







🍅程序员小王的博客:程序员小王的博客
🍅 欢迎点赞 👍 收藏 ⭐留言 📝
🍅 如有编辑错误联系作者,如果有比较好的文章欢迎分享给我,我会取其精华去其糟粕
🍅java自学的学习路线:java自学的学习路线
一、Hadoop简介
1、什么的Hadoop
-
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
-
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
1、Hadoop解决哪些问题?
-
海量数据需要及时分析和处理
-
海量数据需要深入分析和挖掘
-
数据需要长期保存
2、海量数据存储的问题:
-
磁盘IO称为一种瓶颈,而非CPU资源
-
网络带宽是一种稀缺资源
-
硬件故障成为影响稳定的一大因素
二、Hadoop的安装
1、java8安装
-
Java 环境安装配置 /etc/profile:
export JAVA_HOME=/usr/jdk/jdk1.8.0_112
export JRE_HOME=/usr/jdk/jdk1.8.0_112/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
2、安装Hadoop2.7.3
(1)官网下载并且解压:
Index of /dist/hadoop/core/hadoop-2.7.3
tar xzvf hadoop-2.7.3.tar.gz
(2)修改 hadoop-env.sh指定java_home
-
路径:hadoop-2.7.3/etc/hadoop/ hadoop-env.sh
vim etc/hadoop/ hadoop-env.sh

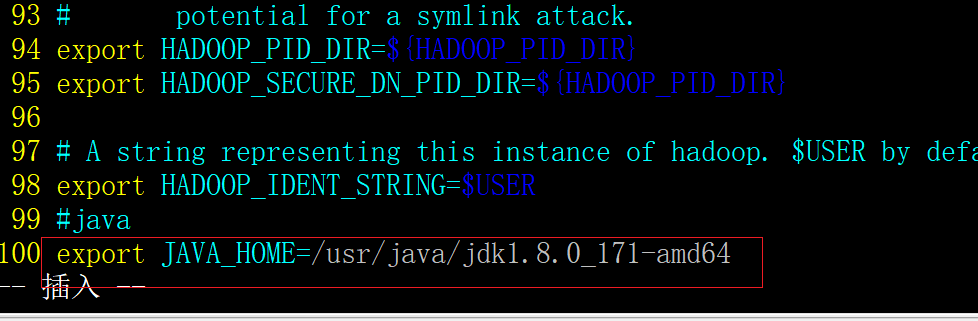
-
注意:此处一定要用路径,如果使用${JAVA_HOME},可能会找不到
(3)修改hdfs的配置文件
-
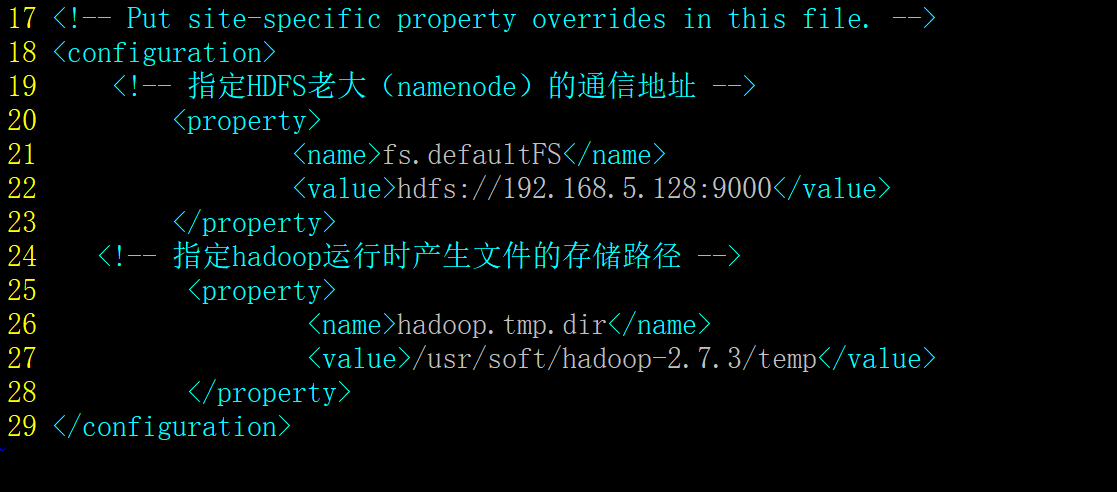
修改/usr/soft/hadoop-2.7.3/etc/hadoop/core-site.xml,如下:
vim /usr/soft/hadoop-2.7.3/etc/hadoop/core-site.xml
17 <!-- Put site-specific property overrides in this file. -->
18 <configuration>
19 <!-- 指定HDFS老大(namenode)的通信地址 -->
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://192.168.5.128:9000</value>
23 </property>
24 <!-- 指定hadoop运行时产生文件的存储路径 -->
25 <property>
26 <name>hadoop.tmp.dir</name>
27 <value>/usr/soft/hadoop-2.7.3/temp</value>
28 </property>
29 </configuration>
-
修改/usr/soft/hadoop-2.7.3/etc/hadoop/hdfs-site.xml,如下:
vim /usr/soft/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
19 <configuration>
20 <!--设置hdfs副本数量-->
21 <property>
22 <name>dfs.replication</name>
23 <value>1</value>
24 </property>
25 </configuration>

3、启动hadoop
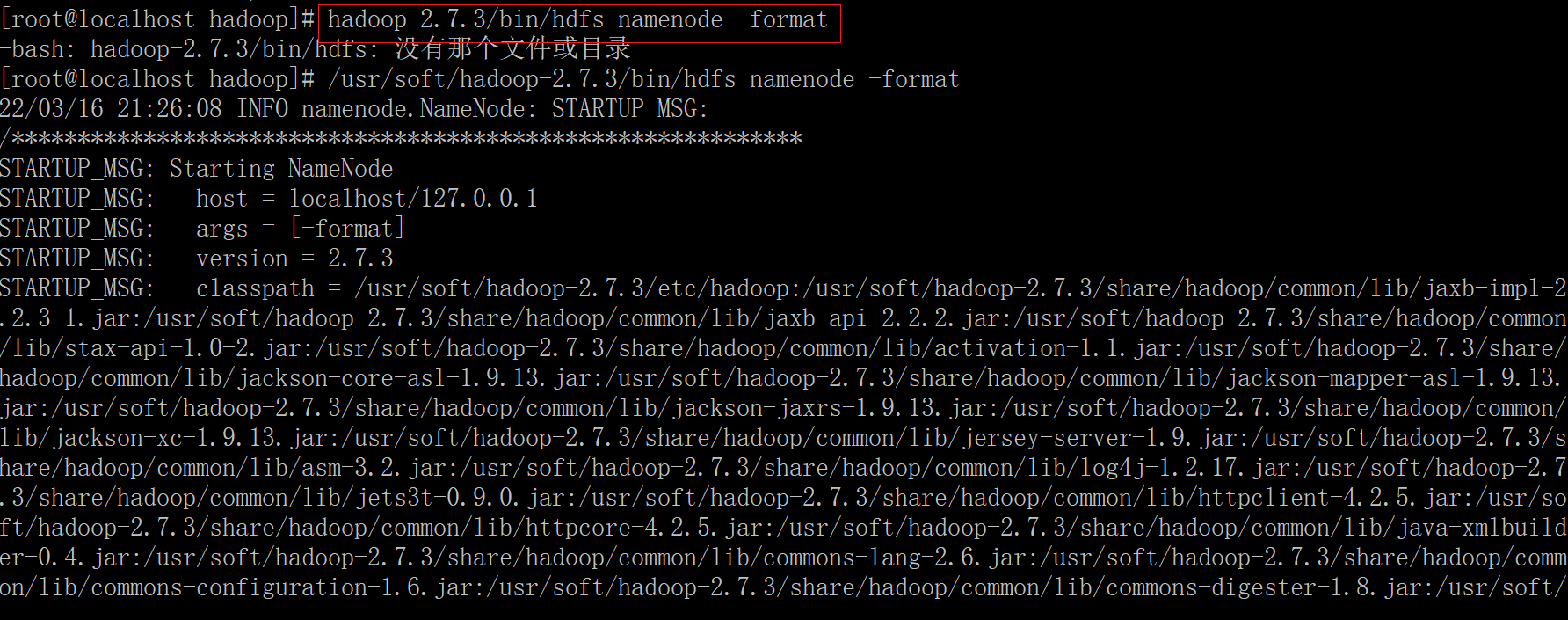
(1)第一次启动需要格式化
/usr/soft/hadoop-2.7.3/bin/hdfs namenode -format
(2)启动hdfs
/usr/soft/hadoop-2.7.3/sbin/start-dfs.sh

(3)输入jps查看:是否启动成功

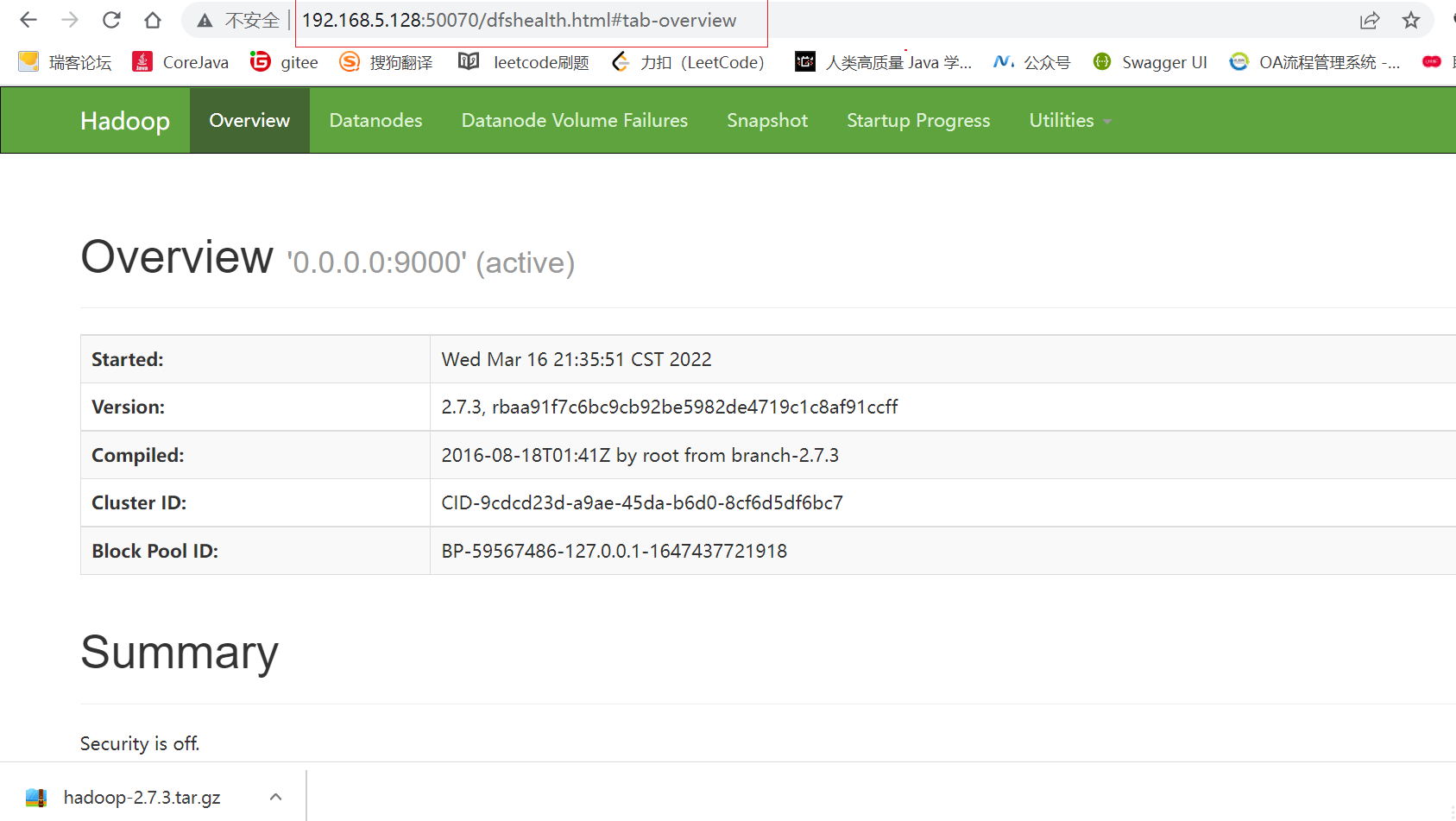
(4)预览地址:
-
linux先关闭防火墙:systemctl stop firewalld
4、关闭hadoop
/usr/soft/hadoop-2.7.3/sbin/stop-dfs.sh
















 3365
3365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











