







1.描述统计
1.数字特征(描述统计)
- 集中趋势
- 众数
- 中位数
- 四分位数
- 平均数:样本平均数( x ˉ \bar{x} xˉ)与总体平均数( μ \mu μ)
- 离中趋势(离散趋势)
- 异众比率:非众数组的频数占总频数的比例,用于衡量众数的代表性
- 四分位差:上四分位数与下四分位数之差,用于衡量中位数的代表性
- 方差和标准差:总体方差
σ
2
\sigma^2
σ2(总体标准差
σ
\sigma
σ)或样本方差
s
2
s^2
s2(样本标准差
s
s
s)(注意样本方差计算时除以n-1)
- 标准化值: z i = x i − x ˉ s z_i = \frac{x_i - \bar{x}}{s} zi=sxi−xˉ
- 经验法则:对称分布时3 σ \sigma σ 原则
- 切比雪夫不等式
- 离散系数(变异系数): 标准差 算数平均数 \frac{\text{标准差}}{算数平均数} 算数平均数标准差
2.推断统计
推断统计学:通过从总体中抽取样本构造适当的统计量,由样本性质推断关于总体的性质。统计量是从样本中得出的一些代表性的数字(依赖于总体分布的未知参数不属于统计量,比如期望和方差),是推断统计的基础。
2.1抽样分布
抽样分布是指统计量的分布,从已知的总体中以一定的样本容量进行随机抽样,由样本的统计数所对应的概率分布称为抽样分布。
- 卡方分布:随机变量
X
1
,
X
2
,
⋯
,
X
n
i
i
d
X_1,X_2,\cdots,X_n iid
X1,X2,⋯,Xniid,
X
i
∼
N
(
0
,
1
)
X_i \sim N(0,1)
Xi∼N(0,1),则
Z
=
∑
i
=
1
n
X
i
2
∼
χ
2
(
n
)
Z= \sum\limits_{i=1}^n X_i^2 \sim \chi^2(n)
Z=i=1∑nXi2∼χ2(n)
- 应用:
- 参数估计:由样本方差推断总体方差:总体均值 μ \mu μ未知,对 σ 2 \sigma^2 σ2区间估计, T = ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) T = \frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1) T=σ2(n−1)S2∼χ2(n−1)
- χ 2 \chi^2 χ2拟合检验法:用来检验总体是否具有某一个指定的分布或属于某一个分布族(因为有时不能知道总体服从什么类型的分布)
- 应用:
- t分布:随机变量
X
∼
N
(
0
,
1
)
,
Y
∼
χ
2
(
n
)
,
X与Y独立
X \sim N(0,1), Y \sim \chi^2(n), \text{X与Y独立}
X∼N(0,1),Y∼χ2(n),X与Y独立,则
Z
=
X
Y
n
∼
t
(
n
)
Z = \frac{X}{\sqrt{\frac{Y}{n}}} \sim t(n)
Z=nYX∼t(n)
- 应用:t检验
- 参数估计:小样本下,由样本平均数推断总体平均数,总体方差 σ 2 \sigma^2 σ2未知,对 μ \mu μ区间估计, T = X ˉ − μ S n ∼ t ( n − 1 ) T= \frac{\bar{X}-\mu}{\frac{S}{\sqrt{n}}} \sim t(n-1) T=nSXˉ−μ∼t(n−1)
- 两个正态总体均值差 μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2的置信区间(两正态总体方差未知)
- 回归系数的显著性检验
- 应用:t检验
- F分布:随机变量
X
∼
χ
2
(
m
)
,
Y
∼
χ
2
(
n
)
,
X
与
Y
独立
X\sim \chi^2(m),Y\sim \chi^2(n),X与Y独立
X∼χ2(m),Y∼χ2(n),X与Y独立,则
Z
=
X
/
m
Y
/
n
∼
F
(
m
,
n
)
Z = \frac{X/m}{Y/n} \sim F(m,n)
Z=Y/nX/m∼F(m,n)
- 应用:
- 方差齐性检验:两个正态总体方差比 σ 1 2 σ 2 2 \frac{\sigma_1^2}{\sigma_2^2} σ22σ12的置信区间(两正态总体均值未知)
- 线性回归方程整体的显著性检验:判断线性关系是否显著


- 应用:
2.2 参数估计
- 点估计:用样本统计量的某个取值直接作为总体参数的估计值
- 区间估计:根据一定的正确度与精确度(置信水平= 1 − α 1-\alpha 1−α)的要求,构造出适当的区间(置信区间),作为总体分布的未知参数或参数的函数的真值所在范围的估计。
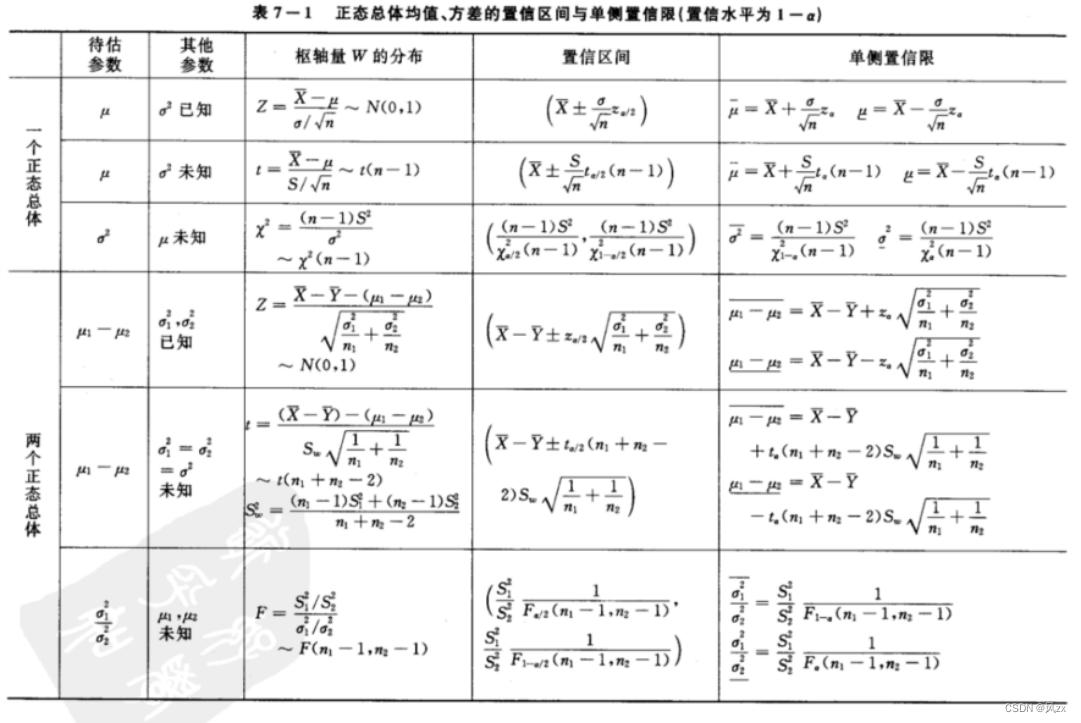
2.3 假设检验
在总体的分布函数完全未知或只知其形式、但不知其参数的情况下,为了推断总体的某些未知特征,提出某些关于总体的假设,根据样本对提出的假设做出接受还是拒绝的决策。
-
区间估计和假设检验之间的关系:
区间估计: ( θ ‾ , θ ˉ ) 是 θ 的一个置信水平为 1 − α 的置信区间, Θ 是 θ 取值范围, ∀ θ ∈ Θ , P ( θ ‾ < θ < θ ˉ ) ≥ 1 − α (\underline{\theta},\bar{\theta})是\theta的一个置信水平为1-\alpha的置信区间,\Theta是\theta取值范围,\forall \theta \in \Theta,P(\underline{\theta}<\theta<\bar{\theta}) \ge 1-\alpha (θ,θˉ)是θ的一个置信水平为1−α的置信区间,Θ是θ取值范围,∀θ∈Θ,P(θ<θ<θˉ)≥1−α
双边检验:显著性水平为 α \alpha α, H 0 : θ = θ 0 , H 1 : θ ≠ θ 0 H_0:\theta=\theta_0, H_1:\theta \neq \theta_0 H0:θ=θ0,H1:θ=θ0,有 P ( ( θ ≤ θ ‾ ) ∪ ( θ ≥ θ ˉ ) ) = α P{((\theta \le \underline\theta) \cup (\theta \ge \bar{\theta}))}=\alpha P((θ≤θ)∪(θ≥θˉ))=α,即拒绝域为 ( θ ≤ θ ‾ ) ∪ ( θ ≥ θ ˉ ) (\theta \le \underline\theta) \cup (\theta \ge \bar{\theta}) (θ≤θ)∪(θ≥θˉ)
-
非参数检验:总体分布未知(因此不涉及总体分布的参数),检验能力较弱
- 卡方检验:分析列联表中行变量和列变量是否互相独立
3. 基本分析方法
-
相关分析:相关分析最全总结
- 相关系数(或皮尔逊相关系数):用于Numerical Data,比如x和y
- 相关系数的显著性检验(t检验)
- 卡方检验:用于Nominal Data,比如二乘二列联表分析是否吸烟和性别的关系
- 相关系数(或皮尔逊相关系数):用于Numerical Data,比如x和y
-
回归分析:先进行相关分析确定变量存在相关性,然后使用回归分析确定数据关系的具体形式
- 种类:一元回归,多元回归,线性回归,非线性回归
- 判定系数:衡量了回归直线对观测数据的拟合优度
R = S S R S S T = ∑ i = 1 n ( y i ^ − y ˉ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R=\frac{SSR}{SST}=\frac{\sum\limits_{i=1}^n (\hat{y_i} - \bar{y})^2}{\sum\limits_{i=1}^n (y_i - \bar{y})^2} R=SSTSSR=i=1∑n(yi−yˉ)2i=1∑n(yi^−yˉ)2 - 线性回归方程整体的显著性检验(F检验):判断线性关系是否显著
- 回归系数的显著性检验(t检验)
-
方差分析:分析类型自变量(定类数据)X和数值型因变量(定量数据)Y之间的关系,比如电脑品牌和销量的关系,通过检验各总体的均值是否相等来判断X和Y是否有显著影响
-
数学描述为: 检验 s 个总体 N ( μ 1 , σ 2 ) , ⋯ , N ( μ s , σ 2 ) 的均值是否相等,即检验假设 H 0 : μ 1 = μ 2 = ⋯ μ s , H 1 : μ 1 , μ 2 , ⋯ , μ s 不全相等,并做出未知参数 μ 1 , μ 2 , ⋯ , μ s , σ 2 的估计 检验s个总体N(\mu_1,\sigma^2),\cdots,N(\mu_s,\sigma^2)的均值是否相等,即检验假设H_0:\mu_1=\mu_2=\cdots\mu_s,H_1:\mu_1,\mu_2,\cdots,\mu_s不全相等,并做出未知参数\mu_1,\mu_2,\cdots,\mu_s,\sigma^2的估计 检验s个总体N(μ1,σ2),⋯,N(μs,σ2)的均值是否相等,即检验假设H0:μ1=μ2=⋯μs,H1:μ1,μ2,⋯,μs不全相等,并做出未知参数μ1,μ2,⋯,μs,σ2的估计
-
基本思想是采用方差对比随机误差和系统误差的方法检验均值是否相等
-
-
分类分析:机器学习分类、回归相关算法
-
聚类分析:机器学习聚类算法
-
时间序列分析
-
关联规则分析















 3306
3306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









