




 本篇博客介绍了一个基于RFM模型和KMeans算法开发的挖掘型标签——用户价值。首先在用户画像项目中添加四级和五级标签,然后通过代码实现RFM数据的获取、归一化、向量化、KMeans聚类,并计算每个类别的价值,最终将结果写入Hbase。整个过程详细阐述了挖掘型标签的开发流程。
本篇博客介绍了一个基于RFM模型和KMeans算法开发的挖掘型标签——用户价值。首先在用户画像项目中添加四级和五级标签,然后通过代码实现RFM数据的获取、归一化、向量化、KMeans聚类,并计算每个类别的价值,最终将结果写入Hbase。整个过程详细阐述了挖掘型标签的开发流程。
在前面的几篇博客中,博主不仅为大家介绍了匹配型标签和统计型标签的开发流程,还为大家科普了关于机器学习的一些"干货",包括但不限于KMeans算法等…本篇博客,我们将正式开发一个基于RFM模型的挖掘型标签,对RFM不了解的朋友可以👉大数据【企业级360°全方位用户画像】之RFM模型和KMeans聚类算法~

我们本次需要开发的标签是用户价值。相信光听这个标签名,大家就应该清楚这种比较抽象的标签,只能通过挖掘型算法去进行开发。
话不多说,我们来看看开发一个这样的标签需要经历哪些步骤?
添加标签
首先我们需要在用户画像项目中的web页面添加这个需求所需要的四级标签(标签名)和五级标签(标签值)。
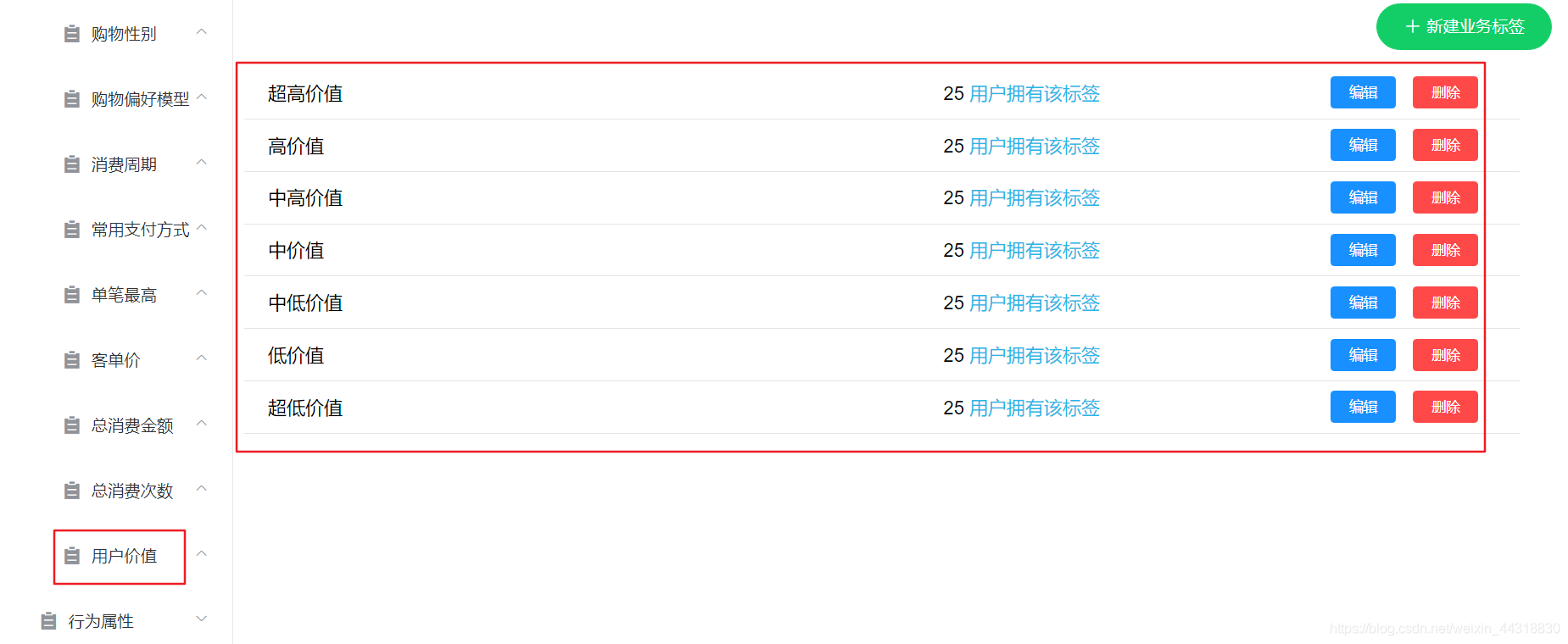
添加成功之后,我们可以在后台数据库中看到数据。
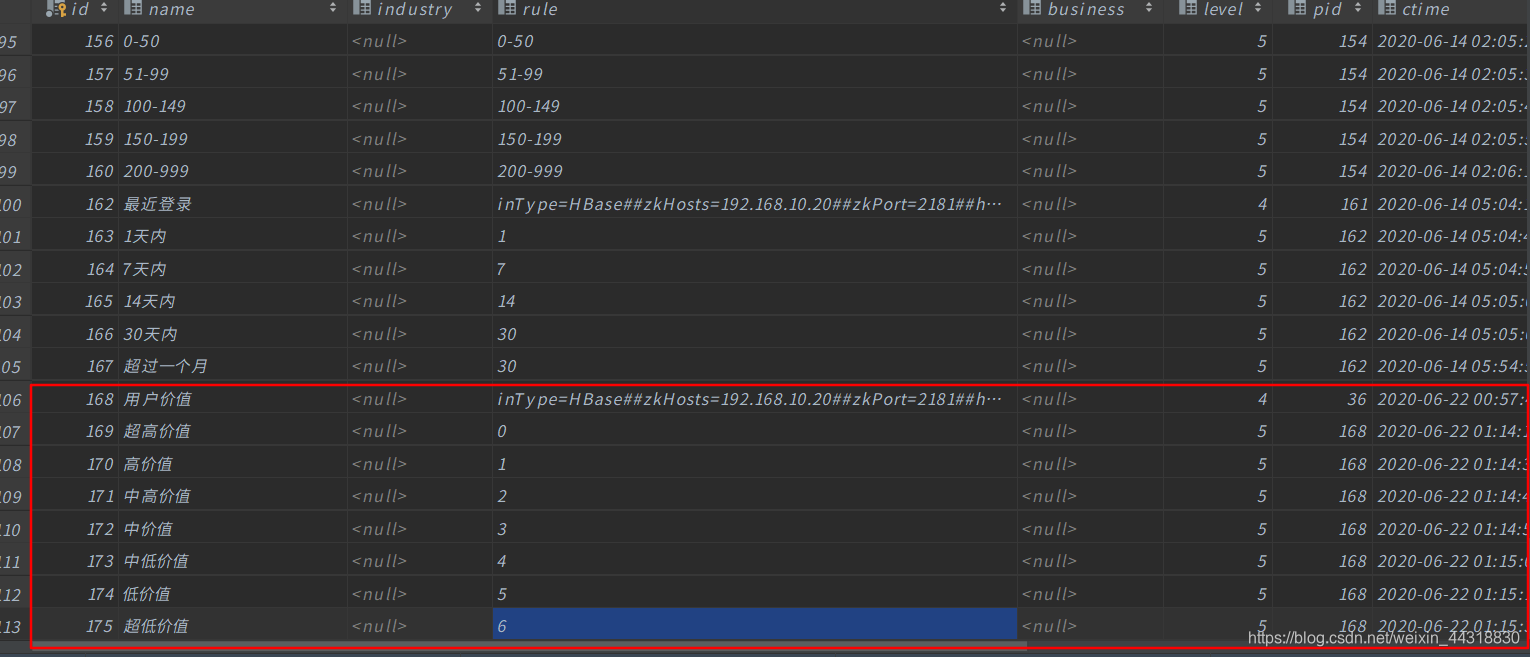
开发
页面所需标签和标签值已经准备好了,剩下的就该我们撸代码了。
准备pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>userprofile29</artifactId>
<groupId>cn.itcast.up</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Job</artifactId>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<hbase.version>1.2.0-cdh5.14.0</hbase.version>
<solr.version>4.10.3-cdh5.14.0</solr.version>
<mysql.version>8.0.17</mysql.version>
<slf4j.version>1.7.21</slf4j.version>
<maven-compiler-plugin.version>3.1</maven-compiler-plugin.version>
<build-helper-plugin.version>3.0.0</build-helper-plugin.version>
<scala-compiler-plugin.version>3.2.0</scala-compiler-plugin.version>
<maven-shade-plugin.version>3.2.1</maven-shade-plugin.version>
</properties>
<dependencies>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scalanlp</groupId>
<artifactId>breeze_2.11</artifactId>
<version>0.13</version>
</dependency>
<!-- HBase -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- Solr -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>${solr.version}</version>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>${solr.version}</version>
</dependency>
<!-- MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>cn.itcast.up29< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6708
6708











 到【灌水乐园】发言
到【灌水乐园】发言









