







PostgreSQ 数据库对象
database
每个PG服务可以包含多个独立的database。
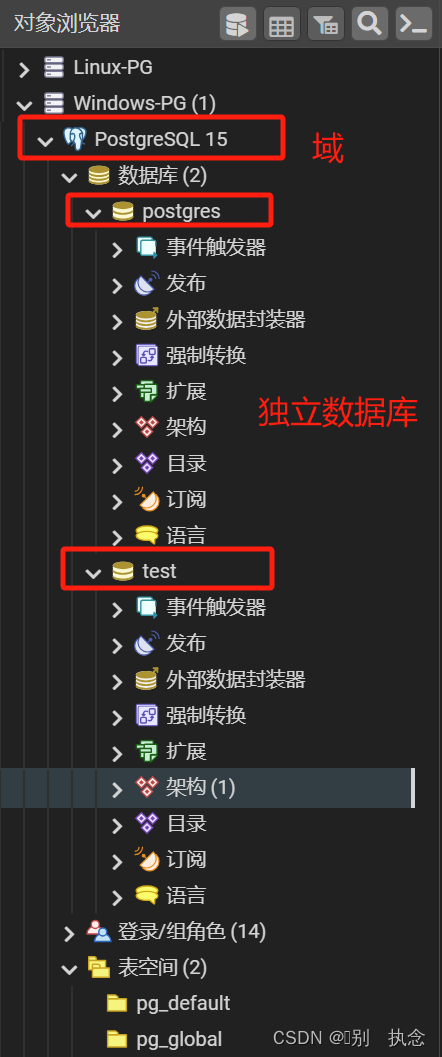
schema
如果把databases比作一个国家,那么schema就是一些独立的省。大多数对象是隶属于某个schema的,然后schema又隶属于某个databases。在创建一个新的database时,PG会自动为其创建一个名为public的schema。如果未设置searc_path变量,那么PG会将你创建的所有对象默认放入public schema中。如果表的数量较少,这是没问题的,但是如果你有几千张表,那么我们还是建议你将他们分门别类放入不同的schema中。
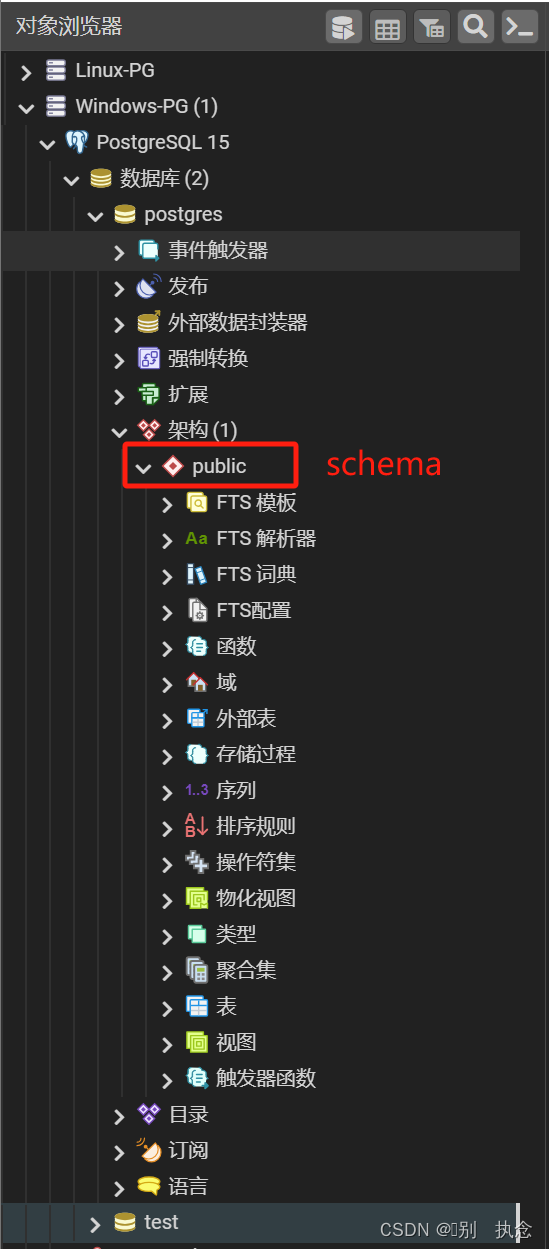
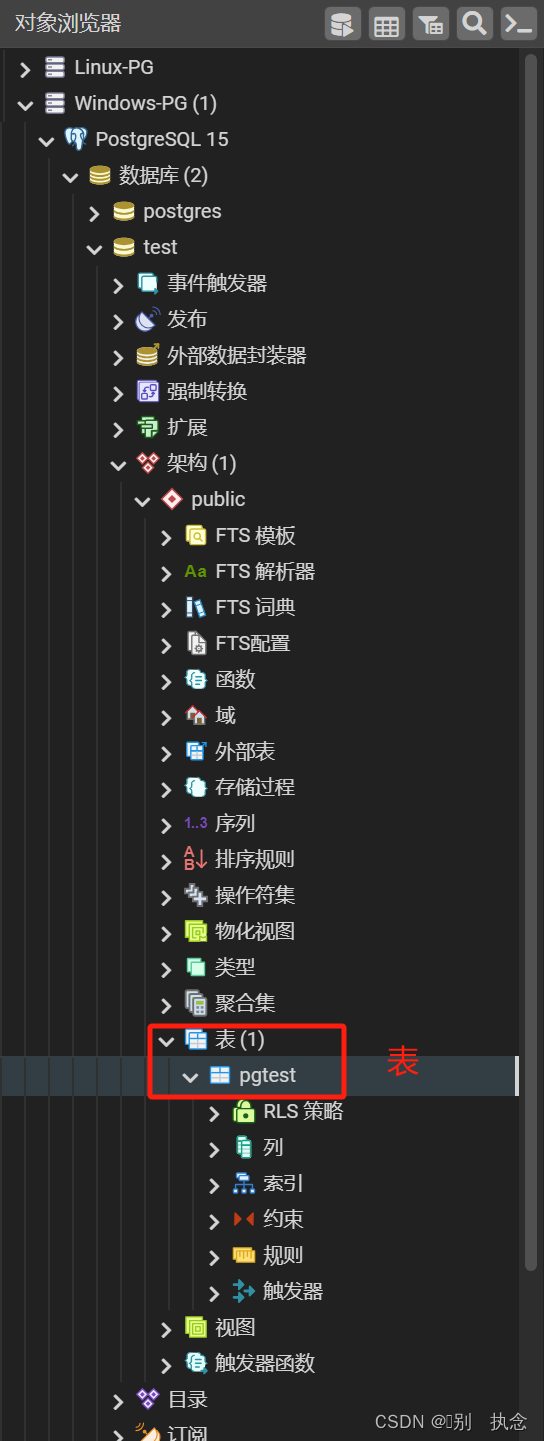
表
任何一个数据库中,表都是最核心的对象类型。在PG中,表首先属于某个schema,而schema有属于某个database,这样就构成一种三级存储结构。PG的表支持两种很强大的功能。第一种是继承,即一张表可以有父表和子表,这种层次化的结构可以极大的简化数据库设计,还可以为你省掉大量的重复查询代码。第二种是创建一张表的同时,系统会自动为此表创建一种对应的自定义数据类型。
PostgreSQL 整体架构
PostgreSQL 作为一个单机的关系型数据库,与单机Oracle的架构是比较相似的,与MySQL的InnoDB引擎也比较像。据我目前的了解,单机数据库的整体架构都差不太多,都是包含一个主的进程,一些辅助进程,以及一个大的共享内存池。下面我们具体学习一下PG架构里面的这些部分。
进程架构
PostgreSQL是一个多进程架构的客户端/服务器模式的关系型数据库管理系统。PG数据库中的一系列进程组合进来就是PostgreSQL服务端。这些进程可以细分为以下几大类:
postgres server进程 -是PG数据库中所有进程的父进程。
backend进程 - 每个客户端对于一个backend进程,处于这个客户端中的所有请求。
background进程 - 包含多个后台进程,比如做脏块刷盘的BACKGROUND WRITER进程,做垃圾清理的AUTOVACUUM进程,做检查点的CHECKPOINTER进程等。
replication相关进程 - 处理流复制的进程。
background workder进程 - PG9.3版本增加,执行由用户自定义开发的逻辑。
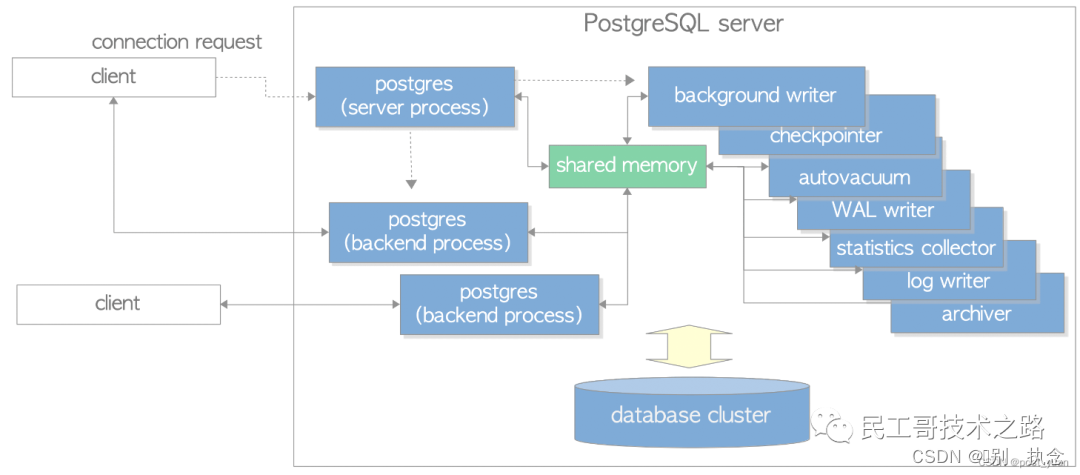
从上图可以看出,PG数据库中有一个主的postgres server进程,针对每个客户端有一个backend postgres进程,另外有一系列的background后台进程(针对不同的功能模块)。所以这些进程都对应一个共享内存shared memory。
下面我们再具体学习一下每类进程的主要工作内容。
Postgres Server Process
postgres server process是所有PG进程的父进程,在以前的版本中称为postmaster。当使用pg_ctl start启动数据库时,这个进程就被启动了, 然后它会启动一个共享内存shared memory,启动多个background后台进程,启动复制相关进程,如有需要也启动background worker progress,然后等待客户端的连接。
当接收到一个客户端连接时,它就会启动一个backend progress,专门服务于这个客户端。
postgres server process通常有一个对应的监听端口,默认是5432。如果一台机器上安装多个postgres实例有多个postgres server process,那么就需要修改对应的端口地址比如5433、5434等。
Backend Process
backend process也称为postgres进程,是由上面的postgres server process启动的用于服务于对应的客户端,通过TCP协议和客户端进行通信。
由于这个进程只能服务于一个特定的database,所以需要在连接PG数据库的时候指定一个默认连接的database。
PG允许多个客户端同时连接数据库,由max_connections参数控制最大并发连接数,默认是100。
如果有很多客户端频繁的对数据库进行短连接与释放连接,那么可能会造成连接耗时比较长,因为PG目前没有连接池的功能。针对于这种场景,一般通过像pgbouncer或pgpool-II这种插件来优化。
Background Process
background process后台进程有多个,每个进程负责一个模块或是一类任务,下面表格总结每个进程的描述。

以下是一个环境中查看到的PG相关进程列表,
postgres> pstree -p 9687
-+= 00001 root /sbin/launchd
-+- 09687 postgres /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
|--= 09688 postgres postgres: logger process
|--= 09690 postgres postgres: checkpointer process
|--= 09691 postgres postgres: writer process
|--= 09692 postgres postgres: wal writer process
|--= 09693 postgres postgres: autovacuum launcher process
|--= 09694 postgres postgres: archiver process
|--= 09695 postgres postgres: stats collector process
|--= 09697 postgres postgres: postgres sampledb 192.168.1.100(54924) idle
--= 09717 postgres postgres: postgres sampledb 192.168.1.100(54964) idle in transaction 内存架构
了解完进程架构后,我们再来了解一下内存架构,PG中的内存主要分为两类:
本地内存区 - 用于每个backend process内部使用,每个客户端连接对应一个本地内存区。
共享内存区 - 所有PG进程共享使用。
本地内存区
本地内存区有多个,每个对应一个backend progres进程,用于处于这个连接内部的一些工作,包括:

共享内存区
共享内存区在数据库启动时创建,也可以划分为多个子区域,包括:

除此之外,共享内存区还包括一些其他的子区域:
•用于多种访问控制的内存区域。
•用于多种后台进程如checkpointer、vacuum的内存区域。
•用于事务处理的区域如savepoint、二阶段提交。
感谢 PostgreSQL中文社区:PostgreSQL中文社区:: 世界上功能最强大的开源数据库...
感谢 民工哥技术之路 https://zhuanlan.zhihu.com/p/645899384
















 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









