







英语6级选词填空全部选A和随机不重复填空选哪个?(菜鸡质问)
part1_discussion
相信小伙伴们都在2019/12/14 下午17:25:00’结束了CET6,小伙伴们对此展开了踊跃的讨论:
discuss(1)
discuss(2)
discuss(3)

discuss(4)
discuss(5)

part_2argument
在讨论的时候突然大家开始争论选词填空全部选A和随机不重复填空选哪个?对于英语基础差劲的两位程序员提出了两个不同的看法
A:我直接全部选A可以将期望近似逼近1
B:十个填空全选a不如瞎选得分高
话不多说,直接开题:
problem:
对于一套全国大学生英语六级考试试卷,英语成绩不好的两位同学A,B采用不同策略对答题卡进行填涂
A:所有空填涂A
B: 不重复随机填涂
问采用哪种策略得分效率更高?

solution:
拿到这个问题闲得慌的博主开始写了个简单的全排列程序,思想如下:
(1)用DFS深搜枚举出所有全排列情况,每一种全排列序列都对应一个得分效率,在边界处将得分效率相加得到总得分效率
(2)最后将总分与概率空间做比,得到期望值
假设随机变量X表示同学们填涂答案正确的个数,E(x)表示x的期望
a.对于A,如果不考虑经验成分,那么A同学的期望是Ea(x)=1*10/15=0.66666666666666666666666666666667
b. 对于B, 如果不考虑经验成分,那么概率空间Ω.size() =P(10,15)=10,897,286,400
而事件X的所有情况有多少?如何计算,首先想到了概率论错排公式,但是有5个答案是无效的,直接计算一定没这样轻松,害,何不直接用dfs呢?A用了不太长的时间也就是10min左右敲出代码开始验证:
#include <iostream>
using namespace std;
const int maxn=16;
int n,P[maxn],hashTable[maxn]={0};
long long ans=0,pos=0;
void generateP(int index)
{
if(index==n+1)//检查p中n个数的排列
{
ans+=pos;
return;
}
for(int x=1;x<=n+5;x++)//枚举1~n将x填入P[index]
{
if(hashTable[x]==0)//x不在p[0]~p[index-1]中
{
P[index]=x;//令P的第index位为x,即把x加入当前排列
pos=(x==index)?pos+1:pos;//计数
hashTable[x]=1;//记x在p中
generateP(index+1);//处理排列的index+1位
hashTable[x]=0;//处理完p[index]为x的子问题还原状态
pos=(x==index)?pos-1:pos;//复位
}
}
}
int main()
{
cin>>n;
generateP(1);
cout<<ans;
return 0;
}
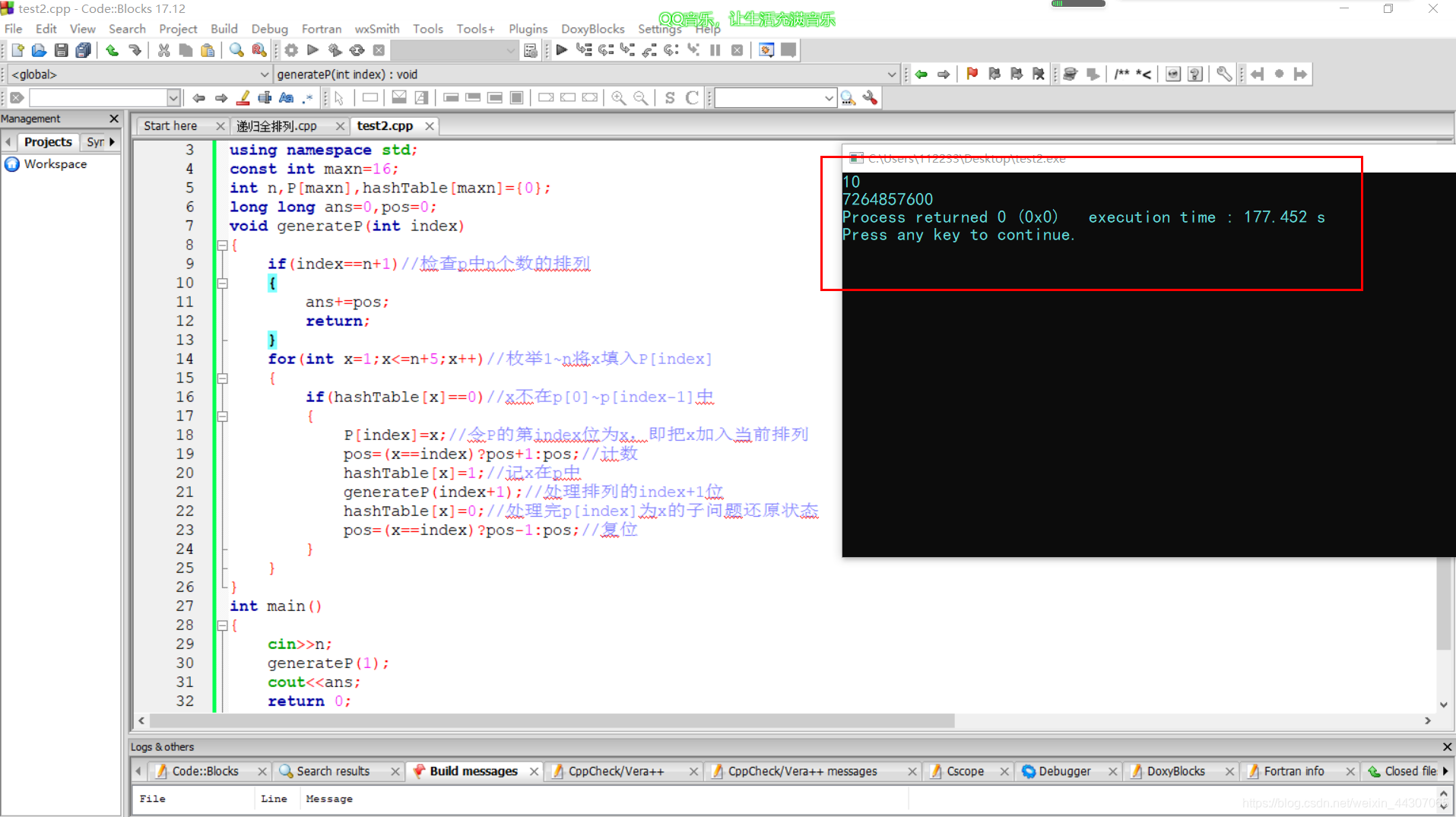
测试结果是:s=7264857600
根据几何概型,
Eb(x)=s/Ω.size() =7264857600/10897286400= 1/1.5 =0.66666666666666666666666666666667
显然Eb(x)-Ea(x)=0
结论
所有空填涂A与不重复随机填涂的结果一致
所以说,结果居然是期望一致???what 惊呆zzzzzz但是答案就在眼前:

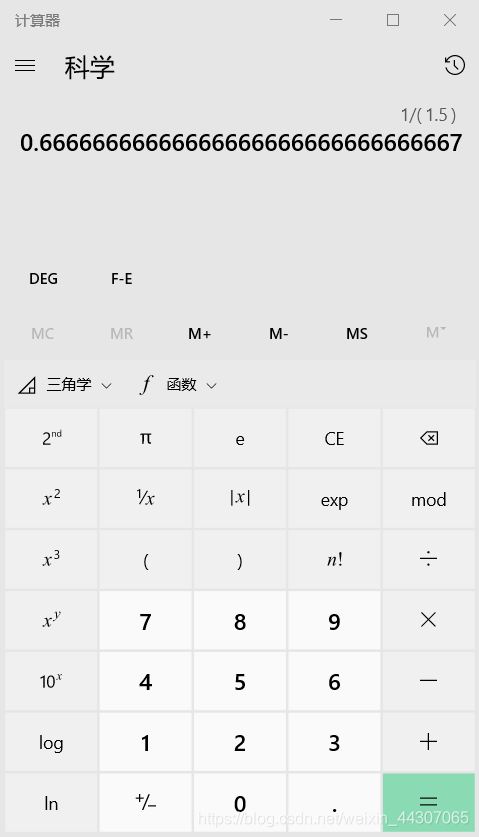
当然经验告诉我,A出现的概率近乎逼近1/10,所以填A的期望逼近1,换过来也就是3.5’,这3.5’近乎必得
后期讨论?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









