







数据处理
-
丢弃不必要的数据,由于本项目是预测学生是否能通过考试,则数据集中有些字段对该预测并不能起到作用,因此可以丢弃。
-
将分类变量转换成数值型变量,便于决策树进行决策
-
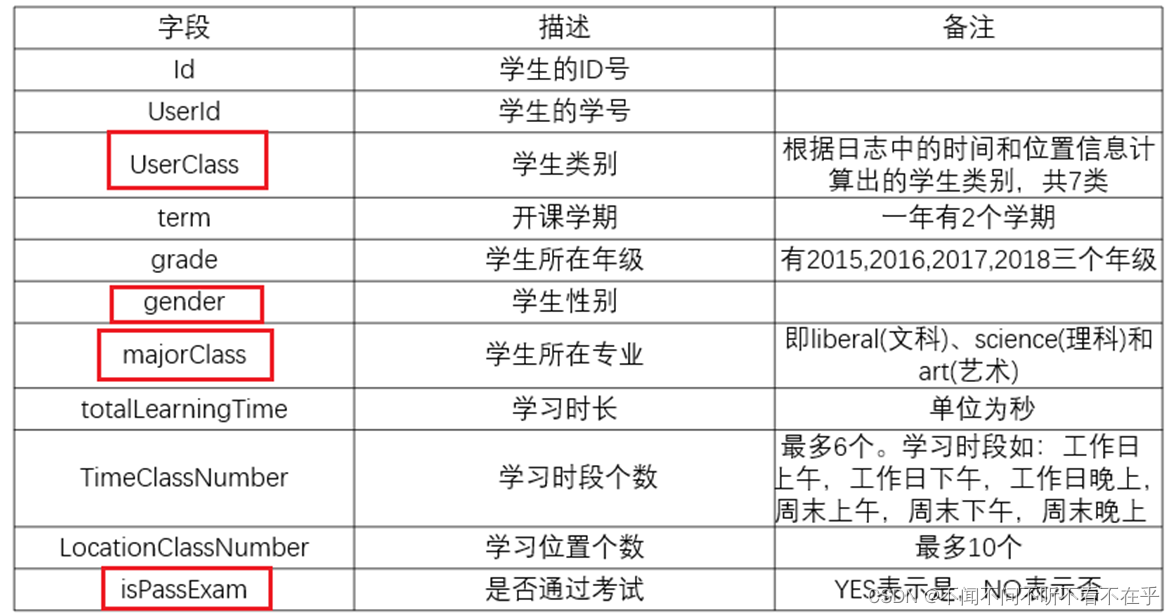
填充缺失值,在本数据集中,学生的学习时长数据存在部分缺失
tips: 在开始选择哪个属性来划分数据集时,样本在某个属性上有缺失的处理?
1. 抛弃缺失值,适用数据集具有极少缺失值的情况下
2. 填充方式:默认值0,均值,中位数,众数,KNN插值法(计算邻近的K个数据,填充其均值)
3. 计算信息增益率时根据缺失率的大小对信息增率进行打折。
一个属性已经被选选择,那么在决定分割点时,有些样本在这个属性上有缺失怎么处理??
1. 忽略缺失值
2. 填充缺失值
3. 把缺失的样本分配给所有的子集,也就是每个子集都有缺失的样本。
4. 单独将缺失的样本归为一个分支
决策树模型构建好后,测试集上的某些属性是缺失的,属性如何处理?
1. 如果有单独的缺失值分支,依据此分支预测
2. 把待分类的样本的属性A分配一个最常出现的值,然后进行分支预测。
3. 待分类的样本在到达属性A结点时就终止分类,然后根据此时A结点所覆盖的叶子节点类别状况为其分配一个发生概率最高的类。
本实验经过填充不同插入值进行结果对比后,选择了KNN插值法(计算邻近的K个数据,填充他们的均值)
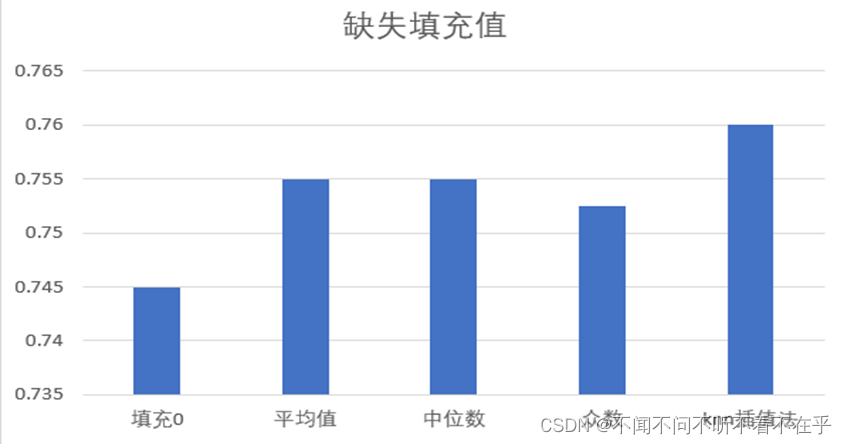
KNN插值法中K值的确定,通过交叉验证法,选取最好的K值
交叉验证是机器学习建立模型和验证模型参数时常用的方法。交叉验证,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,组合为不同的训练集和测试集。训练集中的某样本在下次可能会成为测试集中的样本。
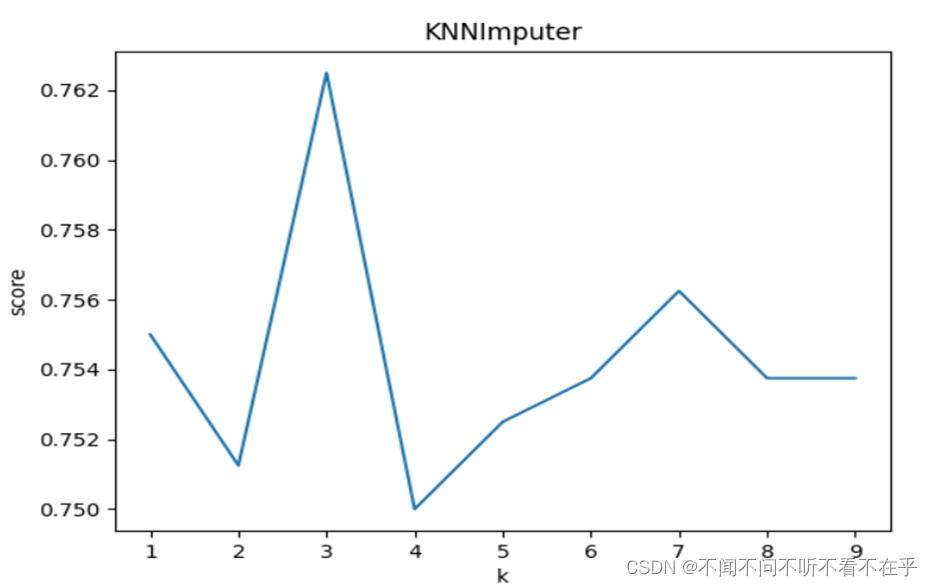
- 连续值离散化:连续属性有效的离散化,能减少算法的时间和空间开销,离散化的特征相对于连续型特征更易于理解,能有效克服数据中隐藏的缺陷。本项目采用的是等频离散化,根据数据的频率分布进行排序,按照频率进行离散。
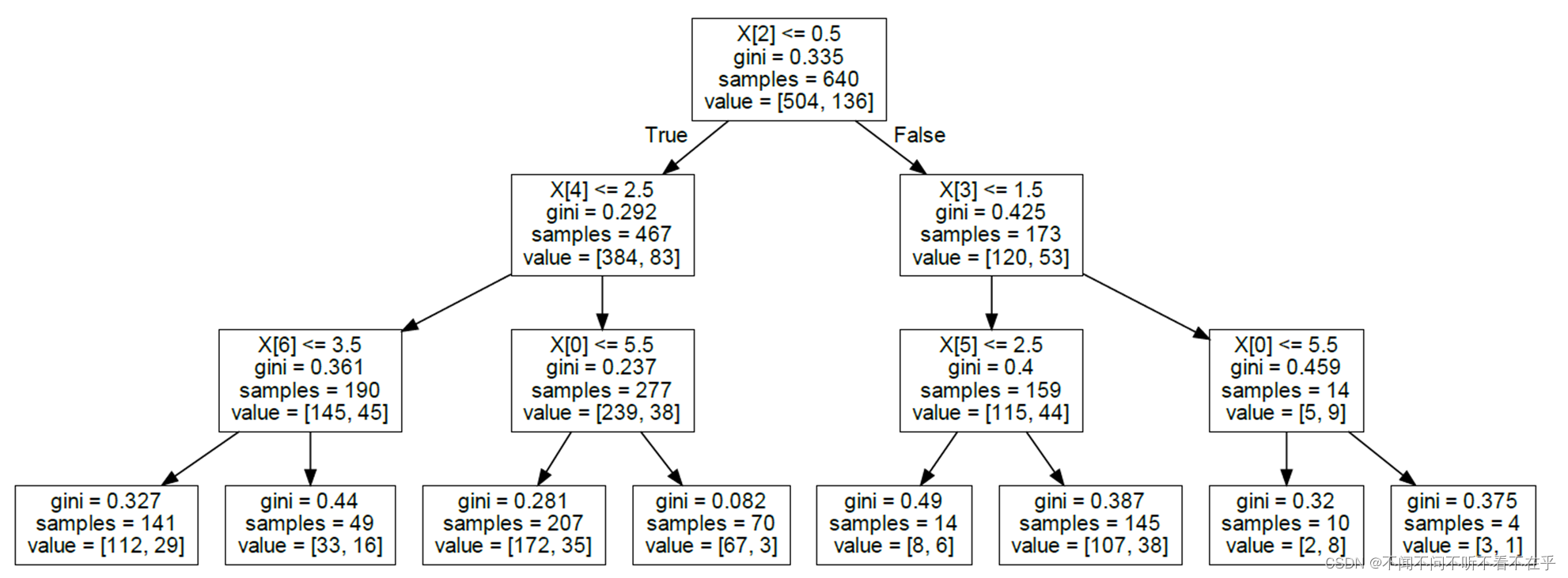
决策树可视化
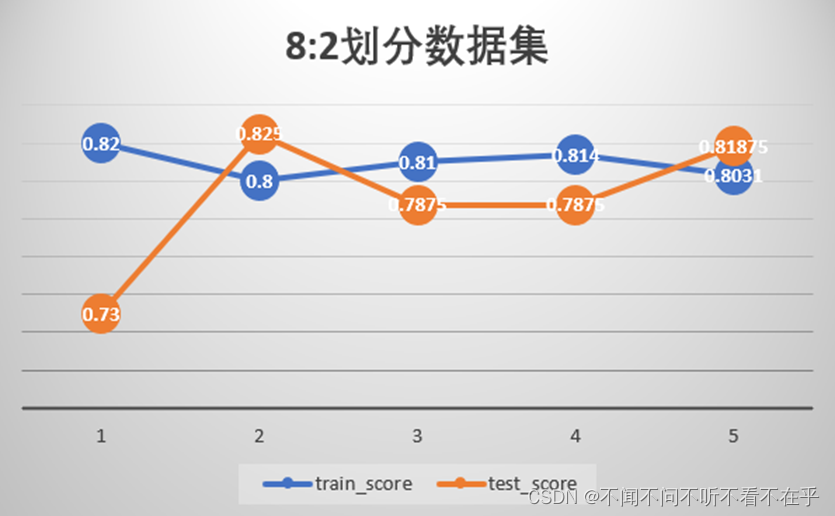
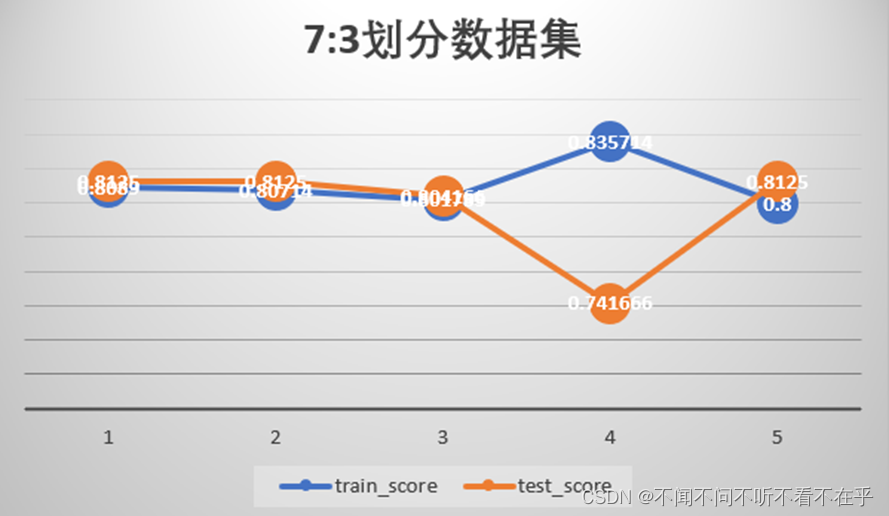
对比
- 不稳定性,根据训练集跟测试集划分方式不同,结果也有较大差异
- 使用随机森林进行实验,发现随机森林比决策树的稳定性要强。随机森林是由很多决策树构成的,不同决策树之间没有关联。进行分类任务时,新的样本输入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果哪一个分类最多,那么随机森林会把结果当作最终的结果。通过对许多树进行平均预测来限制这种决策树的不稳定性。
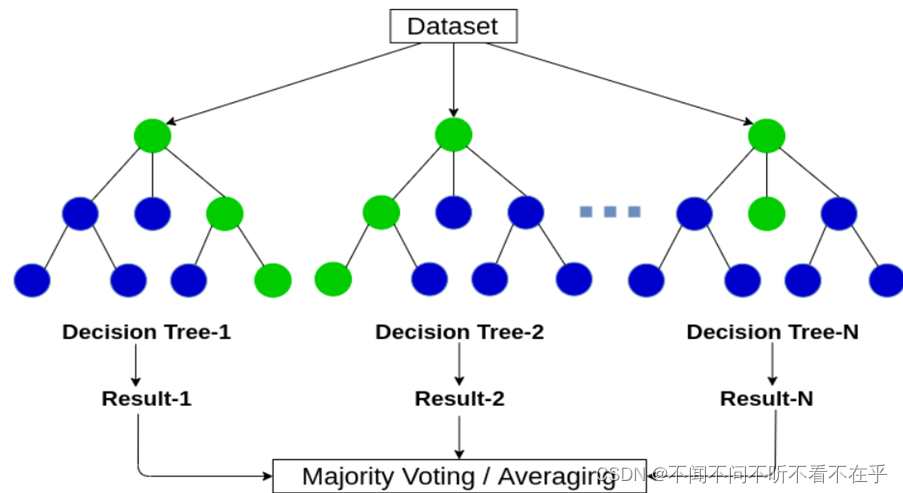
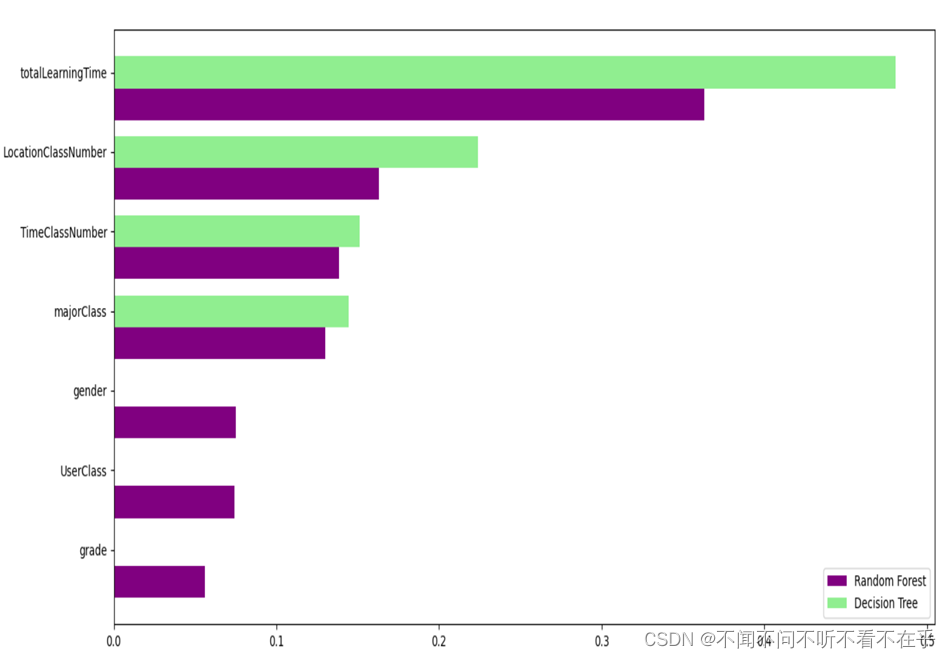
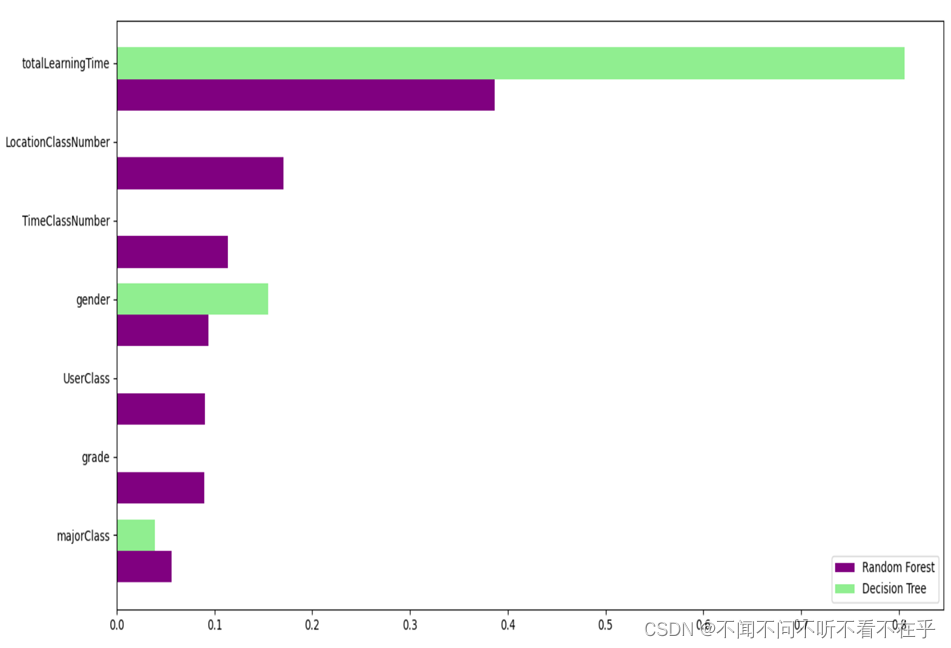
- 不同特征的重要性描述
不同的划分方式决策树中每个特征的重要性都有所波动,而比随机森林就比较稳定。
自动调参策略
-
Grid Search网格搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。

-
Random Search, 利用随机数求极小点而求得函数近似的最优解的方法,在搜索次数相同时,随机搜索相对于网格搜索会尝试更多的参数值,相对来说,速度较快。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









