法:
1、就是通过 create undo tablespace undo_XXX add datafile ‘/path/undo_xxx.ibu’;多添加几个UNDO表空间。
2、磁盘上如果条件允许采用高性能的SSD来存储数据,存储REDO,UNDO等。
8. DB响应延迟监控
wget http://github.com/downloads/Lowercases/tcprstat/tcprstat-static.v0.3.1.x86_64
cp -a tcprstat-static.v0.3.1.x86_64 /usr/bin/tcprstat
chmod +x /usr/bin/tcprstat
tcprstat -p 3306 -n 0 -t 1 -l `/sbin/ip a| grep inet | egrep 'eth|lo' | awk '{print $2}' | cut -d'/' -f1 | xargs echo | sed -e 's/ /,/g'`
参考: https://opensource.actionsky.com/20191030-mysql/
只有avg/99_avg出现剧烈波动时,才能证明db服务器响应有问题
对于mongo、redis同样适用
9.MySQL8.0还原单表
/usr/bin/xtrabackup -uroot -'' -S /data/mysql/mysql.sock --tables='test.t_user' --backup --target-dir=/data/backup
xtrabackup --prepare --export --target-dir=/data/backup
CREATE TABLE `t_user` (
-> `id` bigint NOT NULL AUTO_INCREMENT,
-> `name` varchar(255) DEFAULT NULL,
-> `age` tinyint DEFAULT NULL,
-> `create_time` datetime DEFAULT NULL,
-> `update_time` datetime DEFAULT NULL,
-> PRIMARY KEY (`id`),
-> KEY `idx_name` (`name`),
-> KEY `idx_age` (`age`)
-> ) ENGINE=InnoDB AUTO_INCREMENT=1091002 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.16 sec)
ALTER table t_user discard tablespace;
cd /data/backup/test/
cp * /data/GreatSQL/test02/
ll
-rw-r--r-- 1 root root 964 Nov 24 04:12 t_user.cfg
-rw-r----- 1 root root 18874368 Nov 24 04:10 t_user.ibd
ALTER TABLE t_user import tablespace;
select count(*) from test02.t_user;
10.查询db已连接用户
mysql -uroot -p'' -e"show processlist;">>/home/process.log
cat /home/process.log| grep -e ^[1-9] | grep -vie "system\ user\|Uptime" | awk -F' ' '{print $2}' | sort | uniq -c
11.索引信息统计
1.查询95%中位数查询语句的耗时延迟,全表扫描等信息
select query,db,full_scan,exec_count,avg_latency,rows_sent,first_seen,last_seen from sys.statements_with_runtimes_in_95th_percentile where query like 'select%';
2.查询当前表访问过程中的锁的等待时间,这里通过查看平均每次的访问表的等待时间,发现某些时间较长的表,说明有缺少索引或索引有问题的可能性。
select object_schema as database_name,object_name as table_name,sum_timer_wait/count_star/1000000000000 as sec from performance_schema.table_lock_waits_summary_by_table where count_star <> 0 ;
3.查看表中索引的个数(仅仅在MYSQL8 中作用,information_schema)
select it.name,ii.index_count from innodb_tables as it inner join (select table_id,count(*) as index_count from information_schema.INNODB_INDEXES group by TABLE_ID) as ii on it.table_id = ii.table_id where it.name not like 'sy%' and it.name not like 'mysq%';
4.查询表的等待时间,通过查询数据获得平均每次访问表I/O的等待时间。
select object_schema as database_name,object_name as table_name,sum_timer_wait/count_star/1000000000000 as sec from performance_schema.table_io_waits_summary_by_table where count_star <> 0 limit 10;
5.对索引和表使用时的I/O等待时间进行统计和计算,这里统计的是每次调用的延迟时间,通过历史数据比较可以发现某些索引或表在I/O上面的延迟变化,发现相关的索引使用中的衰减的现象。
select object_schema as database_name, object_name as table_name,index_name, sum_timer_wait/count_star/1000000000000 as sec from performance_schema.table_io_waits_summary_by_index_usage where SUM_TIMER_WAIT <> 0 ;
6.查看全表扫描的信息
select db,query,total_latency/exec_count as avg_latency_us,no_index_used_count from sys.statements_with_full_table_scans;
7.仅有主键、唯一键表
SELECT T1.TABLE_SCHEMA,
T1.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS T1 JOIN INFORMATION_SCHEMA.TABLES T2 ON T1.TABLE_SCHEMA=T2.TABLE_SCHEMA AND T1.TABLE_NAME=T2.TABLE_NAME
WHERE T1.TABLE_SCHEMA NOT IN ('SYS',
'MYSQL',
'INFORMATION_SCHEMA',
'PERFORMANCE_SCHEMA')
AND T2.TABLE_TYPE='BASE TABLE'
AND T1.COLUMN_KEY != ''
AND T1.TABLE_SCHEMA='db'
GROUP BY T1.TABLE_SCHEMA,
T1.TABLE_NAME HAVING group_concat(COLUMN_KEY) NOT REGEXP 'MUL';
12.客户端技巧
- edit(\e)
官网解释说命令用于编辑当前输入SQL命令,默认的编辑器是vi,也可以通过设置环境变量EDITOR来改变成其他的编辑器,比如调整为vim编辑器export EDITOR=$(which vim)。
有这个命令后,输出错误的SQL,就不需要再用\c终止了,而是直接在其后加上\e进行编辑,修改成正确的后,再执行。
比如我实际上想要执行的命令中tt2表不存在,那么只需要通过\e更新SQL语句中的表名字就可以继续执行,不需要再重新编辑整条SQL。
-
ego(\G)
提交SQL语句到服务器,并且将返回的数据列式显示。 -
tee(\T)
将所有执行的SQL命令及输出结果保存到指定文件中。这在调测、生产维护过程中,都是非常有用的一个功能,特别是一些安全要求高的环境中,控制台只能显示几十行命令时,想要查找之前执行的命令及执行的结果比较难,此时就能用上\T了。
\T /root/a.log
\! cat /root/a.log
- \s 查看mysql状态
mysqladmin -uroot -proot -P3307 -S /tmp/mysql3307.sock -r -i 1 ext |grep -i 'question'
- prompt
#主库上
mysql> prompt master> ;
PROMPT set to 'master> '
master>
#从库上
mysql> prompt slave> ;
PROMPT set to 'slave> '
slave>
二、故障处理类
1.主从不一致修复
#建议第一时间切换域名,读流量切到主库或其他正常从库
#登录从库 查看报错
show slave status\G;
1.Error_code: 1062
Retrieved_Gtid_Set:重试错误的事务
Executed_Gtid_Set:85fc6271-4b86-11ec-a335-043f72d0ac4a:1-140327629当前执行的事务
stop slave ; #首先停止gtid复制
SET @@SESSION.GTID_NEXT= '85fc6271-4b86-11ec-a335-043f72d0ac4a:140327630' ; 设置当前下一个执行的事务Id
BEGIN; COMMIT; # 设置空事务,直接提交
SET SESSION GTID_NEXT = AUTOMATIC; #恢复下一个事务号
START SLAVE; # 继续开启事务
#不一致sql太多
#配置my.cnf(非必要不建议使用)
slave-skip-errors=1062
#重启db
#使用pt工具进行数据校验和修复(建议)
#重做从库(若需要)
1.主库备份(安装备份工具)
mkdir -p /data/tools
cd /data/tools/
wget dl.heroesofnewerth.com/rog/percona-toolkit-3.0.10-1.el7.x86_64.rpm
wget dl.heroesofnewerth.com/rog/percona-xtrabackup-24-2.4.11-1.el7.x86_64.rpm
yum -y install percona-xtrabackup-24-2.4.11-1.el7.x86_64.rpm
yum -y install percona-toolkit-3.0.10-1.el7.x86_64.rpm
备份脚本中移除slave-info
2.传输备份到从库
3.从库还原备份
systemctl stop mysqld
cd /data1
mv mysql mysql.bak
cd /data
mv logs01 logs01.bak
mkdir logs01
chown -R mysql.mysql logs01
cd /data1
/usr/bin/innobackupex --apply-log rebuild/(备份数据所在文件夹)
mv rebuild/ mysql
chown -R mysql.mysql mysql
systemctl start mysqld
cd /daat1/mysql
head -n 1 /data1/mysql/xtrabackup_slave_info
#登录从库
reset master;
set global gtid_purged='(上面文件中的点位)';
STOP SLAVE;CHANGE MASTER TO master_host='',master_user='',master_password='',MASTER_PORT=3306,MASTER_AUTO_POSITION = 1;start slave;
show slave status\G;
2.主库down
1.确认故障主库和待切换从库的ip与域名信息
2.新主库建立repl账号,其他从库建立与新主库复制关系
#新主库
sed -i "s/read_only=1/read_only=0/g" /etc/my.cnf
cat /etc/my.cnf|grep read_only
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'' identified by'@';flush privileges;
set global read_only=0;
retset slave all;
hostnamectl set-hostname
#其他从库
show slave status\G;
reset slave all;
change master to master_host='', master_user='repl',master_password='', MASTER_LOG_FILE='*****',MASTER_LOG_POS=********,MASTER_PORT=3306;
show slave status\G;
start slave;
show slave status\G;
3.切换主库域名到新主库ip
登录148.153.133.18
#修改前查看目前statisticdb绑定域名信息
export ETCDCTL_API=3
/data1/etcd/etcdctl --endpoints http://10.123.3.60:2379 get /a /z |grep -A 5 statisticdb
/data1/etcd/etcdctl --endpoints=10.123.3.60:2379 put /skydns/域名'{"host":"新机器IP"}'
#确认是否正常
ping 新域名
#旧主库kill连接
select concat('kill ',ID,';') from information_schema.processlist
where user ='garenabmg';
4.旧主库作从库(旧主库恢复后)
hostnamectl set-hostname
change master to master_host='', master_user='repl',master_password='', MASTER_LOG_FILE='*****',MASTER_LOG_POS=********,MASTER_PORT=3306;
show slave status\G;
start slave;
show slave status\G;
set global read_only=1;
sed -i "s/read_only=0/read_only=1/g" /etc/my.cnf
cat /etc/my.cnf|grep read_only
5.cmdb更新















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









