







Spark SQL概述
什么是Spark SQL

为什么要有Spark SQL

Spark SQL原理

什么是DataFrame
1)DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
2)DataFrame与RDD的主要区别在于,DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
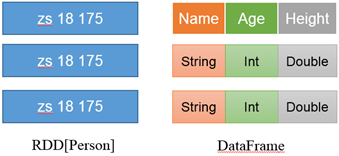
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
3)Spark SQL性能上比RDD要高。因为Spark SQL了解数据内部结构,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在Stage层面进行简单、通用的流水线优化。


什么是DataSet
DataSet是分布式数据集合。
- DataSet是强类型的。比如可以有DataSet[Car],DataSet[User]。具有类型安全检查
- DataFrame是DataSet的特例,type DataFrame = DataSet[Row] ,Row是一个类型,跟Car、User这些的类型一样,所有的表结构信息都用Row来表示。
RDD、DataFrame和DataSet之间关系
1)发展历史
RDD(Spark1.0)=》Dataframe(Spark1.3)=》Dataset(Spark1.6)
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同的是他们的执行效率和执行方式。在后期的Spark版本中,DataSet有可能会逐步取代RDD和DataFrame成为唯一的API接口。
2)三者的共性
(1)RDD、DataFrame、DataSet全都是Spark平台下的分布式弹性数据集,为处理超大型数据提供便利
(2)三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action行动算子如foreach时,三者才会开始遍历运算
(3)三者有许多共同的函数,如filter,排序等
(4)三者都会根据Spark的内存情况自动缓存运算
(5)三者都有分区的概念
Spark SQL的特点
1)易整合
无缝的整合了SQL查询和Spark编程。

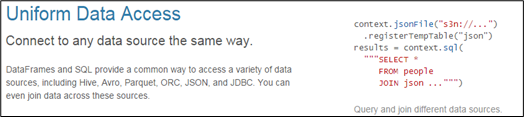
2)统一的数据访问方式
使用相同的方式连接不同的数据源。
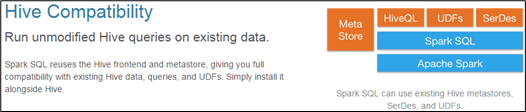
3)兼容Hive
在已有的仓库上直接运行SQL或者HQL。
4)标准的数据连接
通过JDBC或者ODBC来连接















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









