






开飞机换引擎:不停机迁移MongoDB数据到MySQL
数据库迁移是我正式走上工作岗位后遇到的第一个技术难题,整个过程非常艰辛和曲折,但是在同事的帮助和共同努力下,最终完成了这项艰难的任务,真正做到了开着飞机换引擎。于是借此机会记录一下整个迁移过程。
一、数据库迁移的业务背景
A. 为什么要迁移?
- MongoDB并非主流的数据库,团队成员对MongoDB的技术储备不足,还没有达到完全驾驭的程度,没办法有效的应对线上问题调优。
- 团队大部分的同学,特别是新加入的同学,没有MongoDB相关的技术储备,导致大家对MongoDB的理解层次比较浅,无法形成有效的规范和经验沉淀,导致在MongoDB的使用上,五花八门,充斥的不同的风格。
- 对于复杂的查询语句,MongoDB的SQL语法上也比较难理解,调优起来比较困难。
- 对MongoDB的底层原理和机制了解较少,业务系统线上出现过几次因MongoDB数据库导致的问题,如:
- 服务流量瞬时激增,连接池自动扩容,会导致连接池瞬间消耗完,后续请求进入等待队列迟迟得不到释放,CPU被打满;
- 难以理解的SQL查询执行策略,如在某种情况下,索引选择策略不使用where条件的字段,反而选择排序字段。
- MongoDB的文档型数据库属性,如子文档嵌套、灵活的字段类型拓展等,用起来特别爽,但是也是一把双刃剑。在项目实践中,逐步也暴露出来了几个问题:
- 对于数据库表的变更,公司没有有效的管控工具来限制:如修改一个字段类型,代码直接修改即可生效;代码层面只会对新插入表的数据生效;而历史数据的文档模型就没办法统一修改,导致存在历史数据兼容问题。
- 数据模型混乱,对于同一个Collection, 每条记录的字段数不尽相同,无法从数据库层面看出Collection的模型到底是什么,只能借助上层应用的代码PO Bean映射来梳理。
- MongoDB在公司中缺少运维支持:
- MongoDB在公司内未来不会重点发展和支持;
- MongoDB云控制台相关的运维能力不足,比如无法监控慢SQL监控和告警不完善;
- 没有DBA做日常支撑和答疑。
- 系统的数据量增速非常快,预期很快会有千万级的表。而MongoDB的分库分表没有比较完善和高可用的技术方案,还需要我们花一些精力来解决。
B. 当初为什么选择MongoBD作为主数据库?
- 业务系统的数据本身就是些结构化的大文本数据,而MongoDB是一个文档型数据库,在存储大文本数据上存在天然的优势,使用起来非常的方便。
- 早期的业务系统只是个小的应用,并没有太多人使用,所以当初在技术选型上就选择了一种简单的方案。
二、待解决的关键性问题
- 如何把MongoDB的数据同步到MySQL中?
- 存量数据(批量迁移)
- 增量数据(实时同步)
- 代码层面如何做代码切流,确保核心业务不受影响?
- 不停机平滑迁移
- 灵活的切流策略
- 异常场景容错,预案保证
- 如何进行数据一致性比对,确保迁移后的数据准确无误?
- MongoDB和MySQL中的数据要完全一致
能力要求:
a. 容错性:同步任务因异常挂掉,保证可以断点续传重试
b. 不能丢数据
c. 实时性:秒级或者分钟级的延迟
d. 支持异构同步:MongoDB(文档型) -> MySQL(关系型)
三、迁移的整体流程
迁移步骤流程图:

详细步骤:
- 开启Flink数据同步任务,进行存量&增量的数据同步
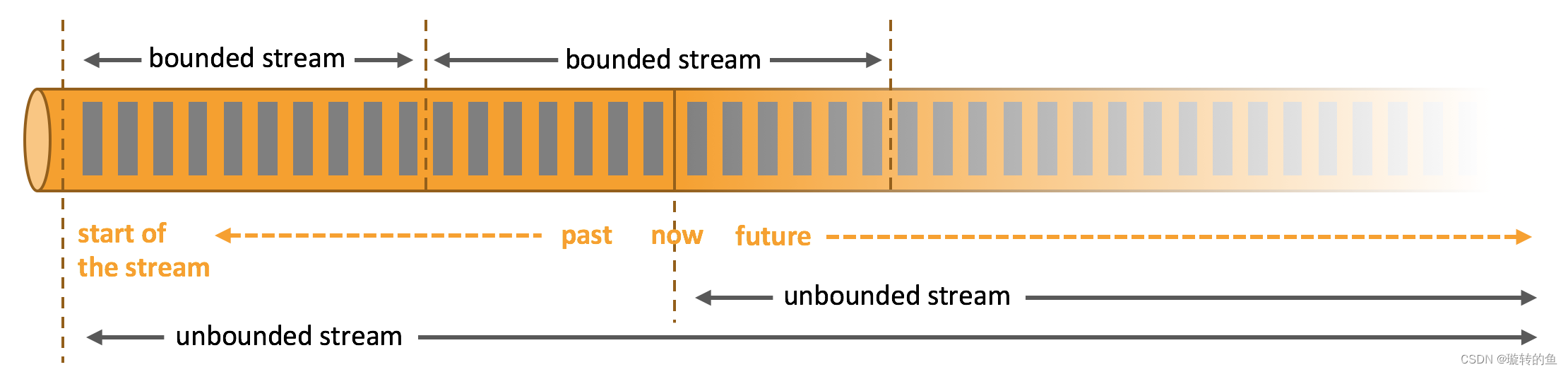
- 存量数据 - 有界流(bounded stream) : 存量数据的批量导入
- 增量数据 - 无界流(unbounded stream):基于时间时序的强一致性的同步,实时更新
- 等待数据同步完成后关闭同步任务,同时打开双写过程。双写过程整体可以分成3个阶段:
- 第一阶段:
- 读写以MongoDB为主,重点保障MongoDB侧的读写,同时将写数据同步写入到MySQL中。对于MySQL侧的写操作,吞掉异常,不做处理。通过观察日志以及监控,及时发现MySQL侧的写入异常,并进行手动处理。
- 业务系统数据分析读取数据以MongoDB为主。
- 第二阶段:
- 进行切流,读写以MySQL为主,重点保障MySQL侧的读写,同时将写数据同步写入到MongoDB中。对于MongoDB侧的写操作,吞掉异常,不做处理。通过观察日志以及监控,及时发现MongoDB侧的写异常以及MySQL侧的异常情况,并进行手动处理。
- 虽然进行了切流,读写以MySQL为主了,但是业务系统的数据分析侧还未完成切流改造,所以数据分析仍以读MongoDB为主。
- 第三阶段:
- 经过一段时间的双写以及每天的数据比对,所有的问题都已经解决,数据库切换后业务完全正常。
- 数据分析侧已经完成切流,切换成了读取MySQL数据库的数据。则断流MongoDB数据库,完成迁移。
- 第一阶段:
- 异构数据一致性比对过程:
- 原理:在数仓中创建2张结构完全一样的表,分别用来存储MySQL和MongoDB的数据。将MySQL和MongoDB中对应表的数据都导入到数仓的两张表中,通过比对工具逐一比对数据一致性。
- 同步数据校验:
- 异构数据一致性比对贯穿整个迁移过程。第一次进行数据比对是在关闭同步任务后进行,用于确保迁移前后两个库的数据完全一致。之后的每天凌晨都会定时执行数据比对任务,及时发现有问题的数据,必要时采取人工方式订正数据。
- 异构数据比对具体流程(通过DataWorks & ODPS & 云图 来完成):
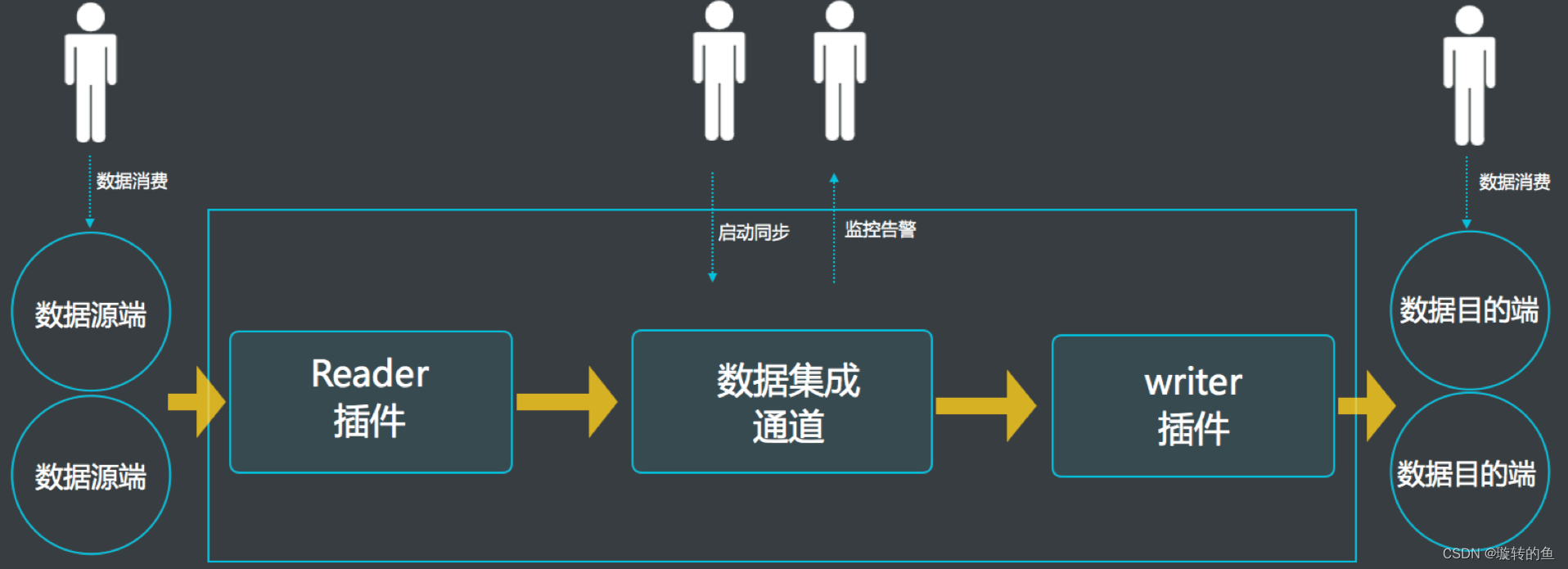
- 在ODPS中创建两张表,分别对应MySQL(TDDL)和MongoDB中的表,利用DataWorks的数据同步能力,将MongoDB和TDDL中的源数据抽取成同源的ODPS数据存储在数仓。
- 通过云图平台,对两张ODPS表中的数据进行逐一比对,并将结果同步推送至钉群、邮件。
- 代码功能校验:新增lippi-goal-dal-instrumentation模块,仅用于单元测试。分别调用MySQL的实现和MongoDB的实现中的相同方法,对比两种方法的返回结果是否完全一致。
- 整体数据校验流程图:
四、数据库迁移其他相关项
A. Fink CDC介绍
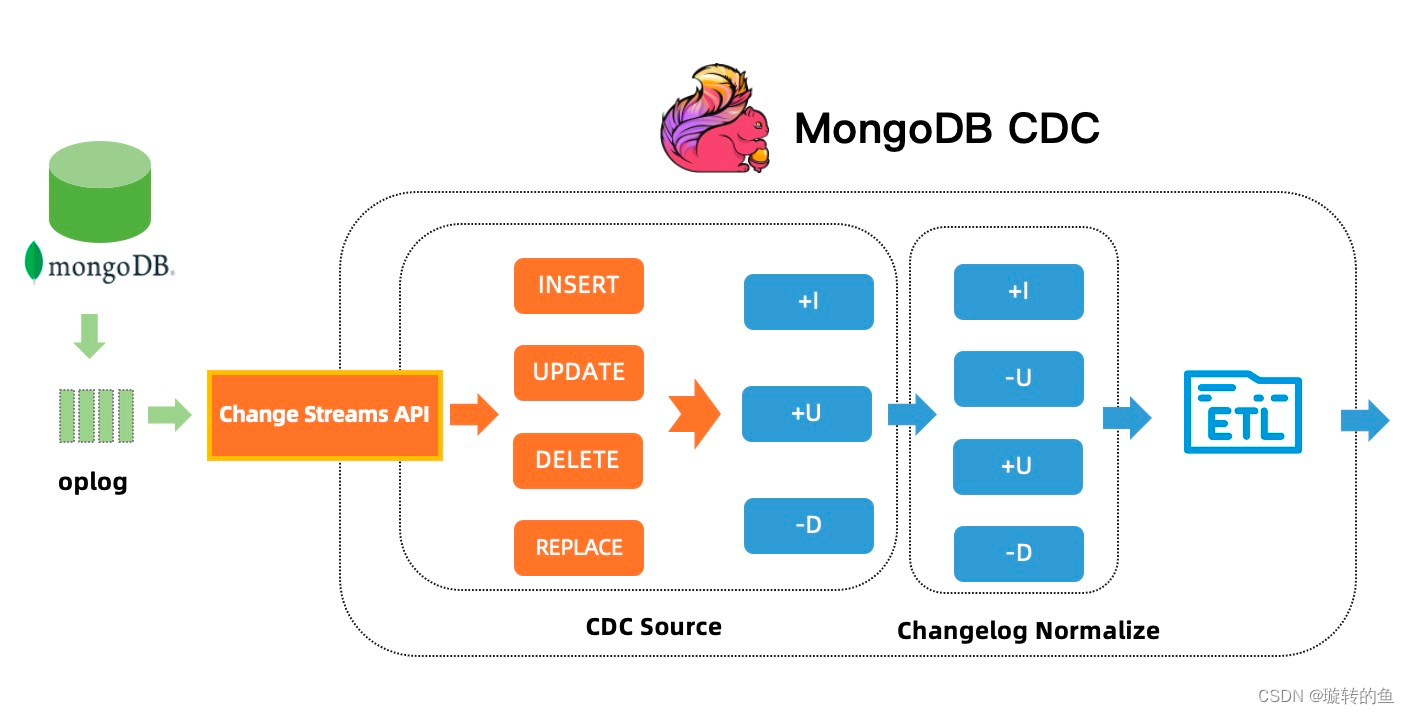
- CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
- 基于日志的CDC(迁移方案所采用的)能够实现:
- 实时消费日志,流处理,例如 MySQL 的Binlog日志完整记录了数据库中的变更,可以把Binlog文件当作流的数据源;
- 保障数据一致性,因为Binlog文件包含了所有历史变更明细;
- 保障实时性,因为类似Binlog的日志文件是可以流式消费的,提供的是实时数据;
- 增量同步能力:可以很好的做到增量同步。
- 选用Flink CDC的理由:
- 支持全量+增量同步;
- 分布式架构、支持断点续传;
- 不丢数据:Exactly Once (确保所有的操作只执行一次);
- 生态比较完善,现成的mongodb-cdc和tddl-cdc连接器工具,使用成本低;
- 面向SQL的语法,将复杂的同步过程封装掉,只需要简单的SQL语句就能完成同步。
- Flink CDC的基本原理:
- Flink MongoDB CDC 连接器支持捕获并记录 MongoDB 数据库中实时变更数据,其原理是伪装一个 MongoDB 集群里副本,利用 MongoDB 集群的高可用机制,该副本可以从 master 节点获取完整 oplog(operation log) 事件流。Change Streams API 则提供实时订阅这些 oplog 事件流的能力,可以将这些实时的 oplog 事件流推送给订阅的应用程序。
- 建立CDC连接时,会结合数据库内容和oplog 做一份checkpoint,将这部分数据批量导入到mysql中,完成之后,之后基于checkpoint后的oplog转换成同步的SQL。

B. Fink CDC的数据同步流程
- 假设需要迁移MongoDB中的一张公告表announces,字段类型如下:
| 字段名称 | 字段类型 |
|---|---|
| _id | ObjectId |
| title | String |
| content | String |
| priotity | NumberInt |
| creatorId | String |
| modifierId | String |
| created | ISODate |
| updated | ISODate |
| isDeleted | Boolean |
-
STEP 1 :在MySQL中建立同名的一张表:announces,(最好是同名,当然不同名也没关系),按照MongoDB中的字段名称依次创建字段。
-
根据公司数据库创建规范,需要有一个自增的主键,所以创建MySQL表时,保留自增主键id,实际使用的是uid(即MongoDB中的_id)
-
MySQL的uid映射MongoDB的_id字段,由于MongoDB的ObjectId类型是24位的字符串,所以定义uid为varchar(36)
MySQL字段名称 MySQL字段类型 映射MongoDB的字段名称 id bigint unsigned 无(MySQL的自增主键) uid varchar(36) _id title text title content text content priotity int(11) priotity creator_id varchar(36) creatorId modifier_id varchar(36) modifierId gmt_create datetime(3) created gmt_modified datetime(3) updated is_deleted varchar(1) isDeleted
-
-
STEP 2 :编写Flink CDC同步脚本,这里可以借助的阿里云的Flink平台来进行同步任务。Flink CDC的脚本写法如下:
-- 创建数据源表 [用于连接MongoDB,将需要迁移的Mongo表数据读取到Flink的动态表中] CREATE TEMPORARY TABLE announces ( `_id` STRING, `title` STRING, `content` STRING, `priority` INT, `creatorId` STRING, `modifierId` STRING, `created` TIMESTAMP, `updated` TIMESTAMP, `isDeleted` BOOLEAN, PRIMARY KEY (_id) NOT ENFORCED ) WITH ( 'connector' = '指定连接器 [mongodb-cdc]', 'hosts' = '填写需要连接的MongoDB地址', 'username' = '填写MongoDB数据库用户名', 'password' = '填写MongoDB数据库密码', 'database' = '填写需要读取的数据库', 'collection' = '填写需要读取的集合名' );-- 创建输出表 [用于连接MySQL] create TEMPORARY table ANNOUNCES_NEW ( `uid` VARCHAR(36), `title` STRING, `content` STRING, `priority` INT, `creator_id` VARCHAR(36), `modifier_id` VARCHAR(36), `gmt_create` TIMESTAMP, `gmt_modified` TIMESTAMP, `is_deleted` VARCHAR(1), PRIMARY KEY (uid) NOT ENFORCED ) with ( 'connector' = '指定连接器 [tddl]', 'appName' = '填写TDDL的appName', 'tableName' = 'TDDL中的表名', 'isSharding' = '是否分库分表', 'accessKey' = '填写accessKey', 'secretKey' = '填写secretKey' );-- 进行字段映射,执行数据同步过程 [将MongoDB数据写入到MySQL] BEGIN STATEMENT SET; insert into ANNOUNCES_NEW SELECT _id as uid, title, content, priority, creatorId as creator_id, modifierId as modifier_id, IFNULL(`created`, LOCALTIMESTAMP) as `gmt_create`, IFNULL(`updated`, LOCALTIMESTAMP) as `gmt_modified`, (CASE WHEN `isDeleted`=false THEN 'n' ELSE 'y' END) as `is_deleted` FROM announces; END; -
STEP 3 :上传编写好的作业脚本,运行脚本等待数据同步完成即可。
C. Flink CDC使用过程踩坑记录
-
MongoDB中的isDeleted(含义:是否删除)定义为Boolean类型,MySQL中并没有Boolean类型,因此MySQL中采用Varchar(1)进行存储,取值为 “n” 和 “y”。SQL的 IF…THEN…语句无法使用,需要使用CASE…WHEN…ELSE语句进行处理;注意:尽量采用写法一。这样做是因为MongoDB中的数据由于历史原因,有的记录里面没有isDeleted字段,对于没有的情况,写法二会将数据同步为
isDeleted=‘y’,造成数据同步错误,而写法一则会同步为isDeleted=‘n’。当然,也可以直接采用写法三。-- 写法一 (CASE WHEN `isDeleted`=true THEN 'y' ELSE 'n' END) as `is_deleted`, -- 写法二 (CASE WHEN `isDeleted`=false THEN 'n' ELSE 'y' END) as `is_deleted`, -- 写法三 (CASE WHEN `isDeleted` is null THEN null WHEN `isDeleted`=true THEN 'y' ELSE 'n' END) as `isDeleted`, -
如果在MySQL中定义了Json类型来映射MongoDB中的数据,目前Flink CDC官方已经支持将Json作为STRING进行读取写入;
-
由于MongoDB的灵活性以及历史操作原因,在同步MongoDB一个表数据时发现,存在一条记录中包含created字段,而另一条记录中不包含,会造成同步失败,需要进行判空处理;如果存在其他字段为空的情况,可以采用同样的方式进行处理。
IFNULL(`created`, LOCALTIMESTAMP) as `gmt_create`, IFNULL(`updated`, LOCALTIMESTAMP) as `gmt_modified`, -
在Java中会将Json格式映射为String,但是在写入MySQL时,发现String类型的数据写入到MySQL中的Json类型失败,无法写入,处理方式为:在定义MySQL字段时,不采用Json类型,使用Text类型代替;
-
MongoDB中的特殊类型:比如数组类型、文档类型,根据业务需求进行处理,一般有两种方式:
- 进行拆表,将这些复杂类型的字段拆成一张新的表,通过外键关联起来;
- 考虑直接作为一个String类型的大文本进行存储,在代码中进行解析,拿到大文本中的各个字段值;
-
某些大文本字段,在创建表时,采用text类型进行存储,但是在实际同步时发现,会存在几条数据的长度超出了text字段的长度范围,最好在定义MySQL字段时预先查询一下MongDB中该字段的最大长度再决定采用text还是mediumtext、longtext。
-
MongoDB会将整数默认保存为int,而浮点型会默认保存为double,导致一个表中的记录的weight字段,有时候是int有时候是double。解决方法是将MySQL中该字段定义为decimal(n, m)类型,在Flink CDC脚本都使用decimal(n, m)来读取MongoDB和MySQL中该字段的值。
-
对Dao层接口进行重构后进行单测对比时发现,MongoDB的ISODate类型的字段使用datetime来接收会存在问题,不会精确到毫秒,且存在时区问题,因此为了确保重构后的接口获取的值与原接口一摸一样,所以在映射ISODate字段时采用datetime(3)类型。
-
MongoDB中某些字段的值中包含ObjectId类型、ISODate类型的字段,比如:
'emails': [ { '_id': ObjectId("xxxxxxxxxxxxxxxxxxxxxxxx"), 'email': "xxx@alibaba-inc.com", 'state': 0 } ],Flink CDC源码中会自动加上 “$oid”(ISODate类型会自动加上 “$date”),同步成MySQL的字段值为:
[{"_id": {"$oid": "xxxxxxxxxxxxxxxxxxxxxxxx"}, "email": "xxx@alibaba-inc.com", "state": 0}]这里可以通过在代码中进行处理,比如转为json对象后,截取字符串获取到对应的值。也可以拉取Flink Mongo CDC源码,在源码中删除" o i d " 、 " oid"、" oid"、"date"等添加的字段,编译打包后上传到实时计算平台,在同步时使用上传的connector进行同步。
-
在本地Flink任务工作台跑迁移的作业时,如果出现报错:没有可用的数据源,需要在pom.xml的的中加入:
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/> -
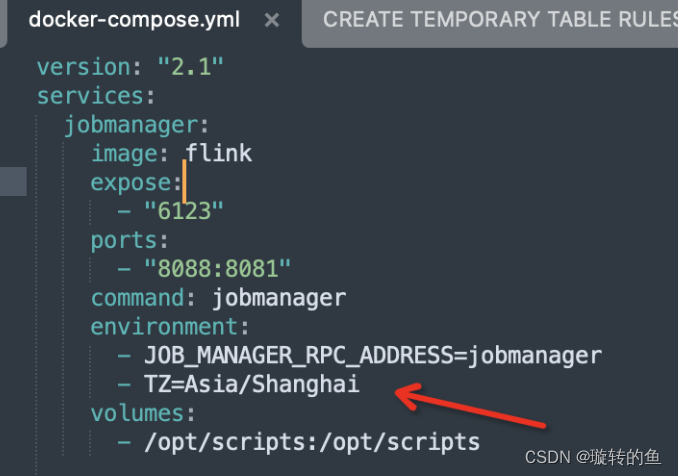
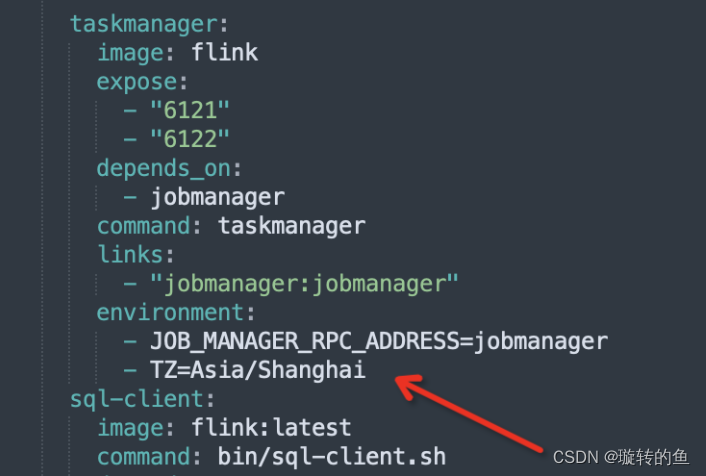
本地Flink CDC同步时间字段的数据时,遇到时区问题,会产生8小时的时差,在docker脚本environment增加时区和tddl保持一致,可以解决mongo->mysql时间时区问题(flink默认0时区导致sink到mysql也是0时区)
D. 代码切流方案设计
-
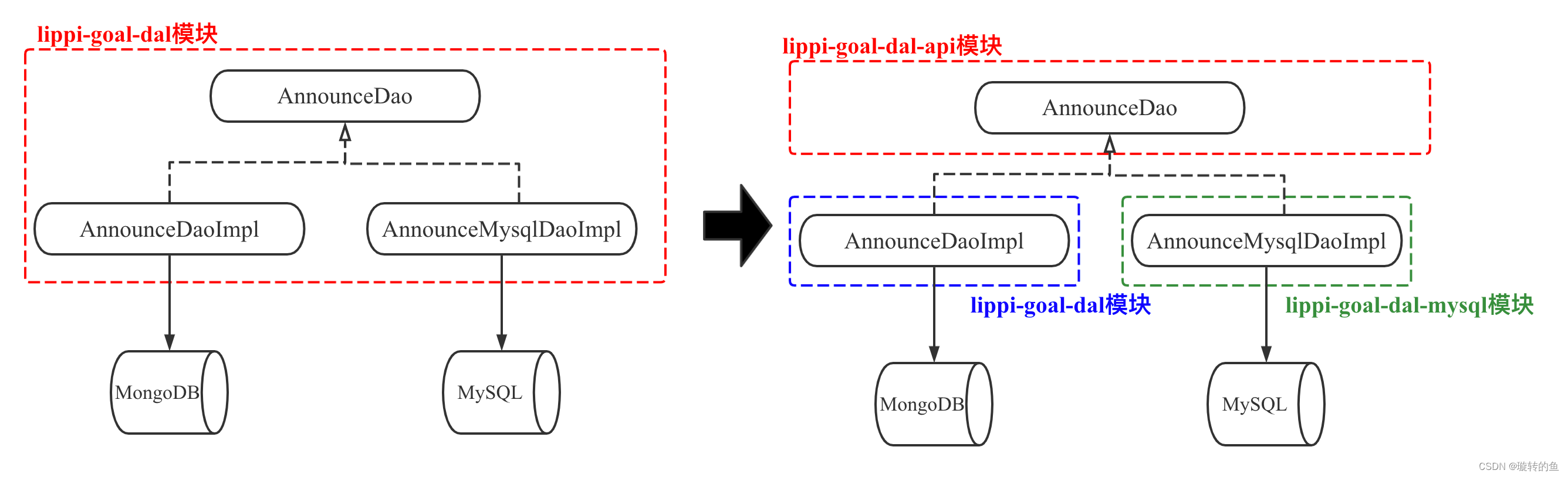
模块改造:增加api模块存放公共Dao层接口,同时新增dal-mysql模块存放MySQL的实现类。原来的dal模块仍存放MongoDB的实现类。
- 解决模块功能杂糅,做到单一职责
- 区分MySQL和MongoDB的实现类,每个模块功能单一
- 新增加lippi-goal-dal-instrumentation模块,该模块仅仅用了写单元测试,用于校验两个实现(Mongo和MySQL)返回的结果是否完全一致,即验证重构后的接口实现类是否能完成与原接口实现相同的功能。
-
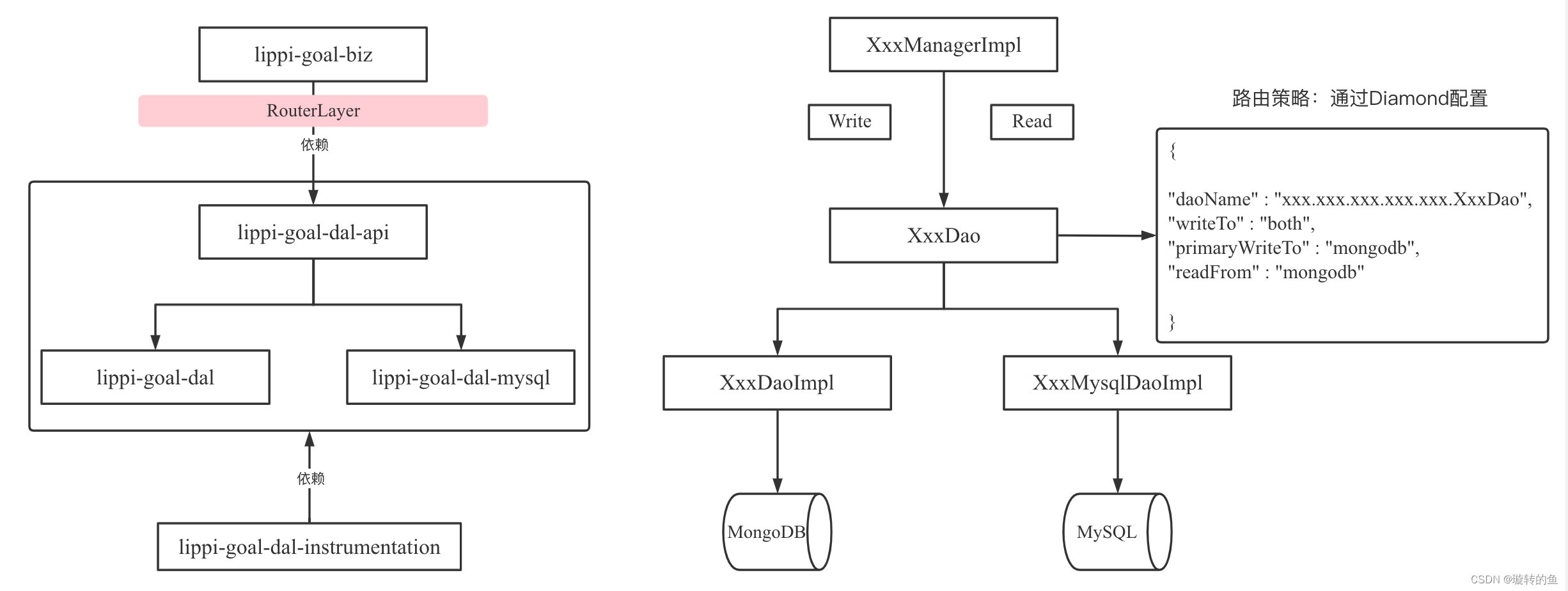
新增动态路由层,即RouterLayer,基于Spring的BeanDefinition拓展,获取到Dao接口下两种实现的动态代理对象,通过读取配置好的路由策略(路由策略可以配置在配置中心上),来决定具体走哪一种实现,做到上下游无感,将代码侵入做到最低。
-
在Dao层接口上,添加注解@RouterDao ,表明此Dao需要被动态数据库切换
@RouterDao public interface AnnounceDao {} -
修改MongoDB的Bean声明,指定Bean Name,以mongodb前缀开头
// MongoDB实现类 - 改造前 @Service public class AnnounceDaoImpl implements AnnounceDao {} // MongoDB实现类 - 改造后 @Component("mongodbAnnounceDao") public class AnnounceDaoImpl implements AnnounceDao {} -
新增MySQL实现类,并实现 lippi-goal-dal-api定义的Dao层对应接口,指定Bean Name以mysql前缀开头
@Component("mysqlAnnounceDao") public class AnnounceDaoImpl implements AnnounceDao {} -
扫描指定包下的所有被@RouterDao注解打标的Dao接口服务类,扩展这些Dao接口的BeanDefinition,将这些Dao的BeanClass设置为动态路由类(RouterDaoFactory.class),这样Spring在获取Dao接口的实现类时,会通过RouterDaoFactory来获取实例
public class RouterDaoBeanDefinitionRegistry implements BeanDefinitionRegistryPostProcessor, ResourceLoaderAware, ApplicationContextAware { private static final String DEFAULT_RESOURCE_PATTERN = "**/*.class"; private MetadataReaderFactory metadataReaderFactory; private ResourcePatternResolver resourcePatternResolver; private ApplicationContext applicationContext; @Override public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException { String scanPackages = applicationContext.getEnvironment().getProperty(CONST_ROUTER_SCAN_PACKAGES); if (StringUtils.isEmpty(scanPackages)) { throw new BeanCreationException( "ROUTER-DAO initialization failed,please check com.dingtalk.router.scanPackages has configured."); } // 扫描Dao包,获取该包下面的所有被@RouterDao注解打标的Dao接口类 Set<Class<?>> beanClazzs = scannerPackages(scanPackages); for (Class beanClazz : beanClazzs) { BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(beanClazz); GenericBeanDefinition definition = (GenericBeanDefinition)builder.getRawBeanDefinition(); definition.getConstructorArgumentValues().addGenericArgumentValue(beanClazz); // 修改Dao接口类的BeanClass为动态路由类 definition.setBeanClass(RouterDaoFactory.class); //这里采用的是byType方式注入,类似的还有byName等 definition.setAutowireMode(GenericBeanDefinition.AUTOWIRE_BY_TYPE); definition.setPrimary(true); registry.registerBeanDefinition(CONST_ROUTER_BEAN_PREFIX + "#" + beanClazz.getSimpleName(), definition); } } /** * 根据包路径获取包及子包下的所有类 * @param basePackage basePackage * @return Set<Class < ?>> Set<Class<?>> */ private Set<Class<?>> scannerPackages(String basePackage) { Set<Class<?>> set = new LinkedHashSet<>(); String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + DEFAULT_RESOURCE_PATTERN; try { Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath); for (Resource resource : resources) { if (resource.isReadable()) { MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource); String className = metadataReader.getClassMetadata().getClassName(); Class<?> clazz; try { clazz = Class.forName(className); RouterDao routerDao = clazz.getAnnotation(RouterDao.class); if (null != routerDao) { set.add(clazz); } } catch (ClassNotFoundException e) { e.printStackTrace(); } } } } catch (IOException e) { e.printStackTrace(); } return set; } protected String resolveBasePackage(String basePackage) { return ClassUtils.convertClassNameToResourcePath( this.getEnvironment().resolveRequiredPlaceholders(basePackage)); } @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { } @Override public void setResourceLoader(ResourceLoader resourceLoader) { this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader); this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader); } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } private Environment getEnvironment() { return applicationContext.getEnvironment(); } } -
定义动态路由类:RouterDaoFactory,并实现FactoryBean接口,通过重写getObject( )方法来动态获取需要的实现类。在该类中还需要对所有的写方法打标。
public class RouterDaoFactory<T> implements FactoryBean<T> { private Class<T> interfaceType; @Resource private ApplicationContext applicationContext; @Resource @Setter private RouterDaoPolicyProvider routerDaoPolicyProvider; public RouterDaoFactory(Class<T> interfaceType) { this.interfaceType = interfaceType; } @Override public T getObject() throws Exception { // 通过动态代理来获取对应的实例 // proxy : 代理对象 // method : 调用的方法 // args : 方法的参数 InvocationHandler invocationHandler = (proxy, method, args) -> { try { Map<String, T> instances = applicationContext.getBeansOfType(interfaceType); Pair<T, T> databaseInstancePair = findInstancesByType(instances); if (Arrays.stream(interfaceType.getDeclaredMethods()).noneMatch( item -> StringUtils.equals(method.getName(), item.getName()))) { return method.invoke(databaseInstancePair.getRight(), args); } // MongoDB的实现 T mongodbInstance = databaseInstancePair.getLeft(); // MySQL的实现 T mysqlInstance = databaseInstancePair.getRight(); // 路由策略配置 RouterPolicy routerPolicy = routerDaoPolicyProvider.getRouterPolicy(interfaceType.getName()); if (null == routerPolicy) { if (MapUtils.isEmpty(instances)) { throw new BeanIsNotAFactoryException(interfaceType.getName(), interfaceType); } return method.invoke(mongodbInstance, args); } log.debug("ROUTER-DAO-LAYER, INTERFACE:{}, METHOD:{}, POLICY:{}", interfaceType, method.getName(), JSONObject.toJSONString(routerPolicy)); Boolean hasMultipleInstance = databaseInstancePair.getLeft() != databaseInstancePair.getRight(); // 主库,双写时不同阶段的主读写库不一样,通过这里实现的 Boolean isMongodbPrimaryWrite = CONST_MONGODB.equalsIgnoreCase(routerPolicy.getPrimaryWriteTo()); T throwableInstance = isMongodbPrimaryWrite ? mongodbInstance : mysqlInstance; T catchableInstance = isMongodbPrimaryWrite ? mysqlInstance : mongodbInstance; if (isWrite(method)) { if (CONST_MONGODB.equalsIgnoreCase(routerPolicy.getWriteTo())) { return method.invoke(mongodbInstance, args); } if (CONST_MYSQL.equalsIgnoreCase(routerPolicy.getWriteTo())) { //尝试预填充id tryInitId(method, args); return method.invoke(mysqlInstance, args); } // 双写情况,确保主写按照正常逻辑,副写采用兜底逻辑,保证最大限度的交付 if (CONST_BOTH.equalsIgnoreCase(routerPolicy.getWriteTo())) { //有不同的实现,则看下优先策略 if (hasMultipleInstance) { //尝试预填充id tryInitId(method, args); //执行需要捕获异常的实例 try { method.invoke(catchableInstance, args); } catch (Exception e) { log.error("ROUTER-DAO-LAYER, write-error,database:{},daoName:{},params:{}", isMongodbPrimaryWrite ? "mysql" : "mongo", catchableInstance.getClass().getName(), JSONObject.toJSONString(args), e.getCause() == null ? e : e.getCause()); } //执行可以抛出异常的实例 return method.invoke(throwableInstance, args); } return method.invoke(databaseInstancePair.getRight(), args); } } if (isRead(method)) { if (CONST_MONGODB.equalsIgnoreCase(routerPolicy.getReadFrom())) { return method.invoke(databaseInstancePair.getLeft(), args); } if (CONST_MYSQL.equalsIgnoreCase(routerPolicy.getReadFrom())) { return method.invoke(databaseInstancePair.getRight(), args); } } // 兜底策略 return method.invoke(databaseInstancePair.getLeft(), args); } catch (InvocationTargetException e) { if (null != e.getCause()) { throw e.getCause(); } throw e; } catch (Exception e) { throw e; } }; return (T)Proxy.newProxyInstance(interfaceType.getClassLoader(), new Class[] {interfaceType}, invocationHandler); } public Pair<T, T> findInstancesByType(Map<String, T> instances) { T mongoInstance = null, mysqlInstance = null; //将动态代理生成的服务剔除掉 Optional<String> delegateKey = instances.keySet().stream().filter( item -> item.startsWith(CONST_ROUTER_BEAN_PREFIX)).findFirst(); delegateKey.ifPresent(instances::remove); // 找mongo 实现 Optional<String> optionalMongo = instances.keySet().stream().filter( item -> item.startsWith(CONST_ROUTER_DAO_PREFIX_MONGO)).findFirst(); if (optionalMongo.isPresent()) { mongoInstance = instances.get(optionalMongo.get()); } // 找mysql 实现 Optional<String> optionalMysql = instances.keySet().stream().filter( item -> item.startsWith(CONST_ROUTER_DAO_PREFIX_MYSQL)).findFirst(); if (optionalMysql.isPresent()) { mysqlInstance = instances.get(optionalMysql.get()); } // 如果未涉及到特殊改造,统一走默认的实现逻辑,默认mongo if (!optionalMongo.isPresent() && !optionalMysql.isPresent() && instances.size() == 1) { T defaultInstance = instances.values().stream().findFirst().get(); mongoInstance = defaultInstance; mysqlInstance = defaultInstance; } if (null == mongoInstance) { mongoInstance = mysqlInstance; } if (null == mysqlInstance) { mysqlInstance = mongoInstance; } if (null == mongoInstance || null == mysqlInstance) { throw new BeanIsNotAFactoryException(interfaceType.getName(), interfaceType); } return Pair.of(mongoInstance, mysqlInstance); } /** * 给主键id赋值 * @param method 调用方法 * @param args 方法参数 */ private void tryInitId(Method method, Object[] args){ try { Parameter[] parameters = method.getParameters(); for(int i = 0; i < parameters.length; i++) { Parameter param = parameters[i]; if(param.isAnnotationPresent(InitId.class)) { Class<?> clazz = param.getType(); Object realArg = args[i]; String keySetMethodStr = "set" + param.getAnnotation(InitId.class).keyField(); String keyGetMethodStr = "get" + param.getAnnotation(InitId.class).keyField(); Class orignClazz = param.getAnnotation(InitId.class).clazz(); // 如果是List<T>范型 if (clazz.isAssignableFrom(List.class)) { if( !(orignClazz == Object.class) ) { clazz = orignClazz; } else { Type[] actualTypeArguments = ((ParameterizedType)param.getParameterizedType()).getActualTypeArguments(); clazz = (Class<?>)actualTypeArguments[0]; } Method setId = clazz.getMethod(keySetMethodStr, String.class); Method getId = clazz.getMethod(keyGetMethodStr); List<?> list = (List<?>) realArg; for(Object o : list){ if(getId.invoke(o) == null) { setId.invoke(o, ObjectId.get().toString()); } } } else { if( !(orignClazz == Object.class) ) { clazz = orignClazz; } // 普通model类型 Method setId = clazz.getMethod(keySetMethodStr, String.class); Method getId = clazz.getMethod(keyGetMethodStr); if(getId.invoke(realArg) == null) { setId.invoke(realArg, ObjectId.get().toString()); } } } } }catch (Exception e) { log.error("ROUTER-DAO-LAYER, tryInitId-error, method:{}", method.getName(), e.getCause() == null ? e : e.getCause()); } } /** * 判断是否是写操作,未来需要补充下注解形式作为兜底 * * @param method * @return */ private Boolean isWrite(Method method) { String methodName = method.getName(); // 第一个:要把每一个方法看一下命名规则和真正试行是不是一致;第二个如果不一致,看能不能方法上通过注解的方式打标,标识写行为 return methodName.startsWith("save") || methodName.startsWith("insert") || methodName.startsWith("add") || methodName.startsWith("reset") || methodName.startsWith("update") || methodName.startsWith("remove") || methodName.startsWith("ensure") || methodName.startsWith("delete") || methodName.startsWith("batchSave") || methodName.startsWith("batchInsert") || methodName.startsWith("batchUpdate") || methodName.startsWith("create") || methodName.startsWith("batchRemove") || methodName.startsWith("batchDelete") || methodName.startsWith("batchSafeDelete") || methodName.startsWith("batchLogicalRemove"); } private Boolean isRead(Method method) { return !isWrite(method); } @Override public Class<T> getObjectType() { return interfaceType; } @Override public boolean isSingleton() { return true; } }
-
-
既然要进行双写,需要确保写入两库的数据完全一致,如何保证两个数据的UID一致?
-
定义方法参数注解:@InitId,给需要处理UID的方法参数添加该注解
-
在路由层进行双写前,利用Java的反射技术,获取到方法中有@InitId注解打标的参数。通过反射获取到id字段的get和set方法,并通过反射调用getId方法,如果获取不到则调用setId方法设置一个UID
private void tryInitId(Method method, Object[] args){ try { Parameter[] parameters = method.getParameters(); for(int i = 0; i < parameters.length; i++) { Parameter param = parameters[i]; if(param.isAnnotationPresent(InitId.class)) { Class<?> clazz = param.getType(); Object realArg = args[i]; String keySetMethodStr = "set" + param.getAnnotation(InitId.class).keyField(); String keyGetMethodStr = "get" + param.getAnnotation(InitId.class).keyField(); Class orignClazz = param.getAnnotation(InitId.class).clazz(); // 如果是List<T>范型 if (clazz.isAssignableFrom(List.class)) { if( !(orignClazz == Object.class) ) { clazz = orignClazz; } else { Type[] actualTypeArguments = ((ParameterizedType)param.getParameterizedType()).getActualTypeArguments(); clazz = (Class<?>)actualTypeArguments[0]; } Method setId = clazz.getMethod(keySetMethodStr, String.class); Method getId = clazz.getMethod(keyGetMethodStr); List<?> list = (List<?>) realArg; for(Object o : list){ if(getId.invoke(o) == null) { setId.invoke(o, ObjectId.get().toString()); } } } else { if( !(orignClazz == Object.class) ) { clazz = orignClazz; } // 普通model类型 Method setId = clazz.getMethod(keySetMethodStr, String.class); Method getId = clazz.getMethod(keyGetMethodStr); if(getId.invoke(realArg) == null) { setId.invoke(realArg, ObjectId.get().toString()); } } } } }catch (Exception e) { log.error("ROUTER-DAO-LAYER, tryInitId-error, method:{}", method.getName(), e.getCause() == null ? e : e.getCause()); } }
-
-
路由策略配置:通过配置中心来配置每一张表的路由策略
[ { "daoName": "com.dingtalk.goal.dal.api.dao.AnnounceDao", // 需要路由的Dao服务 "writeTo": "both", // 写库(both:双写,mongo, mysql) "primaryWriteTo": "mongodb", // 主写库,以此库执行结果为准 "readFrom": "mongodb" // 读库 } ]
E. 数据一致性比对遇到的挑战&解法
-
异构数据同步带来的"伪"一致性问题
- 由于异构数据本身存储特性的差异,导致在迁移过程中,即使利用Flink数据同步能适配大部分数据类型,但仍存在一些数据无法完美适配。比如MongoDB中的文档类型[Document]在转换到TDDL的Json类型时,会转成Bson的格式。
- TDDL 对应字段:
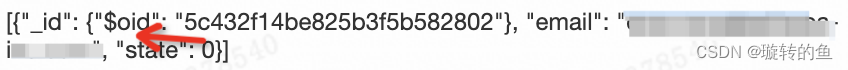
- 如上图id字段,转换到TDDL的过程中由于是Bson类型因此会写入$oid字段,造成与MongoDB不一致的情况,而在业务语义上,认为该数据应当是一致的。
-
异构数据同步带来的"伪"一致性问题解决方案:由于此次迁移节奏较快、且前期已存在部分如上迁移完毕的数据、为保证不影响到历史数据比对以及稳定性等因素,我们选择了第二种方案作为此次生产上使用。
-
方案一:从源头抓起,修改Flink转换模块源码以适配业务。实现:整理Flink MongoDB CDC转换模块源码链路如下:
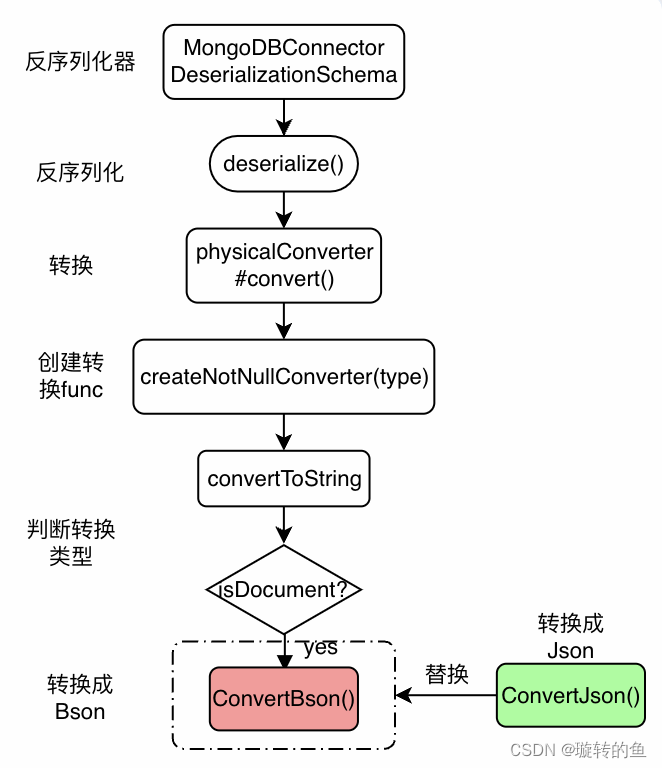
根据链路可知可以自行实现Json转换逻辑后进行替换
优点:从源头抓起,同步期间便解决问题
缺点:Mongo CDC本身内部数据流转复杂,调用链路繁多,需要对其有较强的掌控力,贸然修改代码容易造成牵一发而动全身 -
方案二:通过编写UDF上传至DataWorks进行数据清洗 。实现:通过自行Java代码实现UDF(用户自定义函数)并上传至大数据平台,在Mongo和TDDL数据同步完成后新增数据任务节点进行统一的数据清洗:
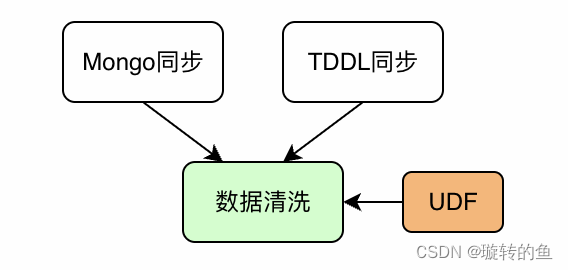
优点:通过自行编写UDF函数来做适配,屏蔽了修改Flink代码造成的风险。以及大数据平台内操作安全可靠,利用Java开发技能栈更加匹配。在使用方式上等同于SQL函数,基本没有使用成本
缺点:需要一定的代码量做适配
-
-
数据存储&比对问题:MongoDB和TDDL分别为非关系型数据库和关系型数据库。在数据类型上存在一定的差异,抽取完数据后如何进行方便、精细、准确的对比帮助我们发现问题为首要任务
-
数据存储&比对问题解决方案:在数据比对方面,云图对比相比于传统自行编写SQL具有较大的优势,因此选择了云图作为数据比对平台
- 方案一:SQL比对,抽取到数据集后通过SQL进行对比
实现:利用SQL自身携带的交叉集,表连接等特性,比对出差异结果并返回
优点:SQL开发简单,无需引用其他工具或者资源
缺点:业务表中存在大数据量表,单纯利用SQL做表连接可能会出现笛卡尔积,在表数据量大的情况下查询结果会倍增,耗时大幅增加,且比对结果可视化较差,难以第一时间发现问题所在 - 方案二:云图比对,统一将数据流转到ODPS,通过云图进行比对校验
实现:利用ODPS的海量数据处理能力,将MongoDB和MySQL的数据同步至数仓。利用云图(集团内高效可视的数据对比平台)进行比对并将结果同步推送至钉群、邮件
优点:对比结果可视化且尤为精细(字段级对比并支持差异率计算),推送机制保证高效发现数据问题
缺点:需要使用云图平台开发对比任务(几乎没有使用门槛)
- 方案一:SQL比对,抽取到数据集后通过SQL进行对比
F. 本地环境跑Flink CDC任务教程
- 方式一:本地下载Flink安装包执行:会有一些不可知的问题,比如可能JobManager、TaskManager、webUI 等组件起不来,如果对Flink不是很精通,会有很多参数调整成本
- 方式二:通过Docker镜像;
- 优点:Docker镜像将内部服务封装好了,基本确认可跑,免去了没有必要的调参成本;
- 缺点:需要对Docker有一定的了解,如目录共享,compose定义。
- Docker部署Flink教程:
-
Mac 电脑安装 Docker Desktop 。
-
Docker 安装 Flink:
- Step1:拉取镜像: docker pull flink
- Step2:创建目录,定义docker-compose.yml文件。在本地电脑创建一个空目录,如 “/opt/flink”, 然后创建如下文件:
version: "2.1" services: jobmanager: image: flink expose: - "6123" ports: - "8088:8081" command: jobmanager environment: - JOB_MANAGER_RPC_ADDRESS=jobmanager volumes: - /opt/scripts:/opt/scripts taskmanager: image: flink expose: - "6121" - "6122" depends_on: - jobmanager command: taskmanager links: - "jobmanager:jobmanager" environment: - JOB_MANAGER_RPC_ADDRESS=jobmanager sql-client: image: flink:latest command: bin/sql-client.sh depends_on: - jobmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager - Step 3:启动:docker-compose up -d 。关闭:docker-compose down。
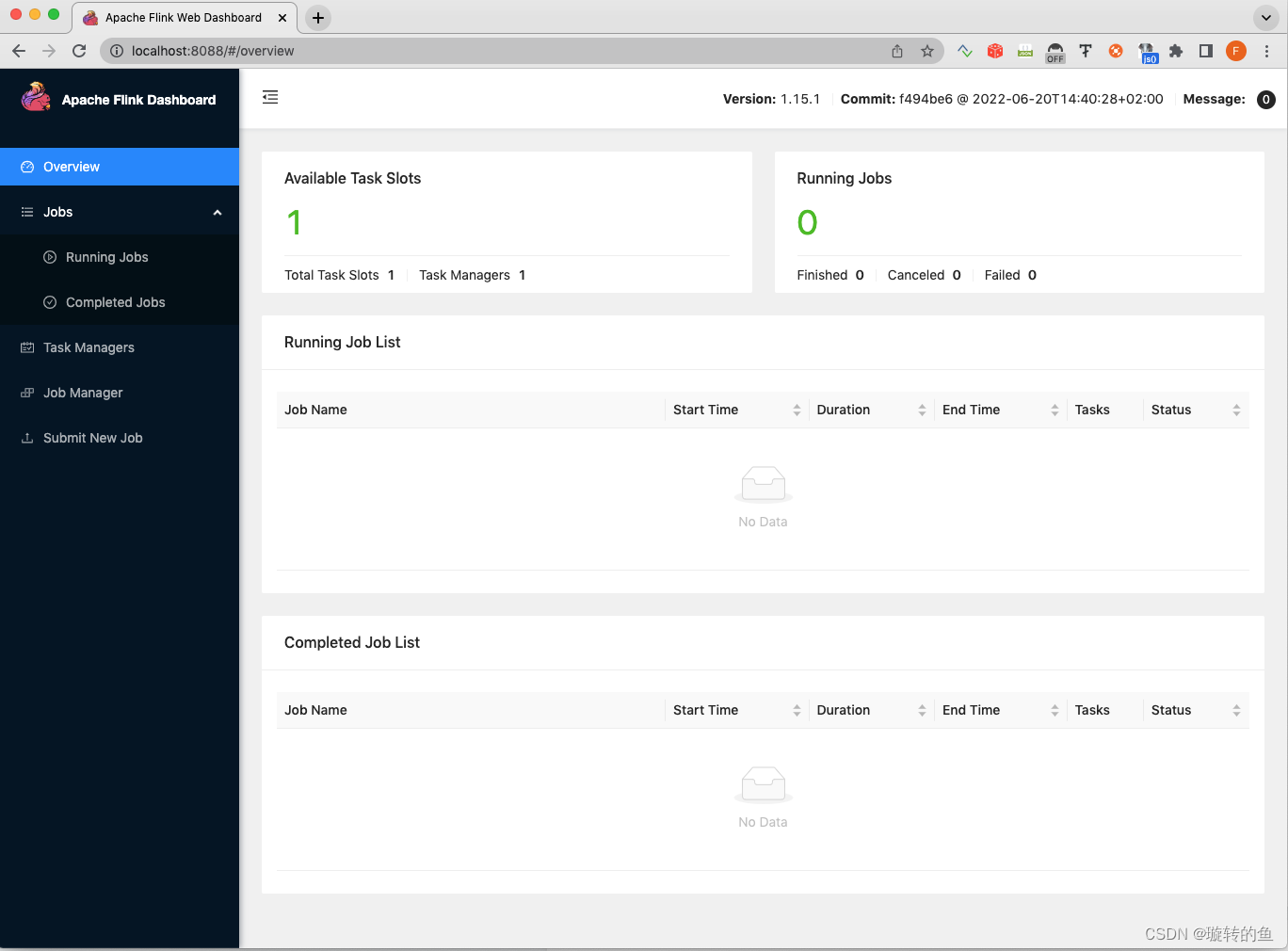
成功之后,在docker instance上会有如下:
本地访问:http://localhost:8088
-
开发运行jar包。Flink 的执行,是通过 上传jar包来完成的。jar包类需要引入Flink的相关依赖,完整的pom关系如下:
<dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-Java</artifactId> <version>5.1.40</version> </dependency> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>ververica-connector-tddl</artifactId> <version>1.16-vvr-7.0-SNAPSHOT</version> <exclusions> <exclusion> <artifactId>flink-shaded-force-shading</artifactId> <groupId>org.apache.flink</groupId> </exclusion> <exclusion> <artifactId>mysql-connector-java</artifactId> <groupId>mysql</groupId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>ververica-connector-common</artifactId> <version>1.16-vvr-7.0-SNAPSHOT</version> <exclusions> <exclusion> <artifactId>flink-shaded-force-shading</artifactId> <groupId>org.apache.flink</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-csv</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mongodb-cdc</artifactId> <version>2.3-SNAPSHOT</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>test</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <dependency> <groupId>org.hamcrest</groupId> <artifactId>hamcrest-all</artifactId> <version>1.3</version> <scope>test</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> <scope>runtime</scope> </dependency> </dependencies><build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>org.apache.flink:force-shading</exclude> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF </exclude> <exclude>META-INF/*.DSA </exclude> <exclude>META-INF/*.RSA </exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.alibaba.okr.ActivitySyncJob</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> -
Flink本地同步的脚本
public class SyncJob { public static void main(String[] args) throws Exception { String mongoSql = "CREATE TEMPORARY TABLE announces (\n" + " `_id` STRING,\n" + " `title` STRING,\n" + " `content` STRING,\n" + " `priotity` INT,\n" + " `creatorId` STRING,\n" + " `modifierId` STRING,\n" + " `created` TIMESTAMP,\n" + " `updated` TIMESTAMP,\n" + " `isDeleted` BOOLEAN,\n" + " PRIMARY KEY (_id) NOT ENFORCED\n" + ")\n" + "WITH (\n" + "'connector' = 'mongodb-cdc',\n" + " 'hosts' = '${host}',\n" + " 'username' = '${root}',\n" + " 'password' = '${password}',\n" + " 'database' = '${database}',\n" + " 'copy.existing.max.threads' = '4',\n" + " 'copy.existing.queue.size' = '500',\n" + " 'poll.max.batch.size' = '500',\n" + " 'collection' = '${collectionName}'\n" + " );"; String mysql ="create TEMPORARY table announces (\n" + " `uid` varchar(36),\n" + " `title` varchar(36),\n" + " `content` varchar(36),\n" + " `priotity` int,\n" + " `creator_id` varchar(128),\n" + " `modifier_id` varchar(128),\n" + " `gmt_create` TIMESTAMP(3),\n" + " `gmt_modified` TIMESTAMP(3),\n" + " `is_deleted` varchar(1),\n" + " PRIMARY KEY (uid) NOT ENFORCED\n" + ")\n" + "with (\n" + "'connector' = 'tddl',\n" + " 'appName' = '${tddl_app_name}',\n" + " 'tableName' = '${tableName}',\n" + " 'isSharding' = 'false',\n" + " 'bufferSize' = '400',\n" + " 'batchSize' = '200',\n" + " 'accessKey' = '${accessKey}',\n" + " 'secretKey' = '${secretKey}'\n" + ");"; String query = "SELECT _id as uid,\n" + " `title`,\n" + " `content`,\n" + " `priority`,\n" + " `creatorId` as `creator_id`,\n" + " `modifierId` as `modifier_id`,\n" + " IFNULL(`created`, LOCALTIMESTAMP) as `gmt_create`,\n" + " IFNULL(`updated`, LOCALTIMESTAMP) as `gmt_modified`,\n" + " (CASE\n" + " WHEN `isDeleted`=false THEN 'n'\n" + " ELSE 'y'\n" + " END) as `is_deleted`\n" + "FROM\n" + "announces;"; System.out.println(mongoSql); System.out.println(mysql); System.out.println(query); EnvironmentSettings settings = EnvironmentSettings.inStreamingMode(); TableEnvironment tEnv = TableEnvironment.create(settings); // MongoDB tEnv.executeSql(mongoSql); // TDDL tEnv.executeSql(mysql); //Query Table temp = tEnv.sqlQuery(query); temp.executeInsert("activityOperation"); } } -
打包上传执行
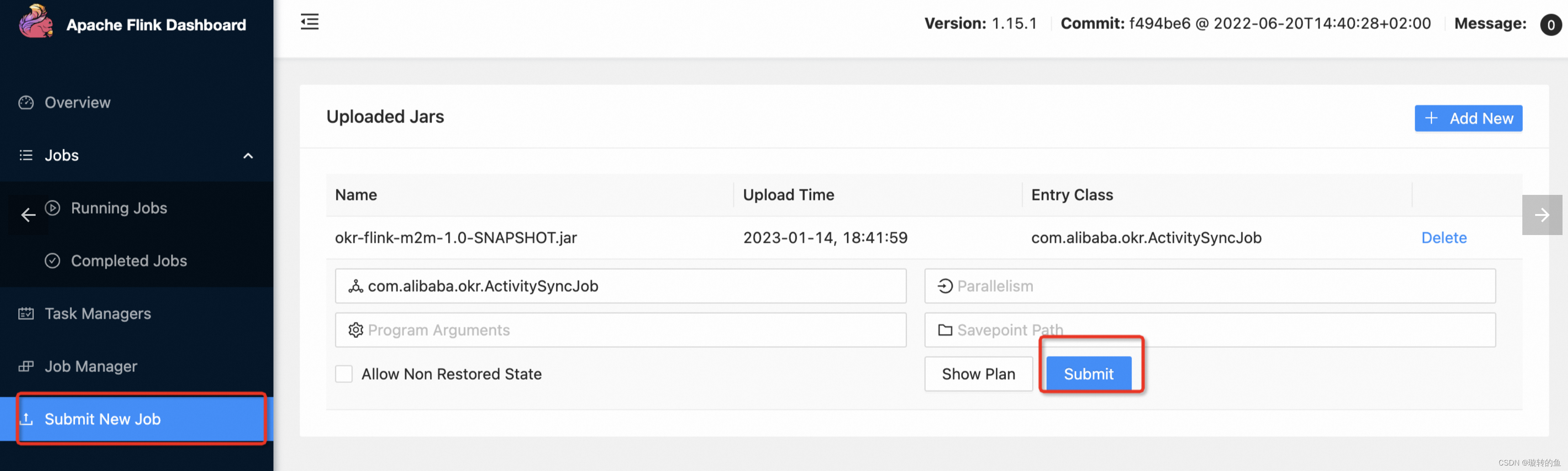
执行跑起来之后,可以看到会有数据流执行。执行成功,会有同步的SQL执行结果。
-
G. Dao层单元测试实践:testcontainers框架
DAO层是改造的重点, 那就必须要保证同一个接口在MySQL/MongoDB下的表现(入参和返回结果一致)是相同的, 考虑到DAO层是相对基础的模块, 变动较小, 使用全量单测覆盖是一个较好的验证方法。因为需要对数据进行频繁的CRUD操作, 使用日常的数据库很容易污染且不可二次插入, 因此本地Docker就成了较好的选择。在进行一番调研后, 发现了testcontainers这个测试神器。具体实践如下:
-
基础配置:
-
首先去Docker官网下载Docker Desktop, 本机启动Docker Desktop。 对于每一个DO都有对应的Test文件, 可以把相同的配置收拢到一个父class, 我们这边定义为AbstractDaoTest, 其余的DaoTest都继承这个class。
-
接着配置MySQL数据库:
@ClassRule public static MySQLContainer<?> mySqlDB = new MySQLContainer<> ("mysql:5.7.37") .withImagePullPolicy(PullPolicy.ageBased(Duration.ofDays(2650))) .withDatabaseName("lippi_goal_test") .withUsername("admin") .withPassword("admin") .withCommand("--character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci"); -
配置MongoDB数据库:
@ClassRule public static MongoDBContainer mongoDB = new MongoDBContainer ("mongo:4.2") .withImagePullPolicy(PullPolicy.ageBased(Duration.ofDays(2650)));具体的配置和自己的业务数据库保持一致, 避免因为版本不同导致其他问题。
-
动态配置Spring参数:
public static class Initializer implements ApplicationContextInitializer<ConfigurableApplicationContext> { @Override public void initialize(ConfigurableApplicationContext configurableApplicationContext) { TestPropertyValues values = TestPropertyValues.of( "spring.datasource.url=" + mySqlDB.getJdbcUrl() + "?serverTimezone=Asia/Shanghai", "spring.datasource.password=" + mySqlDB.getPassword(), "spring.datasource.username=" + mySqlDB.getUsername(), "spring.data.mongodb.uri=" + mongoDB.getReplicaSetUrl() ); values.applyTo(configurableApplicationContext); } }这样, 基本的配置就完成了, 每次启动对应的Test Class时, testcontainers会自动连接Docker, 拉取镜像, 关闭程序时自动销毁, 每次用完即删, 完美做到重复使用。
-
-
表结构初始化
- 因为是新的容器, 不同于MongoDB会在数据写入时自动创建Collection, MySQL的表结构需要提前创建。首先把相关的 建表语句/插入语句 写入一个文件中, 通过文件读取来执行指令:
文件的命名以tableName作为区分, 比如import_announces_mysql.sql, 这样方便查找和归类。/** * @param : sqlFile sql文件的位置 * @description : 在单测方法执行之前创建MySQL的表以及插入数据 */ protected void initializeMysqlTable(String tableName) { String sqlFile = getMysqlFilePath(tableName); final URL ddlTestFile = getClass().getClassLoader().getResource(sqlFile); assertNotNull("Cannot locate " + sqlFile, ddlTestFile); try (Connection connection = getJdbcConnection()) { ScriptRunner sr = new ScriptRunner(connection); //Creating a reader object Reader reader = new BufferedReader(new FileReader(new File(ddlTestFile.toURI()))); //Running the script sr.runScript(reader); } catch (Exception e) { throw new RuntimeException(e); } } - MongoDB的初始化相对简单, 读取文件中的数据, 插入即可:
/** * @param : mongoTemplate * @param : filePath MongoDB带插入的数据文件位置 * @param : clazz MongoDB的集合的实体类 * @description : 在单测方法执行之前创建MongoDB集合并插入数据 */ protected void initializeMongoCollection(MongoTemplate mongoTemplate, String collectionName, Class clazz) throws IOException { String filePath = getMongoFilePath(collectionName); ClassPathResource classPathResource = new ClassPathResource(filePath); String result = FileUtils.readFileToString(classPathResource.getFile()); val list = JSONArray.parseArray(result, clazz); mongoTemplate.insert(list, clazz); }
- 因为是新的容器, 不同于MongoDB会在数据写入时自动创建Collection, MySQL的表结构需要提前创建。首先把相关的 建表语句/插入语句 写入一个文件中, 通过文件读取来执行指令:
-
编写方法的单测
-
Before和After的定义:
@Before public void initialize() throws Exception { initializeMongoCollection(mongoTemplate, TABLE_NAME, MONGODB_DO_CLAZZ); initializeMysqlTable(TABLE_NAME); } @After public void clearHistoryDate() { dropTableInMySQL(TABLE_NAME); dropCollectionInMongoDB(mongoTemplate, MONGODB_DO_CLAZZ); }TABLE_NAME定义为static String, 每个Class自己定义一份。除了基本的初始化数据之外, 测试中需要使用的数据也可以写在一份文件中, 按需读取:
public List<ObjectivesDO> initialization() throws IOException { ClassPathResource classPathResource = new ClassPathResource( "com.dingtalk.goal.dal.testcase/import_objectives_test_case.json"); String result = FileUtils.readFileToString(classPathResource.getFile()); return JSONArray.parseArray(result, ObjectivesDO.class); } public List<ArchiveObjectivesDO> initializationArchive() throws IOException { ClassPathResource classPathResource = new ClassPathResource( "com.dingtalk.goal.dal.testcase/import_archive_objectives_test_case.json"); String result = FileUtils.readFileToString(classPathResource.getFile()); return JSONArray.parseArray(result, ArchiveObjectivesDO.class); }后面就可以愉快的对每个方法写单测啦, 一个简单的case:
@Test public void testListByFields() throws IOException { String orgId = "5c4057f0be825b390667abee"; String executorId = "5d49951fb3a43200013ee0e6"; String periodId = "62a15b629ceff639f50b0c39"; List<ObjectivesDO> objectivesMysqlDOList = objectivesMysqlDao.listByFields(orgId, executorId, Lists.newArrayList(periodId), null, null); List<ObjectivesDO> objectivesMongoDOList = objectivesMongoDao.listByFields(orgId, executorId, Lists.newArrayList(periodId), null, null); DataValidationUtils.allAssertEquals(objectivesMysqlDOList, objectivesMongoDOList, true, true, true, true); }
-
-
踩坑经验总结:
- 插入/更新 时, 因为 插入/更新 时机的不同, MongoDB和MySQL的 创建时间/更新时间 字段的值是不一样的, 这个需要注意。
- List数据的排序问题, 在MongoDB中的List到了MySQL我们这边统一都按json处理, 所以写入时因为toJsonString会导致顺序不一致, 读取时比对的时候需要排序。
- MongoDB对于 空值/空List 的处理和MySQL不一样, MongoDB插入 空值/空List 不会报错, 会直接跳过, 但MySQL不同, 会抛出SQL的异常, 之前的代码里面经常有不判空的时候, 导致同样逻辑的代码到MySQL直接报错。
- MongoDB的主键id字段, 插入时没有的话会自动生成一个, 但是MySQL的主键id是固定的Long, 和MongoDB的不一样, 因此我们这边对于MySQL都会添加一个uid标识原来的MongoId, 因此需要注意保证两边id的一致。
五、数据库迁移结果
在项目组成员的紧密配合下,项目组历时5个月,在保障业务需求交付的同时,也完成了数据库迁移和架构优化,真正做到了“开着飞机换引擎”。经过大家的努力,最终取得了不错的结果:
- 当前系统性能(线上29台机器):线上混合场景下集群QPS可达到 800QPS; 其中RPC调用服务480QPS, 是原先期望值 (240 QPS) 的两倍。
- 迁库前后对比:经过架构优化和迁库,业务系统单机QPS 有 50% 左右的提升;另MySQL数据库本身有更好的性能表现,通过集群机器扩展,业务系统集群 QPS有200%的提升。
| 压测场景 | 场景接口数 | 平均单机QPS | 场景QPS(场景下每个接口都达到的QPS) | 场景总QPS | 核心接口80%RT | ECS CPU利用率 | MySQL CPU利用率 |
|---|---|---|---|---|---|---|---|
| 首页 | 10 | 31 | 900 | 9000 | 98.91ms | 65% | 40% |
| 调用系统 | 5 | 45 | 1300 | 6500 | 68.41ms | 60% | 45% |
| 我的团队 | 4 | 28 | 800 | 3200 | 300ms | 60% | 40% |
| 我的团队+首页+调用系统 访问QPS 比例 1:3:6 | 19 | 28 | 800 (我的团队:80 ; 首页:240; 调用系统:480) | 5120 | 130ms | 48% | 30% |
六、总结
将数据从MongoDB迁移到MySQL数据库本身是件比较难的一项工作,由于MongoDB属于非关系型数据库,目前还没有一个成熟的将非关系型数据库迁移到关系型数据库到迁移经验,现有的一些数据迁移工具仅支持同类型的数据库之间的数据迁移。经过不断地调研摸索后,终于找到了一个合适的迁移工具:Flink CDC。如果在项目中遇到需要将非关系型数据库的数据迁移到关系型数据库的需求时,可以考虑使用Flink CDC来实现。















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









