







重要提示:本文章仅作为技术分享与学习交流,严禁用于其他任何用途,如有任何问题请及时与我联系,谢谢!
一、数据标注
-
利用labelimg标注数据集生成yolo格式执行
pip install labelimg即可安装 -
准备好需要标注的数据,创建一个总文件夹,再创建一个名为images的子文件夹存放需要标注图片;创建一个名为labels的子文件夹存放标注的标签文件;创建一个名为classes.txt的txt子文件存放标注的类别名称。然后在classes.txt文件里面输入定义的类别。最终目录结构如下

-
进入总文件夹执行命令
labelimg images classes.txt labels打开如下界面。命令的意思是打开labelimg工具、读取images待标注图片的文件夹、初始化classes.txt里面定义的类、保存标注结果到labels文件夹。
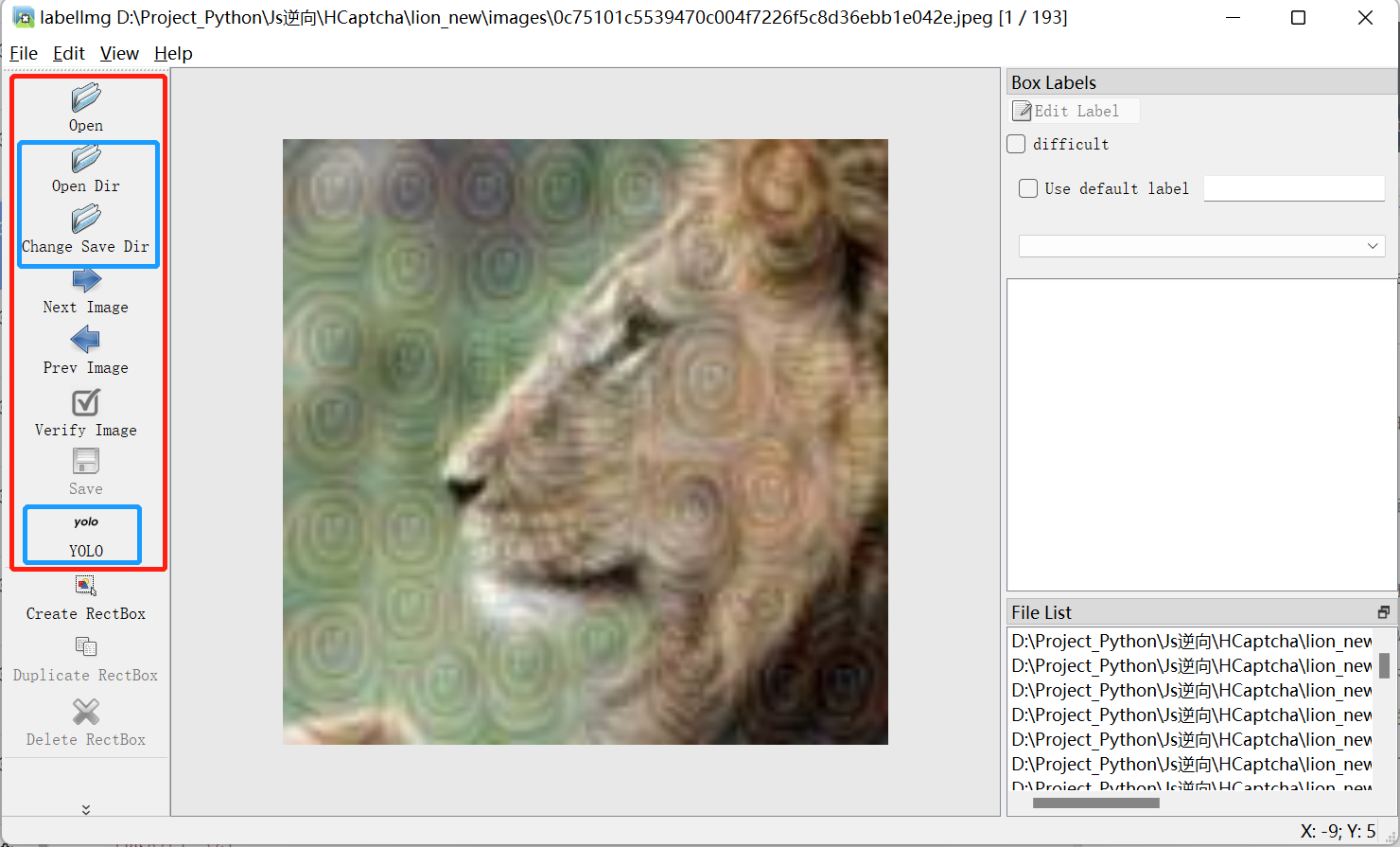
Open Dir:待标注图片的路径;Change Save Dir:保存标注后数据的路径;YOLO:标注后数据保存txt格式;VOC:标注后数据保存xml格式;
-
常用快捷键
A:切换到上一张图片D:切换到下一张图片W:调出标注十字架Del:删除标注框
-
点击
View进行功能设置Auto Save mode:切换下一张图片自动保存标签Display Labels:显示标注框、标签Advanced Mode:标注十字架一直悬浮在窗口
-
所有图片标注结束后,执行如下代码创建
train、valid文件夹,然后将已标注好的图片和标签一部分放入train文件夹中,一部分放入valid文件夹中。(valid放入少量即可,或者train与valid不区分,两个文件夹数据全部相同)
"""
@Author : Man
@Time : 2022/9/22 18:47
@Project : make_yaml
"""
import os
def make_data_dir_yaml(yaml_name, class_names):
# 生成存放数据集的图片和标签文件夹
for dirs in ['train/images', 'train/labels', 'valid/images', 'valid/labels']:
if not os.path.exists(dirs):
os.makedirs(dirs)
# 生成数据集配置.yaml
with open(yaml_name, "w", encoding='utf-8') as f:
f.write(f"train: {save_dir}/train/images\n")
f.write(f"val: {save_dir}/valid/images\n")
f.write("\n")
f.write(f"nc: {len(class_names)}\n")
f.write(f"names: {class_names}\n")
if __name__ == '__main__':
save_dir = 'D:/Project_Python/Learning/HCaptcha'
with open('classes.txt', 'r', encoding='utf-8') as f:
class_list = f.readlines()
class_list = [_.strip() for _ in class_list]
print(class_list)
make_data_dir_yaml('verify_HCaptcha.yaml', class_list)
- 最终文件结构与内容

二、数据训练
- 打开yolov5文件夹中
train.py,修改相关代码- 指定模型(没有此模型会自动下载,下载失败打开游览器根据提示网址自行下载放入yolov5文件夹下)

- 打开
models文件夹,复制一份指定模型对应的yaml文件只需修改nc的值也就是要训练类的数量即可

- 指定上方步骤复制的模型配置文件

- 指定数据集配置文件

- 指定训练总轮次(根据自己情况定)

- 指定批次大小(根据自己情况定)

- 指定训练的图片大小(根据自己情况定)

- 指定模型(没有此模型会自动下载,下载失败打开游览器根据提示网址自行下载放入yolov5文件夹下)
- 修改结束,直接运行
train.py开始训练,结果保存在runs\train\exp文件夹下

三、检测模型
- 打开yolov5文件夹中
detect.py,修改相关代码- 指定要检测的模型所在路径

- 指定要检测的单张图片/文件夹路径

- 指定图片大小

- 指定要检测的模型所在路径
- 修改结束,直接运行
detect.py开始检测,结果保存在runs\detect\exp文件夹下

四、调用模型识别HCaptcha验证

五、最后
- 有什么疑问欢迎留言!
- 公众号乱炖Set,欢迎前来关注!














 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









