







 本文介绍了如何使用Python的requests库结合xpath解析技术,详细分析了8684公交查询网站的页面结构,提取了公交线路、运行时间、更新时间等关键信息,并给出了具体的代码实现步骤。
本文介绍了如何使用Python的requests库结合xpath解析技术,详细分析了8684公交查询网站的页面结构,提取了公交线路、运行时间、更新时间等关键信息,并给出了具体的代码实现步骤。
一.分析网站
url = 'http://xian.8684.cn/'
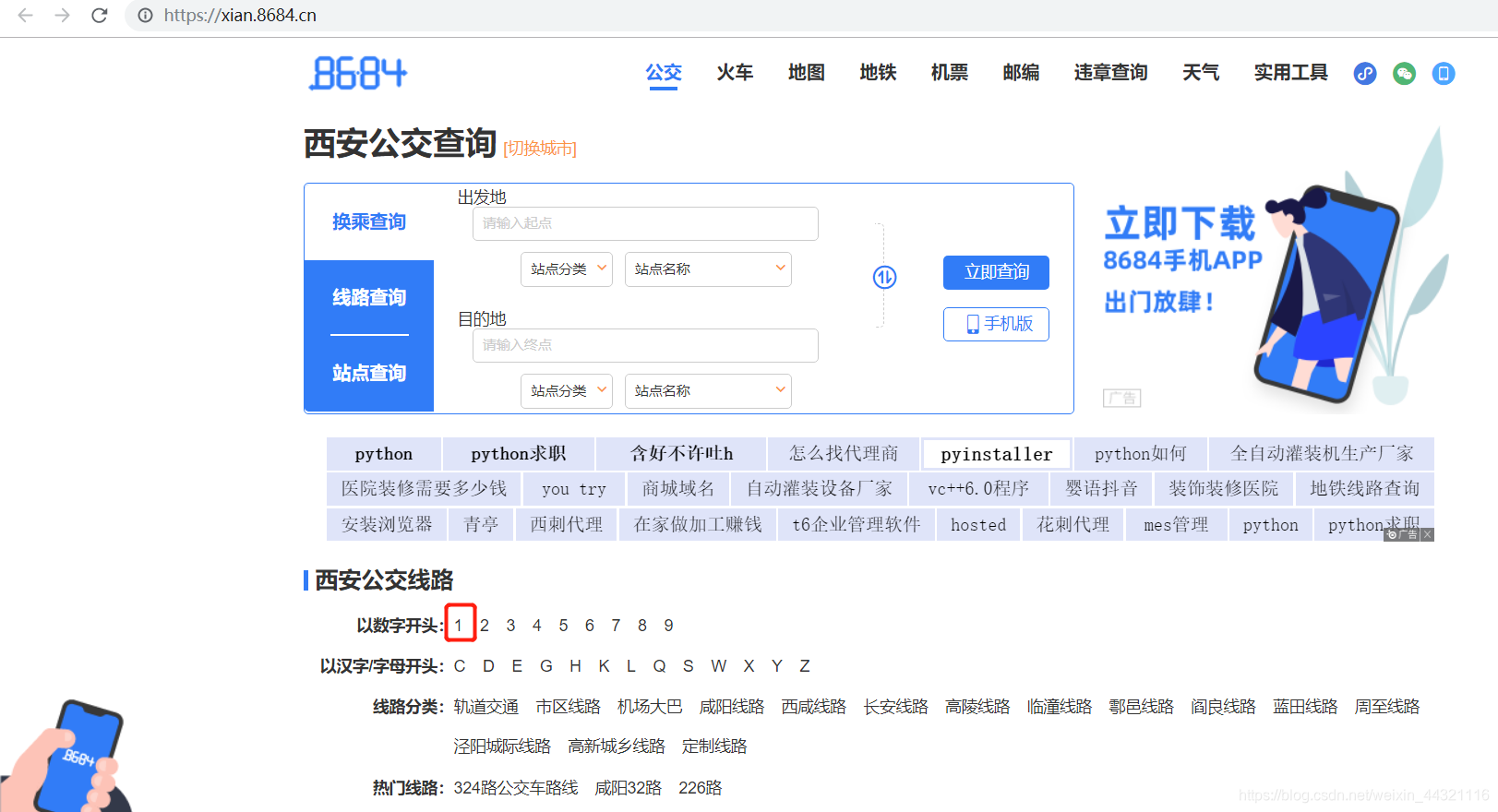
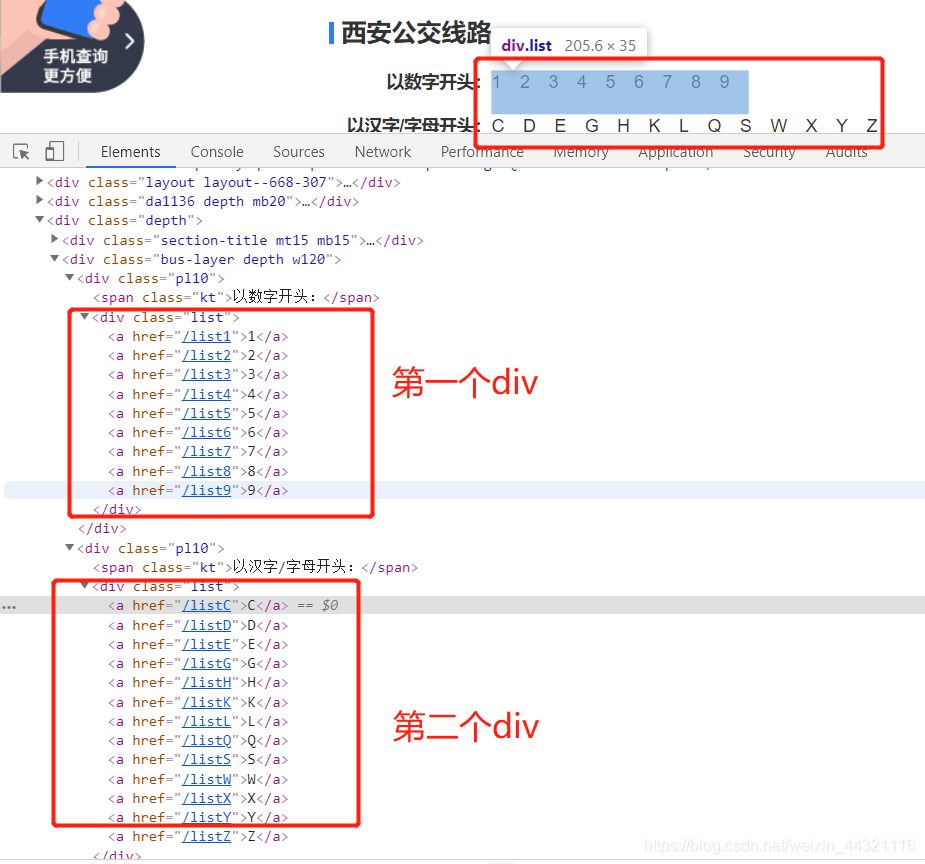
1.第二层路线xpath:
# 查找以数字开头的所有链接
number_href_list = tree.xpath('//div[@class="list"][1]/a/@href')
# 查找以字母开头的所有链接
char_href_list = tree.xpath('//div[@class="list"][2]/a/@href')
2.准确路线xpath:
route_list = tree.xpath('//div[@class="list clearfix"]/a/@href')
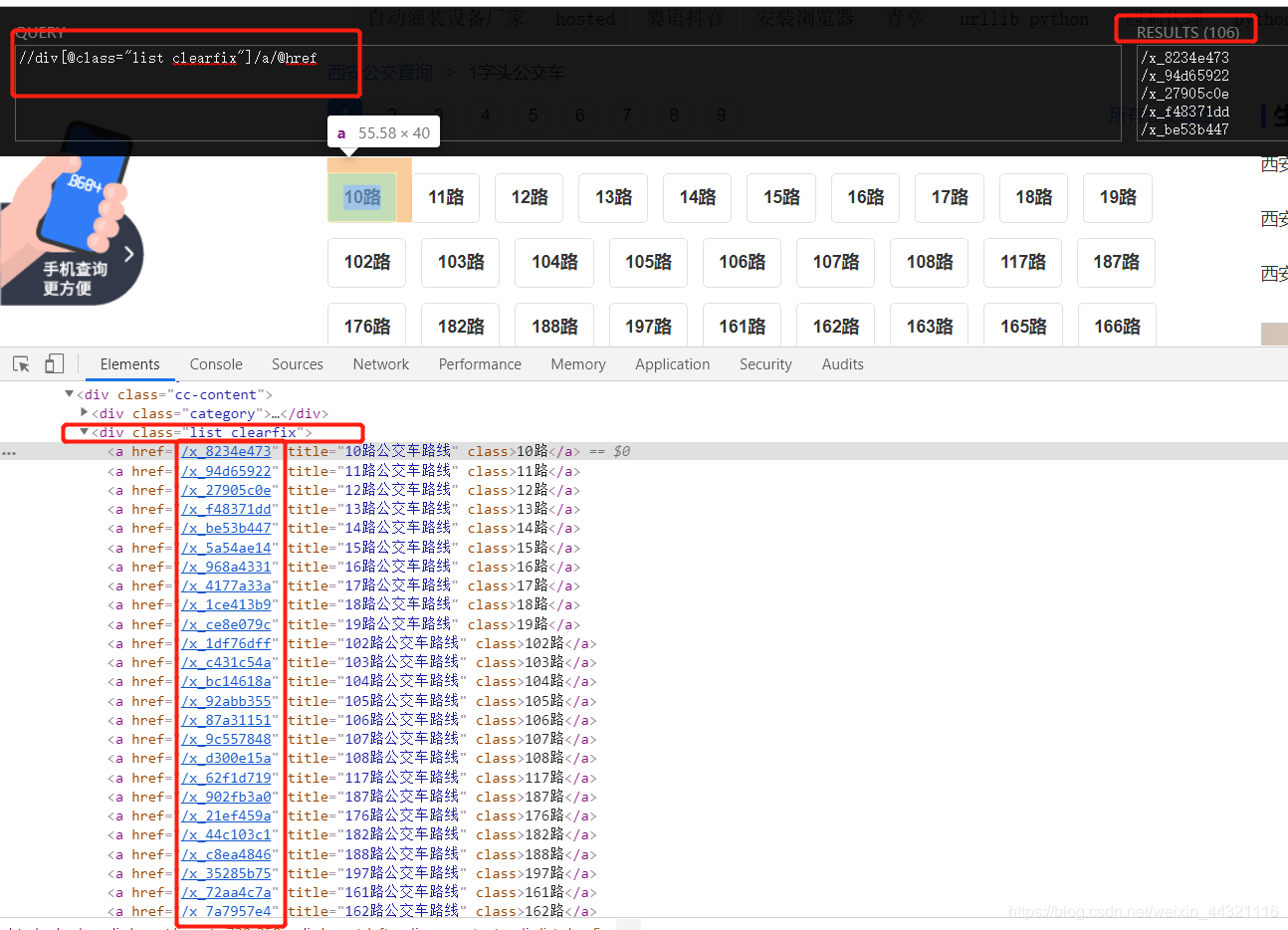
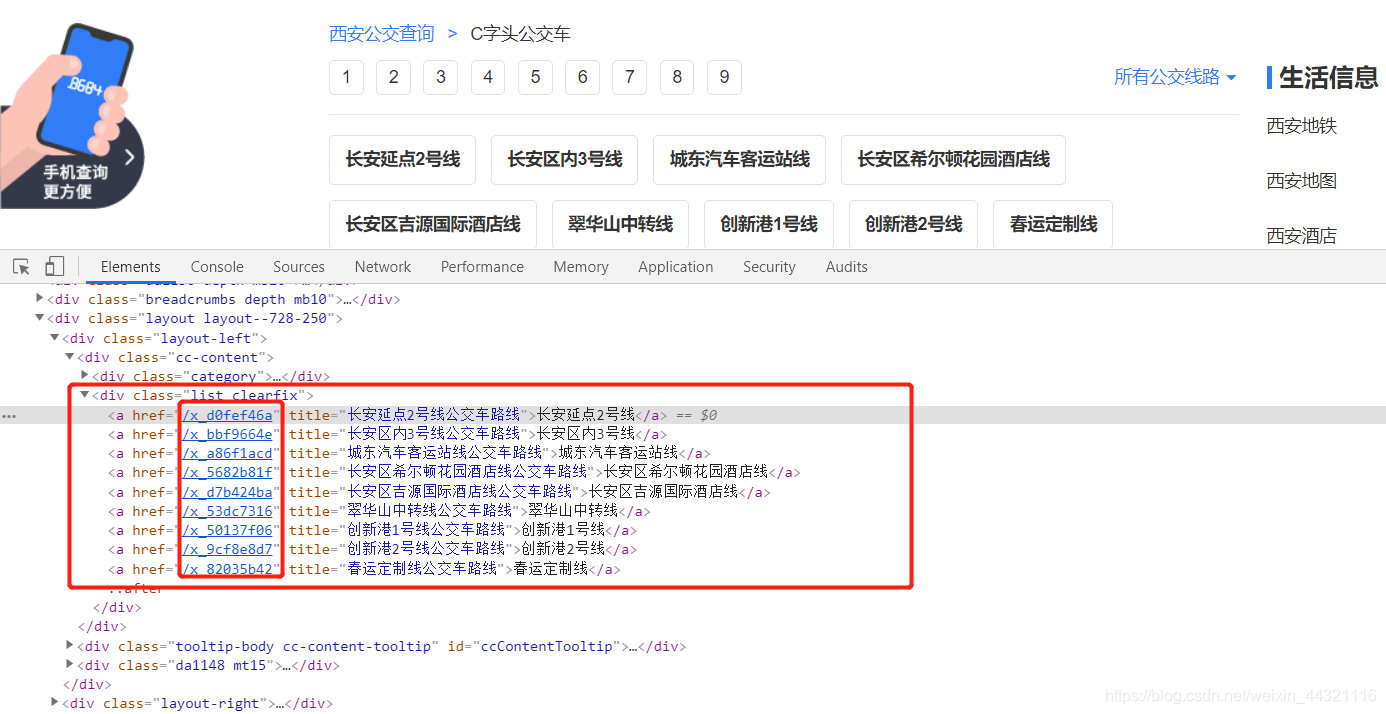
3.提取所需要爬取的内容:
3.1获取公交信息:
bus_number = tree.xpath('//div[@class="info"]/h1/text()')[0]
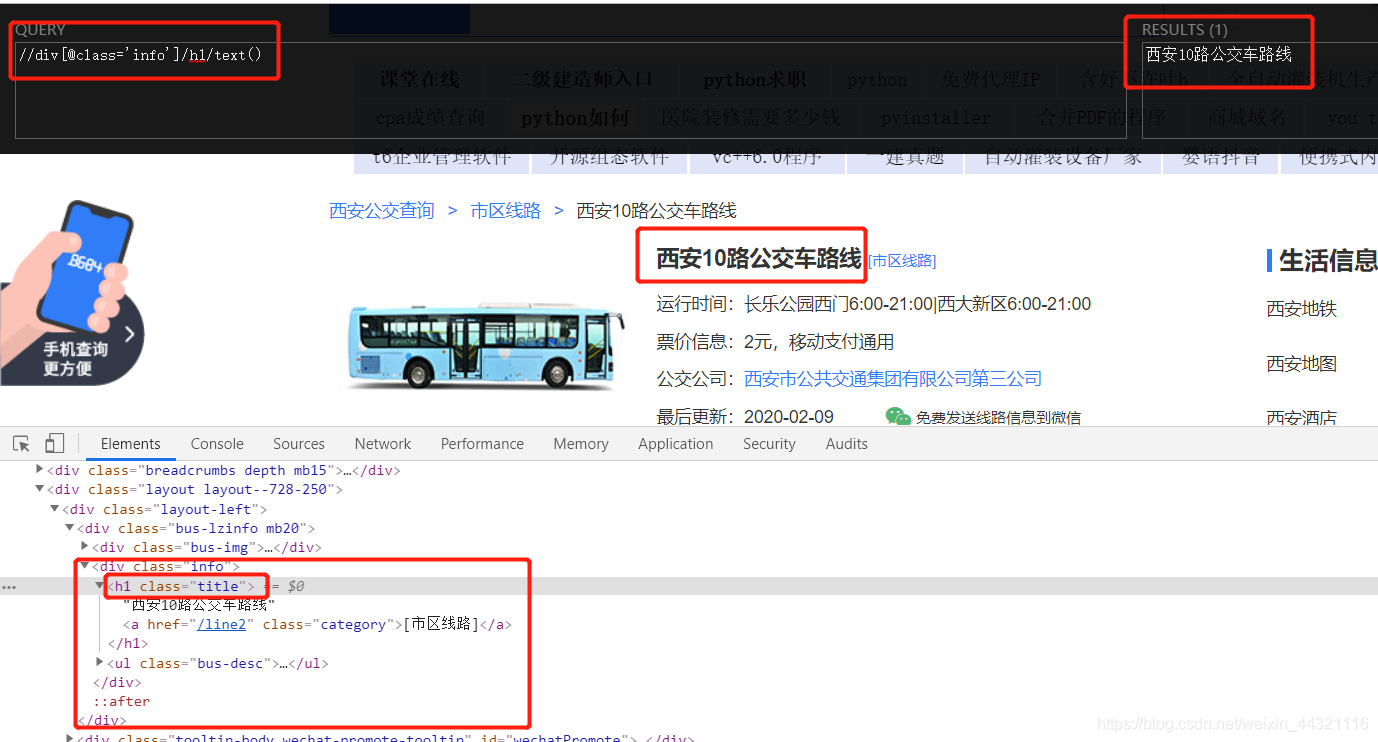
3.2 获取运行时间:
run_time = tree.xpath('//ul[@class="bus-desc"]/li[1]/text()')[0]
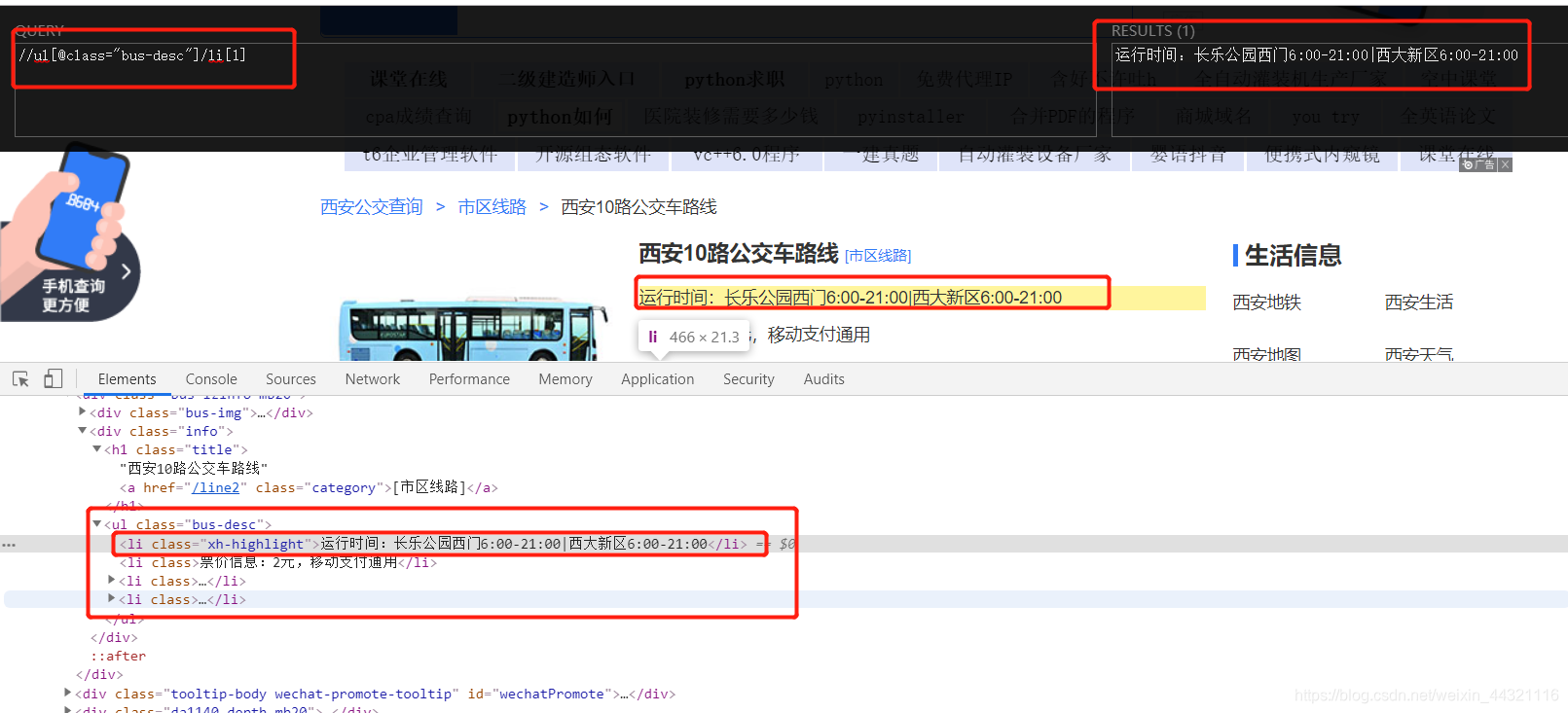
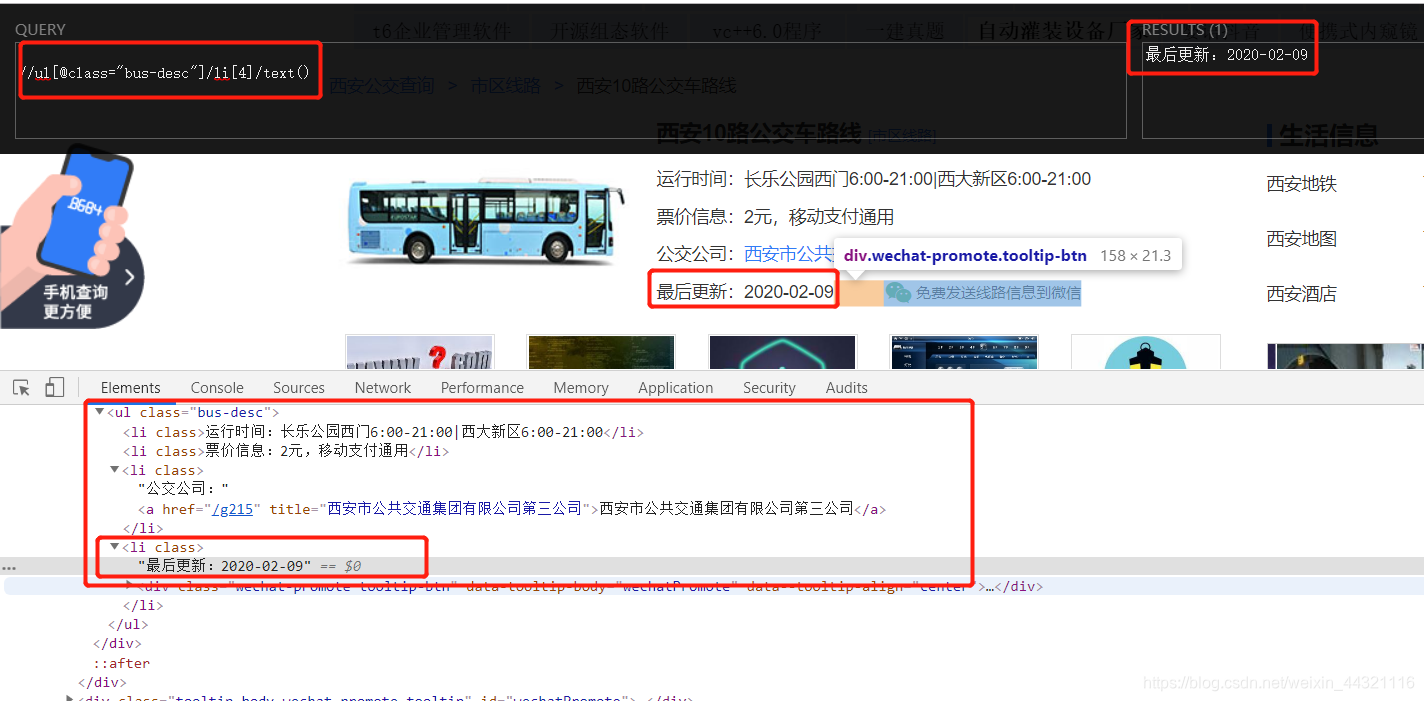
3.3获取更新时间:
laster_time = tree.xpath('//ul[@class="bus-desc"]/li[4]/text()')[0]
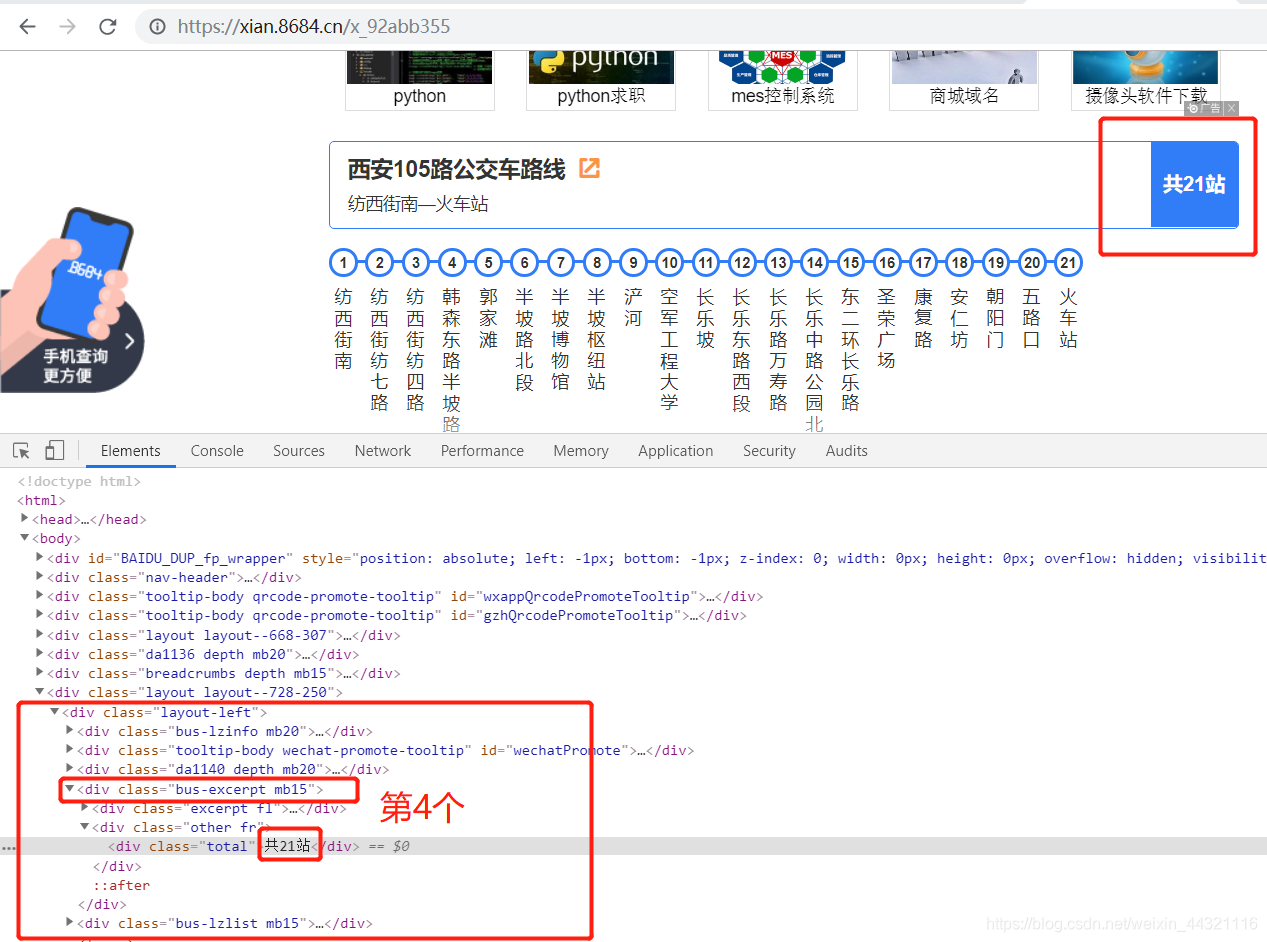
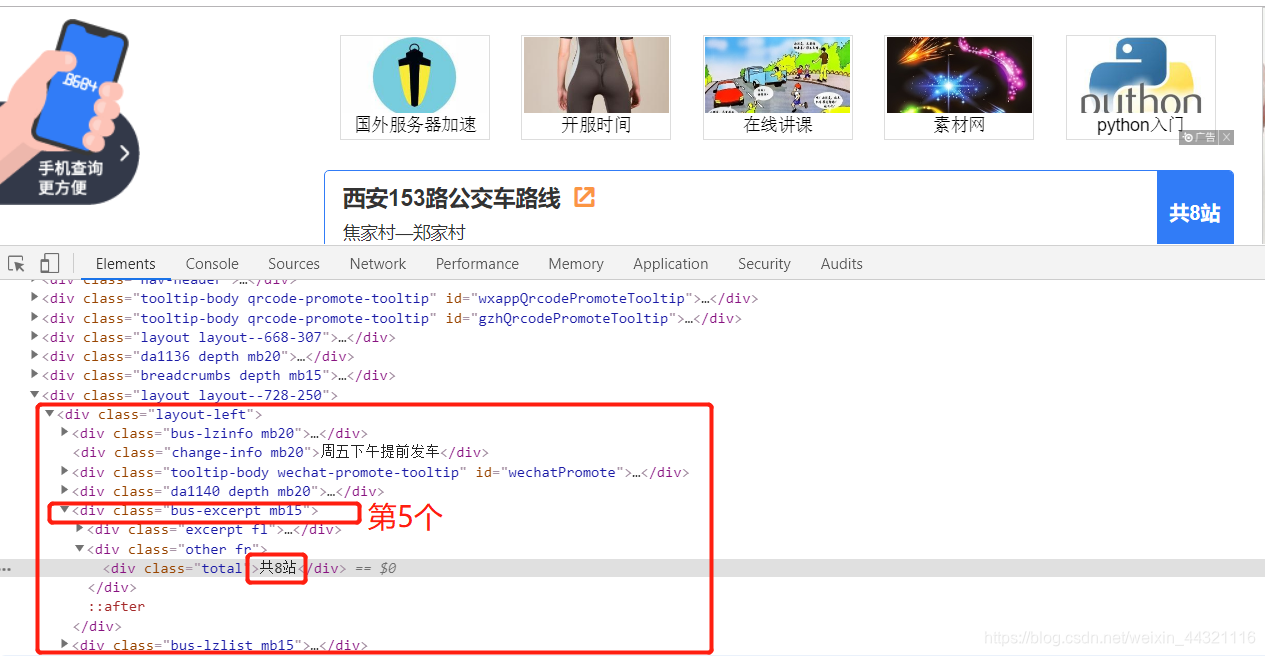
3.4获取上行总站数:
up_total = tree.xpath('//div[@class="layout-left"]/div[4]/div/div[@class="total"]/text()')[0]
或
up_total = tree.xpath('//div[@class="layout-left"]/div[5]/div/div[@class="total"]/text()')[0]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3853
3853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









