






集群的主要监控指标介绍
一、集群监控概述
成熟稳健的系统往往需要对集群运行时的各个指标进行收集,如系统的load、CPU利用率、I/O繁忙程度、网络traffic、内存利用率、应用心跳等,对这些信息进行实时监控,如发现异常情况,能够第一时间通知到相应的开发和运维人员进行处理,在用户还没有察觉之前处理完故障和异常,将损失降低到最低。
二、监控指标解释
load :反映系统的闲忙程度
-
在Linux系统中,可以通过top和uptime命令来查看系统的load值
-
系统的load定义:特定时间间隔内运行队列中的平均线程数,如果一个线程满足以下条件,该线程就会处于运行队列中:
-
没有处于I/O等待状态
-
没有主动进入等待状态,也就是没有调用wait操作
-
没有被终止 (当然load计算的算法较为复杂,因此,这种情况也不是绝对的)
-
-
load值越大,也就意味着系统的CPU越繁忙,这样线程运行完以后等待操作系统分配下一个时间片段的时间也就越长
-
CPU 1分钟内最多处理100个线程任务,load值为0.2,意味着这1分钟内CPU处理了20个任务
-
CPU 1分钟内最多处理100个线程任务,load值为1,意味着这1分钟内CPU刚好将这100个任务处理完
-
CPU 1分钟内最多处理100个线程任务,load值为1.7,意味着这1分钟内CPU除了处理了这100个任务外,还有70个任务等待处理
-
-
一般来说,只要load值不大于3,我们认为它的负载是正常的(考虑到多核CPU的系统),如果load值大于5,则表示当前系统的负载已经非常高了,需要采取相应的措施来降低系统的负载。
-
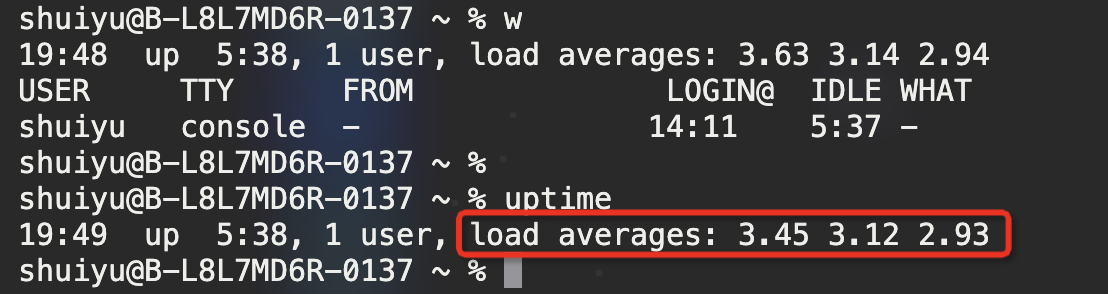
w、top、uptime这三个命令都可以用来查看系统的load值
-
-
load average后面跟的三个值分别表示在过去1分钟、5分钟、15分钟内系统的load值
-
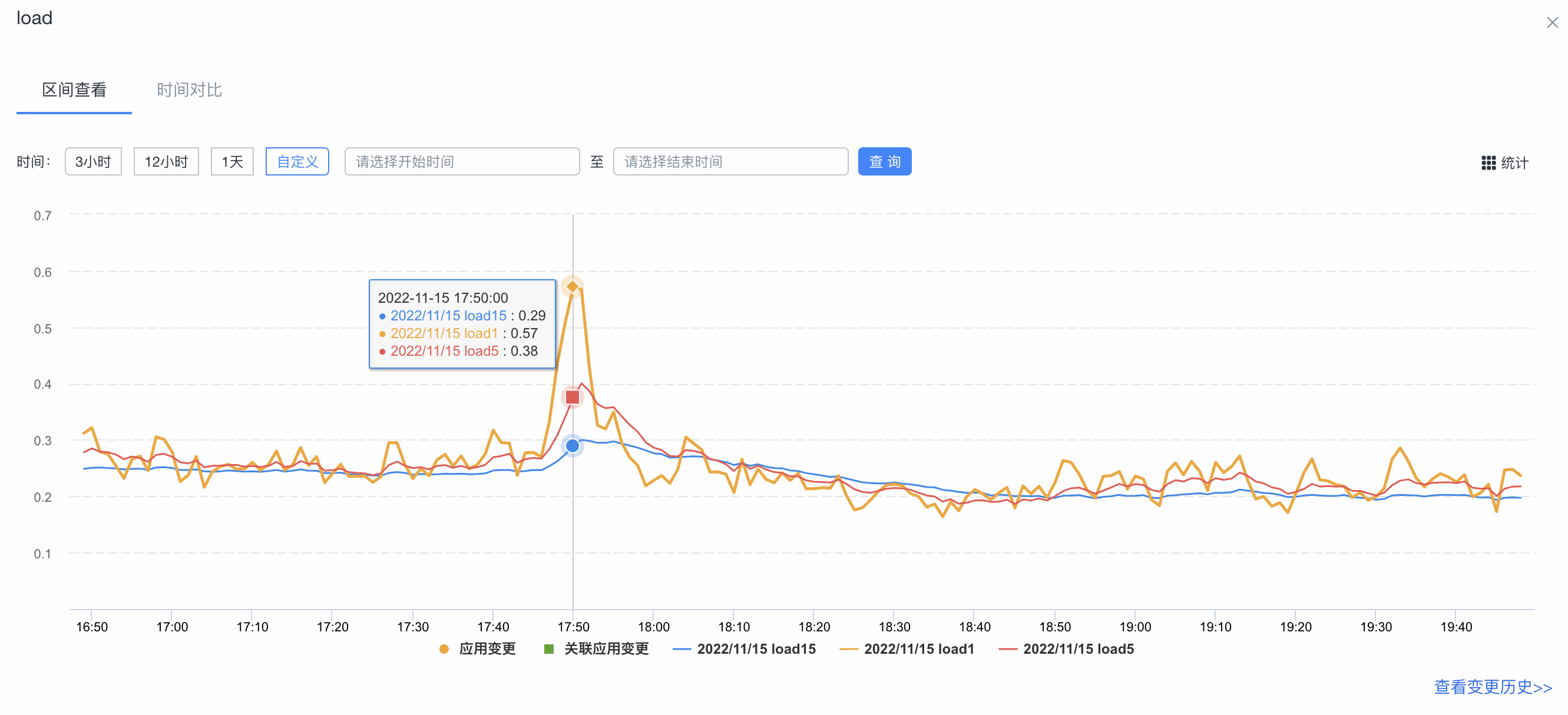
集群Load监控图:
CPU利用率:反映CPU的使用和消耗情况
-
在Linux系统中,CPU的时间消耗主要在这几个方面:用户进程、内核进程、中断处理、I/O等待、Nice时间、丢失时间、空闲等几个部分,而CPU的利用率则为这些时间所占用的总时间的百分比
-
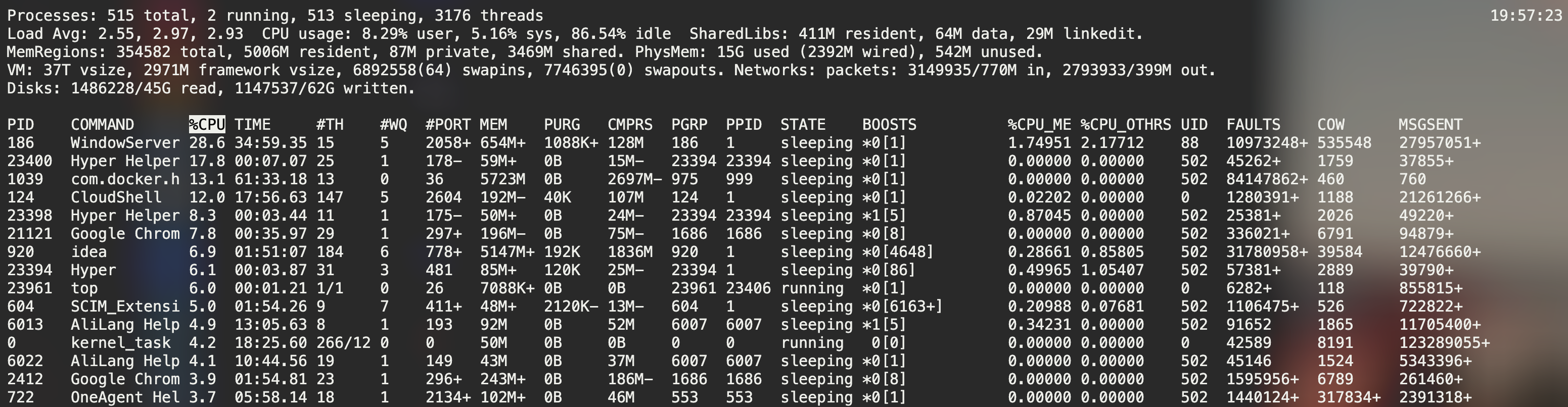
可以通过top命令来查看Linux系统的CPU消耗情况:
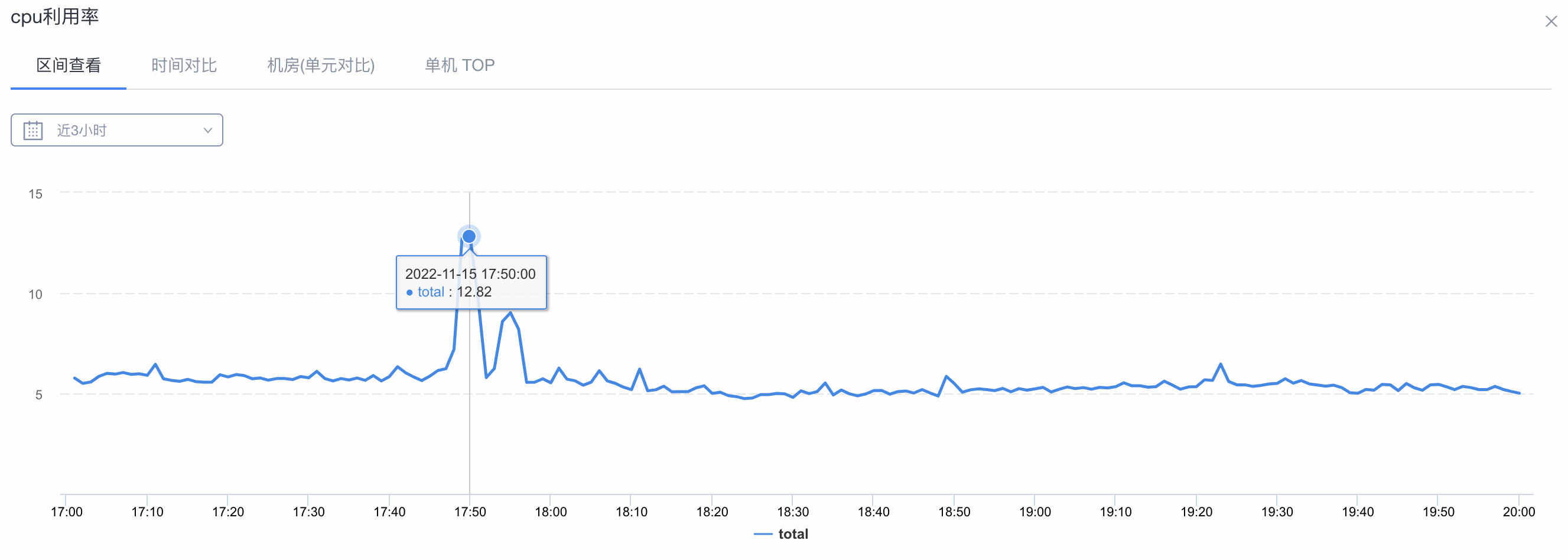
集群的CPU利用率监控图:
磁盘剩余空间
-
如果磁盘没有足够的剩余空间,正常的日志写入以及系统I/O都将无法进行
-
通过df命令可以查看磁盘的剩余空间
磁盘I/O :磁盘读/写的繁忙程度
-
对于I/O密集型的应用来说,比如数据库应用和分布式文件系统,I/O的繁忙程度也一定程度上反映了系统的负载情况,容易成为应用程序性能的瓶颈
-
可以使用iostat来查看系统的I/O状况
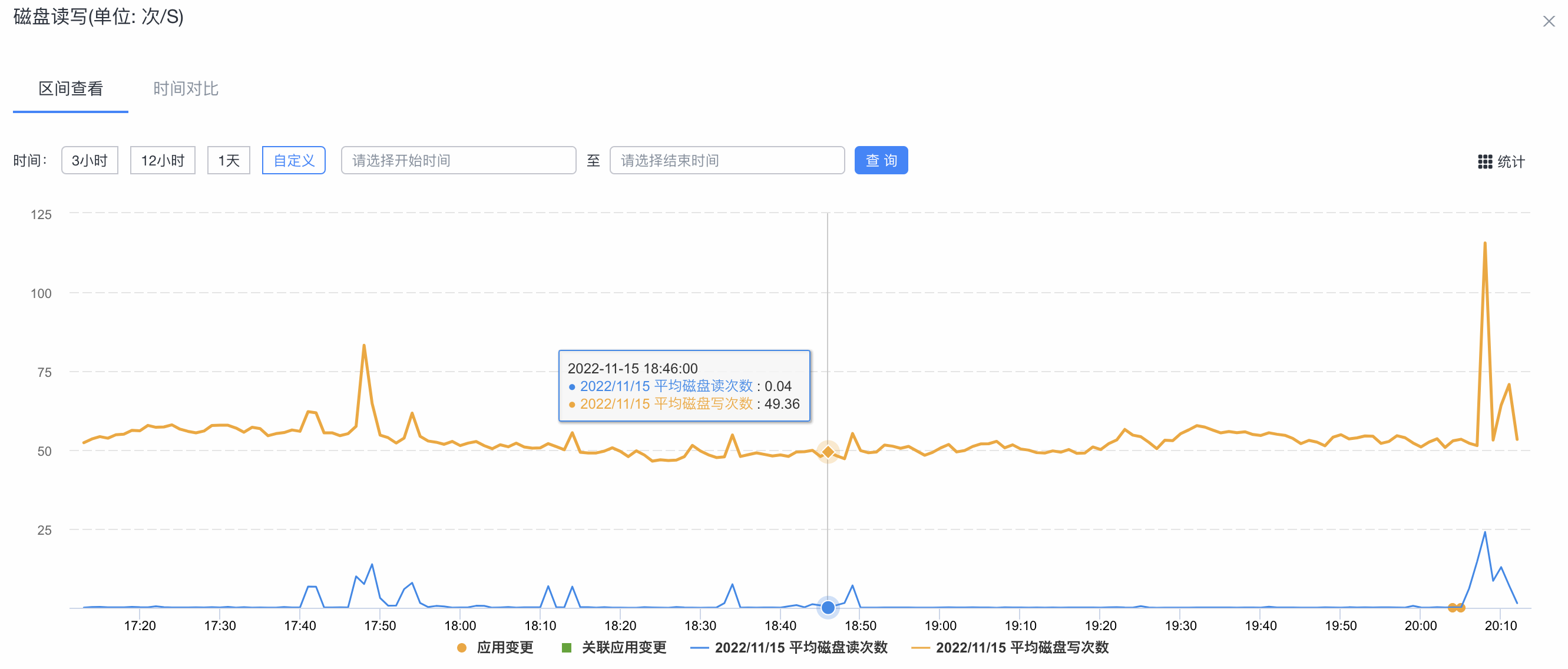
集群的磁盘读写监控图:
内存利用率
-
程序运行时的数据加载、线程并发、I/O缓冲等,都依赖于内存,可用内存的大小决定了程序是否能正常运行以及运行的性能
-
通过free命令能够查看到系统的内存使用情况
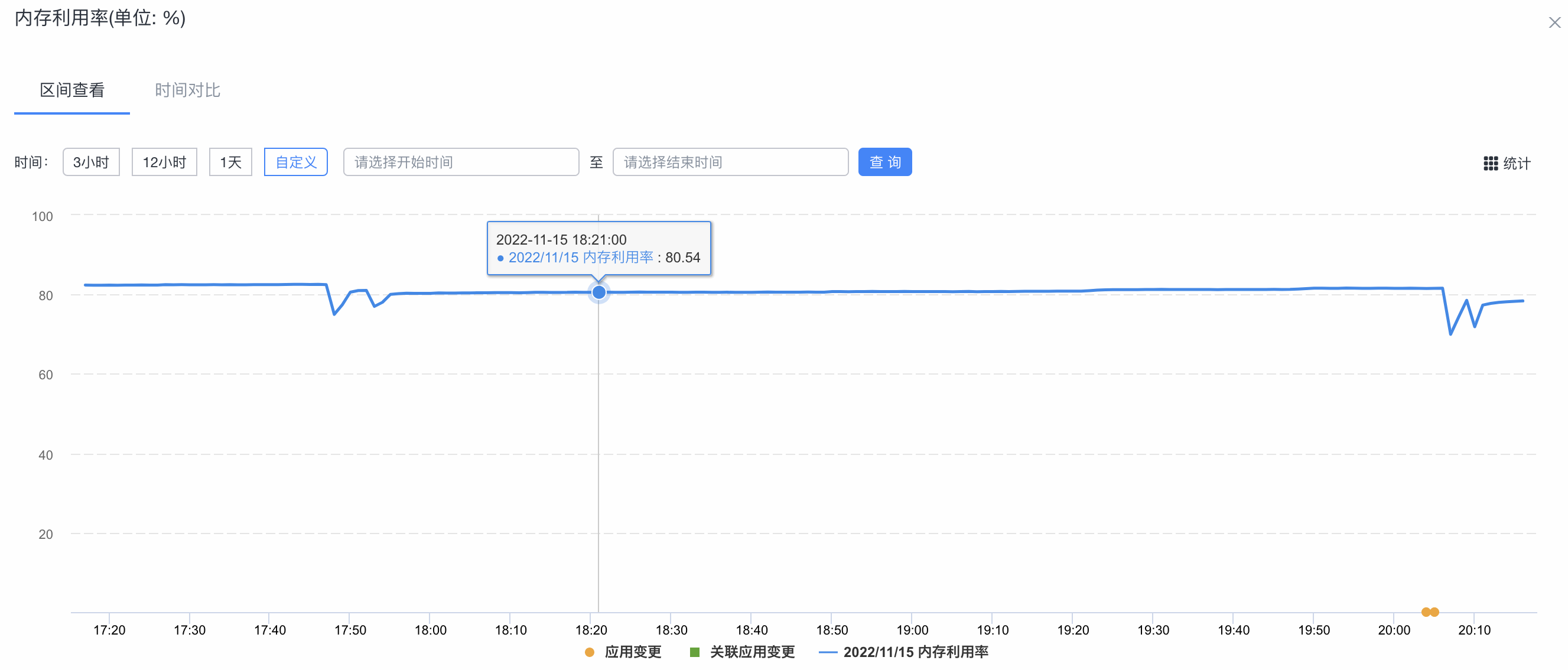
集群的内存利用率监控图:
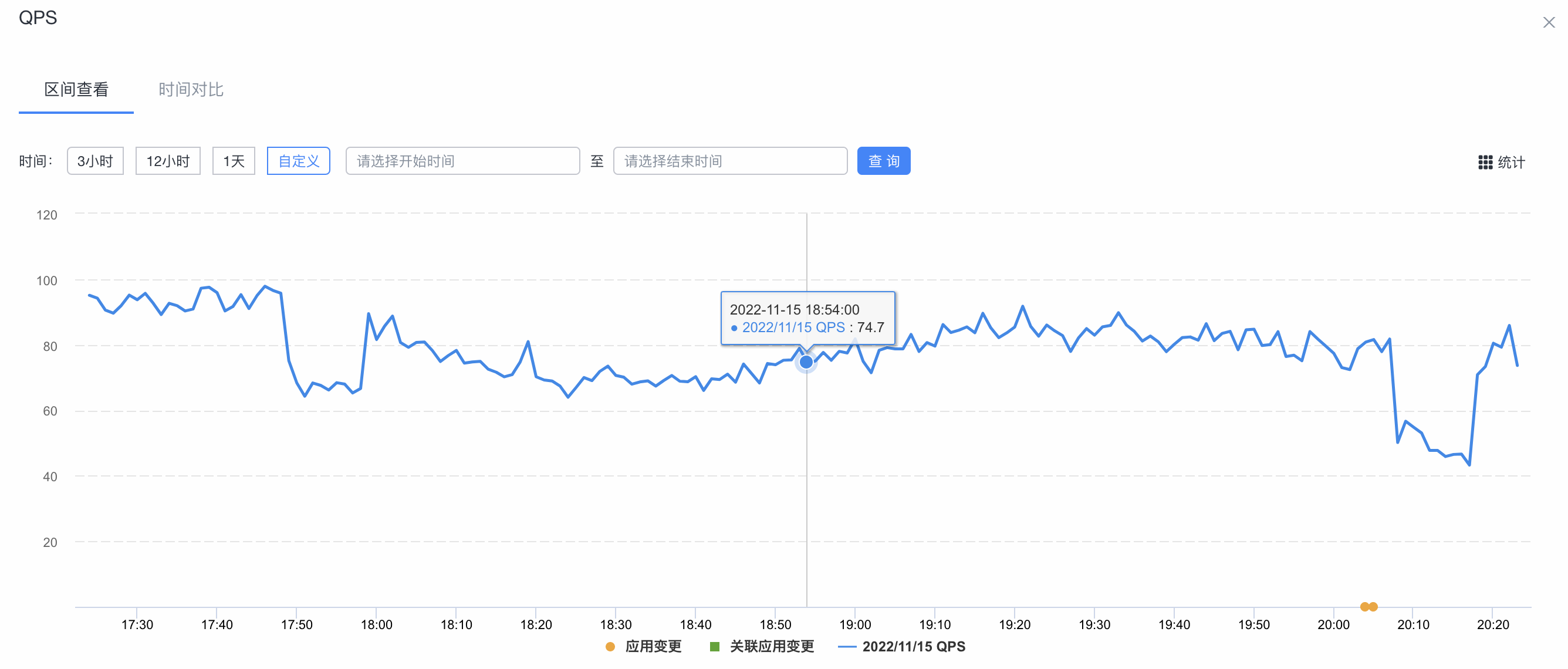
QPS :每秒查询数
-
每秒能够响应的查询次数
-
这里的查询是指用户发出请求到服务器做出响应成功的次数,简单理解可以认为查询=请求request
集群的QPS监控图:
TPS :每秒事务数
-
每秒处理的事务数
-
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程
-
客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
-
针对单接口而言,TPS可以认为是等价于QPS的,比如访问一个页面/index.html,是一个TPS,而访问/index.html页面可能请求了3次服务器比如css、js、index接口,产生了3个QPS
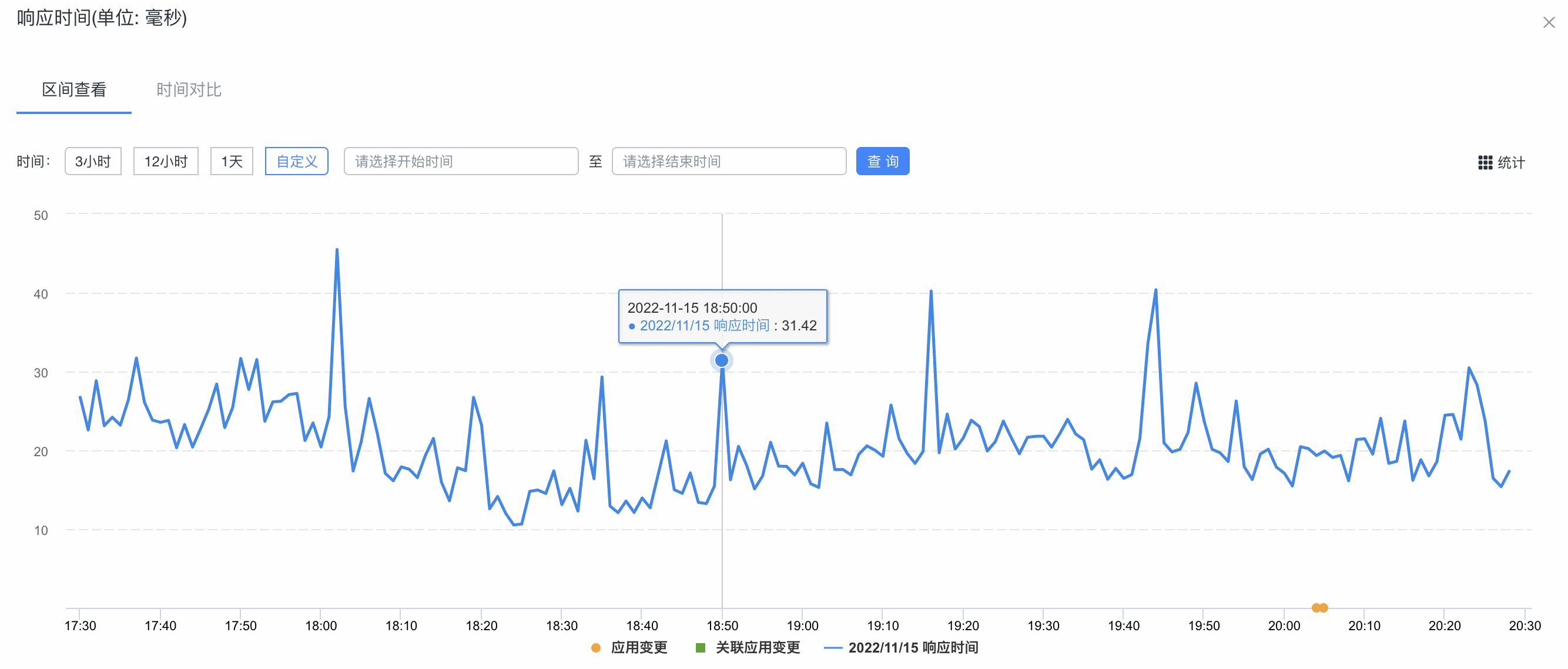
RT :响应时间
-
简单理解为系统从输入到输出的时间间隔
-
宽泛来说,代表从客户端发起请求到服务端接受到请求并响应所有数据的时间差
-
一般取平均响应时间
集群的响应时间(RT)监控图:
系统吞吐量
-
一般来说,系统吞吐量指的是系统的抗压、负载能力,代表一个系统每秒钟能承受的最大用户访问量
-
一个系统的吞吐量通常由QPS(TPS)、并发数来决定,每个系统对这两个值都有一个相对极限值,只要某一项达到最大值,系统的吞吐量就上不去了



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











