






 博客围绕物联网、Java等技术展开。介绍了MQTT、COAP等物联网协议,涵盖消息结构、Qos等内容;阐述Java集合、并发、网络编程等知识;还涉及MySQL、Redis等数据库,消息队列、Docker等技术,以及线上问题排查和JDK版本等信息。
博客围绕物联网、Java等技术展开。介绍了MQTT、COAP等物联网协议,涵盖消息结构、Qos等内容;阐述Java集合、并发、网络编程等知识;还涉及MySQL、Redis等数据库,消息队列、Docker等技术,以及线上问题排查和JDK版本等信息。


文章目录
- 物联网协议
- 物联网数据传输安全与隐私保护
- 时序数据库(Time Series Database,TSDB)
- Java集合
- Java并发
- 网络编程/IO
- 设计模式
- Web开发框架
- JVM
- MySQL
- Redis
- 消息队列
- Docker
- Kubernetes(K8s)
- Linux
- CI/CD持续集成部署
- Arthas
- Nginx
- 线上问题排查与解决
- JDK版本
物联网协议
MQTT
概念
MQTT是一款基于发布订阅模式的轻量级通讯协议,构建于TCP/IP协议之上。应用在有限带宽、低开销和不可靠网络的环境中。
消息结构
既然MQTT是一个消息协议,那它就会有自己的消息规则,即规定这条消息该以怎样的格式进行传输。
MQTT消息的数据包结构分为固定头、可变头和有效载荷。
固定头
固定头的大小至少为两个字节,第一个字节高4位bit代表消息类型,低四位代表消息类型的具体标识,如DUP重发标识、Qos等级、保留标识等信息,有的消息类型没有;第二个字节标识了可变头和有效载荷的长度。固定头的消息类型代表数据包的类型,比如CONNECT、PUBLISH、SUBSCRIBE等,DUP用来标识是否为重发的消息,Qos定义了消息的服务质量,保留标识位标识服务器是否保留此消息。
可变头 有效载荷
可变头和有效载荷存在某些消息类型中,其内容因消息类型的不同而不同,例如CONNECT的可变头就包括协议名、协议级别、连接标志和保持连接,其中连接标志包含有清除会话标志、遗嘱标志、用户名标志、密码标志等,如果遗嘱标志、用户名标志、密码标志的标志位为1,那么CONNECT的有效载荷里就会包含遗嘱主题、遗嘱消息、用户名密码,遗嘱信息用于客户端异常退出或网络故障等未知因素时,服务器可以发送这条信息给订阅者,用户名密码则可提供给服务器进行身份验证和授权;保持连接用于设置心跳间隔,每到间隔时间时,客户端会发送PINGREQ报文给服务器,如果没有响应PINGRESP报文,则会关闭与服务器的连接。又例如SUBSCRIBE的可变头包含了报文标识符(Packet Identifier),用于将SUBSCRIBE消息与SUBACK(订阅确认)进行匹配,SUBSCRIBE的有效载荷包含主题和Qos等级。(PUBLISH的可变头包含主题名和报文标识符,PUBLISH的有效负荷包含要发布的信息,并且该消息的接收者必须按照PUBLISH固定头的Qos等级发送响应)
Qos
Qos是消息服务质量等级,用于保障消息的传达。
Qos分为
Qos0:最多一次,发送者只发送一次PUBLISH报文给接收者,无论接收者是否真的收到,依赖于底层TCP的重传;
Qos1:至少一次,发送者发送一条PUBLUSH报文,并在本地保存这个报文,接收者收到后会响应一条PUBACK给发送者,当发送者收到这条PUBACK报文后,会根据其可变头的Packet Identifier删除对应的在本地保存的PUBLISH报文,如果发送端没接收到PUBACK包,则发送端会将PUBLISH的固定头的DUP重发标识置为1,至此,接收端可能会受到重复的消息。
Qos2:正好一次,发送者发送一条PUBLUSH包,并在本地保存一份,接收者收到后回复PUBREC标识消息已经成功接收,防止重复传递,发送者收到PUBREC后将本地对应的PUBLUSH包丢弃,同时保存该PUBREC包,并返回PUBREL告知接收者可以释放之前保留的资源,正式将消息传递给上层应用,并且返回PUBCOMP给发送者,确认消息已经传输完成。至此一次Qos2就完成了。
COAP
概念
COAP是面向受限环境的应用层协议,对于小设备来说,通过TCP和HTTP协议入网是个过分的要求,为了让小设备可以接入网络,COAP协议被设计出来。
双层结构
COAP协议采用了双层结构,包括事务层和**请求/响应层。**以此来提供可靠的传输机制
事务层
用于处理节点间的信息交换,每个信息都有唯一的事务标识符(Token)用于标识相关的请求和响应。
同时也提供了对多播和拥塞控制的支持。
CoAP使用拥塞控制机制来管理网络的负载,以避免网络拥塞和资源浪费
请求/响应层
用以传输对资源进行操作的请求和响应信息。
REST架构基于该层的通信。REST请求附在一个CON或者NON消息上,而REST响应负载匹配的ACK消息上。
特点
COAP运行在UDP网络传输层协议上;COAP基于REST,server的资源地址和互联网一样也有类似url的格式,客户端同样有POST、GET、PUT、DELETE的方法来访问server;COAP是二进制格式的,而HTTP是文本格式的,COAP比HTTP更紧凑;且COAP的最小长度仅仅4B;COAP支持IP多播,可以同时向多个设备发送请求;非长连接通讯,适用于低功耗的物联网场景。
消息结构
COAP的消息结构包含版本(Ver)、消息类型(T)、Token长度(TKL)、列代码(Code)、消息ID(Messgae ID)、标记(Token)、选项(Options)、有效载荷(Payload)。
消息类型
CON(Confirmable),需要被确认的请求,如果CON请求被发送,那么对方给出确认消息,用以可靠消息传输;
NON(Non-confirmable),不需要被确认的请求,如果NON请求被发送,那么对方不必做出回应,适用于丢包不影响正常操作,用以不可靠消息传输;
ACK(Acknowledgment),应答消息,对应CON消息的响应;
RST(Reset),复位消息,当接收者接收到不认识或不关心或错误的消息时,不能回ACK消息,必须回RST消息;
列代码
当消息是一个请求时,Code字段表示请求方法;当响应时,代表响应代码;
消息ID
用于请求和响应之间的消息匹配,也可以用来表示重发场景下是否为同一报文。
Token
用于标识请求响应之间的关联。
Options
用在消息中传递额外的参数和选项,类似HTTP请求头,例如COAP端口号、主机号、查询字符串等。
资源发现机制
定义
COAP提供了一种资源发现机制,允许客户端在服务器上自动发现可用资源。
怎么进行资源发现
客户端GET请求到服务器特定的用于资源发现的路径,这通常是“/.well-known/core”,服务器会返回包含资源描述符的响应,这个资源描述符基于CoRE Link Format(CoRE链接标准)格式,CoRE Link Format描述了服务器上可用资源的URI及其属性,客户端通过解析这些资源描述可以获取资源信息,从而可以与服务器进行进一步的交互,例如发送请求读取、写入或触发资源操作等。通过资源发现机制,客户端可以自动发现服务器上的可用资源,而无需事先知道资源的确切路径和标识。
CoRE Link Format(CoRE链接标准)
CoRE Link Format使用类似于超链接的格式,将资源的URI(Uniform Resource Identifier)和相关的属性组织在一起。它使用尖括号(< >)包围URI,使用分号(;)分隔属性。每个属性由属性名和属性值组成,例如rel=“alternate”。
CoRE Link Format支持以下类型的属性:
- href:资源的URI。
- rel:资源的关系类型,描述资源与其他资源之间的关系。
- rt:资源的媒体类型,指示资源的内容类型。
- if:资源的接口描述符,描述资源所支持的接口或功能。
- ct:资源的默认内容类型,指示资源的默认内容类型。
- title:资源的标题或名称,提供对资源的简要描述。
- 其他自定义属性:可以根据需求定义其他自定义属性。
当描述物联网领域的资源时,CoRE Link Format可以使用以下类型的属性:
- href:资源的URI。例如:coap://example.com/sensors/temperature
- rel:资源的关系类型,描述资源与其他资源之间的关系。例如:rel="alternate"表示资源是一个备选的表示形式。
- rt:资源的媒体类型,指示资源的内容类型。例如:rt="temperature"表示资源是一个温度传感器。
- if:资源的接口描述符,描述资源所支持的接口或功能。例如:if="sensor"表示资源是一个传感器接口。
- ct:资源的默认内容类型,指示资源的默认内容类型。例如:ct=application/json表示资源的默认内容类型是JSON格式。
- title:资源的标题或名称,提供对资源的简要描述。例如:title="Temperature Sensor"表示资源是一个温度传感器。
- 自定义属性:根据具体需求,可以定义其他自定义属性来描述资源的特定属性。例如:location="room1"表示资源的位置是在room1。
可观察性(Observability)
定义
客户端可以通过观察资源的状态来实时监测和更新资源的变化,用于实现对资源的实时订阅和通知。
如何实现对资源的实时监测和更新
客户端向服务器发送一个观察请求,请求订阅特定资源的更新通知,该请求中包含一个观察标记(Observe Option)作为标识,用于指示客户端希望观察此资源,服务器在响应中也会返回一个观察标记,让客户端知道观察请求已被接受,并建立了观察会话(Obervation Session),将客户端的相关信息与该会话关联起来,并且该会话与该资源相关联,一旦建立观察会话,服务器在资源发生更新时就会发送给订阅了该资源的所有观察会话的客户端,当客户端不再继续观察时,发送终止观察请求已取消对该资源的观察。
LoRaWAN
概述
LoRaWAN是一种低功耗长距离的无线通信协议,它基于LoRa调制技术来实现的。
LoRaWAN采用星型网络拓扑架构,包括终端设备、网关、网络服务器三个重要主见,终端设备需要与网络进行配对,多个网关可以接收到同个设备的数据。
设备激活方式
OTTA
设备通过发送入网请求(Join)给网络服务器,该消息包含设备EUI和AppKey等信息来向网络服务器验证自己的身份,验证通过后,网络服务器会为设备分配设备标识符(DevAddr)和应用会话密钥(Application Session Key)等信息用于加密和解密设备和服务器之间的通信,完成后设备与网络服务器之间即建立会话。
ABP
设备无需入网请求,设备通过和网络服务器之间预设配置会话参数的方式来与网络服务器进行通信。设备在制造商生产和部署前会进行配置好设备地址(DevAddr)、网络会话密钥(NwkSKey)和应用会话密钥(AppSKey)等会话参数为与网络服务器直接建立通信会话。
终端的工作模式
Class A
终端不上报数据,服务器就无法主动进行下行传输,要求应用在终端上传数据的很短时间内进行服务器的下行传输,服务在其他时间进行的下行传输都得等终端的下一次上行。
Class B
Class B在Class A基础上添加了时间同步和额外接收端口,设备除了会在按固定的接收端口等待网络服务器的响应外,还会再预定的时间间隔内打开额外的接收端口。
Class C
基本一直打开着接收端口,只在发送时短暂关闭。意味着设备可以实时接收网络服务器的下行消息,但也会以牺牲功耗为代价。
从上述三种模式的介绍可以得知:如果设备好几天可能才需要上报一个数据,对时延不太敏感,那么,就可以采用Class A模式;如果设备需要定期上报数据,对时延容忍度不是太高的,则采用Class B模式;如果需要几乎随时能够接收数据,那么,最好是选择常供电并且是Class C模式。
Zigbee
简介
Zigbee是一种低功耗、短距离、自组织网络的无线通信协议。
设备角色
协调器:负责无线网络的组织和管理
路由:负责无线网络数据转发和中继
终端设备:负责无线网络数据的采集
当一个设备收到一个数据包时,它可以判断该数据包的目标节点是否在其直接通信范围内。如果目标节点不在直接通信范围内,设备可以通过中继将数据包传递给其他设备,这些设备在网络中更接近目标节点。中继设备会转发数据包,直到数据包到达目标节点或达到一定的跳数限制。
网络拓扑
点对点
两个设备之间直接建立连接,通信方式简单直接。
星型
多个设备连接到一个协调器作为网络的中心节点,每个附属节点只能与中心节点通信,两个附属节点之间通信必须经过中心节点进行数据转发。协调器负责转发数据和管理网络。
树型
一个协调器作为根节点,设备之间形成树状结构。每个子设备只能与其父节点通信,最高级父节点为协调器。在树状网络中,协调器负责整个网络搭建起来,路由器作为承接点,将网络以树状向外扩散,节点与节点之间通过中间的路由器形成多跳通信
网状型
多个设备通过多跳连接构成一个网络,数据可以通过多个路径传输。相邻路由器之间可以直接通信,不需要经过其他节点进行数据转发。提供更大的网络覆盖范围、容错能力、可拓展性和可靠性。
Modbus
NB-IoT
Bluetooth
物联网数据传输安全与隐私保护
安全协议
TLS/SSL协议
基于传输层的加密。使用三个文件来实现身份验证和保证数据安全。
使用cafile来验证服务器证书的合法性,确保与之通讯的服务是可信的。
使用certfile(证书文件)来向服务器证明客户端的身份,服务器通过检测该证书确保与之连接的客户端是经过授权的。
使用keyfile(私钥文件)来生成数字签名,对通信进行加密和解密操作,并与certfile证书配对,只有拥有与证书配对的私钥的客户端才能使用证书进行身份验证。
用户名 密码
提供用户名面膜进行身份验证,确保客户端的访问权限。
需要注意的是,用户名和密码是一种基本的身份验证方法,但并不是最安全或最强大的身份验证方式。在更高级别的安全需求下,可以考虑使用基于证书的身份验证、OAuth令牌等更复杂的身份验证和授权机制来增强安全性。
数据加密
对称加密
使用相同的密钥对数据进行加解密,发送方和接收方使用相同的密钥。常见的对称加密算法有AES、DES。
非对称加密
使用公钥和私钥配对进行加解密,发送方使用接收方的公钥对数进行加密,然后发送方使用相对于的私钥进行解密。公钥是可以公开发放的,而私钥必须保密。厂家的非对称加密算法有RSA、ECC。
混合加密
发送方使用接收方的非对称密钥的公钥对对称密钥进行加密,同时使用对称密钥对数据进行加密,然后将加密后的对称密钥和数据一起发送给接收方,接收方使用非对称密钥的私钥解密出对称密钥,最后使用解密后的对称密钥对数据解密。
传输加密数据:将加密后的数据通过安全通道(如TLS/SSL)或其他安全传输协议传输给接收方。确保数据传输过程中的机密性和完整性,防止数据被窃听或篡改。
数据完整性
哈希校验
发送端使用哈希函数对数据进行摘要计算生成固定长度的哈希值,将数据和哈希值一起发送给接收端,接收端使用相同的哈希函数对接收到的数据进行摘要计算,将接收端计算的哈希值与发送端传递的哈希值进行对比,以此来验证数据是否被篡改或损坏。
哈希校验可以检测是否是否被篡改,但无法提供数据的身份验证。如果攻击者能够篡改数据并重新计算哈希值,既可以通过哈希校验。
数字签名
发送方通过使用私钥对数据进行签名生成一个数字签名,接收方使用发送方的公钥对数字前面进行验证,验证数据有没被篡改。
验证的具体过程如下:
- 使用发送方的公钥对数字签名进行解密,得到解密后的数据,通常称为"解密结果"。
- 将原始数据使用相同的哈希算法或摘要算法进行处理,生成一个摘要值或哈希值。
- 将"解密结果"与生成的摘要值进行比较,如果两者一致,则说明数字签名验证通过,数据完整性得到保证。否则,数字签名验证失败,表明数据可能已被篡改或不是发送方的数据。
数字签名不仅可以验证数据的完整性,还可以提供数据的身份认证。由于数字签名使用非对称加密算法,私钥只有发送方持有,因此其他人无法伪造有效的数字签名。
访问控制列表
Broker可以配置访问控制列表(ACL),定义(客户端)允许或拒绝访问特定主题的规则。
设备ApplicationKey(应用程序密钥)
物联网设备的应用程序密钥用于确保设备与应用程序之间安全通信的机密密钥,保护数据的机密性和完整性。它可以用于加密设备生成的数据,并在发送到应用程序之前进行保护。应用程序密钥还可以用于解密来自应用程序的命令或配置,以供设备进行相应的操作。由制造商生产时生成并分配唯一密钥,存储在设备中,防止未经授权的访问。确保只有经过身份验证和授权的设备和应用程序可以进行通信。
时序数据库(Time Series Database,TSDB)
数据结构
度量(Metric):监测数据的指标,例如风力、温度。(表名)
标签(Tag):标明指标的标识。例如楼层、房间、设备ID等信息。
值(Value):度量对应的值,例如15级(风力)和20℃(温度)。Value有数字型和字符型。
时间戳(Timestamp):数据(度量值)产生的时间点。
数据点(Data Point):采集的每个度量值就是一个数据点,数据点等于 度量+标签+时间戳+值 的维度。
时间序列(Time Series):同一个度量,在不同的标签下都会有不同的时间序列。时间序列等于 度量+标签 组成的维度。
行存储
概述
行存储将每个数据字段作为一行存储在数据库中,每个行包含多个列的数据。
应用场景
基于一列或比较少的列计算的时候;
经常关注一张表某几列而非整表数据的时候;
数据表拥有非常多的列的时候;
数据表有非常多行数据并且需要聚集运算的时候;
数据表列里有非常多的重复数据,有利于高度压缩;
列存储
概述
列存储将数据字段分别存储,同一列的数据存储在一起,每个列包含多个行的数据。
应用场景
关注整张表内容,或者需要经常更新数据;
需要经常读取整行数据;
不需要聚集运算,或者快速查询需求;
数据表本身数据行并不多;
数据表的列本身有太多唯一性的数据;
常用时序数据库
InFluxDB
介绍
数据类型
时序数据有零个或多个数据点,每一个都是一个指标值。
- time(一个时间戳) 【类比SQL中的主键】
- measurement(例如cpu_load) 【可以理解为SQL中的table】
- 至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”) 【类比SQL中的列】
- 零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”, “dc=Frankfurt)。【可以理解为列,与field不同的是,tag理解为一个对象,例如server01的主机温度为21.2。并且tag是被索引起来的】
Prometheus
度量类型
计数器(Counter): 表示收集的数据是按照某个趋势(增加/减少)一直变化的,也是最常用的一种计量器,例如接口请求总数、请求错误总数、队列数量变化等。
计量仪/仪表(Gauge): 表示搜集的瞬时的数据,可以任意变化的,例如常用的 CPU Load、Mem 使用量、Network 使用量、实时在线人数统计等,
计时器(Timer): 用来记录事件的持续时间,这个用的比较少。
分布概要(Distribution summary): 用来记录事件的分布情况,表示一段时间范围内对数据进行采样,可以用于统计网络请求平均延迟、请求延迟占比等。
micrometer-registry-prometheus
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
Micrometer支持Prometheus,Micrometer提供PrometheusMeterRegistry注册表,用于将指标转为Prometheus格式的指标。
Micrometer支持开发人员使用它各种指标度量类型来将所记录的metrics导出到Prometheus,并可通过tags对metrics进行分类。
同时,引入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
其次在配置文件中,配置暴露Prometheus,并允许将指标导入到Prometheus中。
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
可以将Micrometer收集到的指标数据显示在ip:port/actuator/prometheus中,与springboot actuator的metrics集成在一块。
部署
LSMT(Log-Structured Merge Tree)
介绍
日志合并树是一个分层、有序、块存储的数据存储结构。LSM Tree的数据分由内存(Memory)+磁盘(Disk)存储,内存由一个MemTable(内存表)和一个或多个Immutable MemTable(不可变内存表)组成,磁盘由多个级别Level的SSTable组成。
WAL(Write Ahead LOG)
预写日志是一种持久化机制,利用在尾部Append的方式追加记录的日志结构文件,它可以用来系统奔溃后的数据恢复,使得内存块中未持久化到磁盘的数据不会丢失。
MemTable
内存表可以通过跳表或有序数组或红黑树等二叉搜索树等有序数据结构来实现(键值对存储结构)。当发生变更时,首先对MemTable进行写入,读取数据时,会同时读取SSTable和MemTable,将结果合并。随着数据持续写入,MemTable不断增长,被写满后,会创建一个新的MemTable,老的MemTable被锁定。
为什么LSM不直接顺序写入磁盘,而是需要在内存中缓冲一下?
单条写的性能不如批量写来的快,根据条数或者时间刷入磁盘一次,能大大提高写入效率;针对新增的数据,查询时可以直接返回,能够避免一定的IO操作。
SSTable(Sorted String Table)
Immutable MemTable的内容会被顺序写入到SSTable中,SSTable由一组数据block和一组元数据block组成,元数据block存储了SSTable数据block的描述信息,如索引、BloomFilter(布隆过滤器)、压缩、统计等信息,索引采用二分数组结构。
为了提高查找效率,LSM Tree对SSTable进行分层,同一层有多个SSTable,同时,LSM Tree会将多个SSTable合并(Compact),减少SSTable的数量,在合并的过程中会将过时或重复的数据或修改或标记删除的数据删除。
Level级别越大的SSTable具有更大的范围和较高的压缩比率。
SSTable是一种持久化、有序且不可变的键值存储结构。SSTable内部包含一系列大小可配置的Block块,一般为64k,这些Block的index存储在SSTable尾部,用于快速定位Block,当查询数据时,会根据key在index中做二分查找,找到该key对应的磁盘offset后,将磁盘中对应的块读取出来。
提高查询效率的方式
布隆过滤器
内部依赖哈希算法,当检测到莫一条数据是否见过时,有一定概率出现假阳性(False Positive),但一定不会出现假阴性(False Negative)。简而言之,布隆过滤器认为一条数据出现过,那么该条数据很可能出现过;但如果布隆过滤器认为一条数据没有出现过,那么该条数据一定没有出现过。这种特性刚好与此处的需求相契合,即检验某条数据是否缺失。
稀疏索引
稀疏索引是指将有序数据切分成(固定大小的)块,仅对各个块开头的一条数据做索引。
全量索引
全量索引对全部数据进行编制索引,其中的任意一条数据发生增删均需要更新索引。
全量索引查询效率更高,达到了理论极限O(log2n),但写入和删除效率低,每次数据增删均需要更新索引而消耗一次IO操作。通常关系型数据库,如MySQL等,其内部采用B tree作为索引结构,即全量索引。
多路归并机制
多路归并的基本思想是将多个已排序的数据流或文件划分为多个块,然后逐个比较每个块的最小元素,选择最小的元素输出到结果中,并从对应的块中读取下一个元素进行替换。这个过程重复进行,直到所有元素都被合并到输出中。
写数据的过程
- 写入数据时,首先会将数据记录到WAL Log中,可用于故障恢复;
- 接着会把这条数据写入Memtable(如果是删除数据,值会是墓碑标记;更新数据则会直接记录一条重复key的数据),使用红黑树或跳跃表来维持存储数据结构。
- 当Memtable超过一定大小后,会进行冻结,变成Immutable Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。
- 把Immutable Memtable转存到磁盘上的SSTable中,此步骤为Minor Compaction,此时在Level 0层的SSTable是没有进行合并的,此时这里的key range在多个SSTable中可能出现重叠,在层数大于0层后,从增量层(0层)的数据文件中选取一部分进行合并,生成一个新的更大的数据文件。
- 每层的SSTable大小或数量超过一定量后会周期性合并,此步骤为Major Compaction,此阶段会真正清除掉被标记删除和多版本数据的合并。但是发生Major Compaction会非常消耗CPU和磁盘IO,降低整个系统的吞吐量,建议在业务低峰期进行合并。
读数据过程
- 读取数据时,会先在内存里进行查找,如果内存都有就直接返回;
- 如果没有查到就会依次下沉,直到所有Level层都查询一边得到最终结果;
- 如果SSTable的分层较多,会导致需要把所有都扫描一遍,为了提高效率,可采用布隆过滤器、稀疏索引、全量索引,还有就是对每个组的数据进行压缩、定期合并缩身。
修改数据过程
LSM-Tree没有像B-Tree一样所谓的更新过程,需要先检索再修改。它的更新是通过追加数据,最终在合并的时候将旧数据删除,合并成追加的数据的过程。即使旧值还未被删除,在读取的时候,会从低层的SSTable文件开始查数据,低层的SSTable比高层的还要新,故每次总能读取到最新的数据。
删除数据过程
LSM-Tree对删除数据的过程跟追加数据的过程基本一样,只不过追加的时候,有具体的数据值,而删除时,追加的数据值是删除标记。同样在读取的时候,会从 Level0 层的 SSTable 文件开始查找数据,数据在低层的 SSTable 文件中必然比高层的文件中要新,所以如果有删除操作,那么一定会最先读到带删除标记的那条数据。后期合并 SSTable 文件的时候,才会把数据删除。
LSM-Tree 对比 B+Tree
- LSM-Tree将数据拆分成几百兆大小的分段,并且是顺序写入;B+Tree则是将数据拆分成固定大小的Page,一般是4k大小,和磁盘一个扇区的大小对应,Page是读写的最小单位。
- LSM-Tree是通过追加写,然后再Compaction的时候才真正更新和删除;B+Tree则可以做到原地更新和删除。
- LSM-Tree支持高吞吐写;B+Tree支持高效读。
- LSM-Tree在高吞吐写的时候会带来频繁Compaction的副作用,而大量的Compaction会占用大量系统资源,影响系统性能;B+Tree在大规模写场景下,效率会变低,因为为了维护B+Tree的树结构,节点会不断分裂和合并。
Java集合
Map
HashMap
List
ArrayList
LinkedList
Java并发
同步/并发锁机制
synchronized
概述
synchronized是实现线程同步的关键字,用于控制多个线程对共享资源的访问。每次只允许一个线程进入锁,它能够将代码块/方法锁起来。
如果synchronized修饰的是实例方法,则锁的是对象实例;如果synchronized修饰的是静态方法,则锁的是当前类的Class;如果synchronized修饰了代码块,则锁的是传入的对象实例。
原理
在Java中,每个对象都有一个与之关联的监视器锁(也成为内部锁或对象锁)。被synchronized修饰过的程序前后会编译生成monitorenter和monitorexit两个字节码指令,当虚拟机执行到monitorenter时,首先会尝试获取对象的锁,如果这个对象没有锁定,或者当前线程已经拥有了该对象的锁,则把锁计数器加一,当执行monitorexit指令时将锁计数器减一,当计数器为0时,锁就释放了。如果获取对象锁失败,那当前线程就会一直阻塞等待,直到对象锁被另一个线程释放为止。
原生锁优化
在Java6之前,Monitor的实现完全依赖底层操作系统的互斥锁来实现。加锁依赖底层操作系统的mutex相关指令实现,要将一个线程进行阻塞或唤起都需要操作系统的协助,会有用户态和内核态的切换,十分损耗性能。
偏向锁
当一个线程尝试获取锁时,JVM会将对象头中的标志位设置为偏向锁,并将线程id激励在对象头Mark Word中,当其他线程访问该同步块时,会检查对象头的线程id是否与当前要获取锁的线程的id相等,如果相等则当前线程能获取到锁,执行同步块。
轻量级锁
如果通过偏向锁获取失败,偏向锁撤销,升级为轻量级锁。在轻量级锁状态下,当前线程会在栈帧下创建Lock Record,Lock Record会把Mark Word的信息拷贝进去,且有个Owner指针指向加锁的对象。线程执行到同步块时,则使用CAS试图将Mark Word指向到线程栈帧的Lock Record,假设CAS修改成功,则获取到轻量级锁,获取失败则会自旋。
重量级锁
当轻量级锁的CAS自旋一定次数后,则升级为重量级锁。在重量级锁状态下,JVM会将线程阻塞,使其进入等待状态,直到获取到锁的线程释放锁。
锁消除
对检测到不可能存在共享资源竞争的锁进行消除,主要根据逃逸分析。
锁粗化
一系列连续的操作对同一对象进行反复枷锁,甚至加锁操作在循环体内,频繁进行互斥同步操作会带来不必要的性能损耗。锁粗化就是增大锁的作用域。
CAS
概述
CAS全程是Compare and Swap,即比较并交换。CAS的操作核心涉及三个参数:内存值、预期值、新值。比较内存值与预期值是否一致,当一致时,则将内存值修改为新值,如果不一致,则说明此内存值已经被别的线程修改过。CAS具有原子性,由CPU硬件指令实现,JDK中提供了Unsafe类执行这些操作。CAS相当于没有加锁,多个线程可以直接操作共享资源,在实际去修改的时候才判断能否修改成功。
缺点
- 只能保证一个共享变量的原子操作,如果涉及多个共享变量的操作,CAS将变得力不从心,这时使用互斥锁就能解决。
从JAVA1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作
- 长时间失败而自旋会导致CPU开销大。
- ABA问题。CAS的核心是通过对比内存值和预期值是否一致而判断内存值是否被修改或,而如果内存值被其他线程修改为其他的值之后再修改回去原来的值,则CAS会认为此内存值未被修改过,而实际上是有其他线程修改的。ABA问题的解决思路是使用版本号来标识每一次的修改,每个对变量的操作都把版本号加一。
从Java1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值
AtomicStampedReference内部不仅维护了对象值,还维护了一个时间戳。当AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新时间戳,对象值和时间戳都必须满足期望值,写入才会成功。
AQS
概述
AQS全称是AbstractQueuedSynchronizer,是一个用来构建锁和同步器的框架。
AQS内部维护了一个volatile int state变量和一个双向的FIFO阻塞队列。state表示同步状态。state=0说明当前锁没有被任何线程所持有,state=1说明有线程获取了锁,其他线程需进入同步队列等待,当线程使用完释放锁后,会响应唤醒队列中的阻塞线程。
State
用作尝试获取锁的次数,用在可重入锁和共享锁,state不会只是1和0。有着不同的含义,例如在Semaphore代表permits数量、在CountDownLatch代表计数值count,在ReentrantLock中可以理解为冲入次数。
Node类
AQS通过head和tail这两个Node节点成员变量,维护了一个Node结构的双向FIFO阻塞队列,一个Node代表一个等待线程(Node类是对要访问同步块的线程的封装),当一个线程获取锁失败时会加入到该队列尾部,会阻塞等待被唤醒,头节点一般代表当前获取到锁的线程,当它释放锁就会唤醒后继节点,每个Node节点关联其prev节点和next节点,方便线程释放锁后快速唤醒下一个在等待的线程。
waitStatus
Node类包含了五种状态waitStatus。
CANCELLED(1):表示当前节点已取消调度。当一个线程超时或被中断时,会触发变更为此状态,进入该状态后的节点将不会再变化。
SIGNAL(-1):表示后继节点正在等待当前节点唤醒。后继节点入队时,会将前继节点的状态更新为SIGNAL。(在自检前驱节点释放为头节点的方法acquireQueued里调用的shouldParkAfterFailedAcquire方法中有应用)
CONDITION(-2):表示节点在条件队列中等待。当一个线程调用了Condition的await方法时,会将其waitStaus设置为CONDITION,表示该节点在条件队列中等待条件满足,当其他线程调用了Condition的signal方法后,CONDITION状态的节点将从等待队列转移到同步队列中,等待获取同步锁。
PROPAGATE(-3):共享模式下,释放共享资源时需要向后继节点传播,需要唤醒后继节点,同时也可能会唤醒后续的后续节点。
0:表示节点处于初始状态,尚未被标记为其他状态。
两种资源模式
独占模式
获取锁
先尝试获取锁(获取锁的方法由子类去实现),获取不到则把当前线程Node独占类型节点加入到同步队列中去,并且进入循环体,让当前加入的节点检查自己的前驱节点是不是头节点,是的话则继续尝试获取锁资源,继续尝试获取锁成功后,会将头节点设置为当前节点,并把原来当前节点所在的位置置为null,以帮助垃圾回收。如果不是头节点或者是头节点但继续尝试获取锁资源失败,则判断当前线程是否需要挂起,判断的逻辑是通过判断前继节点的waitStatus是否为SIGNAL,是的话则直接挂起,否则如果waitStatus大于0,则向前节点寻找没有被取消的节点,如果小于等于0,则将前置节点的waitStatus设置为SIGNAL,然后重新开始循环体判断。
释放锁
尝试释放锁(释放锁的方法由子类去实现),如果释放成功,则判断当前节点的后继节点是否为null或者已被取消,如果是,则在等待队列中一直往后寻找后继节点的waitStatus是否有小于0,直到找到需要被唤醒的节点执行唤醒操作。
总结
简单来说,就是尝试去获取锁,失败就加入一个队列中挂起,释放锁时,如果队列有等待的线程就进行唤醒。
使用独占模式的类有ReentrantLock、ReentrantReadWriteLock.WriteLock
共享模式
获取锁
先尝试获取锁(获取锁的方法由子类去实现)(这里获取锁的返回值与独占锁不一样,独占锁只返回成功或失败,而共享锁的返回值是个数字,小于0代表获取失败,等于0表示当前线程获取共享锁成功,但是它后续线程是无法继续获取的,返回值大于0则表示它后续等待的节点也有可能继续获取共享锁成功),获取不到则把当前线程Node共享类型节点加入到同步队列中去,并且进入循环体,让当前加入的节点检查自己的前驱节点是不是头节点,是的话则继续尝试获取锁资源,当获取锁资源的返回值大于0,则将当前节点设置为头节点后唤醒后面还在等待的共享节点并把唤醒事件传递下去,会依次唤醒在该节点后面的所有共享节点,不是头节点或者获取锁资源失败则也会判断是否需要挂起。
释放锁
尝试释放锁(释放锁的方法由子类去实现),如果释放成功,唤醒操作由头节点开始的需要被唤醒的后继节点。
总结
共享锁的主要特征就是当一个等待队列中的共享节点获取到锁以后,它必须依次唤醒后面所有可以跟它一起共享当前锁资源的节点,如果等待的是独占锁,则前面已经有一个共享节点获取了,它肯定是获取不到的。
使用共享模式的类有Semaphore、CountDownLatch、ReentrantReadWriteLock.ReadLock
两种模式的对比
相同点
独占锁和共享锁竞争失败时,都会调用addWaiter方法,此方法都会把当前线程封装为Node节点添加到队列中。
不同点
共享模式比独占模式多了一个操作,就是设置完新的头节点后还有一个传递动作,去唤醒队列中所有共享模式的节点,让这些线程再去争夺共享资源,而独占模式则没有这个操作。
ConditionObject类
ConditionObject是AQS中定义的内部类,实现了Condition接口,其内部通过Node类型的firstWaiter和lastWaiter维护了一个等待队列(条件队列),并通过await和signal两个方法来控制入队出队。该条件队列是一个单向链表,它并没有使用Node类中的next属性来关联后继Node,而使用的nextWaiter属性。
nextWaiter是没用volatile修饰的,为什么呢?因为线程在调用await方法进入条件队列时,是已经拥有了锁的,此时是不存在竞争的情况,所以无需通过volatile和cas来保证线程安全。而进入同步队列的都是抢锁失败的,所以肯定是没有锁的,故要考虑线程安全
await(等待)
当线程获取到锁的前提下,使用await方法,会将当前线程加入条件队列中,并释放当前线程占有的锁,然后通过循环判断节点是否在同步队列中(当前已经释放了锁,当前其他线程获取锁并调用了signal/signalAll方法后,该线程可能已经从条件队列中移除而加入到了同步队列中),如果没有,则阻塞当前线程,如果有,则跳出循环,并尝试获取同步锁。
signal/signalAll(唤醒)
signal调用时,会先将条件队列中的头节点firstWaiter从队列中移除,然后将移除的头节点firstWaiter通过enq方法添加到同步队列中。signalAll和signal的原理一样,signalAll针对同步队列中所有节点,而signal则针对第一个对同步队列中节点。
ReentrantLock
ReentrantLock是通过一个抽象类Sync继承了AbstractQueuedSynchronizer,Sync又有两个子类FairSync和UnFairSync,分别代表公平锁和非公平锁。
非公平锁UnFairSync(尝试获得非公平锁)
判断当前State是否为0,当State为0,则使用CAS设置State,如果成功,则设置当前线程为锁持有线程,否则获取锁失败;如果当前State不为0,则证明当前处于有锁状态,则判断锁持有线程是否为当前线程,如果是则重入锁,如果不是,则获取锁失败。
公平锁FairSync(尝试获得公平锁)
公平锁和非公平锁的逻辑大体一致,唯一的区别就是需要先判断是否有当前线程节点的前驱节点,如果等待队列里没有线程。此时使用CAS的方式尝试更改state。如果修改成功,就设置锁的拥有者为当前线程,否则就退出方法,返回false。
尝试释放锁
对state进行减操作,当state为0时,则释放锁成功,并设置锁持有线程为null。
Condition
具体实现类是AQS的内部类ConditionObject。
ReentrantLock与Synchronized的异同
ReentrantLock和Synchronized都是JAVA中用于实现线程同步的两种机制,它们的目的都是为了保护共享资源的访问,避免线程之间的竞争和数据不一致问题。
相同点
- 两者都是线程安全的,不会导致数据的不一致或冲突
- 两者都支持同一线程多次获取同一个锁。即可重入性
- 在获取锁失败时,两者都会阻塞线程。
不同点
- Synchronized是隐式锁,是依赖JVM和操作系统底层互斥锁指令集来实现的,会在进入同步块时自动加锁,退出时释放锁。ReentrantLock是显式锁,是依赖JDK实现的,需要在代码显示地调用lock和unlock来获取和释放锁。
- ReentrantLock比Synchronized更灵活,可支持等待可中断(lockInterruptibly、tryLock(timeout,timeunit)支持等待中断,而lock不支持),可响应中断,超时获取锁,公平与非公平锁,而Synchronized等待不可中断,处于阻塞状态的线程会一直等待锁。
Lock.lockInterruptibly() 方法: 如果一个线程调用了 lockInterruptibly() 方法去获取锁,而此时另一个线程调用了该线程的 interrupt() 方法,那么正在等待获取锁的线程会立即收到一个 InterruptedException 异常,从而可以及时响应中断。
- Synchronized在JVM层面上实现,在代码执行出现异常时,JVM会自动释放锁定,但是使用ReentrantLock则不行,ReentrantLock要保证锁一定会被释放,就必须将unlock()放到finally块中。
CountDownLatch
CountDownLatch是一个同步工具类,能够使一个线程在等待一些线程完成工作之后,再继续执行。
尝试获取(共享)锁(await)
通过判断state是否为0,不为0则证明state计数器还没被递减完,则走AQS共享锁获取的逻辑,继续尝试获取锁失败时,会进入阻塞状态。
尝试释放(共享)锁(countDown)
对state的值减一,并且使用CAS修改state的值,如果修改成功,则判断修改后的值是否为0进行返回。如果修改失败,则继续获取state的值进行减一,然后继续尝试修改。如果修改后的值等于0,则走AQS共享锁释放逻辑,会唤醒正在阻塞获取锁的线程(await)。
Semaphore
Semaphore可以用来控制同时访问某个资源的线程数量。Semaphore维护了一个计数器,表示可用的许可数,当线程获取许可的时候如果没有可用许可,线程将被阻塞,直到其他线程释放了可用的许可。
尝试获取(共享)锁(acquire)
非公平
通过对state的减操作得到剩余许可数量,假如剩余许可数量小于0或者通过CAS修改剩余许可数量成功则返回剩余许可数,否则继续执行上述操作直至成功,如果没有剩余许可数即许可数小于0,则使用AQS的共享锁获取的逻辑,继续获取许可失败则会阻塞当前线程。
公平
公平和非公平的逻辑大体一致,唯一的区别就是需要先判断是否有当前线程节点的前驱节点,有则返回-1,没有则减少许可数,如果剩余许可数不小于0,则尝试修改减少后的许可数,并返回剩余许可数。
尝试释放(共享)锁(release)
通过对state的加操作来添加许可数量,并使用CAS来修改添加后的许可数量。不成功则继续执行上述操作直至成功。成功后会调用AQS的共享锁释放的逻辑,唤醒其他因为获取许可不足而正在阻塞的线程。
CyclicBarrier
CyclicBarrier用于控制多个线程在某个临界点除进行等待,并在到达临界点后同时继续执行,即在一组线程各自完成工作之后互相等待直到所有线程都完成之后才继续往下执行。
CyclicBarrier不是基于AQS实现的同步器。CyclicBarrier每次使用完之后可以重置。
CyclicBarrier底层依赖ReentrantLock和Condition的await和signalAll方法来控制线程的等待和唤醒。CyclicBarrier通过在内部维护一个计数器count,当计数器不为0时,表示还有其他线程没到达屏障点,那么线程都会调用condition的await方法将自己阻塞,此时计数器为减一,当计数器减为0的时候表示所有线程都达到了屏障点,所有调用await方法而被阻塞的线程将被唤醒,并且会将parties赋值给count实现可重置。这既是实现一组线程互相等待的原理。
ReadWriteLock
StampedLock
JMM(Java内存模型)
概念
Java内存模型是一种规范,是Java虚拟机规范中一部分,它定义了Java程序中多线程访问共享内存的规则和语义,确保多线程程序在不同平台上的一致性和正确性。
由来
多线程环境下,多个线程可能同时访问和修改共享变量,这可能导致线程之间的数据不一致性和竞态条件,Java内存模型确保了线程之间的正确同步和协调。
happens-before
多线程
线程池
ThreadLocal
网络编程/IO
IO模型
BIO
概念
同步阻塞,一个连接对应一个线程,即客户端有连接请求时,服务器端就需要启动一个线程进行处理,如果客户端一直没数据发送或者一直在准备数据,则线程会一直阻塞在那里。即read和write只能阻塞执行,线程在读写IO期间不能干其他事情,比如调用socket.read()时,服务器一直没有数据传输过来,线程就一直阻塞。(SockerServer、Socket)
可以使用线程池来实现伪异步IO,但是如果单个消息处理缓慢,或者服务器线程池中的全部线程都被阻塞,那么后续Socket的IO消息都将在队列中排队,新的Socket请求将被拒绝,客户端会发生大量连接超时。
NIO
概念
同步非阻塞,一个线程可以管理多个连接,当客户端没有数据发送或者数据还没准备好时,线程不会被阻塞,可以处理其他连接。NIO基于Reactor,客户端发送的数据都会注册到多路复用器上,多路复用器轮询到有I/O请求就会进行处理。
NIO和BIO的比较
- BIO以流的方式处理数据,而NIO以块的方式处理数据,块I/O比流I/O的效率高很多
- BIO是阻塞的,NIO则是非阻塞的
- BIO基于字节流和字符流进行操作,而NIO基于Channel通道和Buffer缓冲区进行操作,数据总是从通道读取到缓冲区,或者从缓冲区写入到通道。
Buffer(缓冲区)
概述
Buffer是NIO中用于读取和写入数据的缓冲区,类似于传统数组,但提供了更多的功能。
基本属性
容量(capacity)
表示Buffer的最大存储容量,创建后不能修改。(ByteBuffer.allocate() 方法就是用于创建一个指定容量的 ByteBuffer。)
限制(limit)
表示缓冲区可以操作数据的大小。写入数据时,limit不会变化,在写入模式下,limit等于buffer的容量;读取数据时,limit也不会变化,在读取模式下,limit等于写入的数据量。
位置(position)
表示下一个要读取或写入的数据的索引。
标记(mark)与重置(reset)
标记是一个索引,通过mark()方法指定Buffer中特定的位置做了个标记,后面可通过调用reset()方法恢复到这个position。
标记、位置、限制、容量遵守以下不变式:0 <= mark <= position <= limit <= capacity
直接内存(Direct)与堆内存(Heap)
堆内存是Java虚拟机管理的一块内存区域,它的创建和销毁由Java虚拟机自动管理。
直接内存是由操作系统管理的一块内存区域,读写操作不会经过Java堆,而是直接在操作系统的内存中进行。
直接内存直接作用本地系统的IO操作,避免了内存拷贝,而堆内存如果要IO操作需要从本进程内存先复制到直接内存,在利用本地IO处理。
很明显,在做IO处理时,比如网络发送大量数据时,直接内存会具有更高的效率。直接内存使用allocateDirect()创建,但是它比申请普通的堆内存需要耗费更高的性能。不过,这部分的数据是在JVM之外的,因此它不会占用应用的内存。所以呢,当有很大的数据要缓存,并且它的生命周期又很长,那么就比较适合使用直接内存。只是一般来说,如果不是能带来很明显的性能提升,还是推荐直接使用堆内存。字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其isDirect()方法来确。
常见方法
Buffer clear() //清空缓冲区并返回对缓冲区的引用(缓冲区中的数据依然存在,但是处于被遗忘状态)
Buffer flip() //为将缓冲区的界限设置为当前位置,并将当前位置重置为0
int capacity() //返回Buffer的capacity大小
boolean hasRemaining() //判断缓冲区中是否还有元素
int limit() //返回Buffer的界限(limit)的位置
Buffer limit(int n) //将设置缓冲区界限为n,并返回一个具有新limit的缓冲区对象
Buffer mark() //对缓冲区设置标记
int position() //返回缓冲区的当前位置position
Buffer position(int n) //将设置缓冲区的当前位置为n,并返回修改后的Buffer对象
int remaining() //返回position和limit之间的元素个数
Buffer reset() //将位置position转到以前设置的mark所在的位置
Buffer rewind() //将位置设为0,取消设置的mark
Channel(通道)
概述
Channel是NIO与I/O设备进行数据传输的抽象,通道表示打开到IO设备(例如文件、套接字)的连接,它类似于传统的输入输出流,NIO的所有I/O操作都是通过Channel来进行的,不过Channel本身不能直接访问数据,Channel只能与Buffer进行交互。
若需要使用NIO系统,需要获取用于连接IO设备的通道以及用于容纳数据的缓冲区,然后操作缓冲区,对数据进行处理,简而言之,Channel负责传输,Buffer负责存取数据。
与传统流的区别
- 通道可以同时进行读写,而流只能读或者写
- 通道可以实现异步读写数据
- 通道可以从缓冲读数据,也可以写数据到缓冲。
BIO中的stream是单向的,例如FileInputStream对象只能进行读取数据的操作,而NIO中的Channel是双向的,可以读操作,也可以写操作
常见的Channel实现类
FileChannel:用于读取、写入、映射和操作文件的通道
DatagramChannel:通过UDP读写网络中的数据通道
SocketChannel:通过TCP读写网络中的数据
ServerSocketChannel:可以监听新进来的TCP连接,对每一个新进来的连接都会创建一个SocketChannel(ServerSocketChannel类似ServerSocket,SocketChannel类似Socket)
Selector(选择器)
概述
Selector是NIO中用于多路复用的核心组件,它可以用一个线程管理多个Channel。Selector可以检测多个注册的通道上是否有事件发生(可设置选择器监听通道的某某事件),例如连接就绪、数据可读、数据可写等。实现了一个I/O线程可以并发处理N个客户端连接和读写的操作。
可监听的事件类型
- 读:SelectionKey.OP_READ
- 写:SelectionKey.OP_WRITE
- 连接:SelectionKey.OP_CONNECT
- 接收:SelectionKey.OP_ACCEPT
若注册时不止监听一个事件,则可以使用位或操作符连接。每个通道注册到 Selector 时都会关联一个或多个事件
例如SelectionKey.OP_READ |SelectionKey.OP_WRITE
在Java中," | " 符号是位运算中的按位或操作符。通过使用 " | " 运算符将多个事件合并成一个整数值,我们可以将多个事件注册到同一个 SelectionKey 上。在后续的处理中,可以通过 SelectionKey 的 readyOps() 方法来判断发生了哪些事件。通过使用 “|” 运算符将多个事件合并在一个 SelectionKey 上,可以更方便地处理多种不同类型的事件。可以通过 selectedKeys() 方法获取到发生事件的 Channel(已就绪的监听事件)。
AIO
概述
异步非阻塞,通过异步的方式来进行I/O操作,当I/O操作完成时,会通知应用程序进行处理,不需要等待。
网络应用程序框架
Netty
概述
Netty是一个异步事件驱动的网络应用程序框架,用于快速开发可维护、可拓展的网络服务器和客户端。
Reactor模型
概念
Reactor是在NIO多路复用的基础上提出的一个高性能的IO设计模式,核心思想是把响应IO事件和业务处理进行分离,通过一个或者多个线程去处理IO事件,再把就绪的事件分发给业务线程进行异步处理,Reactor模型有三个重要的组件:Reactor、Acceptor、Handlers,以及三种模型:单线程Reactor、多线程Reactor、主从Reactor(多Reactor多线程模型,即Master-Worker模式)。
Reactor模型是一种常用的事件驱动的分发处理模型,基于I/O多路复用模型与线程池复用线程资源,并将输入事件和处理事件的逻辑解耦。不同的角色职责有:Reactor负责事件分发、Acceptor负责处理客户端连接、Handler处理非连接事件。
Reactor的核心
- 事件源:负责产生事件,例如网络连接、IO请求。
- Reactor:负责监听和分发事件。
- 处理器(Handlers):负责处理分发的事件,是实际业务逻辑的实现,对收到的事件进行相应的处理。
- 事件处理器注册表:用于管理事件源和处理器的注册关系,它将事件源和相应的处理器进行绑定。
单Reactor单线程
多个客户端连接请求时,Reactor通过在Selector中的通道轮询到有事件发生,判断事件是连接事件则使用Acceptor建立连接,如果是其他读写事件,则分发给相应的Handler进行处理。缺点是Reactor和Handler在一个线程里,如果处理逻辑阻塞了,那整个Reactor程序就阻塞了。
单Reactor多线程
Reactor通过Selector轮询监听客户端事件,如果是连接事件,则由Acceptor处理并创建一个Handler对象绑定。如果是读写请求,则交给对应的Handler处理,Handler只响应事件,不做具体业务处理,将read方法读到的数据分发给线程池的线程去进行业务处理。
相对比单线程Reactor,在分发这一块异步了,交给了不同线程去处理,发挥了多核CPU的性能,但是Reactor只有一个,所有事件的监听和响应,都由一个Reactor来完成,并发性不好。
主从Reactor
相比于单Reactor多线程,多了一个主Reactor专门用于处理连接事件,如果不是连接事件,则分发给从Reactor去处理。
Netty模型
简介
Netty有两个线程组,分为Boss NioEventLoopGroup和Worker NioEventLoopGroup,这两个NioEventLoopGroup包含多个NioEventLoop,NioEventLoop表示一个不断循环执行处理任务的线程,每个NioEventLoop中都包含一个Selector,用于监听绑定在其上的SocketChannel的网络通讯。
Boss NioEventLoopGroup负责与客户端建立连接,生成一个NioSocketChannel,并将其注册到Worker NioEventLoopGroup的某个NioEventLoop的Selector下;Worker NioEventLoopGroup负责读写请求,在对应的NioSocketChannel处理,在处理NioSocketChannel业务时,会使用pipeline,管道中维护了很多handler处理器来处理Channel中的数据。
组件
NioEventLoop
NioEventLoop中维护了一个线程和任务队列,支持异步提交执行任务,线程启动时会调用NioEventLoop的run方法,执行I/O任务和非I/O任务。
I/O 任务,即 selectionKey 中 ready 的事件,如 accept、connect、read、write 等,由 processSelectedKeys 方法触发。
非 IO 任务,添加到 taskQueue 中的任务,如 register0、bind0 等任务,由 runAllTasks 方法触发。
NioEventLoopGroup
维护了一组NioEventLoop,每个NioEventLoop维护一个Selector实例。每个NioEventLoop对应一个线程,处理绑定在Selector上的Channel的事件,NioEventLoopGroup则相当于这一组线程的组成。
Bootstrap、ServerBootstrap
一个Netty应用通常由一个Bootstrap开始,主要作用是配置整个Netty程序,串联各个组件,Bootstrap类是客户端程序的启动引导类,ServerBootstrap类是服务端启动引导类。
一般使用启动引导类的设置项有:
- 设置EventLoopGroup线程组
一个线程组默认的线程数为CPU核数的两倍,可使用自定义线程数
- 设置Channel通道类型
NioSocketChannel: 异步非阻塞的客户端 TCP Socket 连接。
NioServerSocketChannel: 异步非阻塞的服务器端 TCP Socket 连接。
OioSocketChannel: 同步阻塞的客户端 TCP Socket 连接。
OioServerSocketChannel: 同步阻塞的服务器端 TCP Socket 连接。
- 设置Option参数
用于设置连接配置参数
childOption()常用的参数: SO_RCVBUF Socket参数,TCP数据接收缓冲区大小。 TCP_NODELAY TCP参数,立即发送数据,默认值为Ture。 SO_KEEPALIVE Socket参数,连接保活,默认值为False。启用该功能时,TCP会主动探测空闲连接的有效性。
option()常用参数:SO_BACKLOG Socket参数,服务端接受连接的队列长度,如果队列已满,客户端连接将被拒绝。默认值,Windows为200,其他为128
- 设置handler流水线
- 进行端口绑定
ChannelFuture
Netty的I/O操作都是异步的,这些操作会返回一个ChannelFuture对象,通过对该对象的监听,可以获取IO操作的结果。
Channel
用于执行网络I/O操作。
下面是一些常用的 Channel 类型:
NioSocketChannel,异步的客户端 TCP Socket 连接。
NioServerSocketChannel,异步的服务器端 TCP Socket 连接。
NioDatagramChannel,异步的 UDP 连接。
NioSctpChannel,异步的客户端 Sctp 连接。
NioSctpServerChannel,异步的 Sctp 服务器端连接。 这些通道涵盖了 UDP 和 TCP 网络 IO 以及文件 IO。
Selector
Netty基于Selector来实现I/O多路复用,通过Selector一个线程可以监听多个连接的Channel事件,Selector会不断地轮询这些Channel是否已有已就绪的I/O事件。这样就可以做到一个线程高效管理多个Channel。
ChannelHandler
用于处理网络事件和数据的传递,负责数据从一个地方传递到另一个地方时对数据进行处理和转换,ChannelHandler在ChannelPipeline中形成一条处理链,每个ChannelHandler可以对出站和入站数据进行处理。
ChannelHandler 接口定义了一系列的回调方法,当发生相应的事件时,Netty 会自动调用这些方法。ChannelHandler 可以分为两大类:
- 入站处理器(Inbound Handler):处理入站数据,包括接收、解码、处理接收到的数据。入站处理器的回调方法包括:
- channelRegistered:通道注册事件
- channelActive:通道激活事件
- channelRead:通道读事件
- channelReadComplete:通道读取完成事件
- exceptionCaught:异常捕获事件
- 出站处理器(Outbound Handler):处理出站数据,包括编码、发送数据到网络。出站处理器的回调方法包括:
- bind:通道绑定事件
- connect:通道连接事件
- write:通道写事件
- flush:通道刷新事件
- disconnect:通道断开连接事件
- close:通道关闭事件
ChannelHandlerContext
代表了ChannelHandler在ChannelPipeline中的上下文,通过ChannelHandlerContext,ChannelHandler可以与其所在的ChannelPipeline和其他ChannelHandler进行交互,还可以拿到Channel、ChannelPipeline等对象。当数据从一个 ChannelHandler 传递到下一个 ChannelHandler 时,实际上是通过 ChannelHandlerContext 来实现的。
ChannelPipeline
ChannelPipeline是一条拦截和处理数据的处理链。ChannelPipeline相当于处理器的容器,初始化Channel时,将ChannelHandler桉顺序装在ChannelPipeline中,就可以实现桉顺序执行ChannelHandler。
一个Channel包含了一个ChannelPipeline,而ChannelPipeline中又维护了一个由ChannelHandlerContext组成的双向链表,并且每个ChannelHandlerContext中又关联着一个ChannelHandler。
传递过程:
Channel接收到数据时,即读事件(入站事件),会从ChannelPipeline的头部向尾部传递,在这个过程中会触发ChannelHandler中相应的事件处理方法。同样,当向Channel写数据时,即write事件(出站),会从ChannelPipeline的尾部向前传递直到头部,在这个过程中也会触发ChannelHandler中相应的事件处理方法。
装配方法:
实例化ChannelInitializer,重写initChannel()初始化通道的方法,获得SocketChannel进行装配流水线。将上面的实现类加入到Bootstrap中childHandler()方法,之后与客户端建立连接后每一个生成的NioSocketChannel都会调用这个initChannel()方法进行装配。
粘包拆包问题
粘包和拆包
TCP是一个流协议,它发送的数据是一个没有界限的长串的二进制数据。操作系统在发送TCP数据时,底层会有一个缓冲区,如果一次请求发送的数据量比较小,没达到缓冲区大小,则TCP会将多个请求合并为一个请求发送,这就是粘包;如果依次发送的数据量比较大,超过了缓冲区大小,则TCP会将其拆分为多次发送,这就是拆包,也就是将一个大的包分为多个小的包进行发送。
既然知道了TCP是无界的数据流,且协议本身无法避免粘包、拆包的发生。那我们只能在应用层数据协议上加以控制。
常见的解决方案
- 客户端在发送数据包的时候,每个数据包的长度固定,不足长度则使用空格来补充,服务端读取既定长度的内容作为一条完整的消息;
- 客户端在每个包末尾使用固定的分隔符,例如\r\n,服务端利用这个分隔符分离出每一条消息的内容。如果一个包被拆分了,则等待下一个包发送过来后找到其中的\r\n,然后进行合并,得到一个完整的包;
- 将消息分为头部和消息体,头部保存当前消息的长度,这样服务端就可以根据长度来判断数据是否接收完毕,只有读取到足够长的消息之后才算读到一个完整的消息;
Netty提供的解决方案
在确定了上面使用哪种方案来解决后我们就可以使用对应的解码器了。
FixedLengthFrameDecoder
解码固定长度的消息帧,将接收到的数据按照固定长度进行拆分,将连续的数据流拆分成固定大小的消息帧。
构造函数frameLength用于指定消息帧长度,如果客户端发送的消息不足frameLength,服务端的解码器会等积累到frameLength长度后再解码。
DelimiterBasedFrameDecoder
解码以特定分隔符为界的消息帧,将接收到的数据按照指定的分隔符进行拆分,从而将连续的数据流拆分为多个消息帧。
DelimiterBasedFrameDecoder的maxFrameLength参数表示个消息的最大长度。如果接收到的消息长度超过此值,DelimiterBasedFrameDecoder 将抛出 TooLongFrameException 异常。
LengthFieldBasedFrameDecoder和LengthFieldPrepender结合
LengthFieldBasedFrameDecoder用于从接收的字节流中提取包含消息长度的字段,并根据该长度对字节流进行拆分,进而得到完整的消息帧。
LengthFieldPrepender用于在发送的消息前添加表示消息长度的字段。
LengthFieldBasedFrameDecoder构造函数
- maxFrameLength: 表示单个帧(消息)的最大长度。如果接收到的消息长度超过此值,LengthFieldBasedFrameDecoder 将抛出 TooLongFrameException 异常,用于防止过长的消息导致内存溢出。
- lengthFieldOffset: 表示长度字段的偏移量,即长度字段的起始位置。长度字段是指用于表示帧长度的字段,它是一个固定长度的字段,用于标识整个帧的长度(包括长度字段本身和消息内容)。
- lengthFieldLength: 表示长度字段的长度,即表示帧长度的字段所占用的字节数。通常情况下,长度字段的长度是固定的,可以是 1、2、3、4、8 等字节。
- lengthAdjustment: 表示长度字段的值需要进行调整的值。在某些情况下,帧的长度字段不包含长度字段本身的长度,因此需要进行调整。例如,如果长度字段的值不包含长度字段本身的 4 个字节,而是表示剩余消息内容的长度,那么 lengthAdjustment 就应该设置为 -4。
- initialBytesToStrip: 表示从解码帧中跳过的字节数。在解码出完整的帧之后,可能帧的前面有一些不需要的字节,可以通过 initialBytesToStrip 来指定跳过这些字节。
- failFast: 表示是否在发现超过 maxFrameLength 的帧长度时立即抛出异常。如果设置为 true,则会立即抛出异常并关闭连接;如果设置为 false,则会继续接收数据,直到找到下一个帧的长度或达到 maxFrameLength,然后再拆分帧。
LengthFieldPrepender构造函数参数说明:
- lengthFieldLength: 长度字段的长度,即表示消息长度的字段将占用的字节数。
- lengthIncludesLengthFieldLength: 是否将长度字段的长度包含在总长度中。如果设置为 true,表示总长度 = 消息长度 + 长度字段的长度;如果设置为 false,表示总长度 = 消息长度
零拷贝
传统IO模式
用户应用程序通过read()函数,从用户态切换到内核态,再通过DMA控制器将磁盘(硬件设备)中的数据拷贝到内核缓冲区,接着read()调用返回,从内核态切换到用户态,CPU将内核缓冲区的数据拷贝到用户缓冲区;
用户应用程序通过write()函数,从用户态切换到内核态,接着CPU将数据从用户缓冲区拷贝到内核缓冲区的socket缓冲区,然后write()调用返回,触发从内核态切换为用户态,最后通过异步DMA拷贝socket缓冲区的数据到网卡。
在上面的IO情形中,发生了四次用户态内核态的上下文切换、四次数据拷贝(两次CPU拷贝、两次DMA拷贝)。
DMA代表“Direct Memory Access”(直接内存访问),它是计算机系统中用于实现高速数据传输的一种技术。传统上,CPU负责将数据从一个设备(如硬盘、网络卡等)读取到内存中或从内存中写入到设备中。这个过程需要CPU参与,进行数据的拷贝和传输,会占用CPU的时间和处理能力。
DMA技术通过引入专门的DMA控制器(DMA 本质上是一块主板上独立的芯片),使得外部设备可以直接访问系统内存,无需CPU的干预,从而实现高速数据传输。

概念
零拷贝是一种优化技术,减少数据在内核态和用户态之间的拷贝与上下文切换,从而提高数据传输效率,减少CPU和内存开销。
实现
mmap(Memory Mapping)(内存映射)
通过将内核缓冲区与应用程序共享,将用户空间内存映射到内核空间,这样用户对内存区域的修改可以直接反映到内核空间,同样内核空间的修改也可以直接反映到用户空间,省去了内核缓冲区与用户缓冲区之间的数据拷贝。
用户通过mmap,从用户态切换到内核态,然后通过DMA将磁盘数据拷贝到内核缓冲区,mmap调用返回,从内核态切换回用户态,用户应用程序通过write()向操作系统发起IO调用,从用户态转为内核态,接着CPU将数据从内核缓冲区拷贝到内核缓冲区里的socket缓冲区,wirte()调用返回,并从内核态转回用户态。DMA异步将socket缓冲区拷贝到网卡。
上面的mmap零拷贝IO中发生了四次用户态内核态的上下文切换,三次数据拷贝(两次DMA拷贝、一次CPU拷贝)。
sendfile
只要执行了read()和write()都会分别发生两次的上下文切换,首先从用户态切换到内核态,待内核态完成任务后,切换回用户态交由进程代码执行。
sendfile将read()和write()合并为一个操作,用户应用程序发出sendfile系统调用,从用户态切换到内核态,再通过DMA将数据从磁盘拷贝到内核缓冲区,然后CPU直接将数据从内核缓冲区拷贝到socket缓冲区,接着sendfile调用返回,从内核态切换到用户态,DMA再异步将内核空间socket缓冲区中的数据传递到网卡。
上面的sendfile实现的零拷贝IO发生了两次用户态内核态的上下文切换、三次数据拷贝(两次DMA拷贝和一次CPU拷贝)。
SG-DMA+sendfile
SG-DMA可以直接从内核空间缓冲区将数据拷贝到网卡,无需先复制一份到socket缓冲区,省去了一次CPU拷贝。
用户应用程序发出sendfile系统调用,从用户态切换到内核态,然后通过DMA器将数据从磁盘拷贝到内核缓冲区中,接下来不需要CPU将数据从内核缓冲区拷贝到socket缓冲区,而是将相应的文件描述符信息复制到socket缓冲区(该信息包含内核缓冲区的内存地址和内核缓冲区的偏移量),接着sendfile调用返回,从内核态切换回用户态,DMA根据socket缓冲区中的描述符信息将内核缓冲区中的数据复制到网卡。
上面带有SG-DMA的sendfile实现的零拷贝IO发生了两次用户态和内核态的上下文切换、两次数据拷贝(两次DMA拷贝),实现了最理想的零拷贝IO传输,不需要任何CPU拷贝。
应用实例
- FileChannel的map()使用mmap零拷贝技术,该方法返回MappedByteBuffer,该方法可以在一个打开的文件和MappedByteBuffer之间建立一个虚拟内存映射,MappedByteBuffer是一个文件的共享映射区域,用户空间和内核空间共享该缓冲区。
- FileChannel的transferTo、transferFrom使用sendfile零拷贝技术。
- ByteBuffer采用的直接内存,使用堆外内存直接进行socket读写。使用堆内存则多了一次将堆内存Buffer拷贝到直接内存的操作,然后才写入socket。
- Netty的FileRegion包装的FileChannel.transfer实现直接将文件缓冲区的数据发送到目标Channel(目标文件),避免通过write方法导致的内存拷贝。
- Netty的Unpooled的CompositeByteBuf可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝。合并是通过拷贝字节数组的引用来解决问题的。而不是拷贝字节数组内容。这两个 ByteBuf 在CompositeByteBuf 内部都是单独存在的。
- Netty的Unpooled的wrap操作(底层封装了CompositeByteBuf操作),可以将byte[]数组、ByteBuf、ByteBuffer包装成一个Netty ByteBuf对象,避免了拷贝操作。(生成的ByteBuf对象和原始数据共用了同一个存储空间,对原对象的修改也会反映到ByteBuf对象中)
- Netty的ByteBuf的slice操作,可以将一个ByteBuf切片成多个共享一个存储区域的ByteBuf对象,其实内部就是共享了原ByteBuf存储空间的不同部分而已。
Selector 空轮询BUG
BUG
若Selector的轮询结果为空,也没有wakeup或者新消息处理,则发生空轮询,最后导致CPU使用率满。
Netty中的解决思路
对Selector()方法中的阻塞定时 select(timeMIllinois)操作的 次数进行统计,每完成一次select操作进行一次计数,若在循环周期内,发生N次空轮询,如果N值大于BUG阈值(默认为512),就进行空轮询BUG处理。重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的Selector上,并将原来的Selector关闭。
实时通信
WebSocket协议
通讯协议
TCP/IP
三次握手
四次挥手
UDP
HTTP
设计模式
策略模式
概念
项目里怎么用
单例模式
单例模式是一种设计模式,用于确保一个类只有一个实例,并提供一个全局访问点来访问该实例。
饿汉
class Single{
private static Single instance = new Single();
public static Single getSingle() {
return instance;
}
private Single() {
}
}
懒汉
单线程版本
class Singleton{
private static Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
private Singleton() {
}
}
多线程版本
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
双重检测锁
在实现单例模式时,使用双重检查锁(Double-Checked Locking)是一种常见的方式,结合使用volatile关键字来确保线程安全。
双重检查锁的方式可以在多线程环境下保证只有一个实例被创建,同时也能避免每次获取实例时都需要进行同步操作,提高了性能。它的基本思想是在获取实例时先检查实例是否已经被创建,如果没有被创建,则进入同步块进行实例的创建,这样可以减少多个线程同时进入同步块的情况。而第二次检查是为了在多个线程同时通过了第一个检查,只有一个线程能够创建实例,其他线程则直接返回已经创建的实例。
然而,双重检查锁在没有使用volatile关键字的情况下可能会引发线程安全问题。在Java中,由于指令重排序的存在,一个对象的创建过程可能被重排序,导致其他线程在第一个检查通过后,访问到一个未完全初始化的实例。为了解决这个问题,需要在实例的声明处使用volatile关键字,它的作用是禁止指令重排序,保证实例的创建过程是按照顺序进行的,从而避免了线程安全问题。
因此,使用双重检查锁方式实现单例模式时,需要同时使用volatile关键字,以确保线程安全和正确的对象创建顺序。
当一个对象被创建时,其实例化的过程通常会分为三个步骤:1)分配内存空间,2)初始化对象,3)将内存空间的引用赋值给对应的变量。
然而,在多线程环境下,由于编译器和处理器的优化,这些步骤可能会被重排序,即执行顺序可能不同于程序中的顺序。这种重排序在单线程环境下不会产生问题,因为对于单线程来说,重排序对最终结果没有影响。
但是,在多线程环境下,如果某个线程在执行双重检查锁时遇到了重排序,就可能会导致其他线程在第一个检查通过后,访问到一个尚未完全初始化的对象。这会引发严重的线程安全问题,因为其他线程可能会使用到未初始化完成的对象,导致程序出现意料之外的行为。
下面通过一个简单的例子来说明这个问题:
public class Singleton {
private static Singleton instance;
private Singleton() {
// 构造函数
}
public static Singleton getInstance() {
if (instance == null) { // 第一次检查
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查
instance = new Singleton(); // 重排序可能导致问题
}
}
}
return instance;
}
}
在上述代码中,当线程A通过第一个检查时,发现instance为null,于是进入同步块并执行instance = new Singleton()。然而,由于指令重排序,这个过程可能被重排为1)分配内存空间,2)将内存空间的引用赋值给instance,3)初始化对象。如果此时线程B也通过了第一个检查,那么它会发现instance不为null,并返回一个未完全初始化的对象,导致出现异常或不正确的行为。
为了解决这个问题,我们需要使用volatile关键字修饰instance变量,将其声明为volatile Singleton instance;。这样一来,volatile关键字会禁止指令重排序,确保实例化过程的顺序是按照程序中的顺序进行的,从而避免了其他线程获取到未完全初始化的对象。
责任链模式
模板方法模式
观察者模式
代理模式
Web开发框架
Spring
控制反转(IoC)
控制反转是一种设计原则,指将应用程序中对象的创建和管理交由Spring容器负责,而不需要我们在程序代码中手动去实例化它。
依赖注入(DI)
依赖注入是控制反转的一种实现方式,指的是在创建对象时,将对象所依赖的其他对象注入到它的属性或构造函数中。通过依赖注入,对象无需自己去查找或创建依赖的其他对象,只需要定义好类和依赖关系的配置,由框架负责将依赖的对象注入进来。
创建Bean的方式
- 构造函数注入
- Setter方法注入
- 静态/实例工厂方法注入
Bean的作用域
Singleton
从加载IOC容器开始,Spring IOC容器中同一种类仅会存在一个Bean实例,无论是否从容器中使用了该Bean。
Prototype
每次中容器种取用Bean时,都会创建一个新的Bean,如果不取出Bean,则不会创建Bean对象。
Request
每次HTTP请求都会创建一个新的Bean实例,该作用域仅在Web应用程序上下文中有效(该 bean 仅在当前 HTTP request 内有效)。
Session
同一个HTTP Session(会话)共享一个Bean,不同的Session使用不同的Bean,仅作用域Web应用程序上下文环境中(该 bean 仅在当前 HTTP session 内有效)。
Spring的依赖
Spring IOC容器默认情况下是根据applicationContext.xml中bean的配置顺序来决定创建顺序的,配置在前面的Bean会被优先创建,如果在不改变applicationContext.xml配置顺序的前提下,想调整bean的创建顺序,可以使用标签的depends-on属性来设置依赖关系,即设置当前Bean依赖于depends-on的Bean,则depends-on的Bean会先创建。
面向切面(AOP)
概念
AOP是面向对象编程OOP的一种补充,AOP可以拦截指定的方法并对方法进行增强,而无需侵入到业务代码中。主要应用在事务处理、日志管理、权限控制、异常处理等方面。
比如Spring的事务,通过事务的注解配置,Spring会自动在业务方法中开启、提交业务,并且在业务处理失败时,执行相应的回滚策略。
术语
Joinpoint(连接点):指那些被拦截到的点,即可以被动态代理拦截目标类的方法。(spring只支持方法类型的连接点)
Pointcut(切入点):指要对哪些Joinpoint进行拦截,即被拦截的连接点。
Advice(通知):指拦截到Joinpoint后需要做的事,即对切入点增强的内容。
Target(目标):指代理的目标对象。
Weaving(织入):指把增强应用到目标对象,生成代理对象的过程。
Proxy(代理):指生成的代理对象。(一个类被AOP织入增强后,就产生一个结果代理类)
Aspect(切面):切入点和通知的结合。
通知分类
before(前置通知):在目标方法执行之前通知。
after(后置通知):在目标方法执行后(无论是否发生异常)通知。
after-returning(返回通知):在目标方法返回结果后通知。
after-throwing(异常通知):在目标方法抛出异常后通知。
Around(环绕通知):在目标方法前后通知。
织入时期
编译期:切面在目标类编译时被织入,这种方式需要特殊的编译器,AspectJ的织入编译器就是以这种方式织入切面的。
类加载期:切面在目标类加载到JVM时被织入,这种方式需要特殊的类加载器(ClassLoader),它可以在目标类引入应用之前增强目标类的字节码。
运行期:切面在应用运行的某个时期被织入,一般情况下,在织入切面时,AOP容器会为目标对象动态创建一个代理对象,Spring AOP采用的就是这种织入方式。
实现原理
Spring AOP是通过动态代理实现的。
JDK动态代理
通过Proxy可以创建一个拥有接口的目标类的代理对象,代理对象实现了目标类的接口,并且对接口的所有方法都进行了代理(需要获取目标类的接口信息,根据这个接口就可以生成一个类,再通过ClassLoader加载到内存中),并通过实现InvocationHandler接口的invoke方法来实现代理对象接口的每个方法的调用及前后通知逻辑。通过代理对象调用目标类接口的方法时,会调用我们实现的invoke方法。
JDK动态代理无法为没有在接口中定义的方法实现代理,假设我们有一个实现了接口的类,我们为它的一个不属于接口中的方法配置了切面,Spring仍然会使用JDK的动态代理,但是由于配置了切面的方法不属于接口,为这个方法配置的切面将不会被织入。
CGLIB代理
通过字节码技术生成一个类,来继承目标类,并覆盖其中方法,利用回调函数来实现增强。
生命周期
生命周期阶段
实例化:Spring容器通过Bean定义创建一个Bean的实例,这个通常是通过构造函数实例化Bean对象。
属性赋值:Spring容器通过依赖注入(DI)的方式来实现Bean的属性和依赖,通过Setter方法或直接设置Bean属性进行实现。
初始化:Spring容器会调用Bean的初始化回调方法,通过实现InitializingBean接口的afterPropertiesSet()方法或使用@Bean注解的initMethod属性指定的自定义初始化方法来实现。
使用:这个时候Bean已经被完全初始化,并且可以在应用程序中使用它。
销毁:当Spring容器关闭或手动销毁Bean时,会调用Bean的销毁回调方法。可以通过实现DisposableBean接口的destory()方法或使用@Bean注解的destoryMethod属性指定自定义销毁方法来实现。
通过构造器或工厂方法创建Bean实例,为Bean的属性设置值和对其他Bean的引用,将Bean实例传递给Bean后置处理器的postProcessBeforeInitialization方法,调用Bean的初始化方法(init-method),将Bean实例传递给Bean后置处理器的postProcessAfterInitialization方法,Bean就可以使用了,当容器关闭时,调用Bean的销毁方法(destroy-method)。
事务传播机制
REQUIRED(Spring默认的事务传播类型:需要、依赖、依靠)
如果当前没有事务,则自己新建一个事务,如果当前存在事务则加入这个事务。
当A调用B的时候:如果A中没有事务,B中有事务,那么B会新建一个事务;如果A中也有事务、B中也有事务,那么B会加入到A中去,变成一个事务,这时,要么都成功,要么都失败。(假如A中有2个SQL,B中有两个SQL,那么这四个SQL会变成一个SQL,要么都成功,要么都失败)
如果B出现异常,由于A与B共用一个事务,所以无论A是否catch了B的异常,事务都会回滚。
SUPPORTS(支持、拥护)
当前存在事务,则加入当前事务,如何当前没有事务,就以非事务方式执行。
如果A中有事务,则B方法的事务加入A事务中,成为一个事务(一起成功,一起失败),如果A中没有事务,那么B就以非事务方式运行(执行完直接提交);
MANDATORY(强制性的)
当前存在事务,则加入当前事务,如果当前事务不存在,则抛出异常。
如果A中有事务,则B方法的事务加入A事务中,成为一个事务(一起成功,一起失败);如果A中没有事务,B中有事务,那么B就直接抛异常了,意思是B必须要支持回滚的事务中运行
REQUIRES_NEW(需要创建)
创建一个新的事务,如果当前存在事务,则挂起该事务。
B会新建一个事务,A和B事务互不干扰,他们出现问题回滚的时候,也都只回滚自己的事务;
NOT_SUPPORTED(不支持)
以非事务方式执行,如果当前存在事务,则挂起该事务。
被调用者B会以非事务方式运行(直接提交),如果当前有事务,也就是A中有事务,A会被挂起(不执行,等待B执行完,返回);A和B出现异常需要回滚,互不影响
NEVER(永不)
如果当前没有事务存在,就以非事务方式执行;如果有,就抛出异常。
就是B从不以事务方式运行。A中不能有事务,如果没有,B就以非事务方式执行,如果A存在事务,那么直接抛异常
NESTED(嵌套的)
如果当前事务存在,则在嵌套事务中执行,如果当前没有事务,则进行与REQUIRED类似的操作。
如果A中没有事务,那么B创建一个事务执行,如果A中也有事务(父事务),那么B会开启一个嵌套事务(子事务),父事务回滚时,子事务也会回滚,如果B出现异常,A可以catch其异常,这样只有子事务回滚,父事务不受影响。
SpringMVC
Mybatis
SpringBoot
启动加载过程
-
初始化SpringApplication
1. 根据项目的配置情况和Conditional条件来推断是否是一个Web应用。<br /> 2. 读取所有jar包下面spring.factories文件,解析放入缓存,然后读取ApplicationListener为key的监听器, 后续在SpringBoot加载的过程中会基于事件发布来做很多扩展通知。 -
真正的run方法开始执行,记录开始执行时间stopwatch。
-
读取所有的监听器,放入SpringApplicationRunListeners中,以便支持后续的事件发布订阅。
-
发布ApplicationStartingEvent事件,属于是一个Startup开始事件,感兴趣的监听器就会执行具体对应的startup方法。
-
基于监听器,加载yml或者properties文件,再根据配置文件中指定的spring.profiles.active环境来激活指定的环境配置,来设置Environment对象。
-
发布ApplicationEnvironmentPreparedEvent事件,感兴趣的监听器就会触发具体的方法。
-
打印SpringBoot的Logo、Banner(不重要)。
-
实例化Spring的上下文对象:AnnotationConfigServletWebServerApplicationContext。
-
applicationContext#setEnvironment(),将环境变量配置对象Environment设置到上下文中,然后执行ApplicationContextInitializer初始化上下文对象。
-
发布ApplicationContextInitialzedEvent事件,感兴趣的监听器执行对应的容器初始化方法。
-
解析启动类为BeanDefinition对象,以便后续IOC流程。
-
发布ApplicationPreparedEvent事件,感兴趣的监听器执行对应的方法。
-
#refresh()方法执行,和Spring的refresh不同的是,这个子类是AnnotationConfigServletWebServerApplicationContext。
-
在#refresh()方法中,除了执行IOC的流程外,后面还会执行#onRefresh()方法,这个方法里面就会创建servlet容器,注册DispatcherServlet。
-
计算启动总耗时,打印。
-
发布ApplicationStartedEvent事件,感兴趣的监听器执行对应的started方法。
-
发布ApplicationReadyEvent事件,感兴趣的监听器执行对应的就绪方法。
-
回调2个内置的扩展自动触发方法:
- 回调实现了ApplicationRunner接口的类,且自动执行覆写的run方法。
2. 回调实现了CommandLineRunner接口的类,且自动执行覆写的run方法。
- 回调实现了ApplicationRunner接口的类,且自动执行覆写的run方法。
-
如果启动过程中发生了异常,则发布ApplicationFailedEvent,监听器执行具体的异常处理方法。
SpringCloud
Gateway
JVM
体系结构
类加载
作用
将类加载到内存中。
类加载过程
加载
类加载器获取二进制字节流,并将静态存储结构转化为方法区的运行时数据结构,并在堆中生成此类的Class对象。
连接
当类被加载后,系统位置生成一个对应的Class对象,接着会进入连接阶段,连接阶段负责把类的二进制数据合并到JRE中(合并到JVM的运行状态中)。
验证
验证文件格式、元数据、字节码、符号引用,确保被加载的类信息符合JVM规范。
准备
正式为类变量(static变量)分配内存并设置类变量初始值的阶段(这些初始值通常为数据类型的零值,而非用户定义的初始值),这些内存都将在方法区中进行分配。
解析
将类中的符号引用转换为直接引用,即将类、方法、字段的引用转化为内存地址。
符号引用是一组符号来描述所引用的目标,而直接引用是指向目标的指针、偏移量或其他表示形式。
初始化
前面的过程都是由虚拟机主导,从初始化阶段开始执行类中的Java代码。初始化阶段执行类构造器方法,包括静态变量的赋值操作和静态代码块。这个阶段才会将静态变量设置为用户定义的初始值。首先会初始化父类如有。
类加载器
启动类加载器
负责加载jre/lib/rt.jar里的所有class。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。由C++实现,没有父类加载器。
拓展类加载器
负责加载 jre/lib/ext/*.jar 这些jar包。父类加载器为BootstrapClassLoader。
应用程序加载器
负责加载用户自定义的类及classpath环境变量所配置的jar包。父类加载器为ExtClassLoader。
自定义类加载器
负责加载程序员指定的特殊目录下的字节码文件的,自定义类加载器只需要继承ClassLoader这个抽象类,重写findClass()和loadClass()两个方法即可。父类加载器为AppClassLoader。
双亲委派机制
如果一个类加载器接收到类加载请求,它会把这个请求委派给父加载器去完成,如父加载器还存在父加载器,则会进一步向上委托。只有当父加载器反馈自己无法完成加载请求时,子加载器才会尝试自己去加载。所有加载请求最终都会传递到启动类加载器中。
采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,Java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
内存结构
运行时数据区
方法区
JDK1.8后的元空间。是所有线程共享的内存区域,存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
堆
是JVM所管理的内存中最大的一块,被所有线程共享的内存区域,存放对象实例,该区域是垃圾收集器管理的主要区域。
程序计数器
记录了当前执行到的字节码指令的地址(行号),以便线程切换回来后能恢复到切换前的执行位置以继续执行。程序计数器属于线程私有的。程序计数器内存区域是虚拟机中唯一没有规定OutOfMemoryError情况的区域。
虚拟机栈
用于描述Java方法执行的内存模型,每个方法在执行时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息,每一个方法从调用至执行完成,对应一个栈帧在虚拟机栈中的入栈到出栈。虚拟机栈是线程私有的,它的生命周期和线程相同。栈中不会存储成员变量,只会存储一个引用地址。
虚拟机栈包括:
- 局部变量表:是用来存储我们临时8个基本数据类型、对象引用地址、returnAddress类型。(returnAddress中保存的是return后要执行的字节码的指令地址。)
- 操作数栈:操作数栈在方法执行期间用于支持算术、逻辑运算以及方法调用等操作,例如代码中有个 i = 6*6,他在一开始的时候就会进行操作,读取我们的代码,进行计算后再放入局部变量表中去。
- 动态链接:动态链接是指栈帧中的一个指向运行时常量池中方法的引用。假如在当前方法中,有个 service.add()方法,要链接到别的方法中去,这就是动态链接,存储链接的地方。
- 出口:出口正常的话就是return 不正常的话就是抛出异常落
本地方法栈
与虚拟机栈作用相似,虚拟机栈为执行Java方法服务,本地方法栈为执行Native方法服务。
直接内存
直接内存不是虚拟机运行时数据区的一部分,而是通过一种特定的API来直接从操作系统中分配内存。可通过NIO的ByteBuffer类来完成的,这个类提供了对直接内存的支持,它可以使用native函数库直接分配堆外内存。然后通过一个存储在Java堆中的DirectByteBuffer 对象作为这块内存的引用进行操作。
直接内存申请空间耗费比堆内存高,但IO读写性能要由于堆内存。
执行引擎
负责执行虚拟机的字节码,将Java代码转化为实际的计算机指令,从而使Java程序能够在各种不同的平台上运行。虚拟机的字节码不能直接在物理机上运行,需要JVM字节码执行引擎编译成机器码后才能在物理机上执行。
垃圾回收机制
概念
对于一些没有引用指向的内存对象,由于对象已经无法访问,程序用不了,对于程序而言已经死亡,为确保程序运行时的性能,JVM在程序运行的过程中会不断地自动垃圾回收。
通过引用计数法、可达性分析来判断哪些对象被引用了,哪些没被引用(是否存活)。
引用计数法:每个对象在创建的时候,就给这个对象绑定一个计数器。每当有一个引用指向该对象时,计数器加一;每当有一个指向它的引用被删除时,计数器减一。这样,当没有引用指向该对象时,计数器为0就代表该对象死亡
可达性分析:该种方法是从GC Roots开始向下搜索,搜索所走过的路径为引用链。当一个对象到GC Roots没用任何引用链时(无法到GC Roots),则证明此对象是不可用的,表示可以回收。
垃圾回收的执行在Java程序中是自动的,不能手动强制回收哪些对象内存,可以通过System.gc来建议执行垃圾回收,但它什么时候执行是不可知的。
每次执行GC操作之前都会调用对象的finalize方法。
内存分代
方法去即被成为永久代,而堆中存放的是对象实例。为了回收时对不同对象采用不同的方法以便更好地管理堆内存中的对象的分配和回收,又将堆分为新生代和老年代,默认情况下,新生代占堆的1/3,老年代占堆的2/3。
-XX:NewRatio参数来设置新生代和老年代的比例。具体的计算方式是老年代大小除以新生代大小
-XX:SurvivorRatio:设置 Eden 区和 Survivor 区的比例,默认为 8
- 新生代中,每次垃圾收集时都发现大批对象死去,只有少量对象存活,便采用了复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
- 而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须采用“标记-清理”或者“标记-整理”算法。
新生代
新生代分为三块,一块较大的Eden区和两块较小的Survivor存活区,默认比例为8:1:1,To区域的比例是始终有90%的空间是可以用来创建对象的,而剩下的10%用来存放回收后存活的对象。JVM每次只会使用Eden和其中一块Survivor区,无论什么时候总有一块Survivor区是空闲的。
老年代
在新生代中经历多次GC后仍然存活下来的对象会进入老年代。老年代中的对象生命周期较长,存活率较高。老年代的GC频率相对较低,回收速度也相对较慢。
永久代
永久代也就是JVM的方法区,存储着类信息、常量、静态变量、即时编译器编译后的代码等数据,一般不会进行垃圾回收。
元空间
从JDK8开始,Java开始使用元空间代替永久代,元空间不在虚拟机中,而是直接使用本地内存。默认情况下,元空间大小仅受本地内存限制。
GC
GC过程
新生的对象被分配到Eden区中(大对象直接进入老年区),当Eden区没有足够空间进行分配时,JVM将发起一次Minor GC,GC开始时,对象只会存在于Eden区和Survivor From区,GC进行时,所有存活的对象都会被复制到Survivor To区,对象在Survivor中每熬过一次Minor GC,年龄就加一,当年龄到达阈值(默认为15)的对象会被转移到老年代中。接着清空Eden区和Survivor From区,接着交换Survivor From区和Survivor To区,也就是新的Survivor To区就是上次GC清空的Survivor From区,新的Survivor From区就是上次GC存活的Survivor To区,不管怎样都会保证Survivor To区在新一轮GC后是空的。当Survivor To区没有足够空间存放存活下来的对象时,需要依赖老年代进行分配担保。
Minor GC、Major GC、Full GC
区别
- Minor GC是在新生代,新生代无法为新生对象分配内存空间的时候会触发Minor GC操作,由于新生代中大多数对象的生命周期很短,故Minor GC的频率会很高,回收速度也比较块。
- Major GC是在老年代,通常执行Major GC的时候会伴随一次Minor GC,MajorGC 的速度一般会比 Minor GC 慢10倍以上。
- Full GC是针对整个新生代、老年代、元空间的全局GC。Full GC不等于Major GC,也不等于Minor GC+Major GC,发生Full GC需要看使用了什么垃圾收集器组合,才能解释是什么样的垃圾回收。
触发条件
- Minor GC:当Eden满时,触发Minor GC,在Minor GC之前会判断老年代的可用连续空间是否大于新生代所有对象总空间,如果大于则直接执行Minor GC,如果小于则判断是否开启HandlerPromotionFailure,没有开启则直接Full GC,如果开启了则会判断老年代的最大连续内存空间是否大于历次晋升平均值的大小,如果小于则直接执行Full GC,如果大于则执行Minor GC。
- Major GC、Full GC:老年代空间不足以保存一个大对象时会触发Full GC,最好不要创建大对象;当系统需要加载的类、调用的方法很多,同时方法区没有足够空间,就会触发一次Full GC;老年代最大可用连续空间小于Minor GC历次晋升到老年代对象的平均大小;Minor GC后存活的对象超过了老年代剩余空间;调用System.gc()时。
垃圾回收算法
标记-清除算法(Mark and Sweep Algorithm)
先标记出所有需要回收的对象,标记后统一回收所有被标记的对象。
可以解决循环引用的问题并且必要时才回收;
回收时应用需要挂起(stop the world),标记和清除的效率不高,尤其是扫描的对象比较多的时候,还会造成内存碎片(导致明明有内存空间,但是由于不连续,无法申请稍微大一些的对象)。
适用于老年代生命周期比较长。
标记-整理算法(Mark and Compact Algorithm)
标记-整理算法是标记-清除算法的一个改进版,同样先标记出所有需要回收的对象,标记后该算法并没有直接对标记的对象进行清理,而是将所有存活的对象整理一下,向一端移动,然后清除边界外的内存。
解决了标记-清除算法出现的内存碎片的问题。但是由于移动了可用对象,需要去更新引用。
适用于老年代生命周期比较长。
复制算法(Copying Algorithm)
该算法将内存平均分成两块,每次只使用其中一块,但这一块内存用完了,将内存中所有存活的对象复制到另一块内存中,并将之前的内存清空。
在存货对象不多的情况下,性能高,能解决内存碎片和标记-整理算法中的引用更新问题;
但会造成一部分的资源浪费,而且如果存活对象的数量比较大,复制算法的性能就会变得很差。
一般使用在新生代中,在Eden –>Survivor Space 与To Survivor之间实行复制算法,新生代存活的数量不多,这样复制算法拷贝效率更高。
分代回收算法(Generational Garbage Collection Algorithm)
根据对象的存活周期的不同将内存分为几代,每一代采用不同的算法,这样就可以根据各个代的特点采用最适合的收集算法。
在新生代中,每次都会有大量对象死亡,只有少量存活,因此采用复制算法,通过复制少量存活对象的成本就可以完成收集。
在老年代中,由于对象存活率较高,没有额外的空间进行分配担保,就必须采用标记-清除或标记-整理算法进行回收。
垃圾收集器
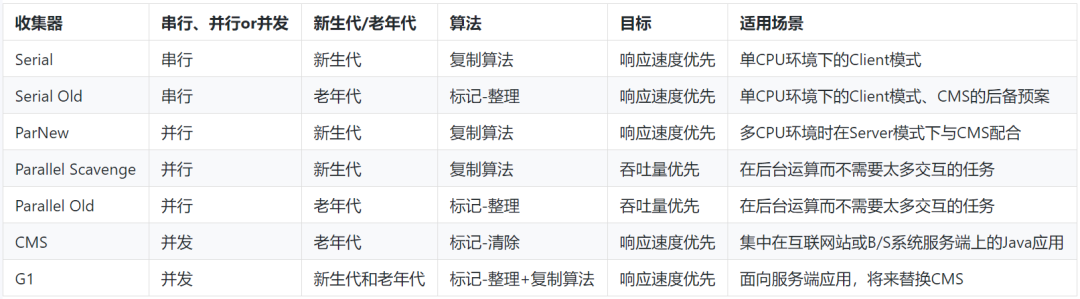
概念
垃圾回收器是垃圾回收算法的具体实现。
分类
新生代收集器
Serial收集器
单线程收集器,采用复制算法,在进行垃圾收集时,必须暂停其他所有的工作线程,直到收集结束。
-XX:+UseSerialGC
ParNew收集器
Serial的多线程版本,采用复制算法,同时启动多个线程去垃圾收集。只有该收集器能与CMS收集器配合使用。
-XX:+UseParNewGC
Parallel Scavenge收集器
多线程收集,采用复制算法,高吞吐量,减少垃圾收集时间。
所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间),虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验,而高吞吐量则可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
设置垃圾收集器:“-XX:+UseParallelGC” --添加该参数来显式的使用改垃圾收集器;
设置垃圾收集器参数:“-XX:MaxGCPauseMillis” --控制垃圾回收时最大的停顿时间(单位ms)
设置垃圾收集器参数:“-XX:GCTimeRatio” --控制程序运行的吞吐量大小吞吐量大小=代码执行时间/(代码执行时间+gc回收的时间)
设置垃圾收集器参数:“-XX:UseAdaptiveSizePolicy” --内存调优交给虚拟机管理
老年代收集器
Serial Old收集器
Serial的老年代版本,使用标记-整理算法,单线程收集。
-XX:+UseSerialGC(使用Serial + Serial Old的垃圾收集器组合)
Parallel Old收集器
Parallel的老年代版本,多线程收集器,使用标记-整理算法。
-XX:+UseParallelOldGC
CMS收集器
基于标记-清除算法的低停顿并发收集器。
对CPU资源非常敏感,无法处理浮动垃圾,可能出现"Concurrent Mode Failure"失败,会产生大量内存碎片。该线程与用户线程基本上可以同时工作。
-XX:+UseConcMarkSweepGC
整堆收集器
G1收集器
分代收集器,解决了CMS内存碎片、更多内存空间等问题。
能充分利用多CPU,可以并行来缩短(stop the world)停顿时间,可以并发让垃圾收集与用户程序同时进行,分代收集范围包括新生代和老年代,能独立管理整个GC堆而不需要其他收集器配合,能够采用不同方式处理不同时期的对象,采用标记-整理 + 复制算法来回收垃圾。
分代收集和区域化: G1将整个堆分为多个区域(Region),同时维护新生代和老年代的概念。每个区域可以是Eden区、幸存者区或老年区。这种区域化的管理使得G1能够更好地控制内存分配和垃圾回收。
设置垃圾收集器:“-XX:+UseG1GC”:指定使用G1收集器;
设置垃圾收集器参数:“-XX:InitiatingHeapOccupancyPercent”:当整个Java堆的占用率达到参数值时,开始并发标记阶段;默认为45;
设置垃圾收集器参数:“-XX:MaxGCPauseMillis”:为G1设置暂停时间目标,默认值为200毫秒;
设置垃圾收集器参数:“-XX:G1HeapRegionSize”:设置每个Region大小,范围1MB到32MB;目标是在最小Java堆时可以拥有约2048个Region
查看垃圾回收器
通过以下命令可以查看当前JVM使用的垃圾回收器:
java -XX:+PrintCommandLineFlags -version
java -XX:+PrintFlagsFinal -version
java -XX:+PrintFlagsFinal -version | grep .*Use.GC.
调优
常用的JVM参数
#常用的设置
-Xms:初始堆大小,JVM 启动的时候,给定堆空间大小。
-Xmx:最大堆大小,JVM 运行过程中,如果初始堆空间不足的时候,最大可以扩展到多少。
-Xmn:设置堆中年轻代大小。整个堆大小=年轻代大小+年老代大小+持久代大小。
-XX:NewSize=n 设置年轻代初始化大小大小
-XX:MaxNewSize=n 设置年轻代最大值
-XX:NewRatio=n 设置年轻代和年老代的比值。如: -XX:NewRatio=3,表示年轻代与年老代比值为 1:3,年轻代占整个年轻代+年老代和的 1/4
-XX:SurvivorRatio=n 年轻代中 Eden 区与两个 Survivor 区的比值。注意 Survivor 区有两个。8表示两个Survivor :eden=2:8 ,即一个Survivor占年轻代的1/10,默认就为8
-Xss:设置每个线程的堆栈大小。JDK5后每个线程 Java 栈大小为 1M,以前每个线程堆栈大小为 256K。
-XX:ThreadStackSize=n 线程堆栈大小
-XX:PermSize=n 设置持久代初始值
-XX:MaxPermSize=n 设置持久代大小
-XX:MaxTenuringThreshold=n 设置年轻带垃圾对象最大年龄。如果设置为 0 的话,则年轻代对象不经过 Survivor 区,直接进入年老代。
#下面是一些不常用的
-XX:LargePageSizeInBytes=n 设置堆内存的内存页大小
-XX:+UseFastAccessorMethods 优化原始类型的getter方法性能
-XX:+DisableExplicitGC 禁止在运行期显式地调用System.gc(),默认启用
-XX:+AggressiveOpts 是否启用JVM开发团队最新的调优成果。例如编译优化,偏向锁,并行年老代收集等,jdk6纸之后默认启动
-XX:+UseBiasedLocking 是否启用偏向锁,JDK6默认启用
-Xnoclassgc 是否禁用垃圾回收
-XX:+UseThreadPriorities 使用本地线程的优先级,默认启用
技巧
-Xms和-Xmx设置为一样
JVM的动态内存策略不太适合服务使用,因为每次GC需要计算Heap是否需要伸缩,内存抖动需要向系统申请或释放内存,特别是在服务重启的预热阶段,内存抖动会比较频繁。另外,容器中如果有其他进程还在消费内存,JVM内存抖动时可能申请内存失败,导致OOM。因此建议服务模式下,将Xms设置Xmx一样的值。
项目中的调优实践
MySQL
事务
概念
事务是一个不可再分的工作单元,通常一个事务对应一个完整流程的业务,需要DML语句共同联合完成,DML语句才有事务。事务规定这一个业务DML操作要么全部成功,要么全部失败。
特性ACID
原子性(Atomicity)
事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。
mysql会事先记录操作前的数据到undo log里面,当最终因为操作不当而发生事务回滚时,会从undo log进行数据回退。
一致性(Consistency)
事务从一个一致的状态变为另一个一致的状态,即要么是成功的状态,要么是失败的状态,不可看到事务还没提交的中间状态。
原子性关注的是成功/失败的状态,而一致性则关注数据的可见性,中级状态的数据对外不可见,只有初始状态和最终状态的数据对外可见。
隔离性(Isolation)
不同事务获知不到对方的操作,多个事务的操作互相隔离。
持久性(Durability)
一旦事务提交,被持久化到数据库中,它对数据库的改变就是永久性的。
通过重做日志:redo log日志,对于用户将对发生了修改而为提交的数据存入了redo log日志中,当此时发生断电等其他异常时,可以根据redo log日志重新对数据做一个提交,做一个恢复。
一致性问题
脏读
读到了其他事务未提交的数据。
不可重复读
在一个事务内,对同一条数据进行多次读取,读取的结果不一致。(事务 A 两次读取同一数据,第一次读取结果为 1,当事务 B 修改了数据并提交,此时的事务 A 第二次读取结果为 2,两次读取结果不一致)
幻读
在一个事务中,由于其他事务的插入/删除操作,导致同样的查询返回不同的结果集。
隔离级别
数据库提供了不同的隔离级别来解决并发事务执行过程中可能出现的这些一致性问题。
为了解决上述问题,数据库提供锁机制来解决并发访问的问题。例如,根据锁定对象不同,分为行级锁和表级锁;根据并发事务锁定的关系,分为共享锁和独占锁。
基于锁机制,数据库给用户提供了不同的事务隔离级别,只要设置了事务隔离级别,数据库就会分析事务中的sql语句然后自动选择合适的锁,可以依次有效地解决脏读、不可重复读和幻读的问题。
未提交读
在一个事务未提交时,其他事务可以看到它做的变更。即一个事务可以读取到另一个事务未提交的数据。会出现脏读、不可重复读和幻读的问题。
实现原理:
无锁读取(Lock-Free Reading): 在未提交读隔离级别下,读取操作不会对数据进行加锁或阻塞其他事务的修改操作。这意味着当一个事务进行读取操作时,即使其他事务正在修改相同的数据,也不会被阻塞或等待锁的释放。因此,未提交读可能读取到其他事务尚未提交的数据,包括可能包含脏数据的情况。
读取已提交数据(Read Committed Data): 虽然未提交读允许读取尚未提交的数据,但在实际实现中,数据库系统通常会遵循一种“读取已提交数据”的原则。这意味着未提交读在读取数据时会检查该数据所属的事务的状态,如果该事务尚未提交,则会等待该事务提交后再读取数据。这样可以避免读取到无效或不一致的数据。
已提交读
一个事务能读取到已提交的数据。可以避免脏读,但无法避免出现不可重复读和幻读。
实现原理:
行级锁(Row-level Locking): 在已提交读隔离级别下,数据库系统使用行级锁来管理并发事务对数据的读写访问。当一个事务读取某个数据时,会对该数据的相应行进行加锁,其他事务如果要修改该行数据,则需要等待该锁的释放。这样可以保证一个事务只能读取到已经提交的数据,避免了脏读问题。
事务日志(Transaction Log): 数据库系统使用事务日志记录每个事务的操作,包括读操作和写操作。在已提交读隔离级别下,当一个事务读取数据时,数据库会根据事务日志的信息来判断该事务能够读取到的数据版本。只有已经提交的数据版本才会被事务读取,保证了读操作的一致性。
可重复读
一个事务多次读取同一个数据时,其结果保持一致。
实现原理:
读取数据时使用一致性快照(Consistent Snapshot): 在可重复读隔离级别下,当事务开始时,会创建一个一致性快照,即事务开始时数据库的一个镜像,用于保留该事务开始时的数据状态。在事务执行过程中,所有的读取操作都基于这个一致性快照,而不受其他并发事务的修改影响。这样可以保证事务在多次读取同一数据时,读取到的数据是一致的。
使用MVCC(多版本并发控制):InnoDB为每行记录添加了一个版本号(系统版本号),每当修改数据时,版本号加一。在读取事务开始时,系统会给事务一个当前版本号,事务会读取版本号<=当前版本号的数据,这时就算另一个事务插入一个数据,并立马提交,新插入这条数据的版本号会比读取事务的版本号高,因此读取事务读的数据还是不会变。
串行化
事务串行执行,每个事务按顺序逐个执行。可以避免幻读,每一次读取的都是数据库中真实存在的数据。
对于同一行记录,写会加写锁,读会加读锁。当出现读写锁冲突时,后访问的事务必须等前一个事务执行完成,才能继续执行。可以避免脏读、不可重复读和幻读问题,但会牺牲并发性能,因为事务需要互斥地访问数据。
另一种解决幻读的方法:
通过对select操作手动加行X锁(写锁 排它锁)(SELECT … FOR UPDATE(字面意思就可以知道,该语句不单单是查询,而是为了后续的修改,所以是要对数据加锁的,并且是悲观锁) )。原因是InnoDB中行锁锁定的
是索引(采用非索引字段进行SELECT … FOR UPDATE时,会造成表锁;当采用索引字段时,如果所查的值占绝大部分时,会走全索引扫描,相当与将该字段看成普通字段来操作,也会造成表锁),纵然当前记录不存在,当前事务也会获得一把记录锁(记录存在就加行X锁,不
存在就加next-key lock间隙X锁),这样其他事务则无法插入此索引的记录,杜绝幻
读。
MVCC
概念
多版本并发控制,是为了在读取数据时不加锁来提高读取效率和并发性的一种手段。
数据库并发存在三种场景:
- 读-读(不存在任何问题)
- 读-写(有线程安全性问题,可能出现脏读、幻读、不可重复读)
- 写-写(有线程安全性问题,可能存在更新丢失等)
MVCC要解决的就是读-写时的线程安全问题,线程不用去争抢读写锁。
- 所以MVCC的读是快照读,也就是普通的select,不加锁,基于多版本,即读到的可能并不是最新数据。
- 还有另一种读取数据的方式是当前读,比如select … lock in share mode(共享锁)和select … for update、update、insert、delete(皆为排它锁),它会对当前读取的数据进行加锁,所以读到的数据都是最新的。
解决的问题
- 在并发读写数据库时,可以做到读操作不阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能。
- 同时还可以解决脏读、不可重复读、幻读等事务隔离问题,但不能解决更新丢失问题。
有了MVCC,我们可以形成两个组合:
MVCC + 悲观锁 :MVCC解决读写冲突,悲观锁解决写写冲突
MVCC + 乐观锁:MVCC解决读写冲突,乐观锁解决写写冲突
原理
MVCC的实现原理主要是依赖记录中的3个隐式字段、undo日志和Read View来实现的。
隐式字段
除了我们自定义的字段外,还有数据库隐式定义的字段:
DB_TRX_ID
表示修改/创建这条记录的事务ID。
DB_ROLL_PTR
回滚指针,用于配合undo日志,指向上一个版本的记录。
DB_ROW_ID
隐式自增主键ID,当数据库表没有主键时,会自动生成。
实际还有一个删除 flag 隐藏字段(deleted_bit ), 既记录被更新或删除并不代表真的删除,而是删除 flag 变了
undo日志
insert undo log
代表事务在insert新纪录时产生的undo log,只在事务回滚时需要,在事务提交后被丢弃。
update undo log
事务在进行update或delete时产生的undo log,不仅在事务回滚时需要,在快照读时也需要,所以不能随便删除,只有在快照读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除。
不同事务或相同事务对同一记录的修改,会导致该记录的undo log成为一条记录版本线性表,即链表,undo log的链首就是最新的旧纪录,链尾就是最早的旧纪录。
Read View(读视图)
事务进行快照读的时候产生的读视图,记录了系统活跃事务的ID,可用来做可见性判断,用来判断当前事务能够看到哪个版本的数据,可能是当前最新的数据,也可能是该行记录的undo log里的某个版本的数据。
读视图包括:
trx_list:活跃的事务ID列表
low_trx_id(up_limit_id):在活跃事务ID中最小的ID
height_trx_id(low_limit_id):在当前生成读视图时的下一个待分配的事务ID,也就是目前出现过的事务ID的最大值加一。
creator_trx_id:生成该 ReadView 的事务的事务 Id。
整体流程
当事务对某行数据执行了快照读,数据库会为该行数据生成一个Read View读视图,事务会拿当前快照读记录(要被修改的数据)的事务ID去跟读视图的low_trx_id、height_trx_id和trx_list属性进行比较,如不符合可见性,那就通过回滚指针去Undo Log中的事务ID再比较,即遍历链表的事务ID,直到找到符合条件的事务ID,则该事务ID所在的旧纪录就是当前事务能看到的最新老版本。
1)如果被访问版本的trx_id与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
2)如果被访问版本的trx_id小于ReadView中的up_limit_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
3)如果被访问版本的trx_id大于ReadView中的low_limit_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
4)如果被访问版本的trx_id属性值在ReadView的up_limit_id和low_limit_id之间,那就需要判断一下trx_id属性值是不是在trx_ids列表中。如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
RC RR的实现
(1)RC的隔离级别下,每个快照读都会生成并获取最新的readview。
(2)RR的隔离级别下,只有在同一个事务的第一个快照读才会创建readview,之后的每次快照读都使用的同一个readview,所以每次的查询结果都是一样的。
锁机制
按锁的粒度划分
全局锁
对整个数据库进行加锁,使整个数据库处于只读状态。增删改、建表、修改表个事务提交等都会被阻塞。
使用场景:做全库逻辑备份。
表级锁
一次性对整张表进行加锁,获取锁和释放锁的速度很快,但资源争用概率增大致使并发性降低。
行级锁
对一条数据加锁,锁粒度小,并发度大。根据两阶段锁协议,行锁是在需要的时候才加上但并不是不需要了就立刻释放,而是等到事务结束时才释放。
行锁是通过锁住表的索引来实现的,如果索引失效,则会上升为表锁。
如果事务中需要锁多个行,要把最可能造成锁冲突,最可能影响并发度的锁尽量往后放。
页级锁
开销和粒度介于表锁和行锁之间。
按锁的兼容性划分
共享锁
又称读锁,简称S锁,多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改,读取数据时,不允许其他事务对当前数据进行修改操作。可以避免不可重读的问题。
排他锁
又称写锁、独占锁,简称X锁,当事务对数据加上写锁后,其他事务既不能对该数据添加读锁,也不能对数据添加写锁,写锁是为了在修改数据时,避免其他事务对当前数据的修改和读取操作。可以避免脏读的问题。
InnoDB在默认的隔离级别下,对于update、delete、insert语句,会自动给涉及的数据集加排它锁。
按锁的模式划分
记录锁
对表中的记录加锁,防止其他事务插入、更新、删除这条记录,也称行锁。锁的列必须为唯一索引或主键索引,否则加的锁会变成临键锁,查询语句也必须精准匹配(=)。
记录锁是锁住索引记录,而不是真正的数据记录,如果锁的列没有索引,则会进行全表记录加锁。
间隙锁
间隙锁是InnoDB在可重复读隔离界别下为了解决幻读问题而引入的锁机制,是行锁的一种。使用间隙锁锁住的是一个开区间,而不仅仅是这个区间中的每一条数据。不锁定记录本身。
SELECT * FROM emp WHERE empid > 100 FOR UPDATE
SELECT * from goods where id between 1 and 10 for update;
临键锁
是记录锁和间隙锁的组合,与非唯一索引有关,在每个数据的非唯一索引列上都会存在一把临键锁,当某个事务持有该数据行的临键锁时,会锁住一段左开右闭区间的数据。
例如某个字段的值为10,下条数据的字段值为24,当执行where条件介于(10, 24]的锁操作时,将获取这个区间的临键锁,后面有事务对该字段执行该范围内的操作时,会被阻塞。
意向锁
当一个事务需要对整个表加共享锁/排它锁时,必须保证没有其他事务持有该表的排它锁和没有其他事务持有该表中任意一行的排它锁,因此当前事务必须去检查表中的每一行是否存在排它锁,而有了意向锁后,当前事务秩序看表上有没有意向锁就好了。
当对不同的N行加了行级X锁,那么这个时候就会存在N个IX锁,如果这个时候有个事务想对整个表加排它X锁,它不需要遍历每一行是否存在S或X锁,而是看看存不存在意向锁,只要存在一个意向锁,那么这个事务就加不了表级排它X锁,要等上面N个IX锁都释放了才行。
意向锁不会为难意向锁,也不会为难 行级排他(X) / 共享(X)锁,它的存在是为难 表级排他(X) / 共享(X)锁。
| 兼容性 | IS | IX | S | X |
|---|---|---|---|---|
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
意向共享锁(intention shared lock, IS)
事务有意向对表中的某些行加共享锁(S锁)。
意向排它锁(intention exclusive lock, IX)
事务有意向对表中的某些行加排它锁(X锁)。
插入意向锁
该锁表示插入意向,是一种特殊的间隙锁,当使用间隙锁插入某个区间内的数据时,另一个事务也进行该区间的插入操作时会阻塞等待,这样会导致插入并发性变差,而使用插入意向锁时,多个事务在同一区间插入位置不同的多条数据时,只要数据本身(主键、唯一索引)不冲突,那么事务之间不需要相互等待。解决了在可重读隔离级别下的并发插入问题。
插入一行数据(对应有主键、唯一索引)时,事务会使用插入意向锁和记录锁。
自增锁
MySQL的自增锁是指在使用自增主键(Auto Increment)时,为了保证唯一性和正确性,系统会对自增字段进行加锁。这样可以确保同时插入多条记录时,每条记录都能够获得唯一的自增值。
需要注意的是,自增锁只会影响涉及到自增列的插入操作,其他查询或更新操作不会受到自增锁的影响。此外,自增锁是一种短暂的锁定,只在插入操作期间保持锁定状态,因此它不会对并发性产生过大的影响。
按锁的态度分类
悲观锁
为防止有其他事务对数据进行操作,每次拿数据的时候就会上锁,直到把锁释放后,其他事务才能对数据加锁。
适用于写多读少的情况,如果还使用乐观锁的话,会经常出现操作冲突,这样会导致应用层会不断地 Retry,反而会降低系统性能。
乐观锁
认为别的事务不会同时修改数据,所以拿数据和修改数据的时候不会上锁,等到要提交的时候才会对数据冲突与否进行检测。
一般通过添加版本号或时间戳字段用于标识数据的版本来实现乐观锁。
适用于读多写少的情况,这样可以省去锁竞争的开销,提高系统的吞吐量。
索引
什么是索引
索引是帮助MySQL高效获取数据的数据结构,数据库可以使用索引来快速定位满足条件的数据行,而不必扫描整个表。
为什么要有索引
提高查询速度、优化数据检索、支持唯一性约束、加快连接操作、支持排序和分组、减少磁盘IO。
索引分类
主键索引
索引列为主键。
单值索引
一个字段上添加索引。
唯一索引
具有unique约束的字段上添加索引。
联合索引
两个字段或更多字段上添加索引。
最左匹配原则
数据库会利用索引中最左边的列,然后逐渐向右匹配其他列。如果没有涉及到最左的列,就无法使用联合索引。
适用于等值查询、排序,但遇到范围查询(>、<、between、like)就会停止匹配(如果左边的列是精确查找的,右边的列可以进行范围查找,会使用到联合索引)。
联合索引首先是按照a(第一列)排序的,b是无序的,只有a值匹配上了,b才相对有序(小范围内递增有序)。
匹配列前缀
如果列使用模糊匹配,如果匹配在前缀,则用的索引,如果匹配是后缀和中缀则只能全表扫描。
前缀模糊匹配使用索引比较的是字符。
全文索引
只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。字段长度比较大时,如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。 MyISAM和InnoDB中都可以使用全文索引。使用MATCH()函数和AGAINST()关键字来执行全文搜索查询。
创建全文索引列:
CREATE FULLTEXT INDEX 索引名 ON 表名(列名) WITH TARSER ngram;
使用全文索引:
SELECT * FROM 表名 WHERE MATCH(列名) AGAINST(‘输入的参数’);
全文索引的插叙效率是比使用LIKE来查询要快的,所以在MySQL8之后是建议使用全文索引的。
聚簇索引
就是找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引。
非聚簇索引
索引的存储和数据的存储时分离的,也就是意味着找到了索引但没有找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
索引数据结构
hash
使用键值对的方式存储数据,key保存索引列,value保存行记录或行磁盘地址。Hash表在等值查询的时候效率很高,时间复杂度为O(1),但不支持任何范围查询(Hash的每个键之间没有任何联系)。
二叉树
每个节点最多有两个分叉,左节点比右节点小。这种分叉使得每次查找可以折半而减少IO次数。
但二叉树会出现树不分叉的情况。
平衡二叉树
平衡二叉树除了具备二叉树的特点外,最主要的特征是左右两树的高度最多相差1,在插入/删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很高、右子树很矮的情况。
但时间复杂度和树高相关,每个节点的读取都需要一次IO操作,在表数据量大时,查询性能就会变很差。并且不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率不高。
btree
B树是一种多叉平衡树,由于访问平衡二叉树的每个节点就要发生一次IO(一次IO默认会读取一页(16k)的数据量),而二叉树一次IO的有效数据量很小,导致空间利用率很低,为了充分利用一次IO的空间,可以在每个节点尽可能多的存储数据,并且将二叉改为多叉(每个节点有多个分叉),这样便可以极大地降低树的高度,使得IO次数变少,查找效率提高。
假如我们查询值等于10的数据。查询路径磁盘块1->磁盘块2->磁盘块5。
第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左路,到磁盘寻址磁盘块2。
第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<10,到磁盘中寻址定位到磁盘块5。
第三次磁盘IO:将磁盘块5加载到内存中,在内存中从头遍历比较,10=10,找到10,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。
相比二叉平衡查找树,在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少。同时,由于我们的比较是在内存中进行的,比较的耗时可以忽略不计。B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
但B树并不支持范围查询的快速查找,如果要查找N到M之间的数据,查找到N之后,需要回到根节点重新遍历查找,需要从根节点多次遍历,查询效率有待提高。每个节点里的键值对应有数据data,data存储了行记录,但如果随着行所在的列数的增多,需要的空间也就更大,会导致一个页可以存储的数据量就会变少,从而树会变高,磁盘IO的次数就会增多。
b+tree
b+tree在btree的基础上继续改造,b+tree只有叶子节点才会存储数据,而非叶子节点存储键值,叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序的链表。
B+tree在范围查询的快速查找时,如果要查找N到M之间的数据,查找到N之后,不需要要回到根节点重新遍历查找,只需要根据叶子节点的指针,向后查找下一个节点(另外一次IO)的数据。
设计原则
- 索引字段经常出现在where后面,以条件的形式存在,即这个字段总是被扫描。
- 索引字段很少的DML操作,因为DML之后索引需要重新排序。
- 在创建联合索引的时候应该把频繁使用的列、区分度高的列放在前面,频繁使用代表所有利用率高、区分度高代表筛选粒度大。
- 查询中与其他表关联的字段(连接查询)建立索引。
- 查询中排序的字段建立索引。
存储引擎
InnoDB
- 支持事务操作,一条SQL默认封装成事务,自动提交,并且是一个支持ACID(原子性、一致性、隔离性和持久性)事务的存储引擎。这使得它非常适合处理要求数据一致性和完整性的应用程序。
- 支持外键;
- 支持表级锁、行级锁等;
- 在MySQL 5.6.4版本之后支持全文索引;
- 必须有主键,否则会为表创建一个隐式主键作为主键索引;
- 存储方式为 .frm文件(存储表结构)、.ibd文件(存储数据内容);
MyISAM
- 支持全文索引;
- 支持表级锁,不支持行级锁;
- 主键不是必须的;
- 存储方式为 .frm文件(存储表结构)、.MYD文件(存储数据内容)、.MYI文件(存储索引文件);
InnoDB于MyISMA的区别
- InnoDB支持事务,MyISMA不支持;
- InnoDB支持外键,MyISMA不支持;
- InnoDB是聚簇索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(.ibd文件),而MyISMA是非聚簇索引,它也是使用B+Tree作为索引结构,但是索引和数据文件是分离的,索引保存的是数据文件的指针(.MYI文件和.MYD文件)。
- InnoDB 必须要有主键,MyISAM可以没有主键;
- InnoDB辅助索引和主键索引之间存在层级关系;MyISAM辅助索引和主键索引则是平级关系;
- InnoDB不保存表的具体行数,而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可;
- InnoDB支持表级锁、行级锁,默认为行级锁;而 MyISAM 仅支持表级锁;
- Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI;
CSV
数据是以CSV文件存储的。
- 不能定于索引,列定义必须为NOT NULL,不能设置自增列,因此不适用于大表或者数据查询、排序等处理操作;
- CSV数据的存储需要用逗号隔开,可直接编辑CSV文件进行数据的编排,但数据安全性低;
- 可以对硬盘中保存的表文件数据进行直接编辑xxx.CSV文件;
应用于数据的快速导入导出和表格直接转换成CSV。
Archive
以压缩协议进行数据的存储。
- 只支持插入和查询操作,不支持更新和删除操作,因此不适用于对数据的处理操作;
- 只允许自增ID列建立索引,因此不方便数据的处理;
- 支持行级锁;
- 不支持事务;
- 数据占用磁盘少;
应用于系统日志和大量的设备数据采集。
MEMORY
数据存储在内存中,基于Hash索引,底层是Hash表,对于精确查询非常高效,但无法通过索引做区间查询,只能全部扫描。
- 数据都是存储在内存中,IO效率比其他引擎高很多;
- 重启后数据会丢失,内存数据表默认只有16M,因此保证不了持久性;
- 支持Hash索引,B Tree索引,默认Hash索引;
- 不支持大数据存储类型,如blog、text等;
- 表级锁;
应用于等值查找热度较高的数据,以及查询结果在内存中进行计算,采用这种存储引擎作为临时表存储需要计算的数据。
MERGE
- 逻辑表:MERGE存储引擎允许你将多个相同结构的表合并成一个逻辑表,这样可以进行跨表查询。
- 不支持事务:MERGE存储引擎不支持事务和外键。
Blackhole
- 数据写入被丢弃:Blackhole存储引擎将所有写入数据都丢弃,适用于复制和数据同步场景。
- 只支持写入:只能用于写入数据,不支持查询操作。
SQL调优
排查慢sql(慢查询日志)
查询超过一定的时间阈值(默认10s)没有返回结果时,MySQL会将执行的SQL记录到日志中,这个日志就叫做慢查询日志,通过分析慢查询日志,可以快速找出执行慢的SQL语句,然后进行优化。
slow_query_log 是否开启慢查询日志
long_query_time 慢查询时间
log_queries_not_using_indexes 如果运行的SQL语句没有使用索引,则MySQL数据库同样会将这条SQL语句记录到慢查询日志文件。
log_throttle_queries_not_using_indexes 表示每分钟允许记录到slow log的且未使用索引的SQL语句次数。该值默认为0,表示没有限制。在生产环境下,若没有使用索引,此类SQL语句会频繁地被记录到slow log,从而导致slow log文件的大小不断增加。
慢查询的日志记录另外一种存储形式就是表。慢查询表默认在mysql数据库,表名为slow_log。
配置方法:
在编辑文件my.cnf/my.ini中修改或添加
[mysqld]
slow_query_log = 1
slow_query_log_file = /path/to/slow-query.log
long_query_time = 2
log_throttle_queries_not_using_indexes = 1
log_throttle_queries_not_using_indexes = 10//每分钟最多记录10条未使用索引的查询语句
重启MySQL服务以生效。
explain sql执行计划
各列字段及值的含义
id
select查询的序列号,表示查询中执行select字句或操作表的顺序。
当id相同时,执行顺序由上至下;当id不同时,如果是子查询,id序号会递增,id值越大优先级越高,越先被执行。
当id“不同”和“相同”两者同时存在,则看table显示的是<derived?>,?指的是指向id为?的表,即id为?的表的衍生表。
select_type
simple:简单的select查询,查询中不包含子查询或union。
primary:查询中若包含任何复杂的子部分,最外层查询则被标记为primary。
derived:在from列表中包含的子查询被标记为derived(衍生),mysql会把子查询的结果放在临时表里。
subquery:在select或where列表中包含了子查询。
union:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived。
union result:从union表获取结果的select。
table
当前执行的表
type
表示查询使用了哪种类型。
system:表只有一行记录(等于系统表),这是const类型的特例。
const:通过索引一次就找到了,用于比较primary key或者unique索引,因为只匹配一行数据,所以很快。
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描。
ref:非唯一性索引扫描,返回所有匹配某个单独值的行。
range:使用索引范围进行查询,一般就是在where语句中出现between、<、>、in等查询,只需要开始于索引的某一点,结束于索引的另一点,不用扫描全部索引。
index:索引扫描,需要遍历索引树,但比all块。
all:全表扫描,将遍历全表以找到匹配的行。
possible_keys
可能用于此查询的索引,这些是在查询优化过程中考虑的潜在索引。
key
查询中实际使用的索引,如果为null,则未选择索引(可能没有建立索引或者索引失效)。
查询中若使用了覆盖索引(select 后要查询的字段刚好和创建的索引字段完全相同),则该索引仅出现在key列表中
key_len
索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
ref
显示索引的哪一列被使用了,哪些列或常量被用于查找索引列上的值。
rows
执行查询时需要检查的行数。
extra
using filesort:查询时需要进行外部文件排序,而不是按照表内的索引顺序进行读取,无法利用索引完成排序。通常发生在order by操作中。
using temporary:在对查询结果进行排序时使用临时表,即需要创建临时表来处理查询。常见于排序order by和分组查询group by。
using index:表示查询操作使用了覆盖索引,避免访问了表的数据行,是一种较高效的查询方式。
如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。
using index condition:表示查询使用了索引条件来进行过滤。
using index for group-by:表示查询使用了索引来处理GROUP BY操作。
using index for order by:表示查询使用了索引来处理ORDER BY操作,通常发生在覆盖索引的情况下。
using where:使用了where过滤。
using join buffer:表明使用了连接缓冲区,提高连接查询性能。
在查询的时候,多表join的次数非常多,那么将配置文件中的缓冲区的join buffer调大一些。
impossible where:where子句的值总是false(例如where id = ‘1’ and id = ‘2’)导致没有匹配的行。
select tables optimized away:表示由于某些优化,查询中的某些表被优化掉,不会被实际访问。
distinct:在找到第一匹配的元组后即停止找同样值的动作。
索引优化
索引失效
通配符开头的模糊匹配(%开头)
使用or作为连接条件(or的前后存在非索引列都会导致索引失效,两边都要有索引才会进行索引查询)
使用联合索引时,没有遵循最左匹配原则
在索引列上进行计算、函数、类型转换等操作
索引列使用不等于(!= / <>)条件
is not null和索引列中存在null值会导致索引失效
尽量索引覆盖
如果查询条件、查询字段都在一个联合索引上,这样根据这个辅助索引查询到的结果就可以直接获取当前语句的完整数据,避免了回表查询。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
读写分离
分库分表
垂直划分
水平划分
主从
表设计
怎么设计
三范式
Redis
数据类型
String字符串
一个Key对应一个Value,value最多可以是512M。
set key value
List列表
双端链表。
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
lpush key value
Set集合
无序集合。
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现
sadd key value
Hash散列
String类型的field(字段)和value(属性)的映射表。
- 缓存: 能直观,相比string更节省空间,维护缓存信息,如用户信息,视频信息等。
hset key field value
ZSet有序集合
每个元素都关联一个double类型的权重参数score,使得集合中的元素能够按score进行有序排列。
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
- 成绩排行:比如一个存储全班同学成绩的sorted set,其集合value可以是同学的学号,而score就可以是其考试得分, 形成了按成绩排序。
- 权重分配:可以用sorted set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
zadd key score value
数据持久化机制
Redis是基于内存的,如果Redis服务挂了,数据就会丢失,为了避免数据丢失,Redis提供了RDB和AOF两种持久化方式。
RDB
概念
将内存数据以快照的形式保存在磁盘,记录的是某一时刻的数据。
在指定的时间间隔内,执行指定次数的写操作时,会将内存中的数据集快照写入磁盘中(触发rdb持久化操作),这是Redis默认的持久化方式。操作完成后,会生成一个dump.rdb文件,Redis重启的时候,通过加载该文件来恢复数据。
触发机制
手动触发
save:同步,会阻塞当前Redis服务。
bgsave:异步,Redis进程执行fork操作创建子进程。
自动触发
save m n:再m秒内数据集存在n次修改,自动触发bgsave。
写时复制(Copy-On-Write,COW)机制
Redis借助操作系统的写时复制(Copy-On-Write)技术,在生成快照的同时,仍然可以接收命令处理数据。bgsave进程中的线程运行后,开始读取主进程的内存数据,如果主进程进行了写操作,则会对命令操作的数据复制一份,生成副本,bgsave进程中的线程会把这个副本写入到dump.rdb文件中,这个过程,主进程仍可以执行命令。
优缺点
缺点
RDB每次持久化需要将所有内存数据写入文件,然后替换原有文件,当内存数据量很大的时候,频繁的生成快照会很耗性能。
如果将生成快照的策略设置的时间间隔很大,会导致redis宕机的时候丢失过的的数据。
优点
应为dump.rdb文件是二进制文件,所以当redis服务崩溃恢复的时候,能很快的将文件数据恢复到内存之中。
AOF(append only file)
概念
记录每个写操作到appendonly.aof文件末尾。AOF是先执行完命令再记录日志的,因为记录日志前不会对命令语法进行检查。
刷盘策略
- always:每次执行完写命令都会刷盘,非常快也非常安全。
- everysec:每个命令执行完,只是先写到AOF内存缓冲区,每隔一秒同步到磁盘。
- no:把日志写到AOF缓冲区,何时写入磁盘由系统去决定。
重写机制
随着时间的迁移,AOF文件会存在一些冗余指令例如无效指令、过期指令等,利用AOF重写机制可以把它们合并为一个命令(类似批处理命令),从而达到精简压缩的目的。
重写过程是由后台子进程bgrewriteaof完成。
优缺点
- 优点:数据的一致性和完整性更高,秒级数据丢失。
- 缺点:相同的数据集,AOF文件体积大于RDB文件。数据恢复也比较慢。
混合持久化
使用RDB恢复内存状态可能会丢失大量数据,使用AOF日志重放相对于RDB又慢很多。Redis4.0为了解决这个问题,带来了混合持久化的方式。
通过如下配置开启:
aof‐use‐rdb‐preamble yes
开启混合持久化后,AOF不在单纯将内存数据命令写入AOF文件,而是在重写这一刻之前对内存做RDB快照,将RDB快照内容和增量的AOF修改内存数据命令存在一起,新的文件一开始不叫appendonly.aof,而是等到写入新的AOF文件后才会更名从而覆盖原来的AOF文件。
在Redis重启时,先加载RDB内容,再重放增量AOF日志就可以替代之前按AOF全量文件重放,大幅度提升效率。
高可用架构
主从复制模式
概念
这个模式可以保证多台服务器的数据一致性,且主从服务器之间采用的是读写分离的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
即所有数据的修改都只在主服务上进行,然后将最新数据同步给从服务,这样使得主从服务的数据一致。
同步过程
同步操作
让服务器B作为服务器A的从服务器,可执行以下命令
# 服务器 B 执行这条命令
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>
第一次同步
第一阶段
**建立连接,协商同步。**执行replicaof命令后,从服务器会给主服务器发送psync命令,表示要进行数据同步。psync包含主服务器的runID和复制进度offset两个参数(第一次同步时,从服务器不知道主服务器的ID,所以这里设置为?,offset设置为-1)。主服务器收到psync命令后,会用带有主服务器runID和主服务器目前复制进度offset的FULLRESYNC响应命令给从服务器,从服务会保存这两个值。
runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。
第一阶段的工作是为了后面的全量复制做准备。
第二阶段
**主服务器同步数据给从服务器。**主服务器执行bgsave命令来生产RDB文件,然后把文件发送给从服务,从服务收到后先清空当前数据,然后载入RDB文件。
但是这期间(bgsave期间)如果有写操作命令是没有记录到刚刚生成的RDB文件中的,这时主从服务器的数据就不一致了,因此主服务器会在RDB文件生成后写入收到的写操作命令到replication buffer缓冲区中。
第三阶段
**主服务器发送新增的写操作命令到从服务器。**在主服务器生成的RDB文件发送后,会将replication buffer缓冲区里所记录的写操作命令发送给从服务器,然后从服务器执行这些操作。
主服务器可以有多个从服务器,但如果从服务器的数量众多,会导致主服务器忙于使用fork创建子线程来生成RDB文件(如果主服务器的内存数据非大,在执行 fork() 函数时是会阻塞主线程的,从而使得 Redis 无法正常处理请求);传输RDB文件也会占用主服务器的网络带宽,从而对主服务器响应命令请求产生影响。
要解决这个问题,可以创建从服务器来管理多个从服务器,它不仅接收主服务器的同步数据,自己也可以作为主服务器将数据同步给旗下的从服务器,从而主服务器的压力可以分摊给这个从服务器。
可以在众多的从服务器上执行下面这条命令,使其作为目标服务器的从服务器
replicaof <目标服务器的IP> <目标服务器的Port>
基于长连接的命令传播
主从服务器在完成第一次同步后,双方会维护一个TCP连接(网络连接会一直维持着),后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,使得主从服务的数据一致。
增量复制
主从服务器在完成第一次同步后,就与基于长连接命令传播。
但是如果网络不稳定导致网络延迟或断开,就无法正常传播命令了,这时就无法保持从服务器于主服务器的数据一致,客户端可能从从服务器读取到旧的数据。
当网络恢复后,主从服务器会采用增量复制的方式继续同步,把网络断开期间主服务器接收到的写命令同步给从服务器。
具体过程:
恢复网络后,从服务会发送psync命令给主服务器,此时的psync命令里的offset参数的值不是-1,主服务器收到该命令后,使用CONTINUE命令告诉从服务器接下来采用增量复制的方式同步数据,主服务器根据自己的复制偏移量和从服务器传过来的复制偏移量之间的差距,在repl_backlog_buffer(复制积压缓冲区,保存主服务器最近传播的写命令)中找到差异的数据,将增量的数据写入replication缓冲区中,这个缓冲区就是要传播给从服务的命令,再把这些命令发送给从服务器,从服务器执行这些命令同步增量数据。
如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
相反,如果判断出从服务器要读取的数据已经不存在
repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。所以为了避免这种情况的频繁发生,要调大repl_backlog_size 这个参数的值,以降低主从服务器断开后全量同步的概率。
全量复制
当从服务器刚刚启动、或者由于断开连接时间过长而无法进行增量复制时,会触发全量复制。主服务器将整个数据集发送给从服务器,从服务器丢弃现有数据,然后加载主服务器发送的完整数据集。
过程:
主节点bgsave->RDB文件网络传输->从节点清空数据->从节点加载RDB->可能的AOF重写
心跳检测
主从节点在建立复制后,主节点会根据 repl-ping-slave-period 配置定时向从节点发送ping命令,判断从节点的存活性和连接状态,默认为10s。从节点在主线程中每隔1秒发送replconf ack{offset}命令,实时监测主从节点网络状态,给主节点上报自身当前的复制偏移量,检查复制数据是否丢失。通过min-slaves-to-write、minslaves-max-lag参数配置,实现保证从节点的数量和延迟性功能。设置合理的复制超时时间 repl-timeout:默认为60秒。
配置实现
主节点redis-master.conf
# master
#端口号
port 6379
#设置客户端连接后进行任何其他指定前需要使用的密码
requirepass 123456
#daemonize no 将daemonize yes注释起来或者 daemonize no设置,因为该配置和docker run中-d参数冲突,会导致容器一直启动失败
daemonize no
# 任何主机都可以连接到redis
bind 0.0.0.0
#是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问,拒绝外部访问。
protected-mode no
# 默认情况下,redis会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。
# 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。
# 开启append only模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态。
# 但是这样会造成appendonly.aof文件过大,所以redis还支持了BGREWRITEAOF指令,对appendonly.aof 进行重新整理。
# 你可以同时开启asynchronous dumps 和 AOF
appendonly yes
从节点1 redis-slave-1.conf
# slave1
port 6379
#设置客户端连接后进行任何其他指定前需要使用的密码
requirepass 123456
# 这一步很重要!主从认证密码,否则主从不能同步!!
masterauth 123456
#daemonize no 将daemonize yes注释起来或者 daemonize no设置,因为该配置和docker run中-d参数冲突,会导致容器一直启动失败
daemonize no
# 任何主机都可以连接到redis
bind 0.0.0.0
#是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问,拒绝外部访问。
protected-mode no
# 开启AOF
appendonly yes
从节点2 redis-slave-2.conf
# slave2
port 6379
#设置客户端连接后进行任何其他指定前需要使用的密码
requirepass 123456
# 这一步很重要!主从认证密码,否则主从不能同步!!
masterauth 123456
#daemonize no 将daemonize yes注释起来或者 daemonize no设置,因为该配置和docker run中-d参数冲突,会导致容器一直启动失败
daemonize no
# 任何主机都可以连接到redis
bind 0.0.0.0
#是否开启保护模式,默认开启。要是配置里没有指定bind和密码。开启该参数后,redis只会本地进行访问,拒绝外部访问。
protected-mode no
# 开启AOF
appendonly yes
docker-compose来配置并启动节点
version: "3.7"
services:
redis-master:
image: redis
container_name: redis-master
volumes:
- ./redis-master.conf:/usr/local/etc/redis/redis.conf
- ./redis-master/data:/data
ports:
- 6379:6379
command: redis-server /usr/local/etc/redis/redis.conf
networks:
- redis-work
redis-slave-1:
image: redis
container_name: redis-slave-1
volumes:
- ./redis-slave-1.conf:/usr/local/etc/redis/redis.conf
- ./redis-slave-1/data:/data
ports:
- 6380:6379
command: redis-server /usr/local/etc/redis/redis.conf --replicaof redis-master 6379
depends_on:
- redis-master
networks:
- redis-work
redis-slave-2:
image: redis
container_name: redis-slave-2
volumes:
- ./redis-slave-2.conf:/usr/local/etc/redis/redis.conf
- ./redis-slave-2/data:/data
ports:
- 6381:6379
command: redis-server /usr/local/etc/redis/redis.conf --replicaof redis-master 6379
depends_on:
- redis-master
networks:
- redis-work
networks:
redis-work:
name: redis-work
进入master和slave节点
auth 123456
info replication
master节点情况
# Replication
role:master
connected_slaves:2
slave0:ip=172.23.0.3,port=6379,state=online,offset=658,lag=1
slave1:ip=172.23.0.4,port=6379,state=online,offset=658,lag=1
master_failover_state:no-failover
master_replid:33efb6127c3700f183b6f0c94cfbceebd16a451d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:658
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:658
slave节点情况
# Replication
role:slave
master_host:redis-master
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:4418
slave_repl_offset:4418
master_link_down_since_seconds:68
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:33efb6127c3700f183b6f0c94cfbceebd16a451d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:4418
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4418
把从节点停机后再重启,不会自动恢复到从节点,需要重新replicaof主节点;而把主节点停机之后,从节点会一直等待主节点恢复后重连。
从机断开后,重新连接,也是可以拿到主机的全部数据的
如果在线上宕机了,在此期间应用就会无法写入数据,这种现象发生在线上环境是很 “危险” 的,那有没有一种方式能监控master节点,发现master节点宕机了之后立即将现有从节点升级为主节点呢?
那就需要哨兵模式来监控…
哨兵模式
背景
当使用主从复制模式时,如果主服务器宕机了,无法执行写操作,只能响应读操作,无法进行故障转移。
哨兵可以解决这个问题,由一个或多个哨兵实例组成的哨兵系统,可监视主服务器,以及旗下的从服务器,当主服务器被哨兵判断为客观下线,各哨兵节点会投票出一个哨兵节点用来推送故障转移选出新的主服务器。
组建工作流程
- 哨兵启动后会向master发送INFO命令,master收到命令后,建立连接并把当前节点以及旗下的从节点信息返回给哨兵;
- 哨兵根据返回的信息,和每个从库建立连接,并监控从库;
- 如果再有一个哨兵,也是同样给master发送INFO命令,也会拿到从节点和哨兵的实例信息;
- 每个哨兵直接会建立一个发布订阅,互相发送ping命令,保证信息长期对称。
在主从集群中,主库上有一个名为__sentinel__:hello的频道,不同哨兵就是通过它来相互发现并互相通信的。例如哨兵 1 把自己的 IP(172.16.19.3)和端口(26579)发布到__sentinel__:hello频道上,哨兵 2 和 3 订阅了该频道。那么此时,哨兵 2 和 3 就可以从这个频道直接获取哨兵 1 的 IP 地址和端口号。然后,哨兵 2、3 可以和哨兵 1 建立网络连接。同理哨兵2.3也可以建立连接,从而形成哨兵集群。
监控和故障处理工作过程
主库下线的判定
哨兵会一直给主节点发送publish sentinel:hello(PING心跳),如果收不到响应,则标记该节点为主观下线(单个哨兵实例对主服务器做出下线判断,如果服务在sentinel down-after-milliseconds给定的毫秒数之内没有回应,那么这个哨兵会单方面认为这个主节点不可用),然后会给其他哨兵发送is-master-down-by-address-port命令,接着,其他哨兵会根据自己和主库的连接情况,做出赞成或反对的投票,汇总投票大于哨兵配置文件中的quorum其实就是超过哨兵数量的半数则任务主节点客观下线(至少有quorum个哨兵认为这个master有故障才会认为这个主节点不可用,有时候某个哨兵因为自身网络故障导致无法连接master会出现误判断)了。
哨兵集群的选举
主库下线后,需要有一个哨兵节点来执行主从切换,这个执行节点由哨兵集群选举产生。通过Raft选举算法(例如当sentinel1和sentinel3同时把指令发送到哨兵内部群里准备竞选时,sentinel2这个时候就说我先接到谁的指令就把票投给谁。假如sentinel1发的早,那么sentinel2的票就会投给sentinel1),某个哨兵的票数满足总哨兵数量的一半之多后这个哨兵就会当选。
Redis 1主4从,5个哨兵,哨兵配置quorum为2,如果3个哨兵故障,当主库宕机时,哨兵能否判断主库“客观下线”?能否主从切换?
(1)可以判定主库“客观下线“。两个哨兵都判定”主观下线“,达到了quorum的值。
(2)不可以主从切换。要进行切换,得到选举的票数必须大于等于5/2+1=3。
新主节点的选出
选举条件:
响应快的;复制偏移量大的;节点创建时间早的(优先级);
故障转移
选举出的哨兵节点来进行故障转移操作,将选举出来的从节点升级为主节点(replicaof no one),将其他的从节点指向新的主节点(replicaof new master的IP端口),并通知客户端主节点已更换,将原主节点变为从节点指向新的主节点。
客户端来连接Redis集群时,会首先连接哨兵,通过哨兵来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向哨兵要地址,哨兵会将最新的主节点地址告诉客户端。因此应用程序无需重启即可自动完成主从节点的切换。
脑裂现象
概念
在主从环境中,出现了两个决策者,即同时拥有两个主节点,它们都能接收写请求。
影响
会导致数据丢失,因为新主库确定后,会向所有实例发送replicaof命令,让所有实例进行全量同步,而全量同步首先会对实例上的数据先清空,所以主从同步期间客户端写入原主库执行的命令就会丢失。
可能原因
- 哨兵之间网络出现分区,导致一部分哨兵无法与另一部分哨兵通信,每部分可能会认为主节点不可用而尝试选举新的主节点,导致不同哨兵集选举出不同的主节点。
- 原主节点暂时故障,在哨兵进行选举和故障转移的过程中原主节点恢复和客户端的通信。
暂时故障有可能以下原因:
1、同服务器其它进程占用大量CPU资源,导致主节点短时间无法响应心跳,CPU资源空闲后恢复正常。
2、主库自身阻塞,如处理bigkey或者发生内存swap时,短时间无法响应心跳,阻塞解决后心跳恢复正常。
- 网络分区被分成了主节点和客户端,哨兵和主库,集主节点和客户端在一个网络,而哨兵和主库在另一个网络,此时哨兵会发起主从切换,从而出现两个主节点。
解决方法
使用min-replicas-to-write和min-replicas-max-lag两个配置项可减轻脑裂问题带来的影响。
min-replicas-to-write
这个配置项指定了在进行写操作时,至少有多少个从节点是可用且健康的。如果可用从节点数量未到达配置值,主节点将拒绝写入,保证有足够的从节点能够接收主节点同步过来的数据,减少数据丢失的风险。
min-replicas-max-lag
这个配置项制定了同步最大延迟时间,如果同步的延迟超过了配置值,主节点拒绝写入,确保只有相对实时的数据副本才能用于写操作,避免再发生故障时,延迟较高的从节点影响主节点数据的一致性。
配置实现
基于主从复制模式,我们需要为redis-master节点添加哨兵作为监视器。
哨兵1 redis-sentinel-1.conf
port 26379
daemonize no
sentinel monitor mymaster redis-master 6379 2
sentinel auth-pass mymaster 123456
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
sentinel down-after-milliseconds mymaster 30000
# 指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
#开启之后可以解析主机名 即在sentinel monitor可以使用容器名来访问
SENTINEL resolve-hostnames yes
复制两份相同的配置文件给哨兵2 哨兵3
cp redis-sentinel-1.conf redis-sentinel-2.conf
cp redis-sentinel-1.conf redis-sentinel-3.conf
启动哨兵
version: "3.7"
services:
redis-sentinel-1:
image: redis
container_name: redis-sentinel-1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./redis-sentinel-1.conf:/usr/local/etc/redis/sentinel.conf
networks:
- redis-work
redis-sentinel-2:
image: redis
container_name: redis-sentinel-2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./redis-sentinel-2.conf:/usr/local/etc/redis/sentinel.conf
networks:
- redis-work
redis-sentinel-3:
image: redis
container_name: redis-sentinel-3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./redis-sentinel-3.conf:/usr/local/etc/redis/sentinel.conf
networks:
- redis-work
networks:
redis-work:
name: redis-work
保证redis和sentinel在同一docker网络下
随便进入一个哨兵节点
info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.25.0.2:6379,slaves=2,sentinels=3
故障测试
停止master节点
docker-compose -f docker-compose-redis.yml stop redis-master
查看哨兵logs
1:X 03 Nov 2023 08:21:26.480 # +tilt #tilt mode entered
1:X 03 Nov 2023 08:21:56.560 # -tilt #tilt mode exited
1:X 03 Nov 2023 08:21:56.560 # +sdown master mymaster 172.25.0.2 6379
1:X 03 Nov 2023 08:21:56.622 # Could not rename tmp config file (Device or resource busy)
1:X 03 Nov 2023 08:21:56.622 # WARNING: Sentinel was not able to save the new configuration on disk!!!: Device or resource busy
1:X 03 Nov 2023 08:21:56.622 # +new-epoch 1
1:X 03 Nov 2023 08:21:56.622 # Could not rename tmp config file (Device or resource busy)
1:X 03 Nov 2023 08:21:56.622 # WARNING: Sentinel was not able to save the new configuration on disk!!!: Device or resource busy
1:X 03 Nov 2023 08:21:56.622 # +vote-for-leader 0c5d30c146d7edc0af7ccef7c1014cf5946241a9 1
1:X 03 Nov 2023 08:22:00.254 # +tilt #tilt mode entered
1:X 03 Nov 2023 08:22:30.332 # -tilt #tilt mode exited
1:X 03 Nov 2023 08:22:33.438 # +odown master mymaster 172.25.0.2 6379 #quorum 2/2
1:X 03 Nov 2023 08:22:33.438 # Next failover delay: I will not start a failover before Fri Nov 3 08:27:57 2023
1:X 03 Nov 2023 08:22:37.577 # +tilt #tilt mode entered
1:X 03 Nov 2023 08:23:03.461 # +config-update-from sentinel 0c5d30c146d7edc0af7ccef7c1014cf5946241a9 172.25.0.7 26379 @ mymaster 172.25.0.2 6379
1:X 03 Nov 2023 08:23:03.461 # +switch-master mymaster 172.25.0.2 6379 172.25.0.4 6379
1:X 03 Nov 2023 08:23:03.461 * +slave slave 172.25.0.3:6379 172.25.0.3 6379 @ mymaster 172.25.0.4 6379
sentinel检测到主节点下线,待客观下线后
+vote-for-leader:为新的领导者投票
启动故障转移
收到来自选举出来的执行故障转移的sentinel leader哨兵节点的更新配置
+switch-master:切换到新的主节点
+slave:添加一个新的从节点
Cluster集群模式(分片集群)
背景
哨兵模式的集群已经基本实现了高可用、读写分离。
但是在这种模式下:
- 主从切换的过程中会丢失数据;
- 由于只有一个主节点,只能单点写,没有水平扩容的能力;
- 每台Redis服务器都存储了相同的数据,非常浪费内存;
- 进行数据恢复时,非常慢;
所以在Redis3.0加入了Cluster集群模式,实现了Redis的分布式存储,即每台Redis节点上存储了不同的内容,即把一大份数据拆分成多份小数据。
在 3.0 之前,我们只能通过构建多个 redis 主从节点集群,把不同业务数据拆分到不同的集群中,这种方式在业务层需要有大量的代码来完成数据分片、路由等工作,导致维护成本高、增加、移除节点比较繁琐。
结构
一个Redis Cluster由多个Redis节点构成,不同节点管理着不同的分片和不同的数据。
节点组内分有主备两类节点,对应master和slave节点,两者数据准实时一致,通过异步化的主备复制机制来保证。如果其中有个主节点失败了,那么整个集群就会缺少某个槽点范围,此时利用从节点选举的方式可以提供新的主节点替代失效的主节点继续服务。
Gossip协议(流行病协议)
背景
在redis cluster集群中,会出现新加入节点、slot迁移、节点宕机、slave选举为master等情况,那就需要将变化能够让整个集群的每个节点都能发现到,所以各个节点间就要连通并传播相关状态数据。
如果采用广播的方式,虽然数据同步较快,但是需要同一时间一并发送给所有节点,对CPU和带宽影响较大。
规则
Gossip协议实现了一种去中心化的集群状态管理方式,会周期性地随机选择邻接节点散播消息,每次散播消息都会选择尚未发送过的节点进行散播,收到消息的节点不再往发送消息的节点散播,通过这样一个“感染”过程,最终每个节点都能够获取集群中其他节点的状态信息,能够动态地适应节点的加入、离开和状态变化,有助于实现Redis Cluster集群的高可用和故障恢复能力。
消息类型
- PING:PING 消息用于询问其他节点的状态。一个节点可以向其他节点发送 PING 消息,以获取它们的状态信息。
- PONG:PONG 消息是对 PING 消息的响应,包含了节点的状态信息。当一个节点收到 PING 消息时,它会回复一个 PONG 消息,包含自己的状态。
- MEET:MEET 消息用于节点的发现。当一个新节点加入集群时,它会向集群中的其他节点发送 MEET 消息,以便其他节点认识它。
- FAIL:FAIL 消息用于指示节点的故障。如果一个节点发现另一个节点故障(例如,长时间没有收到它的消息),它会发送 FAIL 消息来通知其他节点。
- PUBLISH:PUBLISH 消息用于在节点之间传播重要的集群事件,如槽位重新分配、节点故障等。
这些消息类型的交换和处理使得集群中的节点能够相互发现、同步状态,并及时检测到其他节点的故障。通过这种消息交换,Redis Cluster 能够实现高可用性、故障恢复以及动态添加或移除节点等功能。
优缺点
优点:分散传播,降低了发送压力;去中心化,可拓展、自适应性、容错、简单;理论上所有节点都会收到消息,符合最终一致性。
缺点:不确定性,节点间状态同步不是及时的;延迟,节点之间消息传播需要一定时间,会影响故障检测;不是强一致性,节点间的状态可能存在差异。
主从切换原理(故障转移Failover)
从节点发现自己的主节点变为FALL,会触发failover机制,在集群内广播选举消息FAILOVER_AUTH_REQUEST ,请求其他节点同意来进行failover,其他节点收到该消息后只有持有槽的主节点才会处理故障选举消息(FAILOVER_AUTH_REQUEST),处理消息的节点会对请求合法性进行判断并回复FAILOVER_AUTH_ACK消息作为投票,offset越大的从节点越先发送选举消息,可以降低主从复制数据的丢失的数据量,如集群内有N个持有槽的主节点代表有N张选票且只能投给一个从节点,直至有一个从节点获得超过半数的选票,它会成为新的主节点,执行clusterDelSlot操作撤销故障主节点负责的槽,并执行clusterAddSlot把这些槽委派给自己,最后向集群广播消息,通知集群内所有的节点当前从节点变为主节点并接管了故障主节点的槽信息。
哈希槽
一致性hash算法
key和节点都在圆环上,每个缓存节点和key遵循hash算法,映射到环形空间当中的某个位置,每个key的顺时针方向最近的节点,就是key所属的缓存节点。新增或删除节点,key和几点的映射关系需要被改变,需要在缓存命中时才会被刷新到新的节点上。
哈希槽算法
哈希槽是很小粒度的存储分区,通过hash算法将数据存放到对应的槽里面,槽分配给每个redis节点。在redis集群中,会虚拟出16384个槽位来存储数据集。通过对key进行CRC16运算后对16384取模(计算公式:slot = CRC16(key) & 16383)来决定放置在哪个槽。
使用哈希槽的好处就在于可以方便的添加或移除节点。
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
为何设计为16384个槽
理论上CRC16算法可以得到2^16个数值,其数值范围在0-65535之间,也就是最多可以有65535个虚拟槽,但是如果槽位为65535,发送心跳信息的信息头达8k,发送的心跳包过于庞大。
redis的集群主节点数量基本不可能超过1000,超过1000会导致网络拥堵。
槽位越小,节点越少,压缩率越高。
配置实现
缓存问题
缓存穿透
查询一个缓存和数据库都不存在的数据,导致每次请求都要落到数据库。
解决方案:
- 对空值进行缓存;
- 设置可访问白名单;
- 采用布隆过滤器,布隆过滤器认为一条数据出现过,那么该条数据很可能出现过;但如果布隆过滤器认为一条数据没有出现过,那么该条数据一定没有出现过。首先去布隆过滤器中查询该key是否存在。如果不存在,则说明数据库中也不存在该数据,因此不需要查询,直接返回null。如果存在,则继续执行后续的流程,先前往Redis缓存中查询,缓存中没有的话再前往数据库中的查询。
缓存雪崩
在某个时间点,大量缓存失效,导致大量请求落到数据库上,使得数据库负载急剧增加。通常发生在缓存中的数据同时失效的情境下,比如设置了相同的过期时间。
解决方案:
- 构建多级缓存;
- 设置不同的过期时间,比如在基础过期时间上添加随即过期时间;
- 设置过期标志,如果过期会触发通知另外线程去更新;
缓存击穿
某个热点数据失效,导致大量请求同时涌进数据库,缓存击穿针对的是某个热点数据的失效,而不是所有/大量数据。
解决方案:
- 使用互斥锁,对查询数据库的key进行上锁,此时其他请求就无法查询该字段,从而被阻塞,当得到锁的请求完成查询并将值放入缓存后再释放锁,此时其他请求就可以直接从缓存中查到该数据;
- 设置热点数据永不过期或预先设置热点数据的过期时长;
- 使用限流与熔断;
过期策略
定期删除
Redis定期随机抽取一些设置了过期时间的key,检测这些key是否过期,过期了就删除。
惰性删除
当去获取某个key的时候,再去检测下这个key是否已经过期。
"定期删除+惰性删除"就能保证过期的key最终一定会被删掉 ,但是只能保证最终一定会被删除,要是定期删除遗漏的大量过期key,我们在很长的一段时间内也没有再访问这些key,那么这些过期key不就一直会存在于内存中吗?不就会一直占着我们的内存吗?这样不还是会导致redis内存耗尽吗?由于存在这样的问题,所以redis又引入了“内存淘汰机制”来解决。
内存淘汰策略
八种淘汰策略
- noeviction:默认策略,不淘汰数据;大部分写命令都将返回错误(DEL等少数除外);
- allkeys-lru:从所有数据中根据 LRU 算法挑选数据淘汰;
- volatile-lru:从设置了过期时间的数据中根据 LRU 算法挑选数据淘汰;
- allkeys-random:从所有数据中随机挑选数据淘汰;
- volatile-random:从设置了过期时间的数据中随机挑选数据淘汰;
- volatile-ttl:从设置了过期时间的数据中,挑选越早过期的数据进行删除;
- allkeys-lfu:从所有数据中根据 LFU 算法挑选数据淘汰;
- volatile-lfu:从设置了过期时间的数据中根据 LFU 算法挑选数据淘汰;
淘汰算法
LRU
LRU(Least Recently Used,最近最少使用,也就是最久没有使用的。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高,如:key1是在3s之前访问的, key2是在9s之前访问的,删除的就是key2)。
使用链表和哈希表,使用哈希表来存储数据的键和对应的链表节点的指针,使用双向链表来维护数据的访问顺序,头部表示最近被使用的数据,尾部表示最久未被使用的数据。当数据被访问时,如果数据在哈希表中存在,则将对应的链表节点移动到链表头部,表示最近被使用,当需要淘汰数据时,从链表尾部移除最久未被使用的数据。
LFU
LFU(Least Frequently Used,最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高,如:key1最近5s访问了4次, key2最近5s访问了9次,删除的就是key1)。
使用哈希表来存储数据的键和对应的链表节点的指针,维护了两个链表,横向组成的链表用来存储访问频率,每个访问频率节点下的另一个链表用于存储相同访问频率的数据。当添加元素时,找到相同访问频次的节点,然后添加到该节点的数据链表的头部。如果该数据链表满了,则移除链表尾部的节点。当获取元素或者修改元素时,都会增加对应key的访问频次,并把当前节点移动到下一个频次节点。
大Key与热Key
大key
概念
指一个key对应的value占用空间很大,String长度大于10K,List长度大于10240。
问题
slot内存不均;
阻塞请求;
阻塞网络;
排查
redis-cli -h 127.0.0.1 -p 6379 --bigkeys
debug object bigkey
memory usage bigkey(默认抽样5个field来循环累加计算整个key的内存大小)
优化
优化原则是String减少字符串长度,list、hash、set、zset减少成员数。
拆分
将大key拆分成多个小key
get不同的key或者批量获取multiGet;
分别存储在hash中;
压缩数据
采用压缩算法
使用本地缓存
减少redis的访问次数
热key
概念
指被频繁访问的某个键。
问题
流量集中,达到物理网卡上限;
请求过多,缓存分片服务被打垮;
DB击穿,引起业务雪崩;
排查
凭借业务经验进行预估哪些是热key;
在客户端收集,在操作redis之前,加入代码进行数据统计;
monitor命令,能实时抓取redis服务器接收到的命令,然后使用代码统计出热key;
redis-cli --hotkeys
优化
利用二级缓存
使用本地缓存,直接返回数据,避免请求到redis上。
备份热key
把热key备份到多台redis上,当有请求来的时候,就在有备份的redis上随机选取一台进行取值。
分片
将热 Key 分布到多个 Redis 实例中,通过分片技术将访问分散,避免单一实例的负载过高。
限流和降级
针对热 Key,可以考虑实施限流策略,控制对该 Key 的访问频率,或者在高峰时段实施降级策略,避免服务过载。
消息队列
协议
AMQP
JMS
Pulsar
Functions
Kafka
消息队列的共性
模式
点对点
发布订阅
消息积压
消息丢失
消息重复
消息顺序
可靠性
解耦性
Docker
操作Docker的常用命令及参数
构建Dockerfile的常用命令
Docker网络
JIB
如何自动构建制作容器
Docker-Compose
写法
scale扩缩容
Kubernetes(K8s)
作用
Linux
常用命令
CI/CD持续集成部署
自动化部署流程
Arthas
常用命令
Nginx
概念
操作
线上问题排查与解决
内存占用、CPU占用过大怎么排查
OOM
使用-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=来设置系统发生OOM时生成dump文件。使用MAT来分析dump文件,一般流程是:通过Histogram来查看内存占用过大的对象,然后通过dominator_tree来查看调用链(对象被谁引用),确定被谁(可以是哪个线程)引用后,最后通过thread_overview可查看堆栈信息定位到具体代码。
在Histogram中
java.lang.Object[14053]含义:List本质上就是Object[]数组,14053就是里面存放的对象的个数.
Shallow Heap (浅层堆)表示:对象实际占用的堆大小(不包含其它引用对象的大小)
Retained Heap(保留堆)表示:对象实际占用+所包含引用对象的大小

















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









