







参考
ST-GCN源码运行完整版(含OpenPose编译安装)及常见问题_咬我呀_Gemini的博客-CSDN博客
关于在ubuntu20.04下openpose环境安装_openpose ubuntu安装_键盘强者的博客-CSDN博客
Linux服务器下openpose搭建_linux 安装openpose_蓝雨飞扬7的博客-CSDN博客
kinetics-skeleton格式行为数据提取方法_can not find pose estimation results._青年夏日科技工作者的博客-CSDN博客
配置:
CUDA11.1
cudnn 8.1.0
Ubuntu20.04
显卡3070
Python3.6
现有问题:
(1)3.3 节运行离线Demo失败,但目前来看不影响后续训练模型
(2)只能单卡跑,双卡报错还未解决
(3)测试结果比原文少了百分之1.4左右
1.下载源码、预训练模型
源码:
https://gitee.com/chenhongqiong/st-gcn.git
预训练模型:
下载好的模型文件拷贝至源码文件中./models文件路径下
下载数据集
kinetics-skeleton数据集,st-gcn作者提供的预处理kinetics-skeleton数据集是谷歌网盘,需要翻墙才能下载,大概8g。可以通过百度网盘,提取码:sqpx下载,(感谢第四条参考中提供的百度网盘链接)
原始ntu-rgbd数据集:
百度云版本:
也可以去官网填写申请(我用的这个方法,填写申请之后等一两天,只需要5.8g的骨骼数据):
2.环境搭建
2.1创建虚拟环境
conda create -n stgcn python=3.6
activate stgcn2.2安装依赖项(在上述虚拟环境中)
2.2.1 pytorch
去官网查看对应版本的安装指令
以前的版本查询Previous PyTorch Versions | PyTorch
服务器的cuda是11.1,因此对应安装指令为
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge测试安装成功

2.2.2其他依赖项
conda install ffmpeg进入st-gcn源码目录下
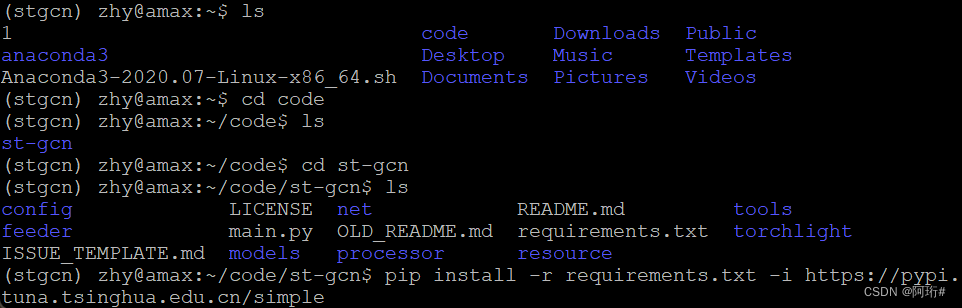
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3 安装与配置openpose
2.3.1检查是否安装opencv和cmake

![]()
2.3.2下载openpose
git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose.git如果在终端下载不了,就去网站手动下载(两个应该都行),全部克隆到本地mirrors / CMU-Perceptual-Computing-Lab / openpose · GitCode
https://github.com/CMU-Perceptual-Computing-Lab/openpose/tree/v1.5.0
2.3.3安装CMake GUI
sudo apt-get install cmake-qt-gui2.3.4安装opencv
sudo apt-get install libopencv-dev2.3.5安装caffe
sudo apt-get update
sudo apt-get install cmake git unzip
sudo apt-get install libprotobuf-dev libleveldb-dev liblmdb-dev
sudo apt-get install libsnappy-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install libatlas-base-dev libopenblas-dev
sudo apt-get install the python3-dev python3-skimage
sudo pip3 install pydot
sudo apt-get install graphviz如果倒数第二条遇到报错pip3:command not found,见Linux使用pip3报错:pip3:command not found_pip3找不到命令_嵌入式Linux充电站的博客-CSDN博客
cd openpose/
git submodule update --init --recursive --remote
报错fatal: Not a git repository (or any of the parent directories): .git,见
解决 fatal: Not a git repository (or any of the parent directories): .git 问题_蜗牛有力量的博客-CSDN博客
sudo bash ./scripts/ubuntu/install_deps.sh
sudo apt install protobuf-compiler libgoogle-glog-dev
cd openpose/3rdparty/
git clone https://github.com/CMU-Perceptual-Computing-Lab/caffe.git
git clone https://github.com/pybind/pybind11
如果上面这两个链接下不了,就用浏览器打开手动下载到本地,然后分别放到caffe和pybind11文件夹内
cd build/
cmake-gui ..出现图形化界面
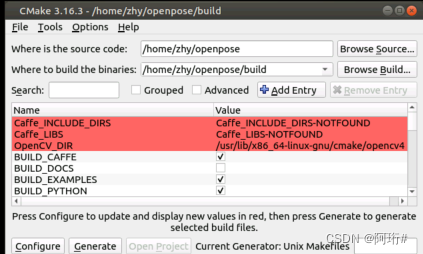
确认上面两个路径没问题后,点击configure,
若报错CMake Error at cmake/Cuda.cmake:227 (message): cuDNN version >3 is required.
则找到Openpose下 cmake/cuda.cmake file 和 /cmake/modules/FindCuDNN.cmake file.
将
file(READ {CUDNN_INCLUDE}/cudnn.h CUDNN_VERSION_FILE_CONTENTS)
改为
file(READ {CUDNN_INCLUDE}/cudnn_version.h CUDNN_VERSION_FILE_CONTENTS)![]()
再次configure,无报错,显示configure done
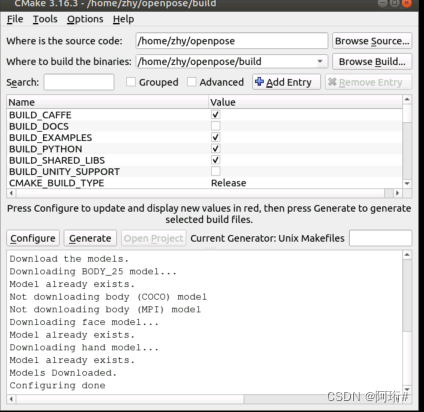
点击generate,然后关闭,回到终端,依旧是build目录下
make -j`nproc`等待编译结束...
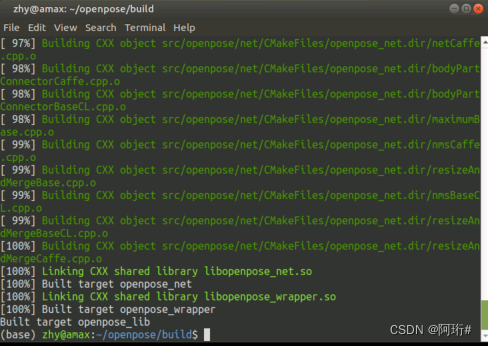
跑例程失败
./build/examples/openpose/openpose.bin --image_dir examples/media/ --face --hand
./build/examples/openpose/openpose.bin --video examples/media/video.avi
若运行
./build/examples/openpose/openpose.bin --video examples/media/video.avi --model_pose MPI_4_layers --net_resolution 320x176则报错模型问题
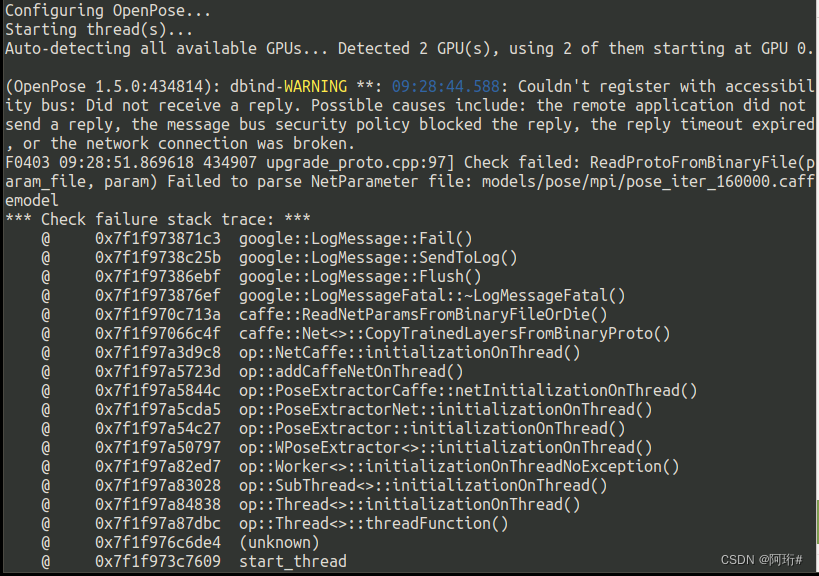
参考ubuntu18编译安装opencv3.4.3, caffe和openpose, 踩坑记录._王二小、的博客-CSDN博客
手动下载模型后放到指定位置
又开始报1vs.0的错误
重新下载caffe GitHub - BVLC/caffe: Caffe: a fast open framework for deep learning.
更改Makefile文件:
![]()
![]()
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial
PYTHON_LIBRARIES ?= boost_python3 python3.6m复制Makefile.config.example,并重命名为Makefile.config,更改
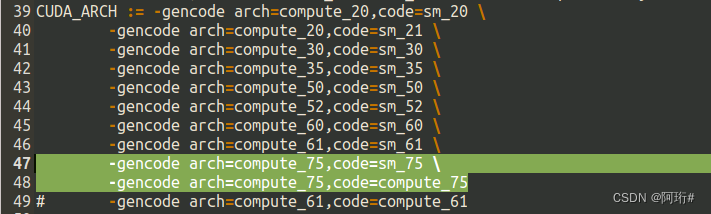
仍然报错1vs.0
有人说是cuda和cudnn和gpu版本不匹配,查询版本:cudnn8.1.0,cuda11.1
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

nvcc -V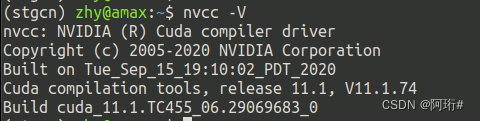
注:nvidia-smi查询到的是显卡支持的最高cuda版本

更新,问题解决了,是服务器显存爆了,显存没问题的话可以运行openpose的测试代码
3按照README.MD进行
3.1 Installation
cd st-gcn
cd torchlight
python setup.py install
cd ..3.2 Get pretrained models
之前已完成
3.3 运行离线Demo失败
这里参考了复现STGCN CPU版 (ubuntu16.04+pytorch0.4.0+openpose+caffe)_stgcn复现_普通网友的博客-CSDN博客
修改processor下的demo.realtime.py
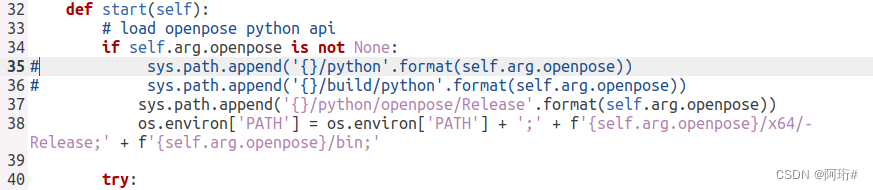
sys.path.append('{}/python/openpose/Release'.format(self.arg.openpose))
os.environ['PATH'] = os.environ['PATH'] + ';' + f'{self.arg.openpose}/x64/Release;' + f'{self.arg.openpose}/bin;'
运行新版demo
python3 main.py demo --openpose '/home/zhy/openpose/build' --video '/home/extend/zhy/code/st-gcn/resource/media/skateboarding.mp4'旧版
python3 main.py demo_old --video /home/extend/zhy/code/st-gcn/resource/media/ta_chi.mp4 --openpose /home/zhy/openpose/build运行新版时报错,原因是刚刚改代码的时候tab和空格混用了,全部改成空格就行
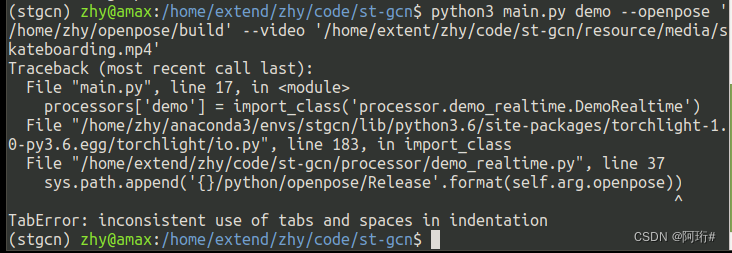
新错误

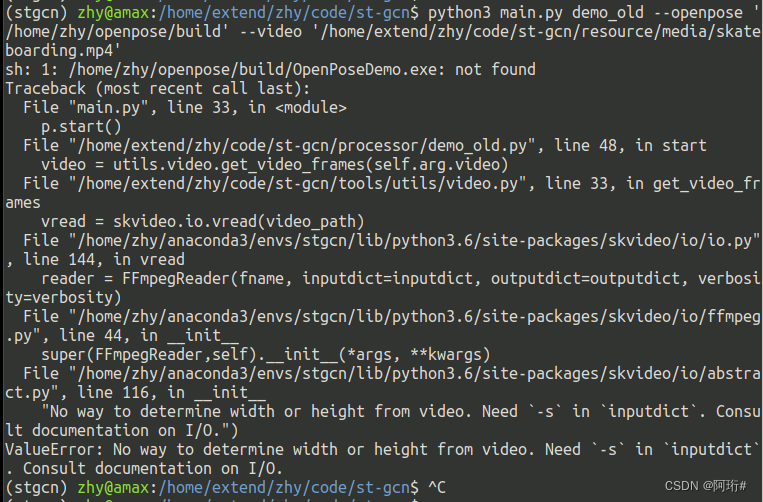
试试运行旧版demo
改processor\demo_old.py
openpose = '{}/OpenPoseDemo.exe'.format(self.arg.openpose)

运行后报错,没有解决,因此无法运行demo文件
3.4 数据预处理
使用以下命令处理ntu数据集,分别是xsub的train和val 还有xview的train和val,最后如果没有做其他更改的话,应该是在st-gcn目录下新建一个data包,保存到data/NTU-RGB-D/nturgb+d_skeletons.
python tools/ntu_gendata.py --data_path /home/extend/zhy/nturgb+d_skeletons等待处理结束:


kinetics如下
python tools/kinetics_gendata.py --data_path /home/extend/zhy/kinetics-skeleton
3.5 Testing Pretrained Models
3.5.1 kinetics-skeleton
python main.py recognition -c config/st_gcn/kinetics-skeleton/test.yaml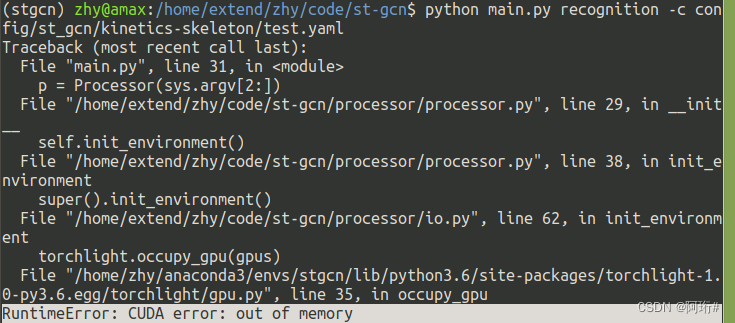
改batch_size再试一次,
python main.py recognition -c config/st_gcn/kinetics-skeleton/test.yaml --test_batch_size 8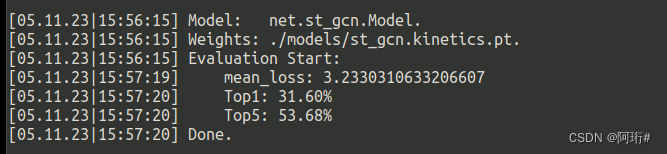
3.5.2 cross-view NTU RGB+D
python main.py recognition -c config/st_gcn/ntu-xview/test.yaml --test_batch_size 8等待结束
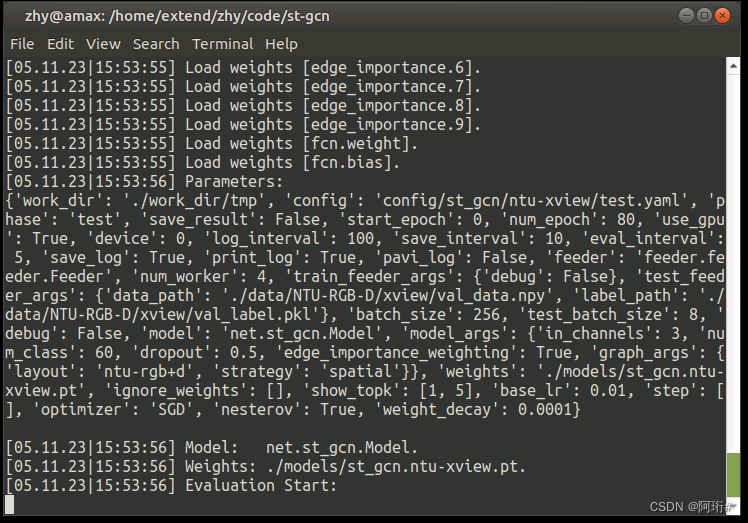
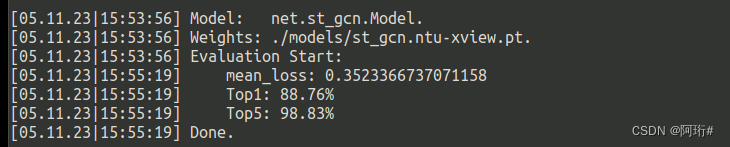
3.5.3 cross-subject NTU RGB+D
python main.py recognition -c config/st_gcn/ntu-xsub/test.yaml --test_batch_size 8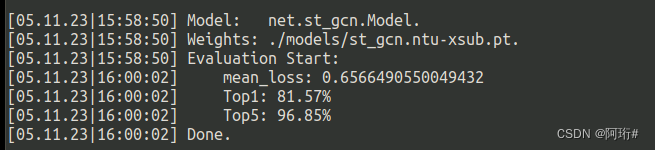
3.6 训练
3.6.1 cross-view NTU RGB+D
以ntu-xview为例进行训练和测试
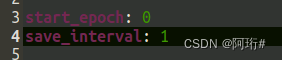
先在config/ntu-xview/train.yaml添加如下,并将batchsize改成8
start_epoch = 0 //这里填写上次训练中断时的epoch,如果上次训练了5个epoch(0,1,2,3,4),那么再次训练的时候填5即可
save_interval = 1 //源码是时10个epoch保存一次模型参数weights,我设置为1
weights = model_path //这里填写最近一个epoch保存的model_weights.pt文件的路径,如果不加上这个参数,则默认训练一个新的模型

训练代码
python main.py recognition -c config/st_gcn/ntu-xview/train.yaml报错,=改成:再运行
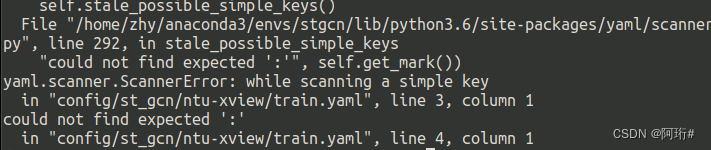
报错
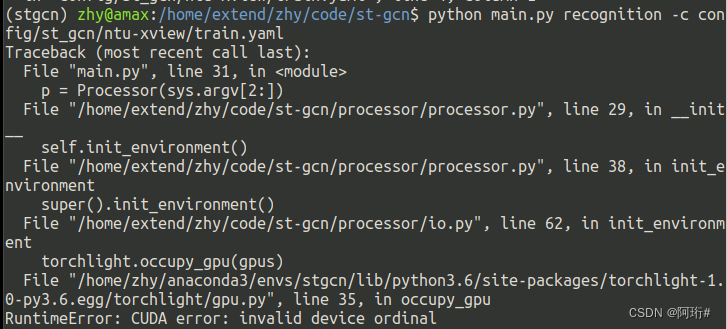
改train.yaml的GPU数量为1

成功开始训练
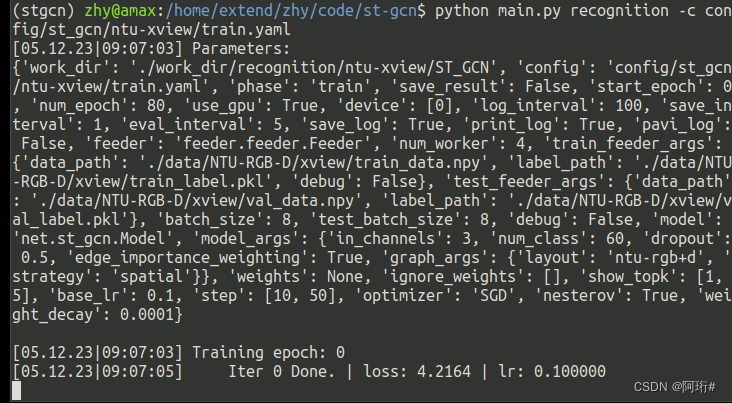
参考win10 ST-GCN复现_mizit的博客-CSDN博客
如果中途暂停可以按照上面的,在train.yaml中更改start_epoch和weights
如下,注意weights要提供绝对路径

就会接着迭代了
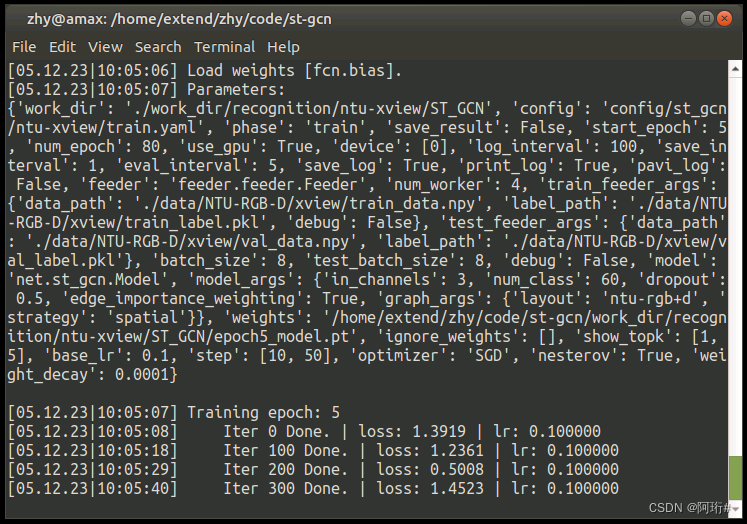
其它问题:试了双显卡训练,报错net/stgcn.py某一行代码的期望输入维度是256,但只提供了3,这个问题没有解决,估计是在这条命令出错了
RuntimeError: Given groups=1, weight of size [60, 256, 1, 1], expected input[8, 3, 1, 1] to have 256 channels, but got 3 channels instead

最后是用单卡,batchsize=56跑的
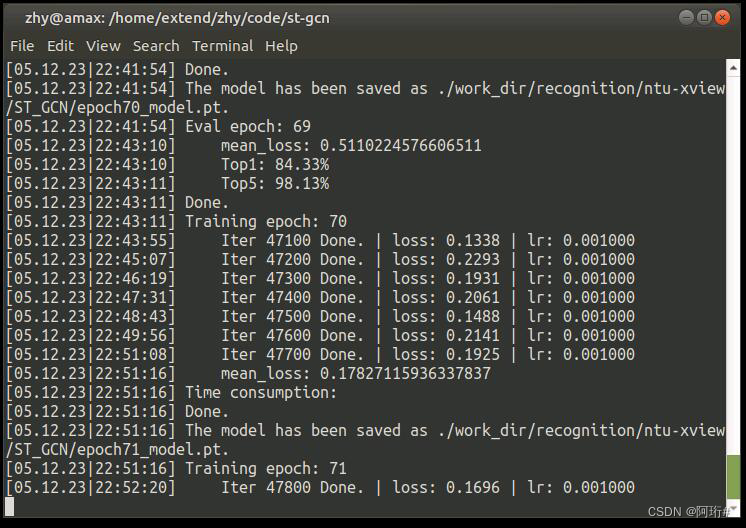
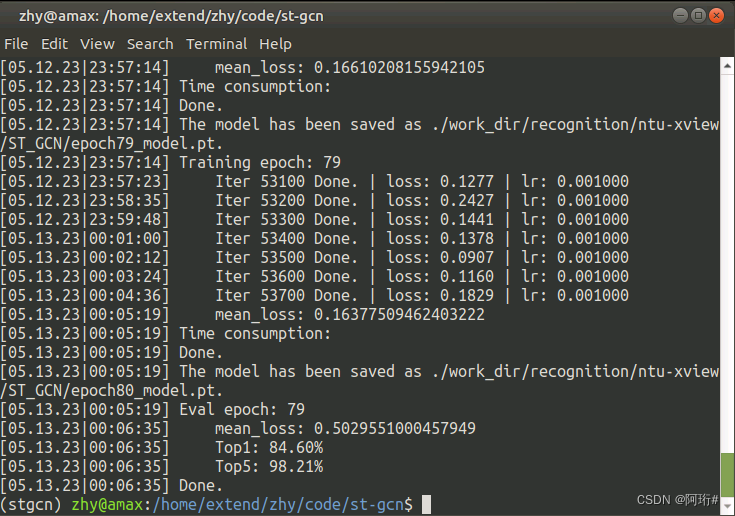
如图,ntu-xview的训练结果是84.6
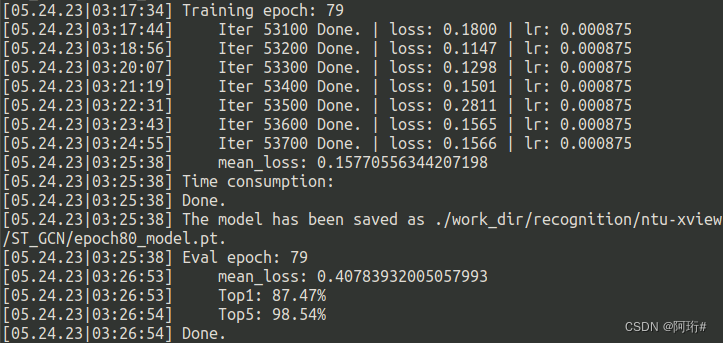
batchsize设为56,尝试等比缩小学习率至0.0875,重新测试

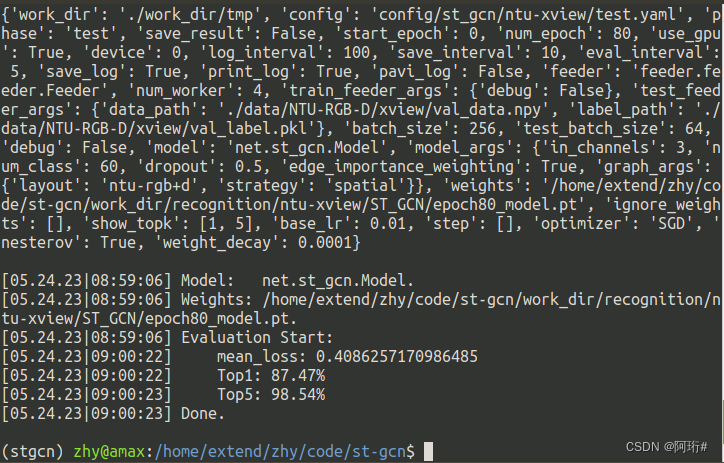
结果87.47,用这次的模型去测试集跑
3.6.2 cross-subject NTU RGB+D
3.6.3 kinetics-skeleton
这两个数据集的测试方法和ntu-xview步骤相同,将训练时的数据集名字改了就可以,因此不做测试了。
4 结果
4.1 cross-view NTU RGB+D
测试代码
python main.py recognition -c config/st_gcn/ntu-xview/test.yaml --weights /home/extend/zhy/code/st-gcn/work_dir/recognition/ntu-xview/ST_GCN/epoch80_model.pt结果:
————————————————————(完结)——————————————————

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









