






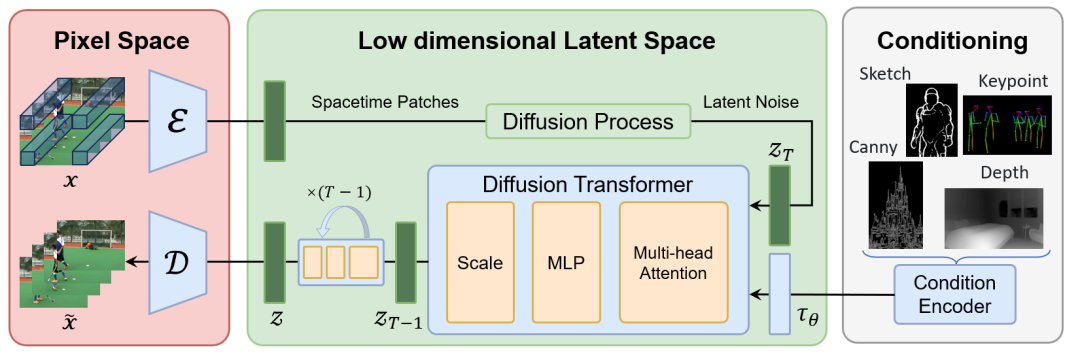
国内一个由北大和Rabbitpre AI发起的Open-Sora Plan的项目,旨在重现 OpenAI 的视频生成模型Sora。技术框架,如下所示:
Video VQ-VAE,这将视频压缩成潜在的时间和空间维度。
Denoising Diffusion Transformer。
Condition Encoder(条件编码器),这支持多个条件输入。
支持可变长宽比、可变分辨率和可变时长,如下所示:
可变长宽比,实现了并行批量训练的动态掩蔽策略,同时参考FIT保持灵活的纵横比。具体来说,调整高分辨率视频的大小,使其最长边为 256 像素,保持宽高比,然后在右侧和底部填充零,以实现一致的 256x256 分辨率。这有助于 videovae 批量编码视频,并方便扩散模型使用自己的注意力掩模对批量潜伏进行去噪。
可变分辨率,在推理过程中,使用位置插值来启用可变分辨率采样,尽管是在固定的 256x256 分辨率上进行训练。将可变分辨率噪声潜伏的位置索引从 [0, seq_length-1] 缩小到 [0, 255],以使它们与预训练范围对齐。这种调整使得基于注意力的扩散模型能够处理更高分辨率的序列。
可变时长,在VideoGPT中使用视频 VQ-VAE将视频压缩为潜在视频,从而实现多持续时间生成。将空间位置插值扩展到时空版本,以处理可变持续时间的视频。
图片
图片

图片
参考文献:
[1] 项目地址:https://pku-yuangroup.github.io/Open-Sora-Plan/
[2] 代码:https://github.com/PKU-YuanGroup/Open-Sora-Plan















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









