







1.去除重复行
^(.*?)$\s+?^(?=.*^\1$)
操作方法如下,快捷键Ctrl+H,在弹出的界面输入表达式,并勾选匹配新行,如图所示:
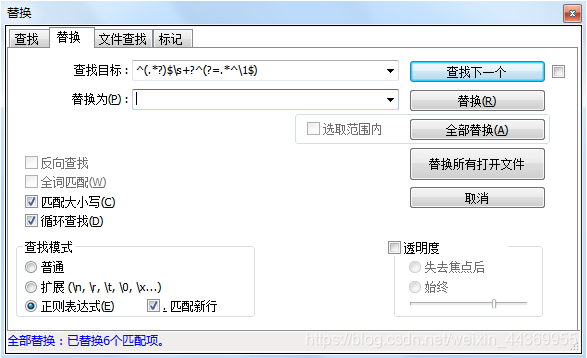
然后点击全部替换,重复行就删除了。
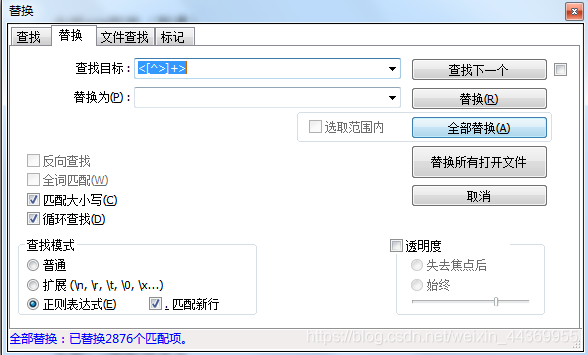
2.复制网页内容到notepad去除html标签,只留下文字
正则表达式<[^>]+>,在替换下选择模式中选择正则表达式,全部替换即可。
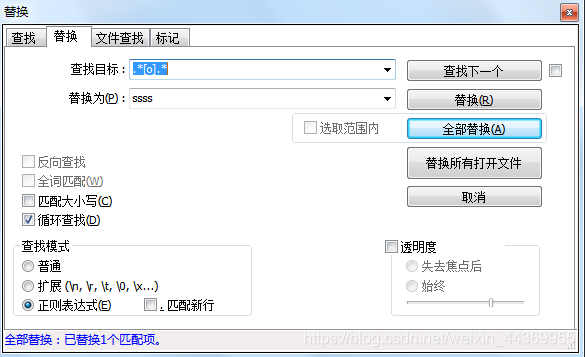
3.替换包含特定字符的行(替换中,不选择匹配新行)
.*[字符].*\r\n 或者 ^.*字符.*$
在替换中,不选择匹配新行
4.删除S 之后的所有字符用:s.*$
删除S 之前的所有字符用:^([^s]*)s
如果是其他字符就把s替换为其他字符


















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











