






前言
随着以ChatGPT为代表的智能问答机器人的横空出世,大模型在各个行业和业务场景下的应用需求也随即爆发。大模型成为企业数据体系中不可或缺的一部分,为企业数字化、智能化的发展提供良好的机遇和动力。本文从以下四个方面介绍大模型在数据领域应用的思路:
1. 利用Embedding优化语义检索
对于搜索问题,我们可以利用GPT模型做些什么优化呢?对于自研搜索功能,往往是基于ElasticSearch这个开源技术来实现,而ES底层的搜索原理则是先分词,然后再进行倒排索引。

图片
试想一下场景,我们在使用数据地图或指标查询时,指标预存信息为“欠款金额”,而我们搜索的指标为“未还款金额”,虽然语义上很接近,但是ES的分词词典中并没有“未还款”,匹配不上,会导致我们搜索不到指标信息。为了提升搜索效果,通常会给ES配置同义词表,把预存的指标信息和开发、业务人员常使用的指标名称做同义词配置,提高查询效果。
而基于Embedding进行语义检索的过程大致如下:

图片
通常我们遇到以下场景会考虑搭建本地知识库:

图片
处理的过程包括:
1. 先将原始文档中的文本内容全部提取出来。然后根据语义切块,切成多个chunk,可以理解为可以完整表达一段意思的文本段落。在这个过程中还可以额外做一些元数据抽取,敏感信息检测等行为。
2. 将这些Chunk都丢给embedding模型,来求取这些chunk的embedding。
3. 将embedding和原始chunk一起存入到向量数据库中。
问题提炼:这个部分是可选的,之所以存在是因为有些问题是需要依赖于上下文的。因为用户问的新问题可能没办法让LLM理解这个用户的意图。
向量检索:独立问题求取embedding这个功能会在text2vec模型中进行。在获得embedding之后就可以通过这个embedding来搜索已经事先存储在向量数据库中的数据。
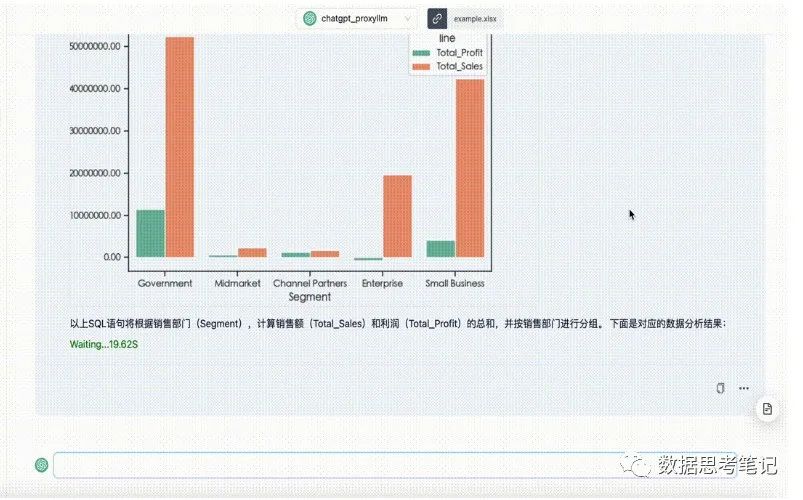
大模型可以根据自然语言输入快速生成SQL代码片段,并通过可视化的方式展示结果,从而协助数据人员的日常工作。这减少了编写复杂查询所花费的时间,因此可以投入更多时间来理解业务和分析查询结果,以此从数据结果中获取决策支持。
可以通过大模型创建一个 SQL 查询来获取一组特定的数据,例如:“显示 2022 年每月的平均收入。”
大模型可以将其转换为 SQL 查询,如下:
集成可视化功能后的效果图如下:
图片
4. 数据集探索性数据分析EDA


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









