1. 一些要知道的概念
- 在表连接过程中。一般选择小表作为驱动表,大表作为被驱动表。
- 驱动表(小表)的连接字段无论建立没建立索引都需要全表扫描的。被驱动表(大表)如果在连接字段建立了索引,则可以走索引。如果没有建立索引则也需要全表扫描。
1.2 两张表连接的情况
- 被驱动表的连接字段有索引:主键索引
- 对于驱动表中的每一条数据,到被驱动表的聚簇索引上寻找其对于的数据。
- 被驱动表的连接字段有索引:二级索引
- 对于驱动表上的每一条数据,到被驱动表的二次索引上寻找其对于的数据id,然后再根据数据id到聚簇索引上寻找对于的数据。
- 被驱动表的连接字段没有索引
- 对于驱动表上的每一条数据,都要到被驱动表上进行一次全表遍历,找到对应的数据。
1.3 join buffer的作用
- 就是针对被驱动表的连接字段没有索引的情况下需要进行全表扫描,所以引入了join buffer内存缓冲区来对这个全表扫描过程进行优化。
2. mysql中表关联的算法
2.0 前提
- 都是在被驱动表的连接字段没有索引的情况下mysql才会使用这些关联算法进行表连接。
2.1 嵌套循环连接 Nested-Loop Join(NLJ)
select * from t1 left join t2 on t1.name=t2.name;
- 会先从表t1里拿出第一条记录row1,完了再用row1遍历表t2里的每一条记录,来寻找是否name字段是否相等,以便输出。然后循环这个过程,直到t1表里的所有的记录都取出。
- 在整个过程中
- t1表遍历了1遍。t2表遍历了100*1遍。即每层t1表中取出1条记录,都要遍历一遍t2表。
- 因为这些文件都是在磁盘上的。想想在遍历t2表100遍过程中得有多少次IO操作呀。
- 整个过程跟我们平时写程序的双重for循环本质是一样的。但是我们程序写的双重for循环是基于内存得,而mysql中这些却是基于磁盘的,需要将文件从磁盘调用内存,这样双重for循环,内表需要反复调入内存。
- 假设将表t2。全部调入内存需要10次IO。即每次调入1000条记录。则在t2表的100次遍历过程中需要调用IO次数为 10*100=1000次IO。
2.2 块嵌套循环连接 Block Nested-Loop Join(BNLJ)
- 基于嵌套循环查询的问题,mysql进行了优化,采用块嵌套循环连接。
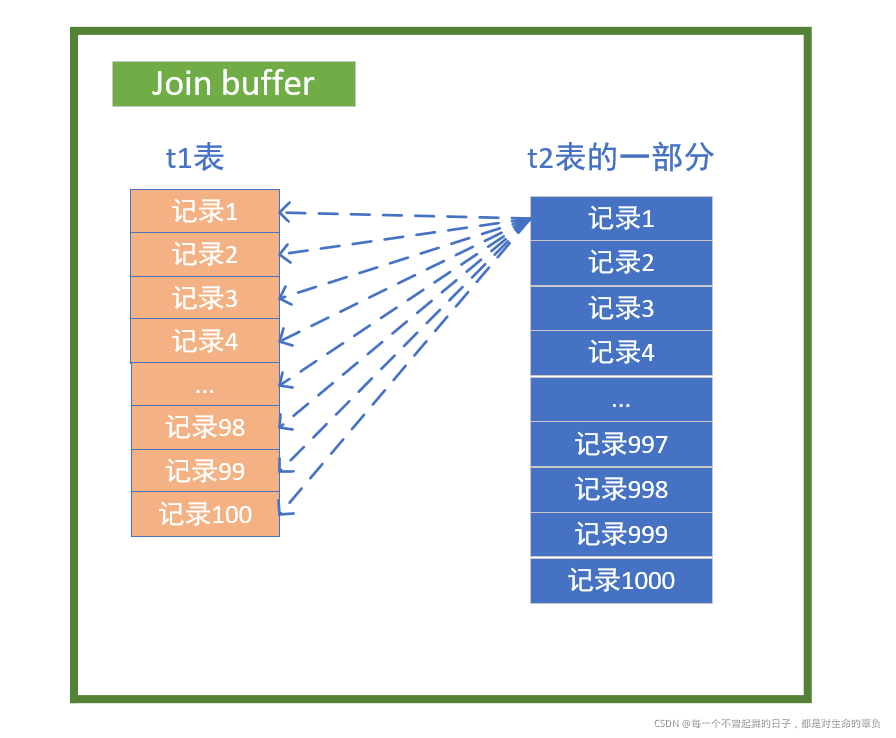
- 它多了一块内存缓冲区join buffer。
- 在这个过程中,不再是每次从t1表中取1条记录。而是在开始时用内存缓冲区join buffer将t1表全部装入内存,每次取t2表的1000条记录调入内存。然后,让t1表与t2表在内存的这一部分(t2表在内存的这一部分作为外层循环,t1表作为内层循环)通过双重for循环进行匹配,然后循环这个过程,直到t2表的10000条数据都调入内存一次(即需要十次IO调入)。
- 在整个过程中
- t1表遍历了1*10000遍,t2表遍历了1遍。再结合表的大小,其实匹配的总的次数是一样的。
- 但是变化的是IO次数。在整个过程中,t1表一开始调入内存,需要一次IO。而t2表也只是将表调入内存一次,需要10次IO。IO的次数是少了两个量级。
2.3 hash join算法
- 在mysql8.0中出现的新算法
- 也是用了join buffer来做内存缓存。
- 它在join buffer中以外表为基础建立了一张hash表。内表通过hash算法来跟hash表进行匹配。
- hash join其实利用上了hash索引,减少了内表的匹配次数。而且IO次数跟BNLJ差不多。

























 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









