







多元梯度下降法
多特征值
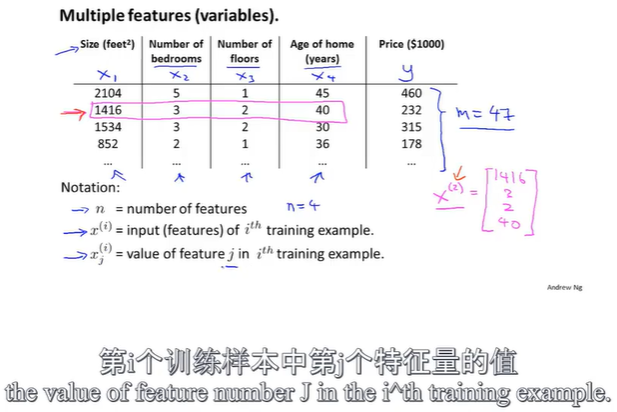
改写后的假设函数形式: h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2+...+\theta_nx_n hθ(x)=θ0+θ1x1+θ2x2+...+θnxn,其中可以认为 x 0 x_0 x0的值为1,这意味着对于第 i i i个样本都有一个向量 x ( i ) x^{(i)} x(i),并且 x 0 ( i ) = 1 x^{(i)}_0=1 x0(i)=1。即定义了第0个特征向量,其取值总是1。

所以现在我们的特征向量 X X X是一个从0开始标记的n+1维向量;同时参数 θ \theta θ也构成一个n+1维的向量,此时假设函数可以写成矩阵相乘的形式: h θ ( x ) = θ T X h_\theta(x)=\theta^TX hθ(x)=θTX
使用梯度下降法来处理多元线性回归

我们不把代价函数 J J J看做是这n+1个数的函数,因此将其改写为更通用的形式 J ( θ ) J(\theta) J(θ),表示参数 θ \theta θ这个向量的函数。若以预测房屋价格为例,则 x i x^i xi表示一个特征值, h θ ( x i ) h_\theta(x^i) hθ(xi)表示预测的房屋价格, y i y^i yi表示房屋实际价格。

在一元线性回归中,由于只有一个特征值,表示为 x i x^i xi,现在使用 x j i x^i_j xji来表示一个特征值, i i i表示第几个样本, j j j表示对应 θ j \theta_j θj。对 J ( θ ) J(\theta) J(θ)求偏导,可以得到 θ j \theta_j θj的取值。
特征缩放
一个多特征值的机器学习问题,如果能确保不同特征的取值都处在一个相近的范围内,如(-1,1)这样一个区间,这样梯度下降法就能更快地收敛。
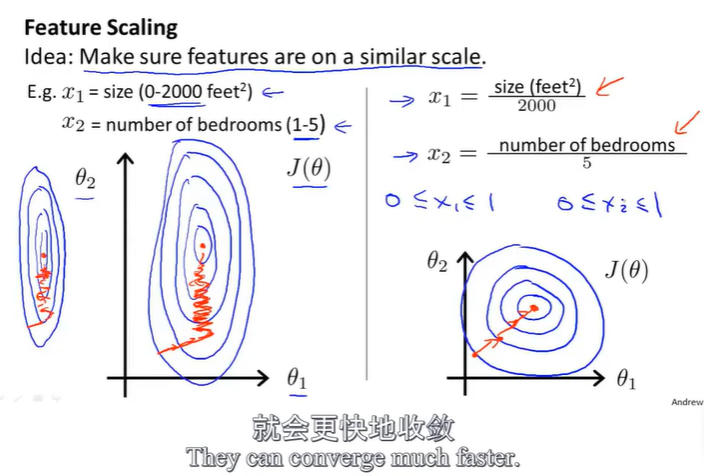
如果你的房屋面积范围是0-2000,房间数范围是0-5,两个数据相差悬殊,此时得到的代价函数的图像是左图一样的瘦高椭圆,由于梯度下降参数每次都朝着垂直等高线的方向更新,因此这种情况下的下降路径像是在反复横跳会很复杂,收敛速度更慢。
对两个数据进行右图所示的特征缩放后,将两个数据的范围都控制在0-1内,此时代价函数的图像偏移变得没那个严重,应该是接近一个圆,那么此时再朝着垂直等高线的方向更新,会更快找到圆心(此处为代价函数的最小值)。
均值归一化

其中 μ 1 \mu_1 μ1表示训练集中特征值 x 1 x_1 x1的平均值, s 1 s_1 s1表示该特征值的范围,即最大值-最小值。这种方法处理后可以让你的特征值大致处于一个相近的范围内。
特征缩放其实并不需要太精确,只是为了让梯度下降,能够运行的更快一点,所需的迭代次数更少而已。
如何选择学习率 α \alpha α?
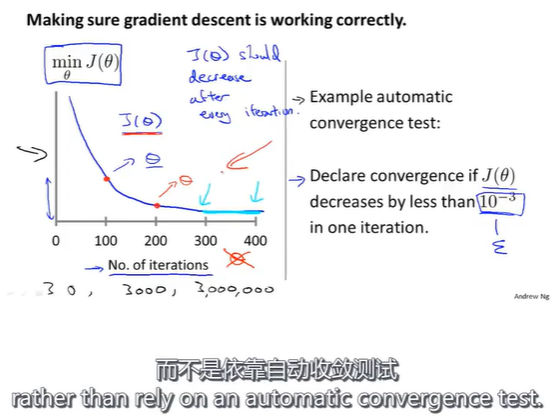
在梯度下降算法运行时,绘出代价函数 J ( θ ) J(\theta) J(θ)的值,左图中x轴表示梯度下降算法的迭代次数,随着梯度下降算法的运行,会得到一条代价函数的变化曲线,每一步迭代之后 J ( θ ) J(\theta) J(θ)都应该下降。这条曲线的作用在于他可以告诉你在多少次迭代后,梯度下降算法差不多已经收敛了。
此外,对于特定的问题,梯度下降算法所需的迭代次数可能会相差很大。实际上我们很难提前预知梯度下降算法需要迭代多少次才能收敛,所以我们可以借助这一曲线来判断梯度下降算法是否已经收敛。
另外,也可以进行一些自动的收敛测试来判断算法是否收敛。例如,当某次迭代后 J ( θ ) J(\theta) J(θ)的值小于一个很小的值 ε \varepsilon ε,这个测试就判断函数已经收敛。但是通常要选择一个合适的阈值 ε \varepsilon ε是相当困难的,因此为了检查梯度下降算法是否收敛,我们实际上更倾向于通过看左边的曲线图来判断。

这种图还能提前告诉我们算法是否正常工作。比如随着迭代次数增加,代价函数 J ( θ ) J(\theta) J(θ)的值反而不断增大,这就说明梯度下降算法没有正常工作。 J ( θ ) J(\theta) J(θ)的值上升,通常是因为 α \alpha α的值太大,导致梯度下降算法更新的步长过长,直接跳过了最小值,这意味着我们应该使用较小的学习率 α \alpha α。
数学家已经证明,只要学习率 α \alpha α足够小,每次迭代后代价函数 J ( θ ) J(\theta) J(θ)的值都会下降。不过学习率 α \alpha α过小的话,梯度下降算法可能收敛得很慢
总结: 如果 α \alpha α太小,可能导致收敛很慢;如果 α \alpha α太大,可能导致不是每次迭代的 J ( θ ) J(\theta) J(θ)的值都减小,有时导致收敛缓慢,或者可能不收敛
在运行梯度下降算法时,可以尝试一系列的 α \alpha α的值,比如0.001,0.01,0.1……每隔10倍取一个值,然后对于这些不同的 α \alpha α值绘制 J ( θ ) J(\theta) J(θ)随迭代步数变化的曲线,然后选择一个使得 J ( θ ) J(\theta) J(θ)快速下降的一个 α \alpha α值














 2018
2018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









