






 本文介绍了如何利用OpenAI的GPT-3.5Turbo模型从电商产品标题中提取实体和关系,构建知识图谱,以实现从非结构化数据中提取有价值信息,支持决策制定和模型微调。
本文介绍了如何利用OpenAI的GPT-3.5Turbo模型从电商产品标题中提取实体和关系,构建知识图谱,以实现从非结构化数据中提取有价值信息,支持决策制定和模型微调。
在昨天的文章《一文搞定检索增强生成(RAG)的理解和LangChain实现(附详细代码)》中,我们掌握了如何利用检索增强生成 (RAG) 这一技术,让大语言模型(LLM) 能够访问最新、私有的特定领域知识(比如企业自己的知识库),以便在文本生成和问答任务中能表现出更卓越的性能。
今天,我们将进一步探索如何将LLM转变成一个更加强大的信息提取工具,它不仅能够处理复杂的非结构化原始文本,还能将这些文本转化为结构化且易于查询的事实。在回顾一些关键概念之后,我们将重点介绍如何使用 OpenAI 的 GPT-3.5 Turbo 从原始文本数据(电商产品标题)中构建知识图谱。
毕竟大多数公司的数据中都有大量未能有效利用的非结构化数据,创建知识图谱能够最大程度的从这些数据中提取有价值的信息,并使用这些信息做出更明智的决策。当然,除了直接应用之外,我们也可以利用这个思路来构建结构化的大模型微调数据集。
小百科:什么是知识图谱?
知识图谱是一种语义网络,它不仅表达和相互连接现实世界中的实体,如人物、组织、物体、事件和概念,还描述这些实体的具体属性及其属性值。这些实体通过以下两种形式的三元组相互关联,构成了知识图谱的基础:
head → relation → tail
本文将使用 OpenAI 的 gpt-3.5-turbo 模型,针对kaggle上的亚马逊产品数据集中的标题数据,创建一个知识图谱。
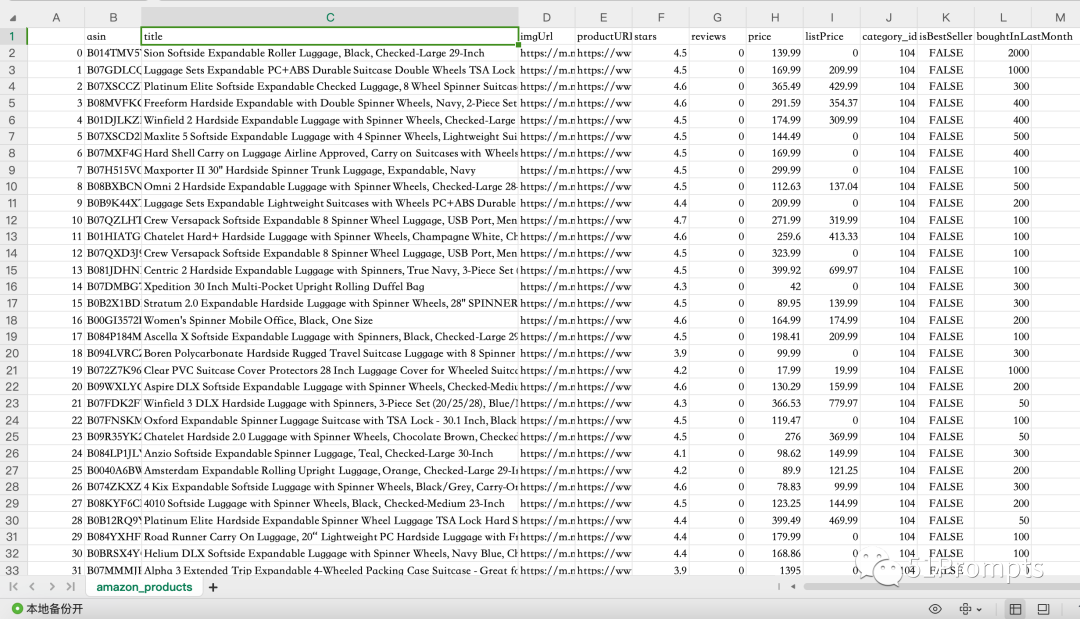
图片
可以看到,数据集包含若干产品的相关字段,但这次我们只用到里面的title字段,如果你手头有其他数据集,包含更完善的信息,也可以同时使用多个字段(如果你打算使用多个字段,那就直接把多个字段拼接为一个新的字段"text",比如标题_描述_规格),然后我们将使用 ChatGPT 从中提取构建知识图谱所需要的实体和关系信息。
1. Python依赖包安装并读取数据
首先,我们要在终端执行下面命令,安装依赖的Python包,或者在IDE中安装也可以。
接下来,我们使用 ChatGPT 来从产品数据中挖掘出实体和它们之间的关系,并把这些信息以 JSON 格式的对象数组返回。
为了引导 ChatGPT 正确进行实体关系提取,我们会提供一系列特定的实体类型和关系类型。这些类型将与 Schema.org 中的对应实体和关系相映射。映射时,我们用的键是提供给 ChatGPT 的实体和关系类型,而值则是 Schema.org 中相关对象和属性的 URL。
relation键,“head”和“tail”之间的关系类型;
5. 图谱构建
现在,我们为数据集中的每个产品调用 extract_information 函数,并创建一个包含所有提取的三元组的列表,这些三元组将代表我们的知识图谱。在本案例中,我们将仅使用 100 个产品的标题数据生成一个知识图谱。
得到的数据结果如下图所示——
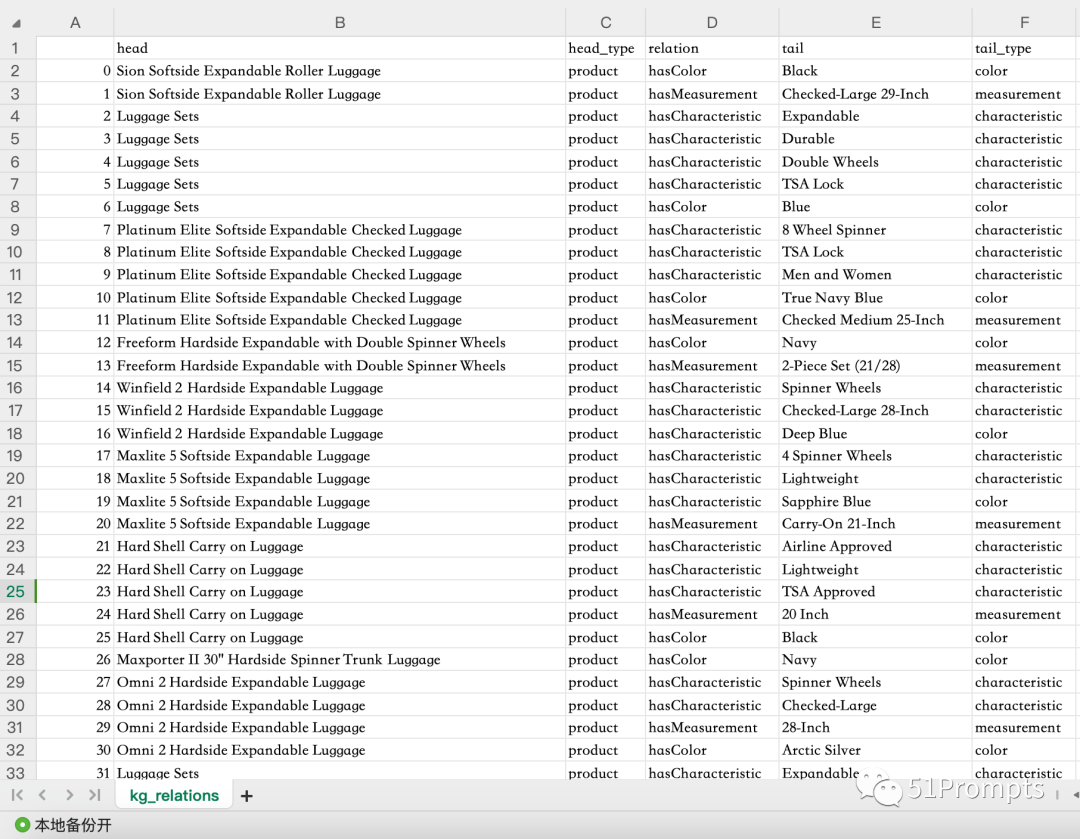
图片
6. 实体解析
实体解析的作用是将数据集中的实体与现实世界中的概念相匹配,会使用 NLP 技术,对数据集中的头部和尾部实体执行基本的实体解析。
在本案例中,我们将使用“all-MiniLM-L6-v2”这个句子转换器,为每个头部创建embedding,并计算头部实体之间的余弦相似度,并检查相似度是否大于 0.95,超过阈值的实体视为相同的实体,并将它们的文本值规范化为相等。同样的道理也适用于尾部实体。举个例子,如果我们有两个实体,一个值为“微软”,另一个值为“微软公司”,那么这两个实体将合并为一个。
我们按以下方式加载并使用embeddeding模型来计算第一个和第二个头部实体之间的相似度。
最终,我们还可以使用 networkx 这个Python 库,来实现图谱数据的可视化。
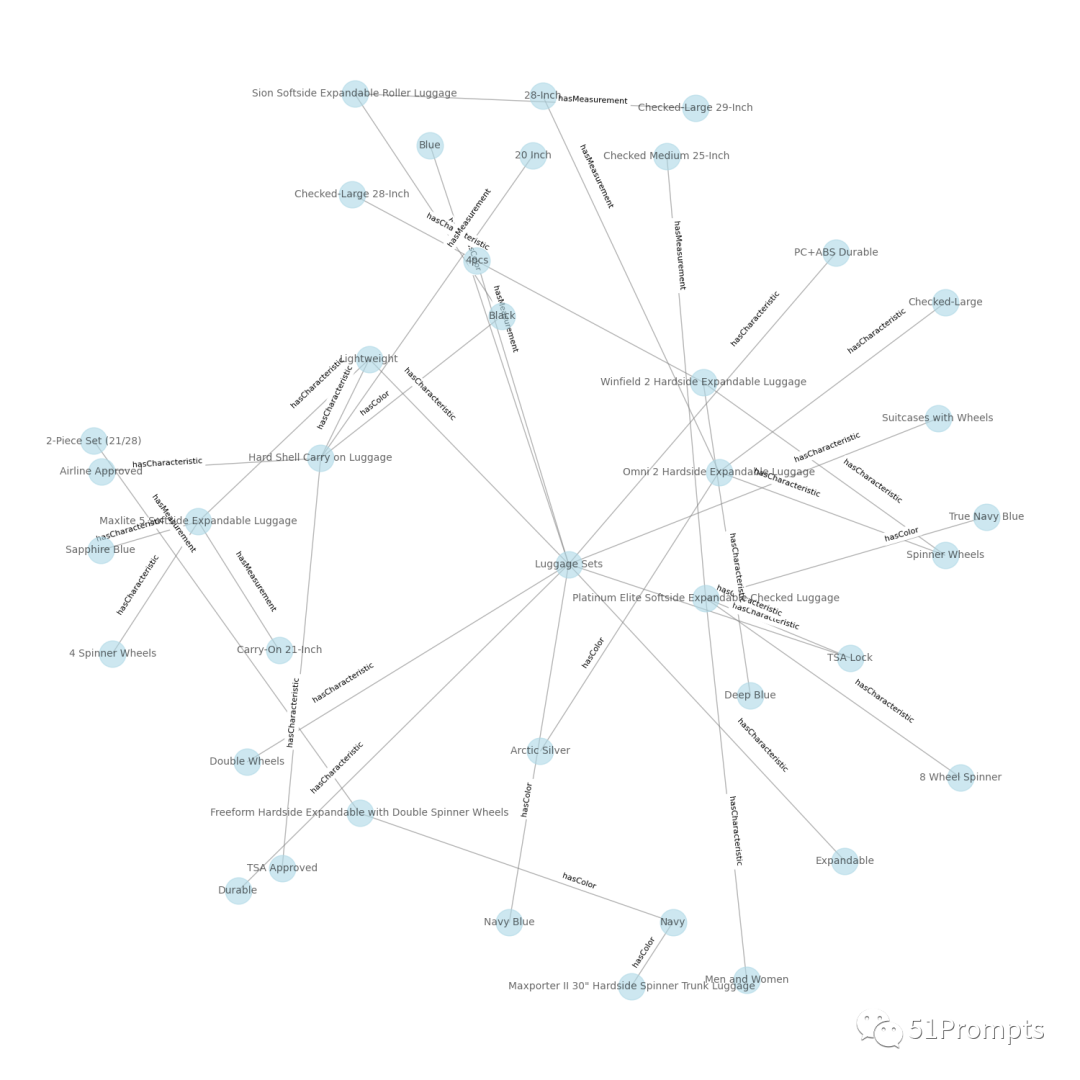
图片
到目前为止,我们已经完成了使用 LLM 从原始文本数据中提取实体和关系的三元组,并自动构建知识图谱,甚至生成可视化图表。

















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









