







XXL-JOB是一个分布式任务调度平台,以下是其基本的使用方法
XXL-JOB是一个轻量级、高效且易于使用的分布式任务调度框架,它由大众点评的许雪里(XXL)开源,旨在解决分布式环境下定时任务的执行难题。以下是XXL-JOB的一些核心特性和应用场景的详细介绍:
1.基本介绍
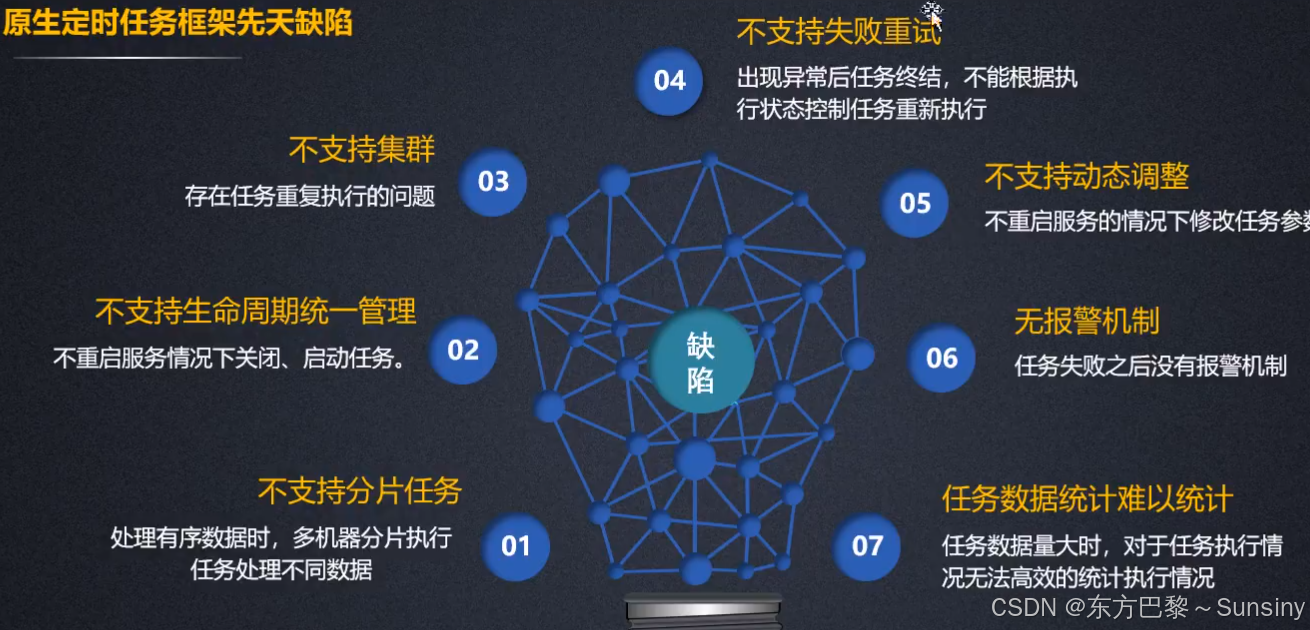
XXL-JOB起源于大众点评内部的分布式任务调度需求,自2016年起开始接入线上产品线,至今已迭代数十个版本,广泛应用于互联网、金融、教育、物流等多个行业。其核心设计目标是“开发迅速、学习简单、轻量级、易扩展”,并且提供开箱即用的体验。
功能特性
- 简单易用:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手。
- 动态管理:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效。
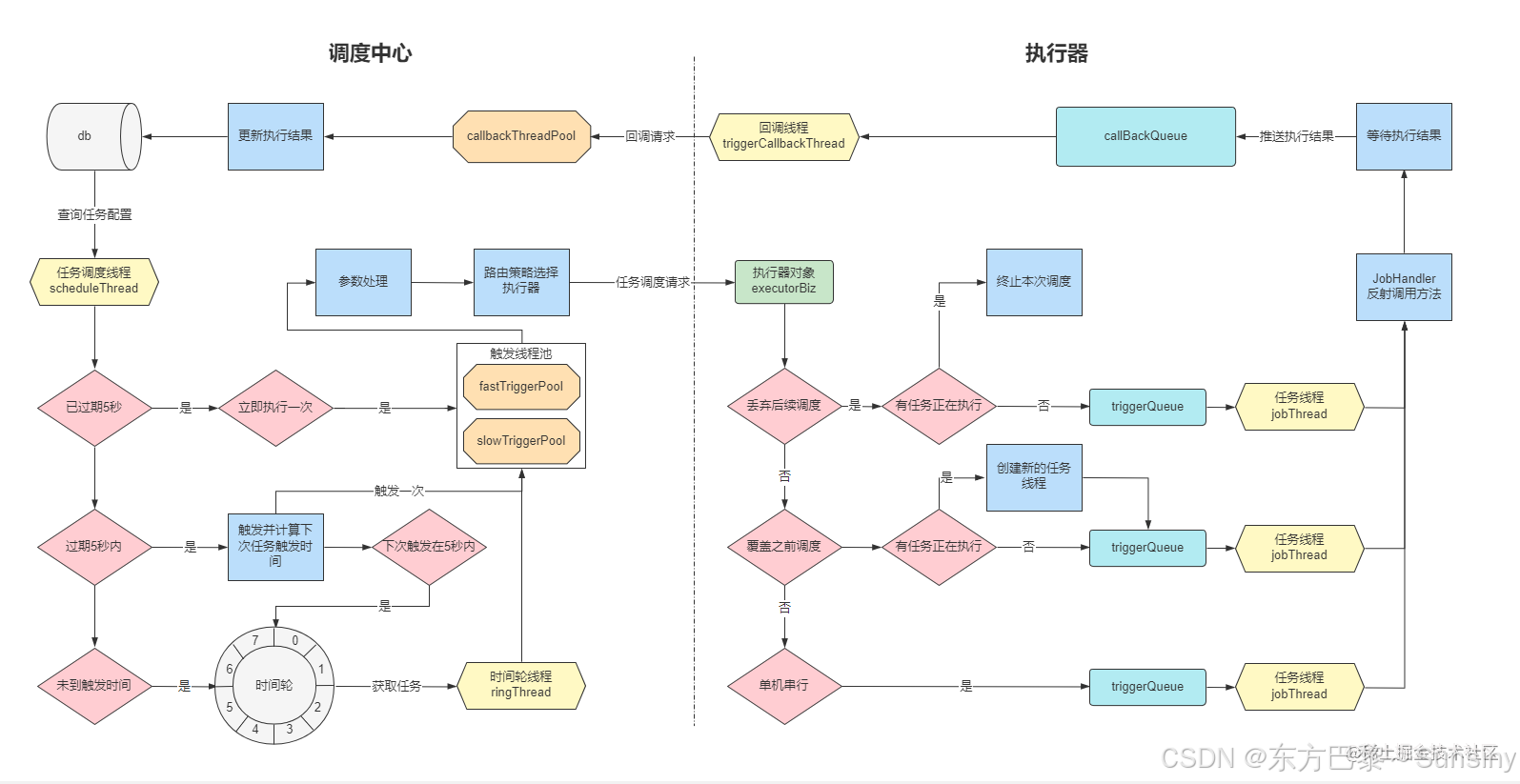
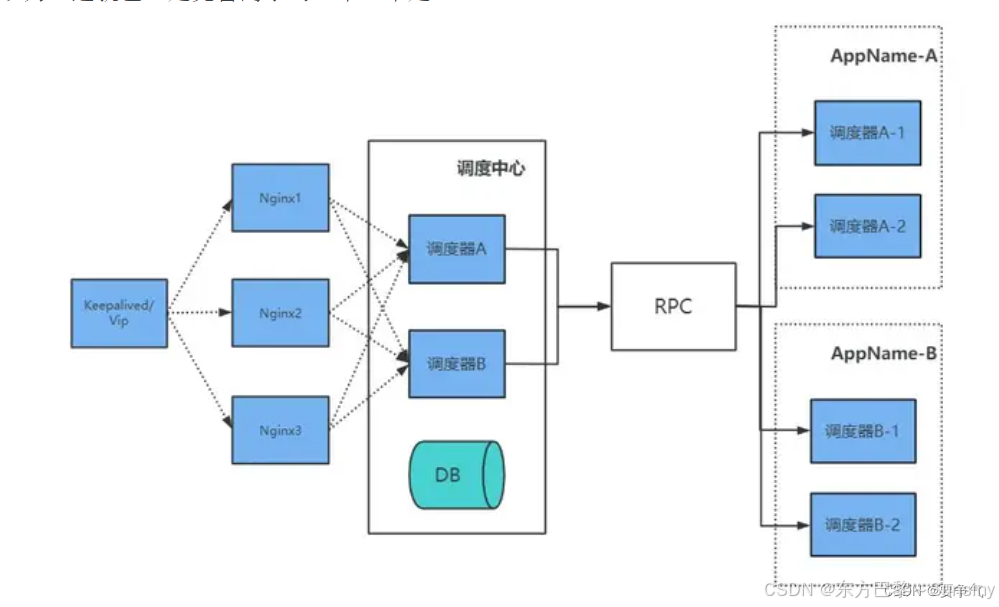
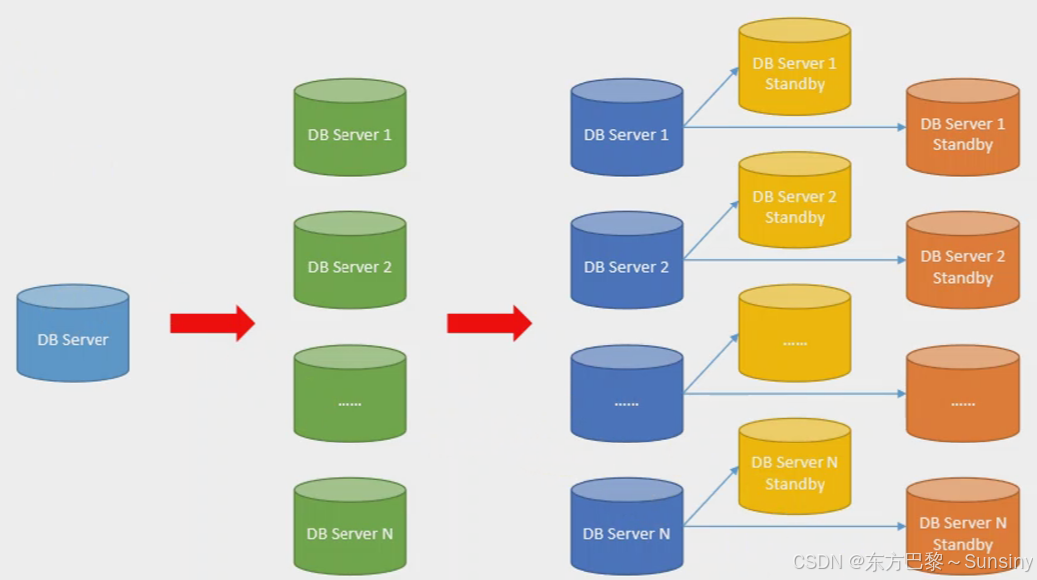
- 调度中心HA:调度采用中心式设计,支持集群部署,可保证调度中心的高可用性。
- 执行器HA:任务分布式执行,支持集群部署,可保证任务执行的高可用性。
- 注册中心:执行器会周期性自动注册任务,调度中心将自动发现注册的任务并触发执行。
- 弹性扩容缩容:一旦有新执行器机器上线或下线,下次调度时将会重新分配任务。
- 路由策略:执行器集群部署时提供丰富的路由策略,包括第一个、最后一个、轮询、随机等。
- 故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括单机串行、丢弃后续调度、覆盖之前调度。
- 任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务。
- 任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试。
- 任务失败告警:默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式。
- 分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务。
- 动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理。
架构与组件
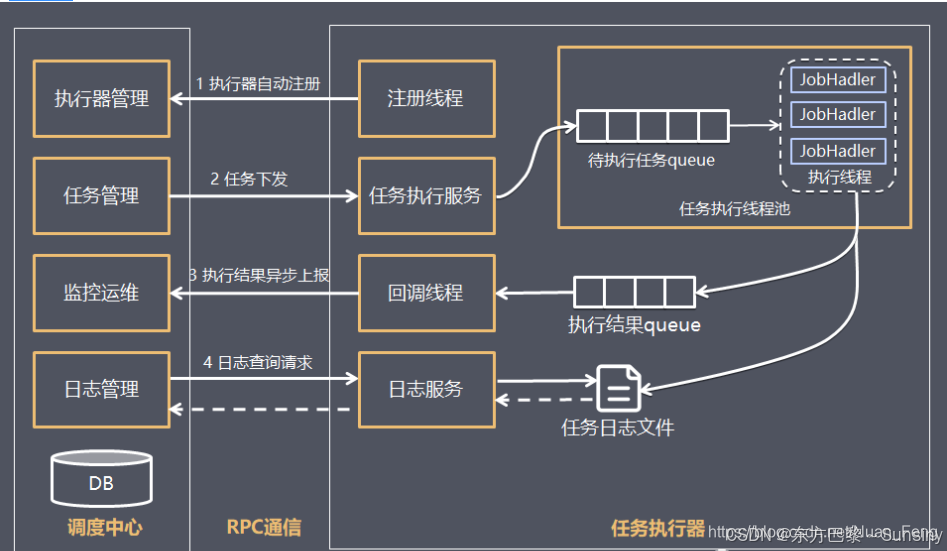
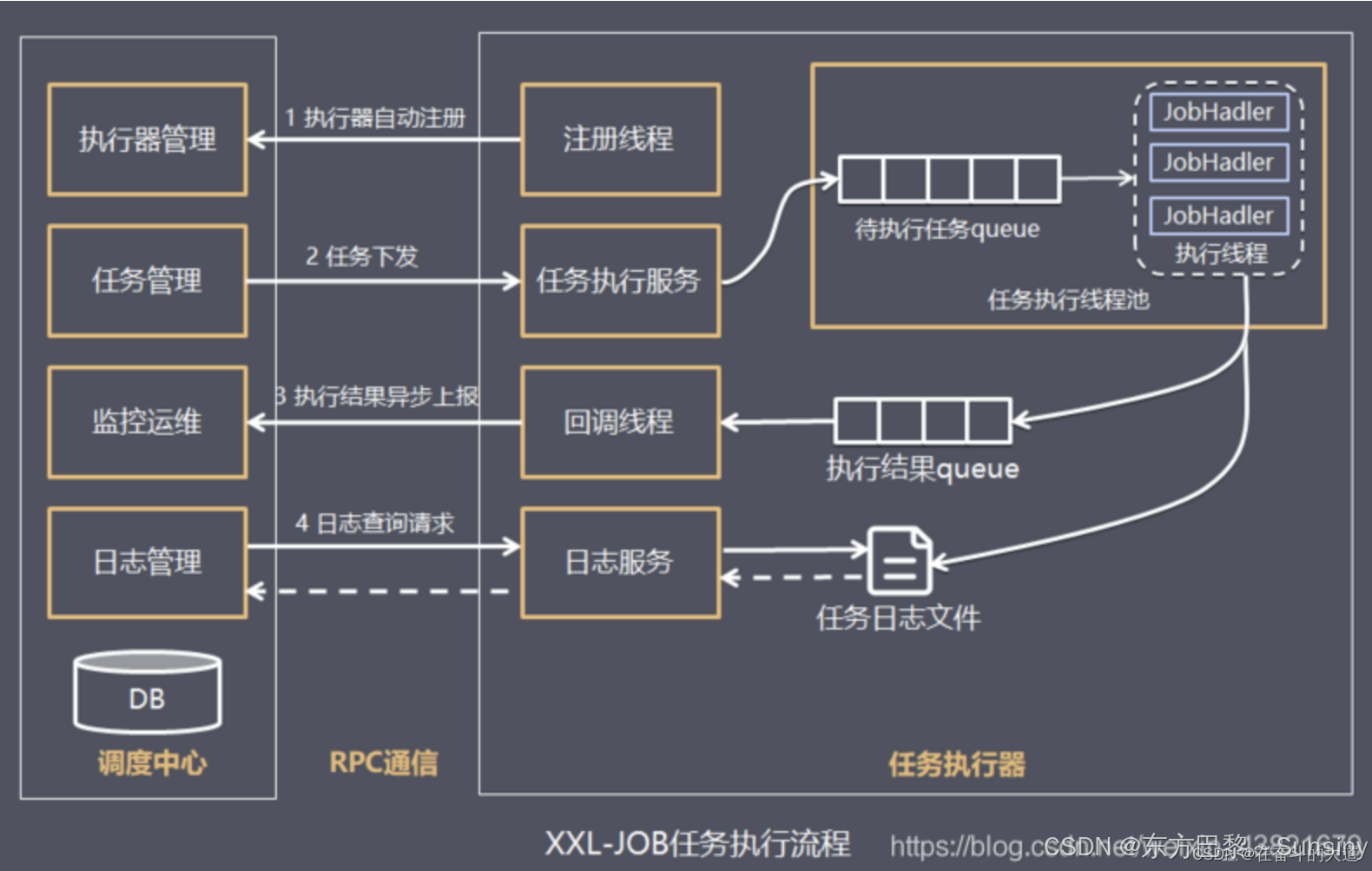
XXL-JOB由两个核心组件构成:调度中心和执行器。调度中心负责维护调度信息并按照预设策略触发任务调度请求,而执行器则负责接收调度请求并执行具体的任务逻辑。此外,数据库用于存储任务配置、执行日志、调度记录等数据,保证调度中心与执行器之间的信息同步。
使用教程
XXL-JOB的使用涉及到环境准备、数据库初始化、配置调度中心与执行器、创建任务等步骤。用户可以通过Web界面进行任务的增删改查操作,并支持多种调度类型(如cron、固定频率、手动触发等)。
XXL-JOB以其轻量级、易扩展和开箱即用的特点,成为了许多公司分布式任务调度的首选解决方案。

2.下载和导入项目
从XXL-JOB的官方Gitee仓库下载项目(https://gitee.com/xuxueli0323/xxl-job),解压后使用IDE导入项目并下载依赖
3.新建数据库和运行SQL
在MySQL中新建数据库,运行项目中doc/db目录下的tables_xxl_job.sql文件以创建所需的表

4.配置和运行调度中心(xxl-job-admin):
在xxl-job-admin模块的application.properties文件中配置数据库和其他相关参数,如时区属性防止乱码
。
启动XxlJobAdminApplication类,访问 http://localhost:8080/xxl-job-admin, 默认账户为admin,密码123456

5.运行项目

访问:http://127.0.0.1:8090/xxl-job-admin/

6.配置执行器:
在XXL-JOB管理界面的“执行器管理”中新增执行器,配置AppName、IP和端口等信息




这样,你的xxljob便完成配置和运行起来了
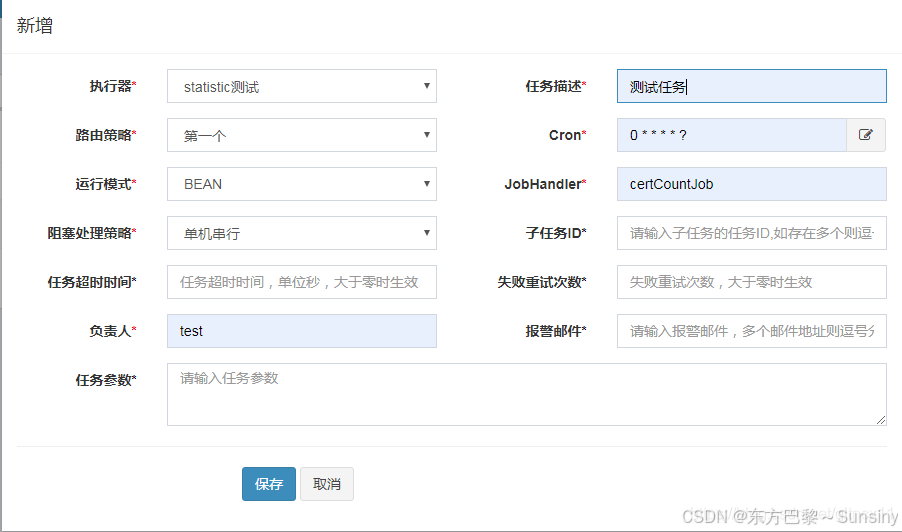
7.新增你自己的调度任务

以上步骤涵盖了XXL-JOB从搭建环境到任务调度的整个流程。更多详细信息和高级配置可以查阅XXL-JOB的官方文档。
8.🤔 如何确保XXL-JOB任务的执行安全性?
确保XXL-JOB任务执行的安全性,可以从以下几个方面进行:
-
加强权限控制:
- 对XXL-JOB的任务管理功能进行权限梳理,对敏感操作进行严格的权限控制,防止未经授权的用户执行任意命令。
-
输入校验和过滤:
- 在处理用户输入时增加校验和过滤机制,对恶意输入进行及时拦截和过滤,防止攻击者通过构造恶意输入来执行任意命令。
-
优化服务器配置:
- 对服务器进行安全配置,如关闭不必要的远程访问端口、及时更新安全补丁等,提高服务器的安全性。
-
设置AccessToken:
- 为提升系统安全性,调度中心和执行器进行安全性校验,双方AccessToken匹配才允许通讯。调度中心和执行器可通过配置项“xxl.job.accessToken”进行AccessToken的设置。
-
限制远程访问:
- 关闭不必要的远程访问端口,仅允许必要的IP地址访问XXL-JOB后台,减少潜在的安全风险。
-
定期安全审计:
- 对XXL-JOB的后台进行定期安全审计,检查是否存在可疑操作或潜在的安全风险。
-
限制执行权限:
- 对XXL-JOB的管理员和普通用户设置不同的权限级别,限制执行敏感操作。
-
加强日志监控:
- 对XXL-JOB的日志进行实时监控和分析,及时发现异常操作和潜在的安全威胁。
-
使用最新版本:
- 保持XXL-JOB的软件版本最新,以便及时修复已知的安全漏洞。
-
SSL/TLS加密:
- XXL-JOB支持SSL/TLS加密,保护任务数据在传输过程中的安全。
通过上述措施,可以有效地提高XXL-JOB任务执行的安全性,保护系统免受未经授权的访问和潜在的安全威胁。
要设置XXL-JOB的访问控制列表(ACL),主要通过配置访问令牌(AccessToken)来实现。以下是具体的设置步骤:
-
调度中心配置:
- 在XXL-JOB的调度中心配置文件
application.properties中,设置xxl.job.accessToken属性。这个属性是非空时启用的,用于配置调度中心通讯的TOKEN。
### 调度中心通讯TOKEN [选填]:非空时启用; xxl.job.accessToken=sffsfststsrter - 在XXL-JOB的调度中心配置文件
-
执行器配置:
- 在执行器的配置文件中,同样设置
xxl.job.accessToken属性,确保执行器和调度中心的AccessToken匹配。
xxl: job: accessToken: sffsfststsrter admin: addresses: http://127.0.0.1:8081/xxl-job-admin - 在执行器的配置文件中,同样设置
-
重启服务:
- 配置完成后,需要重启XXL-JOB的调度中心和执行器服务,以使配置生效。
以上步骤确保了只有设置了正确AccessToken的执行器才能与调度中心进行通讯,从而增强了系统的安全性。如果调度中心和执行器设置了相同的AccessToken,则它们可以正常通讯;如果没有设置或者设置不同,则无法通讯。这是一种简单的ACL实现方式,用于控制和限制对XXL-JOB系统的访问。
9.🛡️ 如果忘记设置AccessToken,如何恢复访问权限?
如果忘记设置XXL-JOB的AccessToken,或者需要恢复访问权限,可以按照以下步骤操作:
-
重新设置AccessToken:
- 在XXL-JOB的调度中心配置文件
application.properties中,找到xxl.job.accessToken属性,并设置一个安全的值。
### 调度中心通讯TOKEN [选填]:非空时启用; xxl.job.accessToken=your_new_access_token - 在XXL-JOB的调度中心配置文件
-
重启调度中心:
- 修改配置后,需要重启XXL-JOB的调度中心服务以使配置生效。
-
执行器配置:
- 同样,在执行器的配置文件中(例如Spring Boot项目中的
application.properties或yml文件),设置相同的AccessToken值。
xxl: job: accessToken: your_new_access_token - 同样,在执行器的配置文件中(例如Spring Boot项目中的
-
重启执行器:
- 修改执行器配置后,也需要重启执行器服务以使配置生效。
-
确保通讯:
- 确保调度中心和执行器设置了相同的AccessToken,这样它们之间才能正常通讯。
-
安全性考虑:
- 建议设置一个强AccessToken,避免使用默认值或简单值,以增强系统的安全性。
-
备份与恢复:
- 如果之前有备份ACL配置,可以通过备份文件来恢复ACL设置。使用
setfacl --restore acl.txt命令来恢复之前备份的ACL权限。
- 如果之前有备份ACL配置,可以通过备份文件来恢复ACL设置。使用
通过以上步骤,可以重新设置和恢复XXL-JOB的访问控制列表(ACL),确保系统的安全性和正常运行。
10.🛠️ 如何优化XXL-JOB的性能?
要优化XXL-JOB的性能,可以从以下几个方面入手:
-
线程池配置优化:
- XXL-JOB提供了线程池配置参数,可以根据业务需求调整线程池的大小和其他相关参数。例如,可以调整
xxl.job.executor.thread.corePoolSize(核心线程数)和xxl.job.executor.thread.maxPoolSize(最大线程数)等参数来优化性能。
- XXL-JOB提供了线程池配置参数,可以根据业务需求调整线程池的大小和其他相关参数。例如,可以调整
-
数据库模型优化&SQL优化:
- 对底层数据库模型进行重构,并简化一些SQL语句。例如,使用
bigint类型,为相关表增加索引,为xxl_job_log表增加uuid,以及去掉不必要的order by查询。
- 对底层数据库模型进行重构,并简化一些SQL语句。例如,使用
-
并发优化:
- 调度优化中存在并发问题,可能会导致同一任务在同一秒内被调度多次。可以通过检查
xxl_job_log表是否存在同一任务在同一秒内产生多条调度日志来排查问题。
- 调度优化中存在并发问题,可能会导致同一任务在同一秒内被调度多次。可以通过检查
-
批量调度优化:
- 在调度任务上千,每秒调度上百任务时,XXL-JOB可能会显得吃力。可以通过增加批量API来优化,如客户端API和批量发起调度的服务端API。
-
调度策略与算法优化:
- XXL-JOB支持多种调度策略,包括CRON表达式、固定间隔、固定延迟等。其内部采用高效的调度算法,如时间轮算法或最小堆算法,来优化任务调度的性能。
-
高可用与容灾:
- 支持多调度中心部署,执行器故障转移,以及数据持久化,以确保系统的高可用性和容灾能力。
-
实战应用与最佳实践:
- 合理配置任务优先级,集成监控系统,实时监控任务执行状态,对异常情况及时报警,减少故障影响范围。
-
分片任务处理:
- 对于大数据量处理,分片任务可以将一个庞大任务分解为多个较小的任务单元,并行执行,提升处理效率。
-
阻塞处理策略:
- 当任务处理失败或超时时,XXL-JOB提供多种阻塞处理策略,包括FAIL、RETRY、FAIL_RETRY,根据业务场景选择合适的策略。
-
路由策略:
- 支持灵活的路由策略,指定任务执行的节点,如FIRST、LAST、ROUND、RANDOM,以实现任务负载均衡。
通过上述优化措施,可以有效提升XXL-JOB的性能和稳定性。
11.🔄 如何监控XXL-JOB的性能指标?
要监控XXL-JOB的性能指标,可以采取以下几种方法:
-
实时查看与监控:
- 通过XXL-JOB提供的Web界面,可以实时查看任务的执行情况,包括执行日志、执行进度和执行结果等信息。
- 集成监控系统(如Prometheus、Grafana等)来监控任务调度器的性能指标,例如任务的执行次数、成功次数、失败次数以及调度器的健康状态。
-
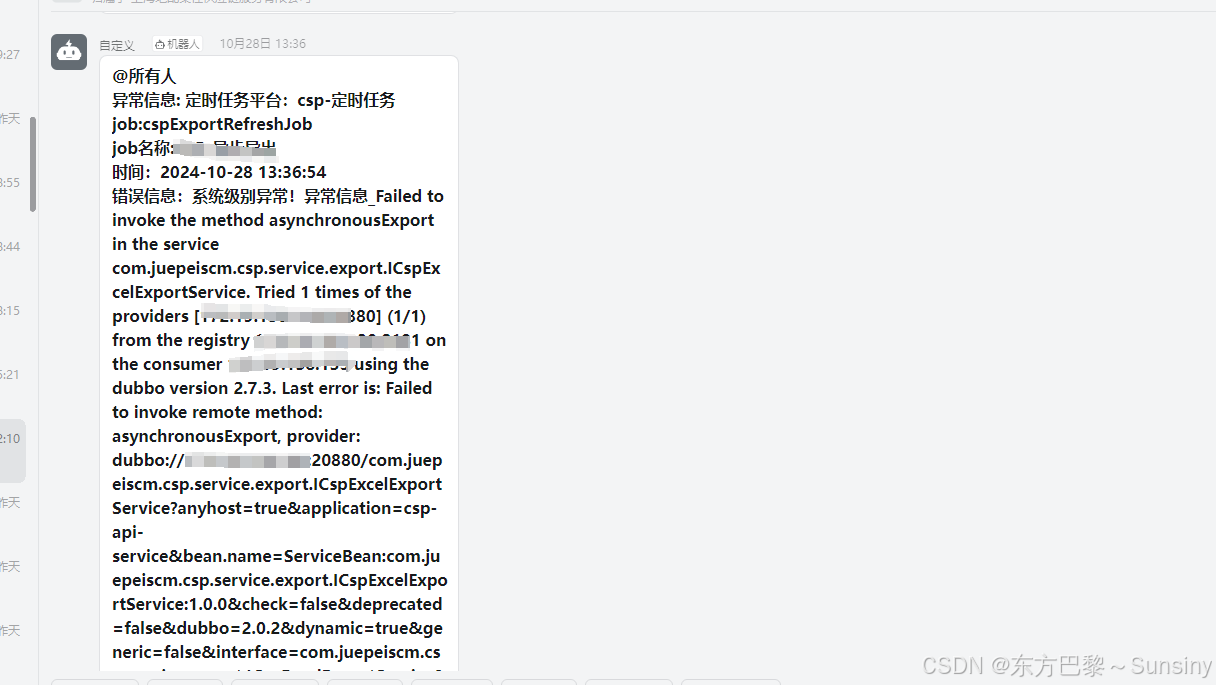
报警机制:
- 集成报警系统(如钉钉机器人、邮件通知等)来实现对任务调度异常的实时报警。当任务执行失败或超时时,配置报警规则以便及时收到通知并处理。
- 开发自定义报警实现,例如通过AOP切面拦截XXL-JOB注解的方法,捕获异常并发送报警通知,如飞书消息等。
-
任务调度中心监控:
- XXL-JOB的任务调度中心会定时监控任务表的变化情况,默认每3秒扫描一次任务表,以保证任务调度的准确性。这个时间间隔可以通过配置
xxl.job.trigger.regular.time在application.properties中进行修改。
- XXL-JOB的任务调度中心会定时监控任务表的变化情况,默认每3秒扫描一次任务表,以保证任务调度的准确性。这个时间间隔可以通过配置
-
执行器监控:
- 执行器(executor)通过定时任务扫描
xxl_job_info表获取需要执行的任务并执行,默认扫描频率是3秒一次。这个频率也可以通过配置xxl.job.executor.scan-interval在application.properties中进行调整。
- 执行器(executor)通过定时任务扫描
-
日志记录:
- 在任务Handler中添加详细的日志信息,以追踪任务的执行情况并及时发现问题。
-
动态调度与任务依赖监控:
- 利用XXL-JOB的动态调度功能来应对实时需求的变化,如动态调整任务触发时间、任务取消、任务延迟等。
- 监控任务之间的依赖关系,确保任务按照正确的顺序执行。
-
版本管理与测试:
- 使用版本控制工具(如Git)来管理任务Handler代码,以便跟踪任务逻辑的变化和恢复历史版本。
- 在开发任务Handler时进行充分的单元测试,确保任务逻辑的正确性。
通过上述方法,可以有效地监控XXL-JOB的性能指标,确保任务调度的稳定性和可靠性。
12.接入钉钉消息预警提醒
@Slf4j
@Component
public class DingDingJobAlarm implements JobAlarm {
private final RestTemplate restTemplate = new RestTemplate();
@Resource
private DingDingConfig dingDingConfig;
@Override
public boolean doAlarm(XxlJobInfo info, XxlJobLog jobLog) {
boolean alarmResult = true;
if (info != null && 2 == info.getJobGroup() && info.getTriggerStatus() == 0){
System.out.println("mita的定时任务服务挂机了,请注意!!!");
log.info("info={},jobLog={}", JSON.toJSONString(info),JSON.toJSONString(jobLog));
}
if (jobLog != null && 2 == jobLog.getJobGroup() && jobLog.getTriggerCode() != 200){
System.out.println("测试服务的定时任务挂机了"+jobLog.getExecutorHandler()+"请注意!!!");
MessageWarningUtils.sendMessage("测试服务的定时任务挂机了:"+jobLog.getExecutorHandler()+",请注意!!!", dingDingConfig.getToken(), dingDingConfig.getSecretKey());
log.info("info={},jobLog={}", JSON.toJSONString(info),JSON.toJSONString(jobLog));
}
return alarmResult;
}
}
@Component
public class DingDingConfig {
@Resource
private Environment environment;
@Value("${dingding.warning.token}")
private String token;
@Value("${dingding.warning.secretKey}")
private String secretKey;
public String getToken() {
return environment.getProperty("dingding.warning.token");
}
public void setToken(String token) {
this.token = token;
}
public String getSecretKey() {
return environment.getProperty("dingding.warning.secretKey");
}
public void setSecretKey(String secretKey) {
this.secretKey = secretKey;
}
}
spring.profiles.active=prod
### web
server.port=8090
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.base-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.web.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource 调度中心JDBC链接
spring.datasource.url=jdbc:mysql://114:3306/xxl_job?useUnicode=true&useSSL=false&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000
### xxl-job, email 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=2286169307@qq.com
spring.mail.from=2286169307@qq.com
spring.mail.password=971103spy
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=default_token
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
# 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
# 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
# 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
spring.redis.host= 47.115
spring.redis.port= 6379
spring.redis.password=123456
# 最大连接数
spring.redis.lettuce.pool.max-active= 8
# 最大空闲连接数
spring.redis.lettuce.pool.max-idle= 8
# 最大阻塞等待时间(使用负值表示没有限制)
spring.redis.lettuce.pool.max-wait= -1ms
# 最小空闲连接数
spring.redis.lettuce.pool.min-idle= 0
## 哨兵集群主节点名
#spring.redis.sentinel.master= mymaster
## 哨兵集群各节点
#spring.redis.sentinel.nodes = {ip}:{port}, {ip}:{port}, {ip}:{port}
dingding.warning.token= https://oapi.dingtalk.com/robot/send?access_token=979463598e237d1c94783c40df98b9180acb7cbeeb9cf8a2c449486ea2269947
dingding.warning.secretKey= SECd397d2292284f89cd6d7966781c8c4208d94b8e9960a99f617dbdfd0e03f0549
这个是效果
13.🔍 如何设置XXL-JOB的报警阈值?
在XXL-JOB中设置报警阈值主要涉及到任务失败重试次数和任务超时时间的配置,以下是具体的设置方法:
-
任务失败重试次数:
- 在任务配置中,可以设置失败重试次数(
failRetryCount)。当任务执行失败时,XXL-JOB会根据设定的重试次数自动进行重试。这个参数可以在任务的高级设置中进行配置。例如,设置失败重试次数为5次:@XxlJob("demoJobHandler") public ReturnT<String> execute(String param) throws Exception { XxlJobExecutor.failRetryCount = 5; // 设置重试次数为5次 // 任务执行逻辑 // ... return ReturnT.SUCCESS; } - 这个设置确保了在任务失败时,系统会尝试重新执行任务,直到达到设定的重试次数。
- 在任务配置中,可以设置失败重试次数(
-
任务超时时间:
- 支持自定义任务超时时间,任务运行超时将会主动中断任务。这个参数同样可以在任务的高级设置中进行配置。例如,设置任务超时时间为10秒:
@XxlJob(value = "demoJobHandler", timeout = 10) // 超时时间为10秒 public ReturnT<String> execute(String param) throws Exception { // 任务执行逻辑 // ... return ReturnT.SUCCESS; } - 这个设置有助于防止任务因执行时间过长而影响系统性能。
- 支持自定义任务超时时间,任务运行超时将会主动中断任务。这个参数同样可以在任务的高级设置中进行配置。例如,设置任务超时时间为10秒:
-
报警邮件配置:
- 在XXL-JOB的调度中心配置文件
application.properties中,可以配置邮件报警相关的参数,如邮件服务器地址、端口、用户名、密码等。例如:### xxl-job, email spring.mail.host=smtp.qq.com spring.mail.port=25 spring.mail.username=xxxx@qq.com spring.mail.from=xxxx@qq.com spring.mail.password=xxxxx spring.mail.properties.mail.smtp.auth=true spring.mail.properties.mail.smtp.starttls.enable=true spring.mail.properties.mail.smtp.starttls.required=true spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory - 这些配置项用于设置邮件报警的发送参数,当任务失败并且超过重试次数时,系统会通过邮件发送报警通知。
- 在XXL-JOB的调度中心配置文件
通过上述设置,可以有效地监控和管理XXL-JOB任务的执行情况,并在任务失败时及时采取措施。
14.🛠️ 任务执行失败时,XXL-JOB有哪些自动处理机制?
XXL-JOB在任务执行失败时提供了几种自动处理机制,主要包括:
-
失败重试机制:
- XXL-JOB允许您为任务配置失败重试次数和重试间隔。如果任务执行失败,调度中心会根据配置自动重试任务,直到达到设定的重试次数。这有助于提高任务的执行成功率。
-
故障转移机制:
- 在执行器集群部署时,如果某一台执行器发生故障,XXL-JOB可以通过故障转移机制将任务重新分配给其他健康的执行器,确保任务的连续性和可靠性。
-
任务超时控制:
- XXL-JOB支持自定义任务超时时间,如果任务运行超过设定的时间,系统会自动中断任务执行,避免长时间占用资源。
-
邮件报警机制:
- 当任务失败时,XXL-JOB可以配置邮件报警,将失败的任务信息通过邮件通知给负责人,以便及时采取措施。
-
任务补偿机制:
- 对于某些业务场景,XXL-JOB允许配置任务补偿逻辑,当任务失败后,可以自动执行补偿任务,以恢复任务执行前的状态,减少失败对业务的影响。
-
实时监控与日志记录:
- XXL-JOB提供了实时监控任务进度的功能,以及详细的执行日志记录,帮助追踪任务执行情况,及时发现和解决问题。
-
动态调度与任务依赖:
- XXL-JOB支持动态修改任务状态和终止运行中的任务,以及配置任务之间的依赖关系,确保任务按照正确的顺序执行。
通过这些自动处理机制,XXL-JOB能够在任务执行失败时提供必要的恢复和补救措施,确保任务调度的稳定性和可靠性。
15.🛠️ XXL-JOB在执行器集群中如何实现故障转移?
在XXL-JOB的执行器集群中实现故障转移的机制主要包括以下几个方面:
-
路由策略:
- XXL-JOB提供了多种路由策略,其中包括“故障转移”策略。当任务的路由策略设置为“故障转移”时,如果执行器集群中的某一台机器出现故障,XXL-JOB会自动Failover切换到一台正常的执行器发送调度请求。
-
心跳检测:
- 在“故障转移”策略中,调度中心会定期对执行器节点进行心跳检测。如果某台执行器节点没有响应或者返回不可用状态,调度中心会将任务调度到其他正常的执行器节点上。
-
执行器自动注册:
- 执行器会周期性自动注册任务到调度中心,调度中心将自动发现注册的任务并触发执行。这样,一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务,这也为故障转移提供了支持。
-
调度中心的高可用设计:
- 调度中心支持多节点部署,基于数据库行锁保证触发器的名称和执行时间相同,则只且仅有一个调度中心节点去下发任务给执行器,这也有助于在某个节点故障时,其他节点能够接管任务。
-
故障转移与失败重试:
- 在XXL-JOB中,“故障转移”发生在调度阶段,而“失败重试”发生在调度和执行阶段。这意味着如果任务在执行过程中失败,XXL-JOB会根据预设的失败重试次数主动进行重试。
通过上述机制,XXL-JOB能够在执行器集群中实现有效的故障转移,确保任务的连续性和系统的稳定性。
16.🔄 故障转移后,XXL-JOB如何保证任务的一致性?
XXL-JOB在执行器集群中实现故障转移后,保证任务一致性的机制主要包括以下几点:
-
数据库锁保证调度一致性:
XXL-JOB通过数据库锁来保证集群环境下任务调度的一致性。调度中心在进行任务调度之前,会尝试获取一个数据库级别的锁,确保在同一时间只有一个调度中心节点执行任务调度。这是通过执行特定的SQL语句来实现的,例如:select * from xxl_job_lock where lock_name = 'schedule_lock' for update。这种方式可以防止多个调度中心实例同时调度同一个任务,保证了任务在同一时间只会被一个调度中心触发一次。 -
故障转移策略:
当任务配置了故障转移路由策略后,如果执行器集群中的某一台机器发生故障,XXL-JOB会自动Failover切换到一台正常的执行器发送调度请求,从而保证任务的连续性和稳定性。 -
任务超时控制和失败重试:
XXL-JOB支持自定义任务超时时间和失败重试次数。如果任务运行超时,系统会主动中断任务;如果任务失败,系统会根据预设的失败重试次数主动进行重试,这有助于确保任务最终能够成功执行。 -
执行器的心跳检测:
XXL-JOB的调度中心会定期对执行器节点进行心跳检测,以确定执行器节点是否可用。如果发现某个执行器节点不可达,调度中心会将其从可用执行器列表中移除,并在下一次调度时选择其他可用的执行器节点。 -
阻塞处理策略:
当执行器节点存在多个相同任务ID的任务未执行完成时,XXL-JOB提供了阻塞处理策略,包括串行、丢弃旧任务、丢弃新任务等策略,以保证任务的有序执行。
通过上述机制,XXL-JOB能够在执行器集群中实现故障转移后,仍然保持任务的一致性和可靠性。
17.🔄 能否详细解释一下XXL-JOB的路由策略?
XXL-JOB提供了丰富的路由策略来决定在集群部署时如何选择具体的执行器节点来执行任务。以下是XXL-JOB支持的路由策略的详细解释:
-
FIRST(第一个):
- 固定选择注册地址中的第一台机器执行任务。
-
LAST(最后一个):
- 固定选择注册地址中的最后一台机器执行任务。
-
ROUND(轮询):
- 按照注册地址的顺序轮询选择机器执行任务。
-
RANDOM(随机):
- 随机选择在线的机器执行任务。
-
CONSISTENT_HASH(一致性HASH):
- 每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
-
LEAST_FREQUENTLY_USED(最不经常使用):
- 使用频率最低的机器优先被选举执行任务。
-
LEAST_RECENTLY_USED(最近最久未使用):
- 最久未使用的机器优先被选举执行任务。
-
FAILOVER(故障转移):
- 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度。
-
BUSYOVER(忙碌转移):
- 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度。
-
SHARDING_BROADCAST(分片广播):
- 广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。
这些路由策略使得XXL-JOB能够适应不同的业务场景和执行器集群的部署需求,提高任务调度的灵活性和系统的容错性。通过合理选择和配置路由策略,可以有效地提升XXL-JOB在分布式任务调度中的性能和可靠性。
18.🤔 如何配置XXL-JOB的路由策略以适应高并发任务调度?
为了适应高并发任务调度,XXL-JOB提供了多种路由策略,以下是几种推荐的路由策略配置方法:
-
分片广播(SHARDING_BROADCAST):
- 当执行器集群部署时,如果需要同时触发所有机器执行任务,可以选择分片广播策略。这种策略会广播触发对应集群中所有机器执行一次任务,并且系统自动传递分片参数,可以根据分片参数开发分片任务。这对于需要并行处理同一张数据表里的数据的场景特别有用,可以大大提升处理效率。
-
随机(RANDOM):
- 如果任务数量较多且执行时间较长,随机策略可以提供更好的负载均衡,随机选择在线的机器执行任务,避免单点过载。
-
最少并发(LEAST_FREQUENTLY_USED):
- 这种策略将任务分配给并发任务最少的工作节点,适用于任务数量较多且执行时间较长的场景,可以防止某些工作节点过载。
-
一致性哈希(CONSISTENT_HASH):
- 对于任务数量非常多且执行时间较长的场景,一致性哈希策略可以根据任务的名称或其他属性计算哈希值,然后将任务分配给哈希值相同的工作节点,提高命中率。
-
故障转移(FAILOVER):
- 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度。这种策略可以确保任务在集群中的某个节点发生故障时,能够快速转移到其他节点执行。
-
忙碌转移(BUSYOVER):
- 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度。这种策略适用于需要确保任务在非忙碌节点上执行的场景。
在配置路由策略时,可以根据任务的特性和业务需求选择合适的策略。例如,对于需要高并发处理的任务,分片广播策略可以提供很好的支持;而对于需要负载均衡的场景,随机或最少并发策略可能更为合适。通过合理配置路由策略,可以有效地提升XXL-JOB在高并发任务调度中的性能和稳定性。
19.🔧 能否详细解释一下分片广播策略的工作原理?
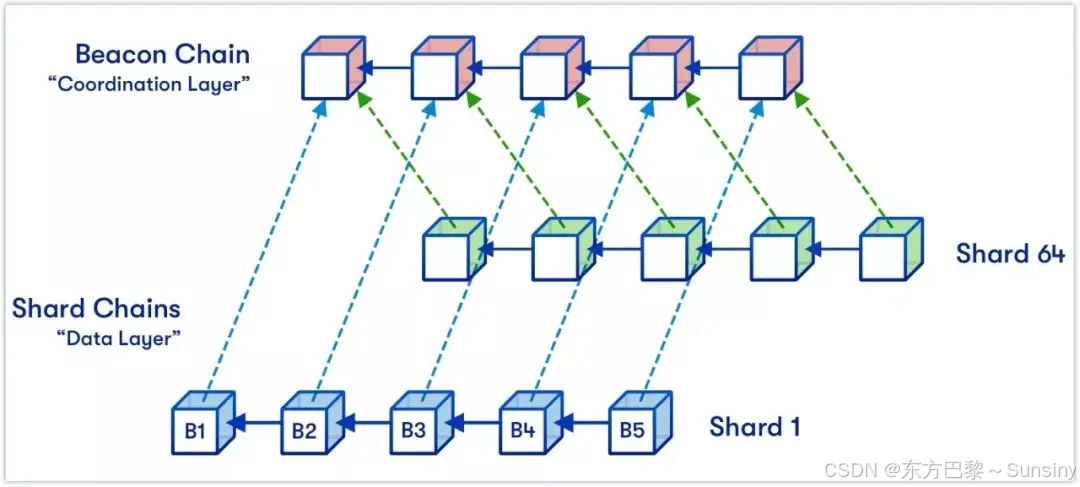
分片广播策略是XXL-JOB中处理高并发任务调度的一种重要机制。以下是其工作原理的详细解释:
-
任务配置与分发:
- 在XXL-JOB的调度中心,用户通过Web界面创建一个分片广播类型的任务,并设置相应的参数,如分片总数(shardingTotalCount)。当调度触发时,调度中心会将此任务广播至所有注册的执行器。
-
分片参数传递:
- 每个执行器在接收到广播的任务时,会自动获得分片参数,包括分片总数和当前执行器应该处理的分片序号(shardingItem)。这些参数由XXL-JOB框架自动注入,使得执行器能够知道它应当处理哪个数据分片。
-
分片逻辑执行:
- 实际的分片逻辑需要在执行器的任务处理器代码中实现。开发者需要根据分片序号和总数,决定处理哪些数据。这通常涉及对数据源的分片访问,例如数据库查询时使用分页查询或者ID取模等方法来确定每个执行器处理的数据范围。然后各个执行器并行处理各自分片的数据,互不影响。
-
结果汇总:
- 由于是广播任务,每个执行器处理的是全量数据的一个子集,因此不存在汇总操作,每个执行器独立完成自己的处理逻辑。如果需要最终汇总结果,需要额外的逻辑来收集和整合各个执行器的输出。
-
动态扩容执行器集群:
- 分片广播以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理。在进行大数据量业务操作时可显著提升任务处理能力和速度。
-
代码实现示例:
- 在执行器集群部署时,任务路由策略选择“分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。
通过上述机制,XXL-JOB的分片广播策略能够有效地将大规模任务分解为多个小任务,并在多个执行器上并行执行,从而提高任务处理的效率和速度。这对于需要处理大量数据的场景尤其有用,如数据同步、大数据处理、批量报表生成等业务场景。
20.🔍 分片广播策略在XXL-JOB中与其他任务调度策略相比有哪些优势?
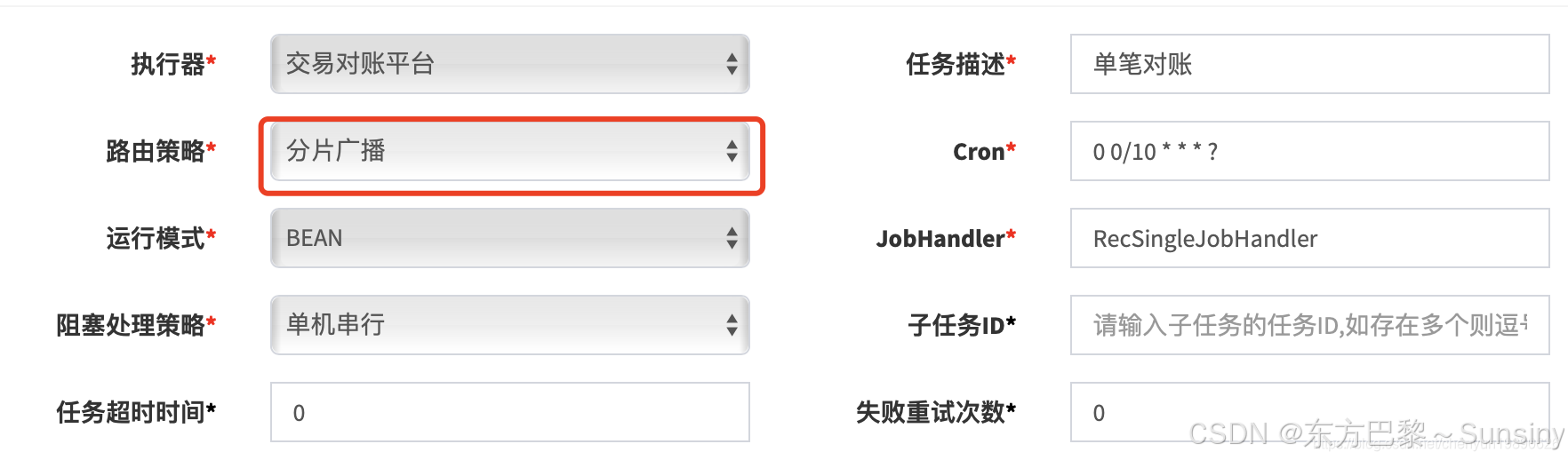
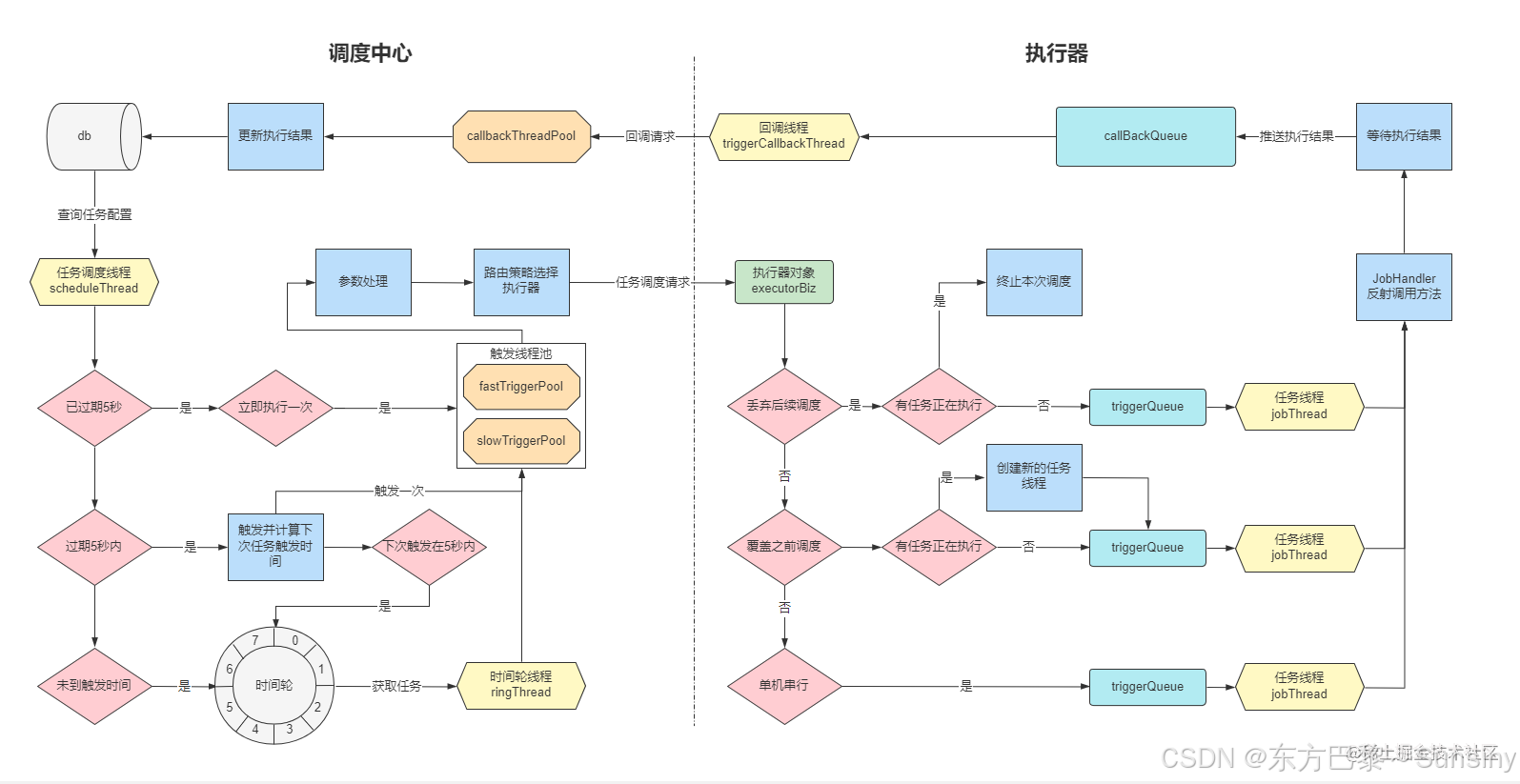
分片广播策略在XXL-JOB中与其他任务调度策略相比的优势主要体现在以下几个方面:
-
高并发处理能力:
分片广播策略可以将一个任务分片并广播到所有执行器节点上执行,有效提高任务并发性,缩短执行时间。这对于需要处理大量数据的场景尤其有用,如大数据处理或批量任务执行,可以显著提升任务处理能力和速度。 -
负载均衡:
通过分片广播,任务可以均匀分配到所有节点,每个节点只需要执行部分数据,这样可以平衡各节点的负载,避免单点压力过大。 -
灵活性和动态扩容:
分片广播以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理。这意味着当执行器节点数量变化时,系统可以自动适应,无需人工干预。 -
简化任务分配逻辑:
XXL-JOB自动为每个注册节点分配一个index,并记录注册节点的总个数,这些信息可以被任务逻辑直接使用,简化了任务分配的复杂性。 -
提高任务执行效率:
相比常用的轮询策略,分片广播策略效率更高,因为轮询调度只会调度某一台节点,而分片广播策略可以让所有节点都参与任务执行。 -
适用于大规模分布式系统:
分片广播策略特别适用于大规模分布式系统中的高并发任务调度,可以充分利用集群资源,提高系统的整体性能和吞吐量。 -
容错性和可靠性:
由于任务被分发到多个节点执行,即使某个节点失败,其他节点仍然可以继续执行任务,从而提高了任务的容错性和可靠性。
综上所述,分片广播策略在处理高并发、大规模分布式任务时,提供了负载均衡、灵活性、效率和可靠性等多方面的优势,使其成为XXL-JOB中处理此类任务的理想选择。
21.🛠️ 能否详细说明分片广播策略在XXL-JOB中的具体实现步骤?
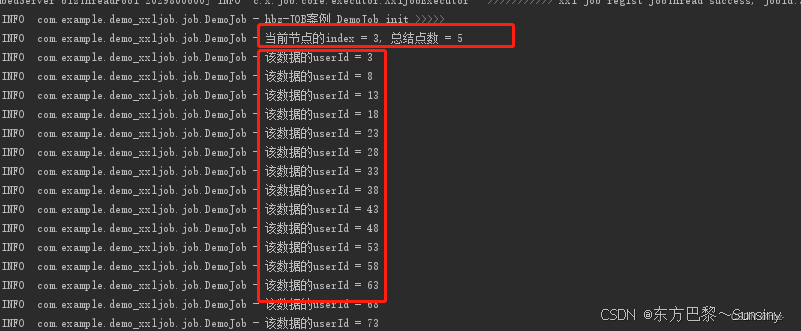
分片广播策略在XXL-JOB中的具体实现步骤如下:
-
任务配置与分发:
- 在XXL-JOB的调度中心,用户通过Web界面创建一个分片广播类型的任务,并设置相应的参数,如分片总数(shardingTotalCount)。当调度触发时,调度中心会将此任务广播至所有注册的执行器。
-
分片参数传递:
- 每个执行器在接收到广播的任务时,会自动获得分片参数,包括分片总数和当前执行器应该处理的分片序号(shardingItem)。这些参数由XXL-JOB框架自动注入,使得执行器能够知道它应当处理哪个数据分片。
-
分片逻辑执行:
- 实际的分片逻辑需要在执行器的任务处理器代码中实现。开发者需要根据分片序号和总数,决定处理哪些数据。这通常涉及对数据源的分片访问,例如数据库查询时使用分页查询或者ID取模等方法来确定每个执行器处理的数据范围。然后各个执行器并行处理各自分片的数据,互不影响。
-
获取分片参数:
- 在任务执行的方法中,可以通过
XxlJobHelper.getShardIndex()和XxlJobHelper.getShardTotal()来获取当前分片的序号和总分片数。这些信息用于决定当前执行器需要处理的数据范围。
- 在任务执行的方法中,可以通过
-
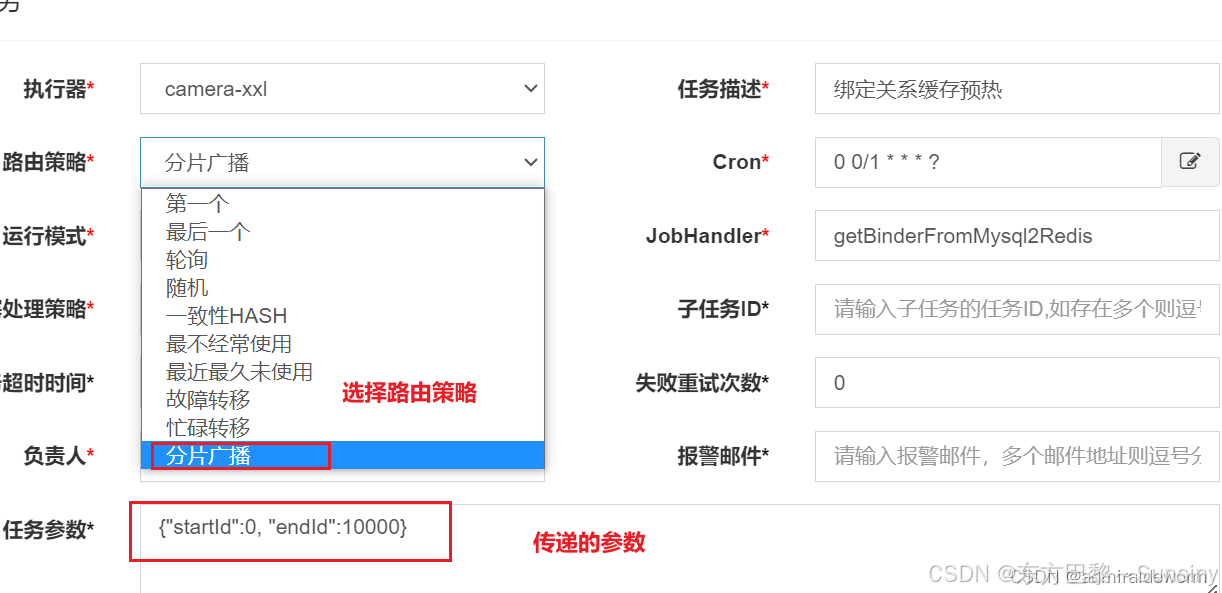
代码实现:
- 在执行器的代码中,根据分片参数执行具体的业务逻辑。例如,可以通过取模运算符来确定哪些数据由当前执行器处理。以下是一个示例代码,展示了如何根据分片参数来处理数据:
@XxlJob("shardingJobHandler") public ReturnT<String> shardingJobHandler(String param) throws Exception { // 分片参数 ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo(); XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal()); // 业务逻辑 for (int i = 0; i < shardingVO.getTotal(); i++) { if (i == shardingVO.getIndex()) { XxlJobLogger.log("第 {} 片, 命中分片开始处理", i); } else { XxlJobLogger.log("第 {} 片, 忽略", i); } } return ReturnT.SUCCESS; }
- 在执行器的代码中,根据分片参数执行具体的业务逻辑。例如,可以通过取模运算符来确定哪些数据由当前执行器处理。以下是一个示例代码,展示了如何根据分片参数来处理数据:
- 结果处理:
- 由于是广播任务,每个执行器处理的是全量数据的一个子集,因此不存在汇总操作,每个执行器独立完成自己的处理逻辑。如果需要最终汇总结果,需要额外的逻辑来收集和整合各个执行器的输出。
通过上述步骤,XXL-JOB的分片广播策略能够有效地将大规模任务分解为多个小任务,并在多个执行器上并行执行,从而提高任务处理的效率和速度。
22.🤔 分片广播策略与轮询策略相比,具体提升了多少效率?
分片广播策略与轮询策略相比,在效率提升方面具有显著优势。以下是具体的效率提升案例和分析:
-
处理海量数据更新的效率提升:
- 在一个具体案例中,有100万用户需要在每天0点定时将每个用户的“当天剩余流量包”重置。如果采用传统的轮询调度,所有100万数据都会冲击到1台节点执行,效率显然不合格。而采用分片广播调度,发动所有节点同时执行,100万的用户数据均匀分配到所有节点,每个节点只需要执行部分数据。
-
Redis新集群定时任务缓存预加载功能的效率提升:
- 在开发Redis新集群定时任务缓存预加载功能时,需要将2500万条信息写入Redis缓存中。采用分片广播模式的优势在于,XXL-JOB调度中心只要发出一次调度,所有的相关节点会全部执行一次。这样,2500万的数据均匀分配到所有节点,每个节点只需要执行所分配到的数据即可。相比常用的轮询策略,效率提升明显。
-
大规模数据处理的效率提升:
- 分片广播策略通过将一个大任务拆分成多个小任务,并由多个执行器节点并行处理,每个执行器节点处理分片任务的一部分,适用于需要大规模并行处理的场景。这种方式类似于MQ的广播模式,可以将任务广播到集群中的所有执行器上执行。此策略适用于数据同步或分布式计算等需要并行处理大量任务的场景。
综上所述,分片广播策略相比于轮询策略,在处理高并发、大规模数据量的任务时,可以显著提升任务处理能力和速度,同时保证负载均衡和系统的稳定性。通过实际案例可以看出,分片广播策略可以将任务均匀分配到所有节点执行,避免了单点过载的问题,从而大幅度提高了效率。
23.🔄 轮询策略和分片广播策略各自适用于哪些场景?
轮询策略和分片广播策略是XXL-JOB中两种不同的任务调度策略,它们各自适用于不同的场景:
轮询策略(ROUND)
轮询策略按照执行器列表的顺序轮流将任务分配给每个可用的执行器节点。这种策略简单且公平,适用于以下场景:
- 负载均衡:当所有执行器节点的性能相近,且任务可以均匀分配时,轮询策略可以确保任务平均分配到每个节点,实现负载均衡。
- 无状态任务:对于那些不依赖于特定执行器节点的任务,如数据清理、日志归档等,轮询策略是一个合适的选择。
- 简单的任务分发:适用于任务执行逻辑简单,且对执行顺序没有特定要求的场景。
分片广播策略(SHARDING_BROADCAST)
分片广播策略将任务分片并广播到所有执行器节点,每个节点执行任务的一部分。这种策略适用于以下场景:
- 大规模数据处理:需要处理大量数据时,如批量数据处理、大数据分析等,分片广播策略可以将数据分片并行处理,显著提高处理速度。
- 分布式计算:在需要进行分布式计算的场景中,如机器学习、科学计算等,分片广播策略可以将计算任务分配到多个节点并行执行,提高计算效率。
- 数据同步:在多个数据库或服务之间同步数据时,分片广播策略可以确保数据的一致性和完整性,同时提高同步效率。
- 高并发任务处理:面对高并发的任务请求,分片广播策略可以分散任务到多个节点执行,避免单点过载,提高系统的整体处理能力。
总结来说,轮询策略适合于简单的、无状态的、对执行顺序无特定要求的任务调度,而分片广播策略适合于需要大规模并行处理、高并发处理以及分布式计算的场景。选择合适的策略可以提高任务执行的效率和系统的稳定性。
24.🌐 在分布式系统中,轮询策略和分片广播策略各自的优势和劣势是什么?
在分布式系统中,轮询策略和分片广播策略各有其优势和劣势,以下是它们的具体分析:
轮询策略(Round Robin)
优势:
- 简单易懂:轮询策略的原理非常简单,易于理解和实现,适用于初学者。
- 数据均匀分布:轮询策略可以确保数据均匀分布在各个分区中,提高了系统的整体性能和可用性。
- 高效率:轮询策略是一种非常高效的分发方法,因为它只需要将数据元素逐个循环发送至各个分区,而不需要进行复杂的计算。
- 可靠性强:轮询策略以其可靠性著称,可以确保所有数据元素都被发送至某个分区,而不会丢失任何数据元素。
劣势:
- 数据倾斜:尽管轮询策略可以防止数据倾斜,但在某些情况下它仍然可能发生,尤其是当数据元素具有不同的大小或处理时间时。
- 效率低下:在处理大数据量时,轮询策略可能会变得效率低下,因为需要将每个数据元素逐个循环发送至各个分区。
- 扩展性差:轮询策略的扩展性较差,因为它无法很好地支持数据量的快速增长。当分区数量增加时,轮询策略的效率可能会大幅下降。
分片广播策略(Sharding Broadcast)
优势:
- 高并发处理能力:分片广播策略可以将一个任务分片并广播到所有执行器节点,有效提高任务并发性,缩短执行时间。
- 负载均衡:通过分片广播,任务可以均匀分配到所有节点,每个节点只需要执行部分数据,这样可以平衡各节点的负载,避免单点过载。
- 灵活性和动态扩容:分片广播以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理。
- 提升任务执行效率:相比常用的轮询策略,分片广播策略效率更高,因为轮询调度只会调度某一台节点,而分片广播策略可以让所有节点都参与任务执行。
劣势:
- 复杂性较高:相比于简单的轮询策略,分片广播策略的实现更为复杂,需要处理分片参数的传递和任务的分片逻辑。
- 资源消耗:在所有节点上执行相同任务可能会造成资源的重复消耗,尤其是在任务不需要在所有节点上执行时。
总结来说,轮询策略适合于简单的、无状态的、对执行顺序无特定要求的任务调度,而分片广播策略适合于需要大规模并行处理、高并发处理以及分布式计算的场景。选择合适的策略可以提高任务执行的效率和系统的稳定性。
25.🛠️ 如何改进轮询策略以适应更复杂的高并发场景?
为了改进轮询策略以适应更复杂的高并发场景,我们可以从以下几个方面进行优化:
-
加权轮询(Weighted Round Robin):
- 在传统的轮询策略中,所有服务器被平等对待,不考虑它们实际的性能差异。加权轮询策略通过给不同的服务器分配不同的权重来解决这个问题。权重可以根据服务器的性能指标动态调整,如CPU利用率、内存使用情况、响应时间等参数,以此保证负载均衡更加精确地映射了后端服务器的实际处理能力。
-
最少连接(Least Connections):
- 最少连接策略会将新的请求发送到当前活跃连接数最少的服务器上。这样做的好处在于能够相对平均地分配负载,避免某些服务器压力过大而其他服务器空闲。这种策略适合于处理长连接请求的场景,如WebSocket、FTP服务。
-
加权最少连接(Weighted Least Connections):
- 加权最少连接是最少连接策略的改进版。在此策略中,除了考虑服务器的当前连接数外,还会给每台服务器配置一个权重,根据权重来分配请求。这意味着即便是连接数最少的服务器,如果权重较低,也不会接收太多的请求,从而更加精确地保证负载均衡和服务器性能的最优利用。
-
基于IP哈希(IP Hash):
- 基于IP哈希的负载均衡策略根据客户端IP地址的哈希值来分配请求。这种方法能够保持客户端与特定服务器之间的一致性,因此用户的会话信息能在同一个服务器上保持一致。这种策略适用于需要保持客户端会话一致性的场景,例如需要维护用户session的Web应用。
-
健康检查与故障切换(Health Checks and Failover):
- 负载均衡不仅仅是关于请求的分发,还包括监控服务器的健康状况并且在检测到问题时进行故障切换。健康检查确保流量只被发送到健康的服务器上,而故障切换机制能够在服务器失效时快速将其排除出负载均衡池。
-
动态调整策略:
- 在实际系统中,可以结合监控和反馈机制,根据系统负载动态调整线程池的配置。例如,当系统负载较高时,可以适当增加最大线程数;当系统负载较低时,可以减少核心线程数和最大线程数,以节约资源。
通过上述优化措施,轮询策略可以更好地适应高并发场景,提高系统的稳定性和效率。


















 8318
8318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











