






APAUNet: Axis Projection Attention UNet for Small Target in 3D Medical Segmentation
Yuncheng Jiang,Zixun Zhang,Shixi Qin,Yao Guo,Zhen Li,Shuguang Cui
ACCV 2022
Abstract
在3D医学影像分割中,小目标分割对于诊断至关重要,但仍面临挑战。在本文中,我们提出了名为APAUNet的Axis Projection Attention UNet,用于3D医学影像分割,尤其是小目标。考虑到3D特征空间中背景的比例很大,我们引入了一种投影策略,将3D特征投影到三个正交的2D平面中,以捕捉来自不同视图的上下文注意力。通过这种方式,我们可以过滤掉冗余的特征信息,减少3D扫描中小病灶的关键信息丢失。然后,我们利用维度混合策略将3D特征与来自不同轴的注意力融合在一起,并通过加权求和将它们合并,以自适应地学习不同视角的重要性。最后,在APA解码器中,我们在2D投影过程中连接高分辨率和低分辨率特征,从而获得更加精确的多尺度信息,这对于小病灶分割至关重要。在两个公共数据集(BTCV和MSD)上的定量和定性实验结果表明,我们提出的APAUNet优于其他方法。具体来说,我们的APAUNet在BTCV上的平均dice得分为87.84,在MSD-Liver上为84.48,在MSD-Pancreas上为69.13,并且显著超过了之前在小目标上的SOTA方法。
要解决的问题
- 3D医学影像分割中,小目标分割仍面临挑战,已有的方法在性能和计算效率上都不优越
- 基于CNN的医学影像分割即使有下采样的操作,但还是缺乏学习全局上下文和远程空间依赖性的能力
- 基于硬注意力(hard attention)的方法通常需要大量的可训练参数并且难以收敛,对于3D医学分割来说效率太低
- 基于自注意力(self attention)的方法,没有考虑到小病灶和大器官变异的类别不平衡问题,方法还不够有效
Method

1. Axis Projection Attention (APA) Encoder and Decoder

3D特征被投影到三个正交的2D平面以提取2D空间注意力。然后将2D特征与3D特征聚合增强特征表示。

IE代表Internal Encoder块操作
在APA Decoder Block 中,输入是具有不同分辨率的两个特征,主要任务是提取和融合多分辨率特征以生成分割结果。解码器将两种不同分辨率的特征在三个2D平面上融合生成2D上下文注意力,然后将3D特征图与2D注意力融合以获得3D上下文特征。这样可以更好地保留小尺度前景信息,避免丢失关键特征。将三个3D上下文特征加权求和作为下一级的输入特征。
2. Internal Encoder and Decoder
参考了CoT,Contextual Transformer Networks for Visual Recognition
-
正交投影策略
将3D特征投影到笛卡尔坐标系的矢状面、轴向面、冠状面,以生成K、Q,而V保持3D形状。K Q的使用global average pooling(GAP)和global max pooling(GMP)生成
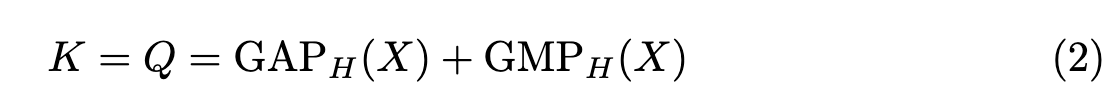

-
维度混合策略
正交投影之后,在K上用3x3的卷积来提取局部注意力,得到L。之后,将局部注意力L和Q连接起来,通过卷积进一步得到注意力矩阵G。
在得到2D的注意力矩阵G后,使用广播乘法与V进行计算得到混合注意力矩阵H,尺寸是CxHxWxD。

-
多分辨率融合解码
为了更好地从多分辨率特征中获取多尺度上下文信息,将上采样操作集成到注意力提取过程中。
Decoder与Encoder的不同之处在于,在Decoder中,输入是低分辨率特征和高分辨率特征,低分辨率使用反卷积上采样到高分辨率的尺寸,设定一般都是正好两倍,再与高分辨率特征cat起来,跟UNet的跳层连接操作很像。
-
损失函数
联合使用Dice损失和交叉熵损失

Experiment

总结
- 这篇文章提出了2D+3D的医学影像分割方案,可以借鉴的是论文提出的方案依据:
- 3D医学CT包含过多背景信息,阻碍了上下文注意力的学习,而2D+3D的混合策略,可以过滤冗余信息来提高性能
- 仅用2D注意力用于3D分割任务是次优的
- 池化操作或者说transformer的架构,比卷积更有效,尽管卷积的可学习参数比池化算子更灵活,但由于医学影像中背景信息的比例很大,即使卷积核很大,也很容易受到噪声的干扰,池化算子优在可以直接处理全局信息。通过结合avgpooling和maxpooling的互补性,可以获得更好的性能。
- 总结一下论文对提出的问题-医学影像的小目标分割的解决方案:
- 利用正交投影策略和维度混合策略
- 结合2D和3D,观察模型可以发现,attention的操作基本都是对2D特征进行的,原因在于2D特征的生成使用的是avgpooling和maxpooling结合的提取方法,有效过滤了3D特征中非常冗余的背景信息,再利用attention对过滤后的特征进行学习,使得学习到的特征更加准确有效。
- 多视角提取2D特征的方法也确实提高了2D特征的丰富性,作者的观点是3D结构中,不同视角包含的信息量是不同的,在不同投影轴上提取到的特征是不对称的,非对称的特征对模型的学习更有帮助。















 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









