









实验六:SVM基础练习;利用SVM构建垃圾邮件分类器
一、实验目的
使用支持向量机(SVM)构建垃圾邮件分类器。
二、实验环境
Window10,Octave
三、实验步骤/过程
1.支持向量机:
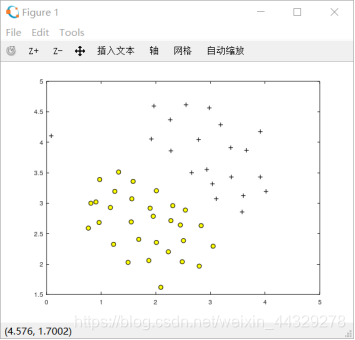
1.1样例数据集1:在这个数据集中,正例(用+表示)和负例(用 o 表示)的位置有一段间隔,即该正例和负例数据可由此间隔分开。
1.2 高斯核支持向量机:
1.2.1高斯核:在 gaussianKernel.m 中添加代码以计算两个示例之间的高斯核:
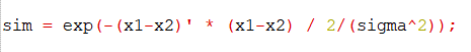
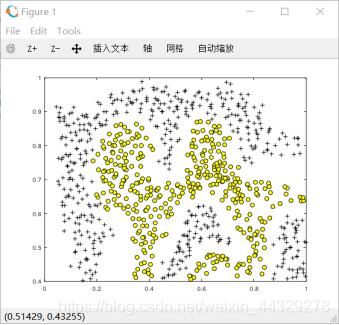
1.2.2 样例数据集2:该数据集无法通过线性决策边界来分隔正反两个例子,通过使用高斯核和支持向量机,能够学习到一个非线性决策边界。
1.2.3 样例数据集3:在dataset3Params.m中添加代码,使用交叉验证集 Xval,yval 来确定将要使用的最优参数 C 和σ:

2垃圾邮件分类:
2.1电子邮件预处理:将电子邮件预处理和标准化。
2.1.1词汇表:在processEmail.m中添加代码,将预处理电子邮件中的每个单词映射到单词索引列表中:

2.2从电子邮件中提取特征:在emailFeatures.m中添加代码为电子邮件生成特征向量:

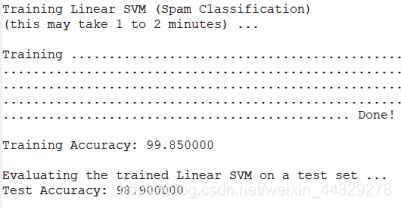
2.3 训练 SVM 进行垃圾邮件分类:加载预处理后的训练数据集来训练SVM分类器。
2.4 垃圾邮件的主要预测符:在分类器中找到具有最大正值的参数,并显示出相应的单词。
四、实验结果
1.1样例数据集1:
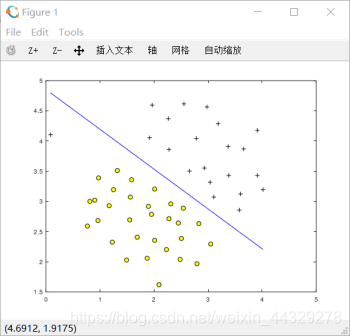
1.2.1高斯核:

1.2.2 样例数据集2:
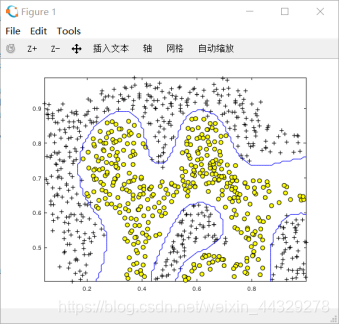
1.2.3 样例数据集3:
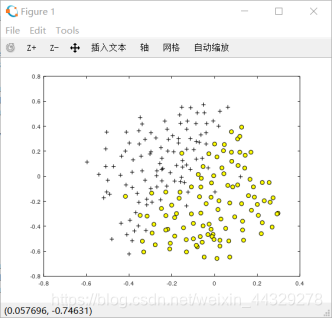
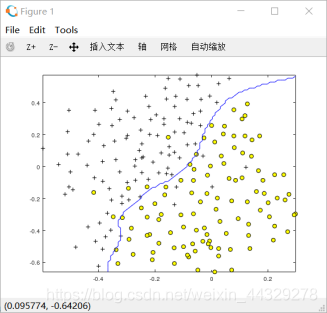
2.1电子邮件预处理:

2.1.1词汇表:

2.2从电子邮件中提取特征:

2.3 训练 SVM 进行垃圾邮件分类:
2.4 垃圾邮件的主要预测符:















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









