前言
本范围根据官方视频整理制作,适合于TiDB 证书之PCTA v6版本的考试
各知识点均根据官方的视频内容总结而来,详情需参考以上课程。
结构图
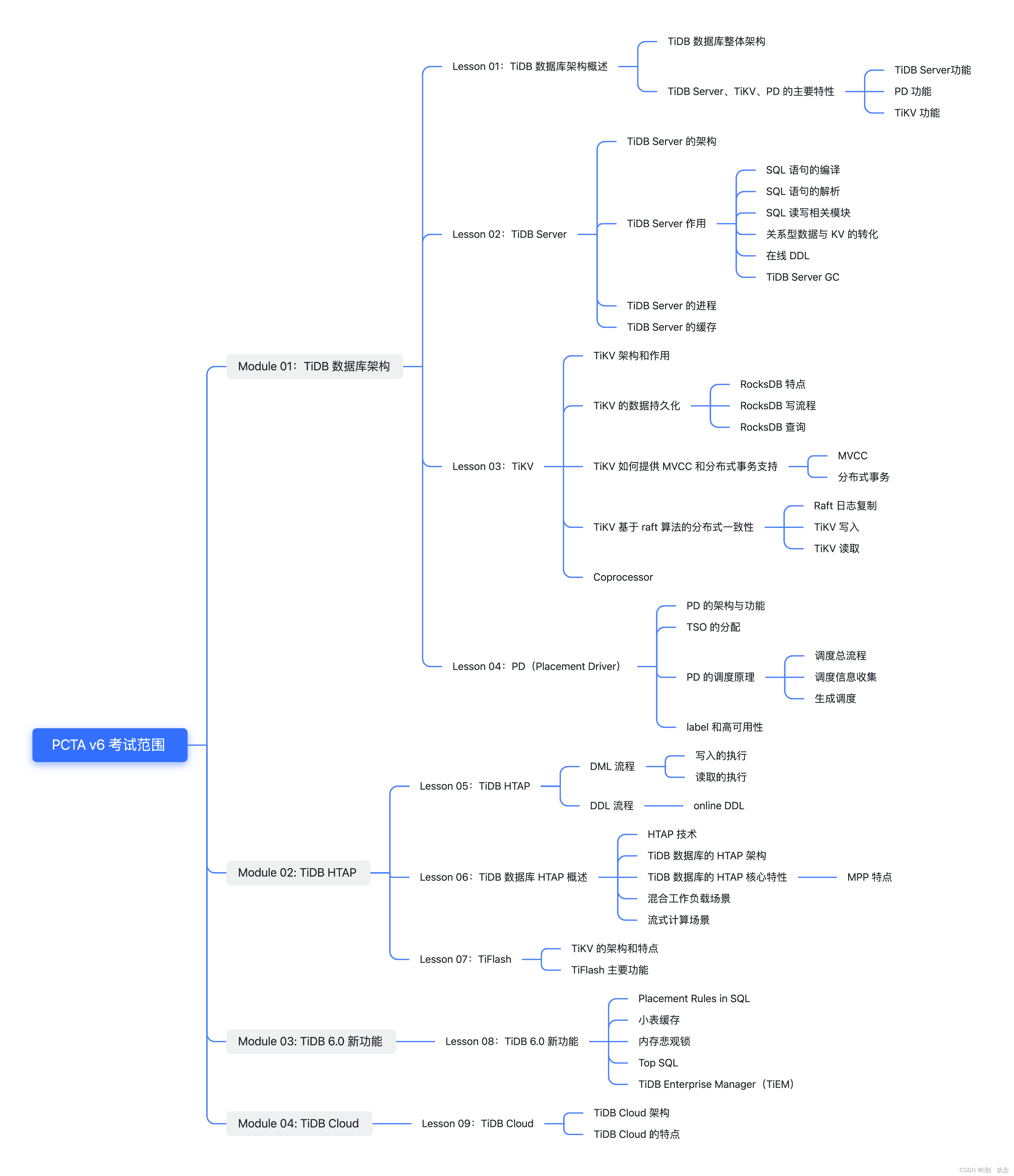
一、Module 01:TiDB数据库架构
Lesson 01:TiDB数据库架构概述
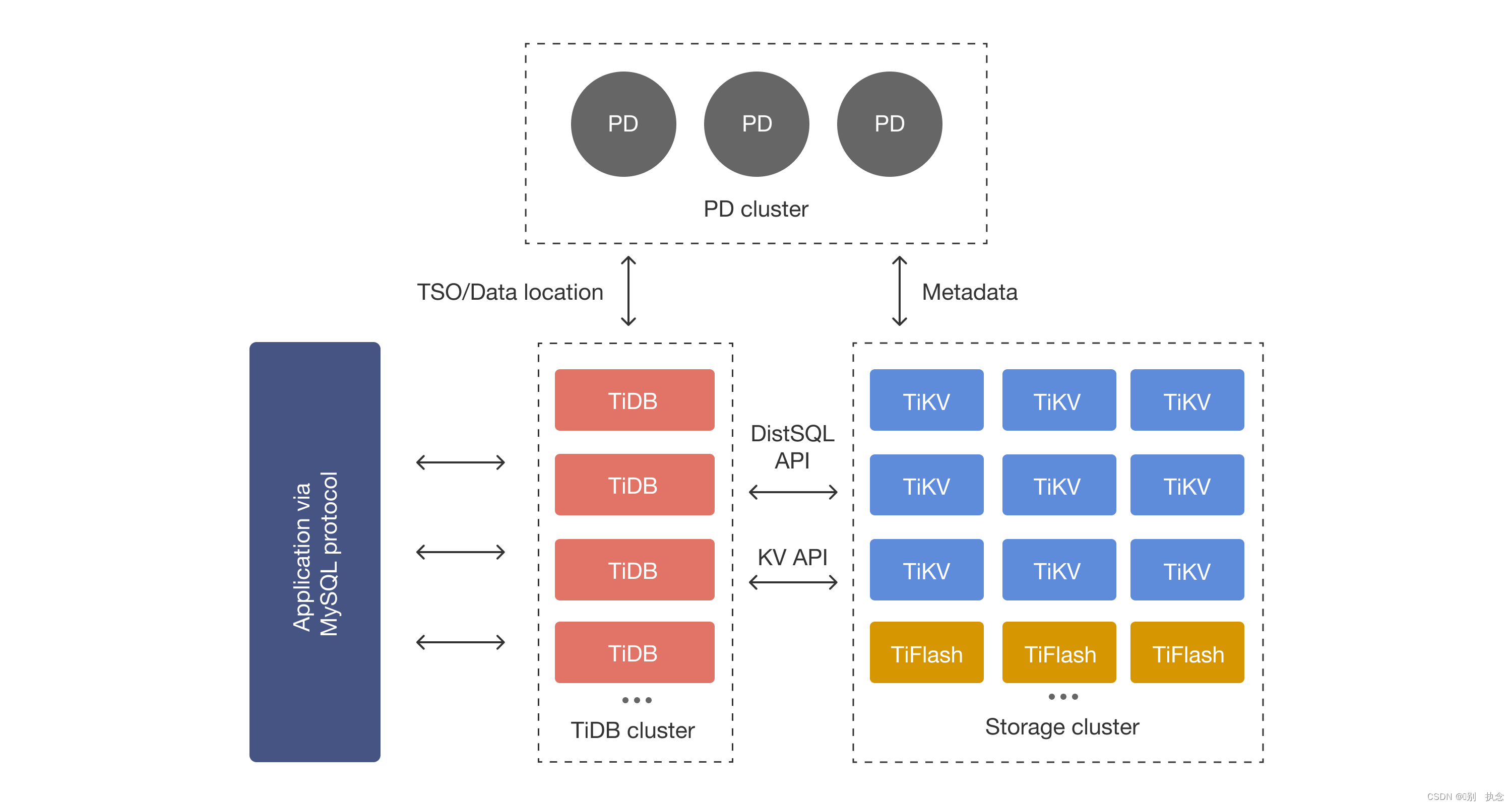
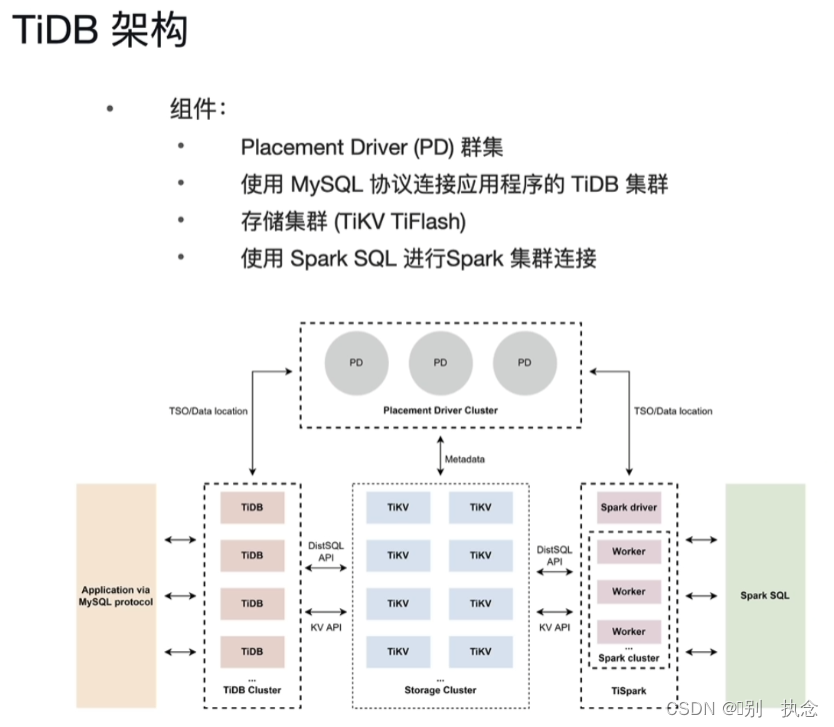
1.TiDB数据库整体架构
2.TiDB Server、TiKV、PD的主要特性
2.1 TiDB Server功能
TiDB Server
:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
2.2 PD功能
PD (Placement Driver) Server
:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
2.3 TiKV功能
TiKV Server
:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
TiFlash
:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
课堂测验
1.下列功能是由 TiKV 或 TiFlash 实现的为?( 选 2 项 )
A. 根据集群中 Region 的信息,发出调度指令
B. 对于 OLAP 和 OLTP 进行业务隔离
C. 将关系型数据转化为 KV 存储进行持久化
D. 将 KV 存储转化为关系型数据返回给客户端
E. 配合 TiDB Server 生成事务的唯一 ID
F. 副本的高可用和一致性
正确答案:
B. 对于 OLAP 和 OLTP 进行业务隔离、F. 副本的高可用和一致性
2.关于 TiKV 或 TiDB Server,下列说法
不正确的是?
A. 数据被持久化在 TiKV 的 RocksDB 引擎中
B. 对于老版本数据的回收(GC),是由 TiDB Server 在 TiKV 上完成的
C. 两阶段提交的锁信息被持久化到 TiDB Server 中
D. Region 可以在多个 TiKV 节点上进行调度,但是需要 PD 节点发出调度指令
正确答案:
C. 两阶段提交的锁信息被持久化到 TiDB Server 中
Lesson 02:TiDB Server
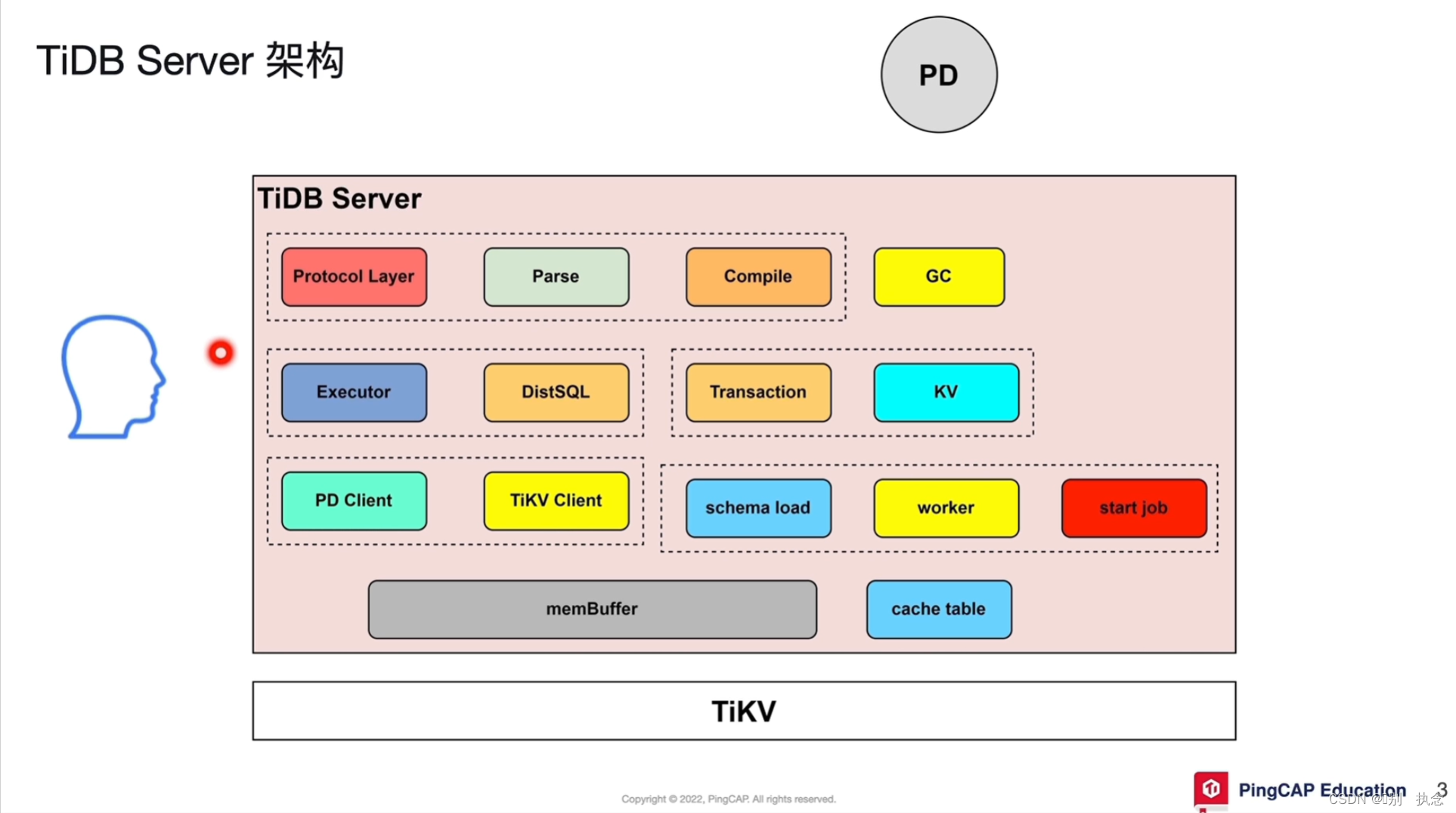
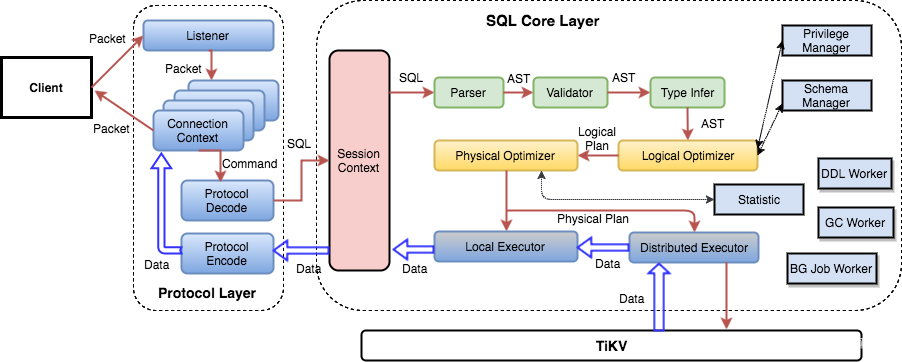
1.TiDB Server的架构
2.TiDB Server作用
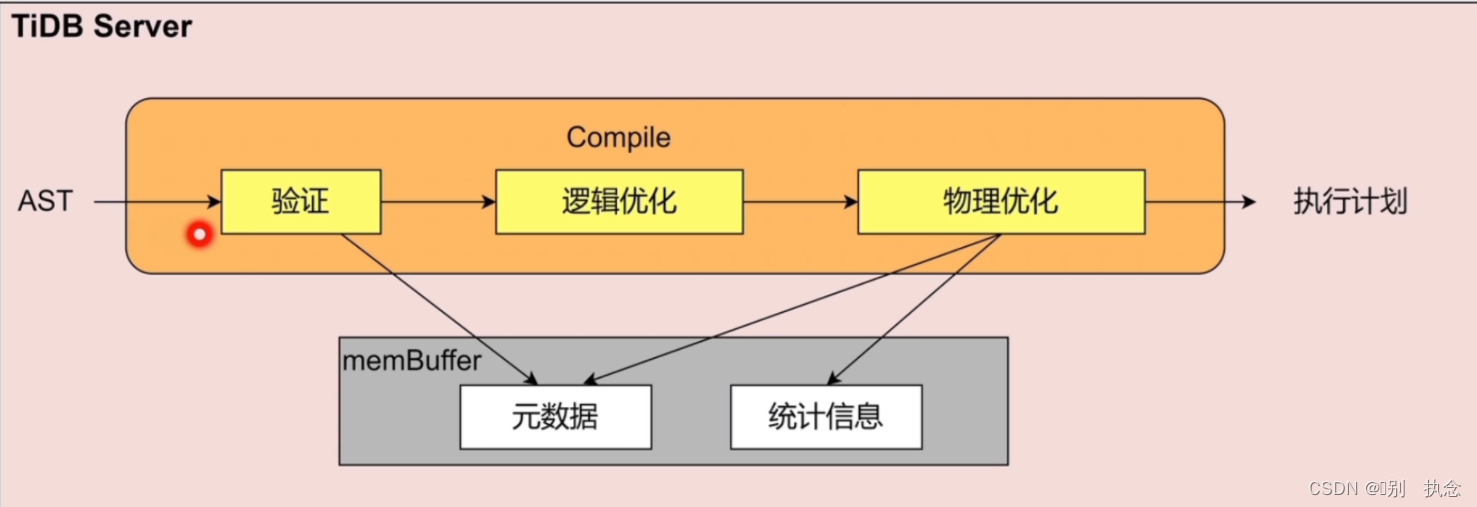
2.1 SQL语句的编译
TiDB Sever SQL语句编译Compile
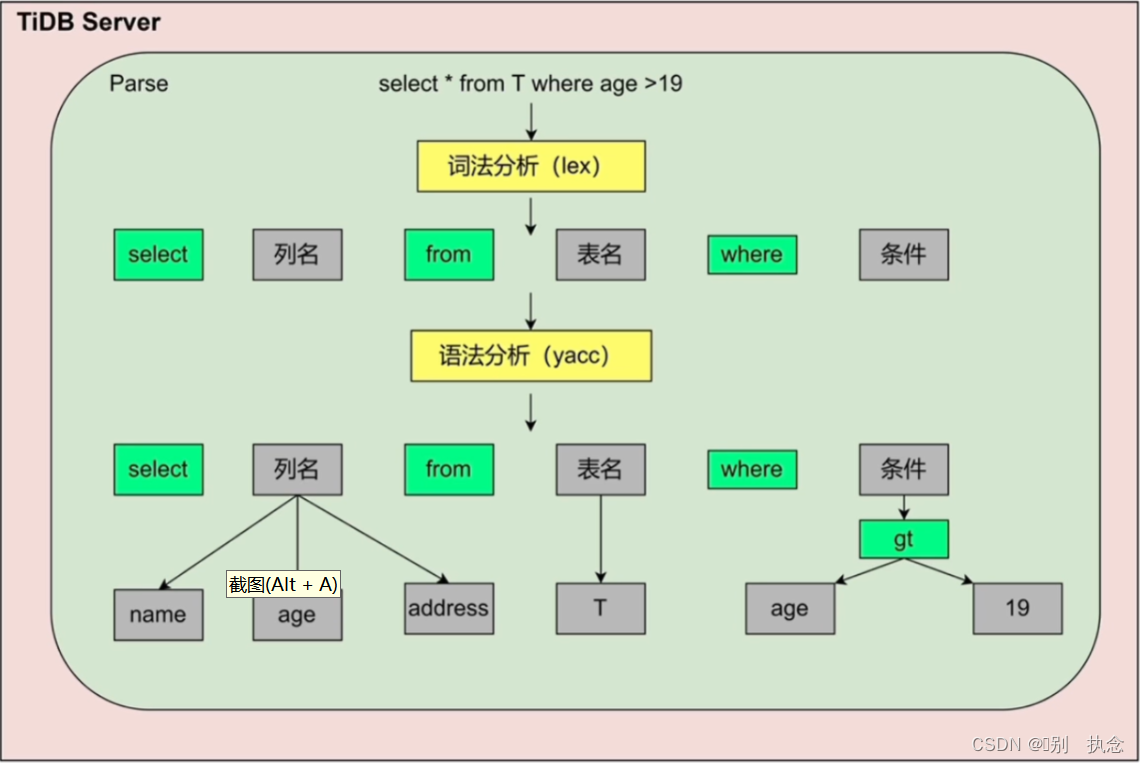
2.2 SQL语句的解析
TiDB Sever SQL语句解析Parse
2.3 SQL读写相关模块
SQL读写相关模块
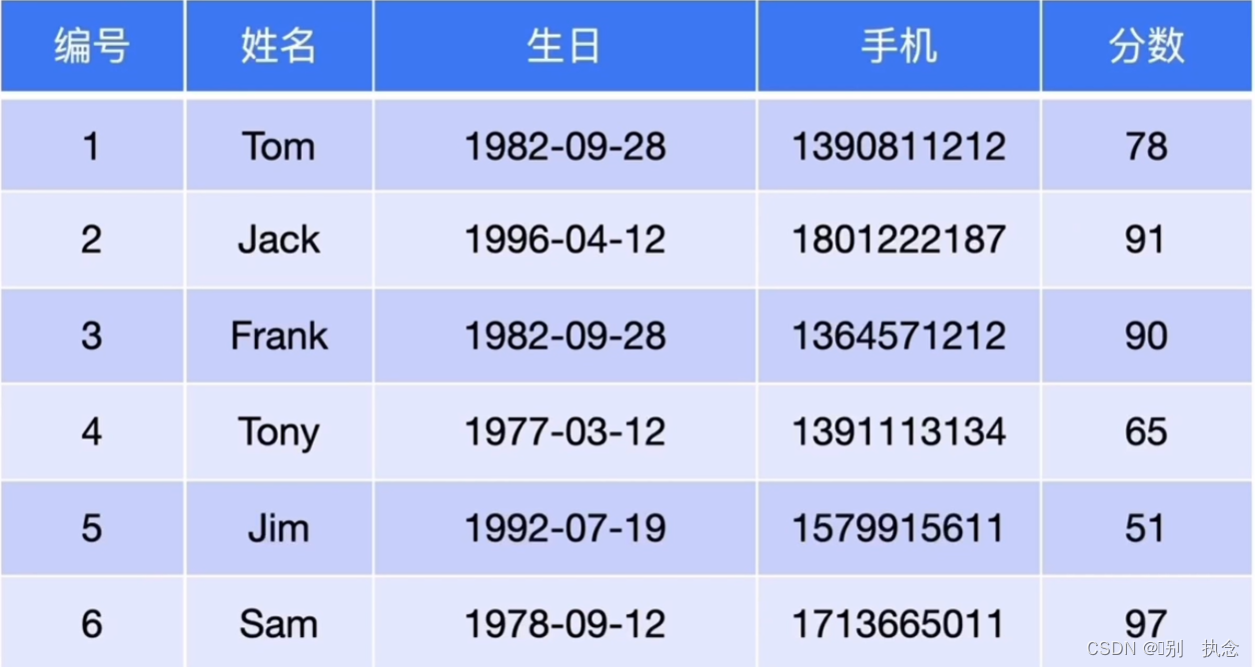
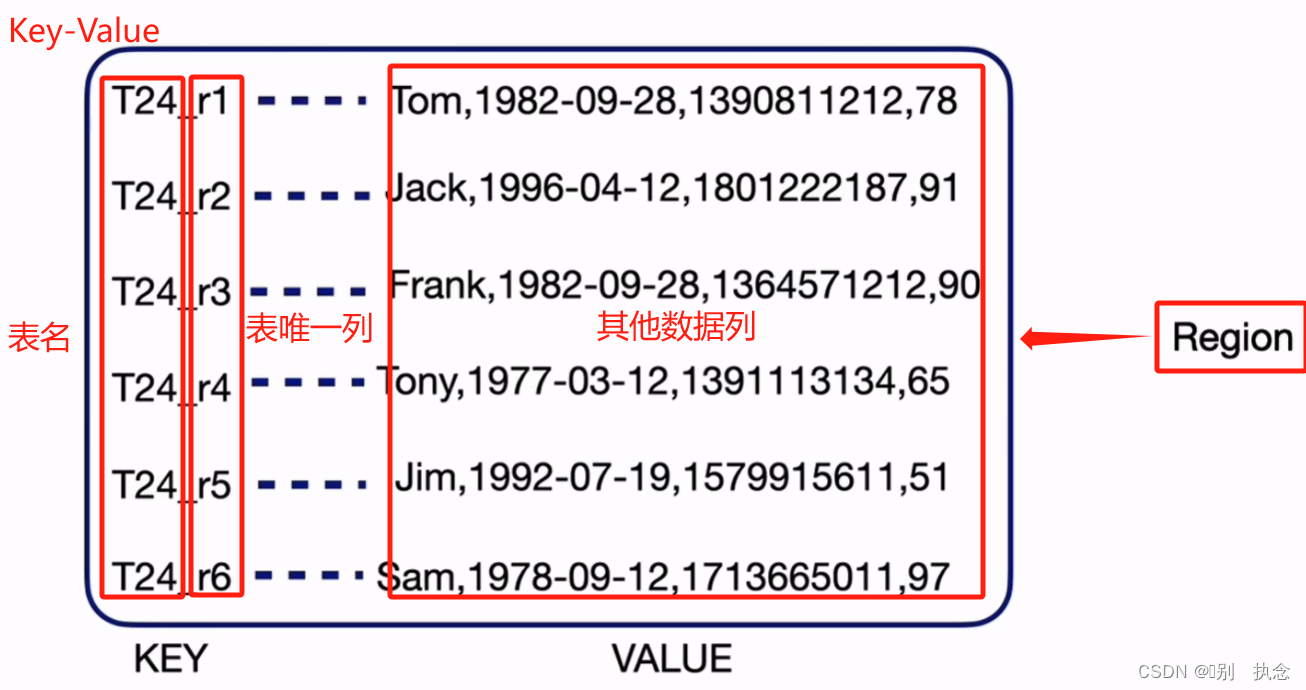
2.4 关系型数据与KV的转化
关系型数据与KV的转化
转化前,正常的关系型数据表列,此例编号为主键,示例为聚簇表
转化后,自动生成表名(表号)和键值对,确保唯一性
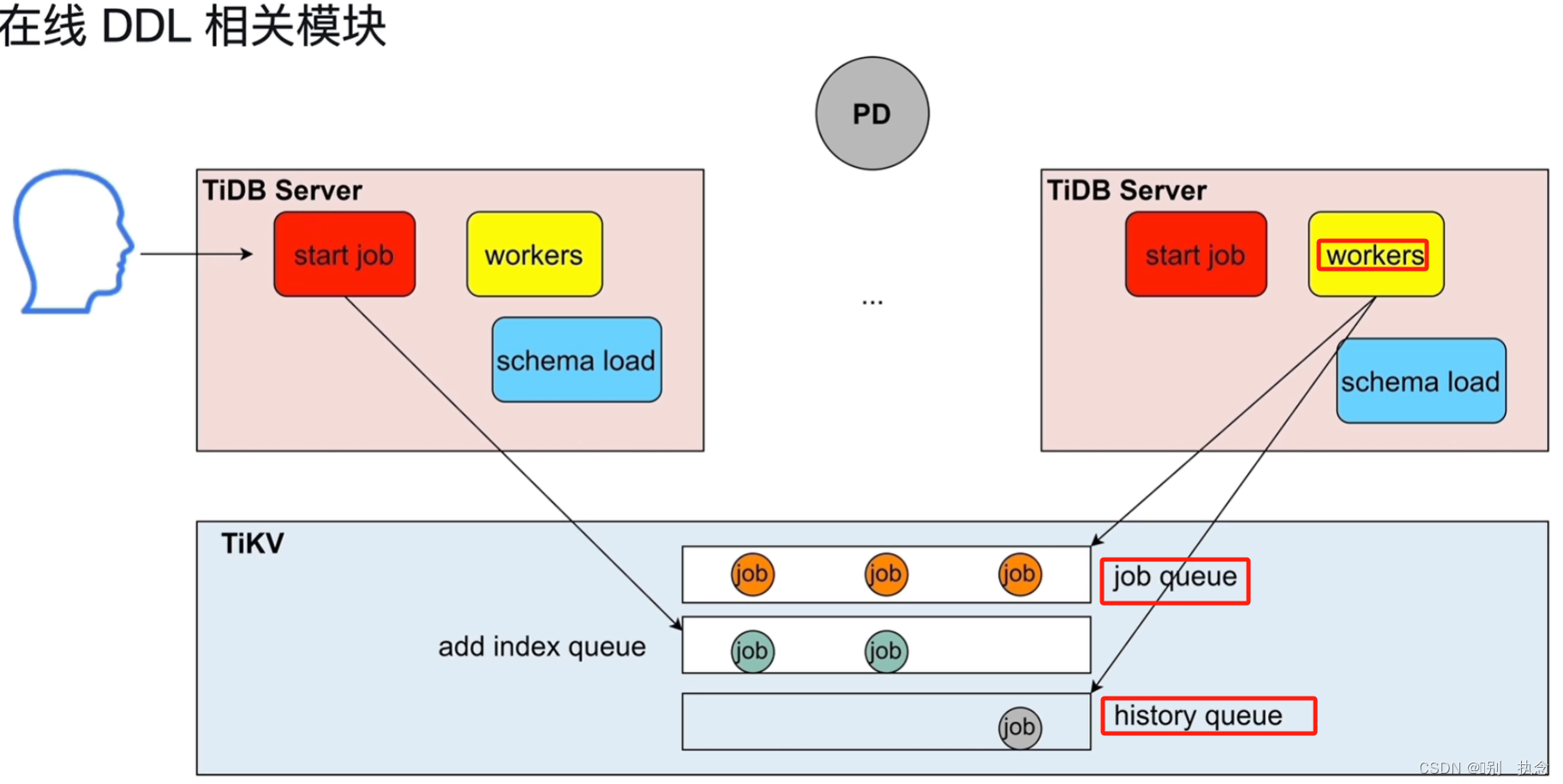
2.5 在线DDL
online DDL操作
同一时间,只能有一个TIDB的worker可以进行DDL操作
流程:DDL语句发送至TIDB server--start job接收DDL语句--放入job queue队列--TIDB server的OWNER节点取队列中的一个job执行--将执行完成的job放到history queue队列,重新读取下一个job
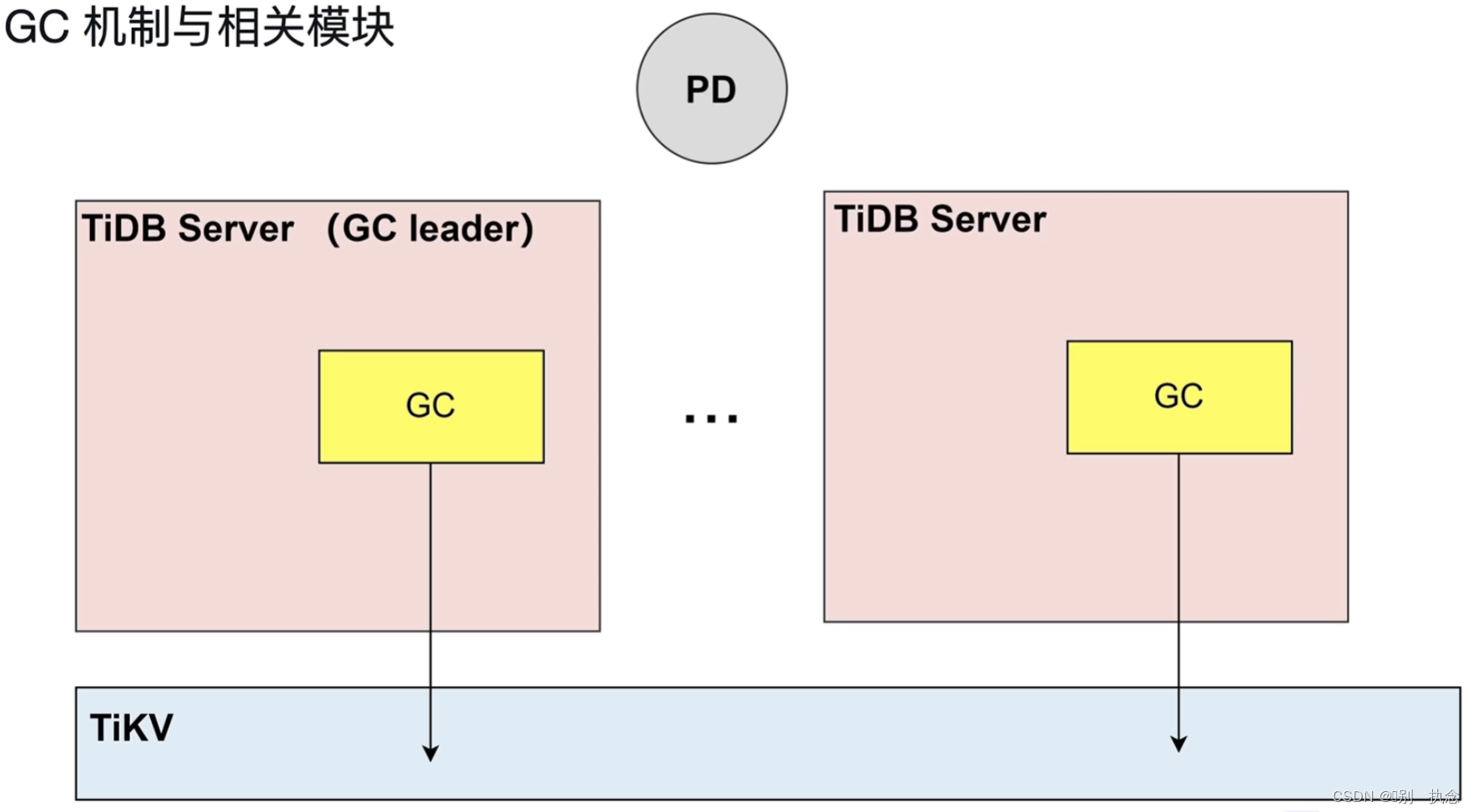
2.6 TiDB Server GC
TiDB server GC
根据safe point来清理数据,GC_LIFE_TIME默认十分钟
3.TiDB Server的进程
TiDB Server是SQL层,对外暴露MySQL协议的连接endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB层本身是无状态的,TiDB Server本身并不存储数据,只是解析 SQL,将实际的数据读取请求翻译成key-value操作转发给底层的存储节点 TiKV(或 TiFlash),最终查询结果返回给客户端。
SQL层架构如下所示:
用户的SQL请求会直接或者通过 Load Balancer发送到TiDB Server,TiDB Server会解析MySQL Protocol Packet,获取请求内容,对SQL进行语法解析和语义分析,制定和优化查询计划,执行查询计划并获取和处理数据。数据全部存储在TiKV集群中,所以在这个过程中TiDB Server需要和TiKV交互,获取数据。最后 TiDB Server需要将查询结果返回给用户。
4.TiDB Server的缓存
4.1 TIDB Server缓存
-
作用域:SESSION | GLOBAL
-
是否持久化到集群:是
-
类型:整数型
-
默认值:
1073741824
(1 GiB)
-
范围:
[-1, 9223372036854775807]
-
单位:字节
-
在 v6.1.0 之前的版本中,作用域为
SESSION
。v6.1.0 及之后的版本,作用域变更为
SESSION | GLOBAL
。
-
-
-
当变量值为
0
或
-1
时,表示内存阈值为正无穷。此外,当变量值小于 128 时,将默认被设置为
128
。
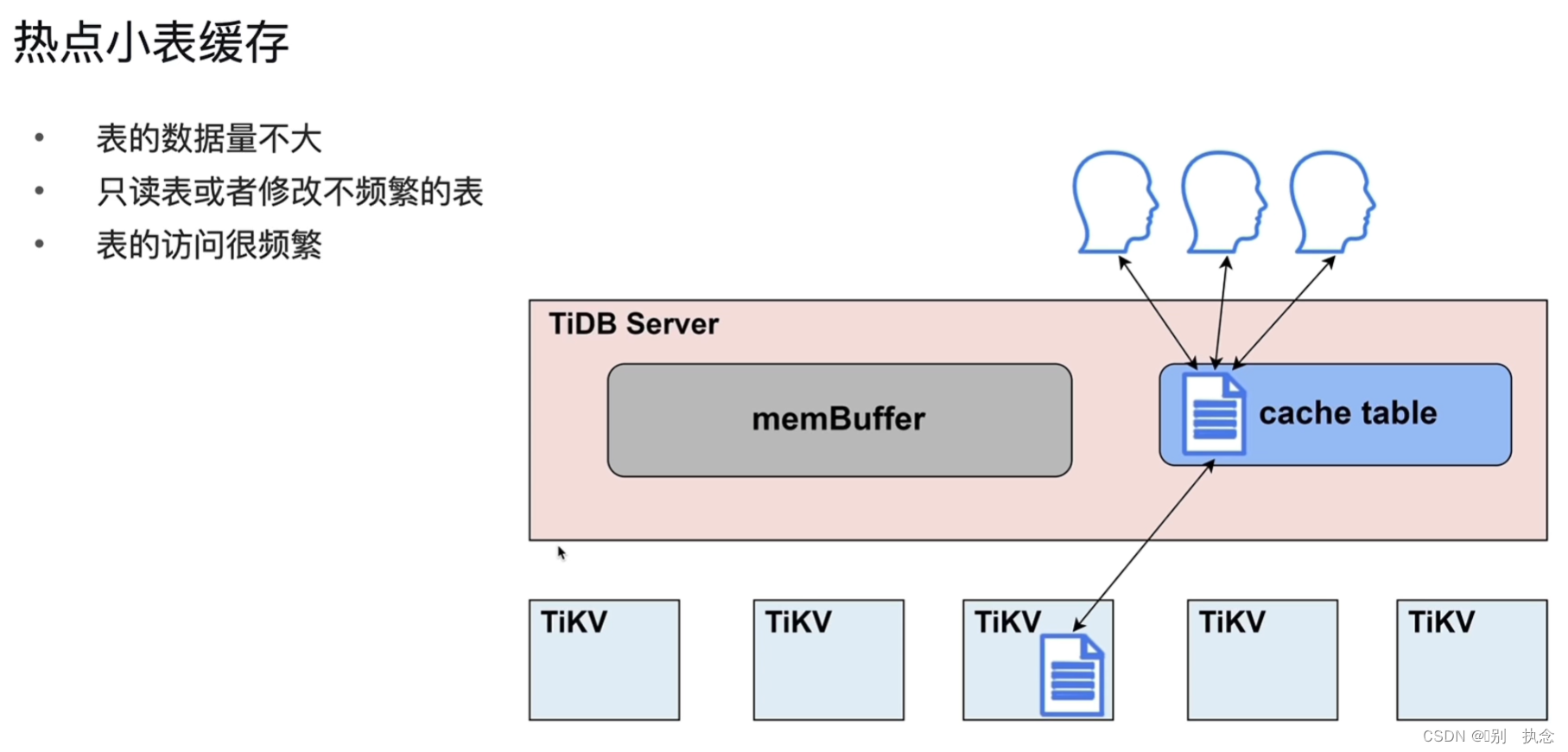
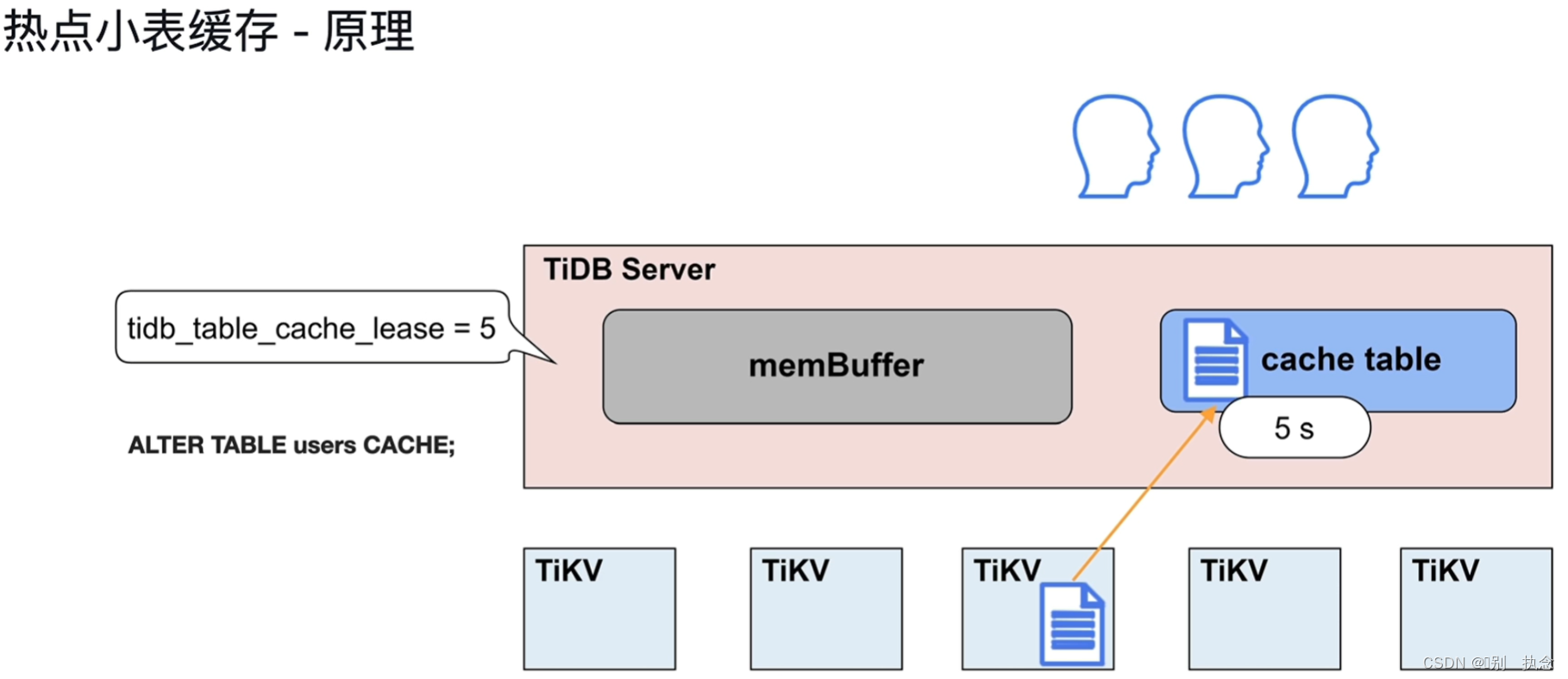
4.2 热点小表缓存
注意:适合热点缓存的表要求满足表大小在64M以下
将表放到缓存中语句alter table users CACHE;
缓存表在租约中只读,租约参数可设置,租约时间内读表在缓存中,写操作时,缓存失效,直到写完毕后继续续约后可读缓存表。
课堂测验
1.下列哪些模块直接与 TiDB 的事务处理有关?( 选 2 项 )
A. KV
B. Parse
C. Schema load
D. Transaction
E. GC
F. start job
正确答案:
A. KV、D. Transaction
2.
关于关系型数据与 KV 的转化,下列说法不正确的是?
A. 如果没有定义主键,key 中包含 RowID,Index ID 和 Table ID,都是 int64 类型
B. Table ID 在整个集群内唯一
C. 如果定义了主键,那么将使用主键作为 RowID
D. 不需要为每张表指定主键
正确答案:
C. 如果定义了主键,那么将使用主键作为 RowID
Lesson 03:TiKV
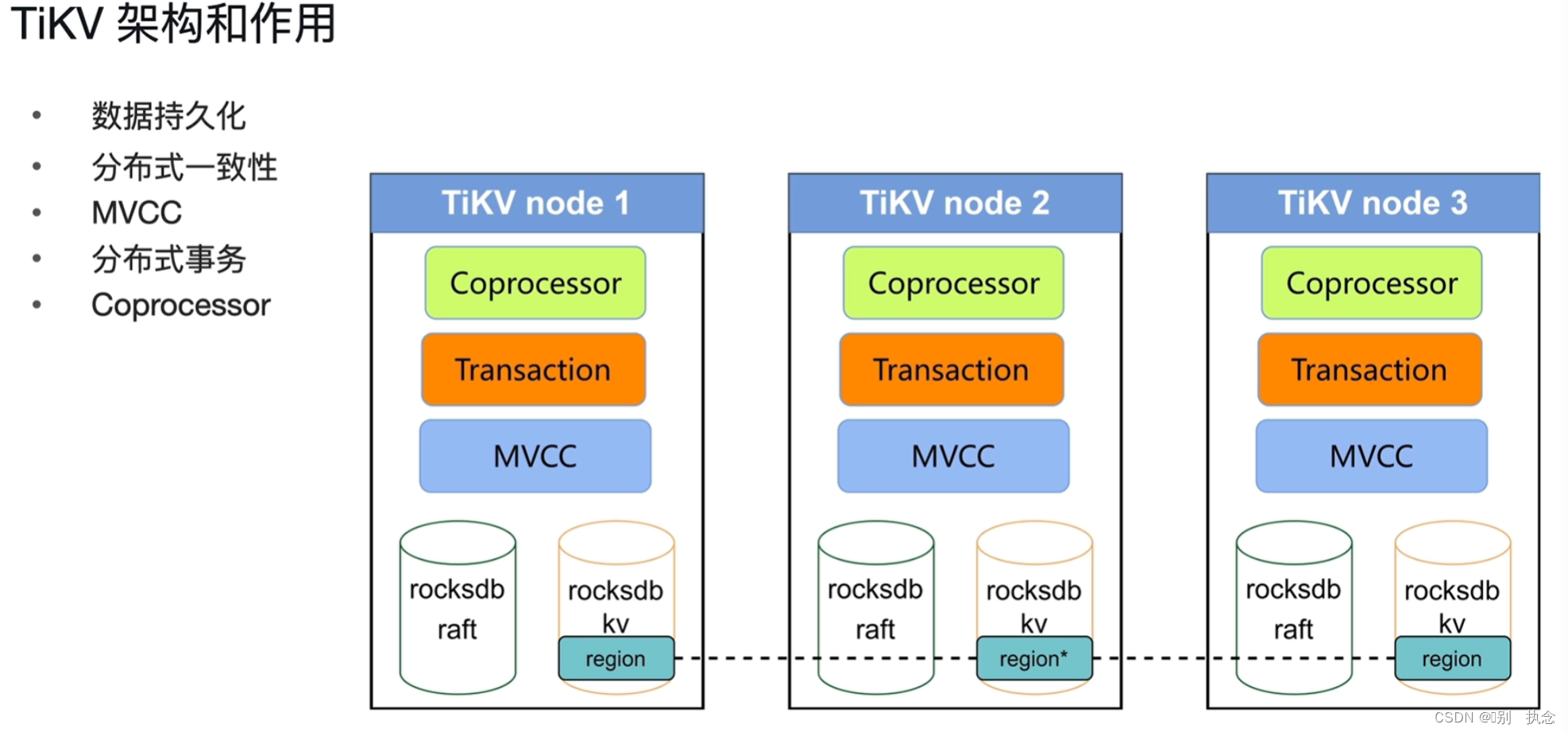
1.TiKV架构和作用
底层:rocksdb key-value rocksdb raft
控制层:MVCC多版本数据并发控制
事务层:分布式事务的支持Transaction
协同化处理Coprocessor
2.TiKV的数据持久化
2.1 RocksDB特点
RocksDB针对Flash存储进行优化,延迟极小,使用LSM存储引擎
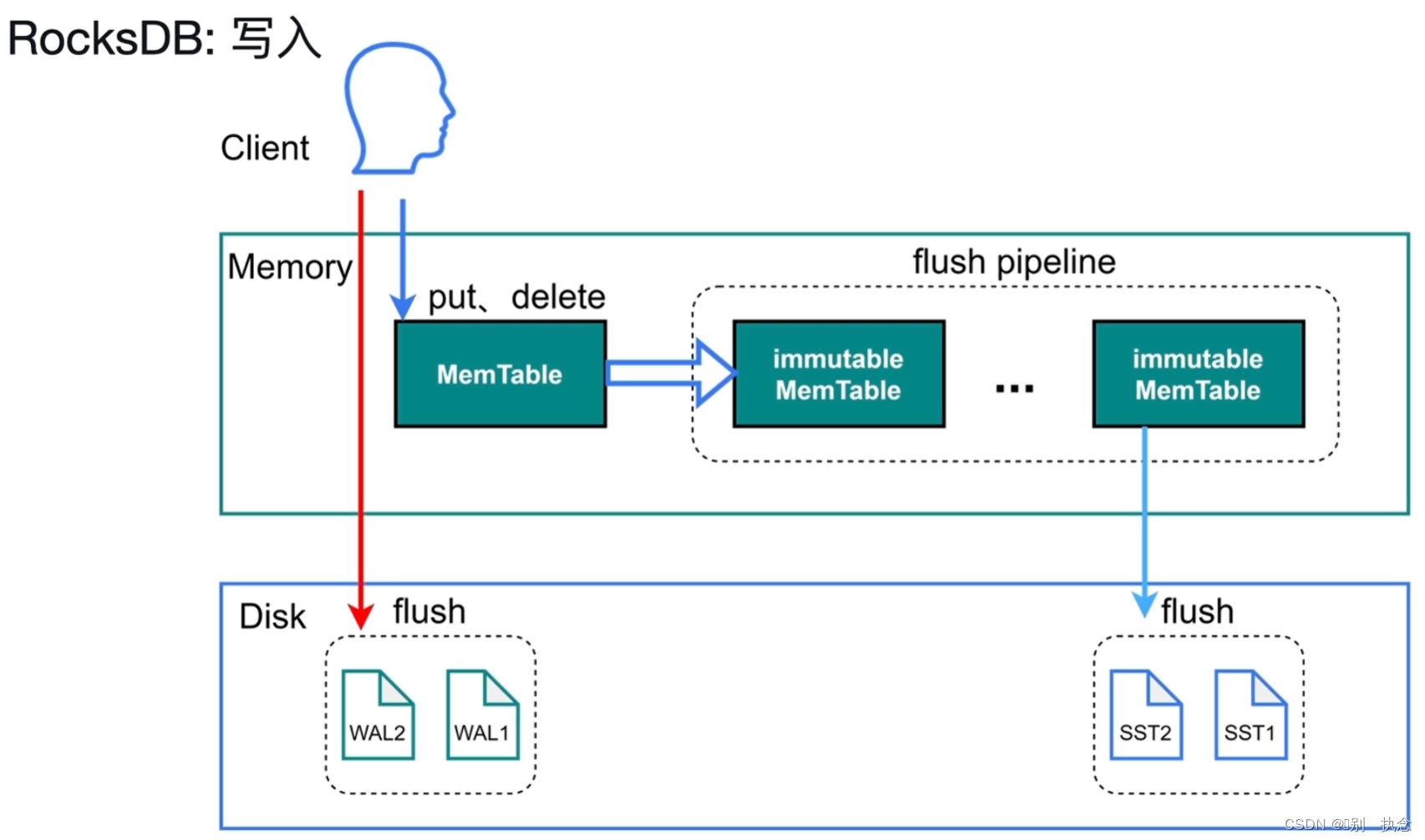
2.2 RocksDB写流程
写入流程:
-
采用LSM Tree的结构插入数据,首先将数据存储在MemTable,达到一定量之后再写入磁盘。
-
LSM树横跨内存和磁盘,MemTable,immutable MemTable和SST
-
写数据之前预写入日志文件
WAL( Write-Ahead Logging,预写日志系统),之后再将数据写到内存中。sync_log=true,让写入直接写入磁盘,跳过操作系统缓存。
-
MemTable中数据大小达到write_buffer_size的时候,旧将数据转存immutable MemTbale,另外再开辟新MemTable。
-
immutable MemTable是MemTable写入磁盘的中间站,MemTable写入磁盘的时候会阻塞读写,所以使用immutable MemTable作为中间站。
-
如果写入速度特别块,刷磁盘速度跟不上,immutable MemTable数量达到五个,则触发流控(write stall)。客户端写入速度变慢。流控会写入日志。
相关参数:
sync-log=true
在tidb中,打开
sync-log
时,disk io util 可以超过
90%
,设置
sync-log=false
后,它下降到1%
TiDB基于Raft共识算法,它需要确保每一个raft日志在提交之前会持久保存到大多数磁盘上。使 确保日志持久化,我们需要两个步骤:
写(log_fd,日志)和fsync(log_fd),
当
sync-log=false
时,TiDB 会跳过 fsync
,这有助于提高性能并且在
没有停电的
情况下是安全的
将其设置为true,即使在
停电
情况下,数据也始终完好无损
一般来说,开启
sync-log
会让性能损耗 30% 左右
write-buffer-size
-
memtable 大小。
-
defaultcf
默认值:
"128MB"
-
writecf
默认值:
"128MB"
-
lockcf
默认值:
"32MB"
-
最小值:0
-
单位:KB|MB|GB
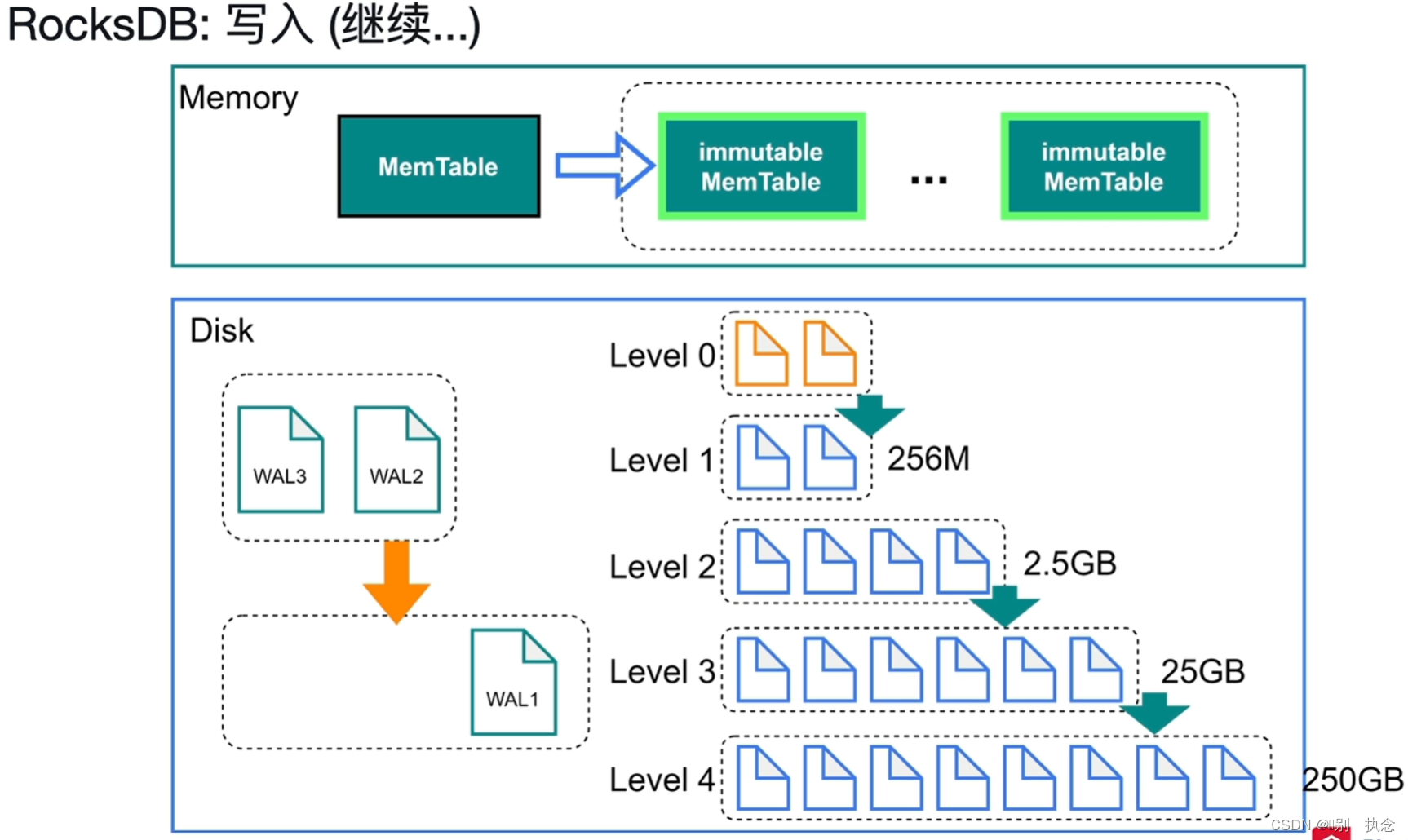
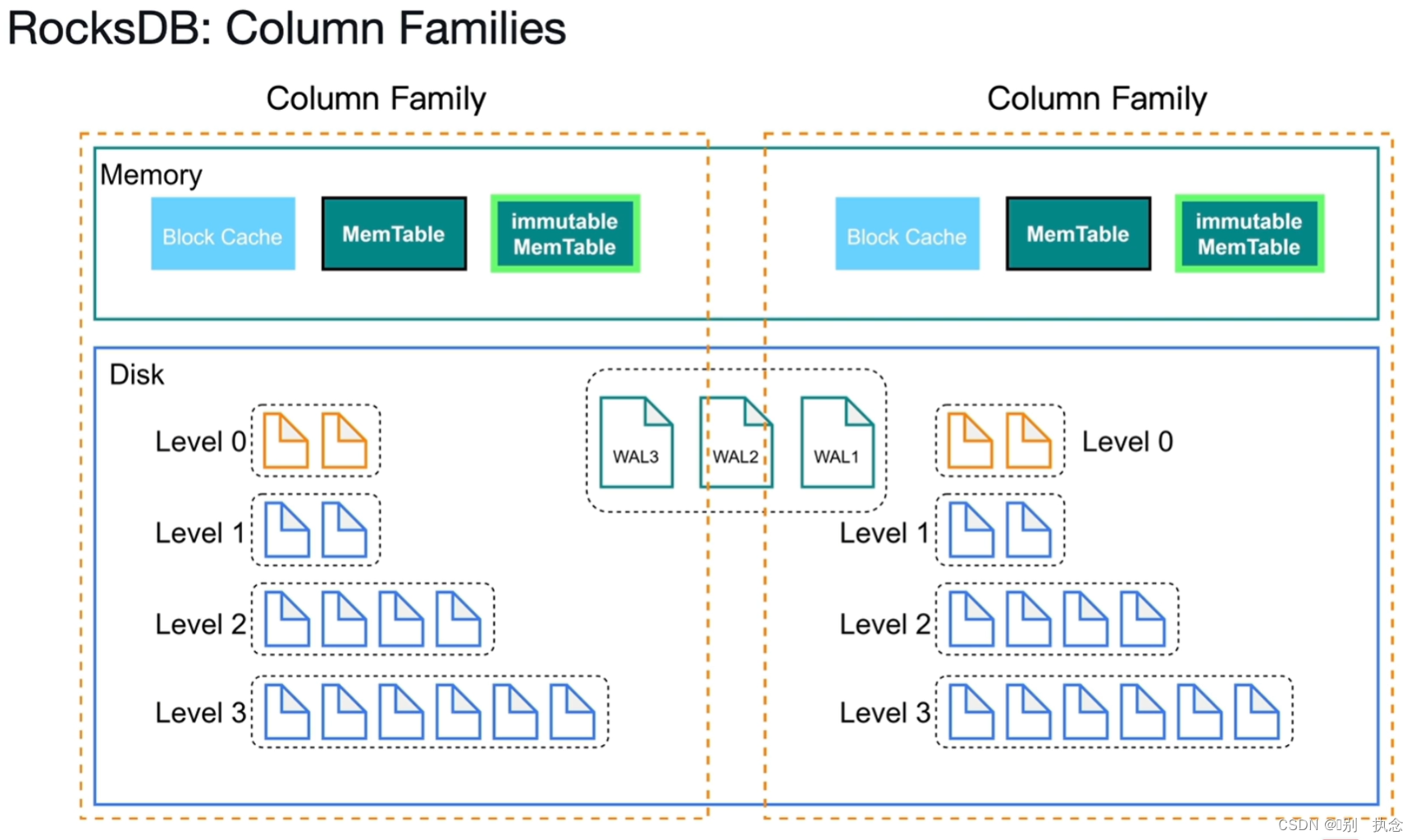
落盘之后的数据存储:
-
Level 0是immutable MemTable的复刻,内容与其完全一样。
-
Level 0中文件达到4个之后,就写入
Level 1
。Level 1开始,key都是排好序的。查找的时候使用二分查找即可。
-
删除操作,是写入一条删除操作的数据。更新也是这样。
-
每次写入的时候不用考虑数据在哪,直接写入MemTable即可。
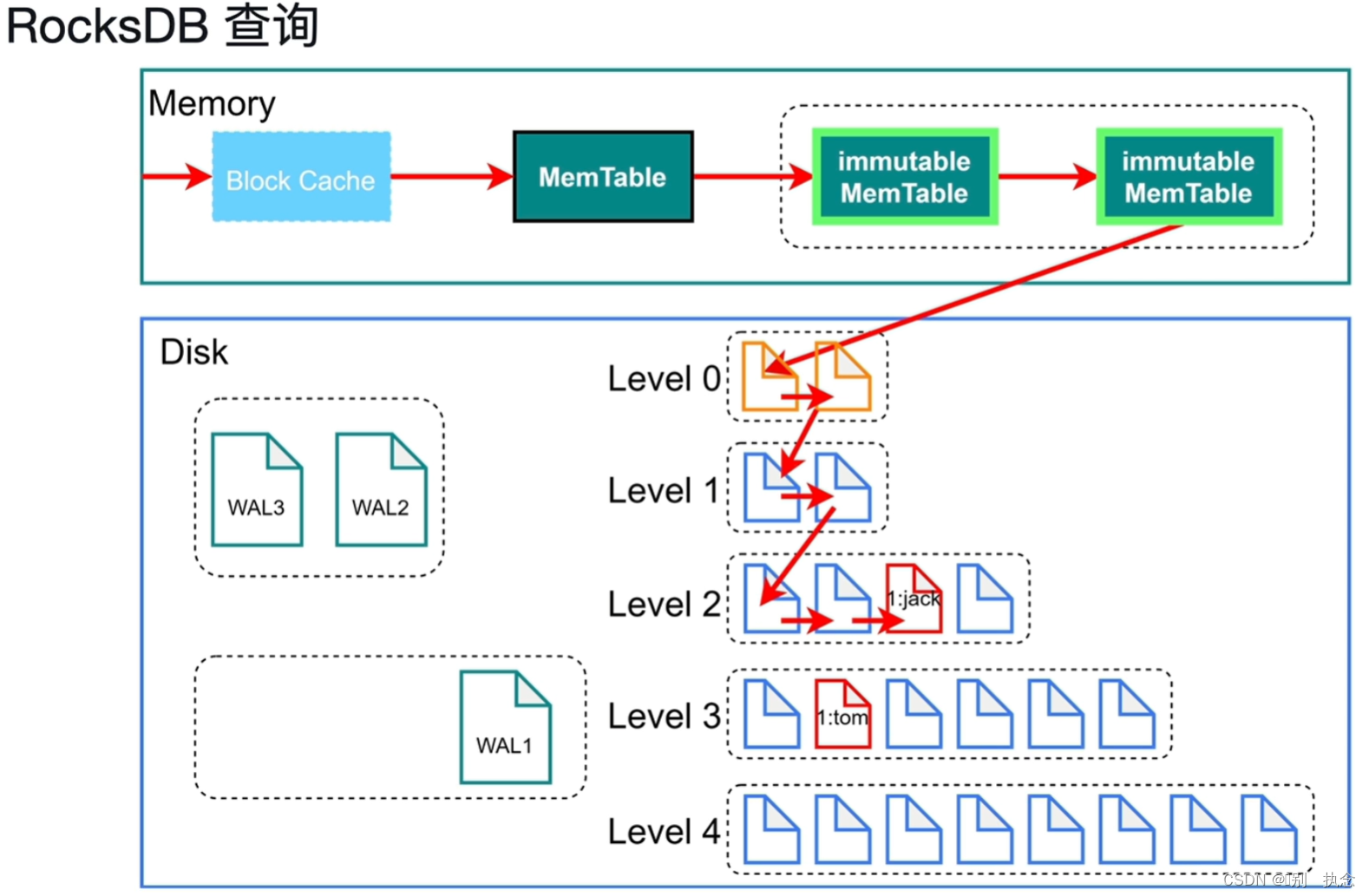
2.3 RocksDB查询
查询过程:先在Block Cache里去查询--MemTable里去查询--immutable Mem Table里查询--磁盘中一级一级查询,直到查询到为止
以上为单个RocksDB里的查询,下面介绍RocksDB里的CF
列簇CF(Column Families):
3.TiKV如何提供MVCC和分布式事务支持
3.1 MVCC
多版本并发控制 (MVCC),
TiKV 的 MVCC 实现是通过在 Key 后面添加版本号来实现
没有 MVCC 之前,
Key1 -> Value
Key2 -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1_Version3 -> Value
Key1_Version2 -> Value
Key1_Version1 -> Value
……
Key2_Version4 -> Value
Key2_Version3 -> Value
Key2_Version2 -> Value
Key2_Version1 -> Value
……
对于同一个 Key 的多个版本,版本号较大的会被放在前面,版本号小的会被放在后面
,这样当用户通过一个 Key + Version 来获取 Value 的时候,可以通过 Key 和 Version构造出MVCC的Key,也就是Key_Version。然后可以直接通过 RocksDB的SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
当用户确信自己需要更长的读取时间时,比如在使用了 Mydumper 做全量备份的场景中(Mydumper 备份的是一致性的快照),可以通过调整 TiDB 中mysql.tidb
表中的tikv_gc_life_time
的值来调大 MVCC 版本保留时间,需要注意的是tikv_gc_life_time的配置是立刻影响全局的,调大它会为当前所有存在的快照增加生命时长,调小它会立即缩短所有快照的生命时长。过多的 MVCC 版本会拖慢 TiKV 的处理效率。
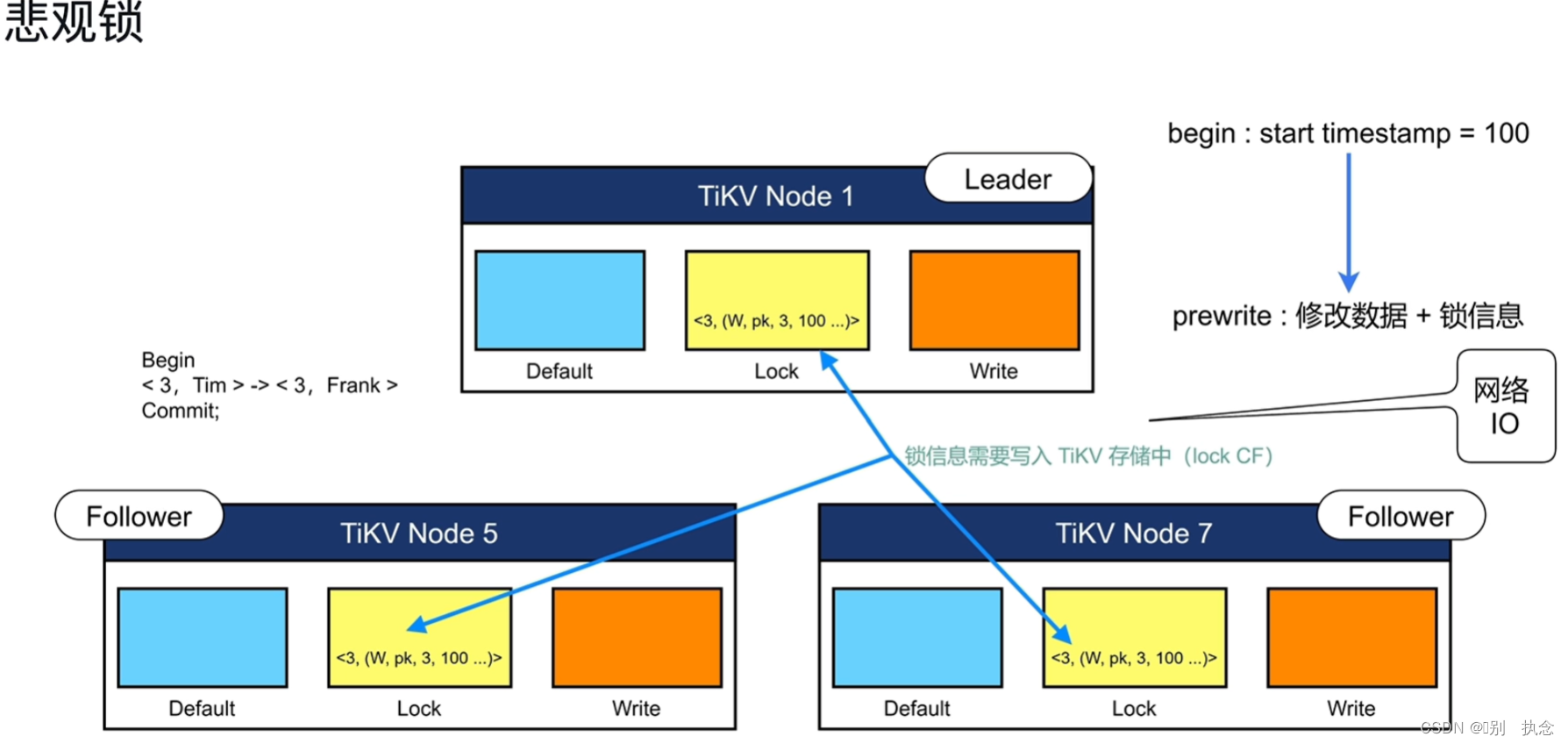
3.2 分布式事务
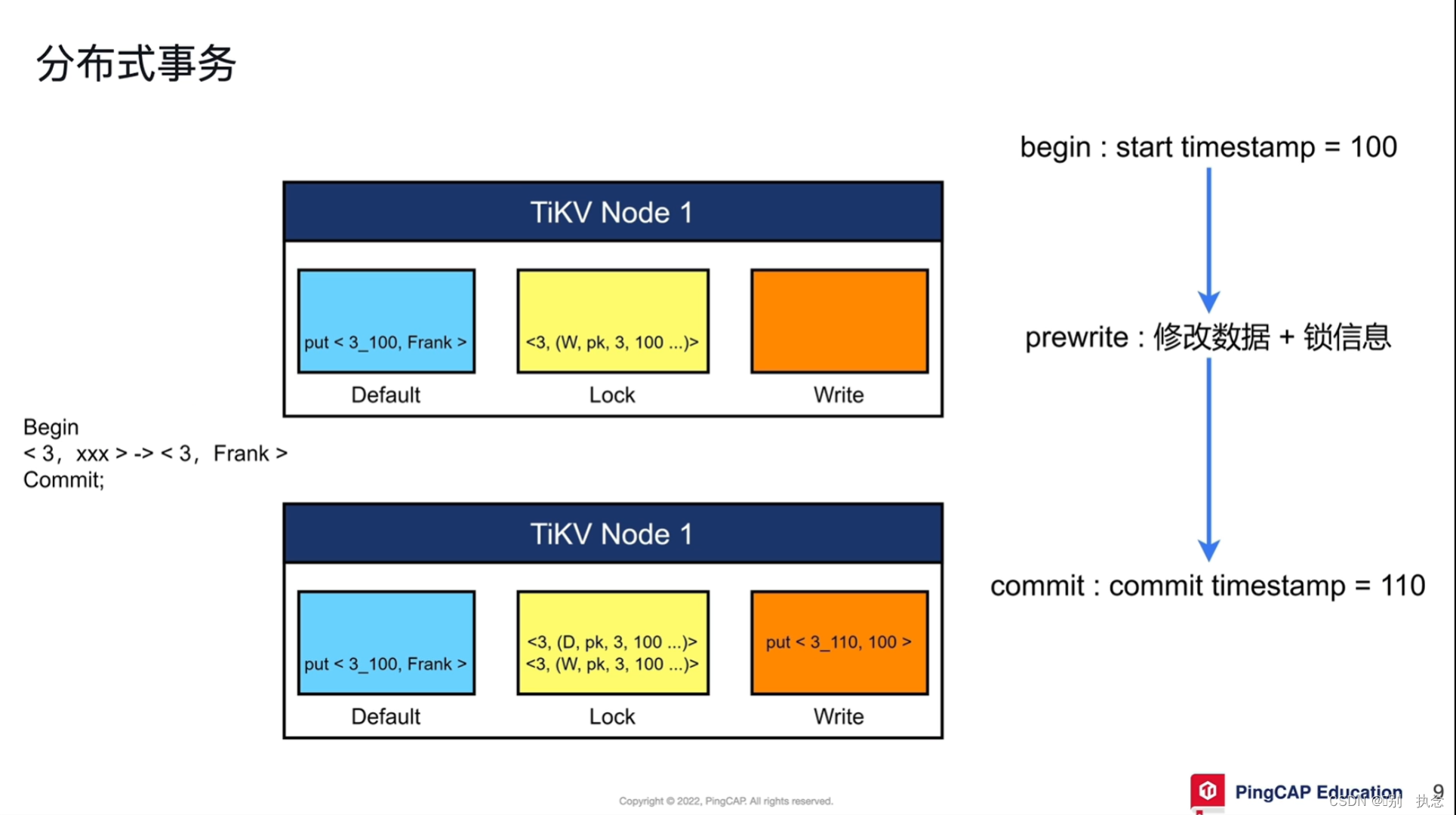
分布式事务的流程:
1.首先begin,在begin之后会从PD中获取时间戳TSO,即事务的开始时间start_ts
2.将修改的数据读取出来,存放到TiDB Server的内存中进行修改
3.遇到Commit时,开始将事务进行两阶段的提交,第一阶段Prewrite,将上一步内存中修改数据和锁信息写入到TiKV节点中
当begin和commit之间的过程不被感知时,即锁信息未被写入,此时为乐观锁
如果需要将begin和commit之间的过程被感知到,需要提前将锁信息进行修改,此时即为悲观锁
第二阶段,事务会向PD去索要结束时间戳commit_ts,并写一个提交信息,标志事务结束。
数据写入TIKV的过程:
Prewrite阶段:
-
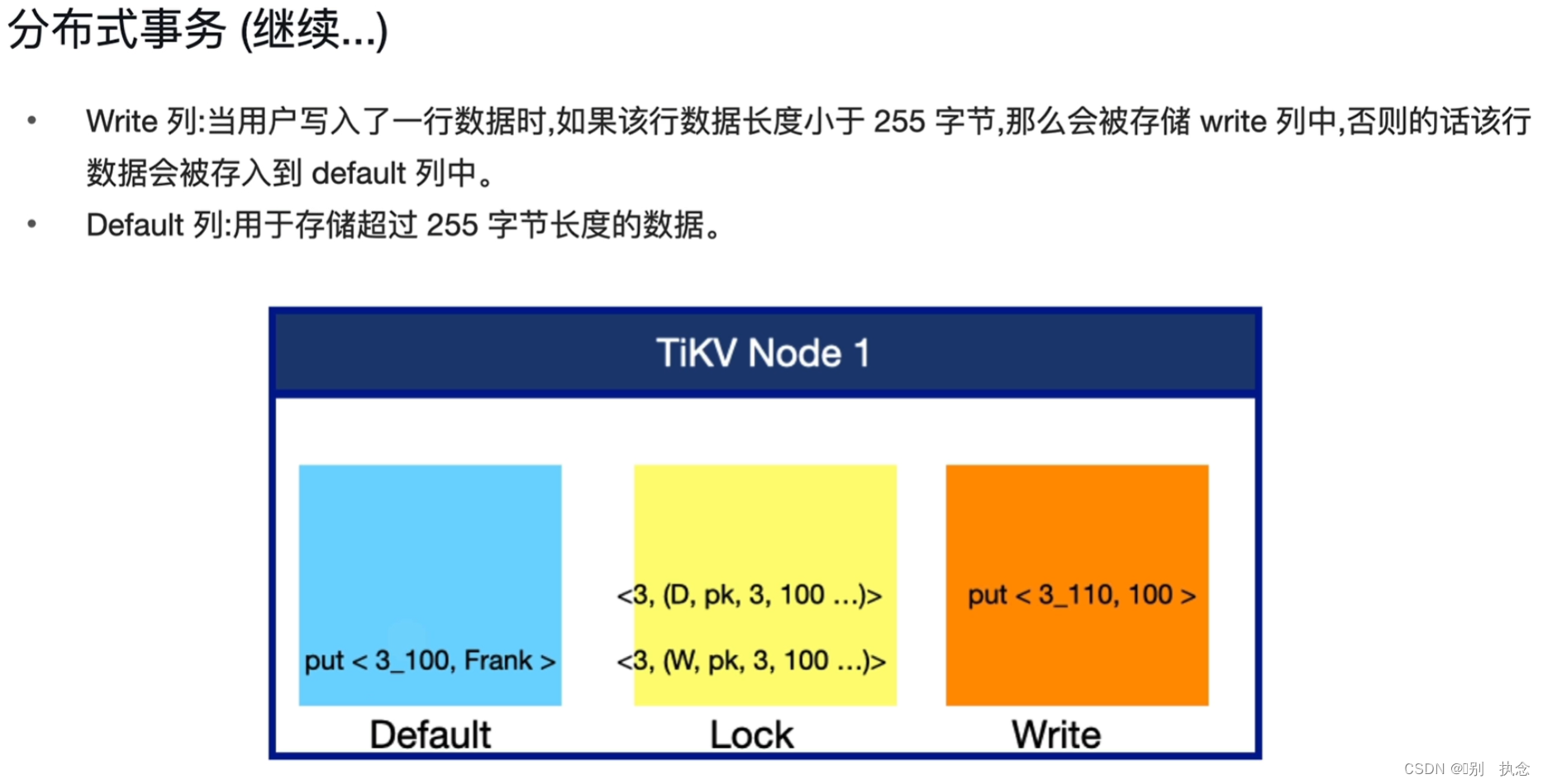
在修改数据由内存写入TiKV节点时,TiKV节点使用三个列簇(CF)来分别存放
修改数据(Default),锁信息(Lock),提交信息(Write)。
-
写入时,在Default列簇里,写入的不止是表列的值,还有时间戳,例上图中,3为列值,TiKV中为3_100,其中,3为列值,100为start_ts的值
-
只给事务第一行加一把主锁(pk)并写入Lock列簇中,其他的锁都指向这个锁。
Commit阶段:
-
在commit从PD获取到结束时间戳后,首先会在Write的CF里写入提交信息,即上图的put <3_110,100>,元素有3(事务ID),110(结束时间戳),100(开始时间戳)
-
锁清理写入到Lock的CF里,即<3,(D,pk,3,100...)>,D表示Delete删除
至此,数据写入提交完成。
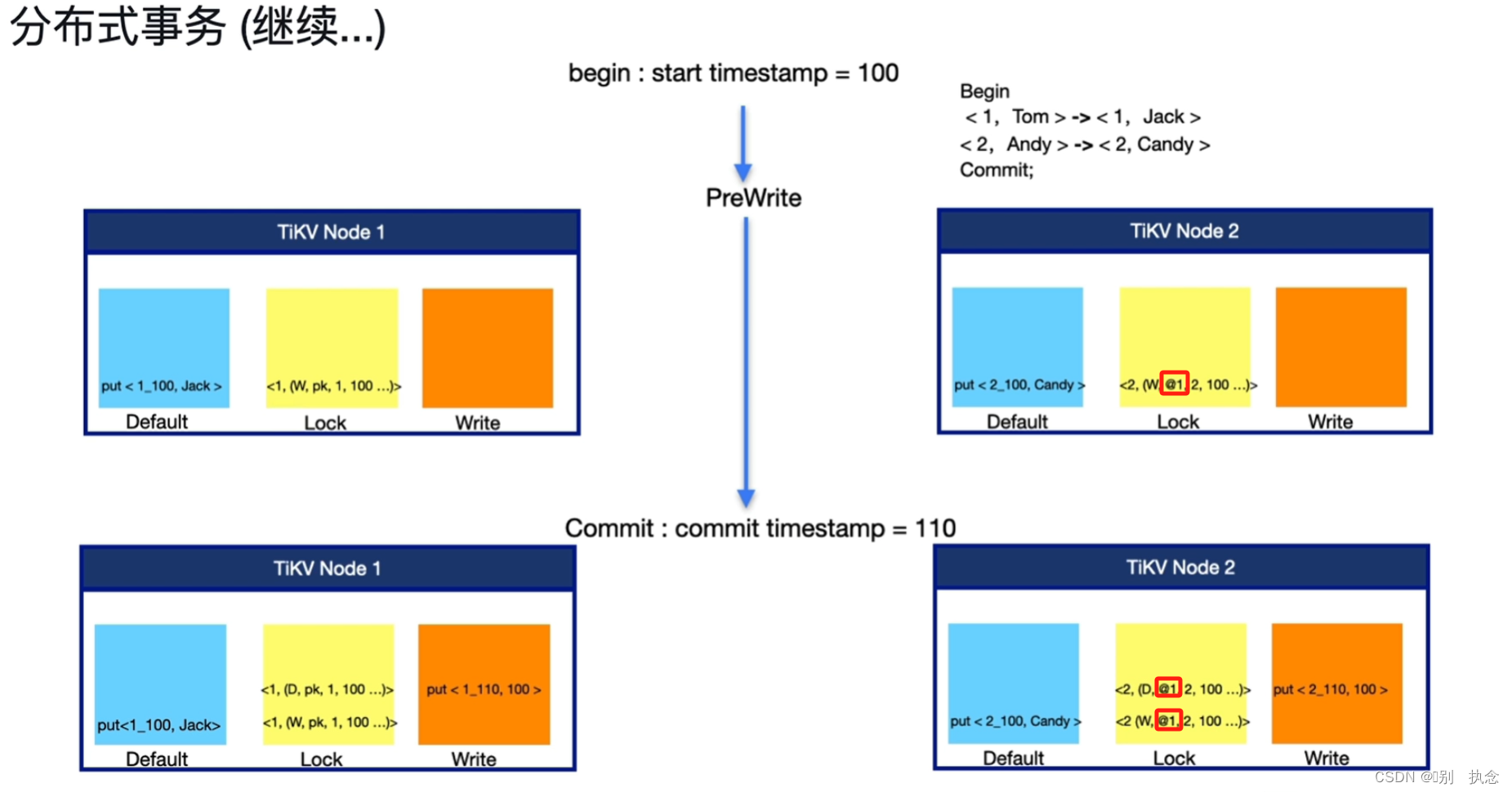
其他注意点:当修改的数据不在同一个TIKV节点时,从第二行开始,Lock的锁信息均指向第一行数据的锁,即下图中的@1
4.TiKV基于raft算法的分布式一致性
4.1 Raft日志复制
Raft:
-
leader:由所有节点选举,在candidate中产生,负责整个集群的状态以及元数据管理,当发现更大的term时,转化为follower
-
candidate:由follower在集群选举时转化而成,选举时得到多数选票,则转化为leader,若发现主节点或者更大的term则转化为follower
-
follower:集群初始化时所有节点的角色都是follower,若未发现leader心跳,则发起leader选举,并将角色转化为candidate;leader以及candidate在某些条件下也会转化成follower
-
region:键值对的集合,key顺序排序。达到96M后,会另起一个region。region长到144M时候,会自动分裂。过小的时候会进行合并
Raft日志复制过程:
-
Propose:leader写入一条raft日志
-
Append:接受raft日志并持久化到raftdb中,只在leader节点持久化
-
Replicate:将日志复制到其他节点中,其他节点接收到日志之后,将日志append持久化,之后给leader一个响应。
-
Committed:超过一半节点发回响应之后,进入committed。这个只是raft log的committed
-
Apply:把数据写到rockdb kv中
Raft Leader选举:
-
term:
通俗来讲就是任期,即一个leader正常工作的时间段,如果因为某些原因当前的leader不再是leader时,则该term结束,重新进行选举,开始新的任期,
另外term在raft算法中也起到了逻辑时钟的作用,在raft的实现中起到了重要的作用,此处用一句话先来概括:即term大的优先级高,leader必须是拥有更大的term。用白话理解:就是当前总统和前总统的关系,总统只能有一个就是当期总统,前总统在当前总统面前就变成选民了。在Raft中,term是个整数型的值,term变化即将term的值加1
-
election timeout:集群创建之初,没有leader节点的时候,各节点等待的时间,值一般为150ms-300ms
-
heartbeat timeout:,心跳超时,即Leader节点掉线后,其他节点重新选举时的等待时间
-
heartbeat time intervol:心跳时间间隔,同上
选举过程和情况:
集群初始化时,大家都是follower,当未发现leader心跳并超时后,则follower变成candidate,并发起leader election。每个candidate的动作如下:
在此过程中会出现三种情况:
-
该candidate收到了多数(majority)的选票当选了leader,并发送leader心跳告知其他节点,其他节点全部变成follower,集群选主成功
-
该candidate收到了其他节点发来的leader心跳,说明主节点已经选举成功,该candidate变成follower,集群选主成功
-
一段时间内(election timeout),该candidate未收到超过半数的选票,也未收到leader心跳,则说明该轮选主失败,重复进行leader election,直到选主成功
上述情况的产生需要满足下面几个约束:
-
在每个任期中每个人只能投出一票:注意是每个任期,任期变了(准确的说法是任期增加了)就可以重新投票
-
投票的规则:candidate肯定投给自己,follower是先到先得
-
当选leader的条件是得到多数(N/2+1)选票:此处的多数选票是为了避免脑裂而出现多leader的情况而进行的约束,保证了整个集群中leader的唯一性
-
leader的消息是最新的(其实就是term最大,index也是最大的,后面的log replication模块进行详细分析)
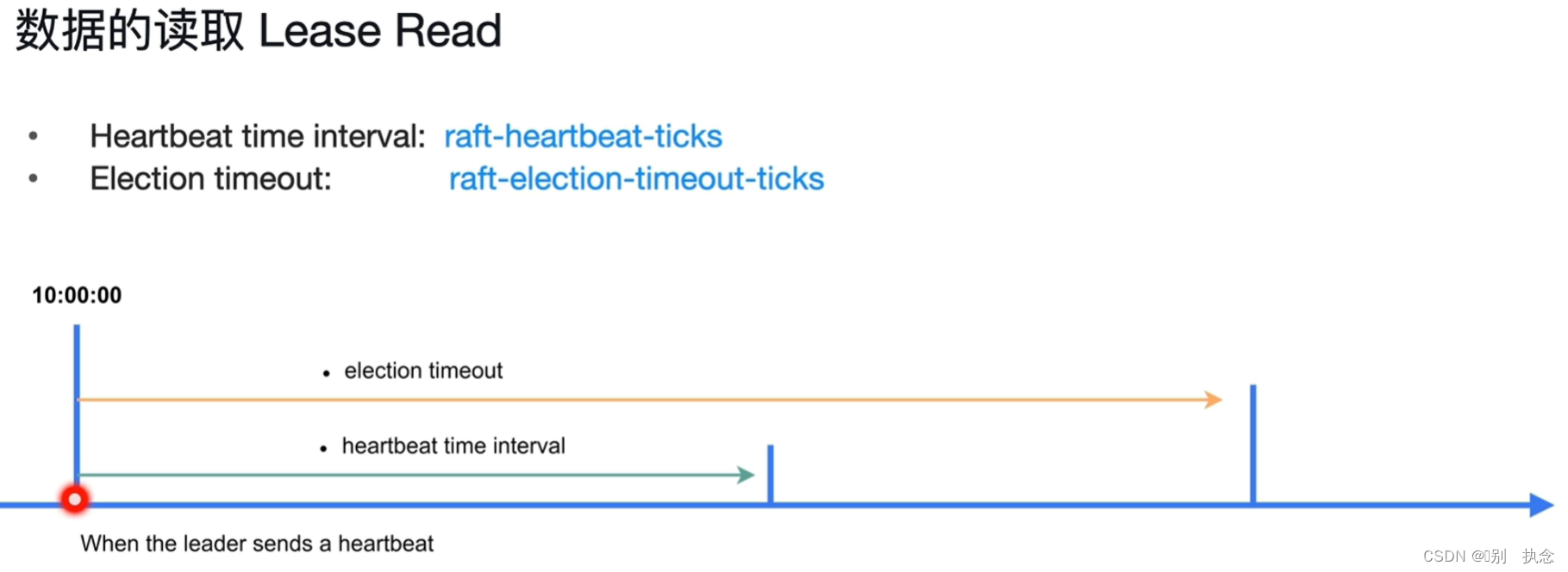
对应参数:
Election timeout:raft-election-timeout-ticks
Heartbeat time interval:raft-heartbeat-ticks
raft-haartbeat-ticks *raft-base-tick-interval
raft-election-timeout-ticks *raft-base-tick-interval
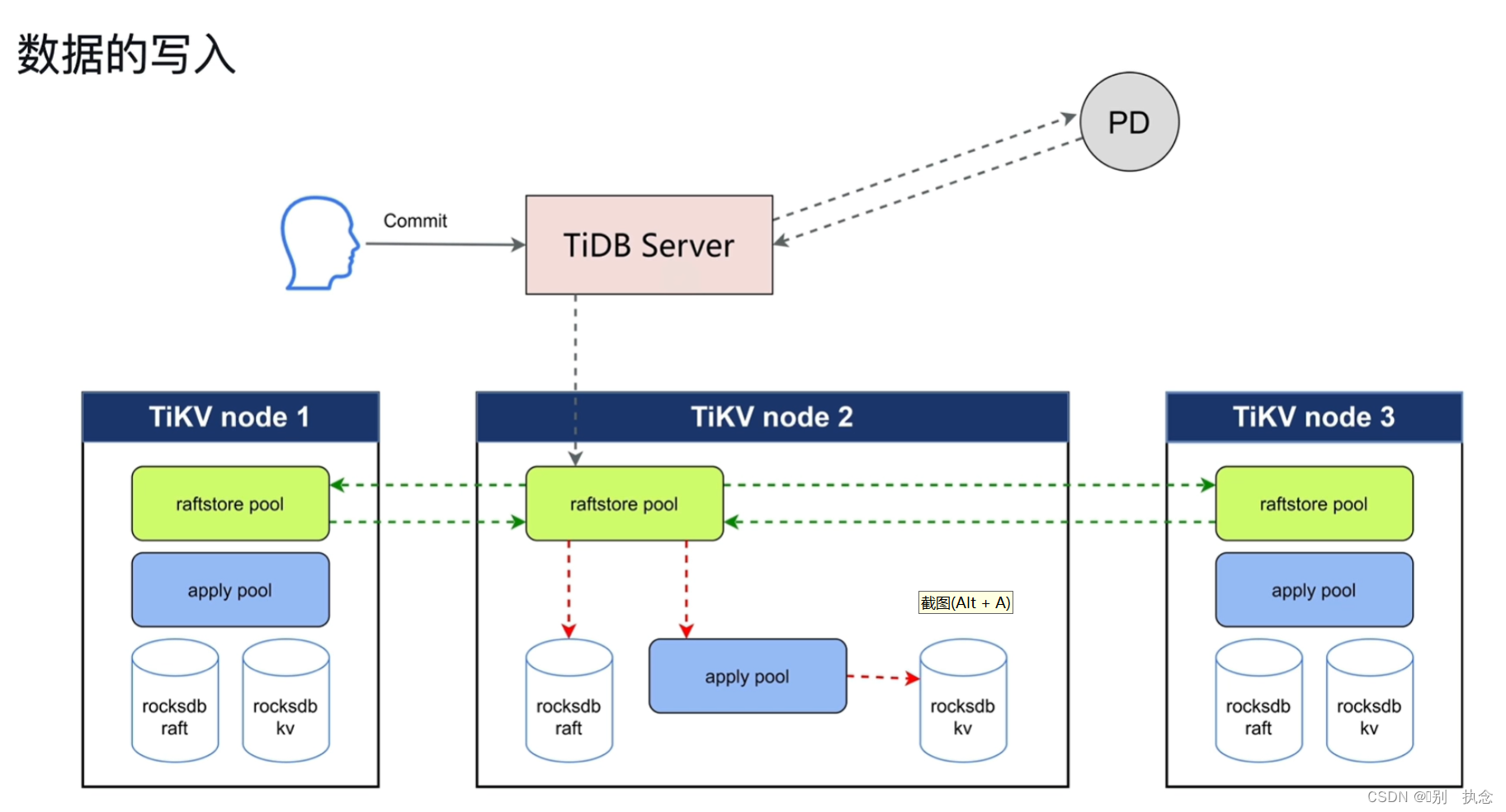
4.2 TiKV写入
前提约定:抛去事务层和MVCC
PD发送调度命令,将TiDB节点的缓存数据写入TiKV中,到TiKV后,写请求通过raftstore pool线程池接收Raft日志并持久化到自己节点的raft日志库中。 apply pool线程池通过raftstore pool将发送的日志解析后,将数据写入kv池中。
写入步骤:
-
propose:将写请求转化为raft log
-
append:通过raftstore pool线程池将raft log日志存储到rocksdb raft持久化库中
-
replicat:各节点之间复制日志文件
-
committed:此提交指大多数TiKV节点已复制raft log日志并持久化到本节点日志中,返回消息给Leader节点,要区别与用户的commit
-
用户commit: apply pool将rocksdb raft的日志应用并解析到rocksdb kv中后,用户commit才算完成
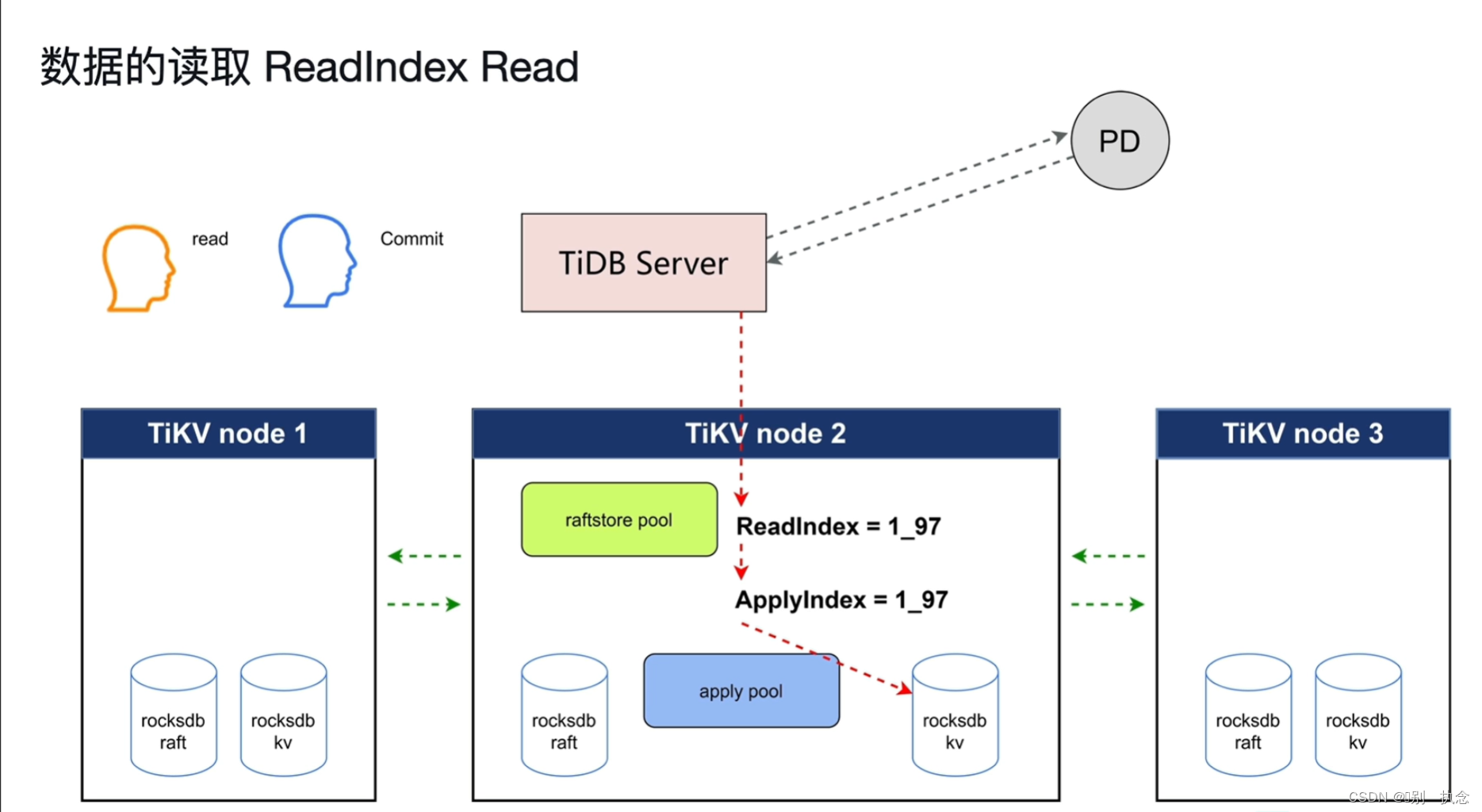
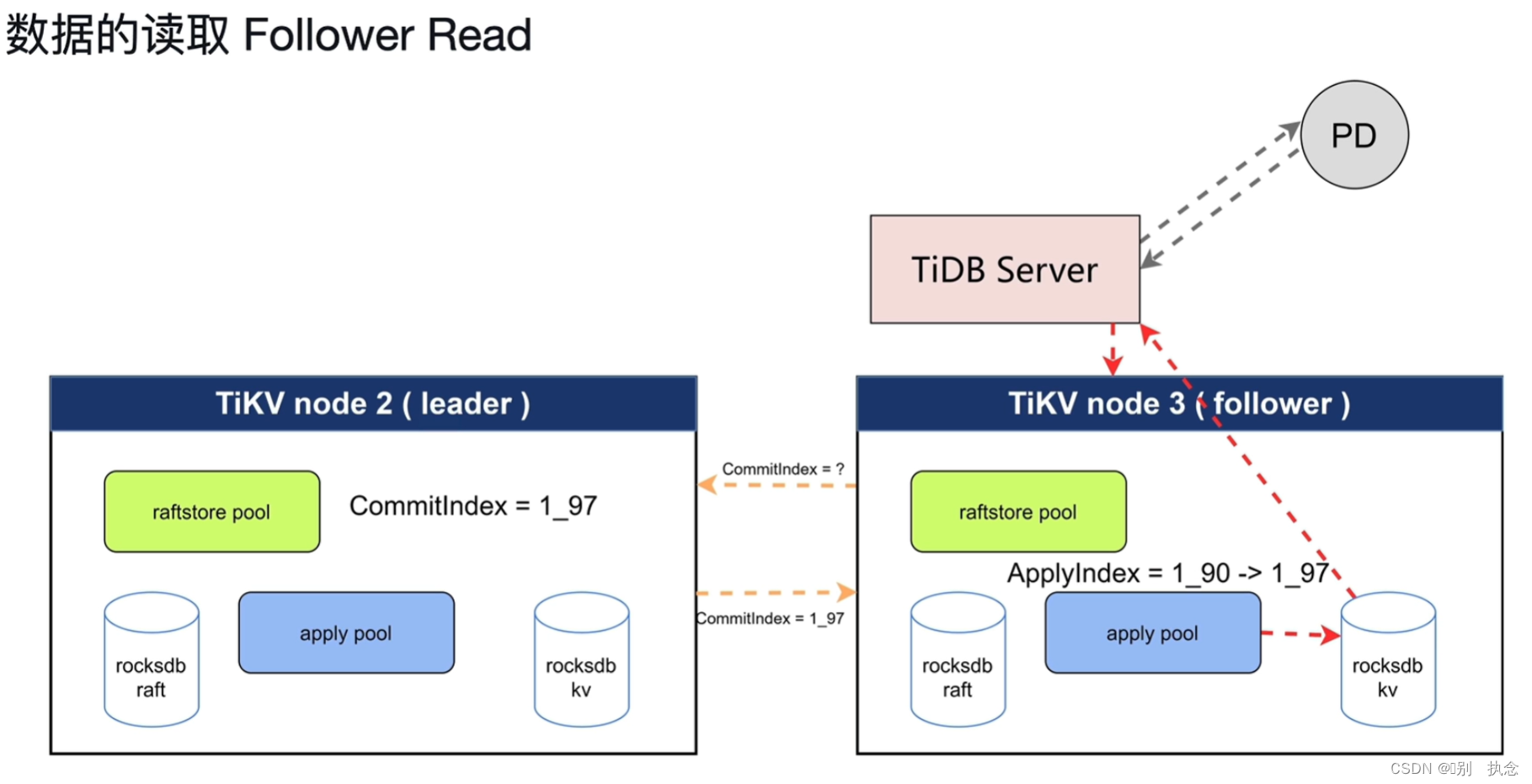
4.3 TiKV读取
ReadIndex Read
由TiDB Server节点发出读取命令到PD节点,PD去查找数据在哪一个TiKV节点的哪一个Leader角色的region上
读取过程中的问题:
通过Leader节点向其他节点发送心跳询问并返回消息来确保输出的数据为Leader节点。
TiDB引入了ReadIndex和ApplyIndex,readindex保证了读取时一定可以读取到之前修改的值。当读取数据时,先获取到要读取的数据所在的位置(index)。然后寻找Raft日志复制阶段中commited阶段的index,确保commited的index大于要读取的数据的index后,记录commited的index作为ReadIndex值,寻找Raft日志复制阶段中的apply阶段的index作为ApplyIndex值。只有当ApplyIndex的值等于ReadIndex的值时,可以确定当前index的数据已经提交持久化,从而知道要读取的数据所在的index的值已确定持久化,此时读取的数据就是提交后的数据。
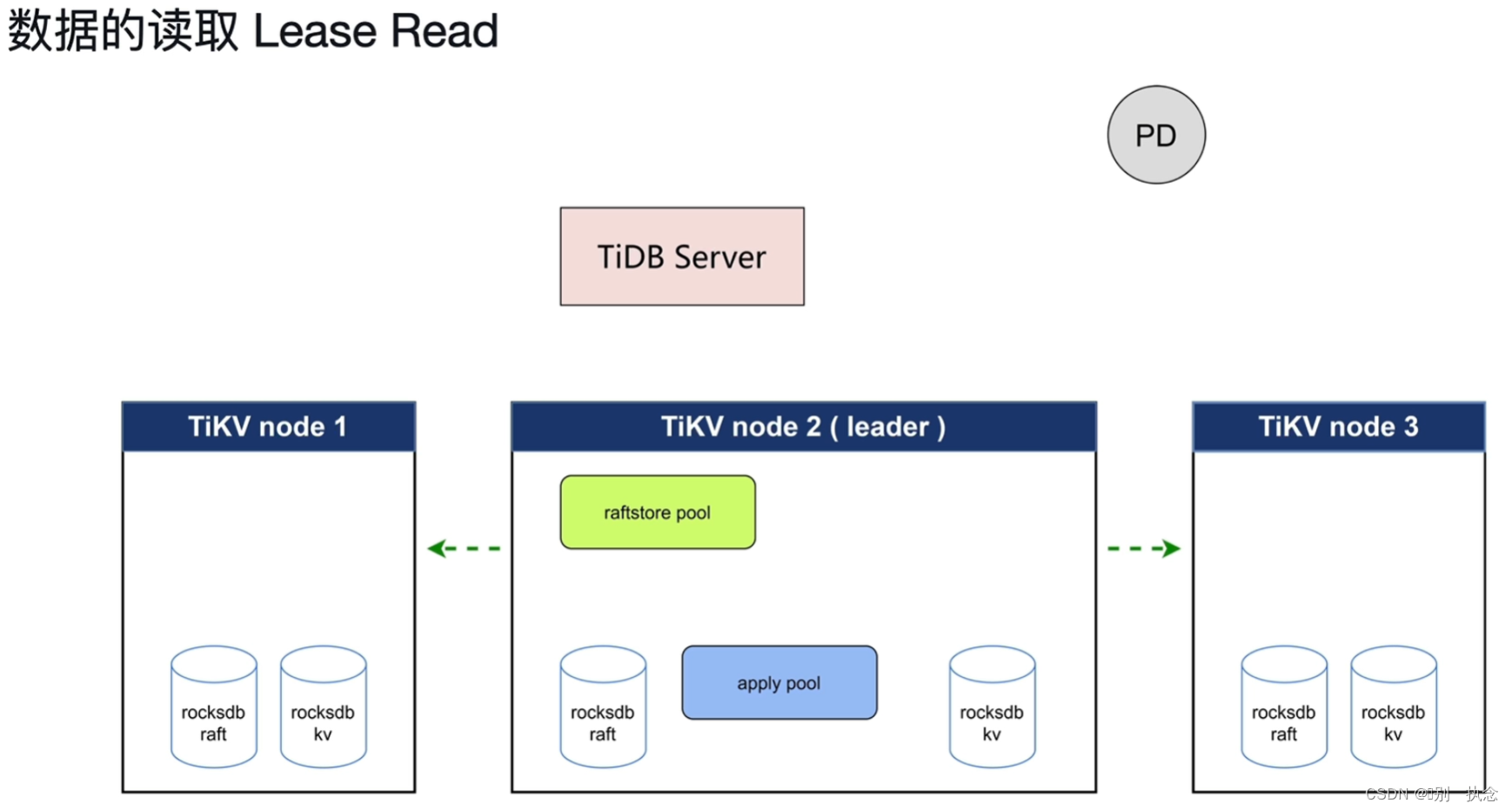
第一种读取方式:
Lease Read
TiDB Server从PD获得leader时(TSO),此时的leader还是正常的,那么leader会发送心跳,时间间隔是heartbeat time interval,而follower会等待election timeout,如果达到election timeout还没收到心跳,才会进行重新选举leader。这意味着,即便从TiDB Server从PD获取到leader后(TSO后)leader就出现问题,那么也至少需要等待election timeout这么长时间集群才会重新选举leader,也就是在election timeout这个时间范围内,还是可以从原leader处读取数据的。这就是Lease Read。
第二种读取方式:Follower Read
首先,这种方式需要保证follower的数据与leader的数据是一致的;但这种读取方式可能得原因是Follower节点比Leader节点得apply要快,从而在查询中会返回Follower节点的数据。
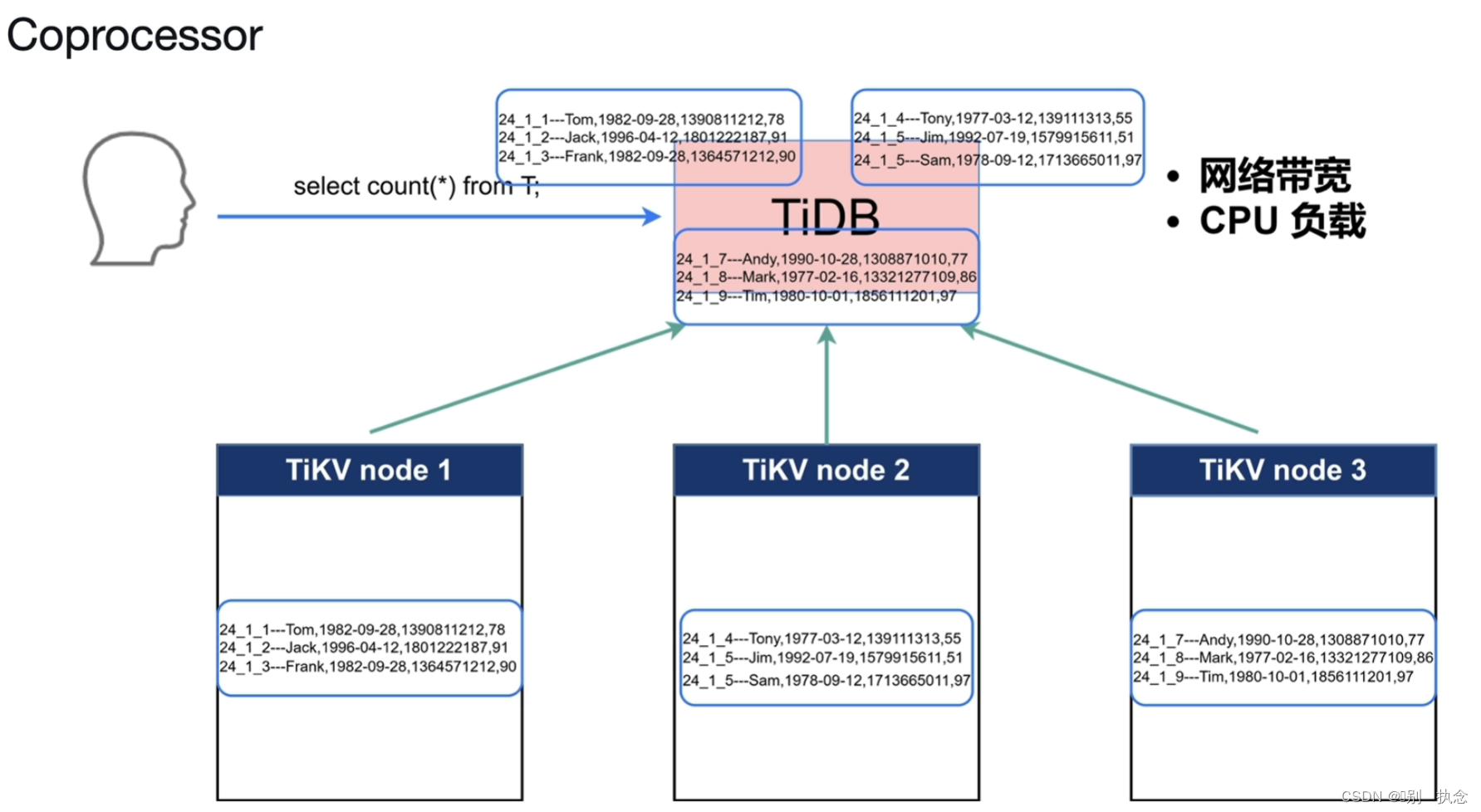
5.Coprocessor
5.1Coprocessor协同处理器的作用
帮助TIDB节点将来自客户端的查询下推到TiKV中,可以实现:执行物理算子,算子下推,聚合、全表扫描、索引扫描等。
TiKV Coprocessor 处理的读请求目前主要分类三种:
-
DAG:执行物理算子,为 SQL 计算出中间结果,从而减少 TiDB 的计算和网络开销。这个是绝大多数场景下 Coprocessor 执行的任务。
-
Analyze:分析表数据,统计、采样表数据信息,持久化后被 TiDB 的优化器采用。
-
CheckSum:对表数据进行校验,用于导入数据后一致性校验。
5.2 工作流程
TiDB Server接收到用户的请求后, TiKV的所有数据会发送到TiDB Server做运算,这样会增加网络带宽,还会使负载很高,在有了Coprocessor协同处理器后,可以将TiDB Server收到的count请求下推给TiKV的各个节点,各TiKV节点在做完count计算后,将值返回给TiDB server,此时,TiDB server只需对返回值进行识别处理即可,这样就减少了计算节点的计算压力。
课堂测试
1.下列属于 TiKV 相关功能的是?( 选 4 项 )
A. 系统参数和元数据信息的持久化
B. 产生 TSO
C. 分布式事务实现
D. MVCC
E. 生成物理执行计划
F. 表统计信息的持久化
正确答案: A. 系统参数和元数据信息的持久化、C. 分布式事务实现、D. MVCC、F. 表统计信息的持久化
2.关于 TiKV 数据持久化,下列说法不正确的是?
A. RocksDB 有 2 个实例,分别用来持久化 raft log 和 key value 数据
B. RocksDB 中 WAL 用来保证写不丢失
C. 对于删除操作,只需要在原 key value 数据上标记已删除即可
D. RocksDB 中,除了 Level 0 层的数据,其他 Level 都是单一排序持久化的
正确答案: C. 对于删除操作,只需要在原 key value 数据上标记已删除即可
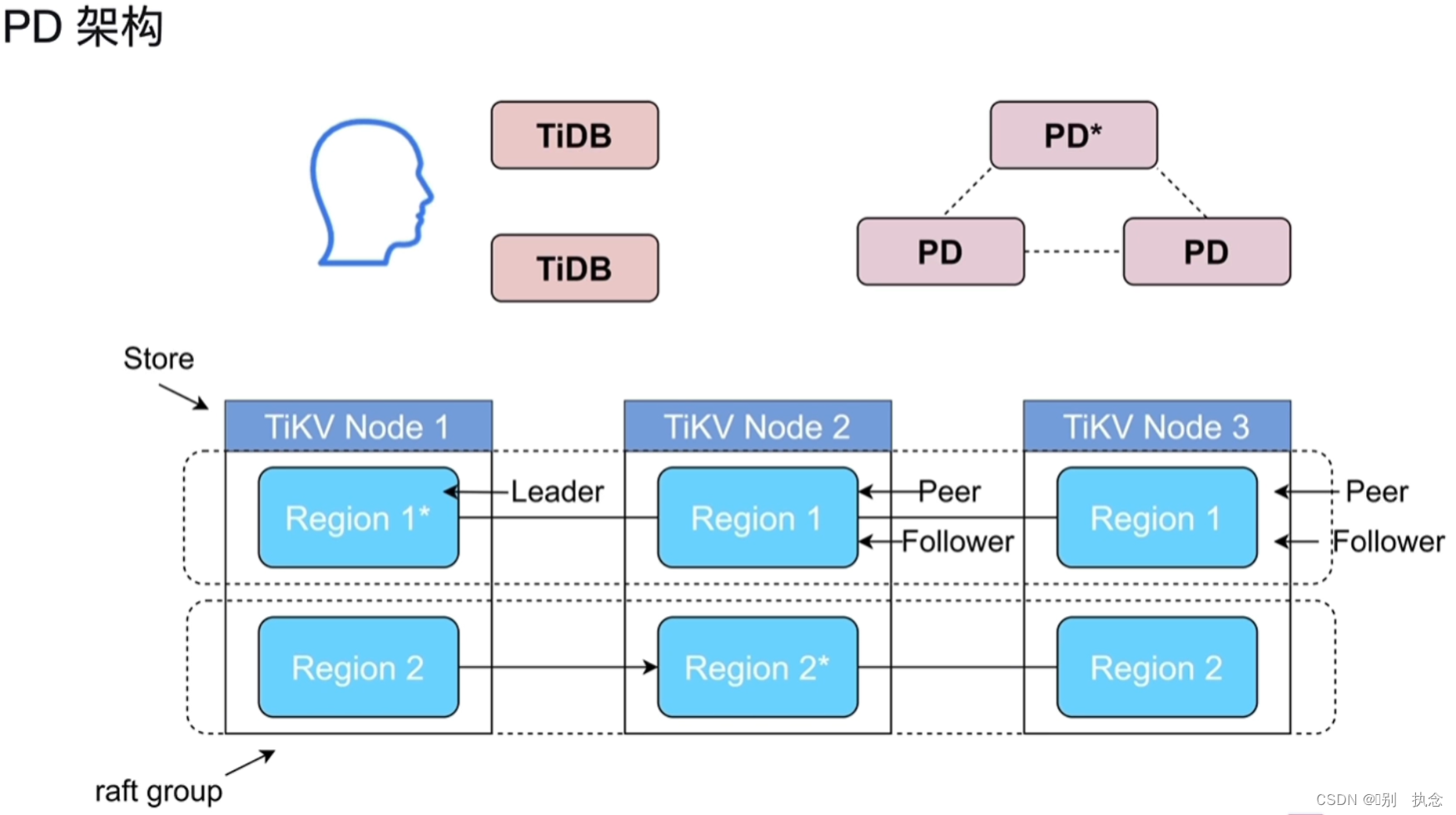
Lesson 04:PD(Placement Driver)
1.PD的架构与功能
1.1 概念理解
-
store:对应存储节点,这里的节点指的是TIKV实例,不是物理主机
-
peer/region/raft group:region是集群内部的一段连续数据,也是调度的最小单位,默认96M。每一份数据会有三个不同的副本,每一个副本就是一个peer,这三个副本就构成了一个region的raft group。对于region来说,我们会把所有的key按照字节进行排序,排序过后会产生一个大大的sort map,然后对着一个大大的sort map进行拆分,把大的sort map拆分成为一个个的region。
-
leader/follower/learner:对应region的三种不同角色,leader负责对外提供读写服务,follower从leader处通过raft协议同步数据,learer是一种特殊的角色,不参与投票
-
region split:region的分裂,比如在对表从mysql同步到tidb的时候涉及到对表的大量insert操作,这个时候region的分裂会影响导入的速度,可以通过tidb Lightning提高处理速度。
-
pending/down:对于region的特殊状态,pending状态表示与leader 的数据差异较大,不能被选举。长时间没有收到对应peer的信息那么peer的状态就会被标记为down
-
scheduler:调度策略,主要有balance-leader-scheduler/balance-region-scheduler/hot-region-scheduler和evict-leader-scheduler。
1.2 PD主要功能
-
整个集群TiKV的元数据存储
-
分配全局ID和事务ID
-
生成全局时间戳TSO
-
收集集群信息进行调度
-
提供label,支持高可用
-
提供TiDB Dashboard
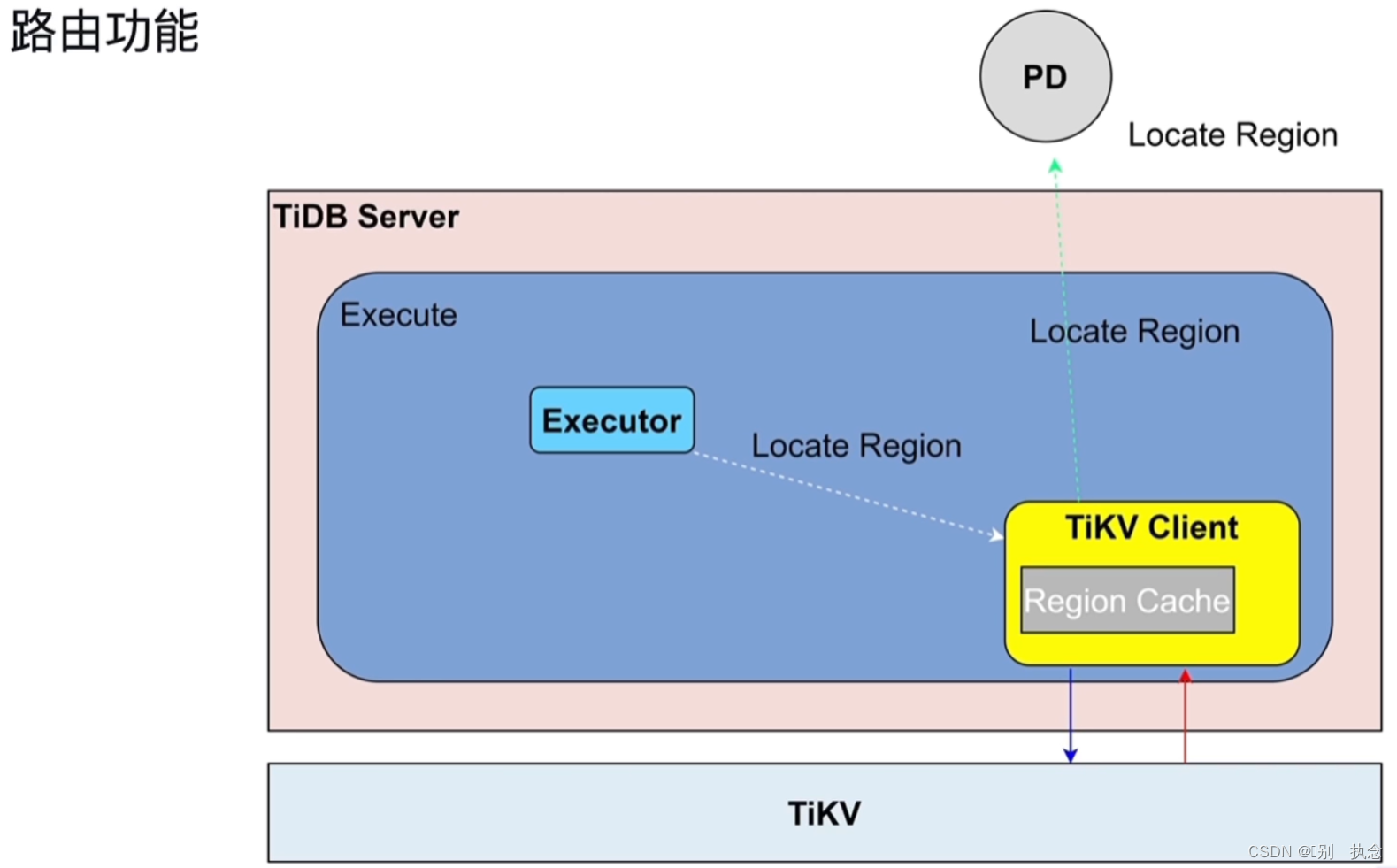
2.路由功能
2.1 路由功能
用key读数据的时候,去PD找在哪一个region。为了避免每次找,将结果缓存在TiKV Client的Region Cache的当中。backoff:如果leader变了,Region Cache就要重新载入。
2.2 TSO的分配
TSO概念:
TSO=physical time logical time
是一个int64的整型数,physical time为物理时间,即UNIX系统时间,logical time为逻辑时间1ms,将1ms分成262144个TSO数
过程:
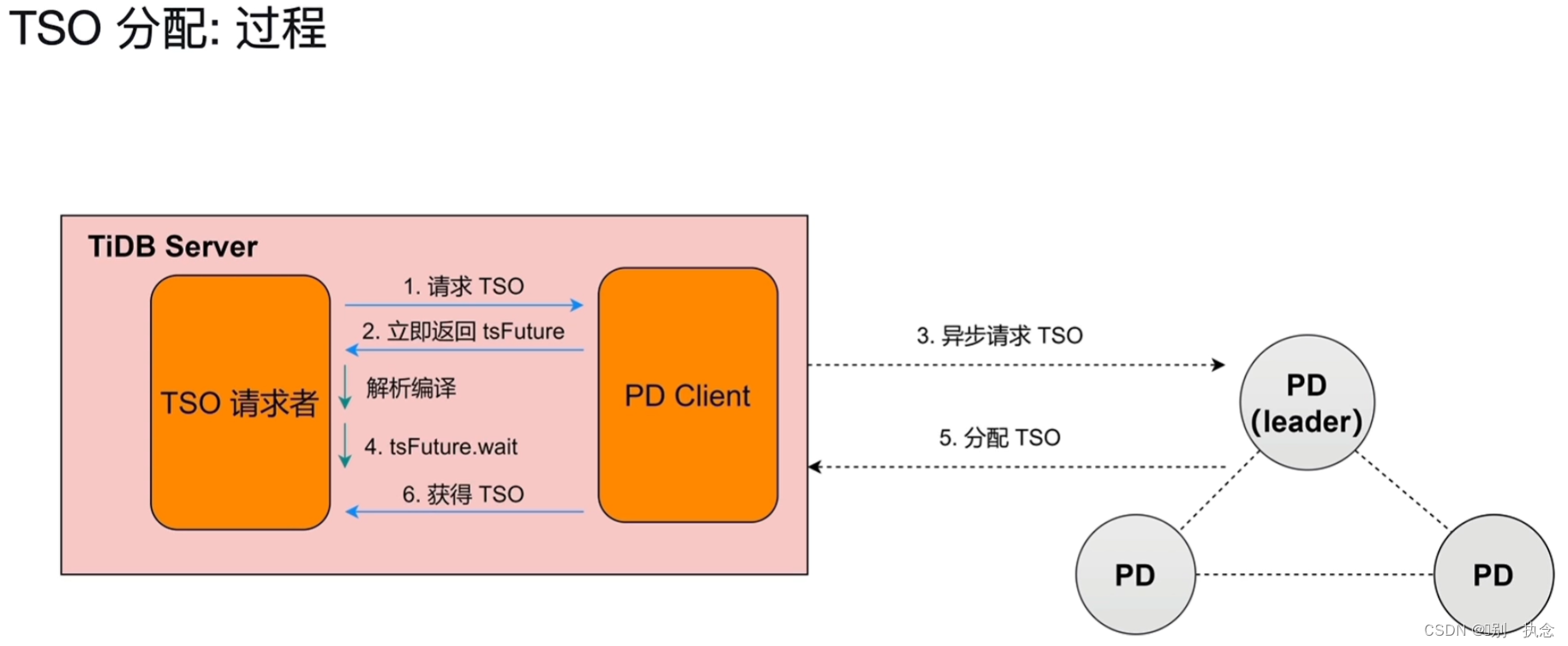
-
TiDB节点的TSO请求者(包括SQL或事务的开始和提交)将请求发送到PD Client
-
PD client本该继续将请求发送给PD的Leader节点,进行串行的同步请求,此时,PD Client会立即返回tsFuture,并将异步请求TSO发给PD节点,实现异步请求
-
TiDB在接收到tsFuture后,会继续它的工作,对SQL进行解析编译
-
处理完解析编译后,tsFuture会生成一个tsFuture.wait,等待PD分配TSO,
-
当PD分配TSO返回给PD Client后,PD Client将分配的TSO给与TiDB Server节点,执行操作。
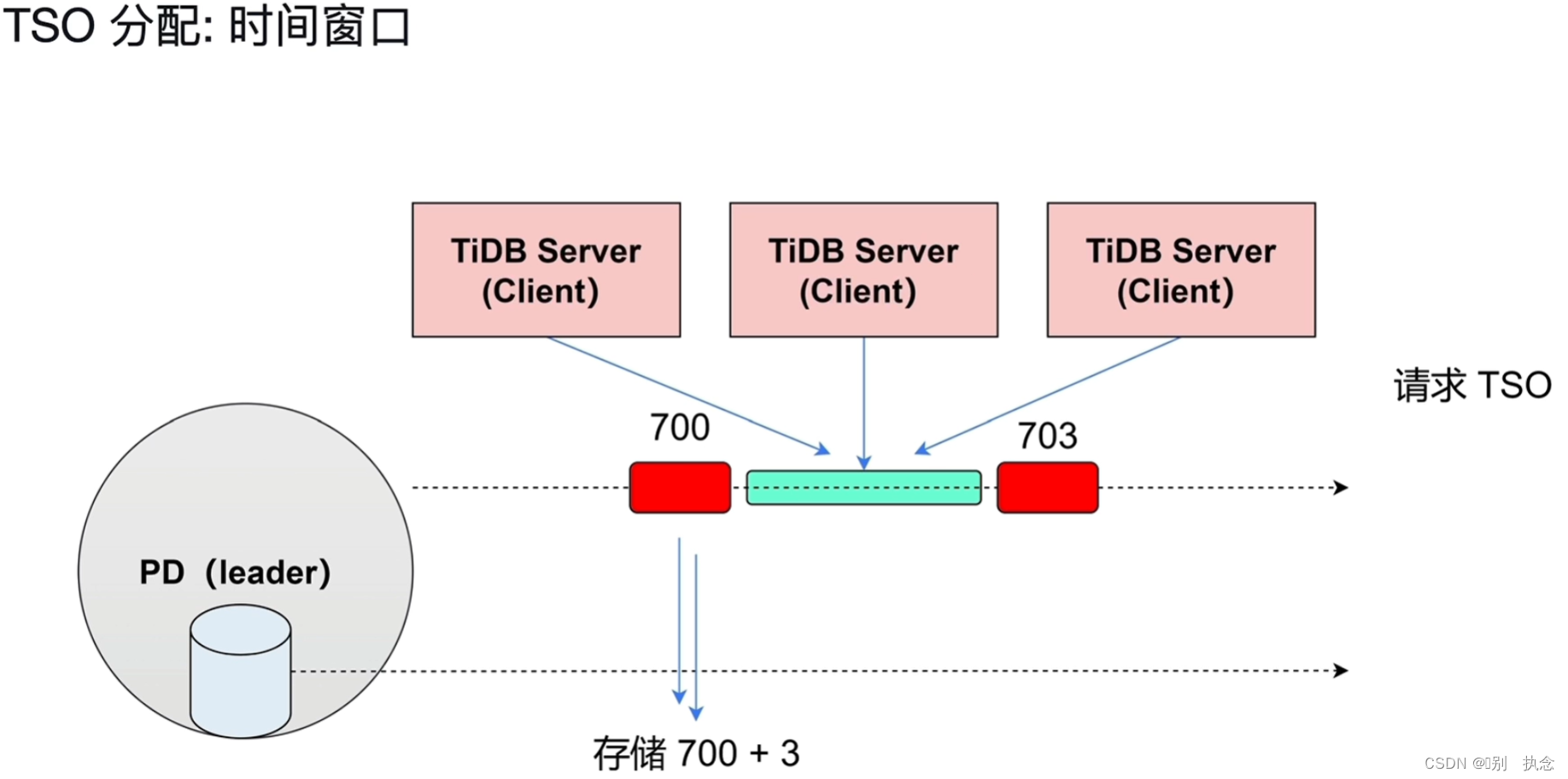
TSO请求不会来一条就发送一次,PD Client有一个批处理的功能,将一段时间内的TSO请求一并发送给PD Leader节点,这个时间称之为时间窗口。
时间窗口:解决性能问题的方法,将一段时间的TSO放入缓存,让TiDB Server去缓存队列去获取TSO,此时间为3秒钟的TSO
在高可用的情况下,如果PD的Leader节点挂了,TSO会有断层,无法保证连续性。
3.PD的调度原理
3.1 调度总流程
信息收集--生成调度--执行调度
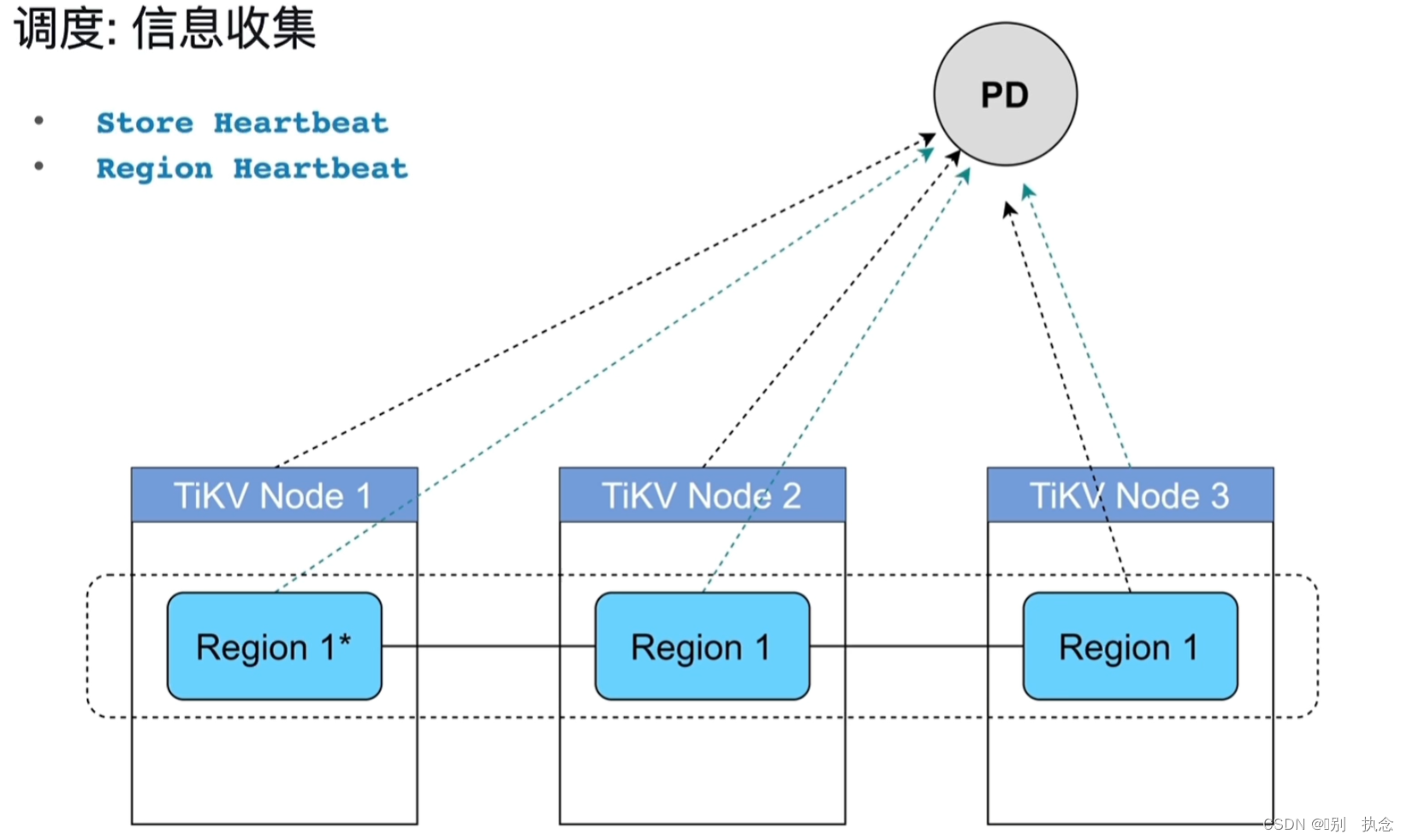
3.2 调度信息收集
信息收集:主要是通过tikv周期性发送给PD的心跳信息来获取,心跳有两种一种是storeheart记录了store的容量、空闲空间、流量等等信息;另外一种是region heartbeat记录了region层面的信息。
3.3 生成调度
生成调度:根据需求、限制和从PD采集的信息综合分析后生成调度计划
-
Balance
-
Hot Region
-
集群拓扑
-
缩容
-
故障恢复
-
Region merge
4.label和高可用性
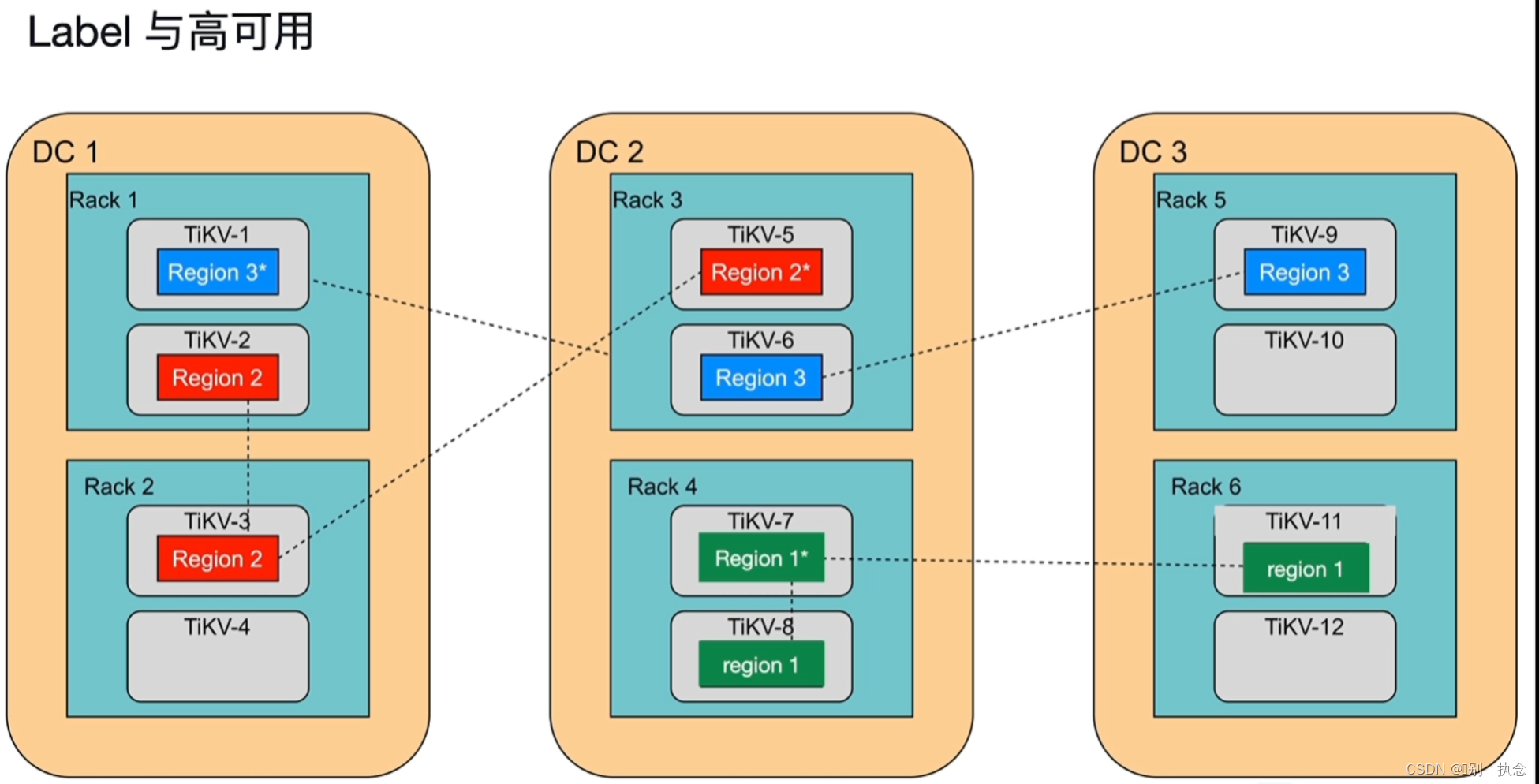
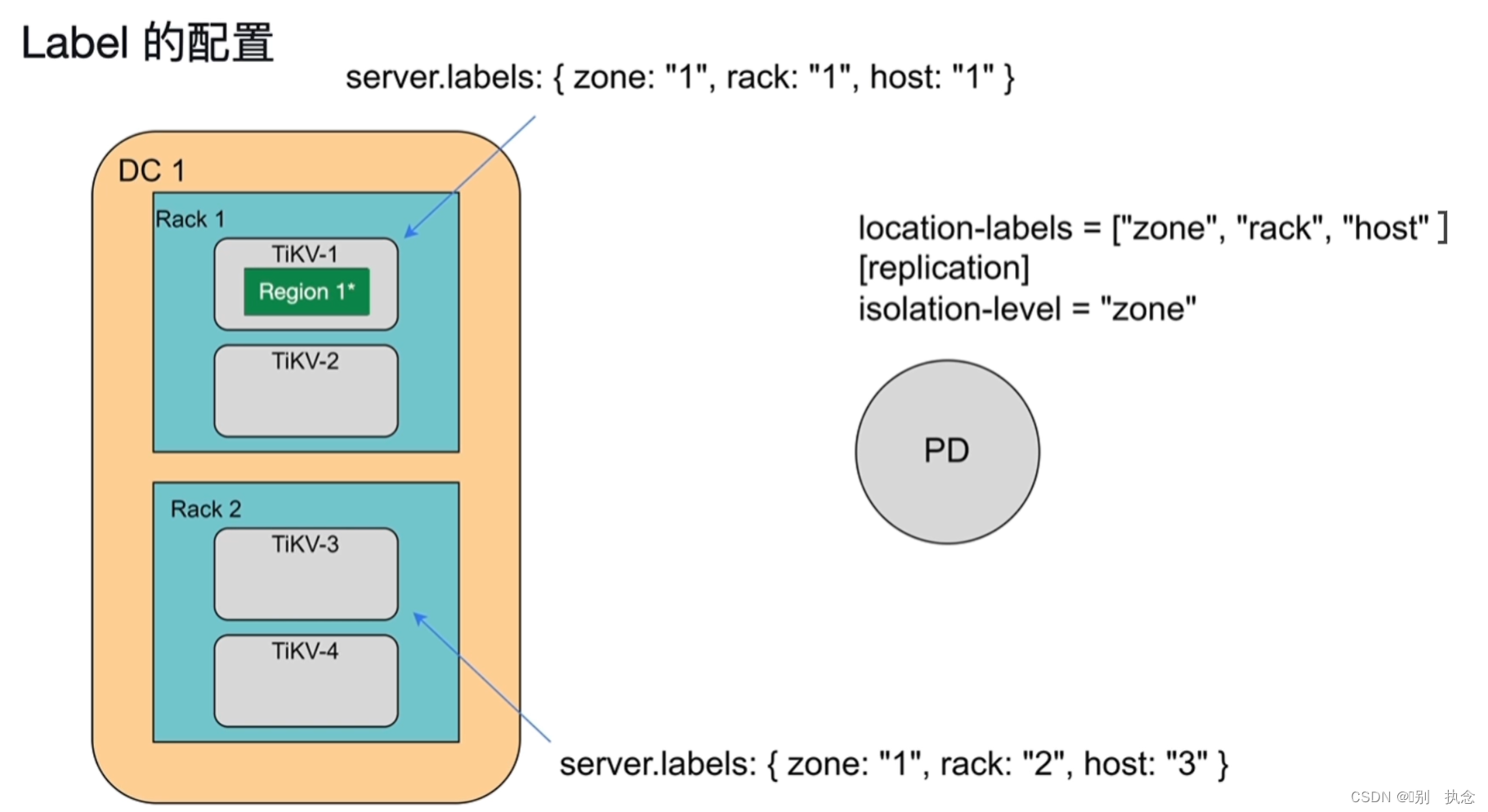
上图说明:DC1、DC2、DC3分别代表3个独立的数据中心,每个数据中心分别有两个机柜Rack,每个机柜有两个TiKV的主机,默认3副本
不同的region分布会对集群的高可用有影响
上图的region1和region2保证不了高可用,region3在三个数据中心都有,所以高可用
实现:使用打标签label的方式隔离region的分布
上图的server.labels的三个隔离级别,zone代表数据中心DC1,rack代表机柜rack,host代表服务器,isolation-level级别决定了region的不同分布。
课堂测试
1.下列关于 PD(Placement Driver)架构和功能正确的是?
A. 访问 PD 集群中的任何一个节点都可以获得 TSO
B. TiKV 会周期性地向 PD 上报状态
C. PD 会周期性地查询 TiKV 的状态,不需要 TiKV 上报,目的是为了高效
D. PD 的调度功能只能平衡 region 的分布,无法对 leader 进行调度
正确答案: B. TiKV 会周期性地向 PD 上报状态
2.关于 label ,下列说法不正确的是?
A. label 的本质是个调度系统,可以人为控制 region 副本的存放位置
B. label 需要在 PD 和 TiKV 上进行配置
C. isolation-level 要和数据中心(DC)对应,这样可以获得最大的可用性
D. 如果某个 region 的所有副本不可用,有可能造成整个 TiDB 数据库不可用
正确答案: C. isolation-level 要和数据中心(DC)对应,这样可以获得最大的可用性
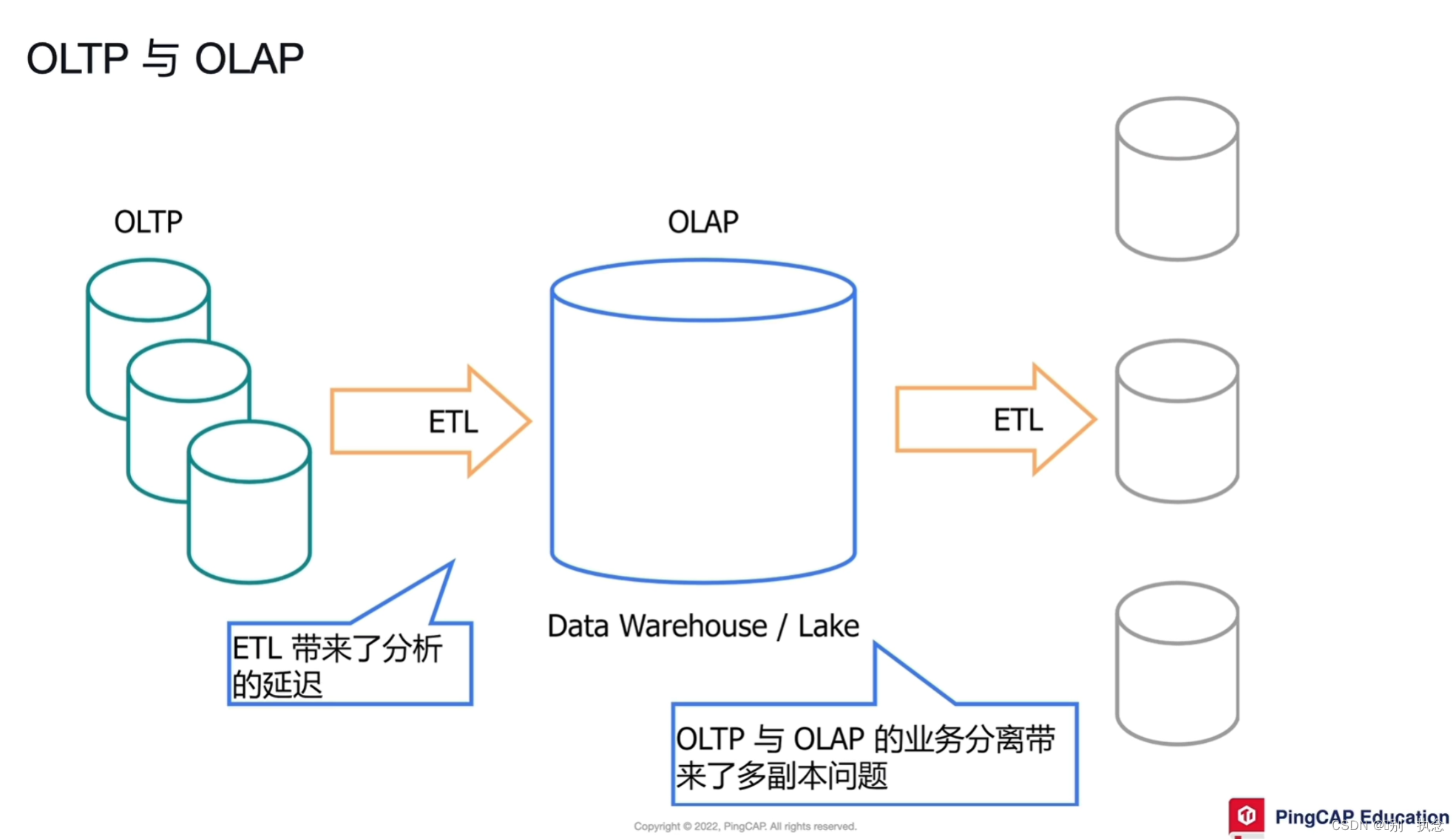
Module 02:TiDB HTAP
Lesson 05:TiDB HTAP
1.DML流程
1.1 读取的执行
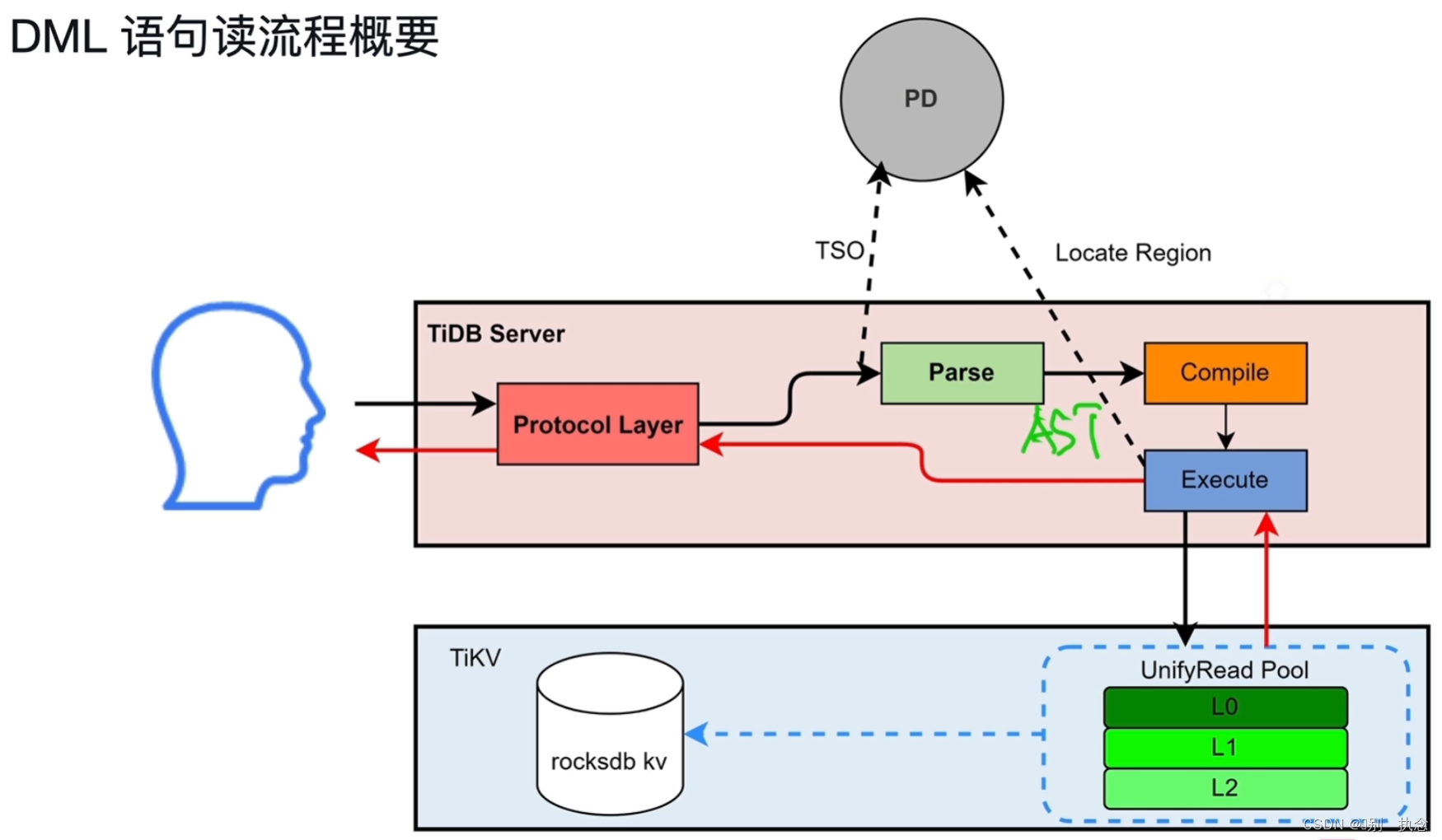
流程概要:TiDB Server中的Protocol Layer首先接收用户的SQL请求,协议层向PD申请时间戳TSO
同时将请求发送给parse模块进行解析SQL,通过词法解析与语法解析生成AST语法树给编译SQL Compile模块,根据编译生成执行计划发送给Executor,执行结果从TIKV获取数据返回给用户。
流程详情:
Protocol Layer接收到SQL请求后,会由PD Client与PD进行交互,获取TSO。
Parse模块会对SQL进行词法分析、语法分析,生成抽象语法树AST。
Compile分成几个阶段:
Compile的产物是执行计划,有了执行计划之后就由Executor进行执行。
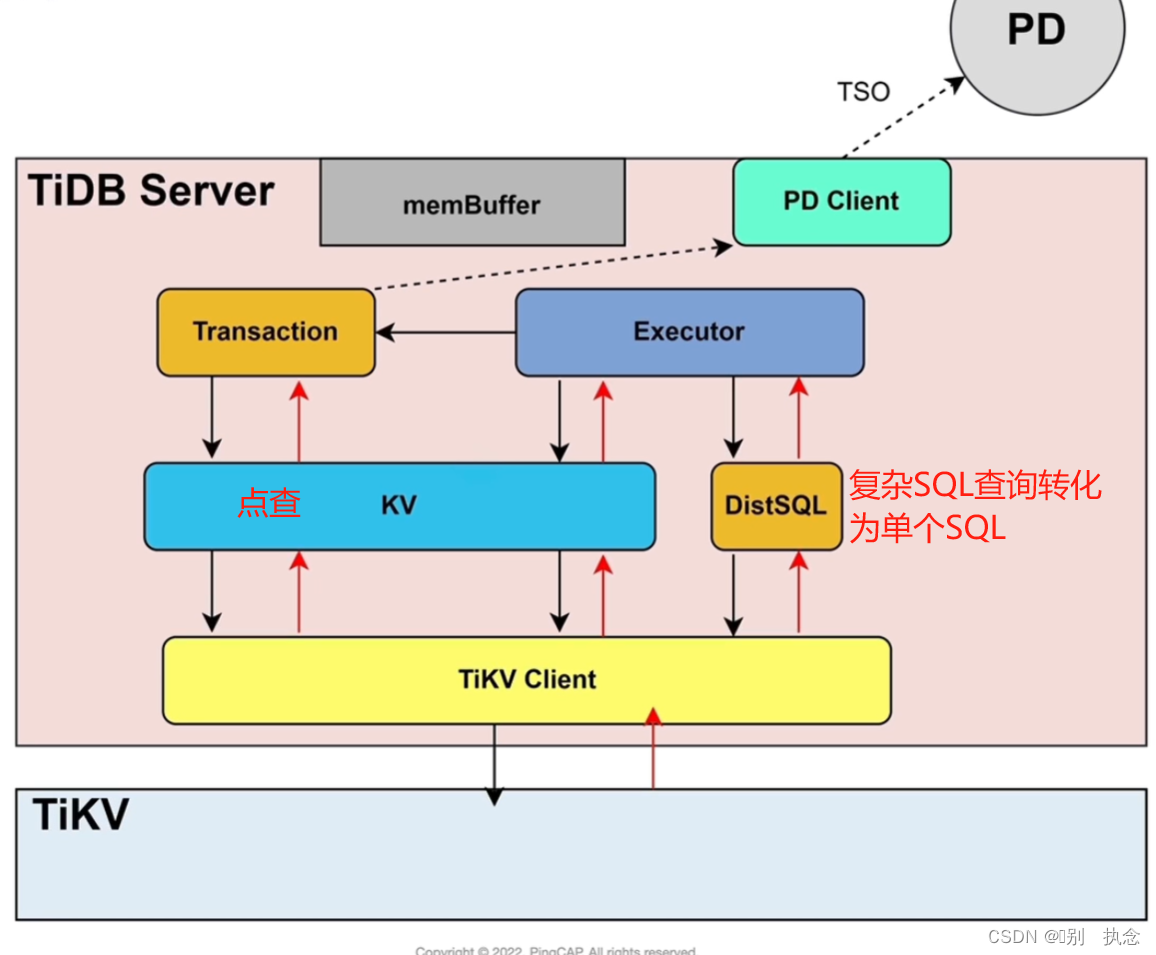
Executor先获取information schema,information schema可以预先从TiKV加载到TiDB Server。然后Executor需要从PD获取Region的元数据信息,为了减少TiDB Server与PD交互带来的网络开销、延迟,TiKV Client的region Cache可以缓存Region的元数据信息,后续就可以直接使用。
Executor执行数据读取有两种类型,点查SQL,直接读取KV;复杂SQL,需要通过DistSQL将复杂SQL转换成对单表的简单查询SQL。
TiKV接收到读取请求后,会创建一个数据快照snapshot,所有查询SQL都会进入UnifyRead Pool线程池,然后从RocksDB KV读取数据。
当数据读取完成后,数据通过TiKV Client返回给TiDB Server。
由于TiDB实现了算子下推,对于聚合操作,TiKV完成cop task,TiDB Server完成root task,也就是在TiDB Server中还需要对下推算子的聚合结果进行汇总。
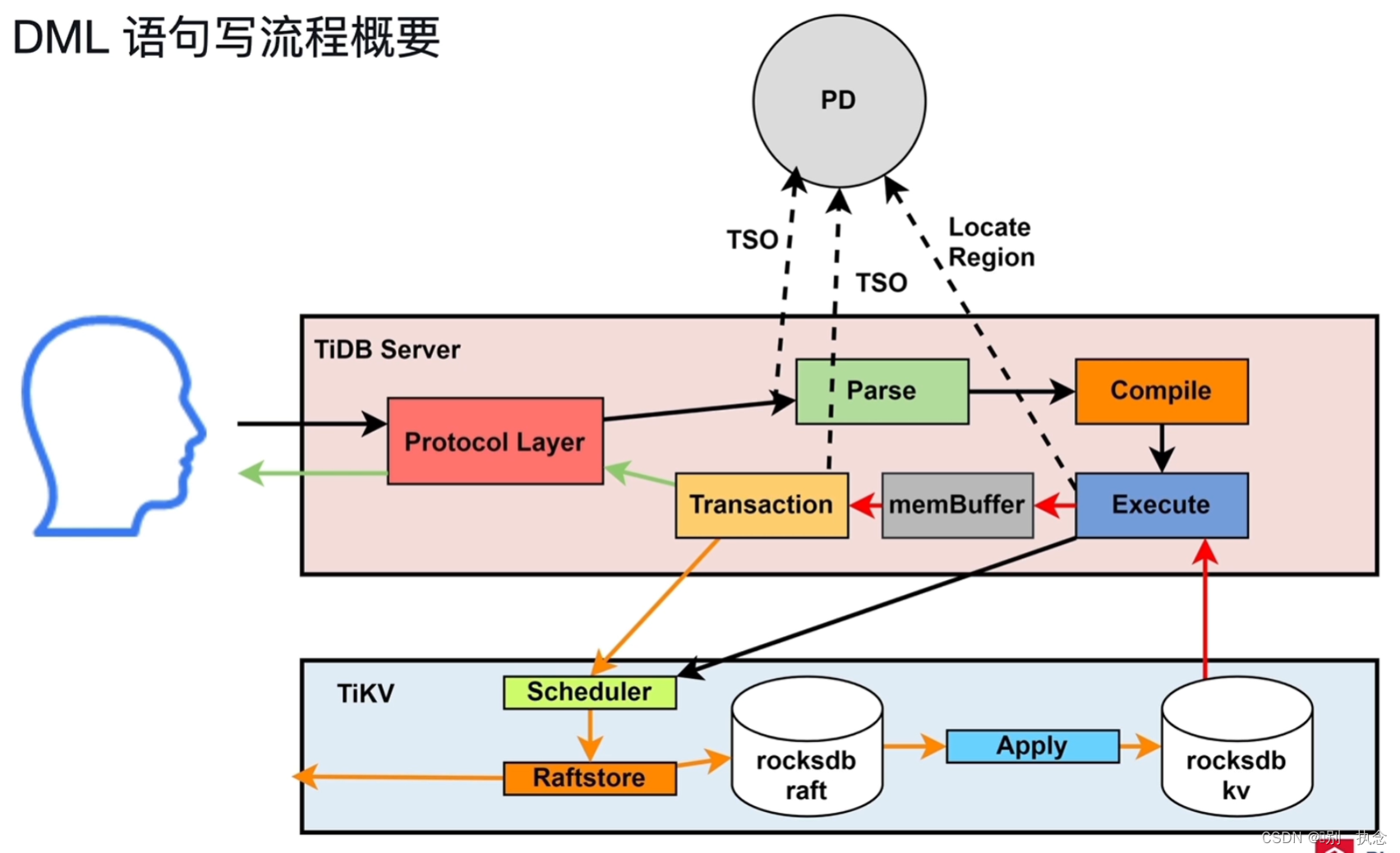
1.2 写入的执行
写流程,会先经过一次读流程,将数据读取到缓存MemBuffer中,然后再进行数据修改,最后进行两阶段提交进行数据写入。
Transaction执行两阶段提交。
Transaction按行读取memBuffer的数据进行数据写入,事务包含两个TSO,一个是事务开始TSO,一个是事务提交TSO。
写请求发送给TiKV的Scheduler,Scheduler是接收并发处理的,所需需要负责协调冲突写入(两个会话并行写相同的Key),冲突写入采用分配latch,谁获得latch谁执
行写操作的方式解决冲突。无冲突的写入,交Raftstore,完成Raft日志写入过程,涉及本地append、replicate、commited、apply等过程。
2.DDL流程
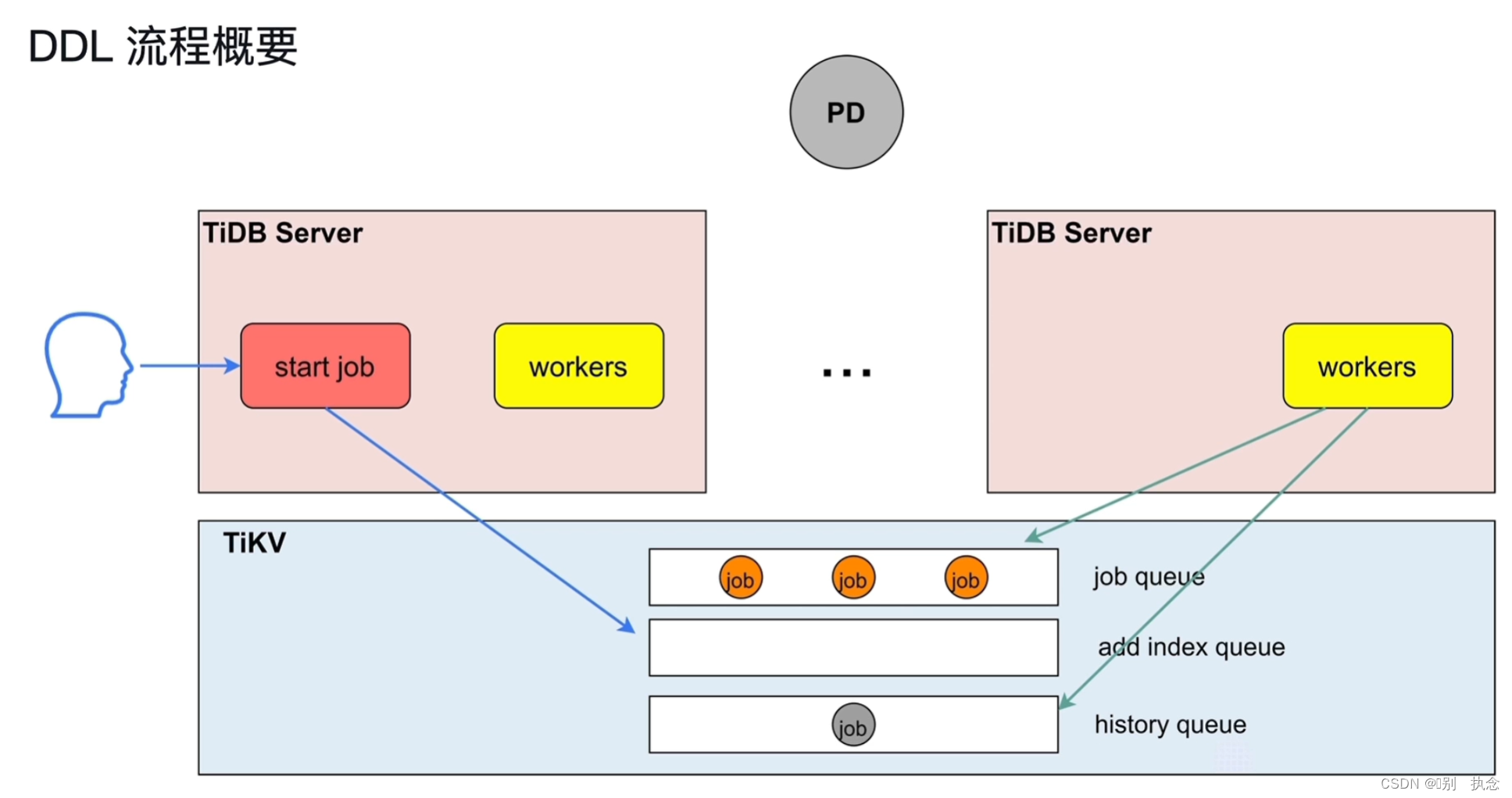
2.1 online DDL
TiDB Server接收到用户的DDL请求,start job模块将操作写入队列,由TiDB Server的Owner角色的workers模块负责执行队列中的DDL语句。
workers从job queue队列中获取待执行的DDL语句,执行,执行完成后将其放到history queue队列中。
TiDB支持Online DDL,也就是DDL不锁表,不阻塞读、写。
同一时刻,只有一个TiDB Server的角色是Owner角色的,只有Owner角色的TiDB Server的workers才可以执行DDL。schema load负责将最新的表结构信息加载到TiDB Server。
Compile生成的执行计划,交给start job,start job先检查本机节点的角色是否是Owner,如果是,则可直接由本机workers直接执行,如果不是,则start job将DDL操作封装成job加入到job queue队列中。如果DDL操作是对索引的操作,则job会加入到add index queue。
Owner的workers会定时扫描job queue,发现queue中有job就获取执行,执行完成后将job加入到history queue中。
Owner角色由PD协调,在TiDB Server之间是轮询切换,所以总体来说,每个TiDB Server都有机会成为Owner。
课堂测试
1.下列关于 DML 语句读写说法正确的是?( 选 2 项 )
A. Region Cache 的主要作用是缓存热数据,减少访问 TiKV 的次数
B. 二阶段提交在获取事务开始的 TSO 和提交的 TSO 时,都是由 TiDB Server 完成的
C. schedule 模块采用 latch 来控制当前正在写的数据不被读取
D. 在写操作中,锁信息也会被写入到 RocksDB KV 中
正确答案: B. 二阶段提交在获取事务开始的 TSO 和提交的 TSO 时,都是由 TiDB Server 完成的、D. 在写操作中,锁信息也会被写入到 RocksDB KV 中
2.关于 DDL 语句的执行流程,下列说法正确的是?
A. DDL 语句不可以在 TiDB 中并行执行
B. 同一时刻,不可以有多条 DDL 语句在等待执行
C. 同一时刻,只有一个 TiDB Server 可以执行 DDL 语句
D. 等待执行的 DDL 语句被持久化在 TiDB Server 的存储中
正确答案: C. 同一时刻,只有一个 TiDB Server 可以执行 DDL 语句
Lesson 06:TiDB数据库HTAP概述
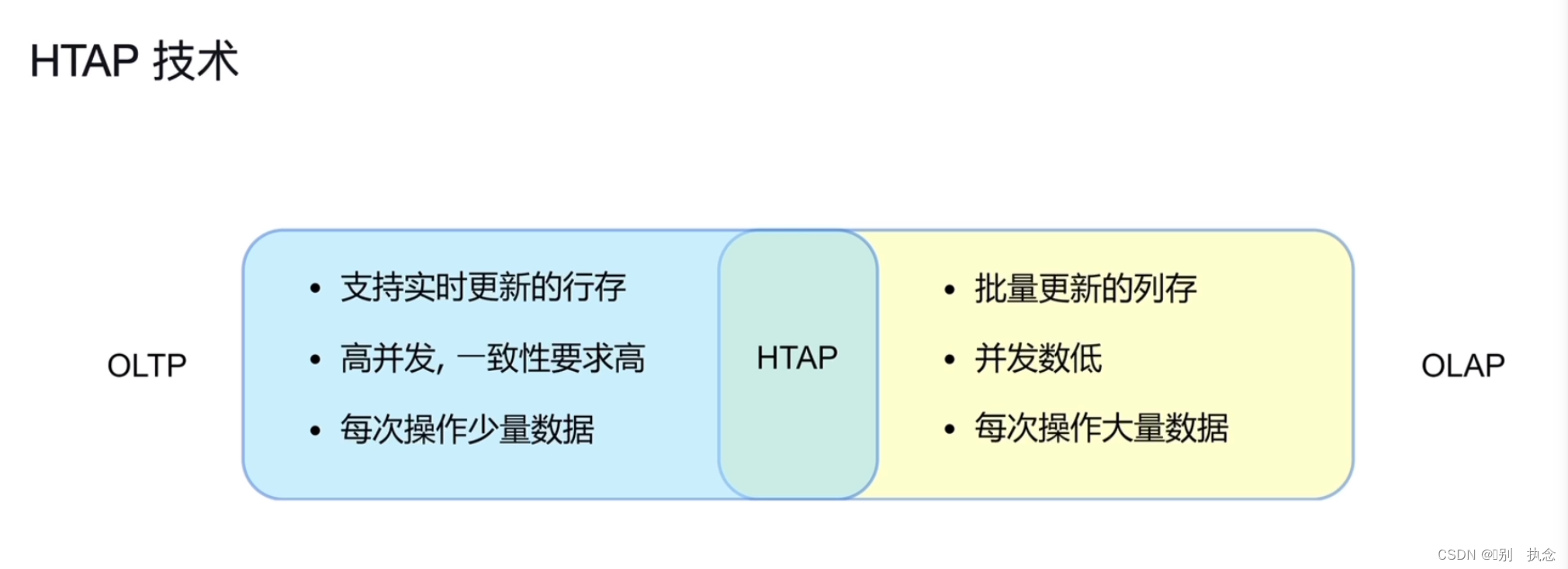
1.HTAP技术
HTAP的要求:
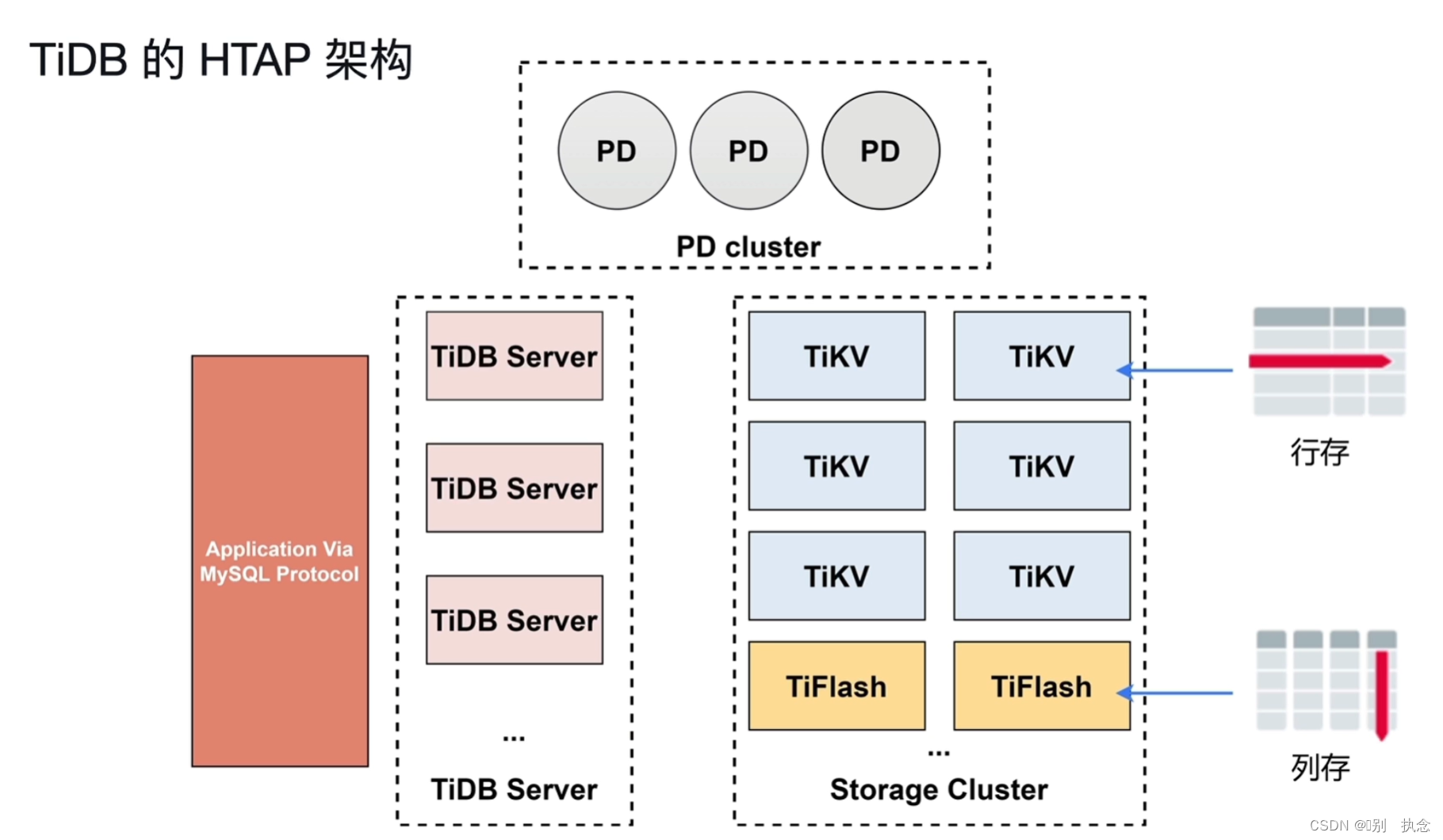
2.TiDB数据库的HTAP架构
Tiflash特性:
3.TiDB数据库的HTAP核心特性
-
行列混合
-
列存 (TiFlash) 支持基于主键的实时更新
-
TiFlash 作为列存副本
-
OLTP 与 OLAP 业务隔离
-
智能选择(CBO 自动或者人工选择)
-
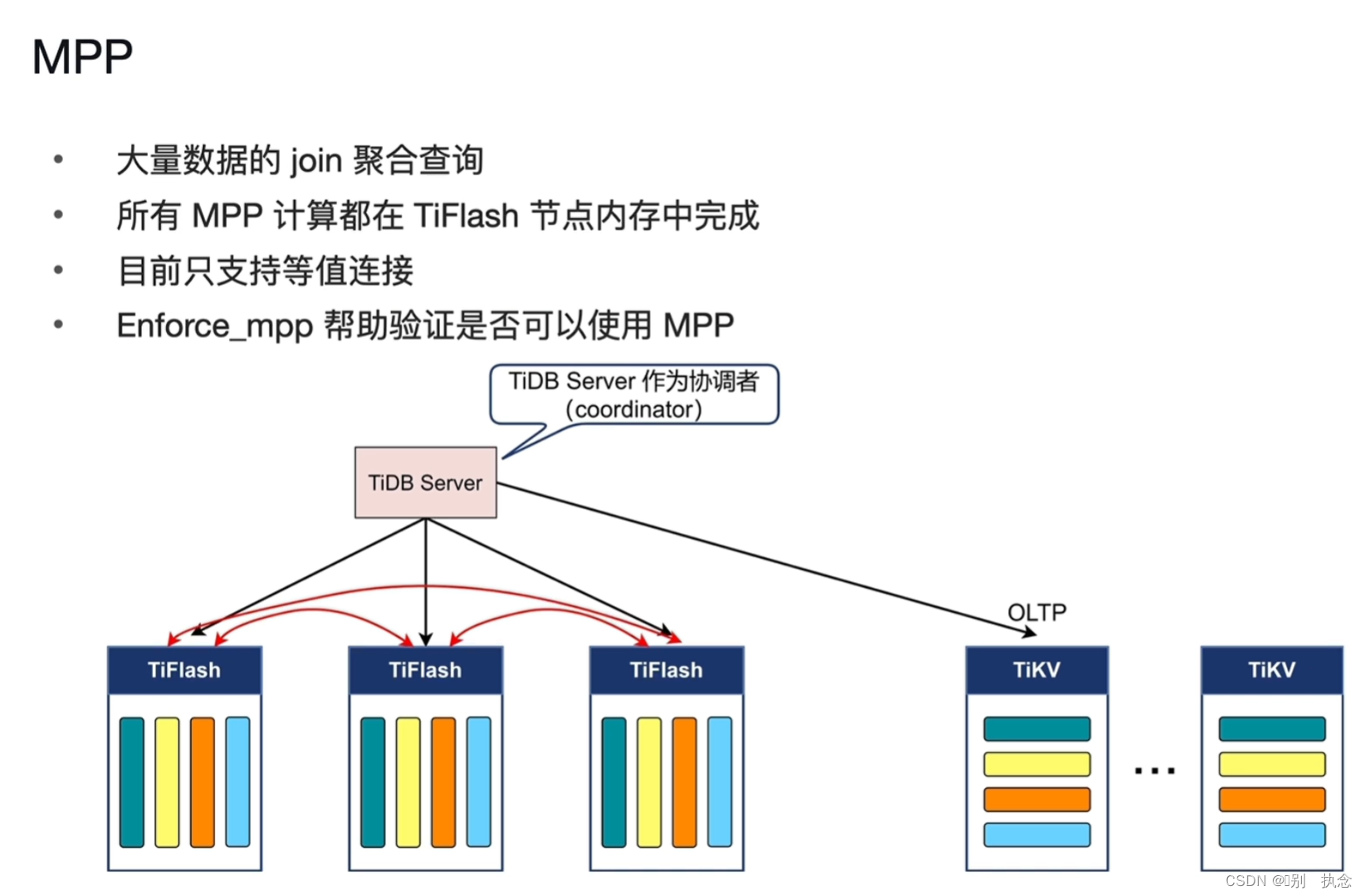
MPP 架构
MPP特点
MPP(Massively Parallel Processing,
大规模并行处理
)
架构,
是一种分布式数据处理技术,能够通过将工作负载分散到多个节点上来提高数据处理性能。
与传统的共享架构不同,MPP采用非共享架构(Share Nothing),将单机数据库节点组成集群,每个节点拥有独立的磁盘和内存系统,通过专用网络或商业通用网络连接彼此、协同计算,从而提供整体数据处理服务。在设计上,MPP架构优先考虑一致性(Consistency),其次考虑可用性(Availability),同时尽量做到分区容错性(Partition Tolerance)。
TiDB的MPP架构只存在于TiFlash模块中。
MPP架构中,每个TiFlash作为MPP worker进行并行计算
MPP工作原理:
举例说明:现有SQL语句如下:
select count(*) from order,product
where order.pid=product.pid
and sub_str(order.dic,3)='7C0'
and product.pct_date>'2021-09-30'
order by order.state;
过滤:mpp根据以上SQL,会先并发将sub_str(order.dic,3)='7C0'和product.pct_date>'2021-09-30'的数据
过滤并存放到TiFlash的内存中
数据交换:使用hash函数根据连接条件计算hash值,根据hash值将相关的数据进行
数据交换,集中在一个TiFlash中
JOIN:
数据交换后,所有连接操作均在同一个TiFlash节点中
聚合:
类似的,对于聚合操作,利用hash函数根据聚合条件order by order.state
计算hash值,根据hash值将相关的数据再次进行数据交换,集中在一个TiFlash节点中,
根据各个TiFlash节点的计算结果进行
聚合
后返回TiDB Server
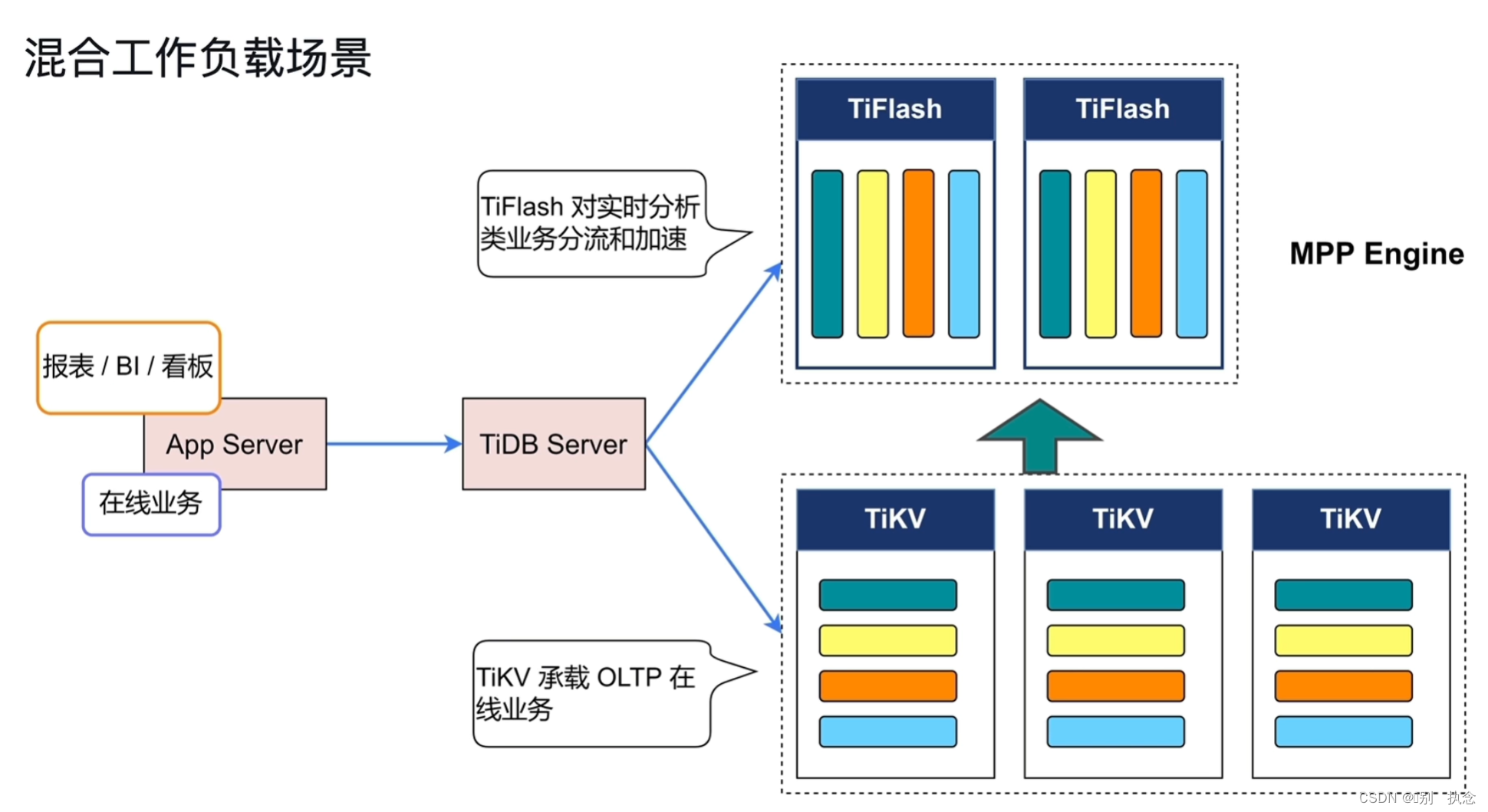
4.混合工作负载场景
在混合工作负载场景下,TiDB会根据业务类型,将OLTP和OLAP的分别给到适合的模块中去处理业务。
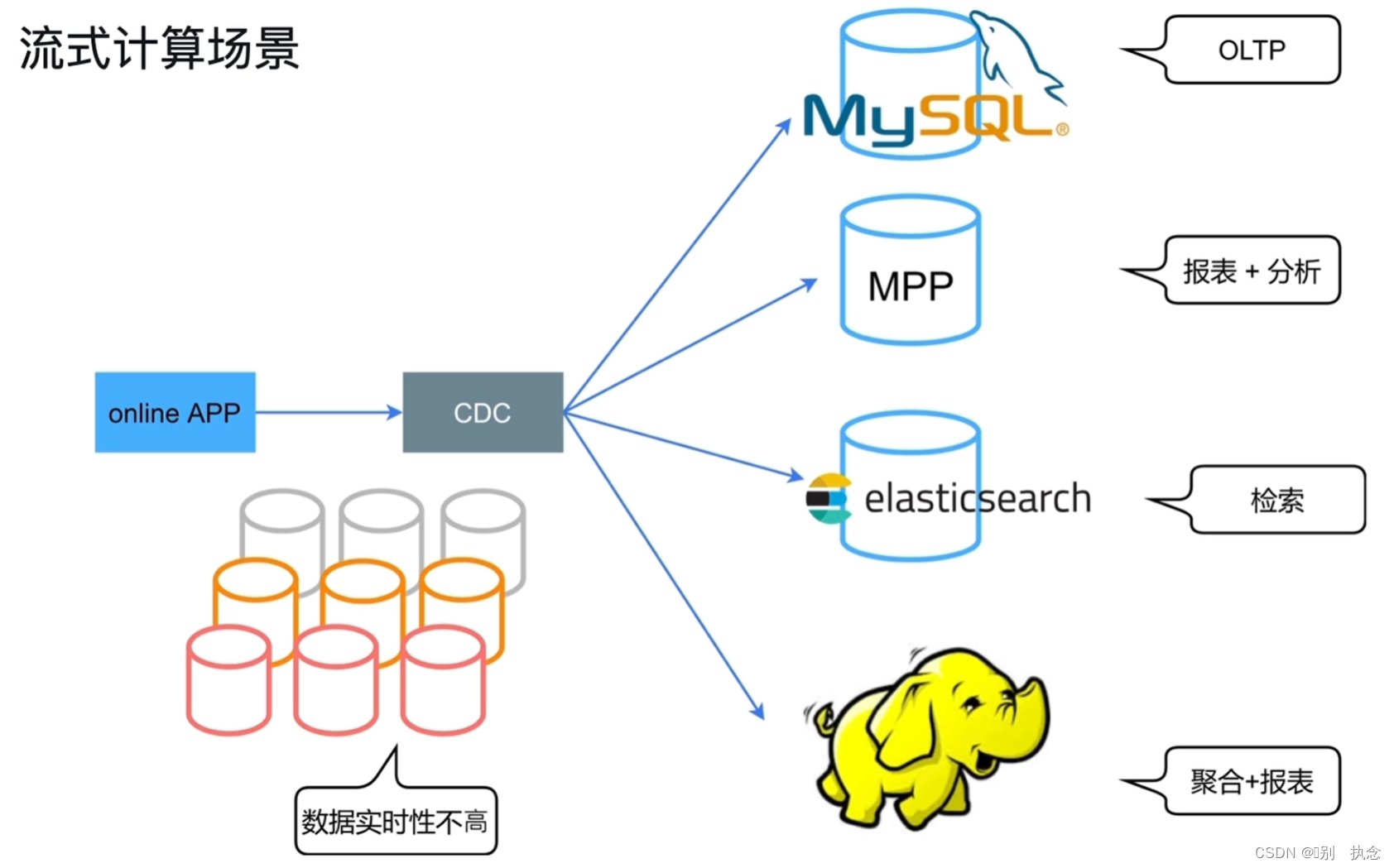
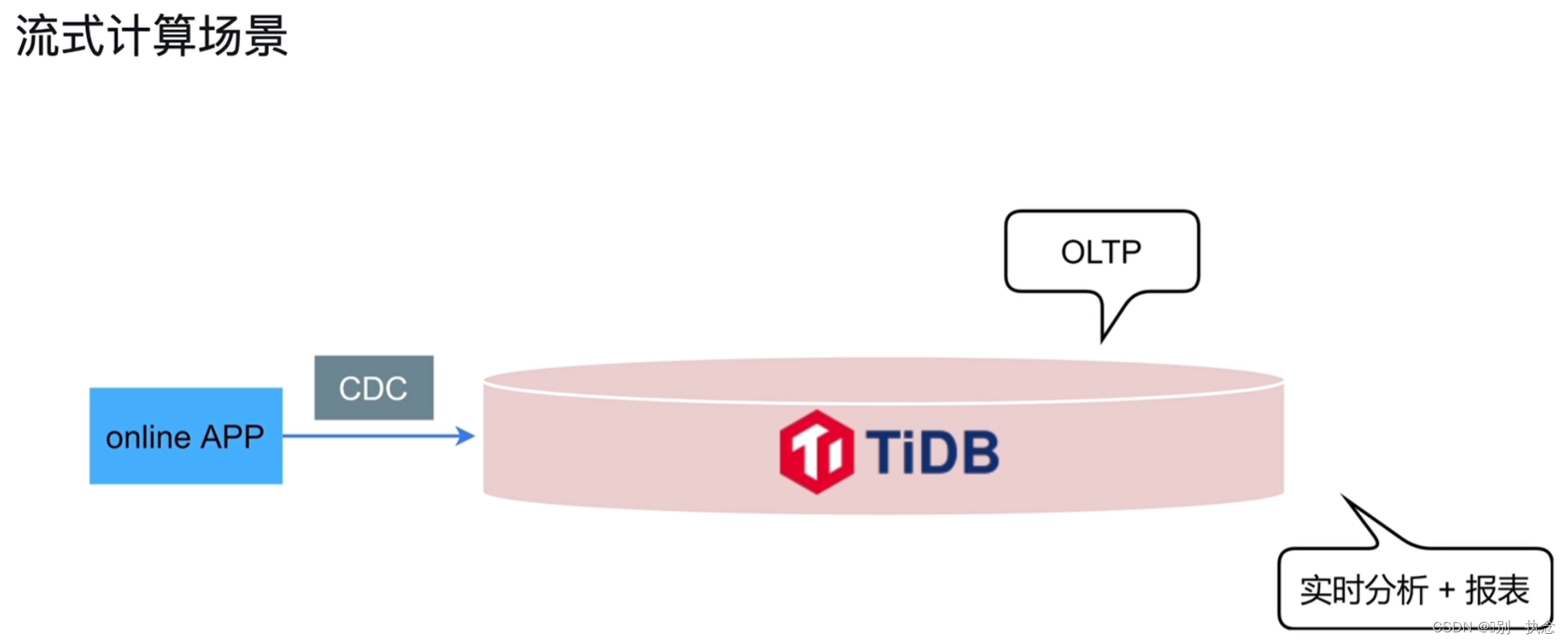
5.流式计算场景
传统场景,需将不同类型的业务分门别类的传输到每个不同功能的库中,在TiDB中,会将所有数据都传输过去,由TiDB进行HTAP操作
课堂测试
1.下面属于 HTAP 场景特点的是?(请选择 3 项)
A. 在故障恢复方面可以做到 RPO = 0
B. 支持分区特性
C. 支持在线业务高并发
D. 同时支持 OLTP 和 OLAP 业务
E. 能够读取到一致性的数据
正确答案: C. 支持在线业务高并发、D. 同时支持 OLTP 和 OLAP 业务、E. 能够读取到一致性的数据
2.关于 MPP 架构,下列说法不正确的是?
A. MPP 架构的中间结果都在内存中
B. MPP 架构可以作用于 TiKV 和 TiFlash 上的数据
C. MPP 架构目前不支持非等值 join
D. MPP 架构可以对聚合、JOIN 等操作加速
正确答案: B. MPP 架构可以作用于 TiKV 和 TiFlash 上的数据
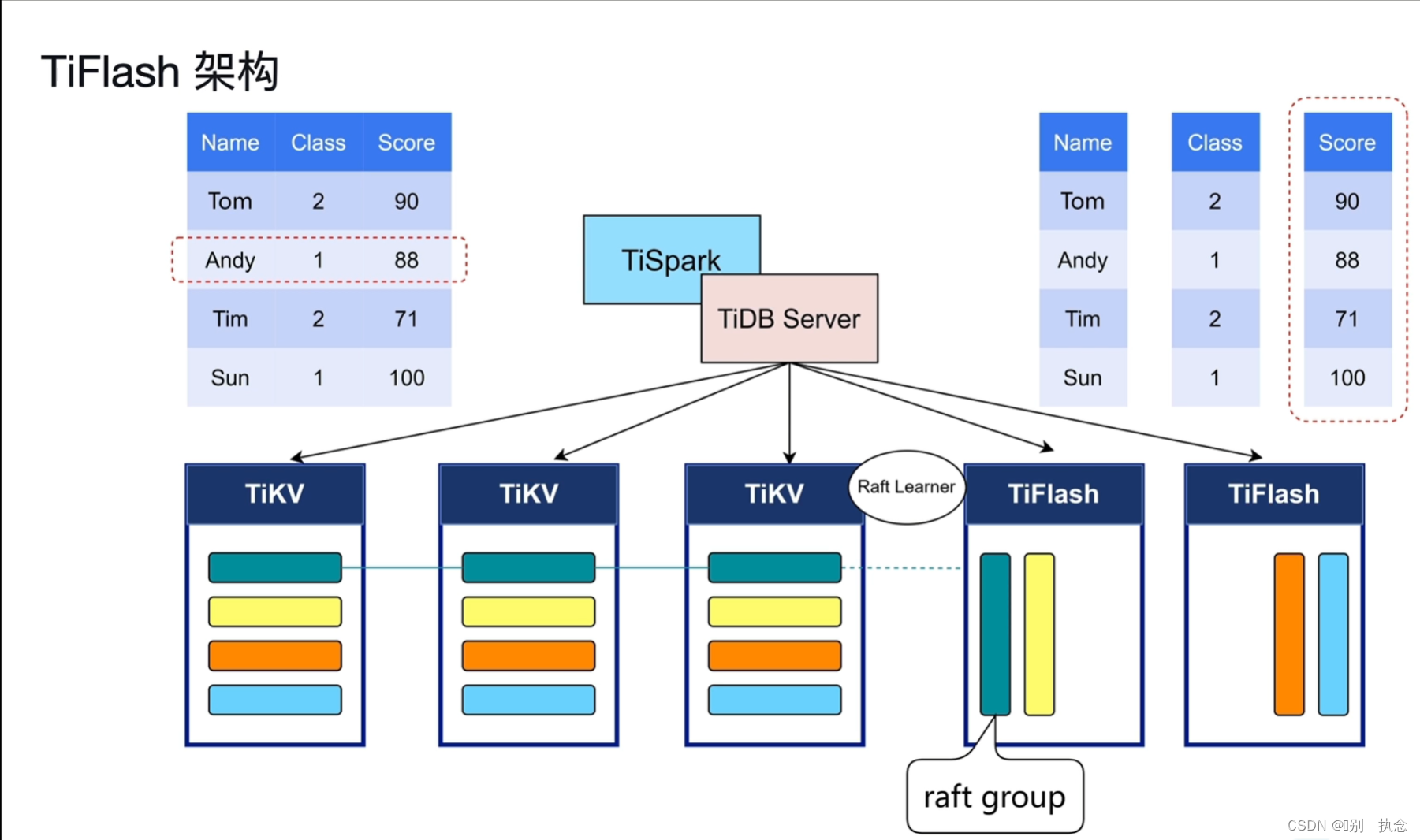
Lesson 07:TiFlash
1.TiFlash的架构和特点
2.TiFlash主要功能
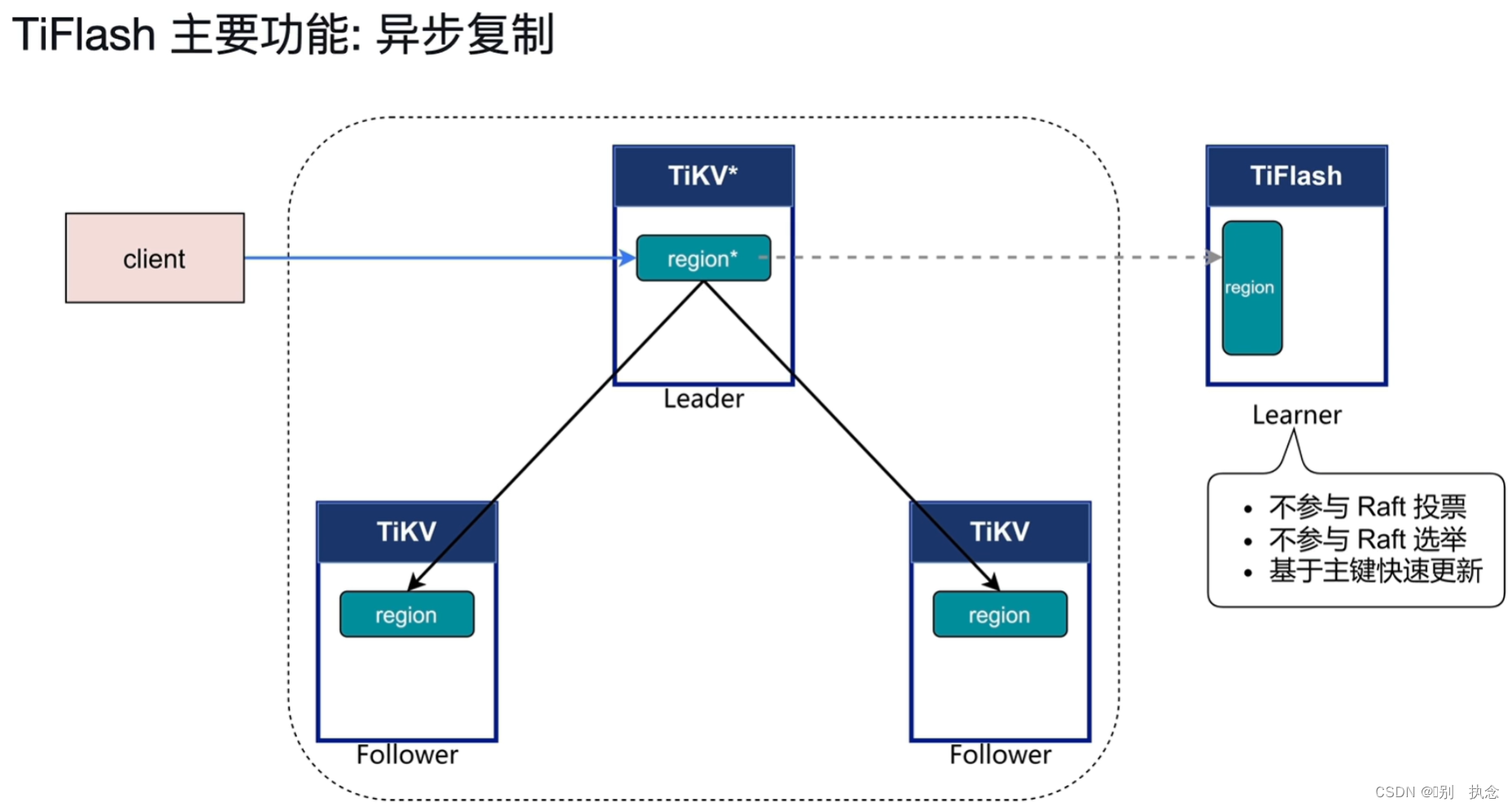
2.1 异步复制
Learner不参与Raft投票、选举,并基于主键进行快速更新。
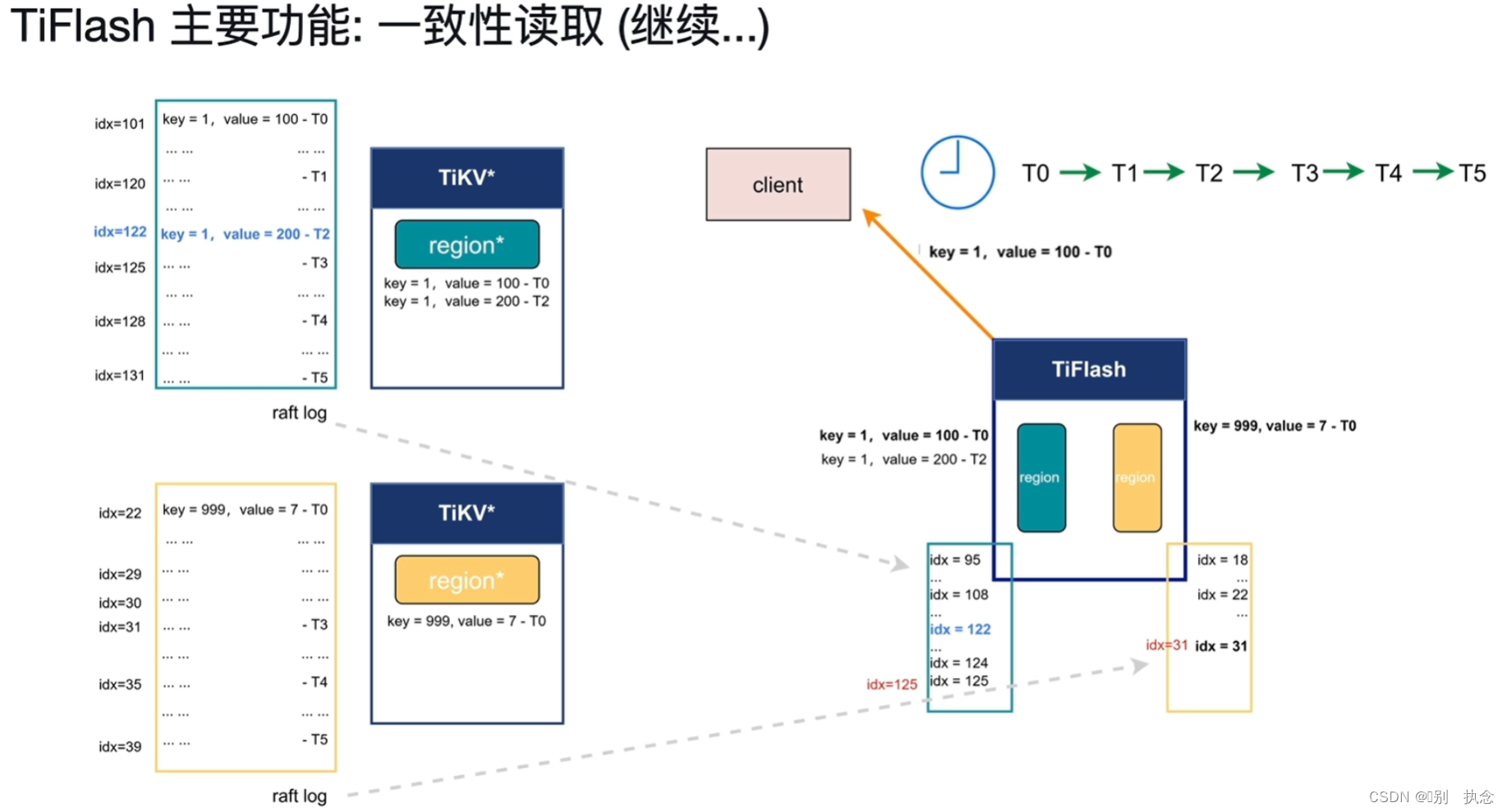
2.2 一致性读取
从T0时刻到T5时刻,TiFlash只需轻量级的去询问
raft log的idx,并等待raft log在TiKV中将变更走到相应的idx对应值即可同步,确保一致性读取。
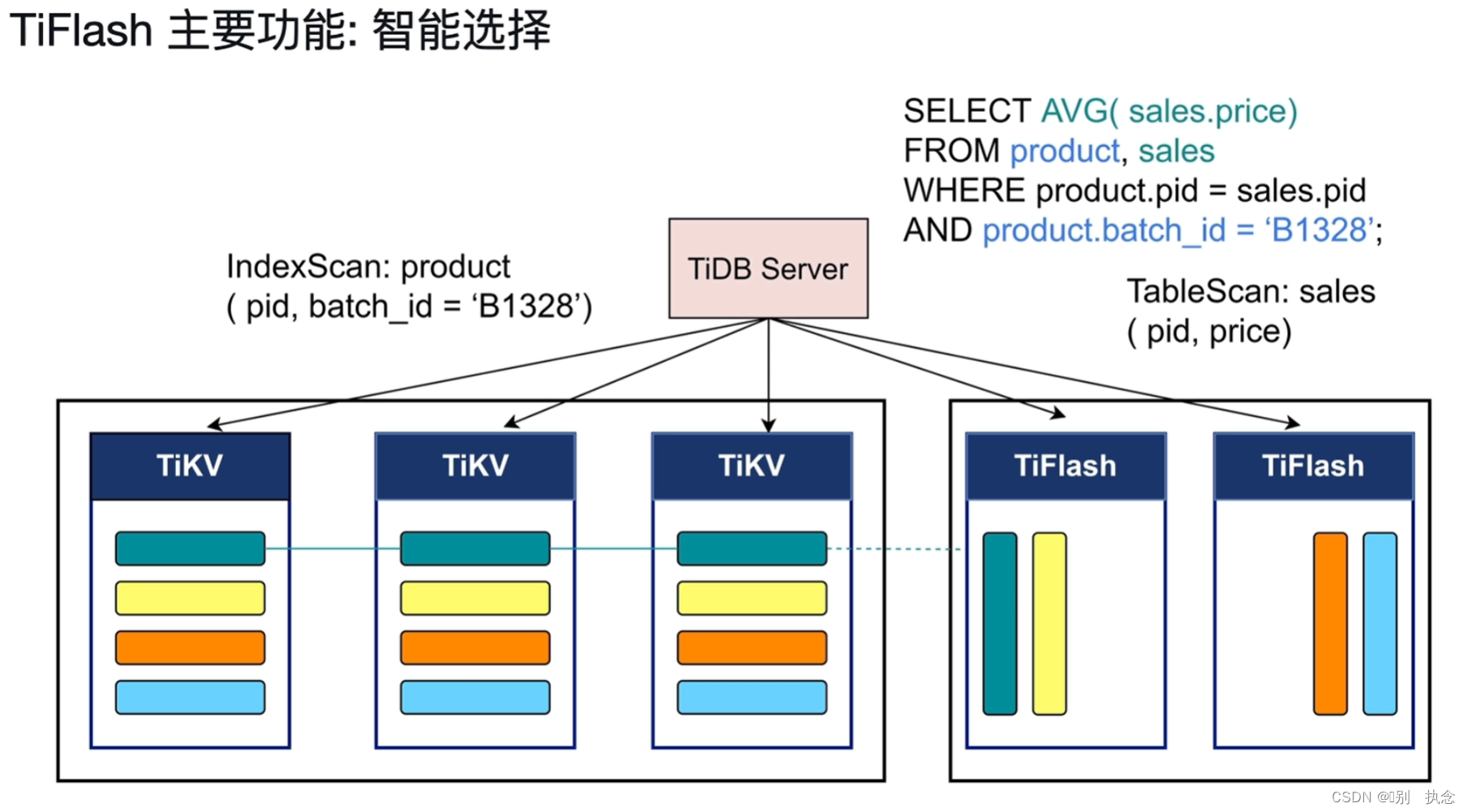
2.3 引擎智能选择
表扫描和索引扫描根据不同的SQL
2.4 计算加速
TiFlash的列存是对SQL的一种计算加速,同时,还可以将TiDB的一部分计算下推,承担一部分计算任务的并行加速处理
课堂测验
1.下面属于TiFlash核心特性的是?(请选择3项)
A.采用行存+列存的混合存储方式
B.region支持raft投票和选举
C.TiFlash采用异步复制来保证和TiKV一致
D.在TiKV上写入数据成功后,在TiFlash上可以一致性读取
E.CBO基于成本选择在TiFlash或者TiKV上执行SQL
答案:C,D,E
解析:A:TiFlash负责列存,TiKV负责行存;B:TiFlash不参加TiKV的选举,投票
2.关于TiFlash的使用,描述不正确的是?
A.TiFlash不善于处理高并发,QPS一般不应过高
B.SQL语句执行中,要不然数据完全从TiKV中读取,要不然完全从TiFlash中读取
C.MPP中表连接前的过滤和交换完全是在TiFlash节点上完成的
D.在读取TiFlash 中数据的时候,我们需要通过TiKV中的数据确认一致性
答案:B
解析:A:TiFlash承载低并发的OLAP,且QPS<50;B:根据执行代价,SQL语句部分由TiKV执行,部分由TiFlash执行;C:MP在TiFlash上的聚合和连接操作的加速,此前的过滤和数据交互同样在TiFlash执行;D:读取TiFlash中的数据,TiFlash向TiKV发起进度校验
Module 03:TiDB 6.0新功能
Lesson 08:TiDB 6.0新功能
1.Placement Rules in SQL
TiDB 6.0版本提供的基于SQL接口的
数据放置框架(Placement Rules in SQL)功能,支持针对任意数据提供副本数、角色类型、放置位置等维度的灵活调度管理能力,这使得在多业务共享集群、跨 AZ 部署等场景下,TiDB 能够提供更灵活的数据管理能力,满足多样的业务诉求。
1.1 Placement Rules in SQL前后对比
Placement Rules in SQL之前:
-
跨地域部署的集群,无法本地访问
-
无法根据业务进行隔离资源
-
难以按照业务等级配置资源和副本数
Placement Rules in SQL之后:
-
跨地域部署的集群,支持本地访问
-
根据业务隔离资源
-
按照业务等级配置资源和副本数
1.2 Placement Rules in SQL使用步骤
(1)设计业务拓扑,为不同的TiKV实例设置标签
server.labels:{zone:"BeiJing",rack:"Rack-1",host:"TiKV-1"}
(2)创建Placement Policy(放置策略)
可以定义leader角色、follower角色的region的放置位置和副本数量
(3)设置数据对象的Placement POLICY
上图SQL解释:将T5表创建,并按照(2)中的PLACEMENT POLICY P1的策略放置数据
1.3 Placement Rules in SQL的应用:
(1)精细化数据放置,
控制本地访问和跨区域访问
(2)指定
副本数,提高重要业务的可用性和数据可靠性
(3)将业务按照等级、资源需求或数据生命周期进行
隔离
(4)业务数据
整合,降低运维成本和复杂度
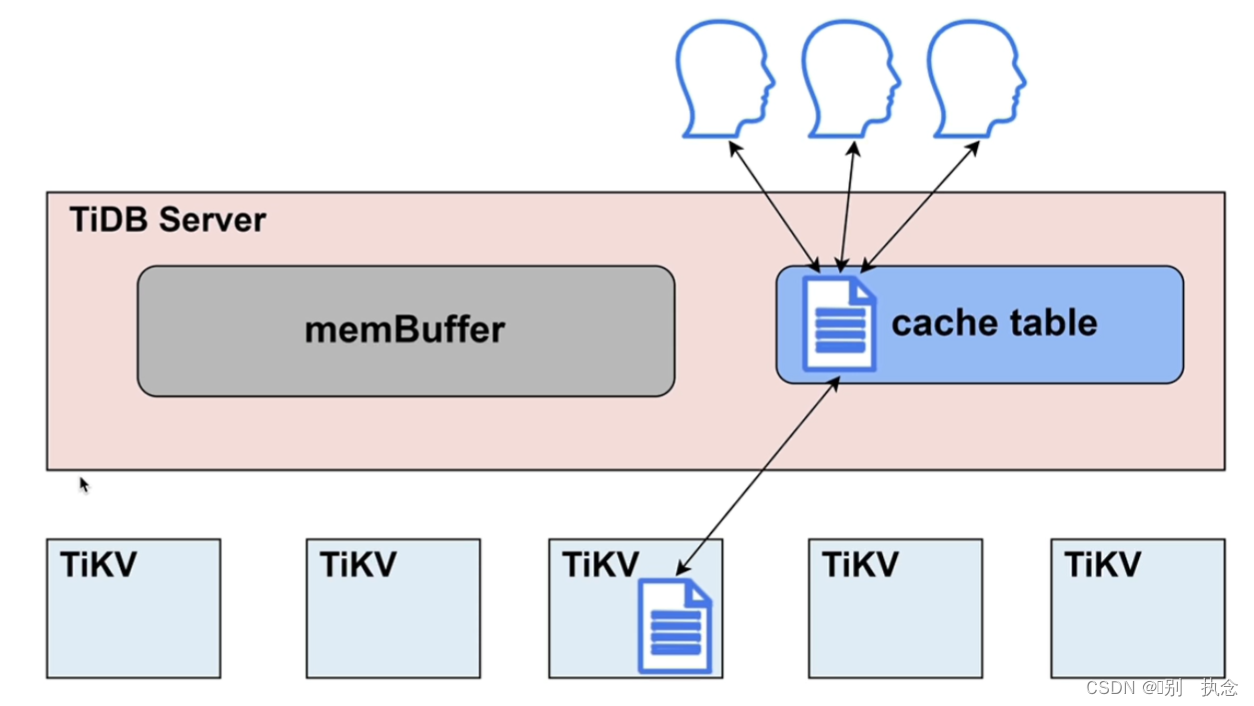
2.小表缓存
2.1热点小表缓存的表的特点
-
表的数据量不大
-
只读表或者修改不频繁的表
-
表的访问频繁
将经常访问的小表直接写入TiDB Server的缓存中,用户直接访问缓存表即可
2.2热点小表缓存原理
此小节详情于前面
Lesson 02:TiDB Server中的第
4.2 热点小表缓存小节有介绍,此处不再详细叙述。
将表放入缓存表中,需保证表大小小于等于64MB
控制数据一致性参数:tidb_table_cache_lease,内存表的租约期
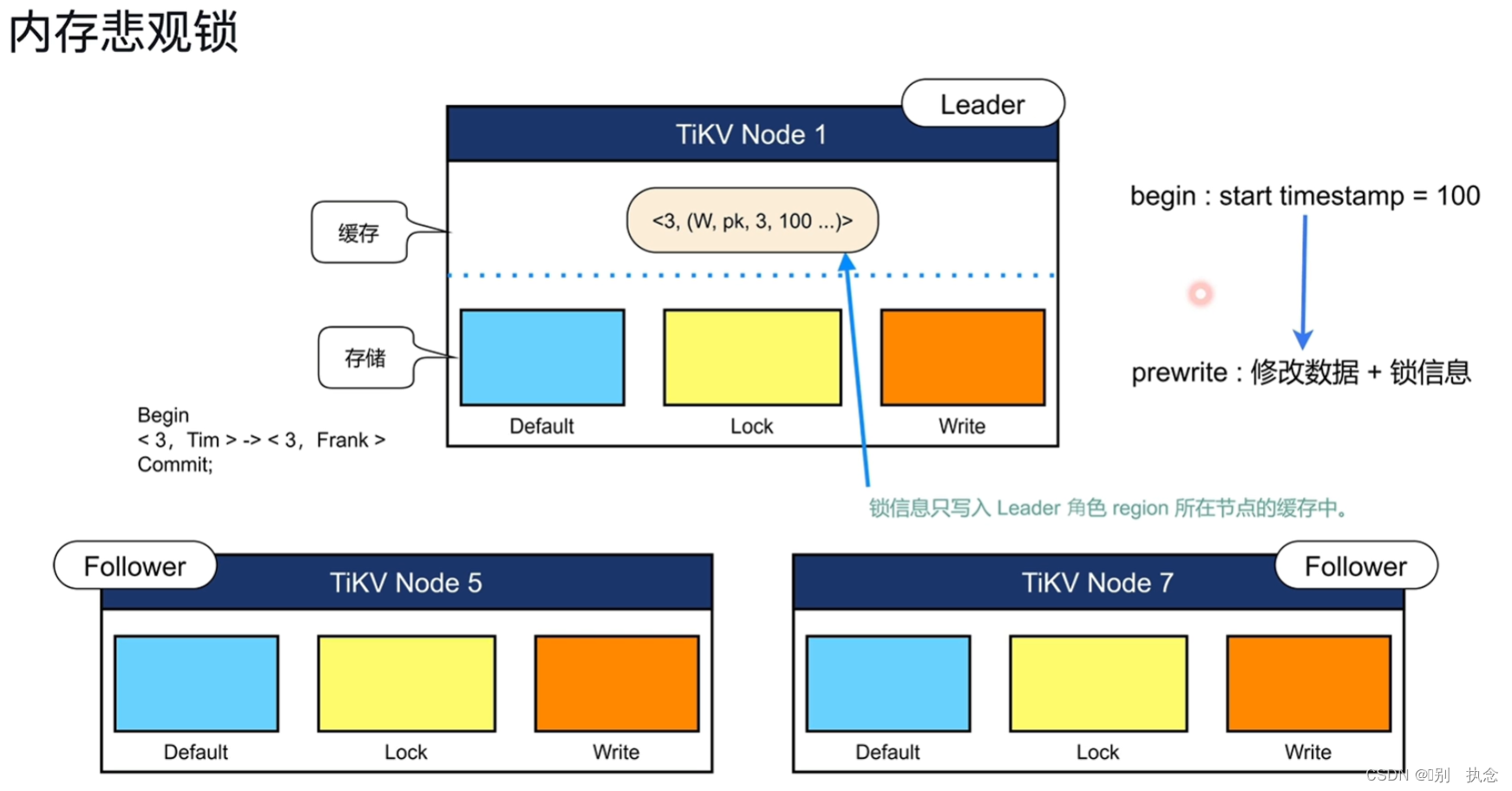
3.内存悲观锁
关于悲观锁、乐观锁等,在TIKV章节中有详细介绍。
乐观锁:在Commit前,修改的数据和锁信息存储在TIDB Server的内存中;除了本事务其他事务无法感知,只有当prewrite后修改的数据和锁信息才存入TiKV并被其他事务感知,故乐观锁只有在Commit时才知道是否有锁冲突
悲观锁:在Commit前,修改的数据存储在TiDB Server的内存中,而锁信息存入TiKV中(Lock簇)并被事务感知,故悲观锁在Commit前就知道是否有锁冲突
内存悲观锁
:统称的悲观锁需要磁盘IO和网络IO,而内存悲观锁则省去了磁盘IO和网络IO转为缓存IO,即将修改的数据和锁信息存储在TiKV的缓存中供其他事务感知,提升性能。
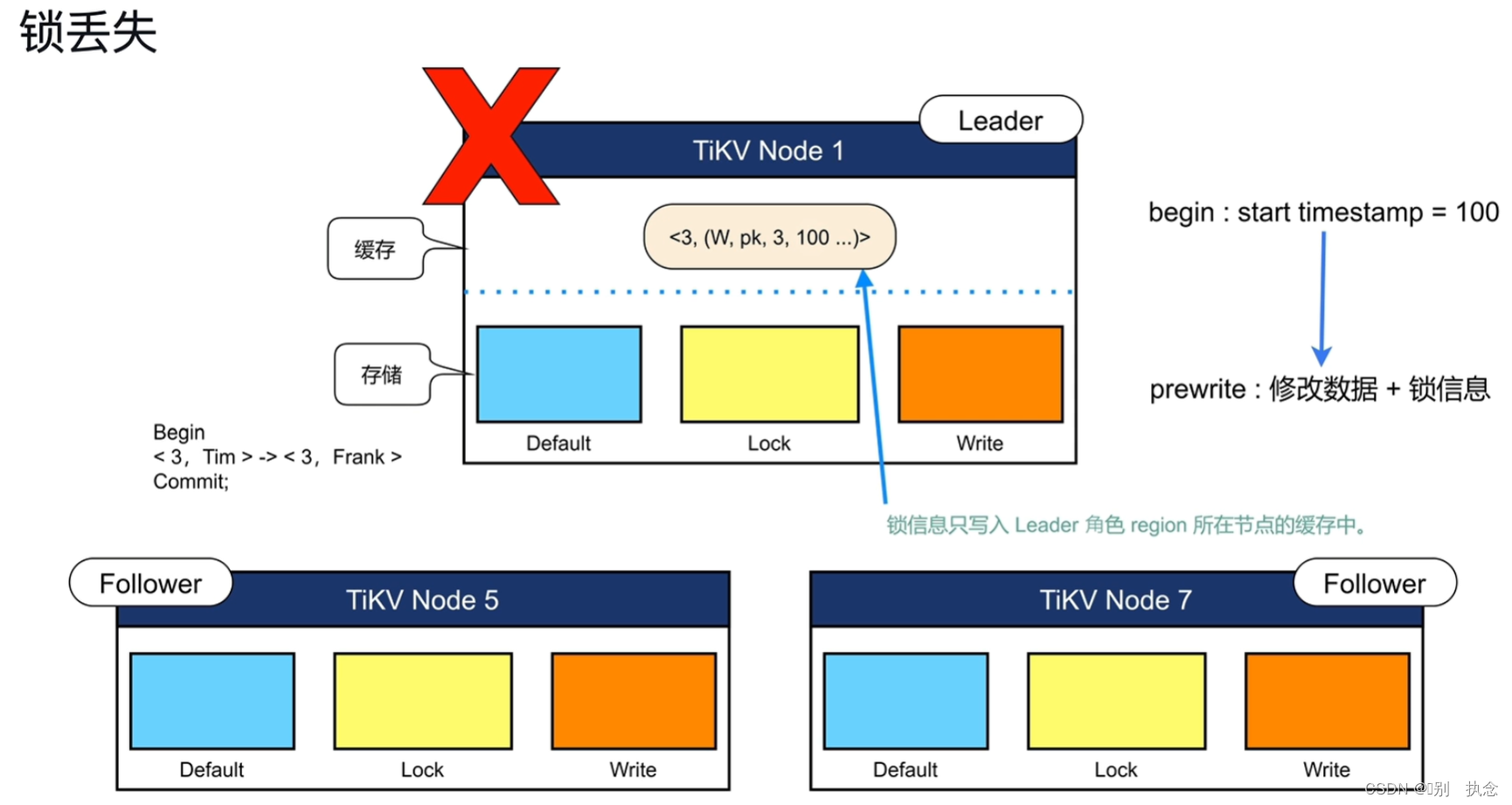
锁丢失
当leader宕机,导致锁丢失时,不会破坏数据的一致性且TiDB数据库执行事务回滚机制将事务回滚,锁信息不会丢失,但事务会失败
故内存悲观锁不适应于如事务失败导致带来巨大问题的情况
内存悲观锁的使用
使用参数set config tikv pressimistic-txn.pipelined和set config tikv pressimistic-txn.in-memory开启内存悲观锁
在线开启内存悲观锁:
>set config tikv pressimistic-txn.pipelined='true'
>set config tikv pressimistic-txn.in-memory='true'
内存悲观锁-应用
-
减少事务的延迟
-
降低磁盘和网络带宽
-
降低TiKV的CPU消耗
-
锁丢失问题
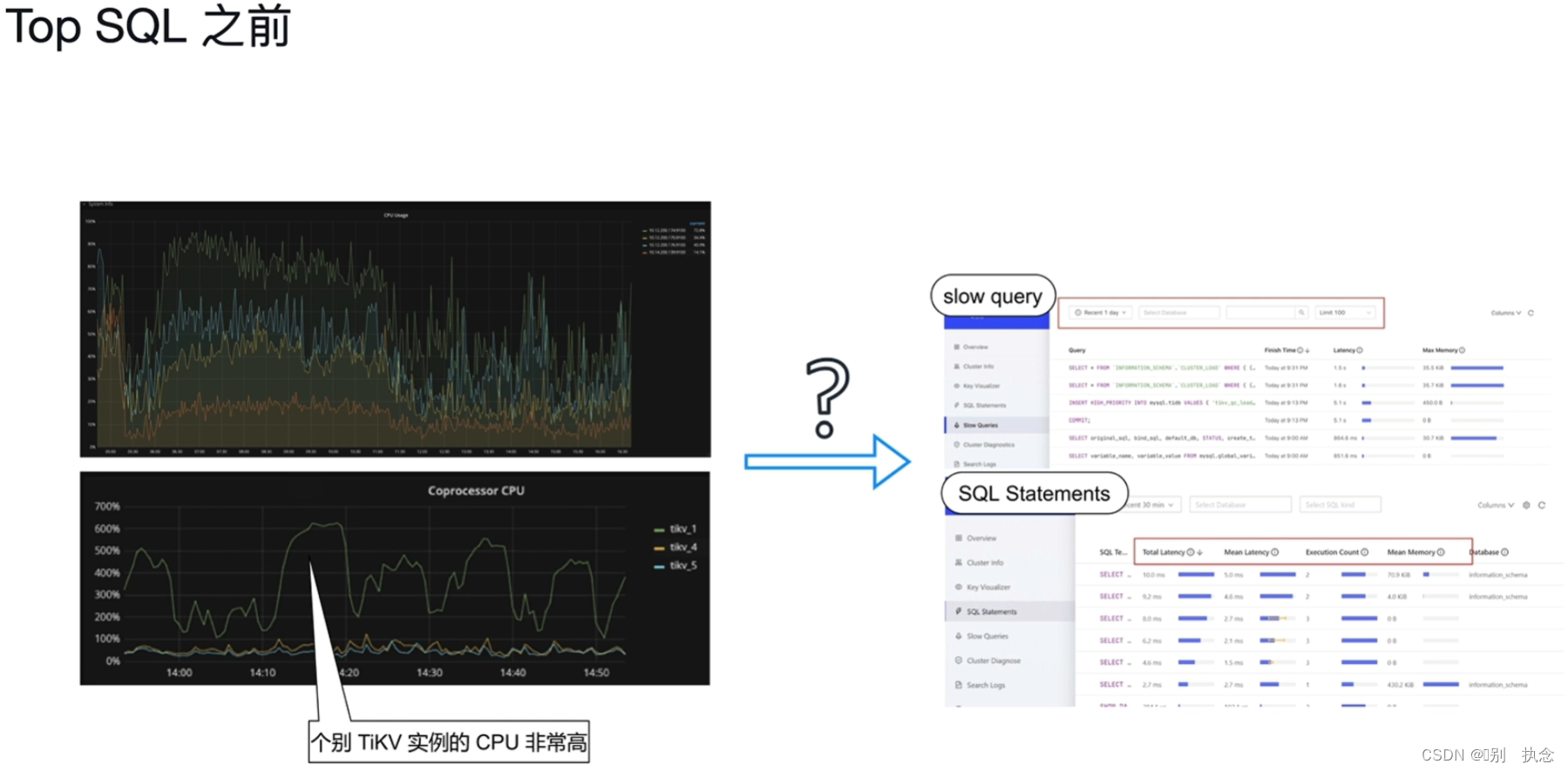
4.Top SQL
4.1 TOP SQL之前
-
个别TIKV实例的CPU非常高
-
CPU使用率突然发生了显著的变化
4.2 TOP SQL之后
-
指定TiDB和TiKV实例
-
正在执行的SQL语句
-
CPU开销最多的Top 5类语句
-
每秒请求数、平均延迟等信息
4.3 TOP SQL的使用
(1)选择需要观察负载的具体的TiDB Server或者TiKV实例
(2)观察TOP 5类 SQL
4.4 TOP SQL的作用
(1)可视化地展示CPU开销最多的Top 5类SQL语句
(2)支持指定TiDB Server及TiKV实例进行查询
(3)支持统计所有正在执行的SQL语句
(4)支持每秒请求数、平均延迟、查询计划等详细执行信息
5.TiDB Enterprise Manager(TiEM)
5.1 企业中TiDB集群管理的问题
数量增长:集群数量、节点数量、组件数量、工具数量
复杂度增长:配置参数复杂度、命令行复杂度、管理接口复杂度
5.2 企业中TiDB集群管理的任务
部署集群、升级集群、参数管理、组件管理、备份恢复于高可用管理、集群监控与告警、集群日志收集、审计与安全
5.3 TiDB Enterprise Manager(TiEM)功能
-
一键部署集群&多套集群一站式管理
-
集群原地升级
-
参数管理
-
克隆集群&主备集群切换
课堂测试
1.对于TiDB v6.0新特性描述正确的为?(请选择3项)
A.小表缓存支持DML和DDL语句操作
B.内存悲观锁功能可以起到降低网络带宽的作用
C.当某个TiKV实例的IO过高,我们可以通过Top SQL监控到其上IO最高的5类SQL语句
D.TiDB Enterprise Manager (TiEM)可管理多套集群
E.我们可以通过Placement Rules in SQL功能增加某些重要业务表的副本数
答案:B,D,E
解析:A:缓存表不支持DDL操作,执行DDL操作前需关闭热点小表缓存功能;B:内存悲观锁将锁信息写入leader的内存中,不需要同步至follower,减少了网络IO;C:Top SQL能检测导致TiKV实例CPU负载高的5类SQL,而非IO
2.下列哪些情况不适宜开启小表缓存?(请选择2项)
A.表数据量小于128MB
B.频繁读取的热点小表
C.只读的热点小表
D.读取和修改都非常频繁的热点小表
答案:A,D
解析:A:热点小表缓存中的每张缓存表的数据量应小于64MB;D:热点小表缓存应用于只读或修改不频繁的情况,而非频繁修改
Module 04:TiDB Cloud
Lesson 09:TiDB Cloud
1.TiDB Cloud架构
1.1 概念
多租户:在多租户架构中,应用程序的多个实例在共享环境中运行,每个租户在物理上都是集成的,但在逻辑上是分开的,一个软件实例为多个租户提供服务。
非多租户:用户在物理和逻辑上均是独立的,成本高,不灵活!
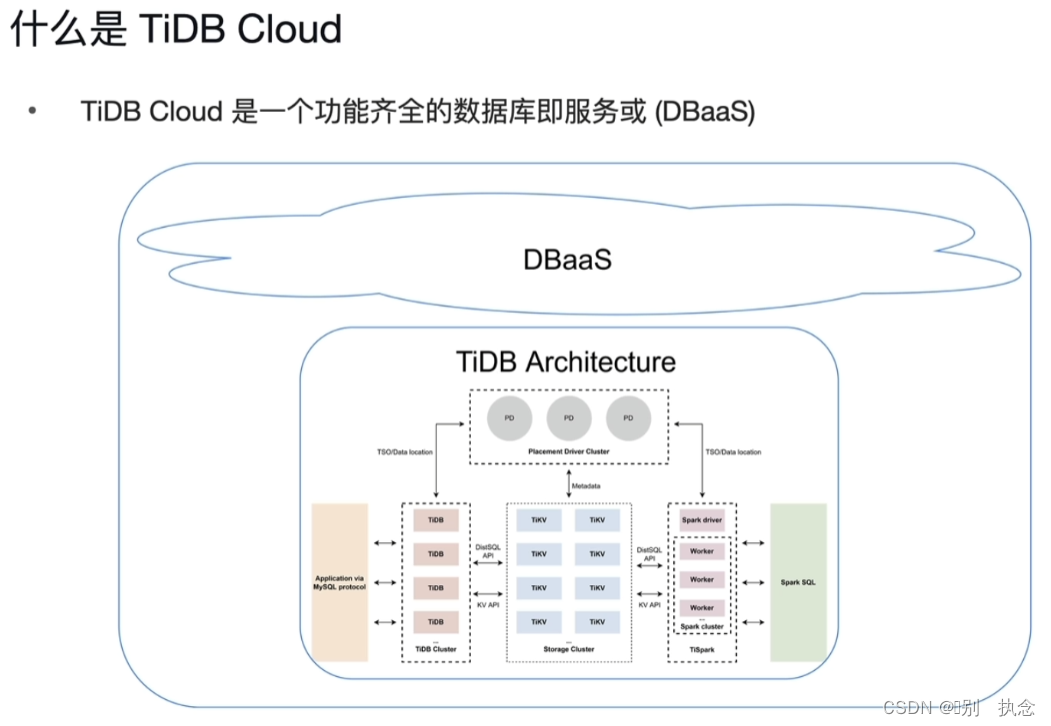
1.2 什么是TiDB Cloud
TiDB Cloud是一个功能齐全的数据库即服务或DBaaS。
1.3 名词(缩写)解释
IaaS (Infrastructure as a Service):基础设施即服务,云服务供应商提供各种硬件支持
Paas (Platform as a Service):平台即服务,云服务供应商提供平台支持
SaaS (Software as a Service):软件即服务,云服务供应商提供软件支持
DaaS (Data as a Service):数据即服务,云服务供应商提供数据四级及分析支持
DBaaS (DataBase-as-a-Service):数据库即服务,云服务供应商根据用户需求提供数据库支持(TiDB Cloud)
云DBaaS相较于本地数据库相比在,安装费用,成本效益,维护,可扩展性,速度上均有优势
,但在安全,可靠性两者
持平
(取决于和供应商之间的协议)
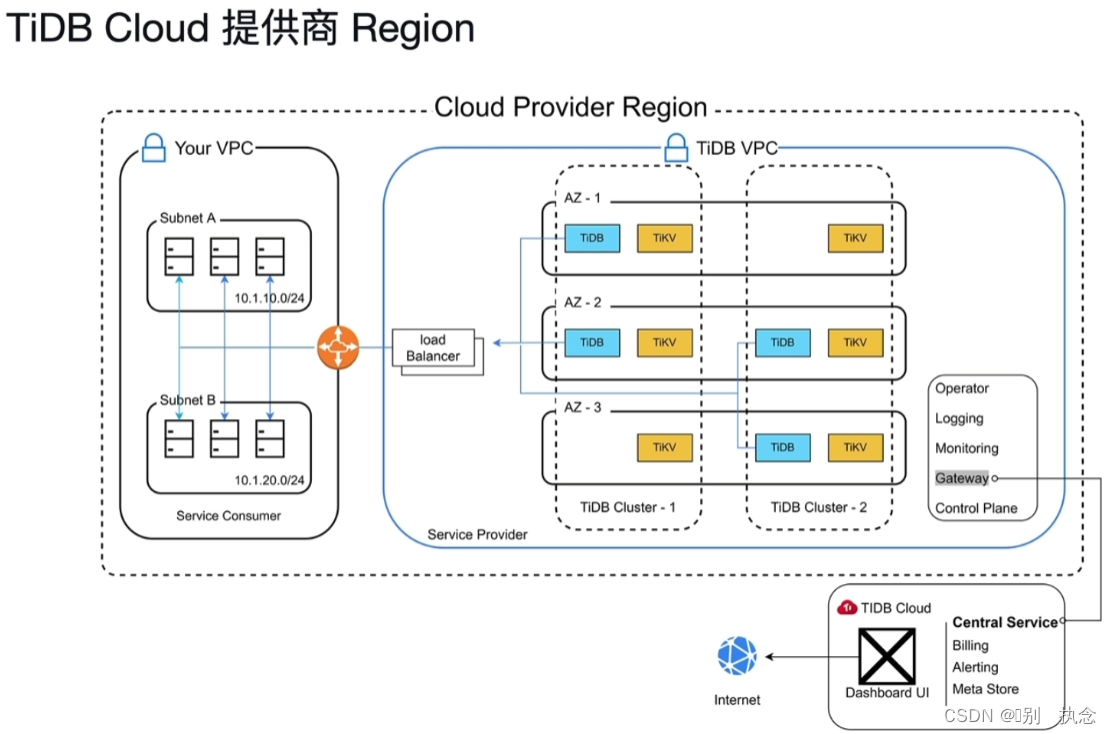
Cloud Provider Region
VPC:虚拟专有网络,处于云端的专有网络并有控制负责均衡,流量控制,控制私有网络间的通信等功能
TiDB Central Service(TiDB中心服务):有计费,警告,元数据存储等功能
2.TiDB Cloud的特点
2.1 TiDB Cloud入门
(2)创建TiDB Cloud账号
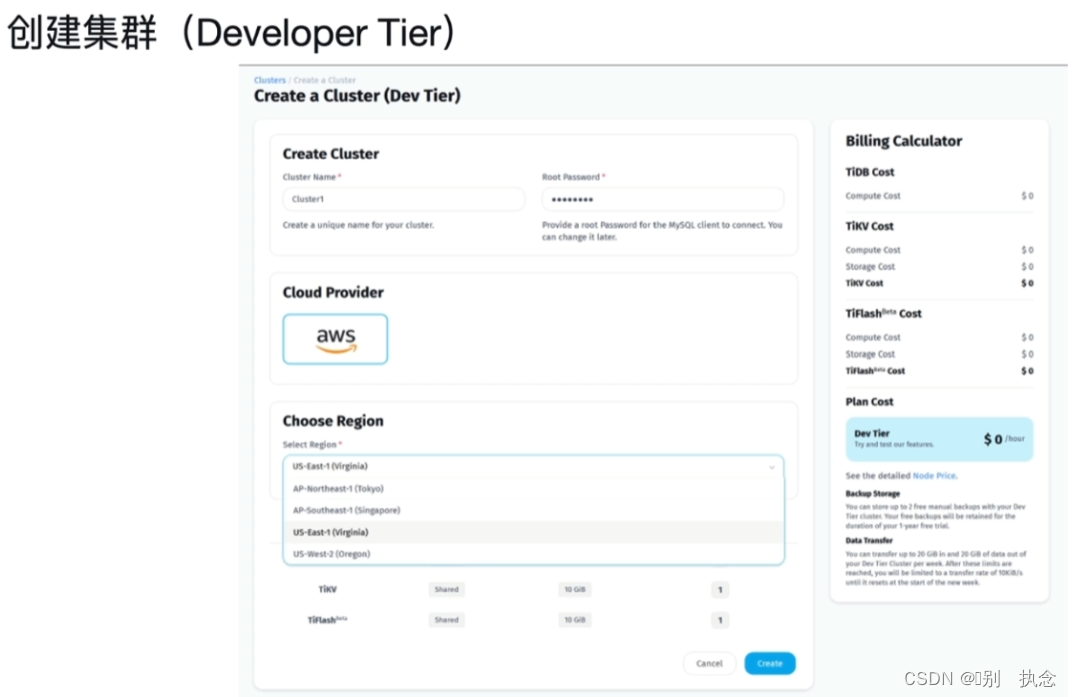
(3)选择Developer Tier或Dedicated Tier
2.2 Developer Tier与Dedicated Tier
Developer Tier
Developer Tier是实验且免费性质的集群层级,提供1个TiDB Server,1个TiKV和1个TiFlash;一个账户只能创建一个Developer Tier的集群,且有效期为一年,到期后需重新创建。
Developer Tier包括:
这意味着什么...
其他注意事项:
Dedicated Tier
-
专用于生产用途,具有跨区域高可用、横向扩展和HTAP的优势
-
根据业务需求,轻松定义TiDB、TiKV和TiFlash的集群大小
-
对于每个TiKV节点和TiFlash节点,节点上的数据都会被复制分发到不同的可用区,以实现高可用性
-
要创建Dedicated Tier集群,需要添加付款方法或申请概念验证(poC)试用
2.3 项目、支持、集群所有者
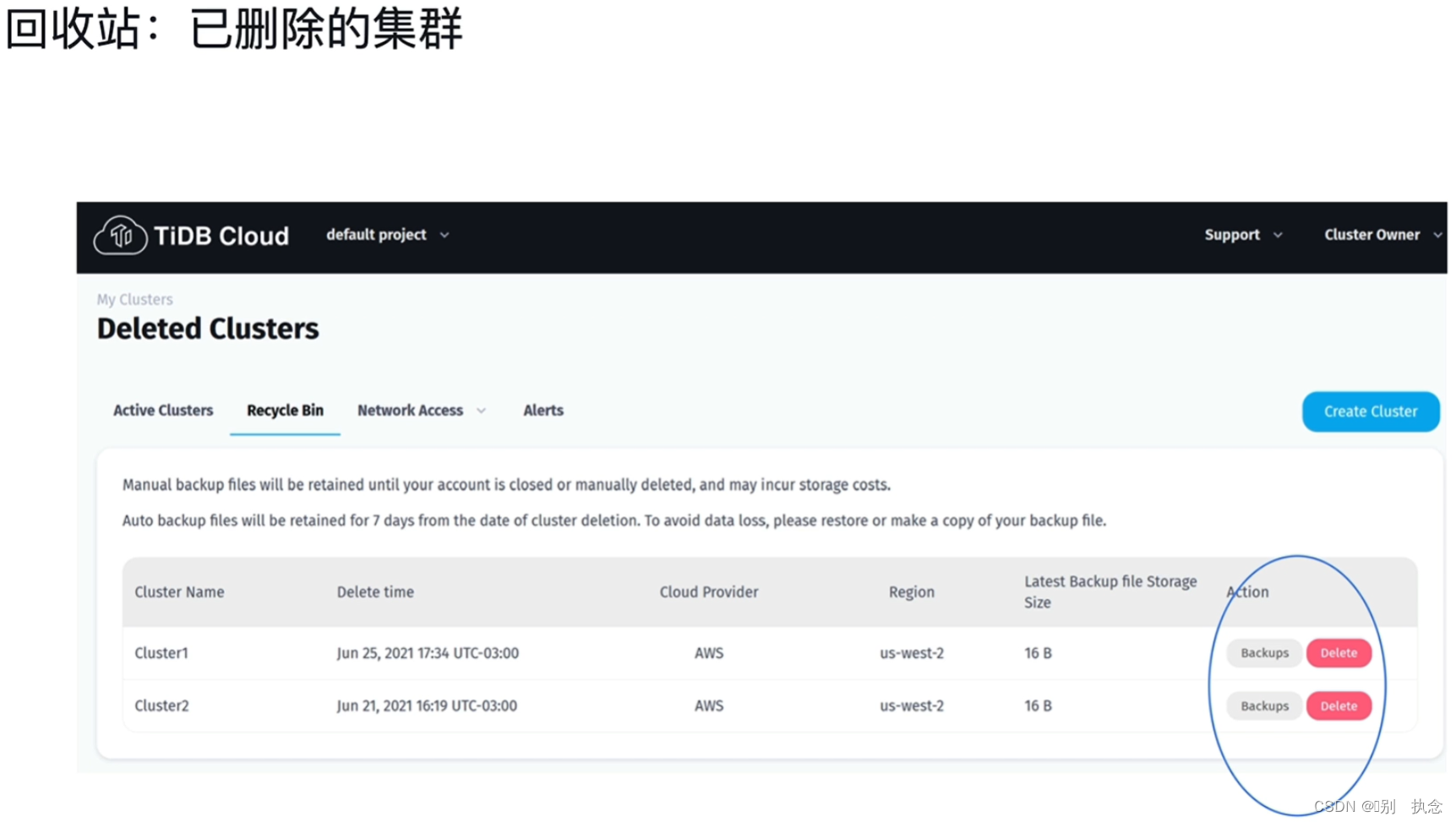
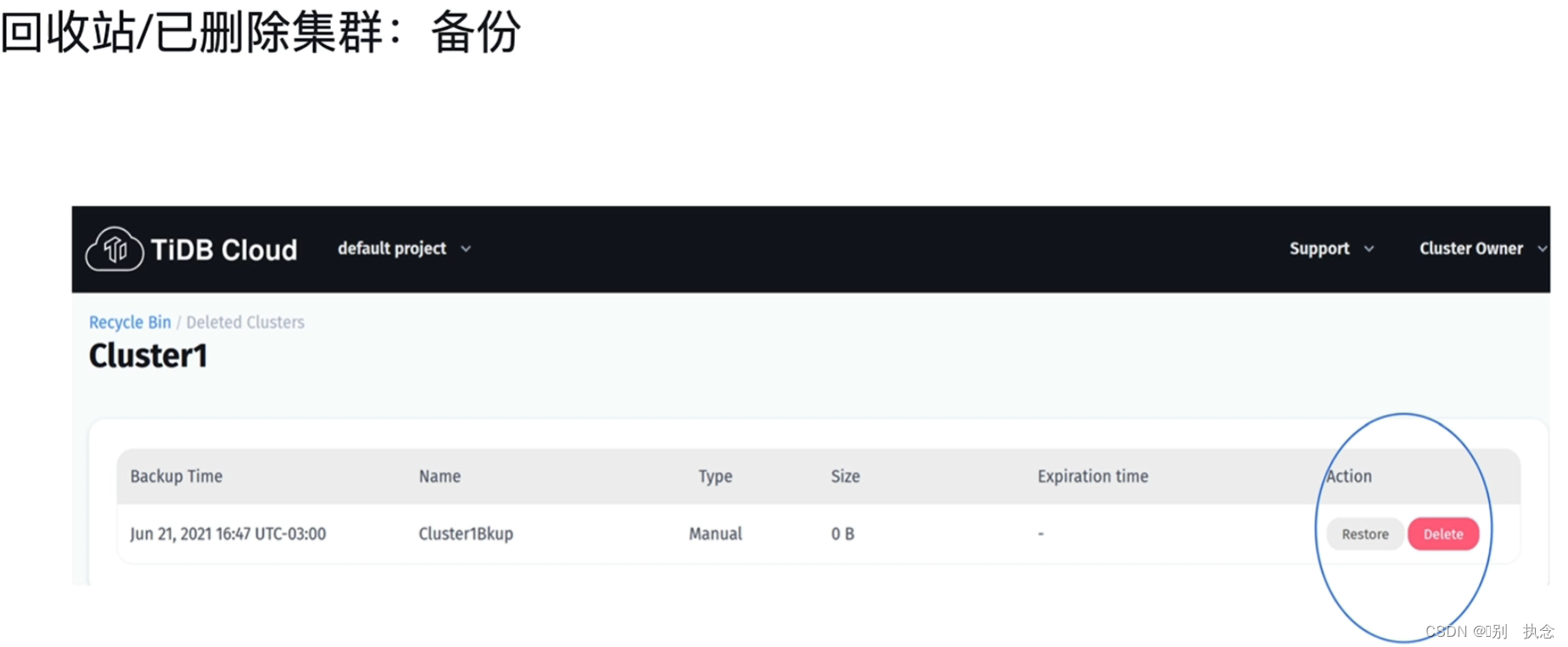
2.4 回收站
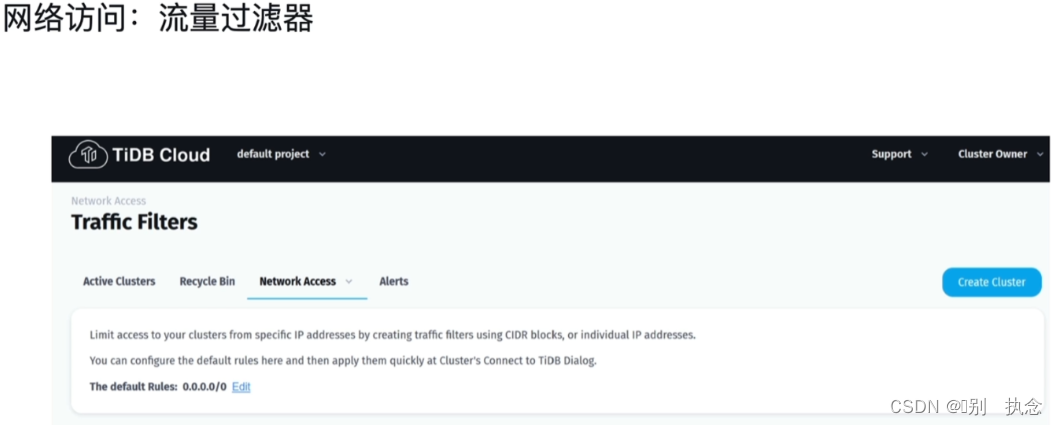
解析:A:只有Dedicated Tier具有VPC Peer,而Developer Tier没有;B,E:由于Developer Tier的节点限制,Developer Tier不支持横向扩容和缩容,且不具有可用性
















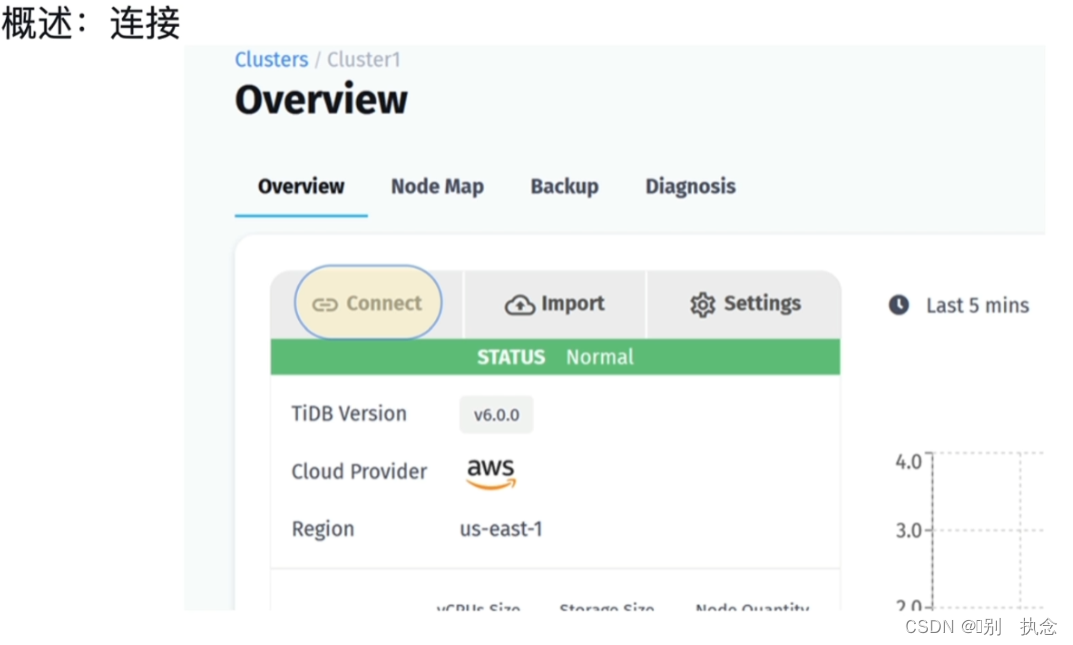
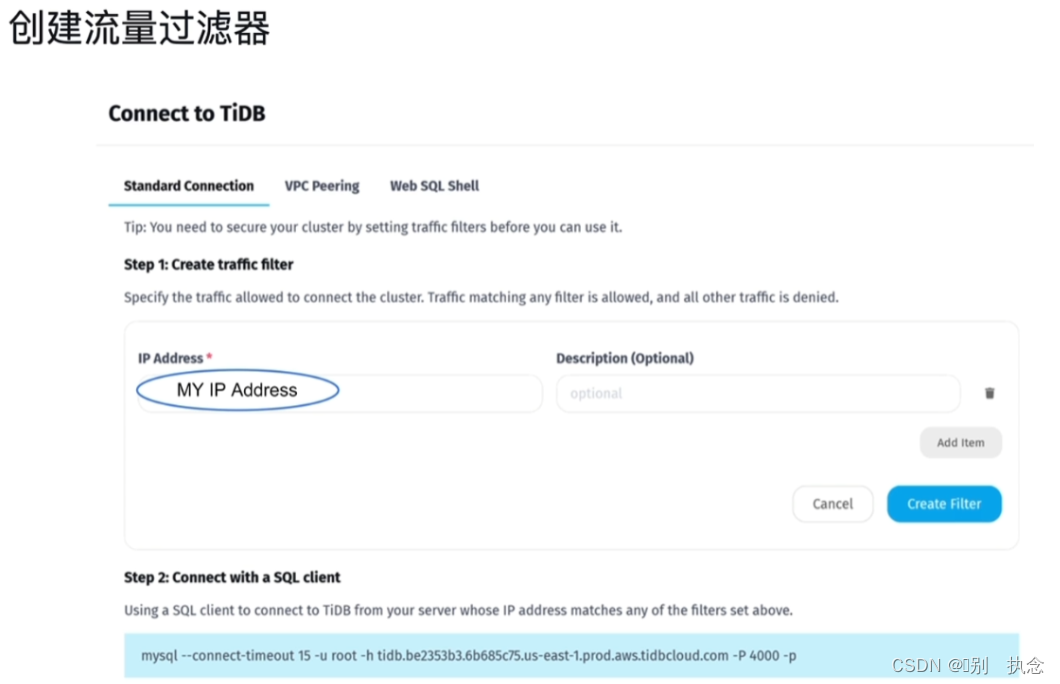
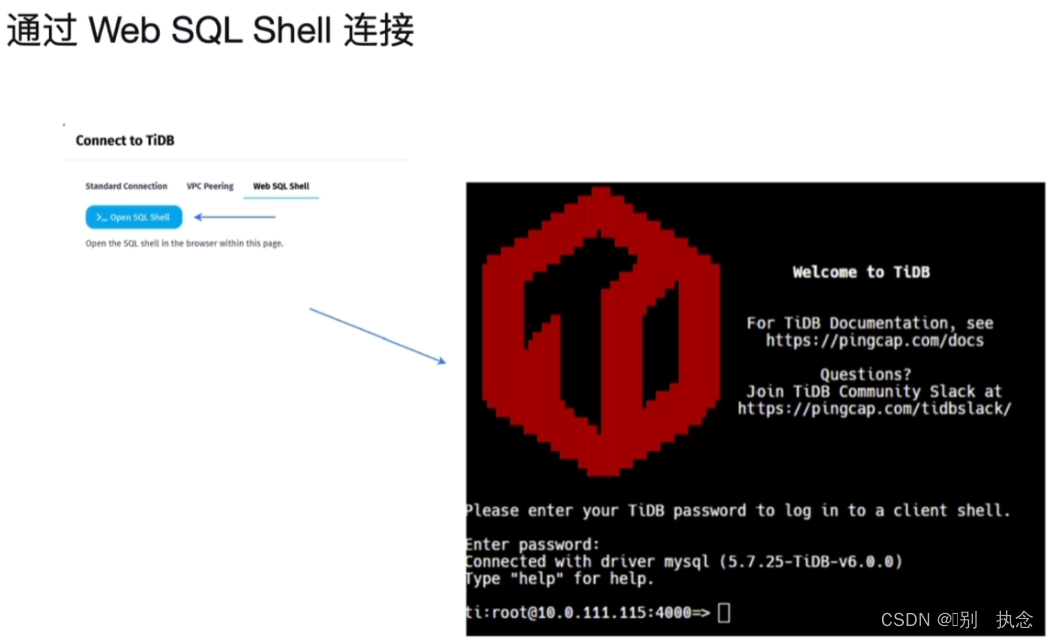


















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









