







总结:
1 表的起名尽量不要是关键字(order): 配置一对多等映射关系时,会报错
2 一些映射关系,都会进行多余的sql操作,很影响效率。
1 前置配置
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useTimezone=true&serverTimezone=GMT%2B8&allowMultiQueries=true
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver #驱动
jpa:
hibernate:
ddl-auto: update #自动更新
show-sql: true #日志中显示sql语句 ddl-auto属性用于设置自动表定义
- create 启动时删数据库中的表,然后创建,退出时不删除数据表
- create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在报错
- update 如果启动时表格式不一致则更新表,原有数据保留
- validate 项目启动表结构进行校验 如果不一致则报错
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>2属性的介绍
以下属性都是围绕 @Entity 的实体下解释
| @Entity(name="t_user") | 1:该实体类就是数据库的表必须加。否则像数据库添加数据报错。2:不指定数据库表名,就会认为表名和实体类一样,数据库没有就会创建表(ddl_auto) |
| @Table | 1:就是指定映射哪个表 @Entity+@Table(name="t_user") 等效于@Entity(name="t_user") |
| @Basic | 1:隐藏字段,当我们实体类中属性不加任何注解,也会和数据库映射 |
| @Transient | 1:实体类中属性和数据库无关连时,必须加上该注解。 |
| @Column | 1:属性和数据库不一样时可以映射数据库字段 |
| @Temporal(TemporalType.DATE) | 1:日期类型属性,和数据库精度对应。(DATE,TIME,TIMESTAMP) |
3主键配置:
方式一:自增方式
@Id
@Column(name = "t_id")
@GeneratedValue //主键自增
private Long id;方式二:通过表监控方式自增
1:先要创建一个数据库表
CREATE TABLE `jpa_id_generators` (
`id` bigint NOT NULL AUTO_INCREMENT,
`pk_name` varchar(50) DEFAULT NULL,
`pk_value` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;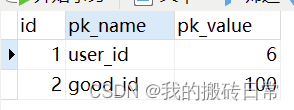
@Id
@Column(name = "t_id")
/**
* 根据表方式自增
*/
@TableGenerator(name = "ID_GENERATOR",
table = "jpa_id_generators",
pkColumnName = "pk_name",
pkColumnValue = "user_id",
valueColumnName = "pk_value",
allocationSize = 1) //增长跨度 每次添加数据主键+1
@GeneratedValue(strategy = GenerationType.TABLE, generator = "ID_GENERATOR")
private Long id;
详解: 用jpa_id_generators 这个表的 pk_name字段下 的 user_id的pk_value作为主键。没加一条数据,user_id的pk_value会+1 (配置的是+1)
import lombok.Data;
import lombok.ToString;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
import java.util.List;
@Data
@ToString
@Entity
@Table(name = "t_user")
public class Tuser implements Serializable {
//t_id 区分数据库和实体字段
@Id
@Column(name = "t_id")
// @GeneratedValue 主键自增
/**
* 根据表方式自增
*/
@TableGenerator(name = "ID_GENERATOR",
table = "jpa_id_generators",
pkColumnName = "pk_name",
pkColumnValue = "user_id",
valueColumnName = "pk_value",
allocationSize = 10) //增长跨度 每次+1
@GeneratedValue(strategy = GenerationType.TABLE, generator = "ID_GENERATOR")
private Long id;
//t_name
@Column(name = "t_name", length = 6)
private String name;
//t_age
@Column(name = "t_age")
private Integer age;
//t_address
@Column(name = "t_address")
private String address;
/* @Column(name = "create_time")
@Basic
*/
/**
* 这个字段不加任何注解 也会保存到数据库中,也就是默认每一个属性都是有隐藏注解的@Basic
* 如果是驼峰形式会自动转换 createTime-->create_time
*
* @Temporal(TemporalType.DATE)
* @Temporal(TemporalType.TIME)
* @Temporal(TemporalType.TIMESTAMP)
*/
@Temporal(TemporalType.TIMESTAMP)
private Date createTime;
/**
* 这个字段我们是和数据库没有任何关系的就用这个注解
*/
@Transient
private String aaa;
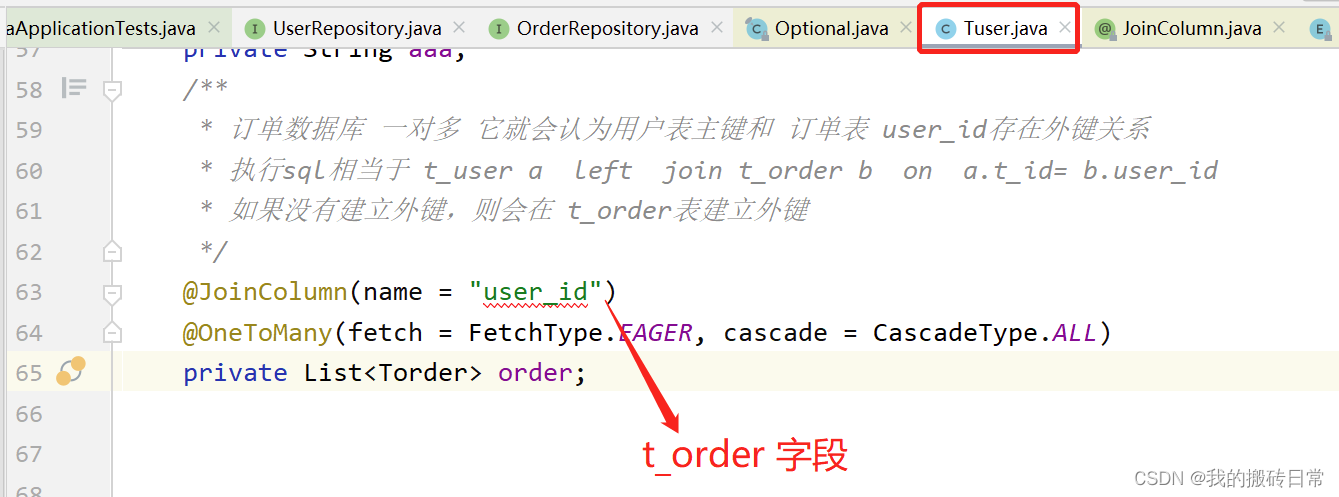
/**
* 订单数据库 一对多 它就会认为用户表主键和 订单表 user_id存在外键关系
* 执行sql相当于 t_user a left join t_order b on a.t_id= b.user_id
* 如果没有建立外键,则会在 t_order表建立外键
*/
@JoinColumn(name = "user_id")
@OneToMany(fetch = FetchType.EAGER, cascade = CascadeType.ALL)
private List<Torder> order;
}@Data
@ToString
@Entity
@Table(name = "t_order")
public class Torder implements Serializable {
@Id
@Column(name = "id")
/**
* 根据表方式自增
*/
@GeneratedValue
private Integer id;
@Column(name = "test_id")
private Integer testId;
@Column(name = "order_id")
private Integer orderId;
@Column(name = "user_id")
private Integer userId;
}/**
* Tuser 对应数据库表
* Long 主键类型
*/
public interface UserRepository extends JpaRepository<Tuser,Long> {
}4映射关系
总结: 1:软删除(不是真的删除 isdelete=0) 怎么映射出? 查询更新 都要加啊
2:需要额外执行一些多余sql影响效率
单向多对一,单向一对多,双向多对一,双向一对一,双向多对多
单向:就是只有一个配置了关系,(用户/订单 只有一个配置了关系)
双向:就是两个都配置关系(用户/订单 都配置了关系)
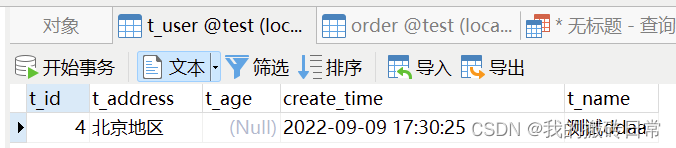
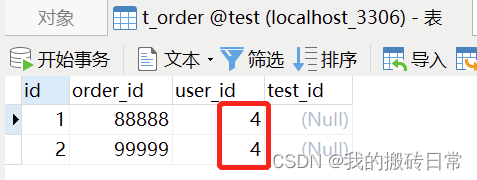
4.1 :一对多映射(一个用户多个订单)
如下方式保存:
1: 如果没有建立外键,则会在t_order表中建立外键
2:t_order表中会自动填写对应的外键数据
@Test
void test2() {
Tuser tuser = new Tuser();
tuser.setName("jpa");
Torder torder = new Torder();
torder.setOrderId(000);
List<Torder> torderList = new ArrayList<>();
torderList.add(torder);
tuser.setOrder(torderList);
userRepository.save(tuser);
}

分开保存方式则不会生成给外键添值
@Test
void test2() {
Tuser tuser = new Tuser();
tuser.setName("jpa");
Torder torder = new Torder();
torder.setOrderId(000);
userRepository.save(tuser);
orderRepository.save(torder);
} 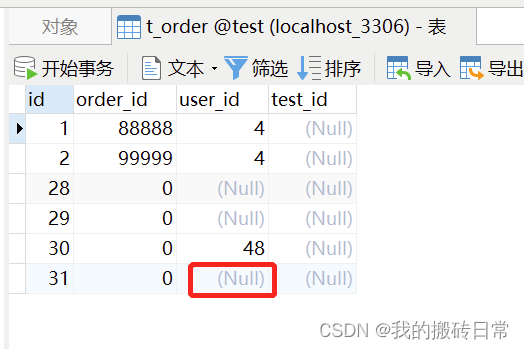
删除方式:
我只是删除了主表数据,但是从表中订单关联数据也没有了
cascade = CascadeType.ALL
详解每个属性
persist 保存时联级, merge 更新时联级, remove 删除时联级, refresh , detach
userRepository.deleteById(4L);
4.2 :多对一映射(一个订单多个用户)
配置多对一时: 只能有一个 user_id 字段映射,如下图,只能存留一个。
/* @Column(name = "user_id")
private Integer userId;*/
/**
* 使用注解的形式配置多对一关系
* 1.配置表关系
* @ManyToOne : 配置多对一关系
* targetEntity:对方的实体类字节码
* 2.配置外键(中间表)
* * 配置外键的过程,配置到了多的一方,就会在多的一方维护外键
*/
@ManyToOne(targetEntity = Tuser.class, fetch = FetchType.EAGER, cascade = CascadeType.ALL)
@JoinColumn(name = "user_id")
private Tuser tuser;4.3 多对多
总结:多对多只配置一个映射关系,。另一个引用即可
角色对用户:
/**
* 角色
*/
@Data
@Entity
@Table(name = "t_role")
public class Trole implements Serializable {
@Id
@Column(name = "t_role_id", length = 20)
@GeneratedValue
private Long id;
@Column(name = "t_role_name", length = 25)
private String name;
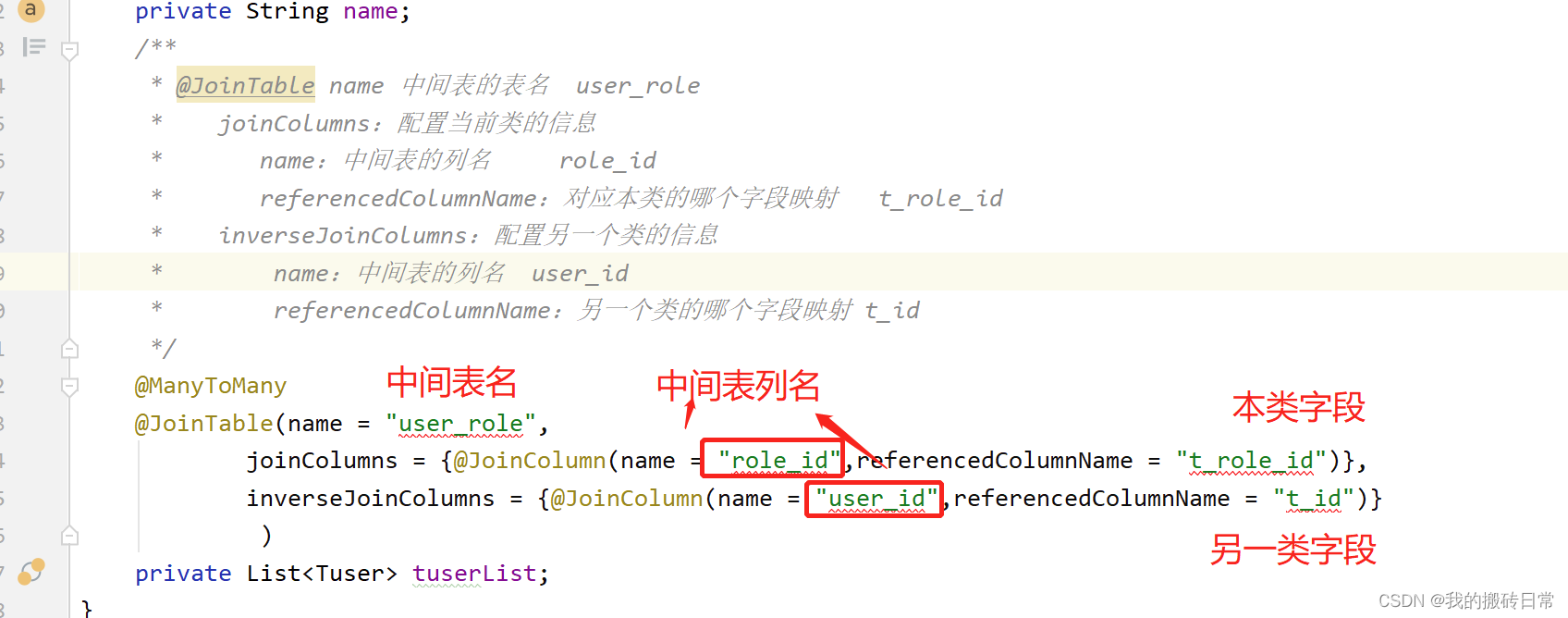
/**
* @JoinTable name 中间表的表名
* joinColumns:配置当前类的信息
* name:中间表的列名
* referencedColumnName:对应本类的哪个字段映射
* inverseJoinColumns:配置另一个类的信息
* name:中间表的列名
* referencedColumnName:另一个类的哪个字段映射
*/
@ManyToMany
@JoinTable(name = "user_role",
joinColumns = {@JoinColumn(name = "role_id",referencedColumnName = "t_role_id")},
inverseJoinColumns = {@JoinColumn(name = "user_id",referencedColumnName = "t_id")}
)
private List<Tuser> tuserList;
}
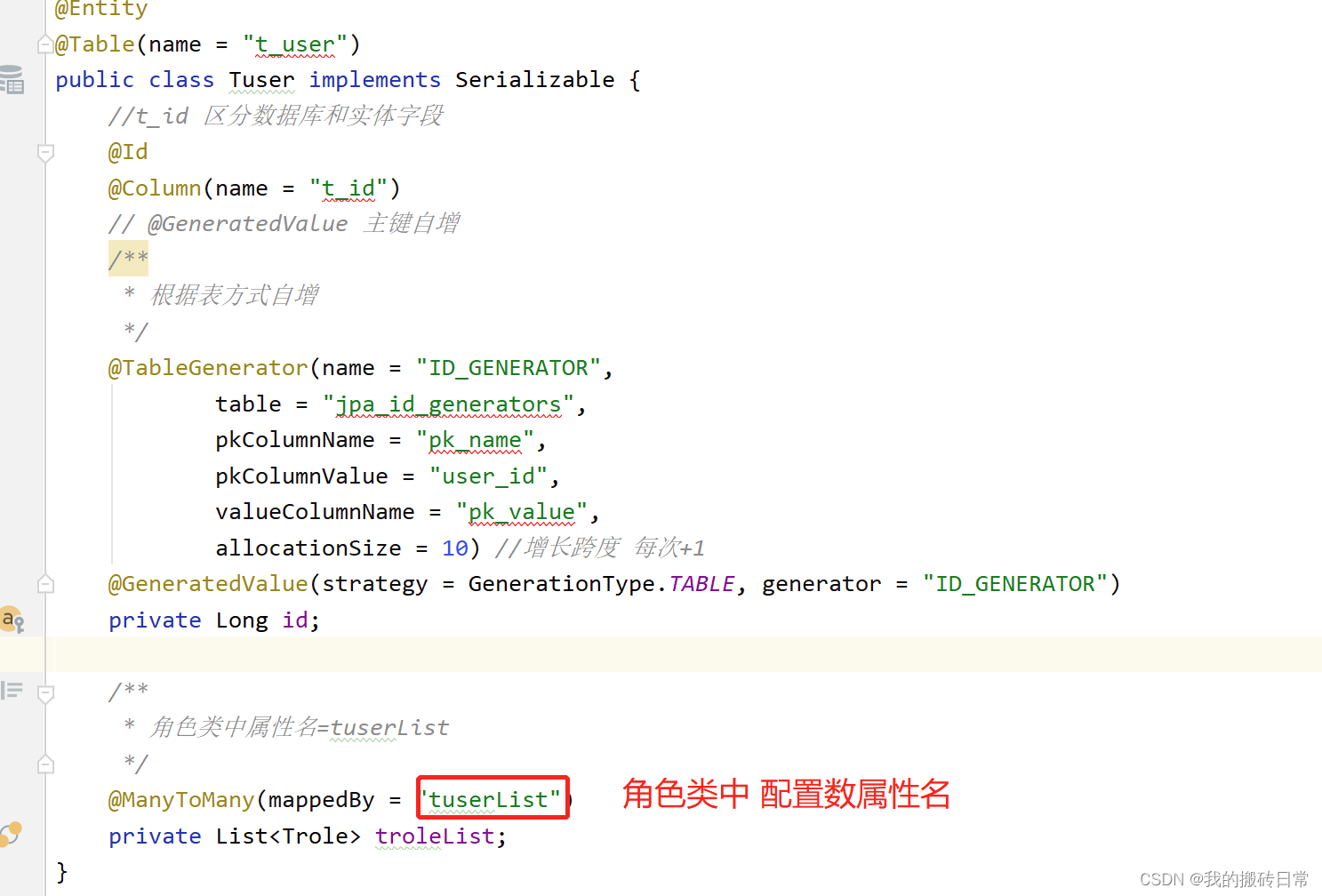
就这俩字段是不是太少了?时间呢?是否删除呢?
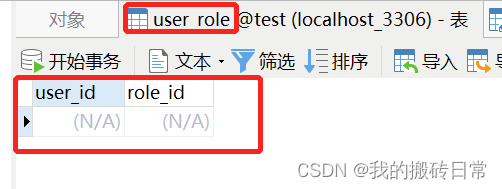
配置了映射关系的一方先保存,
@Test
void test3() {
List<Tuser> tuserList = new ArrayList<>();
List<Trole> troleList = new ArrayList<>();
Tuser tuser = new Tuser();
tuser.setName("学生");
Trole trole = new Trole();
trole.setName("低级权限");
tuserList.add(tuser);
troleList.add(trole);
trole.setTuserList(tuserList);
tuser.setTroleList(troleList);
userRepository.save(tuser);
roleRepository.save(trole);
}
5自定义sql
两种方式:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.transaction.annotation.Transactional;
/**
* Tuser 对应数据库表
* Long 主键类型
*/
public interface UserRepository extends JpaRepository<Tuser,Long> {
/**
* 方式一 写类名 和类中属性
* @param username
* @param id
* @return
*/
@Transactional
@Modifying
@Query("update Tuser a set a.name = ?1 where a.id = ?2")
int updateTuser1(String username, Long id);
/**
* 方式二 直接写sql
* nativeQuery true表示数据的sql 分页时就要用这种方式
* @return
*/
@Transactional
@Modifying
@Query(value="update t_user a set a.t_name = ?1 where a.t_id = ?2",nativeQuery=true)
int updateTuser2(String username, Long id);
/**
* 方式三 直接写sql
* nativeQuery true表示数据的sql 分页时就要用这种方式
* 有的版本可能 写法不同 :#{#tuser.name}/#{#tuser.name}
* @return
*/
@Transactional
@Modifying
@Query(value="update t_user set t_name =:#{#tuser.name} where t_id = :#{#tuser.id}",nativeQuery=true)
int updateTuser3(@Param("tuser") Tuser tuser);
}















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









