









随着Java在各类开发场景中的广泛应用,序列化(Serialization)和反序列化(Deserialization)成为了我们在开发过程中经常遇到的一个重要概念。无论是传输数据、存储对象状态,还是在网络通信、缓存、分布式系统等场景中,序列化与反序列化的理解与应用至关重要。
今天我们将详细介绍Java中的序列化与反序列化机制,帮助你在实际开发中掌握这些重要技术。
一、什么是序列化和反序列化?
- 序列化(Serialization):
序列化指的是将对象转换为字节流的过程。通过这个过程,对象可以被保存到磁盘或通过网络传输。简言之,序列化就是将一个复杂的Java对象转化成字节数据,方便保存或传输。 - 反序列化(Deserialization):
反序列化则是序列化的逆过程,即从字节流恢复成原来的对象。这种操作通常用于将之前序列化的对象从文件、数据库或者网络中恢复回来。
二、序列化与反序列化的使用场景
- 分布式系统:在RPC(远程过程调用)中,客户端和服务端需要传递对象,序列化与反序列化在其中扮演了重要角色。
- 网络传输:通过网络传输对象时,序列化可以将对象转为字节流,便于传输。
- 对象数据持久化:在Java中,可以通过序列化将对象保存到磁盘中,比如将一个Java对象保存到文件中,然后在需要时恢复该对象。
- 缓存机制:将对象序列化后存储在缓存中,并在需要时通过反序列化来使用。
三、如何在Java中实现序列化与反序列化
Java的序列化不仅仅局限于标准的Serializable接口,在实际开发中,还有多种方式可以实现对象的序列化和反序列化,具体选择取决于应用场景、性能需求和数据格式的需求。
1. 实现Serializable接口
- 特点:操作简单,只需实现
Serializable接口即可。- 使用场景:Java内部对象存储与传输,通常用于短期存储、缓存、网络传输等。
Java提供了内置的序列化与反序列化机制,使用起来非常简单。为了让一个对象可序列化,该对象的类需要实现java.io.Serializable接口。
这是Java默认的序列化方式,Serializable是一个标记接口,它没有任何方法。只要一个类实现了这个接口,它的对象就可以被序列化。该种方式的序列化是隐式的,会自动序列化所有非static和transient关键字修饰的成员变量。
创建一个Person对象,并实现Serializable序列化
import java.io.Serializable;
/**
* 测试序列化对象
*/
public class Person implements Serializable {
private static final long serialVersionUID = 1L; // 序列化版本号
private String name;
private int age;
private String addr;
public Person(String name, int age, String addr) {
this.name = name;
this.age = age;
this.addr = addr;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
}
下面将Person对象序列化到文件person.ser中,再从文件中读取内容,将其反序列化为Person对象
import java.io.*;
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 序列化
Person person = new Person("玄武后端技术栈", 18, "chengdu");
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"))) {
oos.writeObject(person);
}
// 反序列化
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser"))) {
Person deserializedPerson = (Person) ois.readObject();
System.out.println("name: " + deserializedPerson.getName());
System.out.println("age: " + deserializedPerson.getAge());
System.out.println("addr: " + deserializedPerson.getAddr());
}
}
}
name: 玄武后端技术栈
age: 18
addr: chengdu
我们看下person.ser文件内容

2. 实现Externalizable接口
Externalizable是Serializable的进阶版,提供了更精细的控制序列化过程。实现该接口需要覆盖两个方法:writeExternal()和readExternal(),从而手动指定哪些字段应该序列化,哪些不应该。
public interface Externalizable extends java.io.Serializable {
// 序列化逻辑
void writeExternal(ObjectOutput out) throws IOException;
// 反序列化逻辑
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
- 特点:手动管理序列化过程,效率更高。
- 使用场景:自定义序列化逻辑,如仅部分字段需要序列化,或需要更高效的序列化。适合对序列化过程有更严格要求的场景,比如节省空间或安全需求,比如对数据进行加解密等操作。
现在我们将Employee实现Externalizable接口,然后自定义序列化和反序列化逻辑,并且将密码进行加密处理
/**
* 实现Externalizable序列化,并自定义序列化和反序列化逻辑
*/
public class Employee implements Externalizable {
private String username;
private transient String password; // 密码不直接序列化
private static final long serialVersionUID = 1L;
private static SecretKey secretKey; // 用于加密和解密的密钥
/**
* 必须有无参构造函数
*/
public Employee() {
}
public Employee(String username, String password) {
this.username = username;
this.password = password;
}
public String getUsername() {
return username;
}
public String getPassword() {
return password;
}
public static void setSecretKey(SecretKey key) {
secretKey = key;
}
/**
* 自定义序列化逻辑
*
* @param out
* @throws IOException
*/
@Override
public void writeExternal(ObjectOutput out) throws IOException {
try {
out.writeObject(username);
// 对password进行加密,并写入
byte[] encryptedPassword = AESUtil.encrypt(password.getBytes(), secretKey);
out.writeObject(encryptedPassword);
System.out.println("密码已加密:" + encryptedPassword);
} catch (Exception e) {
throw new IOException("加密失败", e);
}
}
/**
* 自定义反序列化逻辑
*
* @param in
* @throws IOException
* @throws ClassNotFoundException
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
try {
username = (String) in.readObject();
// 读取加密的password并解密
byte[] encryptedPassword = (byte[]) in.readObject();
byte[] decryptedPassword = AESUtil.decrypt(encryptedPassword, secretKey);
password = new String(decryptedPassword);
System.out.println("解密后的密码:" + password);
} catch (Exception e) {
throw new IOException("解密失败", e);
}
}
@Override
public String toString() {
return "Employee{" +
"username='" + username + '\'' +
", password='" + password + '\'' +
'}';
}
}
测试
public class ExternalizableTest {
public static void main(String[] args) throws Exception {
// 创建Employee对象
Employee employee = new Employee("姓名123", "@1234Qingyu");
// 生成AES密钥并设置
SecretKey key = AESUtil.generateKey();
Employee.setSecretKey(key);
// 序列化对象到文件
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("employee.ser"))) {
oos.writeObject(employee);
}
// 反序列化并读取对象
Employee deserializedEmployee;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("employee.ser"))) {
deserializedEmployee = (Employee) ois.readObject();
}
System.out.println("Username: " + deserializedEmployee.getUsername());
System.out.println("Password: " + deserializedEmployee.getPassword());
}
}
密码已加密:[B@b59d31
解密后的密码:@1234Qingyu
Username: 姓名123
Password: @1234Qingyu
序列化和反序列化过程中,需要确保加密和解密的密钥一致,密钥可以通过配置获取或者存储在数据库;
通过这种方式,可以确保序列化数据的安全性,防止敏感数据在传输或存储中被泄露
Tips
static字段不属于实例:Java 的序列化机制只会序列化实例字段,static字段是属于类的,并不会随着对象的序列化和反序列化进行传输。- 序列化时保存类的状态:序列化仅保存对象的状态,
static字段的状态是类的状态,不是对象的状态。因此,静态字段不会被序列化。
如何处理密钥传递问题?
- 手动设置密钥:在序列化和反序列化之前,通过某种方式手动设置
secretKey,从外部提供密钥。 - 不使用
static关键字:如果密钥是每个实例唯一的(例如不同对象使用不同密钥),可以将secretKey设为非静态成员,这样密钥将随着对象一起被序列化和反序列化。然而,这样可能增加密钥的暴露风险,不安全。 - 使用安全密钥存储机制:可以将密钥存储在更安全的地方,如硬件安全模块(HSM)、密钥管理系统(如 AWS KMS)或加密的配置文件中。密钥可以在序列化或反序列化前从这些存储中动态获取。
3. 使用JSON序列化库
JSON是一种轻量级的数据交换格式,常用于前后端交互。Java中有多种JSON序列化库,最常用的是Jackson和Gson。
- 特点:JSON格式的数据可读性非常强,便于调试和传输。
- 适用场景:前后端交互、RESTful API的数据传输。适合跨语言的数据传输、HTTP接口传输等。
这里以Jackson举例说明
引入依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.9</version>
</dependency>
public class Book {
private String name;
private double price;
public Book() {
}
public Book(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
测试
/**
* 使用JSON序列化测试
*/
public class JsonSerializableTest {
public static void main(String[] args) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
// 序列化
Book book = new Book("Java并发编程", 121.99);
String jsonString = objectMapper.writeValueAsString(book);
System.out.println("序列化后的JSON:" + jsonString);
// 反序列化
Book deserializedBook = objectMapper.readValue(jsonString, Book.class);
System.out.println("反序列化后的对象:" + deserializedBook);
}
}
序列化后的JSON:{“name”:“Java并发编程”,“price”:121.99}
反序列化后的对象:Book{name=‘Java并发编程’, price=121.99}
4. 使用XML序列化库
XML是一种可扩展标记语言,常用于需要描述复杂数据结构的场景。Java中常用的XML序列化工具包括JAXB和XStream。
- 特点:XML格式的可扩展性好,适合复杂数据结构。
- 适用场景:配置文件、Web服务(如SOAP)、适合复杂结构的配置、跨平台数据交换等场景。
这里以JAXB(Java Architecture for XML Binding)为例说明
@XmlRootElement // 标记此类可以作为XML根元素
public class Customer {
private String name;
private int age;
// 必须要有无参构造函数,后面说明
public Customer() {
}
public Customer(String name, int age) {
this.name = name;
this.age = age;
}
@XmlElement // 用于标记这个字段应该被序列化
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@XmlElement // 用于标记这个字段应该被序列化
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Customer{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试
/**
* JAXB序列化测试
*/
public class XmlSerializableTest {
public static void main(String[] args) throws Exception {
Customer customer = new Customer("清宇Java", 18);
// 序列化到XML
// 初始化JAXB环境:以便JAXB能够管理指定类的序列化和反序列化。
JAXBContext context = JAXBContext.newInstance(Customer.class);
// 创建Marshaller对象:用于将Java对象序列化成XML格式。
Marshaller marshaller = context.createMarshaller();
// 设置输出格式
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
// 执行序列化,将结果输出在控制台
marshaller.marshal(customer, System.out);
// 反序列化从XML
// 创建Unmarshaller对象:用于将XML数据反序列化成Java对象。
Unmarshaller unmarshaller = context.createUnmarshaller();
// 执行反序列化
Customer deserializedCustomer = (Customer) unmarshaller.unmarshal(
new java.io.StringReader("<customer><name>清宇Java</name><age>18</age></customer>")
);
// 输出反序列化的对象
System.out.println("\n反序列化对象:" + deserializedCustomer);
}
}
输出结果
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<customer>
<age>18</age>
<name>清宇Java</name>
</customer>
反序列化对象:Customer{name='清宇Java', age=18}
这里有个小点说一下:
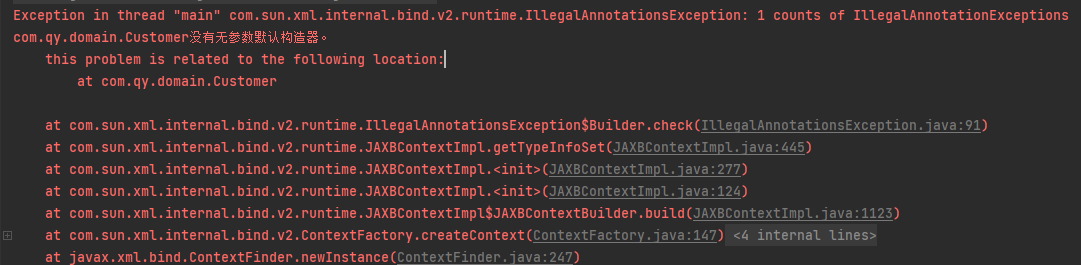
JAXB 中为什么需要无参数构造函数?
JAXB在序列化和反序列化过程中要求被序列化的类有一个无参数的构造函数,这是因为在反序列化(即从 XML 转换为 Java 对象)时,JAXB 需要通过反射机制实例化对象。如果没有无参数的构造函数,JAXB 将无法创建该对象的实例,从而导致反序列化失败。
- JAXB 如何创建对象: JAXB 在反序列化过程中,通过反射调用无参数构造函数来创建对象的实例。然后,它会通过 setter 方法或者直接访问类的字段,将 XML 中的数据填充到对象中。
- 避免使用参数化构造函数: JAXB 无法调用带参数的构造函数,因为它无法自动推断或提供合适的参数。因此,在实例化时,它依赖于无参数的构造函数。
如果没有就会抛出以下错误
5. 使用二进制序列化库
在高性能和大数据量传输场景下,二进制序列化库可以显著提升效率。常用的库有Kryo和Protocol Buffers。
- 特点:高效、紧凑,比JSON、XML等文本格式序列化更快,占用空间更小。
- 适用场景:需要高效传输、存储的场景,常见于分布式系统、大数据应用。
6. 其他序列化方式
除了以上常见的序列化方式外,还有其他的序列化方法,例如:
- Avro:Apache Avro是Hadoop生态系统中常用的序列化框架,适用于大数据场景,支持跨语言数据交换。
- Thrift:Apache Thrift是一个跨语言的RPC框架,它也支持高效的二进制序列化。
这些方式通常用于对性能要求较高的场景,如分布式系统、大数据处理、跨语言通信等。它们的优势主要体现在序列化和反序列化的性能和灵活性上。
各种序列化方式的特点总结
| 序列化方式 | 特点 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| Serializable | 原生Java序列化 | Java对象存储与传输 | 简单直接 | 性能较差,体积较大 |
| Externalizable | 手动控制序列化过程 | 自定义序列化的场景 | 更灵活 | 需要更多手动实现 |
| JSON序列化(如Jackson) | json格式,跨语言 | 前后端交互、API通信 | 可读性强,通用性好 | 体积较大,性能相对较低 |
| XML序列化(如JAXB) | XML格式,跨平台 | 配置文件、SOAP服务 | 可扩展性好 | 体积大,解析速度较慢 |
| 二进制序列化(如Protostuff) | 高效跨语言 | 大数据、分布式系统 | 性能优越,跨语言 | 配置复杂,需要引入库 |
四、序列化过程中的注意事项
- serialVersionUID:
serialVersionUID用于表示类的版本。它保证了在反序列化时,类的版本是兼容的。如果一个类发生了改变(比如增加或删除了字段),但是没有显式指定serialVersionUID,反序列化时可能会抛出InvalidClassException异常。因此,最好为每个可序列化的类显式声明一个serialVersionUID。
private static final long serialVersionUID = 1L;
- transient关键字:
序列化对象时,默认将里面所有的属性都进行序列化,除了static、transient修饰的成员。如果某个字段不希望被序列化,可以使用transient关键字修饰。被transient修饰的字段在序列化时将被忽略。
private transient String password;
- 对象的深拷贝:
序列化不仅可以用于网络传输和持久化,还可以用于对象的深拷贝。将对象序列化为字节流后再反序列化回来,就得到了一个与原对象相互独立的副本。
五、常见问题及解决方案
- 如何避免敏感数据序列化?
你可以使用transient来避免敏感信息(如密码、身份证号)被序列化。在序列化时,这些信息将不会出现在序列化的字节流中。 - 序列化过程中类发生了改变,怎么办?
这时候应该使用serialVersionUID来标识类的版本。如果你不提供serialVersionUID,Java会自动生成一个基于类结构的值,这意味着如果类发生变化,旧的序列化对象将无法反序列化。 - 序列化是否高效?
Java自带的序列化机制由于其实现的灵活性,有时性能不是最优的。在高性能场景下,你可能需要选择更加高效的序列化方案,如Protobuf、JSON、Kryo等。
最后加个餐
说说static 和 transient 在序列化中的区别
static关键字
定义:static 关键字用来修饰类的变量或方法,这意味着它们是属于类本身的,而不是某个对象的实例。
序列化过程:在序列化过程中,被static修饰的变量不会被序列化。因此,序列化一个对象时,不会包含其类变量的值,因为类变量的值在JVM中是全局的,与特定的序列化实例无关。
反序列化过程:在反序列化时,static 变量的值依然是类级别的当前状态,而不是从序列化的数据中获取。因为静态变量是共享的,因此它们与对象序列化或反序列化没有直接关联。
transient关键字
定义:用于修饰类的成员变量,指明该变量在序列化时不应被序列化。
序列化过程:当一个对象被序列化时,transient修饰的变量则会被忽略。
反序列化过程:在对象反序列化时,transient 变量会被初始化为它们的默认值。例如,数值类型会初始化为 0,对象类型会初始化为 null。序列化前设置的值将无法恢复。
希望这篇文章能帮助你在开发过程中更好地处理对象序列化相关问题。如果你有任何问题或建议,欢迎在评论区留言,我们可以一起讨论与学习!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









