








O衡量量级上的差距,当n突破一个点时,时间复杂度低的算法一定比时间复杂度高的算法要快,n越大优势越明显

O表示算法执行的最低上界,算法有几部分(n规模一致),随着数据规模增大,以量级最高的时间复杂度作为主导;规模不一致时要分开考虑


时间复杂度计算实例:考虑最长的字符串长度,因为O是一个上界,假设数组中的字符串长度都更最长的字符串长度是一样的,涵盖了最坏的情况,排序算法O(nlogn)中的nlogn表示比较的次数,对整型数组进行排序只需进行nlogn次比较,两个整型数据的比较是O(1)级别的,两个字符串的比较要耗费O(s),即需要比较nlog次,每次比较需要O(s)的时间消耗

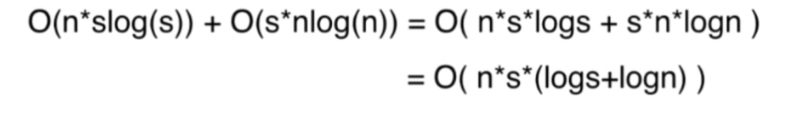
关注平均情况(平均情况下的最低上界)

算法面试时,根据数据规模确定所需的时间复杂度来选择算法:以加法操作为例

空间复杂度:开了多大的辅助空间,仅使用一些临时变量来存储一些临时值,空间复杂度为O(1)

递归调用有空间代价,递归调用深度为n,系统栈中需要装载n个状态,整个递归占据的空间复杂度是O(n)级别
O(n)用例:存在一个循环,这个循环的次数与n相关,即执行的基本操作为cn次,c可以>1=1<1
O(n2)用例:存在双重循环,每层循环都和n正相关

O(logn)用例:n经过log2n次 除以2的操作后等于1,分割了log2n次,在每个范围内的查找操作时间复杂度为O(1)



外层循环logn次,内层循环n次,时间复杂度为O(nlogn)

x从2到根号n变化

O(logn)随着n的规模增大,时间的效率差近乎没有,时间消耗变化非常小

O(nlogn)与O(n)差距不大

在一次递归中最多再进行一次递归调用,计算出递归调用的最大深度为logn,时间复杂度为O(logn):前提是在当前函数中处理问题是O(1)的,递归调用深度是O(logn)的,总体时间复杂度是O(logn)的

递归中进行一次递归调用时,递归调用的深度就是递归调用的次数



在递归中进行多次递归调用时,递归的深度和递归调用的次数是两个概念

指数级算法

树的深度是n,每个节点处理的数据规模是一样的
在排序搜索中,递归树的深度是logn,每层每个节点处理数据规模是逐渐缩小,但每层处理的数据量都是n,每个节点是O(n)级别的算法,总体来说在每一层上处理数据是O(n)级别。得出O(nlogn)

















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









