







Image Super-Resolution Using Very Deep Residual Channel Attention Networks
论文解决的问题:
- 更深层次的图像SR网络更难训练
- 低分辨率的输入和特征包含丰富的低频信息,这些信息在信道间被平等对待,从而阻碍了CNNs的表征能力
论文使用的主要方法:
-
提出RCAN网络
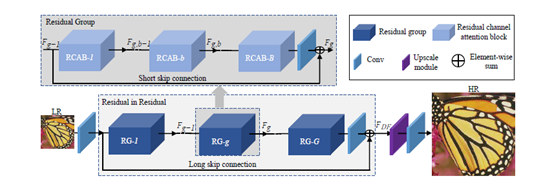
-
shallow feature extraction(与之前的模型EDSR、RDN一样):
只有一个卷积层(Conv)来提取浅特征 -
residual in residual (RIR) deep feature extraction:
它的输出作为深层特征 -
upscale module(与之前的模型EDSR、RDN一样)
several choices to serve as upscale modules:
1. 反褶积层(也称为转置卷积)
2. nearest-neighbor upsampling + convolution
3. ESPCN -
reconstruction part
(与之前的模型EDSR、RDN一样)
-
-
loss function :
- l 1 l o s s l_{1}\ loss l1 loss or l 2 l o s s l_{2}\ loss l2 loss or perceptual loss or adversarial loss
- optimized by using stochastic gradient descent
-
提出RIR(residual in residual)结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Frk4N40R-1576138599497)(../screenshot 2019-12-11-18-11-31.png)]](https://img-blog.csdnimg.cn/20191212161932919.png)
- consists of several residual groups(RG) with long skip connections(LSC)
- Each residual group contains some residual channel attention blocks(RCAB) with short skip connections(SSC)
- low-frequency information can be bypassed through identity-based skip connection
-
提出一种channel attention mechanism
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tXmRsEAv-1576138599497)(../screenshot/2019-12-11-20-34-44.png)]](https://img-blog.csdnimg.cn/20191212161953106.png)
- 提出了一种信道注意机制,通过考虑信道间的相互依赖关系,自适应地重新调整信道特征
- 问题:如何为每个不同的频道产生不同的注意是关键的一步。这里我们主要关注点:
- LR空间中的信息具有丰富的低频成分和有价值的高频成分
- Conv层的每个filer都与一个局部感受野一起工作,使得卷积后的输出无法利用局部区域以外的上下文信息
- 方法:通过使用全局平均池,我们将信道方面的全局空间信息转化为信道描述符:
- Input: X = [ x 1 , ⋯ , x c , ⋯ , x C ] X=[x_{1},\cdots,x_{c},\cdots,x_{C}] X=[x1,⋯,xc,⋯,xC]( C C C feature maps with size of H × W H\times W H×W)
- 通过空间维数
H
×
W
H\times W
H×W来缩小
X
X
X,可以得到信道统计量
z
∈
R
C
z\in \Reals^{C}
z∈RC
z c = H G P ( x c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W x c ( i , j ) z_{c}=H_{GP}(x_{c})=\frac{1}{H\times W}\sum\limits_{i=1}^{H}\sum\limits_{j=1}^{W}x_{c}(i,j) zc=HGP(xc)=H×W1i=1∑Hj=1∑Wxc(i,j) - 这种信道统计可以看作是局部描述符的集合,其统计有助于表示整个图像
- 为了通过全局平均池从聚合的信息中完全捕获信道依赖关系,我们引入了一个门机制two criteria:1.可以学习在信道间的非线性的交互。2.由于可以强调多通道特性,而不是one-hot激活,因此必须学习一种非互斥关系。
- s = f ( W U δ ( W D z ) ) s=f(W_{U}\delta(W_{D}z)) s=f(WUδ(WDz))
- f ( ⋅ ) f(\cdot) f(⋅):sigmoid gating
- δ ( ⋅ ) \delta(\cdot) δ(⋅):ReLU function
- W D W_{D} WD是一个Conv层的权值集,它的作用是按压缩比r进行信道上的下采样
- 经ReLU激活后,低纬信号按比例r通过信道上的上采样层,其权值设置为 W U W_{U} WU
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qq4hFmyq-1576138599497)(../screenshot/2019-12-11-20-35-32.png)]](https://img-blog.csdnimg.cn/20191212162015462.png)
- the residual component is mainly obtained by two stacked Conv layers
- 我们发现MDSR(no rescaling operation)和EDSR(constant rescaling 0.1,没有考虑通道之间的相互依赖关系)中使用的RBs可以看作是我们RCAB的特例















 7486
7486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









