









 本文介绍了如何将Robot Framework脚本转换为CSV格式,并通过Python实现关键字自动化执行,包括open_browser函数和元素定位处理。作者展示了如何读取csv,解析参数,以及使用selenium库操作浏览器和处理不同元素定位方式。
本文介绍了如何将Robot Framework脚本转换为CSV格式,并通过Python实现关键字自动化执行,包括open_browser函数和元素定位处理。作者展示了如何读取csv,解析参数,以及使用selenium库操作浏览器和处理不同元素定位方式。
简介:本身使用过RobotFramework工具一段时间,而且本身RobotFramwork很多的关键字都是基于python实现的,于是自己也动手实践了一下。
1,把RF框架的脚本切换成csv格式,并且去掉空格,关键字与元素之间用,符号隔开,如下
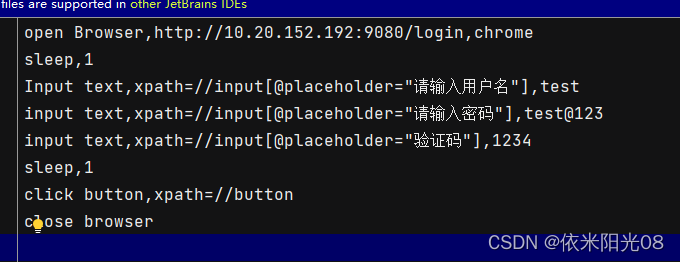
2,创建KDT_eval的py文件,先读取csv的内容
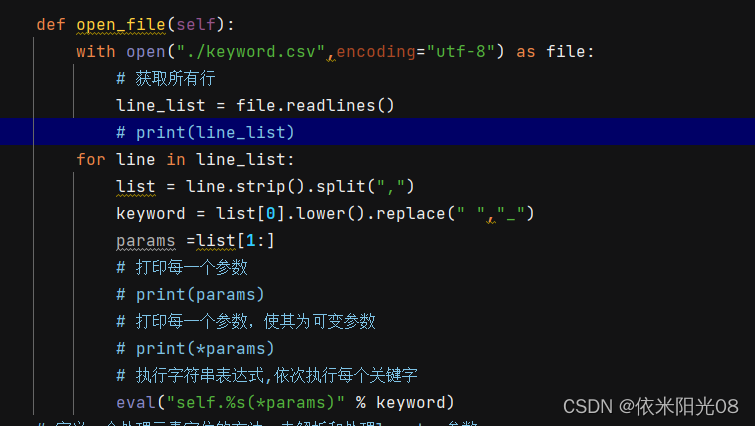
将读取的每行内容,分割出关键字与参数,并且用eval()函数执行字符串的表达式
3,实现关键字,定义不同的方法实现不同的关键字。
如实现open browser,代码如下
def open_browser(self,url,browser):
if browser == "chrome":
self.driver = webdriver.Chrome()
elif browser == "firefox":
self.driver = webdriver.Firefox()
else:
raise Exception("不支持的浏览器")
self.driver.get(url)```
其它的关键字,input text,需要传输元素参数,用split()来分割元素的定位方式和value值
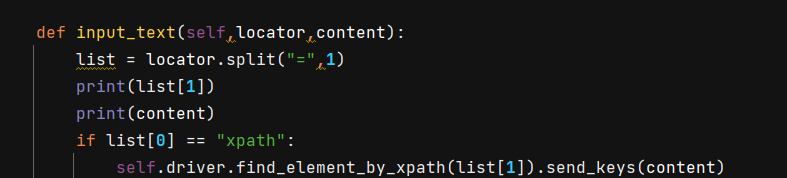
其中,xpath的定位方式中也会用到=符号,所以需要设置只分割一次。
整体代码如下,其中对于元素的处理方法又增加了一个find_element方法,可以整体处理不同方式的元素
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
class KDTDemo:
def __init__(self):
self.driver = None
def open_file(self):
with open("./keyword.csv",encoding="utf-8") as file:
# 获取所有行
line_list = file.readlines()
# print(line_list)
for line in line_list:
list = line.strip().split(",")
keyword = list[0].lower().replace(" ","_")
params =list[1:]
# 打印每一个参数
# print(params)
# 打印每一个参数,使其为可变参数
# print(*params)
# 执行字符串表达式,依次执行每个关键字
eval("self.%s(*params)" % keyword)
# 定义一个处理元素定位的方法,去解析和处理locator参数
def find_element(self,locator):
list = locator.split("=",1)
if list[0].lower()== "id":
element = self.driver.find_element_by_id(list[1])
elif list[0].lower()=="name":
element = self.driver.find_element_by_name(list[1])
elif list[0].lower()=="xpath":
element = self.driver.find_element_by_xpath(list[1])
return element
def open_browser(self,url,browser):
if browser == "chrome":
self.driver = webdriver.Chrome()
elif browser == "firefox":
self.driver = webdriver.Firefox()
else:
raise Exception("不支持的浏览器")
self.driver.get(url)
def sleep(self,timeout):
time.sleep(int(timeout))
def input_text(self,locator,content):
# list = locator.split("=",1)
# print(list[1])
print(content)
# if list[0] == "xpath":
# self.driver.find_element_by_xpath(list[1]).send_keys(content)
#提示find_element_by_xpath过时,建议使用以下方法
# self.driver.find_element(by=By.XPATH,value=list[1]).send_keys(content)
self.find_element(locator).send_keys(content)
def click_button(self,locator):
# list = locator.split("=",1)
# self.driver.find_element_by_xpath(list[1]).click()
#提示find_element_by_xpath过时,建议使用以下方法
# self.driver.find_element(by=By.XPATH,value=list[1]).click()
self.find_element(locator).click()
def close_browser(self):
self.driver.quit()
if __name__ == '__main__':
kdt = KDTDemo()
kdt.open_file()

















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









