







接上一篇
P17-P18
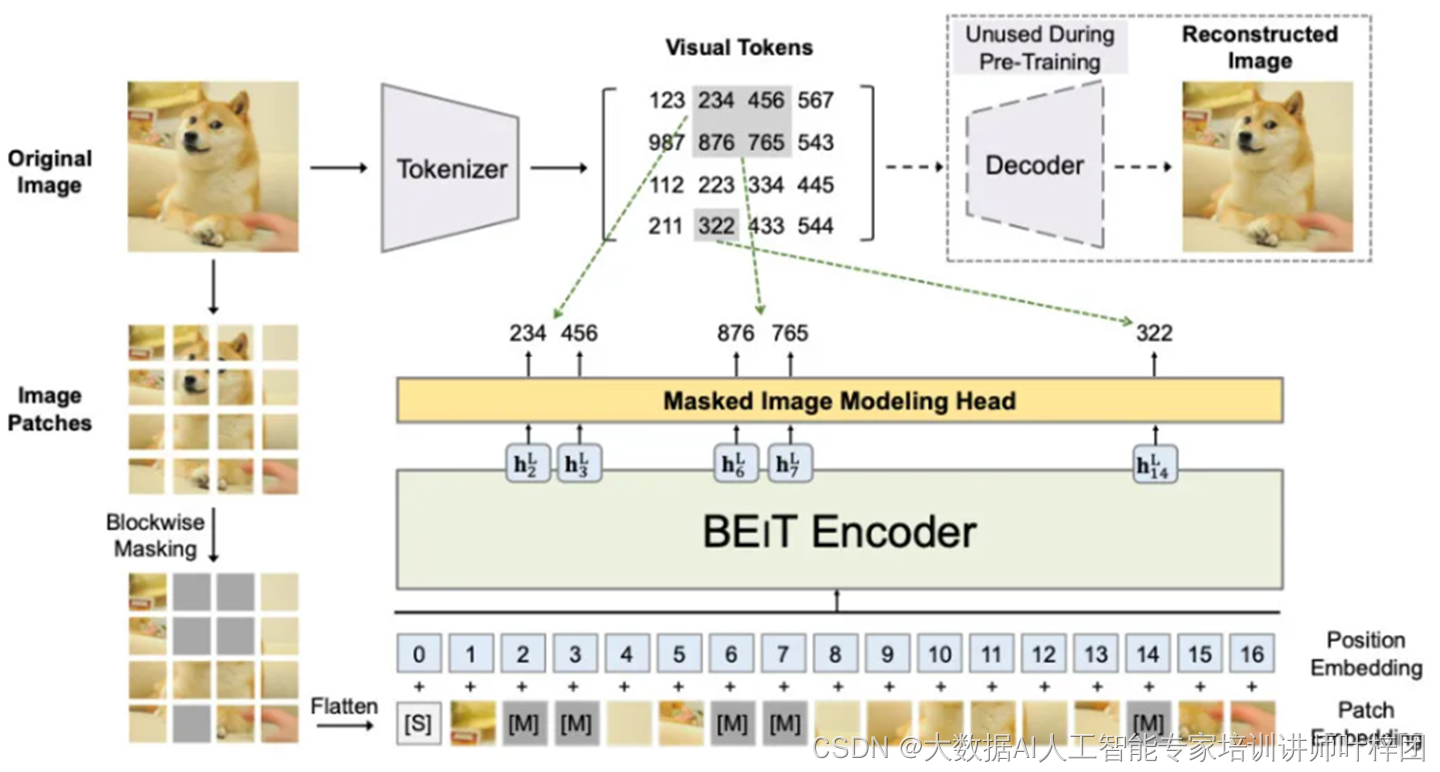
BEiT
n
让
BEIT
看很多的图片,随机遮住一些
patches
,让
BEIT
模型预测遮住的
patches
是什么
n
不断计算预测的
patches
与真实的
patches
之间的差异,利用它作为
loss
进行反向传播更新参数,来达到
Self-Supervised Learning
的效果。
视觉和语言用的masked autoencoder区别
n
架构差异:
CNN
天然适合图像领域,而应用
Transformer
却显得不那么自然,不过这个问题已经被
ViT
解决了。
n
信息密度差异:人类的语言信息密集、博大精深,而图像不一样,它就那么多信息。所以预测的时候,预测
patch
要比预测词语容易很多,只需要对周边的
patch
稍微有些信息就够了。所以我们可以放心大胆地
mask
。
n
自编码器的解码器(将潜在表征映射回输入)在文本和图像重建任务中起着不同的作用。在
CV
任务中,解码器重建的是像素,因此其输出的语义水平低于一般的识别任务。
未完,下一篇继续……
















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











