






Beautiful Soup第三方库的安装
pip install Beautifulsoup4
python中使用BeautifulSoup
import bs4
# 或者
from bs4 import BeautifulSoup
网页解析器语法
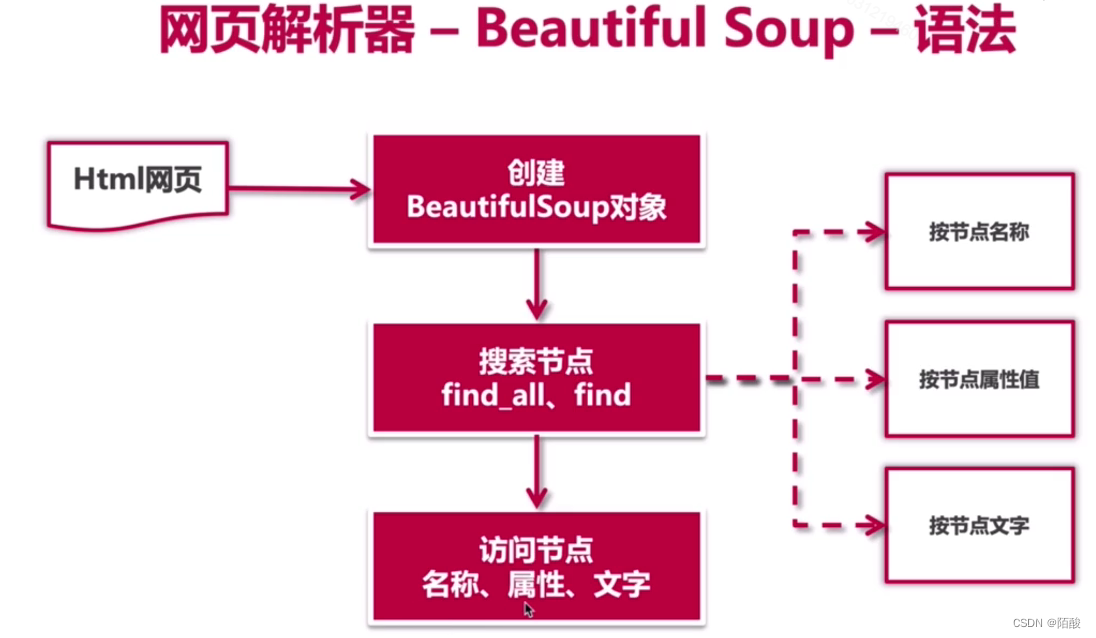
- 创建BeautifulSoup对象
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
soup = BeautifulSoup(
html_doc, # htmll文档字符串
'html.parser', # html解析器
from_encoding='utf8' # html文档的编码
)
- 搜索节点(find_all,find)
find_all(name,attrs,string)
# name:节点名称
# attrs:节点属性
# string:节点的文本
# 查找所有标签为a的节点
soup.find_all('a')
# 查找所有标签为a,链接符合/view/test123.html形式的节点
soup.find_all('a',href='/view/test123.html')
# 查找所有标签为div,class为abc,文字为spider的节点
soup.find_all('div',class_='abc',string="spider")
- 访问节点信息
# 得到节点: <a href="test123.html">Spider</a>
# 获取查找到的节点的标签名称
node.name
# 获取查找到的a节点的href属性
node['href']
#获取查找到的a节点的链接文件
node.get_text()
Beautiful Soup练习
- 创建一个需要提取的html文件,文件名为test.html
<html>
<head>
<meta http-equiv=Content-Type content="text/html;charset=utf-8">
<title>网页标题</title>
</head>
<body>
<h1>标题1</h1>
<h2>标题2</h2>
<h3>标题3</h3>
<h4>标题4</h4>
<div id="content" class="default">
<p>段落</p>
<a href="http://www.baidu.com">百度</a> <br/>
<a href="http://www.crazyant.net">python ice scream</a> <br/>
<a href="http://www.iqiyi.com">爱奇艺</a> <br/>
<img src="https://www.python.org/static/img/python-logo.png"/>
</div>
</body>
</html>
- 利用BeautifulSoup来提取html文件中div模块中的a标签数据
from bs4 import BeautifulSoup
# 打开htm文件
with open("test.html", mode="r") as f:
html_doc = f.read() # 读取html文件中的数据,读取后的数据类型为str
# 创建BeautifulSoup对象
# 三个常用的参数
# markup:字符串或类似文件的对象,表示要解析的标记。
# features:要使用的解析器的理想特性,可以使用("lxml","lxml-xml", "html.parser", or "html5lib")
# from_encoding:要解析的文档的编码格式
soup = BeautifulSoup(markup=html_doc, features="html.parser")
# 定位到我们需要提取的节点模块
# name:节点名称
# attrs:节点属性
# string:节点文本
div_node = soup.find(name="div", id="content")
print(div_node)
print("#" * 30)
# 查找div节点下所有的a标签,返回值是一个list
links = div_node.find_all("a")
for link in links:
# 节点.name:获取节点的名称
# 节点['属性']:获取节点的属性的值
# 节点.get_text():获取节点的文本
print(link.name, link['href'], link.get_text())
打印结果为:
<div class="default" id="content">
<p>段落</p>
<a href="http://www.baidu.com">百度</a> <br/>
<a href="http://www.crazyant.net">python ice scream</a> <br/>
<a href="http://www.iqiyi.com">爱奇艺</a> <br/>
<img src="https://www.python.org/static/img/python-logo.png"/>
</div>
##############################
a http://www.baidu.com 百度
a http://www.crazyant.net python ice scream
a http://www.iqiyi.com 爱奇艺














 3780
3780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









