







 本文是统计学笔记的第三部分,主要讲解数据的预处理,包括数据审核、筛选、排序,以及数据可视化表示,如常用图表和Python绘图库的使用。讨论了数据清理的重要性,并介绍了Python数据挖掘的相关扩展库。此外,还探讨了茎叶图的特点和优缺点,以及如何合理使用图表来展示数据。
本文是统计学笔记的第三部分,主要讲解数据的预处理,包括数据审核、筛选、排序,以及数据可视化表示,如常用图表和Python绘图库的使用。讨论了数据清理的重要性,并介绍了Python数据挖掘的相关扩展库。此外,还探讨了茎叶图的特点和优缺点,以及如何合理使用图表来展示数据。
[统计学笔记三] 整理和显示数据
数据的预处理
数据的预处理是在对数据分类或分组之前所做的必要处理,内容包括:数据的审核、筛选、排序等。
数据审核:就是检查数据中是否存在错误。包括:完整性审核和正确性审核。
数据筛选:根据需要找出符合特定条件的某类数据。
数据排序:按一定的顺序将数据排列,以便于研究者通过浏览数据发现一些明显的特征或趋势,找到解决问题的线索。
大家都比较熟悉的Excel可以帮助实现上述功能。在工作中,Excel可能算得上是最常用的数据预处理工具了。
行业数据挖掘标准过程(CRISP-DM)—目前数据挖掘模型开发的标准过程。这个过程指出了数据挖掘过程的第一阶段为业务理解,或称为研究理解,其中企业和研究人员首先阐明项目目标,然后将这些目标转化为数据挖掘的问题定义,最后为完成这些目标制定初步策略。数据挖掘工作的展开,对于数据需要经过预处理,包括数据清理和数据变换两种形式。
为什么需要对数据进行清理呢?
因为各种来源收集的数据,可能存在如下的问题:
- 过时或冗余数据
- 缺失值
- 离群值
- 其它形式不适合数据挖掘模型的数据
- 与策略或常识不一致的数据
- 等等
所以需要对将要进行数据分析和数据挖掘的数据进行预处理。
数据可视化表示的常用图
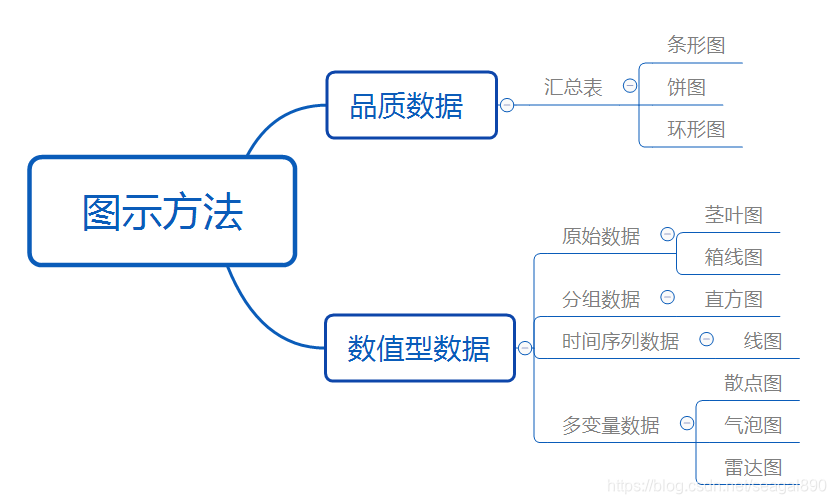
图例说明
可以使用Python,或者直接使用 工具Anaconda方便的制作各种统计图。
我喜欢的工具是:Anaconda。它已经自带了以下库:Numpy,Scipy,Maplotlib,Pandas和Scikit-Learn。
Anaconda 的下载地址:https://www.anaconda.com/distribution/
下面的图例就是通过Anaconda制作的,当然开发语言是使用Python。
Python数据挖掘相关扩展库
| 扩展库 | 简介 |
|---|---|
| Numpy | 提供数组支持,以及相应的高效的处理函数 |
| Scipy | 提供矩阵支持,以及矩阵相关的数值计算模块 |
| Matplotlib | 强大的数据可视化工具、作图库 |
| Pandas | 强大、灵活的数据分析和探索工具 |
| StatsModels | 统计建模和计量经济学,包括描述统计、统计模型估计和推断 |
| Scikit-Learn | 支持回归、分类、聚类等的强大的机器学习库 |
| Keras | 深度学习库,用于建立神经网络以及深度学习模型 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3674
3674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









