






文章目录
简单概述
商业化的关系型数据库已经有30多年的历史了。其中一些比较成熟且流行的商业产品包括:
- Oracle公司的Oracle Database;
- Microsoft公司的SQL Server;
- IBM公司的DB2 Universal Database。
这些数据库服务器的功能都差不多,尽管其中有些长于处理海量或超大吞吐量的数据库,而有些更适合处理对象、大文件或XML文档等。所有这些服务器都很好地遵从了最新的ANSI SQL标准。这是一件好事,本书将展示如何编写无须进行任何修改(或仅需要极少量的修改)就能够在这些平台上运行的SQL语句。
除了商业数据库服务器,开源社区以创建出能够与之抗衡的竞品为目标,在过去的20年中也开展了大量的活动,其中最常用的两个开源数据库服务器是PostgreSQL和MySQL。MySQL是免费的,其下载和安装过程都非常简单。因此,本书的所有示例均在MySQL(8.0版)上运行,并使用命令行工具格式化查询结果。即使你已经使用了其他数据库服务器,而且根本不打算使用MySQL,我也强烈建议你安装最新版的MySQL服务器,加载样本模式和数据,用本书中的数据和示例进行实验。
然而,请牢记以下注意事项:
本书并不是一本关于MySQL如何实现SQL的书。
确切地说,本书旨在教授编写不加修改或稍作修改就能运行在MySQL以及Oracle Database、DB2、SQL Server新近版本上的SQL语句。
几个简单的sql例子
几个简单的增删改查sql例子
创建表
create table 表名
(列名 列类型,列名 列类型....
constraint 主键约束名 primary key 主键名)
例子
CREATE TABLE corporation
(corp_id SMALLINT,
name VARCHAR(30),
CONSTRAINT pk_corporation PRIMARY KEY (corp_id)
);
向表中插入数据
insert into 表名 (列名,列名....)
values (列值,列值...)
例子
INSERT INTO corporation (corp_id, name)
VALUES (27, 'Acme Paper Corporation');
查询表中的数据
select 列名,...
from 表名
where 条件语句
例子
SELECT name
FROM corporation
WHERE corp_id = 27;
+------------------------+
| name |
+------------------------+
| Acme Paper Corporation |
+------------------------+
多表查询 内联语句 inner join
多表查询用到了起别名的方式,让查询语句更清晰
select 表别名1.列名 .....
from 表名1 别名1
inner join 表名2 别名2 on 条件语句(别名1.列名 = 别名2.列名)
inner join 表名3 别名3 on 条件语句(别名3.列名 = 别名2.列名)
inner join 表名4 别名4 on 条件语句(别名4.列名 = 别名2.列名)
where 条件语句(别名1.列名 = 值 ) and 条件语句(别名1.列名 = 值)
and 条件语句(别名3.列名 = 值)
例子
SELECT t.txn_id, t.txn_type_cd, t.txn_date, t.amount
FROM individual i
INNER JOIN account a ON i.cust_id = a.cust_id
INNER JOIN product p ON p.product_cd = a.product_cd
INNER JOIN transaction t ON t.account_id = a.account_id
WHERE i.fname = 'George' AND i.lname = 'Blake'
AND p.name = 'checking account';
+--------+-------------+---------------------+--------+
| txn_id | txn_type_cd | txn_date | amount |
+--------+-------------+---------------------+--------+
| 11 | DBT | 2008-01-05 00:00:00 | 100.00 |
+--------+-------------+---------------------+--------+
1 row in set (0.00 sec)
sql中的注释
大多数SQL实现将位于“/”和“/”之间的文本视为注释
SELECT /* 一个或多个东西 */ ...
FROM /* 一处或多处 */ ...
WHERE /* 一个或多个条件 */ ...
修改表数据
update 表名
set 列名 = '修改的值'
where 条件语句
例子
UPDATE product
SET name = 'Certificate of Deposit'
WHERE product_cd = 'CD';
delete 语句忘记加where子句,会把整个数据表的行全部清空
2. 创建和填充数据库
2.1 使用命令行工具myql
2.1.1 登录数据库
mysql -u root -p 密码
2.1.2 查看所有可用的数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
+--------------------+
5 rows in set (0.01 sec)
2.1.3 使用指定的数据库
mysql> use sakila;
Database changed
启动命令行工具mysql的时候,可以同时指定要使用的用户名和数据库
mysql -u root -p sakila;
2.1.4 查询当前日期和时间
mysql> SELECT now();
+---------------------+
| now() |
+---------------------+
| 2019-04-04 20:44:26 |
+---------------------+
1 row in set (0.01 sec)
oracle中需要添加一个from子句,mysql中可加可不加
mysql> SELECT now()
FROM dual;
+---------------------+
| now() |
+---------------------+
| 2019-04-04 20:44:26 |
+---------------------+
1 row in set (0.01 sec)
2.1.5 退出
quit;
或
exit;
2.2 MySQL数据类型
2.2.1 字符型数据
在定义字符型的列时,必须指定该列所能存储字符串的最大长度。例如,如果希望存储最大长度为20个字符的字符串,可以使用下面的定义方式:
char(20) /* 定长 */
varchar(20) /* 变长 */`
char允许的最大长度为255字节,varchar最大长度则为65,535字节。如果需要存储更长的字符串(比如电子邮件、XML文档等),则要使用某种文本类型(mediumtex和longtext)。
2.2.2 字符集
查看数据库服务器所支持的字符集:
SHOW CHARACTER SET;
结果:
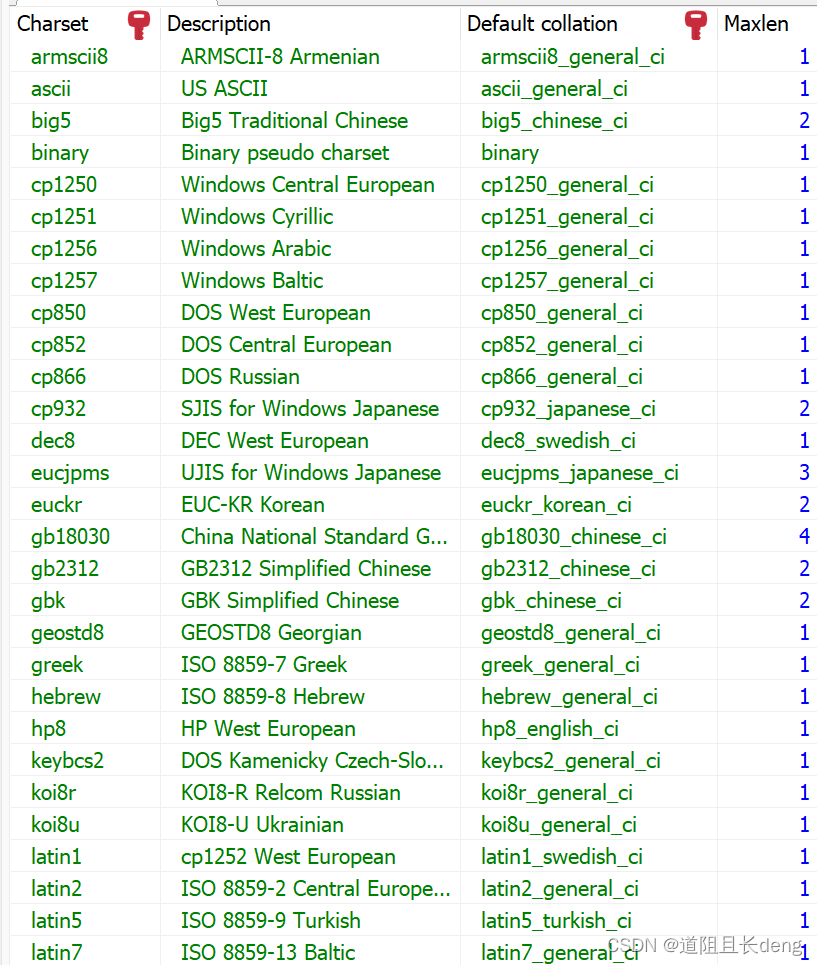
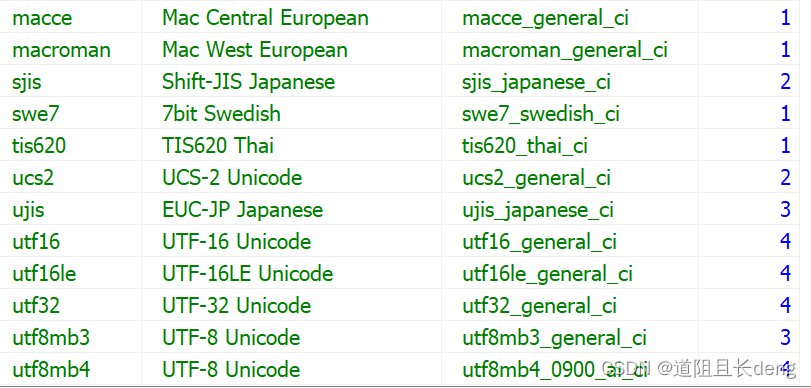
如果第4列maxlen的值大于1,则该字符集为多字节字符集。
在之前版本的MySQL服务器中,默认字符集是latin1,但在版本8中改为了utf8mb4。你可以为数据库中每个字符型的列选择不同的字符集,甚至可以在同一个数据表内存储不同的字符集数据。如果为数据列指定非默认字符集,只需要在类型定义后加上系统支持的字符集名称,例如:
varchar(20) character set latin1
在MySQL中,还可以设置整个数据库的默认字符集:
create database european_sales character set latin1;
2.2.3 文本数据
MySQL文本类型及其最大长度
| 文本类型 | 最大长度/字节 |
|---|---|
| tinytext | 255 |
| txt | 65535 |
| mediumtext | 16777215 |
| longtext | 4294 967 295 |
2.2.4 数值型数据
MySQL的整数类型
| 类型 | signed的取值范围 | unsigned的取值范围 |
|---|---|---|
| tinyint | -128~127 | 0-255 |
| smallint | -32768 ~ 32768 | 0 ~ 65535 |
| mediumint | -8388608 ~ 8388607 | 0 ~ 16777215 |
| int | -2147 483 648 ~ 2147 483 647 | 0 ~ 4294 967 295 |
| bigint | -2^63 ~ 2^63-1 | 0 ~ 2^64-1 |
MySQL的浮点数类型
| 类型 | 取值范围 |
|---|---|
| float(p,s) | -3.402823466E+38 ~ -1.175494351E-38 和1.175494351E-38 ~ 3.402823466E+38 |
| double(p,s) | -1.7976931348623157E+308~ -2.2250738585072014E-38和2.2250738585072014E-38~1.7976931348623157E+308 |
2.2.5 时间型数据
MySQL的时间数据类型
| 类型 | 默认格式 | 取值范围 |
|---|---|---|
| date | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| datetime | YYYY-MM-DD HH:mm:ss | 1000-01-01 00:00:00.000000~9999-12-31 23:59:59.999999 |
| timestamp | YYYY-MM-DD HH:mm:ss | 1970-01-01 00:00:00.000000~2038-01-18 22:14:07.999999 |
| year | YYYY | 1901~2155 |
| time | HHH:mm:ss | -838:59:59.000000 ~ 838:59:59.999999 |
每种数据库服务器所允许的时间类型列的日期范围各不相同。Oracle Datebase接受的日期范围是公元前4712年至公元9999年,SQL Server则只能处理公元1753年至公元9999年(除非使用SQL Server 2008的datetime2数据类型,其日期范围从公元1年至公元9999年)。MySQL位于Oracle和SQL Server之间,其时间范围是公元1000年至公元9999年。对于大多数跟踪当前和未来事件的系统来说,这并没有什么不同,但是如果存储的是历史日期,就需要注意了。
当行被添加到数据表或被修改时,MySQL服务器会自动为timestamp类型的列填充当前的日期/时间。
2.3 构建SQL模式语句
现在创建一个数据库表
CREATE TABLE person
(person_id SMALLINT UNSIGNED,
fname VARCHAR(20),
lname VARCHAR(20),
eye_color CHAR(2),
birth_date DATE,
street VARCHAR(30),
city VARCHAR(20),
state VARCHAR(20),
country VARCHAR(20),
postal_code VARCHAR(20),
CONSTRAINT pk_person PRIMARY KEY (person_id)
);
2.3.1 查看数据库中所有的表格
show tables;
2.3.2 数据表的约束类型
- 主键约束(primary key constraint)
- 外键约束(foreign key constraint)
- 检查约束(check)
MySQL允许在定义列时关联检查约束,如下所示:
eye_color CHAR(2) CHECK (eye_color IN ('BR','BL','GR')),
检查约束在大多数数据库服务器中都能够如所期望的那样工作,然而,MySQL虽然允许定义检查约束,但并不强制使用。实际上,MySQL提供了另一种名为enum的字符数据类型,将检查约束并入了数据类型定义:
eye_color ENUM('BR','BL','GR'),
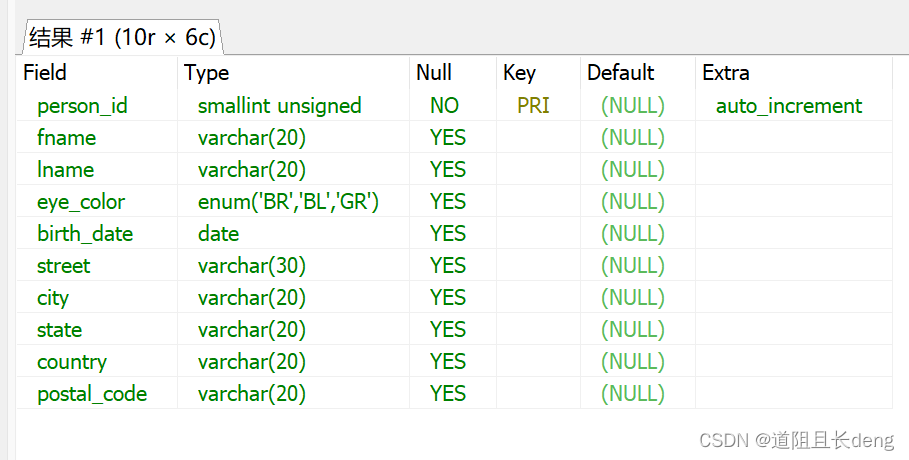
下面是person数据表的定义,其中包含数据类型为enum的eye_color列:
CREATE TABLE person
(person_id SMALLINT UNSIGNED,
fname VARCHAR(20),
lname VARCHAR(20),
eye_color ENUM('BR','BL','GR'),
birth_date DATE,
street VARCHAR(30),
city VARCHAR(20),
state VARCHAR(20),
country VARCHAR(20),
postal_code VARCHAR(20),
CONSTRAINT pk_person PRIMARY KEY (person_id)
);
2.3.3 查看表定义
使用 describe 或 desc简写,查看表定义。
describe person;
或
desc person;

2.3.4 设置是否允许null
在创建数据表时,可以指定哪些列允许为null(默认),哪些列不允许为null(在类型定义后添加关键字not null)
创建favorite_food数据表
CREATE TABLE favorite_food(
person_id SMALLINT UNSIGNED,
food VARCHAR(20),
CONSTRAINT pk_favorite_food PRIMARY KEY (person_id,food),
CONSTRAINT fk_fav_food_person_id FOREIGN KEY (person_id) REFERENCES person(person_id)
);
- 由于一个人可能有多种喜爱的食物(这也是创建本表的首要原因),仅靠person_id列不能保证数据的唯一性,因此本表的主键包含两列:person_id和food。
- favorite_food数据表包含了另一种约束,即外键约束(foreign key constraint),它限制了favorite_food数据表中person_id列的值只能够来自person数据表。通过这种约束,当person数据表中没有person_id为27的记录时,不可以向favorite_food数据表中添加person_id为27、喜爱食物为比萨饼的数据行。
如果一开始创建数据表的时候忘了设置外键约束,随后可以通过alter table语句添加。
2.4 填充和修改数据表
2.4.1 主键自增
在MySQL中,只需简单地为主键列启用自增(auto-increment)特性。通常来说,应该在创建数据表时就完成此项工作,不过这也给了我们一个机会来学习另一个SQL模式语句:alter table。该语句用于修改已有的数据表定义:
ALTER TABLE person MODIFY person_id SMALLINT UNSIGNED AUTO_INCREMENT;
2.4.2 insert语句
添加person表
INSERT INTO person(
fname,lname,eye_color,birth_date
)
VALUES('william','turner','br','1972-05-27');
INSERT INTO person(
fname,lname,eye_color,birth_date,street,city,state,country,postal_code
) VALUES('susan','smith','BL','1975-11-02','23 maple st.','arlington','VA','USA','20020')
添加食物表
INSERT INTO favorite_food(person_id,food) VALUES(1,'pizza');
INSERT INTO favorite_food(person_id,food) VALUES(1,'cookies');
INSERT INTO favorite_food(person_id,food) VALUES(1,'nochos');
检索william喜爱的食物,并使用order by子句将食物按字母顺序排序
SELECT food FROM favorite_food WHERE person_id=1 ORDER BY food;
可以获取xml格式的数据吗
对于MySQL,可以在调用mysql工具时使用–xml选项,所有查询的输出都会自动转换成XML格式。
C:\database> mysql -u lrngsql -p --xml bank
Enter password: xxxxxx
Welcome to the MySQL Monitor...
Mysql> SELECT * FROM favorite_food;
<?xml version="1.0"?>
<resultset statement="select * from favorite_food"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<field name="person_id">1</field>
<field name="food">cookies</field>
</row>
<row>
<field name="person_id">1</field>
<field name="food">nachos</field>
</row>
<row>
<field name="person_id">1</field>
<field name="food">pizza</field>
</row>
</resultset>
3 rows in set (0.00 sec)
对于SQL Server,则无须配置命令行工具,只需要在查询末尾添加for xml子句:
SELECT * FROM favorite_food FOR XML AUTO, ELEMENTS
2.4.3 更新数据
通过update语句填充相关的列
UPDATE person
SET street = '1225 tremont st.',
city = 'Boston',
state = 'MA',
country = 'USA',
postal_code = '0138'
WHERE person_id = 1
根据where子句中给出的条件,也可以使用单个语句修改多行。
WHERE person_id < 10
如果省略where子句,update语句会修改数据表中的每一行。
2.4.4 删除数据
DELETE FROM person WHERE person_id=2;
可以根据where子句中给出的条件删除多行,如果忽略where子句,则会删除所有行。
2.4.5 删除数据库表
DROP TABLE 表名
2.5 常见错误及响应
2.5.1 非唯一的主键
主键必须是唯一的,如果在数据库中插入重复的主键会报错,下列语句忽略了person_id列的自增特性,将person数据表中另一行的person_id值设为1:
mysql> INSERT INTO person
-> (person_id, fname, lname, eye_color, birth_date)
-> VALUES (1, 'Charles','Fulton', 'GR', '1968-01-15');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
2.5.2 不存在的外键
favorite_food数据表定义包括在person_id列上创建的外键约束。该约束确保favorite_food数据表中person_id列的所有值都来自person数据表。下面展示了如果在创建行时违反这一约束的结果:
mysql> INSERT INTO favorite_food (person_id, food)
-> VALUES (999, 'lasagna');
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraintfails ('sakila'.'favorite_food', CONSTRAINT 'fk_fav_food_person_id' FOREIGNKEY('person_id') REFERENCES 'person' ('person_id'))
仅当使用InnoDB存储引擎创建数据表时,外键约束才是强制的。我们会在第12章讨论MySQL的存储引擎。
2.5.3 列值违规
person数据表中的eye_color列将取值限制为’BR’(棕色)、‘BL’(蓝色)、‘GR’(绿色)。如果你试图错误地对该列设置其他值,会得到如下响应:
mysql> UPDATE person
-> SET eye_color = 'ZZ'
-> WHERE person_id = 1;
ERROR 1265 (01000): Data truncated for column 'eye_color' at row 1
2.5.4 无效的日期转换
如果用于填充日期类型列的字符串不符合要求的格式,会产生错误。下面的示例中使用的日期格式不符合默认的日期格式(YYYY-MM-DD):
mysql> UPDATE person
-> SET birth_date = 'DEC-21-1980'
-> WHERE person_id = 1;
ERROR 1292 (22007): Incorrect date value: 'DEC-21-1980' for column
'birth_date' at row 1
一般而言,最好是明确指定格式化字符串,而不是依赖默认格式。下列语句使用str_to_date函数指定了格式化字符串:
mysql> UPDATE person
-> SET birth_date = str_to_date('DEC-21-1980' , '%b-%d-%Y')
-> WHERE person_id = 1;
Query OK, 1 row affected (0.12 sec)
Rows matched: 1 Changed: 1 Warnings: 0
本章之前讨论各种各种时间数据类型时,展示过如“YYYY-MM-DD”这样的日期格式化字符串。尽管很多数据库服务器都采用这种格式化风格,但MySQL使用“%Y”来指定4位数字的年份。下面是一些在MySQL中将字符串转换为datetime类型时可能会用到的格式化字符:
%a 星期几的简写,比如Sun、Mon、…
%b 月份名称的简写,比如Jan、Feb、…
%c 月份的数字形式(0…12)
%d 月份中的天数(00…31)
%f 微秒数(000000…999999)
%H 24小时制中的小时(00…23)
%h 12小时制中的小时(01…12)
%i 小时中的分钟数(00…59)
%j 一年中的天数(001…366)
%M 月份的全称(January…December)
%m 月份的数值形式
%p AM或PM%s 秒数(00…59)
%W 星期几的全称(Sunday…Saturday)
%w 一星期中的天数(0=周日;6=周六)
%Y 4位数字表示的年份
2.6 Sakila数据库
后面的章节中用到的例子的表主要来自这个数据库。
3. 查询入门
3.1 查询子句
| 子句名称 | 作用 |
|---|---|
| select | 决定查询结果集中包含哪些列 |
| from | 指明从哪些数据表中检索数据以及数据表如何连接 |
| where | 过滤掉不需要的数据 |
| group by | 用于对具有相同列值的行进行分组 |
| having | 过滤掉不需要的分组 |
| order by | 根据一个或多个列对最终结果集中的行进行排序 |
3.2 select子句
select * from language;
*号表示表中的所有列都显示在结果集中。
除了通过星号字符指定所有的列,你也可以明确指定需要的列名:
mysql> SELECT language_id, name, last_update
-> FROM language;
因此,select子句的任务如下:
select子句决定哪些列应该包含在查询的结果集中。
如果只能包含from子句中指明的那些数据表中的列,未免太无趣了,可以加入下列内容,让select子句更丰富些。
- 字面量,比如数值或字符串。
- 表达式,比如transaction.amount * −1。
- 内建函数调用,比如ROUND(transaction.amount, 2)。
- 用户自定义函数调用。
接下来的查询演示了数据表列、字面量、表达式以及内建函数调用在针对language数据表的单个查询中的应用:
mysql> SELECT language_id,
-> 'COMMON' language_usage,
-> language_id * 3.1415927 lang_pi_value,
-> upper(name) language_name
-> FROM language;
+-------------+----------------+---------------+---------------+
| language_id | language_usage | lang_pi_value | language_name |
+-------------+----------------+---------------+---------------+
| 1 | COMMON | 3.1415927 | ENGLISH |
| 2 | COMMON | 6.2831854 | ITALIAN |
| 3 | COMMON | 9.4247781 | JAPANESE |
| 4 | COMMON | 12.5663708 | MANDARIN |
| 5 | COMMON | 15.7079635 | FRENCH |
| 6 | COMMON | 18.8495562 | GERMAN |
+-------------+----------------+---------------+---------------+
6 rows in set (0.04 sec)
内建函数的使用
mysql> SELECT version(),
-> user(),
-> database();
+-----------+----------------+------------+
| version() | user() | database() |
+-----------+----------------+------------+
| 8.0.15 | root@localhost | sakila |
+-----------+----------------+------------+
1 row in set (0.00 sec)
3.2.1 列的别名
select 列名 别名,列名 别名.... from 表名;
例子
mysql> SELECT language_id,
-> 'COMMON' language_usage,
-> language_id * 3.1415927 lang_pi_value,
-> upper(name) language_name
-> FROM language;
+-------------+----------------+---------------+---------------+
| language_id | language_usage | lang_pi_value | language_name |
+-------------+----------------+---------------+---------------+
| 1 | COMMON | 3.1415927 | ENGLISH |
| 2 | COMMON | 6.2831854 | ITALIAN |
| 3 | COMMON | 9.4247781 | JAPANESE |
| 4 | COMMON | 12.5663708 | MANDARIN |
| 5 | COMMON | 15.7079635 | FRENCH |
| 6 | COMMON | 18.8495562 | GERMAN |
+-------------+----------------+---------------+---------------+
6 rows in set (0.04 sec)
为了使列的别名更加清晰可见,也可以在别名前使用as关键字:
mysql> SELECT language_id,
-> 'COMMON' AS language_usage,
-> language_id * 3.1415927 AS lang_pi_value,
-> upper(name) AS language_name
-> FROM language;
3.2.2 移除重复数据
例子,检索出现在某部电影中的所有演员的ID,有些演员参演了不止一部电影,所以会多次看到相同的演员ID。
mysql> SELECT actor_id FROM film_actor ORDER BY actor_id;
+----------+
| actor_id |
+----------+
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
...
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
| 200 |
+----------+
5462 rows in set (0.01 sec)
通过在select后面直接添加关键字distinct来实现。
mysql> SELECT DISTINCT actor_id FROM film_actor ORDER BY actor_id;
+----------+
| actor_id |
+----------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
...
| 192 |
| 193 |
| 194 |
| 195 |
| 196 |
| 197 |
| 198 |
| 199 |
| 200 |
+----------+
200 rows in set (0.01 sec)
记住,生成一组不同的结果时需要对数据进行排序,这对于大型结果集会很耗时。不要陷入为了确保没有重复数据而使用distinct的陷阱,而应该花时间充分理解所处理的数据,以便了解是否可能出现重复数据。
3.3 from子句
- from子句定义了查询要用到的数据表以及连接数据表的方式。
- 该定义包含了两个独立且相关的概念,下面我们来逐一讲解。
3.3.1 数据表
宽泛定义的数据表有4种:
- 永久数据表(使用create table语句创建);
- 派生数据表(由子查询返回并保存在内存中的行);
- 临时数据表(保存在内存中的易失数据);
- 虚拟数据表(使用create view语句创建)。
1.派生(由子查询生成)数据表
子查询是包含在另一个查询中的查询。子查询由一对小括号包围,可以出现在select语句的各个部分中。在from子句中,子查询的作用在于生成其他所有查询子句中可见的派生数据表,以及与from子句中的其他数据表交互。下面来看一个简单的示例:
mysql> SELECT concat(cust.last_name, ', ', cust.first_name) full_name
-> FROM
-> (SELECT first_name, last_name, email
-> FROM customer
-> WHERE first_name = 'JESSIE'
-> ) cust;
+---------------+
| full_name |
+---------------+
| BANKS, JESSIE |
| MILAM, JESSIE |
+---------------+
2 rows in set (0.00 sec)
在本例中,customer数据表的子查询返回3列,外围查询(containing query)引用了其中的2列。子查询由外围查询通过其别名cust进行引用。cust的数据在查询期间保存在内存中,随后就被丢弃。这里在from子句中给出子查询很简单,也没太大的实用性,我们会在第9章详细讨论子查询。
- 临时数据表
关键字temporary
所有的关系型数据库都允许定义易失性(或临时)数据表。插入其中的任何数据都会在某个时候(通常在事务结束或数据库会话关闭时)消失。
mysql> CREATE TEMPORARY TABLE actors_j
-> (actor_id smallint(5),
-> first_name varchar(45),
-> last_name varchar(45)
-> );
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO actors_j
-> SELECT actor_id, first_name, last_name
-> FROM actor
-> WHERE last_name LIKE 'J%';
Query OK, 7 rows affected (0.03 sec)
Records: 7 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM actors_j;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 119 | WARREN | JACKMAN |
| 131 | JANE | JACKMAN |
| 8 | MATTHEW | JOHANSSON |
| 64 | RAY | JOHANSSON |
| 146 | ALBERT | JOHANSSON |
| 82 | WOODY | JOLIE |
| 43 | KIRK | JOVOVICH |
+----------+------------+-----------+
7 rows in set (0.00 sec)
3.视图
视图是存储在数据目录中的查询,其行为表现就像数据表,但是并没有与之关联的数据(这就是将其称为虚拟数据表的原因)。当查询视图时,该查询会与视图定义合并,以产生要执行的最终查询。
下面是一个查询employee数据表的视图定义,共包含4列:
mysql> CREATE VIEW cust_vw AS
-> SELECT customer_id, first_name, last_name, active
-> FROM customer;
Query OK, 0 rows affected (0.12 sec)
创建视图时,不会生成或存储额外的数据:服务器只是保留select语句,以备后用。有了视图,就可以向其发出查询了,如下所示:
mysql> SELECT first_name, last_name
-> FROM cust_vw
-> WHERE active = 0;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| SANDRA | MARTIN |
| JUDITH | COX |
| SHEILA | WELLS |
| ERICA | MATTHEWS |
| HEIDI | LARSON |
| PENNY | NEAL |
| KENNETH | GOODEN |
| HARRY | ARCE |
| NATHAN | RUNYON |
| THEODORE | CULP |
| MAURICE | CRAWLEY |
| BEN | EASTER |
| CHRISTIAN | JUNG |
| JIMMIE | EGGLESTON |
| TERRANCE | ROUSH |
+------------+-----------+
15 rows in set (0.00 sec)
创建视图的原因各种各样,包含对用户隐藏列、简化复杂的数据库设计。
3.3.2 数据表链接
一个简单的例子
mysql> SELECT customer.first_name, customer.last_name,
-> time(rental.rental_date) rental_time
-> FROM customer
-> INNER JOIN rental
-> ON customer.customer_id = rental.customer_id
-> WHERE date(rental.rental_date) = '2005-06-14';
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| JEFFERY | PINSON | 22:53:33 |
| ELMER | NOE | 22:55:13 |
| MINNIE | ROMERO | 23:00:34 |
| MIRIAM | MCKINNEY | 23:07:08 |
| DANIEL | CABRAL | 23:09:38 |
| TERRANCE | ROUSH | 23:12:46 |
| JOYCE | EDWARDS | 23:16:26 |
| GWENDOLYN | MAY | 23:16:27 |
| CATHERINE | CAMPBELL | 23:17:03 |
| MATTHEW | MAHAN | 23:25:58 |
| HERMAN | DEVORE | 23:35:09 |
| AMBER | DIXON | 23:42:56 |
| TERRENCE | GUNDERSON | 23:47:35 |
| SONIA | GREGORY | 23:50:11 |
| CHARLES | KOWALSKI | 23:54:34 |
| JEANETTE | GREENE | 23:54:46 |
+------------+-----------+-------------+
16 rows in set (0.01 sec)
3.3.3 定义数据表别名
在上个示例的查询中,在select和on子句中使用的是完整的数据表名称。下面还是相同的查询,只不过这次换用数据表别名:
SELECT c.first_name, c.last_name,
time(r.rental_date) rental_time
FROM customer c
INNER JOIN rental r
ON c.customer_id = r.customer_id
WHERE date(r.rental_date) = '2005-06-14';
另外,你也可以使用as关键字搭配数据表别名,类似于之前展示过的列别名:
SELECT c.first_name, c.last_name,
time(r.rental_date) rental_time
FROM customer AS c
INNER JOIN rental AS r
ON c.customer_id = r.customer_id
WHERE date(r.rental_date) = '2005-06-14';
3.4 where子句
where子句是一种机制,用于过滤掉结果集中不想要的行。
where子句中的条件运算符可以是:and, or和 not。
例子:
例子1:
mysql> SELECT title
-> FROM film
-> WHERE rating = 'G' AND rental_duration >= 7;
例子2:
mysql> SELECT title
-> FROM film
-> WHERE rating = 'G' OR rental_duration >= 7;
在where子句中同时使用运算符and和or
mysql> SELECT title, rating, rental_duration
-> FROM film
-> WHERE (rating = 'G' AND rental_duration >= 7)
-> OR (rating = 'PG-13' AND rental_duration < 4);
3.5 group by和having子句
mysql> SELECT c.first_name, c.last_name, count(*)
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> GROUP BY c.first_name, c.last_name
-> HAVING count(*) >= 40;
+------------+-----------+----------+
| first_name | last_name | count(*) |
+------------+-----------+----------+
| TAMMY | SANDERS | 41 |
| CLARA | SHAW | 42 |
| ELEANOR | HUNT | 46 |
| SUE | PETERS | 40 |
| MARCIA | DEAN | 42 |
| WESLEY | BULL | 40 |
| KARL | SEAL | 45 |
+------------+-----------+----------+
7 rows in set (0.03 sec)
3.6 order by子句
例子:
按姓氏的字母顺序排序,可以将last_name列加入order by子句中:
mysql> SELECT c.first_name, c.last_name,
-> time(r.rental_date) rental_time
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14'
-> ORDER BY c.last_name;
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| DANIEL | CABRAL | 23:09:38 |
| CATHERINE | CAMPBELL | 23:17:03 |
| HERMAN | DEVORE | 23:35:09 |
| AMBER | DIXON | 23:42:56 |
| JOYCE | EDWARDS | 23:16:26 |
| JEANETTE | GREENE | 23:54:46 |
| SONIA | GREGORY | 23:50:11 |
| TERRENCE | GUNDERSON | 23:47:35 |
| CHARLES | KOWALSKI | 23:54:34 |
| MATTHEW | MAHAN | 23:25:58 |
| GWENDOLYN | MAY | 23:16:27 |
| MIRIAM | MCKINNEY | 23:07:08 |
| ELMER | NOE | 22:55:13 |
| JEFFERY | PINSON | 22:53:33 |
| MINNIE | ROMERO | 23:00:34 |
| TERRANCE | ROUSH | 23:12:46 |
+------------+-----------+-------------+
16 rows in set (0.01 sec)
mysql> SELECT c.first_name, c.last_name,
-> time(r.rental_date) rental_time
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14'
-> ORDER BY c.last_name, c.first_name;
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| DANIEL | CABRAL | 23:09:38 |
| CATHERINE | CAMPBELL | 23:17:03 |
| HERMAN | DEVORE | 23:35:09 |
| AMBER | DIXON | 23:42:56 |
| JOYCE | EDWARDS | 23:16:26 |
| JEANETTE | GREENE | 23:54:46 |
| SONIA | GREGORY | 23:50:11 |
| TERRENCE | GUNDERSON | 23:47:35 |
| CHARLES | KOWALSKI | 23:54:34 |
| MATTHEW | MAHAN | 23:25:58 |
| GWENDOLYN | MAY | 23:16:27 |
| MIRIAM | MCKINNEY | 23:07:08 |
| ELMER | NOE | 22:55:13 |
| JEFFERY | PINSON | 22:53:33 |
| MINNIE | ROMERO | 23:00:34 |
| TERRANCE | ROUSH | 23:12:46 |
+------------+-----------+-------------+
16 rows in set (0.01 sec)
当包含多列时,列在order by子句中出现的顺序会有所不同。
3.6.1 升序排序和降序排序
在排序时,可以通过关键字asc和desc来指定升序排序或降序排序。默认为按照升序排序,如果希望按照降序排序,需要加入desc关键字。
例子:
mysql> SELECT c.first_name, c.last_name,
-> time(r.rental_date) rental_time
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14'
-> ORDER BY time(r.rental_date) desc;
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| JEANETTE | GREENE | 23:54:46 |
| CHARLES | KOWALSKI | 23:54:34 |
| SONIA | GREGORY | 23:50:11 |
| TERRENCE | GUNDERSON | 23:47:35 |
| AMBER | DIXON | 23:42:56 |
| HERMAN | DEVORE | 23:35:09 |
| MATTHEW | MAHAN | 23:25:58 |
| CATHERINE | CAMPBELL | 23:17:03 |
| GWENDOLYN | MAY | 23:16:27 |
| JOYCE | EDWARDS | 23:16:26 |
| TERRANCE | ROUSH | 23:12:46 |
| DANIEL | CABRAL | 23:09:38 |
| MIRIAM | MCKINNEY | 23:07:08 |
| MINNIE | ROMERO | 23:00:34 |
| ELMER | NOE | 22:55:13 |
| JEFFERY | PINSON | 22:53:33 |
+------------+-----------+-------------+
16 rows in set (0.01 sec)
MySQL提供了limit子句以允许对数据进行排序,然后只保留前X行。
3.6.2 通过数字占位符进行排序
如果需要根据select子句中的列进行排序,可以选择使用列在select子句中的位置来替代列名。
mysql> SELECT c.first_name, c.last_name,
-> time(r.rental_date) rental_time
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14'
-> ORDER BY 3 desc;
+------------+-----------+-------------+
| first_name | last_name | rental_time |
+------------+-----------+-------------+
| JEANETTE | GREENE | 23:54:46 |
| CHARLES | KOWALSKI | 23:54:34 |
| SONIA | GREGORY | 23:50:11 |
| TERRENCE | GUNDERSON | 23:47:35 |
| AMBER | DIXON | 23:42:56 |
| HERMAN | DEVORE | 23:35:09 |
| MATTHEW | MAHAN | 23:25:58 |
| CATHERINE | CAMPBELL | 23:17:03 |
| GWENDOLYN | MAY | 23:16:27 |
| JOYCE | EDWARDS | 23:16:26 |
| TERRANCE | ROUSH | 23:12:46 |
| DANIEL | CABRAL | 23:09:38 |
| MIRIAM | MCKINNEY | 23:07:08 |
| MINNIE | ROMERO | 23:00:34 |
| ELMER | NOE | 22:55:13 |
| JEFFERY | PINSON | 22:53:33 |
+------------+-----------+-------------+
16 rows in set (0.01 sec)
该特性应该适度使用,如果在select子句中添加了新列,而没有修改order by子句中的数字,则会导致不可预料的结果。
4. 过滤
4.1 条件评估
where子句可以包含一个或多个条件,条件之间以运算符and和or分隔。
例1:
WHERE first_name = 'STEVEN' AND create_date > '2006-01-01'
例2:
WHERE first_name = 'STEVEN' OR create_date > '2006-01-01'
4.1.1 使用括号
WHERE (first_name = 'STEVEN' OR last_name = 'YOUNG')
AND create_date > '2006-01-01'
4.1.2 使用not运算符
筛选名字不为Steven或姓名不为Young,且租借记录创建日期在2006年1月1日之后的人。
WHERE NOT (first_name = 'STEVEN' OR last_name = 'YOUNG')
AND create_date > '2006-01-01'
使用not有点让人难以理解,对于本例,你可以重写where子句,以避免使用not运算符:
WHERE first_name <> 'STEVEN' AND last_name <> 'YOUNG'
AND create_date > '2006-01-01'
4.2 构建条件
条件由一个或多个表达式并通过一个或多个运算符组合而成。表达式可以是:
- 数字;
- 数据表或视图中的列;
- 内建函数,比如concat(‘Learning’, ’ ', ‘SQL’);
- 子查询;
- 表达式列表,比如 (‘Boston’, ‘New York’, ‘Chicago’)。
可以在条件中使用的运算符包括:
- 比较运算符,比如=、!=、<、>、<>、like、in和between;
- 算术运算符,比如+、−、*和/。
4.3 条件类型
有许多种方式可以过滤掉不需要的数据。可以指定特定值、值的集合、需要包含或排除的值的范围,或是在处理字符串数据时,使用各种模式匹配技术来查找部分匹配。
4.3.1 相等条件
title = 'RIVER OUTLAW'
fed_id = '111-11-1111'
amount = 375.25
film_id = (SELECT film_id FROM film WHERE title = 'RIVER OUTLAW')
下列查询使用了两个相等条件,其中一个在on子句中(连接条件),另一个在where子句中(过滤条件):
mysql> SELECT c.email
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) = '2005-06-14';
- 不等条件
下面的查询将上一个示例中where子句的过滤条件改为不等条件:
mysql> SELECT c.email
-> FROM customer c
-> INNER JOIN rental r
-> ON c.customer_id = r.customer_id
-> WHERE date(r.rental_date) <> '2005-06-14';
- 使用相等条件修改数据
从rental数据表中删除租借日期为2004年的行。
DELETE FROM rental
WHERE year(rental_date) = 2004;
这个示例使用了两个不等条件来删除租借日期不在2005年或2006年的行:
DELETE FROM rental
WHERE year(rental_date) <> 2005 AND year(rental_date) <> 2006;
4.3.2 范围条件
检查表达式的值是否处于某个范围。这种条件类型通常用于数值型或时间型数据。
mysql> SELECT customer_id, rental_date
-> FROM rental
-> WHERE rental_date < '2005-05-25';
+-------------+---------------------+
| customer_id | rental_date |
+-------------+---------------------+
| 130 | 2005-05-24 22:53:30 |
| 459 | 2005-05-24 22:54:33 |
| 408 | 2005-05-24 23:03:39 |
| 333 | 2005-05-24 23:04:41 |
| 222 | 2005-05-24 23:05:21 |
| 549 | 2005-05-24 23:08:07 |
| 269 | 2005-05-24 23:11:53 |
| 239 | 2005-05-24 23:31:46 |
+-------------+---------------------+
8 rows in set (0.00 sec)
指定日期的上下限:
mysql> SELECT customer_id, rental_date
-> FROM rental
-> WHERE rental_date <= '2005-06-16'
-> AND rental_date >= '2005-06-14';
+-------------+---------------------+
| customer_id | rental_date |
+-------------+---------------------+
| 416 | 2005-06-14 22:53:33 |
| 516 | 2005-06-14 22:55:13 |
| 239 | 2005-06-14 23:00:34 |
| 285 | 2005-06-14 23:07:08 |
| 310 | 2005-06-14 23:09:38 |
| 592 | 2005-06-14 23:12:46 |
...
| 148 | 2005-06-15 23:20:26 |
| 237 | 2005-06-15 23:36:37 |
| 155 | 2005-06-15 23:55:27 |
| 341 | 2005-06-15 23:57:20 |
| 149 | 2005-06-15 23:58:53 |
+-------------+---------------------+
364 rows in set (0.00 sec)
1.between运算符
当需要同时限制范围的上限和下限时,可以选择使用between运算符构建单个查询条件,而不用两个单独的条件:
mysql> SELECT customer_id, rental_date
-> FROM rental
-> WHERE rental_date BETWEEN '2005-06-14' AND '2005-06-16';
+-------------+---------------------+
| customer_id | rental_date |
+-------------+---------------------+
| 416 | 2005-06-14 22:53:33 |
| 516 | 2005-06-14 22:55:13 |
| 239 | 2005-06-14 23:00:34 |
| 285 | 2005-06-14 23:07:08 |
| 310 | 2005-06-14 23:09:38 |
| 592 | 2005-06-14 23:12:46 |
...
| 148 | 2005-06-15 23:20:26 |
| 237 | 2005-06-15 23:36:37 |
| 155 | 2005-06-15 23:55:27 |
| 341 | 2005-06-15 23:57:20 |
| 149 | 2005-06-15 23:58:53 |
+-------------+---------------------+
364 rows in set (0.00 sec)
由于没有指定日期的时间部分,时间默认为到午夜零点,所以有效范围是2005-06-14 00:00:00到 2005-06-16 00:00:00
除了日期,还可以构建条件以指定数值范围。数值范围很容易掌握,如下所示:
mysql> SELECT customer_id, payment_date, amount
-> FROM payment
-> WHERE amount BETWEEN 10.0 AND 11.99;
+-------------+---------------------+--------+
| customer_id | payment_date | amount |
+-------------+---------------------+--------+
| 2 | 2005-07-30 13:47:43 | 10.99 |
| 3 | 2005-07-27 20:23:12 | 10.99 |
| 12 | 2005-08-01 06:50:26 | 10.99 |
| 13 | 2005-07-29 22:37:41 | 11.99 |
| 21 | 2005-06-21 01:04:35 | 10.99 |
| 29 | 2005-07-09 21:55:19 | 10.99 |
...
| 571 | 2005-06-20 08:15:27 | 10.99 |
| 572 | 2005-06-17 04:05:12 | 10.99 |
| 573 | 2005-07-31 12:14:19 | 10.99 |
| 591 | 2005-07-07 20:45:51 | 11.99 |
| 592 | 2005-07-06 22:58:31 | 11.99 |
| 595 | 2005-07-31 11:51:46 | 10.99 |
+-------------+---------------------+--------+
114 rows in set (0.01 sec)
2.字符串范围
下列查询返回姓氏介于FA和FR之间的客户:
mysql> SELECT last_name, first_name
-> FROM customer
-> WHERE last_name BETWEEN 'FA' AND 'FR';
+------------+------------+
| last_name | first_name |
+------------+------------+
| FARNSWORTH | JOHN |
| FENNELL | ALEXANDER |
| FERGUSON | BERTHA |
| FERNANDEZ | MELINDA |
| FIELDS | VICKI |
| FISHER | CINDY |
| FLEMING | MYRTLE |
| FLETCHER | MAE |
| FLORES | JULIA |
| FORD | CRYSTAL |
| FORMAN | MICHEAL |
| FORSYTHE | ENRIQUE |
| FORTIER | RAUL |
| FORTNER | HOWARD |
| FOSTER | PHYLLIS |
| FOUST | JACK |
| FOWLER | JO |
| FOX | HOLLY |
+------------+------------+
18 rows in set (0.00 sec)
在处理字符串范围时,需要知道所使用的字符集中各字符的顺序[字符在某个字符集内的排序顺序被称为排序规则(collation)]。
4.3.3 成员条件
值的有限集合。
mysql> SELECT title, rating
-> FROM film
-> WHERE rating = 'G' OR rating = 'PG';
尽管这里的where子句(包含两个条件)并不繁杂,但想象一下如果包含10个或20个条件会怎样。对此,可以使用in运算符代替:
SELECT title, rating
FROM film
WHERE rating IN ('G','PG');
有了in运算符,无论集合中含有多少个表达式,只需编写一个条件。
1.使用子查询
mysql> SELECT title, rating
-> FROM film
-> WHERE rating IN (SELECT rating FROM film WHERE title LIKE '%PET%');
2.使用not in运算符
SELECT title, rating
FROM film
WHERE rating NOT IN ('PG-13','R', 'NC-17');
该查询搜索所有评级不为’PG-13’、‘R’、'NC-17’的电影,返回结果和前一个查询的结果一样。
4.3.4 匹配条件
要想查找姓氏以Q开头的所有客户,可以使用内建函数抽取last_name列的第一个字母,如下所示:
mysql> SELECT last_name, first_name
-> FROM customer
-> WHERE left(last_name, 1) = 'Q';
+-------------+------------+
| last_name | first_name |
+-------------+------------+
| QUALLS | STEPHEN |
| QUINTANILLA | ROGER |
| QUIGLEY | TROY |
+-------------+------------+
3 rows in set (0.00 sec)
尽管内建函数left()也能完成任务,但在灵活性上有所欠缺。取而代之的是可以使用通配符来构建搜索表达式。
1.使用通配符
| 通配符 | 匹配 |
|---|---|
- | 单个字符 |
% | 任意数量的字符(包括0个) |
例子:
mysql> SELECT last_name, first_name
-> FROM customer
-> WHERE last_name LIKE '_A_T%S';
+-----------+------------+
| last_name | first_name |
+-----------+------------+
| MATTHEWS | ERICA |
| WALTERS | CASSANDRA |
| WATTS | SHELLY |
+-----------+------------+
3 rows in set (0.00 sec)
上例中的搜索表达式指定了这样的字符串:第2个字符为A,第4个字符为T,接下来是任意多个字符,最终以S结尾。
通配符适合于构建简单的搜索表达式。如果需要匹配更复杂的字符串,可以使用多个搜索表达式,如下所示:
mysql> SELECT last_name, first_name
-> FROM customer
-> WHERE last_name LIKE 'Q%' OR last_name LIKE 'Y%';
+-------------+------------+
| last_name | first_name |
+-------------+------------+
| QUALLS | STEPHEN |
| QUIGLEY | TROY |
| QUINTANILLA | ROGER |
| YANEZ | LUIS |
| YEE | MARVIN |
| YOUNG | CYNTHIA |
+-------------+------------+
6 rows in set (0.00 sec)
2.使用正则表达式
下面使用正则表达式的MySQL实现来重写上一个查询(搜索姓氏以Q或Y开头的所有客户):
mysql> SELECT last_name, first_name
-> FROM customer
-> WHERE last_name REGEXP '^[QY]';
+-------------+------------+
| last_name | first_name |
+-------------+------------+
| YOUNG | CYNTHIA |
| QUALLS | STEPHEN |
| QUINTANILLA | ROGER |
| YANEZ | LUIS |
| YEE | MARVIN |
| QUIGLEY | TROY |
+-------------+------------+
6 rows in set (0.16 sec)
Oracle Database和Microsoft SQL Server同样支持正则表达式。在Oracle Database中,使用regexp_like函数代替regexp运算符,而SQL Server允许正则表达式与like运算符配合使用。
4.4 null:4个字母的单词
在使用null时,应该记住:
- 表达式可以为null,但不能等于(never equal)null;
- 两个null值不相等。
为了测试表达式是否为null,需要使用is null运算符,如下所示:
mysql> SELECT rental_id, customer_id
-> FROM rental
-> WHERE return_date IS NULL;
+-----------+-------------+
| rental_id | customer_id |
+-----------+-------------+
| 11496 | 155 |
| 11541 | 335 |
| 11563 | 83 |
| 11577 | 219 |
| 11593 | 99 |
...
| 15867 | 505 |
| 15875 | 41 |
| 15894 | 168 |
| 15966 | 374 |
+-----------+-------------+
183 rows in set (0.01 sec)
注意:使用
=null是错误的,查询不到任何值,数据库服务器也不会提醒你有错。
如果要查看某列是否已经被赋值,可以使用is not null运算符,如下所示:
mysql> SELECT rental_id, customer_id, return_date
-> FROM rental
-> WHERE return_date IS NOT NULL;
+-----------+-------------+---------------------+
| rental_id | customer_id | return_date |
+-----------+-------------+---------------------+
| 1 | 130 | 2005-05-26 22:04:30 |
| 2 | 459 | 2005-05-28 19:40:33 |
| 3 | 408 | 2005-06-01 22:12:39 |
| 4 | 333 | 2005-06-03 01:43:41 |
| 5 | 222 | 2005-06-02 04:33:21 |
| 6 | 549 | 2005-05-27 01:32:07 |
| 7 | 269 | 2005-05-29 20:34:53 |
...
| 16043 | 526 | 2005-08-31 03:09:03 |
| 16044 | 468 | 2005-08-25 04:08:39 |
| 16045 | 14 | 2005-08-25 23:54:26 |
| 16046 | 74 | 2005-08-27 18:02:47 |
| 16047 | 114 | 2005-08-25 02:48:48 |
| 16048 | 103 | 2005-08-31 21:33:07 |
| 16049 | 393 | 2005-08-30 01:01:12 |
+-----------+-------------+---------------------+
15861 rows in set (0.02 sec)
5. 多数据表查询
5.1.1 笛卡儿积
在没有任何限制条件的情况下,两表连接必然会形成笛卡尔积。
例子:查询检索客户的姓氏和名字,以及居住的街道地址
mysql> SELECT c.first_name, c.last_name, a.address
-> FROM customer c JOIN address a;
5.1.2 内连接
要解决上述笛卡尔积的问题,需要在on子句中限制连接条件
mysql> SELECT c.first_name, c.last_name, a.address
-> FROM customer c JOIN address a
-> ON c.address_id = a.address_id;
如果一个数据表中的address_id列的值在另一个数据表中不存在,则包含该值的行连接失败,相应行不会出现在结果集中。这就是内连接,也是最常用的连接。如果要将一个数据表中的所有行全部纳入结果集,不管其在另一个数据表中是否存在匹配,则需要指定外连接(outer join)
上面的例子中,并没有在from子句中指定所使用的连接类型。但是,如果要对两个数据表使用内连接,最好在from子句中明确指定连接类型。下面的示例提供同样的查询,只不过增加了连接类型(注意关键字inner):
SELECT c.first_name, c.last_name, a.address
FROM customer c INNER JOIN address a
ON c.address_id = a.address_id;
如果没有指定连接类型,那么服务器会默认使用内连接
如果用于连接两个数据表的列名相同(上一个示例就属于这种情况),则可以使用using子句替代on子句,如下所示:
SELECT c.first_name, c.last_name, a.address
FROM customer c INNER JOIN address a
USING (address_id);
5.1.3 ANSI连接语法
本书使用的数据表连接语法是在ANSI SQL标准的SQL92版本中引入的。所有的主流数据库(Oracle Database、Microsoft SQL Server、MySQL、IBM DB2Universal Database、Sybase Adaptive Server)也都采用了SQL92连接语法。
旧的sql查询:
mysql> SELECT c.first_name, c.last_name, a.address
-> FROM customer c, address a
-> WHERE c.address_id = a.address_id;
+------------+------------+------------------------------------+
| first_name | last_name | address |
+------------+------------+------------------------------------+
| MARY | SMITH | 1913 Hanoi Way |
| PATRICIA | JOHNSON | 1121 Loja Avenue |
| LINDA | WILLIAMS | 692 Joliet Street |
| BARBARA | JONES | 1566 Inegl Manor |
| ELIZABETH | BROWN | 53 Idfu Parkway |
| JENNIFER | DAVIS | 1795 Santiago de Compostela Way |
| MARIA | MILLER | 900 Santiago de Compostela Parkway |
| SUSAN | WILSON | 478 Joliet Way |
| MARGARET | MOORE | 613 Korolev Drive |
...
| TERRANCE | ROUSH | 42 Fontana Avenue |
| RENE | MCALISTER | 1895 Zhezqazghan Drive |
| EDUARDO | HIATT | 1837 Kaduna Parkway |
| TERRENCE | GUNDERSON | 844 Bucuresti Place |
| ENRIQUE | FORSYTHE | 1101 Bucuresti Boulevard |
| FREDDIE | DUGGAN | 1103 Quilmes Boulevard |
| WADE | DELVALLE | 1331 Usak Boulevard |
| AUSTIN | CINTRON | 1325 Fukuyama Street |
+------------+------------+------------------------------------+
599 rows in set (0.00 sec)
旧的sql查询:
mysql> SELECT c.first_name, c.last_name, a.address
-> FROM customer c, address a
-> WHERE c.address_id = a.address_id
-> AND a.postal_code = 52137;
+------------+-----------+------------------------+
| first_name | last_name | address |
+------------+-----------+------------------------+
| JAMES | GANNON | 1635 Kuwana Boulevard |
| FREDDIE | DUGGAN | 1103 Quilmes Boulevard |
+------------+-----------+------------------------+
2 rows in set (0.01 sec)
使用了SQL92连接语法的实现与上面相同的查询:
mysql> SELECT c.first_name, c.last_name, a.address
-> FROM customer c INNER JOIN address a
-> ON c.address_id = a.address_id
-> WHERE a.postal_code = 52137;
+------------+-----------+------------------------+
| first_name | last_name | address |
+------------+-----------+------------------------+
| JAMES | GANNON | 1635 Kuwana Boulevard |
| FREDDIE | DUGGAN | 1103 Quilmes Boulevard |
+------------+-----------+------------------------+
2 rows in set (0.01 sec)
但ANSI连接语法具有以下优点
- 连接条件和过滤条件被分隔在两个不同的子句中(on子句和where子句),使得查询语句更易于理解;
- 两个数据表的连接条件出现在其各自单独的on子句中,这样就不太可能错误地忽略连接条件;
- 使用SQL92连接语法的查询语句可以在各种数据库服务器间移植,而旧语法在不同服务器上的表现略有不同。
旧的语法的缺点
乍一看,不太容易判断where子句中哪个是连接条件,哪个是过滤条件。使用哪种类型的连接也不是很明显(要识别连接类型,需要仔细观察where子句中的连接条件,看看是否使用了任何特殊字符)
5.2 连接3个或以上的数据表
mysql> SELECT c.first_name, c.last_name, ct.city
-> FROM customer c
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id;
+-------------+--------------+----------------------------+
| first_name | last_name | city |
+-------------+--------------+----------------------------+
| JULIE | SANCHEZ | A Corua (La Corua) |
| PEGGY | MYERS | Abha |
| TOM | MILNER | Abu Dhabi |
| GLEN | TALBERT | Acua |
| LARRY | THRASHER | Adana |
| SEAN | DOUGLASS | Addis Abeba |
...
| MICHELE | GRANT | Yuncheng |
| GARY | COY | Yuzhou |
| PHYLLIS | FOSTER | Zalantun |
| CHARLENE | ALVAREZ | Zanzibar |
| FRANKLIN | TROUTMAN | Zaoyang |
| FLOYD | GANDY | Zapopan |
| CONSTANCE | REID | Zaria |
| JACK | FOUST | Zeleznogorsk |
| BYRON | BOX | Zhezqazghan |
| GUY | BROWNLEE | Zhoushan |
| RONNIE | RICKETTS | Ziguinchor |
+-------------+--------------+----------------------------+
599 rows in set (0.03 sec)
你认为查询语句中的数据表应该始终以特定的顺序连接,可以将数据表按照需要的顺序排列,然后在MySQL中指定straight_join关键字,例如,要想告知MySQL服务器使用city数据表作为驱动表,然后连接数据表address和customer,可以执行下列查询:
SELECT STRAIGHT_JOIN c.first_name, c.last_name, ct.city
FROM city ct
INNER JOIN address a
ON a.city_id = ct.city_id
INNER JOIN customer c
ON c.address_id = a.address_id
5.2.1 使用子查询作为数据表
mysql> SELECT c.first_name, c.last_name, addr.address, addr.city
-> FROM customer c
-> INNER JOIN
-> (SELECT a.address_id, a.address, ct.city
-> FROM address a
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id
-> WHERE a.district = 'California'
-> ) addr
-> ON c.address_id = addr.address_id;
+------------+-----------+------------------------+----------------+
| first_name | last_name | address | city |
+------------+-----------+------------------------+----------------+
| PATRICIA | JOHNSON | 1121 Loja Avenue | San Bernardino |
| BETTY | WHITE | 770 Bydgoszcz Avenue | Citrus Heights |
| ALICE | STEWART | 1135 Izumisano Parkway | Fontana |
| ROSA | REYNOLDS | 793 Cam Ranh Avenue | Lancaster |
| RENEE | LANE | 533 al-Ayn Boulevard | Compton |
| KRISTIN | JOHNSTON | 226 Brest Manor | Sunnyvale |
| CASSANDRA | WALTERS | 920 Kumbakonam Loop | Salinas |
| JACOB | LANCE | 1866 al-Qatif Avenue | El Monte |
| RENE | MCALISTER | 1895 Zhezqazghan Drive | Garden Grove |
+------------+-----------+------------------------+----------------+
9 rows in set (0.00 sec)
5.2.2 使用同一数据表两次
查询两个演员共同参演的电眼
mysql> SELECT f.title
-> FROM film f
-> INNER JOIN film_actor fa1
-> ON f.film_id = fa1.film_id
-> INNER JOIN actor a1
-> ON fa1.actor_id = a1.actor_id
-> INNER JOIN film_actor fa2
-> ON f.film_id = fa2.film_id
-> INNER JOIN actor a2
-> ON fa2.actor_id = a2.actor_id
-> WHERE (a1.first_name = 'CATE' AND a1.last_name = 'MCQUEEN')
-> AND (a2.first_name = 'CUBA' AND a2.last_name = 'BIRCH');
+------------------+
| title |
+------------------+
| BLOOD ARGONAUTS |
| TOWERS HURRICANE |
+------------------+
2 rows in set (0.00 sec)
5.3 自连接
不仅可以在同一查询中多次包含相同的数据表,还可以将数据表与其自身连接。
mysql> SELECT f.title, f_prnt.title prequel
-> FROM film f
-> INNER JOIN film f_prnt
-> ON f_prnt.film_id = f.prequel_film_id
-> WHERE f.prequel_film_id IS NOT NULL;
+-----------------+--------------+
| title | prequel |
+-----------------+--------------+
| FIDDLER LOST II | FIDDLER LOST |
+-----------------+--------------+
1 row in set (0.00 sec)
6.使用集合
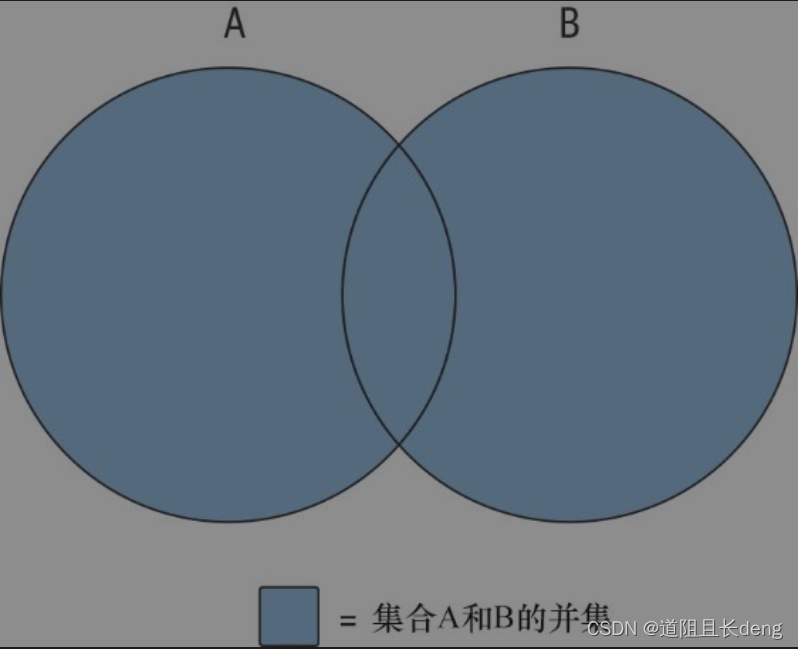
6.1集合论入门
集合A和B的并集(union)
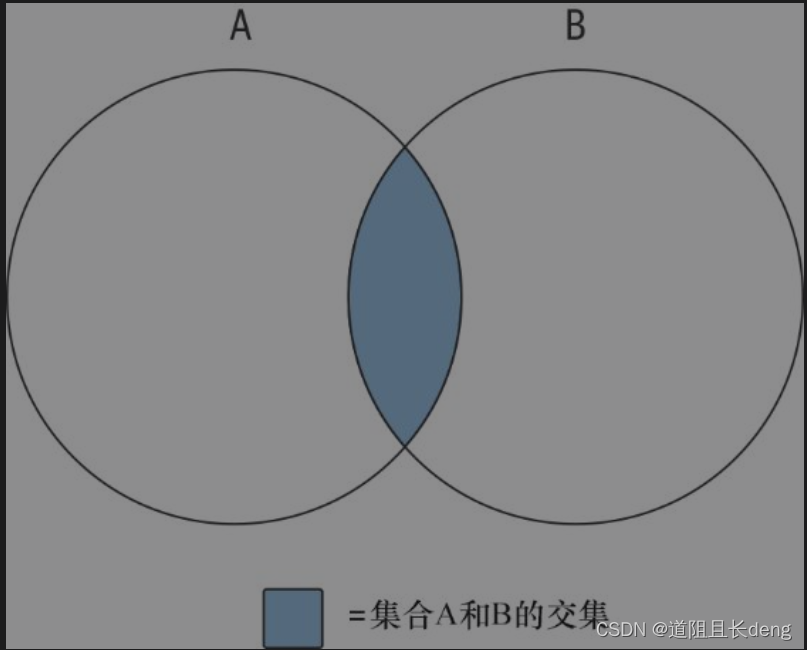
A和B的交集(intersection)
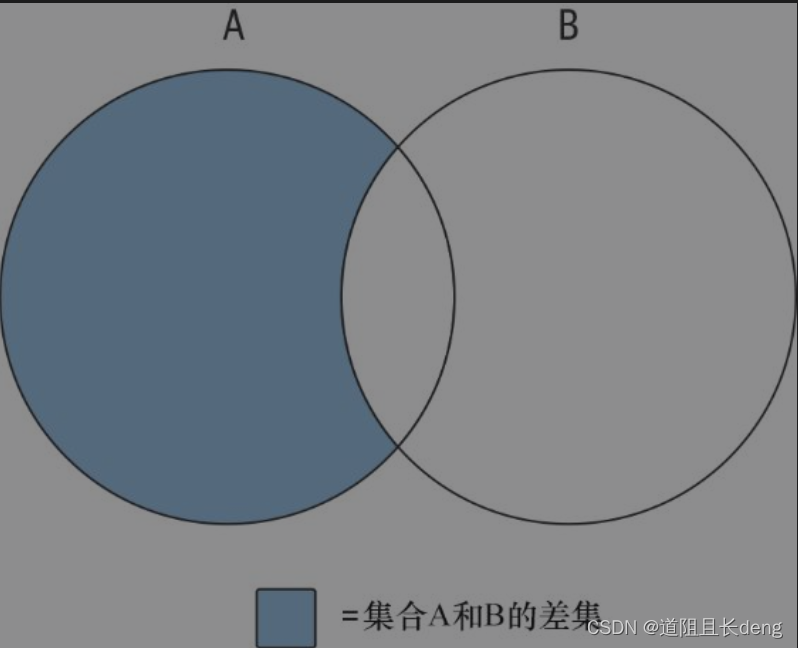
A和B的差集(A except B)
使用这3种运算或者将不同的运算组合在一起,就可以生成任何所需的结果。例如,假设想生成如图6-4所示的集合。
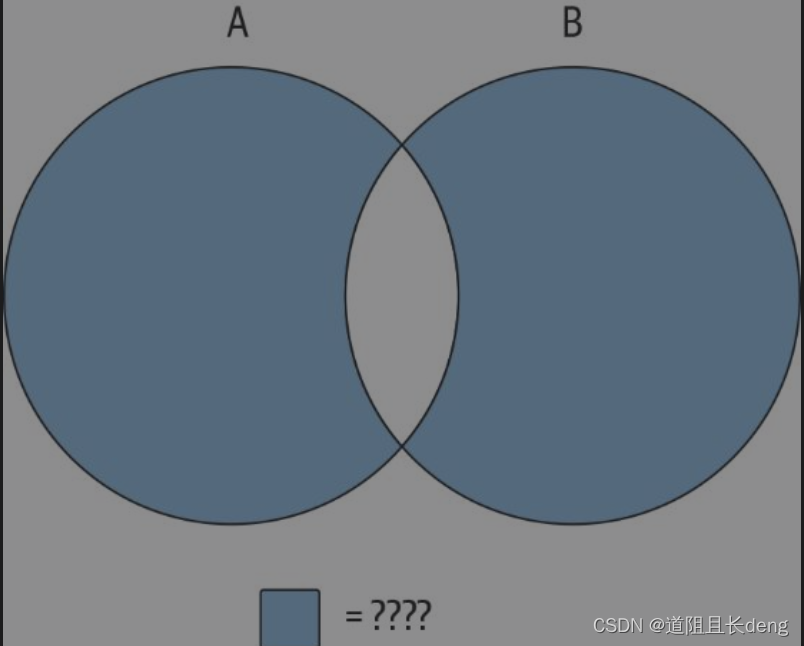
方法1:
(A union B) except (A intersect B)
方法2:
(A except B) union (B except A)
6.2 集合论实践
mysql> SELECT 1 num, 'abc' str
-> UNION
-> SELECT 9 num, 'xyz' str;
+-----+-----+
| num | str |
+-----+-----+
| 1 | abc |
| 9 | xyz |
+-----+-----+
2 rows in set (0.02 sec)
6.3集合运算符
SQL语言包括3个集合运算符,可用于执行之前介绍过的各种集合运算。此外,每个集合运算符有两种风格,一种包含了重复项,另一种去除了重复项(但不一定是所有重复项)。
6.3.1 union运算符
运算符union和union all可以组合多个数据集。两者的区别在于,union会对组合后的集合进行排序并去除重复项,而union all则不然。对于后者,最终得到的数据集的行数总是等于各集合的行数之和。
mysql> SELECT 'CUST' typ, c.first_name, c.last_name
-> FROM customer c
-> UNION ALL
-> SELECT 'ACTR' typ, a.first_name, a.last_name
-> FROM actor a;
+------+------------+-------------+
| typ | first_name | last_name |
+------+------------+-------------+
| CUST | MARY | SMITH |
| CUST | PATRICIA | JOHNSON |
| CUST | LINDA | WILLIAMS |
| CUST | BARBARA | JONES |
| CUST | ELIZABETH | BROWN |
| CUST | JENNIFER | DAVIS |
| CUST | MARIA | MILLER |
| CUST | SUSAN | WILSON |
| CUST | MARGARET | MOORE |
| CUST | DOROTHY | TAYLOR |
| CUST | LISA | ANDERSON |
| CUST | NANCY | THOMAS |
| CUST | KAREN | JACKSON |
...
| ACTR | BURT | TEMPLE |
| ACTR | MERYL | ALLEN |
| ACTR | JAYNE | SILVERSTONE |
| ACTR | BELA | WALKEN |
| ACTR | REESE | WEST |
| ACTR | MARY | KEITEL |
| ACTR | JULIA | FAWCETT |
| ACTR | THORA | TEMPLE |
+------+------------+-------------+
799 rows in set (0.00 sec)
如果想不包含重复行,需要使用union运算符代替union all:
mysql> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'
-> UNION
-> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JENNIFER | DAVIS |
| JUDY | DEAN |
| JODIE | DEGENERES |
| JULIANNE | DENCH |
+------------+-----------+
4 rows in set (0.00 sec)
6.3.2 intersect运算符
ANSI SQL规范中定义了用于执行交集运算的intersect运算符。遗憾的是,MySQL 8.0版还未实现intersect运算符,不过在Oracle或SQL Server 2008中可以使用它。
SELECT c.first_name, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'
INTERSECT
SELECT a.first_name, a.last_name
FROM actor a
WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JENNIFER | DAVIS |
+------------+-----------+
1 row in set (0.00 sec)
6.3.3 except运算符
ANSI SQL规范提供了执行差集运算的except运算符。同样遗憾的是,MySQL 8.0版也没有实现except运算符,因此本节依然沿用6.3.2节的做法
如果你使用的是Oracle Database,则需要使用非ANSI兼容的minus运算符替代except运算符。
except运算符返回第一个结果集减去其与第二个结果集重叠部分后的剩余部分。
SELECT a.first_name, a.last_name
FROM actor a
WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'
EXCEPT
SELECT c.first_name, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JUDY | DEAN |
| JODIE | DEGENERES |
| JULIANNE | DENCH |
+------------+-----------+
3 rows in set (0.00 sec)
6.4.1 对符合查询结果排序
mysql> SELECT a.first_name fname, a.last_name lname
-> FROM actor a
-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'
-> UNION ALL
-> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'
-> ORDER BY lname, fname;
+----------+-----------+
| fname | lname |
+----------+-----------+
| JENNIFER | DAVIS |
| JENNIFER | DAVIS |
| JUDY | DEAN |
| JODIE | DEGENERES |
| JULIANNE | DENCH |
+----------+-----------+
5 rows in set (0.00 sec)
6.4.2 集合运算的优先级
mysql> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'
-> UNION ALL
-> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'
-> UNION
-> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JENNIFER | DAVIS |
| JUDY | DEAN |
| JODIE | DEGENERES |
| JULIANNE | DENCH |
| MARY | TANDY |
| MENA | TEMPLE |
+------------+-----------+
6 rows in set (0.00 sec)
颠倒了集合运算符的位置:
mysql> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'
-> UNION
-> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'
-> UNION ALL
-> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JENNIFER | DAVIS |
| JUDY | DEAN |
| JODIE | DEGENERES |
| JULIANNE | DENCH |
| MARY | TANDY |
| MENA | TEMPLE |
| JENNIFER | DAVIS |
+------------+-----------+
7 rows in set (0.00 sec)
在使用不同的集合运算符时,复合查询的不同构建方式的确会生成不同的查询结果。一般而言,包含3个或以上查询语句的复合查询,是以自顶向下的顺序来评估查询的,但还需要注意下面两点:
- 根据ANSI SQL规范,intersect运算符拥有比其他集合运算符更高的优先级;
- 可以将查询放入括号内,以明确指定查询的执行顺序。
MySQL目前还不允许在复合查询中使用括号,但如果你使用的是其他数据库服务器,则可以将相邻查询放入括号中,以覆盖复合查询默认的自顶向下的处理方式。
如下所示:
SELECT a.first_name, a.last_name
FROM actor a
WHERE a.first_name LIKE 'J%' AND a.last_name LIKE 'D%'
UNION
(SELECT a.first_name, a.last_name
FROM actor a
WHERE a.first_name LIKE 'M%' AND a.last_name LIKE 'T%'
UNION ALL
SELECT c.first_name, c.last_name
FROM customer c
WHERE c.first_name LIKE 'J%' AND c.last_name LIKE 'D%'
)
7. 数据生成、操作和转换
7.1 处理字符串数据
char、varchar、text(MySQL和SQL Server)或clob(Oracle Database)
7.1.1 生成字符串
填充字符列的最简单的方法是将字符串放入引号内,如下所示:
mysql> INSERT INTO string_tbl (char_fld, vchar_fld, text_fld)
-> VALUES ('This is char data',
-> 'This is varchar data',
-> 'This is text data');
Query OK, 1 row affected (0.00 sec)
当字符串超出最大长度的时候,服务器会抛出异常,因为默认为strict模式,可以通过命令修改为ANSI模式。下面的示例演示了如何检查数据库的当前模式以及如何使用set命令改变模式:
mysql> SELECT @@session.sql_mode;
+----------------------------------------------------------------+
| @@session.sql_mode |
+----------------------------------------------------------------+
| STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION |
+----------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SET sql_mode='ansi';
Query OK, 0 rows affected (0.08 sec)
mysql> SELECT @@session.sql_mode;
+----------------------------------------------------------------------+
| @@session.sql_mode |
+----------------------------------------------------------------------+
| REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ONLY_FULL_GROUP_BY,ANSI |
+----------------------------------------------------------------------+
1 row in set (0.00 sec)
1.包含单引号
例如,无法插入下面的字符串,因为服务器认为单词doesn’t中的撇号表示字符串结束了
UPDATE string_tbl
SET text_fld = 'This string doesn't work';
三种数据库服务器都支持直接在单引号前再添加一个单引号进行转义:
mysql> UPDATE string_tbl
-> SET text_fld = 'This string didn''t work, but it does now';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
Oracle Database和MySQL用户也可以选择使用反斜杠字符来转义单引号:
UPDATE string_tbl SET text_fld =
'This string didn\'t work, but it does now'
quote()函数可用于将转义字符加入检索字符串时的结果:
mysql> SELECT quote(text_fld)
-> FROM string_tbl;
+---------------------------------------------+
| QUOTE(text_fld) |
+---------------------------------------------+
| 'This string didn\'t work, but it does now' |
+---------------------------------------------+
1 row in set (0.04 sec)
2.包含特殊字符
SQL Server和MySQL服务器包含内建函数char()(Oracle Database用户可以使用chr()函数),可用于从ASCII字符集的255个字符中任意构建字符串。
mysql> SELECT 'abcdefg', CHAR(97,98,99,100,101,102,103);
+---------+--------------------------------+
| abcdefg | CHAR(97,98,99,100,101,102,103) |
+---------+--------------------------------+
| abcdefg | abcdefg |
+---------+--------------------------------+
1 row in set (0.01 sec)
mysql> SELECT CHAR(128,129,130,131,132,133,134,135,136,137);
+-----------------------------------------------+
| CHAR(128,129,130,131,132,133,134,135,136,137) |
+-----------------------------------------------+
| Çüéâäàåçêë |
+-----------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT CHAR(138,139,140,141,142,143,144,145,146,147);
+-----------------------------------------------+
| CHAR(138,139,140,141,142,143,144,145,146,147) |
+-----------------------------------------------+
| èïîìÄÅÉæÆô |
+-----------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT CHAR(148,149,150,151,152,153,154,155,156,157);
+-----------------------------------------------+
| CHAR(148,149,150,151,152,153,154,155,156,157) |
+-----------------------------------------------+
| öòûùÿÖÜø£Ø |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT CHAR(158,159,160,161,162,163,164,165);
+---------------------------------------+
| CHAR(158,159,160,161,162,163,164,165) |
+---------------------------------------+
| ׃áíóúñÑ |
+---------------------------------------+
1 row in set (0.01 sec)
下面的示例展示了如何使用函数concat()和char()构建短语danke schön:
mysql> SELECT CONCAT('danke sch', CHAR(148), 'n');
+-------------------------------------+
| CONCAT('danke sch', CHAR(148), 'n') |
+-------------------------------------+
| danke schön |
+-------------------------------------+
1 row in set (0.00 sec)
Oracle Database用户可以使用拼接运算符(||)代替concat()函数:
SELECT 'danke sch' || CHR(148) || 'n'
FROM dual;
SQL Server并未提供concat()函数,需要使用拼接运算符(+)代替:
SELECT 'danke sch' + CHAR(148) + 'n'
如果有一个字符,需要找出其对应的ASCII编码,可以使用ascii()函数,该函数接受字符串最左侧的字符,并返回其编码数值:
mysql> SELECT ASCII('ö');
+------------+
| ASCII('ö') |
+------------+
| 148 |
+------------+
1 row in set (0.00 sec)
7.1.2 操作字符串
本节将研究两种字符串函数:
1.返回数值的字符串函数
mysql> SELECT LENGTH(char_fld) char_length,
-> LENGTH(vchar_fld) varchar_length,
-> LENGTH(text_fld) text_length
-> FROM string_tbl;
+-------------+----------------+-------------+
| char_length | varchar_length | text_length |
+-------------+----------------+-------------+
| 28 | 28 | 28 |
+-------------+----------------+-------------+
1 row in set (0.00 sec)
如果想查找字符串’characters’在vchar_fld列中出现的位置,可以使用position()函数,如下所示:
mysql> SELECT POSITION('characters' IN vchar_fld)
-> FROM string_tbl;
+-------------------------------------+
| POSITION('characters' IN vchar_fld) |
+-------------------------------------+
| 19 |
+-------------------------------------+
1 row in set (0.12 sec)
如果没有找到指定的子串,position()函数返回0。
如果想从目标字符串的其他位置开始搜索,那么可以使用locate()函数,下面的示例从vchar_fld列的第5个字符开始查找字符串’is’出现的位置:
mysql> SELECT LOCATE('is', vchar_fld, 5)
-> FROM string_tbl;
+----------------------------+
| LOCATE('is', vchar_fld, 5) |
+----------------------------+
| 13 |
+----------------------------+
1 row in set (0.02 sec)
Oracle Database未提供函数position()或locate(),但提供了instr()函数,该函数在使用两个参数时,能够模拟position()函数;使用三个参数时,能够模拟locate()函数。SQL Server也没有提供position()或locate()函数,但提供了charindx()函数,该函数和Oracle的instr()函数类似,也可以接受两个或三个参数。
另一个接受字符串作为参数并返回数值的函数是字符串比较函数strcmp()。只有MySQL实现了该函数,strcmp()接受两个字符串作为参数,返回下列值之一:
- −1(第一个字符串的排序位于第二个字符串之前);
- 0(两个字符串相同);
- 1(第一个字符串的排序位于第二个字符串之后)。
模拟数据
mysql> DELETE FROM string_tbl;
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO string_tbl(vchar_fld)
-> VALUES ('abcd'),
-> ('xyz'),
-> ('QRSTUV'),
-> ('qrstuv'),
-> ('12345');
Query OK, 5 rows affected (0.05 sec)
Records: 5 Duplicates: 0 Warnings: 0
这5个字符串的排序如下:
mysql> SELECT vchar_fld
-> FROM string_tbl
-> ORDER BY vchar_fld;
+-----------+
| vchar_fld |
+-----------+
| 12345 |
| abcd |
| QRSTUV |
| qrstuv |
| xyz |
+-----------+
5 rows in set (0.00 sec)
下列查询对5个字符串进行6次比较:
mysql> SELECT STRCMP('12345','12345') 12345_12345,
-> STRCMP('abcd','xyz') abcd_xyz,
-> STRCMP('abcd','QRSTUV') abcd_QRSTUV,
-> STRCMP('qrstuv','QRSTUV') qrstuv_QRSTUV,
-> STRCMP('12345','xyz') 12345_xyz,
-> STRCMP('xyz','qrstuv') xyz_qrstuv;
+-------------+----------+-------------+---------------+-----------+------------+
| 12345_12345 | abcd_xyz | abcd_QRSTUV | qrstuv_QRSTUV | 12345_xyz | xyz_qrstuv |
+-------------+----------+-------------+---------------+-----------+------------+
| 0 | −1 | −1 | 0 | −1 | 1 |
+-------------+----------+-------------+---------------+-----------+------------+
1 row in set (0.00 sec)
除了strcmp()函数,MySQL还允许在select子句中使用运算符like和regexp来比较字符串。这些比较的结果为1(true)或0(false)。
mysql> SELECT name, name LIKE '%y' ends_in_y
-> FROM category;
+-------------+-----------+
| name | ends_in_y |
+-------------+-----------+
| Action | 0 |
| Animation | 0 |
| Children | 0 |
| Classics | 0 |
| Comedy | 1 |
| Documentary | 1 |
| Drama | 0 |
| Family | 1 |
| Foreign | 0 |
| Games | 0 |
| Horror | 0 |
| Music | 0 |
| New | 0 |
| Sci-Fi | 0 |
| Sports | 0 |
| Travel | 0 |
+-------------+-----------+
16 rows in set (0.00 sec)
如果想执行更复杂的模式匹配,可以使用regexp运算符,如下所示:
mysql> SELECT name, name REGEXP 'y$' ends_in_y
-> FROM category;
+-------------+-----------+
| name | ends_in_y |
+-------------+-----------+
| Action | 0 |
| Animation | 0 |
| Children | 0 |
| Classics | 0 |
| Comedy | 1 |
| Documentary | 1 |
| Drama | 0 |
| Family | 1 |
| Foreign | 0 |
| Games | 0 |
| Horror | 0 |
| Music | 0 |
| New | 0 |
| Sci-Fi | 0 |
| Sports | 0 |
| Travel | 0 |
+-------------+-----------+
16 rows in set (0.00 sec)
2.返回字符串的字符串函数
重新设置string_tbl数据表的数据:
mysql> DELETE FROM string_tbl;
Query OK, 5 rows affected (0.00 sec)
mysql> INSERT INTO string_tbl (text_fld)
-> VALUES ('This string was 29 characters');
Query OK, 1 row affected (0.01 sec)
concat()函数可用于向已有的字符串追加字符:
mysql> UPDATE string_tbl
-> SET text_fld = CONCAT(text_fld, ', but now it is longer');
Query OK, 1 row affected (0.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
这时,text_fld列的内容如下:
mysql> SELECT text_fld
-> FROM string_tbl;
+-----------------------------------------------------+
| text_fld |
+-----------------------------------------------------+
| This string was 29 characters, but now it is longer |
+-----------------------------------------------------+
1 row in set (0.00 sec)
concat()函数的另一种常见用法是通过数据片段构建字符串。例如,下列查询为每位客户生成一段描述性信息:
mysql> SELECT concat(first_name, ' ', last_name,
-> ' has been a customer since ', date(create_date)) cust_narrative
-> FROM customer;
+---------------------------------------------------------+
| cust_narrative |
+---------------------------------------------------------+
| MARY SMITH has been a customer since 2006-02-14 |
| PATRICIA JOHNSON has been a customer since 2006-02-14 |
| LINDA WILLIAMS has been a customer since 2006-02-14 |
| BARBARA JONES has been a customer since 2006-02-14 |
| ELIZABETH BROWN has been a customer since 2006-02-14 |
| JENNIFER DAVIS has been a customer since 2006-02-14 |
| MARIA MILLER has been a customer since 2006-02-14 |
| SUSAN WILSON has been a customer since 2006-02-14 |
| MARGARET MOORE has been a customer since 2006-02-14 |
| DOROTHY TAYLOR has been a customer since 2006-02-14 |
...
| RENE MCALISTER has been a customer since 2006-02-14 |
| EDUARDO HIATT has been a customer since 2006-02-14 |
| TERRENCE GUNDERSON has been a customer since 2006-02-14 |
| ENRIQUE FORSYTHE has been a customer since 2006-02-14 |
| FREDDIE DUGGAN has been a customer since 2006-02-14 |
| WADE DELVALLE has been a customer since 2006-02-14 |
| AUSTIN CINTRON has been a customer since 2006-02-14 |
+---------------------------------------------------------+
599 rows in set (0.00 sec)
insert()函数
函数接受4个参数:原始字符串、起始位置、要替换的字符数量和替换字符串,第3个参数0表示插入,1为替换
mysql> SELECT INSERT('goodbye world', 9, 0, 'cruel ') string;
+---------------------+
| string |
+---------------------+
| goodbye cruel world |
+---------------------+
1 row in set (0.00 sec)
mysql> SELECT INSERT('goodbye world', 1, 7, 'hello') string;
+-------------+
| string |
+-------------+
| hello world |
+-------------+
1 row in set (0.00 sec)
Oracle Database没有提供像insert()这样灵活的函数,但提供了replace()函数,可用于替换子串。下面使用replace()函数重写上个示例:
SELECT REPLACE('goodbye world', 'goodbye', 'hello')
FROM dual;
replace()函数会使用替换字符串取代所有的搜索字符串,所以要小心替换次数超出你的预期。
SQL Server还提供了与MySQL的insert()函数功能相似的stuff()函数,如下所示:
SELECT STUFF('hello world', 1, 5, 'goodbye cruel')
结果得到字符串’goodbye cruel world’。
三种数据库服务器均提供了substring()函数(Oracle Database提供的是substr()函数),可用于从指定位置提取指定数量的字符。下面的示例从字符串的位置9开始提取5个字符:
mysql> SELECT SUBSTRING('goodbye cruel world', 9, 5);
+----------------------------------------+
| SUBSTRING('goodbye cruel world', 9, 5) |
+----------------------------------------+
| cruel |
+----------------------------------------+
1 row in set (0.00 sec)
7.2 处理数值型数据
所有常见的算术运算符(+、−、*、/)都可用于计算,括号可用于指明优先级,如下所示:
mysql> SELECT (37 * 59) / (78 - (8 * 6));
+----------------------------+
| (37 * 59) / (78 - (8 * 6)) |
+----------------------------+
| 72.77 |
+----------------------------+
1 row in set (0.00 sec)
如果数值型数据大于所在列的指定大小,其在存储时可能会被取整。例如,9.96在被存储到定义为float(3,1)的列时会被取整为10.0。
7.2.1 执行算术函数
单参数数值型函数
| 函数名 | 用途 |
|---|---|
| acos(x) | 计算x的反余弦 |
| asin(x) | 计算x的反正弦 |
| atan(x) | 计算x的反正切 |
| cos(x) | 计算x的余弦 |
| cot(x) | 计算x的余切 |
| exp(x) | 计算e的x平方 |
| In(x) | 计算x的自然对数 |
| sin(x) | 计算x的正弦 |
| tan(x) | 计算x的正切 |
用于计算余数的modulo运算符在MySQL和Oracle Database中是通过mod()函数实现的。下面的示例计算10除以4的余数:
mysql> SELECT MOD(10,4);
+-----------+
| MOD(10,4) |
+-----------+
| 2 |
+-----------+
1 row in set (0.02 sec)
尽管mod()函数常用于整数参数,但在MySQL中也可以使用实数:
mysql> SELECT MOD(22.75, 5);
+---------------+
| MOD(22.75, 5) |
+---------------+
| 2.75 |
+---------------+
1 row in set (0.02 sec)
另一个接受两个参数的数值型函数是pow()函数(如果使用的是Oracle Database或SQL Server,则为power()函数),该函数返回第一个参数的第二个参数次幂:
mysql> SELECT POW(2,8);
+----------+
| POW(2,8) |
+----------+
| 256 |
+----------+
1 row in set (0.03 sec)
7.2.2 控制数值精度
有4个函数可用于限制浮点数的精度:ceil()、floor()、round()和truncate()。三种数据库服务器都提供了这些函数,只不过Oracle Database使用trunc()替代truncate(),SQL Server使用ceiling()替代ceil()。
mysql> SELECT CEIL(72.445), FLOOR(72.445);
+--------------+---------------+
| CEIL(72.445) | FLOOR(72.445) |
+--------------+---------------+
| 73 | 72 |
+--------------+---------------+
1 row in set (0.06 sec)
记住,使用ceil()时向上取整,哪怕小数部分非常小,而使用floor()时向下取整,哪怕小数部分非常大,如下所示:
mysql> SELECT CEIL(72.000000001), FLOOR(72.999999999);
+--------------------+---------------------+
| CEIL(72.000000001) | FLOOR(72.999999999) |
+--------------------+---------------------+
| 73 | 72 |
+--------------------+---------------------+
1 row in set (0.00 sec)
如果这种处理不适用于你的应用程序,可以使用round()函数进行四舍五入:
mysql> SELECT ROUND(72.49999), ROUND(72.5), ROUND(72.50001);
+-----------------+-------------+-----------------+
| ROUND(72.49999) | ROUND(72.5) | ROUND(72.50001) |
+-----------------+-------------+-----------------+
| 72 | 73 | 73 |
+-----------------+-------------+-----------------+
1 row in set (0.00 sec)
round()函数还提供了可选的第2个参数,用于指定小数点后四舍五入保留多少位小数。
mysql> SELECT ROUND(72.0909, 1), ROUND(72.0909, 2), ROUND(72.0909, 3);
+-------------------+-------------------+-------------------+
| ROUND(72.0909, 1) | ROUND(72.0909, 2) | ROUND(72.0909, 3) |
+-------------------+-------------------+-------------------+
| 72.1 | 72.09 | 72.091 |
+-------------------+-------------------+-------------------+
1 row in set (0.00 sec)
和round()函数一样,truncate()函数也提供了第2个可选参数,用于指定小数位数,truncate()的做法是将不需要的小数位直接丢弃。
mysql> SELECT TRUNCATE(72.0909, 1), TRUNCATE(72.0909, 2),
-> TRUNCATE(72.0909, 3);
+----------------------+----------------------+----------------------+
| TRUNCATE(72.0909, 1) | TRUNCATE(72.0909, 2) | TRUNCATE(72.0909, 3) |
+----------------------+----------------------+----------------------+
| 72.0 | 72.09 | 72.090 |
+----------------------+----------------------+----------------------+
1 row in set (0.00 sec)
SQL Server并未提供truncate()函数,而round()函数的第3个可选参数如果存在且不为0,则表明要执行截取操作,而非取整。
函数truncate()和round()都可以使用负数作为第2个参数,表示小数点左侧的部分需要被截取或取整多少位。
mysql> SELECT ROUND(17, −1), TRUNCATE(17, −1);
+---------------+------------------+
| ROUND(17, −1) | TRUNCATE(17, −1) |
+---------------+------------------+
| 20 | 10 |
+---------------+------------------+
1 row in set (0.00 sec)
7.2.3 使用有符号数
有如下数据
+------------+--------------+---------+
| account_id | acct_type | balance |
+------------+--------------+---------+
| 123 | MONEY MARKET | 785.22 |
| 456 | SAVINGS | 0.00 |
| 789 | CHECKING | -324.22 |
+------------+--------------+---------+
下列查询返回可用于生成报表的3列数据,第2列使用了sign()函数,如果账户余额为负数,则返回−1;如果为0,则返回0;如果为正数,则返回1。第3列使用abs()函数返回账户余额的绝对值。
mysql> SELECT account_id, SIGN(balance), ABS(balance)
-> FROM account;
+------------+---------------+--------------+
| account_id | SIGN(balance) | ABS(balance) |
+------------+---------------+--------------+
| 123 | 1 | 785.22 |
| 456 | 0 | 0.00 |
| 789 | -1 | 324.22 |
+------------+---------------+--------------+
3 rows in set (0.00 sec)
7.3 处理时间型数据
时间型数据的部分复杂性源于描述单一日期和时间的多种方式。例如,我正在写书的日期可以用下列方式描述:
Wednesday, June 5, 2019
6/05/2019 2:14:56 P.M. EST
6/05/2019 19:14:56 GMT
1562019 (Julian格式)
Star date [−4] 97026.79 14:14:56 (Star Trek格式)
7.3.1 处理时区
格林尼治标准时(Greenwich mean time,GMT)
我们现在使用的是GMT的一种变体,称为协调世界时(coordinated universal time,UTC)。
SQL Server和MySQL都提供了可以返回当前的UTC时间戳的函数(SQL Server的getutcdate()和MySQL的utc_timestamp())。
MySQL提供两种不同的时区设置:全局时区和会话时区,后者对于每个登录的用户可能有所不同。可以通过下列查询查看这两种设置:
mysql> SELECT @@global.time_zone, @@session.time_zone;
+--------------------+---------------------+
| @@global.time_zone | @@session.time_zone |
+--------------------+---------------------+
| SYSTEM | SYSTEM |
+--------------------+---------------------+
1 row in set (0.00 sec)
system表示服务器使用的是其数据库所在地的时区设置。
可以通过下列命令改变当前会话的时区设置:
mysql> SET time_zone = 'Europe/Zurich';
Query OK, 0 rows affected (0.18 sec)
如果再次检查时区设置,会看到如下结果:
mysql> SELECT @@global.time_zone, @@session.time_zone;
+--------------------+---------------------+
| @@global.time_zone | @@session.time_zone |
+--------------------+---------------------+
| SYSTEM | Europe/Zurich |
+--------------------+---------------------+
1 row in set (0.00 sec)
Oracle Database用户可以通过下列命令修改会话的时区设置:
ALTER SESSION TIMEZONE = 'Europe/Zurich'
7.3.2 生成时间型数据
可以使用下列任意一种方法生成时间型数据:
- 从已有的date、datetime或time列复制数据
- 执行能够返回date、datetime或time类型数据的内建函数;
- 执行能够返回date、datetime或time类型数据的内建函数;
- 构建可以被服务器评估的时间型数据的字符串表示。
为了使用上述最后一种方法,首先必须理解用于格式化日期的各个组成部分。
1.时间型数据的字符串表示
表7-2 日期格式的组成部分
| 组成部分 | 定义 | 取值范围 |
|---|---|---|
| YYYY | 年份,包括世纪 | 1000~9999 |
| MM | 月份 | 01(1月)~12(12月份) |
| DD | 日 | 01~31 |
| HH | 小时 | 00~23 |
| HHH | 小时(已逝去的) | -838~838 |
| MI | 分钟 | 00~59 |
| SS | 秒 | 00~59 |
为了构建能够被服务器解释为date、datetime或time类型的字符串,需要按照表7-3中所示的顺序来整合各种日期组成部分。
表7-3 所需的日期组成部分
| 类型 | 默认格式 |
|---|---|
| date | YYYY-MM-DD |
| datetime | YYYY-MM-DD HH:MI:SS |
| datestamp | YYYY-MM-DD HH:MI:SS |
| time | HHH:MI:SS |
| 因此,为了向datetime列填充日期“2019年9月17日下午3:30”,需要构建下列字符串: |
'2019-09-17 15:30:00'
如果服务器接受datetime类型的数据,比如更新datetime类型的列或调用接受datetime类型参数的内建函数,可以为其提供经过格式化且符合日期组成部分要求的字符串,服务器会执行转换。例如,下面的语句可用于修改租借电影的归还日期:
UPDATE rental
SET return_date = '2019-09-17 15:30:00'
WHERE rental_id = 99999;
下面的简单查询使用cast()函数返回datetime类型的值:
mysql> SELECT CAST('2019-09-17 15:30:00' AS DATETIME);
+-----------------------------------------+
| CAST('2019-09-17 15:30:00' AS DATETIME) |
+-----------------------------------------+
| 2019-09-17 15:30:00 |
+-----------------------------------------+
1 row in set (0.00 sec)
下列查询使用cast()函数生成date和time类型的值:
mysql> SELECT CAST('2019-09-17' AS DATE) date_field,
-> CAST('108:17:57' AS TIME) time_field;
+------------+------------+
| date_field | time_field |
+------------+------------+
| 2019-09-17 | 108:17:57 |
+------------+------------+
1 row in set (0.00 sec)
有些服务器对日期格式要求十分严格,而MySQL服务器对各部分之间的分隔符要求却比较宽松。例如,MySQL可以接受下列各种表示2019年9月17日下午3:30的字符串:
'2019-09-17 15:30:00'
'2019/09/17 15:30:00'
'2019,09,17,15,30,00'
'20190917153000'
3.日期生成函数
str_to_date()函数的使用:从文件中获取了字符串’September 17, 2019’,打算用其更新data列。因为该字符串不符合YYYY-MM-DD格式,所以可以通过str_to_date(),使之可以用于cast()函数:
UPDATE rental
SET return_date = STR_TO_DATE('September 17, 2019', '%M %d, %Y')
WHERE rental_id = 99999;
str_to_date()的第2个参数定义了日期字符串的格式,在本例中,该参数为月份名(%M)、天数(%d)和4位数字的年份(%Y)。可识别的格式组成部分超过30种,表7-4列出了其中最常用的部分。
表7-4 日期格式的组成部分
| 格式的组成部分 | 含义 |
|---|---|
| %M | 月份名称(January~December) |
| %m | 数字形式月份(01~12) |
| %d | 月内天数(01~31) |
| %j | 年内天数(001~366) |
| %W | 星期名称(Sunday~Saturday) |
| %Y | 4位数字形式的年份 |
| %y | 2位数字形式的年份 |
| %H | 小时(00~23) |
| %h | 小时(01~12) |
| %i | 分钟(00~59) |
| %s | 秒(00~59) |
| %f | 微秒(000000~999999) |
| %p | A.M. 或P.M. |
Oracle Database用户可以使用to_date()函数,其用法与MySQL的str_to_date()函数相同。SQL Server提供了convert()函数,但不如MySQL和Oracle Database那样灵活。你的日期字符串必须符合21种预定义的格式之一,而不能使用自定义的格式化字符串。
下列内建函数能够访问系统时钟,并以字符串形式返回当前日期/时间:
mysql> SELECT CURRENT_DATE(), CURRENT_TIME(), CURRENT_TIMESTAMP();
+----------------+----------------+---------------------+
| CURRENT_DATE() | CURRENT_TIME() | CURRENT_TIMESTAMP() |
+----------------+----------------+---------------------+
| 2019-06-05 | 16:54:36 | 2019-06-05 16:54:36 |
+----------------+----------------+---------------------+
1 row in set (0.12 sec)
Oracle Database提供了函数current_date()和current_timestamp(),但没有提供current_time(),Microsoft SQL Server只提供了current_timestamp()函数。
7.3.3 操作时间型数据
1.返回日期的时间型函数
MySQL的date_add()函数允许对指定日期添加各种间隔期(比如,日、月、年),以生成另一个日期。下面的示例演示了如何为当前日期增加5天:
mysql> SELECT DATE_ADD(CURRENT_DATE(), INTERVAL 5 DAY);
+------------------------------------------+
| DATE_ADD(CURRENT_DATE(), INTERVAL 5 DAY) |
+------------------------------------------+
| 2019-06-10 |
+------------------------------------------+
1 row in set (0.06 sec)
第2个参数由3部分组成:interval关键字、间隔值和间隔类型。表7-5列出了部分常用的间隔类型。
表7-5 常用的间隔类型
| 间隔名称 | 含义 |
|---|---|
| second | 秒数 |
| minute | 分钟数 |
| hour | 小时数 |
| day | 天数 |
| month | 月份数 |
| year | 年数 |
| minute_second | 分钟数和秒数,之间以’:’ 分隔 |
| hour_second | 小时数分钟数和秒数,之间以’:’ 分隔 |
| year_month | 年份和月份数,之间以’-'分隔 |
例子:
date_add()函数获取return_date列的值并对其增加3小时27分11秒:
UPDATE rental
SET return_date = DATE_ADD(return_date, INTERVAL '3:27:11' HOUR_SECOND)
WHERE rental_id = 99999;
在员工的出生日期上增加9年11个月
UPDATE employee
SET birth_date = DATE_ADD(birth_date, INTERVAL '9-11' YEAR_MONTH)
WHERE emp_id = 4789;
SQL Server用户可以使用dateadd()函数实现上一个示例,SQL Server不能使用复合的时间间隔(即year_month),所以要先将9年11个月转换成119个月。
UPDATE employee
SET birth_date =
DATEADD(MONTH, 119, birth_date)
WHERE emp_id = 4789
Oracle Database用户可以使用add_months()函数实现这个示例:
UPDATE employee
SET birth_date = ADD_MONTHS(birth_date, 119)
WHERE emp_id = 4789;
last_day()函数,计算当前月份到月底所剩的天数,MySQL和Oracle Database都提供了last_day()函数,SQL Server没有提供与之功能接近的函数)。如果客户要求在2019年9月17日转账,可以通过以下方式找出9月的最后一天:
mysql> SELECT LAST_DAY('2019-09-17');
+------------------------+
| LAST_DAY('2019-09-17') |
+------------------------+
| 2019-09-30 |
+------------------------+
1 row in set (0.10 sec)
2.返回字符串的时间型函数
MySQL提供的dayname()函数可以确定某一天是星期几
mysql> SELECT DAYNAME('2019-09-18');
+-----------------------+
| DAYNAME('2019-09-18') |
+-----------------------+
| Wednesday |
+-----------------------+
1 row in set (0.00 sec)
如果要提取datetime值中的年份,可以执行下列操作:
mysql> SELECT EXTRACT(YEAR FROM '2019-09-18 22:19:05');
+------------------------------------------+
| EXTRACT(YEAR FROM '2019-09-18 22:19:05') |
+------------------------------------------+
| 2019 |
+------------------------------------------+
1 row in set (0.00 sec)
SQL Server没有提供extract()函数的实现,但是提供了datepart()函数。下面展示了如何使用datepart()函数提取datetime类型的值中的年份:
SELECT DATEPART(YEAR, GETDATE())
3.返回数值的时间型函数
MySQL提供了函数datediff(),该函数返回两个日期之间的天数。
mysql> SELECT DATEDIFF('2019-09-03', '2019-06-21');
+--------------------------------------+
| DATEDIFF('2019-09-03', '2019-06-21') |
+--------------------------------------+
| 74 |
+--------------------------------------+
1 row in set (0.00 sec)
datediff()函数忽略其参数中日期的时间部分,即使日期中包含时间部分,也会将第一个日期设置为午夜零时前的最后一秒,第二个日期设置为午夜零时后的第一秒,在计算中这些时间是无效的。
mysql> SELECT DATEDIFF('2019-09-03 23:59:59', '2019-06-21 00:00:01');
+--------------------------------------------------------+
| DATEDIFF('2019-09-03 23:59:59', '2019-06-21 00:00:01') |
+--------------------------------------------------------+
| 74 |
+--------------------------------------------------------+
1 row in set (0.00 sec)
如果交换参数,把时间上靠前的日期放在前面,则datediff()函数返回负数:
mysql> SELECT DATEDIFF('2019-06-21', '2019-09-03');
+--------------------------------------+
| DATEDIFF('2019-06-21', '2019-09-03') |
+--------------------------------------+
| -74 |
+--------------------------------------+
1 row in set (0.00 sec)
SQL Server也提供了datediff()函数,但比MySQL的实现更为灵活,可以为其指定间隔类型(年、月、日、小时等),而不仅仅是计算两个日期之间间隔的天数。下面用SQL Server实现上一个示例:
SELECT DATEDIFF(DAY, '2019-06-21', '2019-09-03')
Oracle Database允许通过将两个日期值相减的方式求出两者之间间隔的天数。
7.4 转换函数
cast()函数:该函数属于SQL:2003标准,并且在MySQL、Oracle和Microsoft SQL Server中均已实现。
使用cast()函数时必须提供一个值或表达式、as关键字和所需要转换的类型。
mysql> SELECT CAST('1456328' AS SIGNED INTEGER);
+-----------------------------------+
| CAST('1456328' AS SIGNED INTEGER) |
+-----------------------------------+
| 1456328 |
+-----------------------------------+
1 row in set (0.01 sec)
将字符串转换为数值时,cast()函数会尝试从左向右转换整个字符串,如果在字符串中遇到非数值字符,则服务器中止转换且不报错。
mysql> SELECT CAST('999ABC111' AS UNSIGNED INTEGER);
+---------------------------------------+
| CAST('999ABC111' AS UNSIGNED INTEGER) |
+---------------------------------------+
| 999 |
+---------------------------------------+
1 row in set, 1 warning (0.08 sec)
mysql> show warnings;
+---------+------+------------------------------------------------+
| Level | Code | Message |
+---------+------+------------------------------------------------+
| Warning | 1292 | Truncated incorrect INTEGER value: '999ABC111' |
+---------+------+------------------------------------------------+
1 row in set (0.07 sec)
在本例中,字符串的前3个数字字符被成功转换,剩余的字符则被丢弃,因而最终结果值为999。但是服务器会发出警告,提示字符串并没有被完整转换。
8. 分组和聚合
8.1 分组的概念
例子:
mysql> SELECT customer_id FROM rental;
+-------------+
| customer_id |
+-------------+
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
...
| 599 |
| 599 |
| 599 |
| 599 |
| 599 |
| 599 |
+-------------+
16044 rows in set (0.01 sec)
使用GROUP BY后,共计599行,而不再是原先的16,044行。数量减少的原因在于有些客户租借了多部电影。
mysql> SELECT customer_id
-> FROM rental
-> GROUP BY customer_id;
+-------------+
| customer_id |
+-------------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
...
| 594 |
| 595 |
| 596 |
| 597 |
| 598 |
| 599 |
+-------------+
599 rows in set (0.00 sec)
可以在select子句中使用聚合函数,以统计每组有多少行:
mysql> SELECT customer_id, count(*)
-> FROM rental
-> GROUP BY customer_id;
+-------------+----------+
| customer_id | count(*) |
+-------------+----------+
| 1 | 32 |
| 2 | 27 |
| 3 | 26 |
| 4 | 22 |
| 5 | 38 |
| 6 | 28 |
...
| 594 | 27 |
| 595 | 30 |
| 596 | 28 |
| 597 | 25 |
| 598 | 22 |
| 599 | 19 |
+-------------+----------+
599 rows in set (0.01 sec)
为了确定哪位客户借的电影最多,只需加入order by子句:
mysql> SELECT customer_id, count(*)
-> FROM rental
-> GROUP BY customer_id
-> ORDER BY 2 DESC;
+-------------+----------+
| customer_id | count(*) |
+-------------+----------+
| 148 | 46 |
| 526 | 45 |
| 236 | 42 |
| 144 | 42 |
| 75 | 41 |
...
| 248 | 15 |
| 110 | 14 |
| 281 | 14 |
| 61 | 14 |
| 318 | 12 |
+-------------+----------+
599 rows in set (0.01 sec)
在对数据进行分组时,可能还需要根据数据分组(而非原始数据)从结果集中过滤掉不想要的数据。由于group by子句是在where子句被评估之后运行的,因此无法为此对where子句增加过滤条件。例如,下面尝试过滤掉租借电影少于40部的客户:
mysql> SELECT customer_id, count(*)
-> FROM rental
-> WHERE count(*) >= 40
-> GROUP BY customer_id;
ERROR 1111 (HY000): Invalid use of group function
无法在where子句中引用聚合函数count(*),因为在评估where子句时,分组尚未生成,因而必须将分组过滤条件放入having子句。下面来看使用having子句的查询:
mysql> SELECT customer_id, count(*)
-> FROM rental
-> GROUP BY customer_id
-> HAVING count(*) >= 40;
+-------------+----------+
| customer_id | count(*) |
+-------------+----------+
| 75 | 41 |
| 144 | 42 |
| 148 | 46 |
| 197 | 40 |
| 236 | 42 |
| 469 | 40 |
| 526 | 45 |
+-------------+----------+
7 rows in set (0.01 sec)
8.2 聚合函数
聚合函数对分组中的所有行执行特定的操作。尽管每种数据库服务器都有自己专有的聚合函数,但所有的主流服务器都提供了下列常见的聚合函数。
| 函数名 | 作用 |
|---|---|
| max() | 返回集合中的最大值。 |
| min() | 返回集合中的最小值。 |
| avg() | 返回集合中的平均值。 |
| sum() | 返回集合中所有值之和。 |
| count() | 返回集合中所有值的个数。 |
下列查询使用了以上这些常见的聚合函数来分析电影租借付款数据:
mysql> SELECT MAX(amount) max_amt,
-> MIN(amount) min_amt,
-> AVG(amount) avg_amt,
-> SUM(amount) tot_amt,
-> COUNT(*) num_payments
-> FROM payment;
+---------+---------+----------+----------+--------------+
| max_amt | min_amt | avg_amt | tot_amt | num_payments |
+---------+---------+----------+----------+--------------+
| 11.99 | 0.00 | 4.200667 | 67416.51 | 16049 |
+---------+---------+----------+----------+--------------+
1 row in set (0.09 sec)
8.2.1 隐式分组与显式分组
在上一个示例中,查询返回的每个值都是由聚合函数生成的。因为没有使用group by子句,所以只有一个隐式分组(payment数据表中的所有行)。
假设想要扩展之前的查询,对于每位客户执行同样的5个聚合函数,而不是在所有客户中查询。为此,在查询中检索customer_id列以及5个聚合函数:
SELECT customer_id,
MAX(amount) max_amt,
MIN(amount) min_amt,
AVG(amount) avg_amt,
SUM(amount) tot_amt,
COUNT(*) num_payments
FROM payment;
但如果执行该查询,会接收到下列错误消息:
ERROR 1140 (42000): In aggregated query without GROUP BY,
expression #1 of SELECT list contains nonaggregated column
尽管显然是想把聚合函数应用于payment数据表中的每位客户,但是该查询失败了,原因在于没有明确指定数据应该如何分组。所以,需要添加一个group by子句来指定聚合函数应该应用于哪个分组:
mysql> SELECT customer_id,
-> MAX(amount) max_amt,
-> MIN(amount) min_amt,
-> AVG(amount) avg_amt,
-> SUM(amount) tot_amt,
-> COUNT(*) num_payments
-> FROM payment
-> GROUP BY customer_id;
+-------------+---------+---------+----------+---------+--------------+
| customer_id | max_amt | min_amt | avg_amt | tot_amt | num_payments |
+-------------+---------+---------+----------+---------+--------------+
| 1 | 9.99 | 0.99 | 3.708750 | 118.68 | 32 |
| 2 | 10.99 | 0.99 | 4.767778 | 128.73 | 27 |
| 3 | 10.99 | 0.99 | 5.220769 | 135.74 | 26 |
| 4 | 8.99 | 0.99 | 3.717273 | 81.78 | 22 |
| 5 | 9.99 | 0.99 | 3.805789 | 144.62 | 38 |
| 6 | 7.99 | 0.99 | 3.347143 | 93.72 | 28 |
...
| 594 | 8.99 | 0.99 | 4.841852 | 130.73 | 27 |
| 595 | 10.99 | 0.99 | 3.923333 | 117.70 | 30 |
| 596 | 6.99 | 0.99 | 3.454286 | 96.72 | 28 |
| 597 | 8.99 | 0.99 | 3.990000 | 99.75 | 25 |
| 598 | 7.99 | 0.99 | 3.808182 | 83.78 | 22 |
| 599 | 9.99 | 0.99 | 4.411053 | 83.81 | 19 |
+-------------+---------+---------+----------+---------+--------------+
599 rows in set (0.04 sec)
8.2.2 统计不同的值
考虑下列查询,它以两种不同的方式对customer_id列使用count()函数:
mysql> SELECT COUNT(customer_id) num_rows,
-> COUNT(DISTINCT customer_id) num_customers
-> FROM payment;
+----------+---------------+
| num_rows | num_customers |
+----------+---------------+
| 16049 | 599 |
+----------+---------------+
1 row in set (0.01 sec)
查询中的第一列只是简单地统计payment数据表中的行数,而第二列则检查customer_id列中的值(仅计算其中不同值的数量)。因此,通过指定distinct,count()函数检查分组中每个成员的列值,以便查找和删除重复项,而不是简单地计算分组中值的数量。
8.2.3 使用表达式
例如,你可能想找出一部电影从被租借到后来归还之间相隔的最大天数,可以通过下列查询实现:
mysql> SELECT MAX(datediff(return_date,rental_date))
-> FROM rental;
+----------------------------------------+
| MAX(datediff(return_date,rental_date)) |
+----------------------------------------+
| 10 |
+----------------------------------------+
1 row in set (0.01 sec)
datediff()函数用于计算每部电影的归还日期和租借日期之间相隔的天数,max()函数返回最大天数值,在本例中是10天。
8.2.4 处理null
先构建一个包含数值型数据的简单数据表
mysql> CREATE TABLE number_tbl
-> (val SMALLINT);
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO number_tbl VALUES (1);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO number_tbl VALUES (3);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO number_tbl VALUES (5);
Query OK, 1 row affected (0.00 sec)
下列查询对该集合执行5个聚合函数:
mysql> SELECT COUNT(*) num_rows,
-> COUNT(val) num_vals,
-> SUM(val) total,
-> MAX(val) max_val,
-> AVG(val) avg_val
-> FROM number_tbl;
+----------+----------+-------+---------+---------+
| num_rows | num_vals | total | max_val | avg_val |
+----------+----------+-------+---------+---------+
| 3 | 3 | 9 | 5 | 3.0000 |
+----------+----------+-------+---------+---------+
1 row in set (0.08 sec)
接下来,向 number_tbl数据表中添加一个null值并再次运行该查询:
mysql> INSERT INTO number_tbl VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
mysql> SELECT COUNT(*) num_rows,
-> COUNT(val) num_vals,
-> SUM(val) total,
-> MAX(val) max_val,
-> AVG(val) avg_val
-> FROM number_tbl;
+----------+----------+-------+---------+---------+
| num_rows | num_vals | total | max_val | avg_val |
+----------+----------+-------+---------+---------+
| 4 | 3 | 9 | 5 | 3.0000 |
+----------+----------+-------+---------+---------+
1 row in set (0.00 sec)
即使数据表中增加了null值,函数sum()、max()和avg()的返回值也没有发生变化,这表明它们忽略了任何遇到的null值。count(*)函数的返回值为4,这是由于number_tbl数据表包含4行,而count(val)函数的返回值仍为3。这两者的区别在于,count(*)统计行数,而count(val)统计val列包含多少个值并且忽略所有遇到的null值。
8.3 生成分组
8.3.1 单列分组
单列分组是最简单,也是最常用的分组类型。
mysql> SELECT actor_id, count(*)
-> FROM film_actor
-> GROUP BY actor_id;
+----------+----------+
| actor_id | count(*) |
+----------+----------+
| 1 | 19 |
| 2 | 25 |
| 3 | 22 |
| 4 | 22 |
...
| 197 | 33 |
| 198 | 40 |
| 199 | 15 |
| 200 | 20 |
+----------+----------+
200 rows in set (0.11 sec)
该查询生成了200个分组,每位演员对应其中的一组,然后汇总每组中的电影数量。
8.3.2 多列分组
在某些情况下,需要跨越多列生成分组。接着扩展上一个示例,假设想要找出每位演员参演的各种分级电影(G、PG…)的数量。下面给出了实现:
mysql> SELECT fa.actor_id, f.rating, count(*)
-> FROM film_actor fa
-> INNER JOIN film f
-> ON fa.film_id = f.film_id
-> GROUP BY fa.actor_id, f.rating
-> ORDER BY 1,2;
+----------+--------+----------+
| actor_id | rating | count(*) |
+----------+--------+----------+
| 1 | G | 4 |
| 1 | PG | 6 |
| 1 | PG-13 | 1 |
| 1 | R | 3 |
| 1 | NC-17 | 5 |
| 2 | G | 7 |
| 2 | PG | 6 |
| 2 | PG-13 | 2 |
| 2 | R | 2 |
| 2 | NC-17 | 8 |
...
| 199 | G | 3 |
| 199 | PG | 4 |
| 199 | PG-13 | 4 |
| 199 | R | 2 |
| 199 | NC-17 | 2 |
| 200 | G | 5 |
| 200 | PG | 3 |
| 200 | PG-13 | 2 |
| 200 | R | 6 |
| 200 | NC-17 | 4 |
+----------+--------+----------+
996 rows in set (0.01 sec)
8.3.3 通过表达式分组
除了使用列进行数据分组,也可以根据表达式产生的值构建分组。下列查询按年份对租借数据进行分组:
mysql> SELECT extract(YEAR FROM rental_date) year,
-> COUNT(*) how_many
-> FROM rental
-> GROUP BY extract(YEAR FROM rental_date);
+------+----------+
| year | how_many |
+------+----------+
| 2005 | 15862 |
| 2006 | 182 |
+------+----------+
2 rows in set (0.01 sec)
该查询使用了一个非常简单的表达式,该表达式利用extract()函数返回日期的年份部分,用于对rental数据表中的行进行分组。
8.3.4 生成汇总
假设在计算每位演员/评级组合的总计数的同时,还想知道不同演员参演的电影总数。下面是经过修改的查询,在group by子句中使用了with rollup选项:
mysql> SELECT fa.actor_id, f.rating, count(*)
-> FROM film_actor fa
-> INNER JOIN film f
-> ON fa.film_id = f.film_id
-> GROUP BY fa.actor_id, f.rating WITH ROLLUP
-> ORDER BY 1,2;
+----------+--------+----------+
| actor_id | rating | count(*) |
+----------+--------+----------+
| NULL | NULL | 5462 |
| 1 | NULL | 19 |
| 1 | G | 4 |
| 1 | PG | 6 |
| 1 | PG-13 | 1 |
| 1 | R | 3 |
| 1 | NC-17 | 5 |
| 2 | NULL | 25 |
| 2 | G | 7 |
| 2 | PG | 6 |
| 2 | PG-13 | 2 |
| 2 | R | 2 |
| 2 | NC-17 | 8 |
...
| 199 | NULL | 15 |
| 199 | G | 3 |
| 199 | PG | 4 |
| 199 | PG-13 | 4 |
| 199 | R | 2 |
| 199 | NC-17 | 2 |
| 200 | NULL | 20 |
| 200 | G | 5 |
| 200 | PG | 3 |
| 200 | PG-13 | 2 |
| 200 | R | 6 |
| 200 | NC-17 | 4 |
+----------+--------+----------+
1197 rows in set (0.07 sec)
8.4 分组过滤条件
在进行数据分组时,也可以在创建分组后对数据应用过滤条件。这类过滤条件应该放在having子句中。考虑下面的示例:
mysql> SELECT fa.actor_id, f.rating, count(*)
-> FROM film_actor fa
-> INNER JOIN film f
-> ON fa.film_id = f.film_id
-> WHERE f.rating IN ('G','PG')
-> GROUP BY fa.actor_id, f.rating
-> HAVING count(*) > 9;
+----------+--------+----------+
| actor_id | rating | count(*) |
+----------+--------+----------+
| 137 | PG | 10 |
| 37 | PG | 12 |
| 180 | PG | 12 |
| 7 | G | 10 |
| 83 | G | 14 |
| 129 | G | 12 |
| 111 | PG | 15 |
| 44 | PG | 12 |
| 26 | PG | 11 |
| 92 | PG | 12 |
| 17 | G | 12 |
| 158 | PG | 10 |
| 147 | PG | 10 |
| 14 | G | 10 |
| 102 | PG | 11 |
| 133 | PG | 10 |
+----------+--------+----------+
16 rows in set (0.01 sec)
如果错误地把两个过滤条件都放入where子句中,会产生以下错误消息:
mysql> SELECT fa.actor_id, f.rating, count(*)
-> FROM film_actor fa
-> INNER JOIN film f
-> ON fa.film_id = f.film_id
-> WHERE f.rating IN ('G','PG')
-> AND count(*) > 9
-> GROUP BY fa.actor_id, f.rating;
ERROR 1111 (HY000): Invalid use of group function
查询失败的原因在于:不能把聚合函数放入查询的where子句。where子句中的过滤条件是在数据被分组之前评估的,所以服务器无法对分组执行任何函数。
向包含group by子句的查询中添加过滤条件时,仔细考虑是过滤原始数据(将过滤条件放入where子句),还是过滤分组后的数据(将过滤条件放入having子句)。
9.子查询
在本章中将展示如何使用子查询来过滤数据、生成值和构造临时数据集。
9.1 什么是子查询
子查询是指包含在另一个SQL语句(后文称为“包含语句”)内部的查询。子查询总是被包围在括号中,通常先于包含语句执行。和其他查询一样,子查询也会返回下列形式的结果集:
- 单行单列;
- 多行单列;
- 多行多列。
子查询返回的结果集类型决定了其用法以及包含语句可以使用哪些运算符来处理子查询返回的数据。执行包含语句后,任何子查询返回的数据都会被丢弃,这使子查询像是一个具有语句作用域的临时数据表(这意味着服务器在执行SQL语句后会清空分配给子查询结果的内存)。
例子:
mysql> SELECT customer_id, first_name, last_name
-> FROM customer
-> WHERE customer_id = (SELECT MAX(customer_id) FROM customer);
+-------------+------------+-----------+
| customer_id | first_name | last_name |
+-------------+------------+-----------+
| 599 | AUSTIN | CINTRON |
+-------------+------------+-----------+
1 row in set (0.27 sec)
如果不清楚子查询究竟做了什么,可以单独运行子查询(不加括号)并查看返回结果。下面是上个示例的子查询:
mysql> SELECT MAX(customer_id) FROM customer;
+------------------+
| MAX(customer_id) |
+------------------+
| 599 |
+------------------+
1 row in set (0.00 sec)
上面的子查询相当于下面的例子:
mysql> SELECT customer_id, first_name, last_name
-> FROM customer
-> WHERE customer_id = 599;
+-------------+------------+-----------+
| customer_id | first_name | last_name |
+-------------+------------+-----------+
| 599 | AUSTIN | CINTRON |
+-------------+------------+-----------+
1 row in set (0.00 sec)
9.2 子查询类型
一些子查询完全独立(称为非关联子查询),而另一些子查询会引用包含语句中的列(称为关联子查询)。接下来我们将探究这两种子查询,展示可用于与其交互的不同运算符。
9.3 非关联子查询
非关联子查询,可以单独执行,不会引用包含语句中的任何内容。除了非关联子查询,之前示例返回的是包含单行单列的结果集。这种子查询称为标量子查询(scalar subquery),可以出现在使用普通运算符(=、<>、<、>、<=、>=)的过滤条件的任意一侧。下面的示例展示了如何在不等条件中使用标量子查询:
mysql> SELECT city_id, city
-> FROM city
-> WHERE country_id <>
-> (SELECT country_id FROM country WHERE country = 'India');
+---------+----------------------------+
| city_id | city |
+---------+----------------------------+
| 1 | A Corua (La Corua) |
| 2 | Abha |
| 3 | Abu Dhabi |
| 4 | Acua |
| 5 | Adana |
| 6 | Addis Abeba |
...
| 595 | Zapopan |
| 596 | Zaria |
| 597 | Zeleznogorsk |
| 598 | Zhezqazghan |
| 599 | Zhoushan |
| 600 | Ziguinchor |
+---------+----------------------------+
540 rows in set (0.02 sec)
该查询返回所有不在印度的城市。
尽管本例中的子查询非常简单,但如果有需要,子查询也可以很复杂,并且能够利用任何可用的查询子句(select、from、where、group by、having和order by)。
如果在相等条件中使用子查询,但该子查询的返回结果不止一行,就会出现错误。如下:
mysql> SELECT city_id, city
-> FROM city
-> WHERE country_id <>
-> (SELECT country_id FROM country WHERE country <> 'India');
ERROR 1242 (21000): Subquery returns more than 1 row
如果单独运行子查询,结果如下所示:
mysql> SELECT country_id FROM country WHERE country <> 'India';
+------------+
| country_id |
+------------+
| 1 |
| 2 |
| 3 |
| 4 |
...
| 106 |
| 107 |
| 108 |
| 109 |
+------------+
108 rows in set (0.00 sec)
包含查询出错的原因在于一个表达式(country_id)不能等于一组表达式(country_id为1,2,3,…,109)。
9.3.1 多行单列子查询
如果子查询的返回结果不止一行,则不能将其放在相等条件的一侧,如之前的示例所示。不过,还有另外4个运算符可用于为这种子查询构建条件。
1.in和not in运算符
下面的示例没有使用子查询,但演示了如何使用in运算符在一组值中查找某个值:
mysql> SELECT country_id
-> FROM country
-> WHERE country IN ('Canada','Mexico');
+------------+
| country_id |
+------------+
| 20 |
| 60 |
+------------+
2 rows in set (0.00 sec)
等价于:
mysql> SELECT country_id
-> FROM country
-> WHERE country = 'Canada' OR country = 'Mexico';
+------------+
| country_id |
+------------+
| 20 |
| 60 |
+------------+
2 rows in set (0.00 sec)
当集合只包含两个表达式时,这种方法看起来是合理的,但是如果集合包含大量的值(如成百上千),那么很容易看出使用in运算符的单个条件更为可取。
下列查询使用in运算符和过滤条件右侧的子查询来返回位于Canada或Mexico的所有城市:
mysql> SELECT city_id, city
-> FROM city
-> WHERE country_id IN
-> (SELECT country_id
-> FROM country
-> WHERE country IN ('Canada','Mexico'));
+---------+----------------------------+
| city_id | city |
+---------+----------------------------+
| 179 | Gatineau |
| 196 | Halifax |
| 300 | Lethbridge |
| 313 | London |
| 383 | Oshawa |
| 430 | Richmond Hill |
| 565 | Vancouver |
...
| 452 | San Juan Bautista Tuxtepec |
| 541 | Torren |
| 556 | Uruapan |
| 563 | Valle de Santiago |
| 595 | Zapopan |
+---------+----------------------------+
37 rows in set (0.00 sec)
除了查看某个值是否存在于一组值中,还可以使用not in运算符实现相反的效果。下面是上一个查询的另一个版本,使用not in代替了in:
mysql> SELECT city_id, city
-> FROM city
-> WHERE country_id NOT IN
-> (SELECT country_id
-> FROM country
-> WHERE country IN ('Canada','Mexico'));
+---------+----------------------------+
| city_id | city |
+---------+----------------------------+
| 1 | A Corua (La Corua) |
| 2 | Abha |
| 3 | Abu Dhabi |
| 5 | Adana |
| 6 | Addis Abeba |
...
| 596 | Zaria |
| 597 | Zeleznogorsk |
| 598 | Zhezqazghan |
| 599 | Zhoushan |
| 600 | Ziguinchor |
+---------+----------------------------+
563 rows in set (0.00 sec)
该查询搜索所有不在Canada或Mexico的城市。
2.all运算符
in运算符可用于查看能否在一个表达式集合中找到某个表达式,all运算符则用于将某个值与集合中的所有值进行比较。构建这种条件时需要将比较运算符(=、<>、<、>等)与all运算符配合使用。例如,下列查询搜索所有从未获得过免费电影租借的客户:
mysql> SELECT first_name, last_name
-> FROM customer
-> WHERE customer_id <> ALL
-> (SELECT customer_id
-> FROM payment
-> WHERE amount = 0);
+-------------+--------------+
| first_name | last_name |
+-------------+--------------+
| MARY | SMITH |
| PATRICIA | JOHNSON |
| LINDA | WILLIAMS |
| BARBARA | JONES |
...
| EDUARDO | HIATT |
| TERRENCE | GUNDERSON |
| ENRIQUE | FORSYTHE |
| FREDDIE | DUGGAN |
| WADE | DELVALLE |
| AUSTIN | CINTRON |
+-------------+--------------+
576 rows in set (0.01 sec)
如果你觉得这种方式有些笨拙,那么请放心,不是只有你这样想。下列查询使用not in运算符,生成的结果和上一个示例一模一样:
SELECT first_name, last_name
FROM customer
WHERE customer_id NOT IN
(SELECT customer_id
FROM payment
WHERE amount = 0)
使用not in或<>运算符比较一个值和一组值时,必须确保这组值中不包含null值,这是因为服务器会将表达式左侧的值与组中的各个值进行比较,任何值与null作相等比较时都会产生unknown。因此,下列查询返回的结果集为空集:
mysql> SELECT first_name, last_name
-> FROM customer
-> WHERE customer_id NOT IN (122, 452, NULL);
Empty set (0.00 sec)
下面是另一个使用all运算符的示例,但这次的子查询位于having子句内:
mysql> SELECT customer_id, count(*)
-> FROM rental
-> GROUP BY customer_id
-> HAVING count(*) > ALL
-> (SELECT count(*)
-> FROM rental r
-> INNER JOIN customer c
-> ON r.customer_id = c.customer_id
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id
-> INNER JOIN country co
-> ON ct.country_id = co.country_id
-> WHERE co.country IN ('United States','Mexico','Canada')
-> GROUP BY r.customer_id
-> );
+-------------+----------+
| customer_id | count(*) |
+-------------+----------+
| 148 | 46 |
+-------------+----------+
1 row in set (0.01 sec)
3.any运算符
和all运算符一样,any运算符允许将单个值与一组值中的各个值进行比较。与all运算符不同的是,只要有一次比较成立,使用any运算符的条件即为真。
mysql> SELECT customer_id, sum(amount)
-> FROM payment
-> GROUP BY customer_id
-> HAVING sum(amount) > ANY
-> (SELECT sum(p.amount)
-> FROM payment p
-> INNER JOIN customer c
-> ON p.customer_id = c.customer_id
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id
-> INNER JOIN country co
-> ON ct.country_id = co.country_id
-> WHERE co.country IN ('Bolivia','Paraguay','Chile')
-> GROUP BY co.country
-> );
+-------------+-------------+
| customer_id | sum(amount) |
+-------------+-------------+
| 137 | 194.61 |
| 144 | 195.58 |
| 148 | 216.54 |
| 178 | 194.61 |
| 459 | 186.62 |
| 526 | 221.55 |
+-------------+-------------+
6 rows in set (0.03 sec)
子查询返回Bolivia、Paraguay、Chile这3个国家中所有客户的电影租借付款总额,包含查询返回付款超出至少其中一个国家的所有客户。
尽管大多数人喜欢使用in,不过= any与in等效。
9.3.2 多列子查询
在某些情况下,要用到返回两列或以上的子查询。为了展示多列子查询的用途,下面先看一个多重单列子查询的示例:
mysql> SELECT fa.actor_id, fa.film_id
-> FROM film_actor fa
-> WHERE fa.actor_id IN
-> (SELECT actor_id FROM actor WHERE last_name = 'MONROE')
-> AND fa.film_id IN
-> (SELECT film_id FROM film WHERE rating = 'PG');
+----------+---------+
| actor_id | film_id |
+----------+---------+
| 120 | 63 |
| 120 | 144 |
| 120 | 414 |
| 120 | 590 |
| 120 | 715 |
| 120 | 894 |
| 178 | 164 |
| 178 | 194 |
| 178 | 273 |
| 178 | 311 |
| 178 | 983 |
+----------+---------+
11 rows in set (0.00 sec)
可以将以上两个单列子查询合并成一个多列子查询,并将结果与film_actor数据表的两列的结果进行比对。为此,过滤条件必须将film_actor数据表的两列放入括号内,且与子查询返回的顺序一致:
mysql> SELECT actor_id, film_id
-> FROM film_actor
-> WHERE (actor_id, film_id) IN
-> (SELECT a.actor_id, f.film_id
-> FROM actor a
-> CROSS JOIN film f
-> WHERE a.last_name = 'MONROE'
-> AND f.rating = 'PG');
+----------+---------+
| actor_id | film_id |
+----------+---------+
| 120 | 63 |
| 120 | 144 |
| 120 | 414 |
| 120 | 590 |
| 120 | 715 |
| 120 | 894 |
| 178 | 164 |
| 178 | 194 |
| 178 | 273 |
| 178 | 311 |
| 178 | 983 |
+----------+---------+
11 rows in set (0.00 sec)
该查询的执行结果和上一个示例一样,但使用返回两列的单个子查询代替各返回一列的两个子查询。此版本的子查询使用了交叉连接,我们会在第10章中介绍。
9.4 关联子查询
关联子查询依赖其包含语句,引用了其中的一列或者多列。与非关联子查询不同,关联子查询并不是先于包含语句一次性执行完毕,而是为每一个候选行(可能会包含在最终结果中)执行一次。例如,下列查询使用关联子查询统计每个客户租借的电影数量,然后由包含查询来检索租借了20部电影的客户:
mysql> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE 20 =
-> (SELECT count(*) FROM rental r
-> WHERE r.customer_id = c.customer_id);
+------------+-------------+
| first_name | last_name |
+------------+-------------+
| LAUREN | HUDSON |
| JEANETTE | GREENE |
| TARA | RYAN |
| WILMA | RICHARDS |
| JO | FOWLER |
| KAY | CALDWELL |
| DANIEL | CABRAL |
| ANTHONY | SCHWAB |
| TERRY | GRISSOM |
| LUIS | YANEZ |
| HERBERT | KRUGER |
| OSCAR | AQUINO |
| RAUL | FORTIER |
| NELSON | CHRISTENSON |
| ALFREDO | MCADAMS |
+------------+-------------+
15 rows in set (0.01 sec)
因为关联子查询会对包含查询返回的每一行执行一次,所以如果包含查询返回很多行,将会引发性能问题。
除了相等条件,也可以在其他类型的条件中使用关联子查询,比如下面所示的范围条件:
mysql> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE
-> (SELECT sum(p.amount) FROM payment p
-> WHERE p.customer_id = c.customer_id)
-> BETWEEN 180 AND 240;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| RHONDA | KENNEDY |
| CLARA | SHAW |
| ELEANOR | HUNT |
| MARION | SNYDER |
| TOMMY | COLLAZO |
| KARL | SEAL |
+------------+-----------+
6 rows in set (0.03 sec)
上述查询的另一处细微不同在于子查询位于条件的左侧,尽管看起来有点奇怪,但完全有效。
9.4.1 exists运算符
如果想在不考虑数量的情况下确定存在关系,可以使用exists运算符。例如,下列查询查找在2005年5月25日之前至少租借过一部电影的所有客户,不考虑租借电影的具体数量:
mysql> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE EXISTS
-> (SELECT 1 FROM rental r
-> WHERE r.customer_id = c.customer_id
-> AND date(r.rental_date) < '2005-05-25');
+------------+-------------+
| first_name | last_name |
+------------+-------------+
| CHARLOTTE | HUNTER |
| DELORES | HANSEN |
| MINNIE | ROMERO |
| CASSANDRA | WALTERS |
| ANDREW | PURDY |
| MANUEL | MURRELL |
| TOMMY | COLLAZO |
| NELSON | CHRISTENSON |
+------------+-------------+
8 rows in set (0.03 sec)
使用exists运算符时,子查询可能会返回0行、1行或者多行结果,然而条件只是简单地检查子查询是否返回至少1行。如果查看子查询中的select子句,就会发现它只由单个字面量1组成,因为包含查询内的条件只需要知道子查询返回了多少行,具体返回的数据无关紧要。事实上,可以让子查询返回任何想要的结果,如下所示:
mysql> SELECT c.first_name, c.last_name
-> FROM customer c
-> WHERE EXISTS
-> (SELECT r.rental_date, r.customer_id, 'ABCD' str, 2 * 3 / 7 nmbr
-> FROM rental r
-> WHERE r.customer_id = c.customer_id
-> AND date(r.rental_date) < '2005-05-25');
+------------+-------------+
| first_name | last_name |
+------------+-------------+
| CHARLOTTE | HUNTER |
| DELORES | HANSEN |
| MINNIE | ROMERO |
| CASSANDRA | WALTERS |
| ANDREW | PURDY |
| MANUEL | MURRELL |
| TOMMY | COLLAZO |
| NELSON | CHRISTENSON |
+------------+-------------+
8 rows in set (0.03 sec)
不过在使用exists时,惯例是指定select 1或select *。
也可以使用not exists来检查没有返回行的子查询,如下所示:
mysql> SELECT a.first_name, a.last_name
-> FROM actor a
-> WHERE NOT EXISTS
-> (SELECT 1
-> FROM film_actor fa
-> INNER JOIN film f ON f.film_id = fa.film_id
-> WHERE fa.actor_id = a.actor_id
-> AND f.rating = 'R');
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| JANE | JACKMAN |
+------------+-----------+
1 row in set (0.00 sec)
该查询查找从未参演过R级电影的所有演员。
9.4.2 使用关联子查询操作数据
到目前为止,本章的所有示例都是select语句,但这并不意味着子查询在其他SQL语句中没有用处。子查询也大量应用于update、delete和insert语句,关联子查询也频繁出现于update和delete语句中。下面的关联子查询用于修改customer数据表中的last_update列:
UPDATE customer c
SET c.last_update =
(SELECT max(r.rental_date) FROM rental r
WHERE r.customer_id = c.customer_id);
该语句通过查找rental数据表中每个客户最近的租借日期,修改了customer数据表中的每一行(因为没有where子句)。尽管认为每个客户至少租借一部电影似乎合情合理,但最好还是在更新last_update列之前检查一下,否则,如果子查询什么都不返回的话,该列会被设置为null。下面是update语句的另一个版本,其中使用了where子句和另一个关联子查询:
UPDATE customer c
SET c.last_update =
(SELECT max(r.rental_date) FROM rental r
WHERE r.customer_id = c.customer_id)
WHERE EXISTS
(SELECT 1 FROM rental r
WHERE r.customer_id = c.customer_id);
set子句中的子查询仅在update语句的where子句中被评估为真(意味着客户至少租借过一次电影)时才执行,这样就避免了last_update列被null覆盖。
关联子查询在delete语句中也很常见。例如,你可能会在每个月末运行数据维护脚本,以删除不需要的数据。该脚本可能包含下列语句,从customer 数据表中删除去年没有租借电影的行:
DELETE FROM customer
WHERE 365 < ALL
(SELECT datediff(now(), r.rental_date) days_since_last_rental
FROM rental r
WHERE r.customer_id = customer.customer_id);
切记,在MySQL的delete语句中使用关联子查询时,无论如何都不能使用数据表别名,这就是在子查询中使用数据表全名的原因。不过,在其他大多数数据库服务器中,customer数据表是可以使用别名的:
DELETE FROM customer c
WHERE 365 < ALL
(SELECT datediff(now(), r.rental_date) days_since_last_rental
FROM rental r
WHERE r.customer_id = c.customer_id);
9.5 何时使用子查询
9.5.1 子查询作为数据源
因为子查询生成的是包含行列数据的结果集,所以非常适合将子查询与数据表一起包含在from子句中。例子:
mysql> SELECT c.first_name, c.last_name,
-> pymnt.num_rentals, pymnt.tot_payments
-> FROM customer c
-> INNER JOIN
-> (SELECT customer_id,
-> count(*) num_rentals, sum(amount) tot_payments
-> FROM payment
-> GROUP BY customer_id
-> ) pymnt
-> ON c.customer_id = pymnt.customer_id;
+-------------+--------------+-------------+--------------+
| first_name | last_name | num_rentals | tot_payments |
+-------------+--------------+-------------+--------------+
| MARY | SMITH | 32 | 118.68 |
| PATRICIA | JOHNSON | 27 | 128.73 |
| LINDA | WILLIAMS | 26 | 135.74 |
| BARBARA | JONES | 22 | 81.78 |
| ELIZABETH | BROWN | 38 | 144.62 |
...
| TERRENCE | GUNDERSON | 30 | 117.70 |
| ENRIQUE | FORSYTHE | 28 | 96.72 |
| FREDDIE | DUGGAN | 25 | 99.75 |
| WADE | DELVALLE | 22 | 83.78 |
| AUSTIN | CINTRON | 19 | 83.81 |
+-------------+--------------+-------------+--------------+
599 rows in set (0.03 sec)
在本例中,子查询生成了客户ID列表以及客户租借的电影数量和支付的总金额。下面是子查询生成的结果集:
mysql> SELECT customer_id, count(*) num_rentals, sum(amount) tot_payments
-> FROM payment
-> GROUP BY customer_id;
+-------------+-------------+--------------+
| customer_id | num_rentals | tot_payments |
+-------------+-------------+--------------+
| 1 | 32 | 118.68 |
| 2 | 27 | 128.73 |
| 3 | 26 | 135.74 |
| 4 | 22 | 81.78 |
...
| 596 | 28 | 96.72 |
| 597 | 25 | 99.75 |
| 598 | 22 | 83.78 |
| 599 | 19 | 83.81 |
+-------------+-------------+--------------+
599 rows in set (0.03 sec)
from子句中的子查询必须是非关联查询[1],它们首先被执行,结果数据一直保留在内存中直至包含查询执行完毕。在编写查询时,子查询提供了极大的灵活性,可以在可用的数据表集合之外创建需要的任何数据视图,然后将结果与其他数据表或子查询连接。如果需要创建报表或是为外部系统生成数据源,用一个查询就能够实现过去需要多重查询或者过程化语言来完成的任务。
1.数据加工
除了使用子查询汇总现有数据,还可以利用子查询生成数据库中不存在的数据。
例子:
第一步编写生成分组定义的查询:
mysql> SELECT 'Small Fry' name, 0 low_limit, 74.99 high_limit
-> UNION ALL
-> SELECT 'Average Joes' name, 75 low_limit, 149.99 high_limit
-> UNION ALL
-> SELECT 'Heavy Hitters' name, 150 low_limit, 9999999.99 high_limit;
+---------------+-----------+------------+
| name | low_limit | high_limit |
+---------------+-----------+------------+
| Small Fry | 0 | 74.99 |
| Average Joes | 75 | 149.99 |
| Heavy Hitters | 150 | 9999999.99 |
+---------------+-----------+------------+
3 rows in set (0.00 sec)
现在已经有了能够生成所需分组的查询,只要将其放入另一个查询的from子句中就可以了:
mysql> SELECT pymnt_grps.name, count(*) num_customers
-> FROM
-> (SELECT customer_id,
-> count(*) num_rentals, sum(amount) tot_payments
-> FROM payment
-> GROUP BY customer_id
-> ) pymnt
-> INNER JOIN
-> (SELECT 'Small Fry' name, 0 low_limit, 74.99 high_limit
-> UNION ALL
-> SELECT 'Average Joes' name, 75 low_limit, 149.99 high_limit
-> UNION ALL
-> SELECT 'Heavy Hitters' name, 150 low_limit, 9999999.99 high_limit
-> ) pymnt_grps
-> ON pymnt.tot_payments
-> BETWEEN pymnt_grps.low_limit AND pymnt_grps.high_limit
-> GROUP BY pymnt_grps.name;
+---------------+---------------+
| name | num_customers |
+---------------+---------------+
| Average Joes | 515 |
| Heavy Hitters | 46 |
| Small Fry | 38 |
+---------------+---------------+
3 rows in set (0.03 sec)
当然,也可以不使用子查询,而是简单地选择构建一个永久性(或临时)数据表来保存分组定义。使用这种方法,你会发现经过一段时间后,数据库中散落的都是一些小型专用数据表,其中对于大多数数据表的创建原因也很难回忆起来。但如果使用子查询,你就能够遵守仅在有明确的存储新数据的业务需求时才向数据库添加新数据表的原则。
2.面向任务的子查询
假设想要生成一份报表,显示每个客户的姓名、所在城市、租借的电影总数以及支付的总金额,可以通过连接数据表payment、customer、address和city,然后按照客户的姓氏和名字进行分组,以实现该需求:
mysql> SELECT c.first_name, c.last_name, ct.city,
-> sum(p.amount) tot_payments, count(*) tot_rentals
-> FROM payment p
-> INNER JOIN customer c
-> ON p.customer_id = c.customer_id
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id
-> GROUP BY c.first_name, c.last_name, ct.city;
+------------+------------+----------------+--------------+-------------+
| first_name | last_name | city | tot_payments | tot_rentals |
+------------+------------+----------------+--------------+-------------+
| MARY | SMITH | Sasebo | 118.68 | 32 |
| PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 |
| LINDA | WILLIAMS | Athenai | 135.74 | 26 |
| BARBARA | JONES | Myingyan | 81.78 | 22 |
...
| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 |
| ENRIQUE | FORSYTHE | Patras | 96.72 | 28 |
| FREDDIE | DUGGAN | Sullana | 99.75 | 25 |
| WADE | DELVALLE | Lausanne | 83.78 | 22 |
| AUSTIN | CINTRON | Tieli | 83.81 | 19 |
+------------+------------+----------------+--------------+-------------+
599 rows in set (0.06 sec)
该查询返回了所需的数据,但如果仔细观察,会发现数据表customer、address、city仅用于显示,payment数据表包含了用于生成分组所需的所有数据(customer_id和amount)。因此,可以将生成分组的任务交由子查询完成,然后将另外3个数据表与子查询产生的数据表连接,从而获得最终的结果。下面是生成分组的子查询:
mysql> SELECT customer_id,
-> count(*) tot_rentals, sum(amount) tot_payments
-> FROM payment
-> GROUP BY customer_id;
+-------------+-------------+--------------+
| customer_id | tot_rentals | tot_payments |
+-------------+-------------+--------------+
| 1 | 32 | 118.68 |
| 2 | 27 | 128.73 |
| 3 | 26 | 135.74 |
| 4 | 22 | 81.78 |
...
| 595 | 30 | 117.70 |
| 596 | 28 | 96.72 |
| 597 | 25 | 99.75 |
| 598 | 22 | 83.78 |
| 599 | 19 | 83.81 |
+-------------+-------------+--------------+
599 rows in set (0.03 sec)
这是查询的核心所在,其他数据表仅用于提供有意义的字符串来代替customer_id值。接下来的查询将上面的数据集与另外3个数据表连接起来:
mysql> SELECT c.first_name, c.last_name,
-> ct.city,
-> pymnt.tot_payments, pymnt.tot_rentals
-> FROM
-> (SELECT customer_id,
-> count(*) tot_rentals, sum(amount) tot_payments
-> FROM payment
-> GROUP BY customer_id
-> ) pymnt
-> INNER JOIN customer c
-> ON pymnt.customer_id = c.customer_id
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id;
+------------+------------+----------------+--------------+-------------+
| first_name | last_name | city | tot_payments | tot_rentals |
+------------+------------+----------------+--------------+-------------+
| MARY | SMITH | Sasebo | 118.68 | 32 |
| PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 |
| LINDA | WILLIAMS | Athenai | 135.74 | 26 |
| BARBARA | JONES | Myingyan | 81.78 | 22 |
...
| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 |
| ENRIQUE | FORSYTHE | Patras | 96.72 | 28 |
| FREDDIE | DUGGAN | Sullana | 99.75 | 25 |
| WADE | DELVALLE | Lausanne | 83.78 | 22 |
| AUSTIN | CINTRON | Tieli | 83.81 | 19 |
+------------+------------+----------------+--------------+-------------+
599 rows in set (0.06 sec)
3.公用表表达式
公用表表达式(common table expression,CTE)是MySQL 8.0版新引入的特性,不过在其他数据库服务器中已经出现多年了。CTE是一个具名子查询,出现在with子句内查询的顶部,该子句可以包含多个以逗号分隔的CTE。除了使查询更易于理解,此特性还允许每个CTE引用相同with子句内在其之前定义的其他CTE。下列示例包括3个CTE,其中第2个CTE引用了第1个CTE,第3个CTE引用了第2个CTE:
mysql> WITH actors_s AS
-> (SELECT actor_id, first_name, last_name
-> FROM actor
-> WHERE last_name LIKE 'S%'
-> ),
-> actors_s_pg AS
-> (SELECT s.actor_id, s.first_name, s.last_name,
-> f.film_id, f.title
-> FROM actors_s s
-> INNER JOIN film_actor fa
-> ON s.actor_id = fa.actor_id
-> INNER JOIN film f
-> ON f.film_id = fa.film_id
-> WHERE f.rating = 'PG'
-> ),
-> actors_s_pg_revenue AS
-> (SELECT spg.first_name, spg.last_name, p.amount
-> FROM actors_s_pg spg
-> INNER JOIN inventory i
-> ON i.film_id = spg.film_id
-> INNER JOIN rental r
-> ON i.inventory_id = r.inventory_id
-> INNER JOIN payment p
-> ON r.rental_id = p.rental_id
-> ) -- end of With clause
-> SELECT spg_rev.first_name, spg_rev.last_name,
-> sum(spg_rev.amount) tot_revenue
-> FROM actors_s_pg_revenue spg_rev
-> GROUP BY spg_rev.first_name, spg_rev.last_name
-> ORDER BY 3 desc;
+------------+-------------+-------------+
| first_name | last_name | tot_revenue |
+------------+-------------+-------------+
| NICK | STALLONE | 692.21 |
| JEFF | SILVERSTONE | 652.35 |
| DAN | STREEP | 509.02 |
| GROUCHO | SINATRA | 457.97 |
| SISSY | SOBIESKI | 379.03 |
| JAYNE | SILVERSTONE | 372.18 |
| CAMERON | STREEP | 361.00 |
| JOHN | SUVARI | 296.36 |
| JOE | SWANK | 177.52 |
+------------+-------------+-------------+
9 rows in set (0.18 sec)
9.5.2 子查询作为表达式生成器
本节将对一开始提到的单列单行的标量子查询进行总结。除了用于过滤条件,标量子查询还可以用在表达式可以出现的任何位置,其中包括查询的select和order by子句以及insert语句的values子句。
例子:
mysql> SELECT
-> (SELECT c.first_name FROM customer c
-> WHERE c.customer_id = p.customer_id
-> ) first_name,
-> (SELECT c.last_name FROM customer c
-> WHERE c.customer_id = p.customer_id
-> ) last_name,
-> (SELECT ct.city
-> FROM customer c
-> INNER JOIN address a
-> ON c.address_id = a.address_id
-> INNER JOIN city ct
-> ON a.city_id = ct.city_id
-> WHERE c.customer_id = p.customer_id
-> ) city,
-> sum(p.amount) tot_payments,
-> count(*) tot_rentals
-> FROM payment p
-> GROUP BY p.customer_id;
+------------+------------+----------------+--------------+-------------+
| first_name | last_name | city | tot_payments | tot_rentals |
+------------+------------+----------------+--------------+-------------+
| MARY | SMITH | Sasebo | 118.68 | 32 |
| PATRICIA | JOHNSON | San Bernardino | 128.73 | 27 |
| LINDA | WILLIAMS | Athenai | 135.74 | 26 |
| BARBARA | JONES | Myingyan | 81.78 | 22 |
...
| TERRENCE | GUNDERSON | Jinzhou | 117.70 | 30 |
| ENRIQUE | FORSYTHE | Patras | 96.72 | 28 |
| FREDDIE | DUGGAN | Sullana | 99.75 | 25 |
| WADE | DELVALLE | Lausanne | 83.78 | 22 |
| AUSTIN | CINTRON | Tieli | 83.81 | 19 |
+------------+------------+----------------+--------------+-------------+
599 rows in set (0.06 sec)
如前所述,标量子查询也可以出现在order by子句中。下列查询检索演员的姓氏和名字,并按照其参演电影的数量进行排序:
mysql> SELECT a.actor_id, a.first_name, a.last_name
-> FROM actor a
-> ORDER BY
-> (SELECT count(*) FROM film_actor fa
-> WHERE fa.actor_id = a.actor_id) DESC;
+----------+-------------+--------------+
| actor_id | first_name | last_name |
+----------+-------------+--------------+
| 107 | GINA | DEGENERES |
| 102 | WALTER | TORN |
| 198 | MARY | KEITEL |
| 181 | MATTHEW | CARREY |
...
| 71 | ADAM | GRANT |
| 186 | JULIA | ZELLWEGER |
| 35 | JUDY | DEAN |
| 199 | JULIA | FAWCETT |
| 148 | EMILY | DEE |
+----------+-------------+--------------+
200 rows in set (0.01 sec)
除了在select语句中使用关联标量子查询,也可以使用非关联标量子查询为insert语句生成值。
INSERT INTO film_actor (actor_id, film_id, last_update)
VALUES (
(SELECT actor_id FROM actor
WHERE first_name = 'JENNIFER' AND last_name = 'DAVIS'),
(SELECT film_id FROM film
WHERE title = 'ACE GOLDFINGER'),
now()
);
9.6 子查询小结
本章介绍了丰富的内容,在此有必要回顾一下。其中的示例演示过的子查询包括:
- 返回单行单列、多行单列、多列多行;
- 独立于包含语句(非关联子查询);
- 引用包含语句中的一列或多列(关联子查询);
- 可用于条件中,这些条件使用比较运算符和其他专用运算符(in、not in、exists和not exists);
- 出现在select、update、delete和insert语句内;
- 生成的结果集可以与查询中的其他数据表或者子查询连接;
- 可以生成值来填充数据表或者查询结果集中的列;
- 可用于查询的select、from、where、having、order by子句中。
10. 再谈连接
至此,我们应该已经熟悉了第5章介绍过的内连接的概念。本章着重学习包括外连接(outer join)和交叉连接(cross join)在内的其他连接数据表的方法。
10.1 外连接
下列查询通过连接这两个数据表,统计每部电影可用的拷贝数量:
mysql> SELECT f.film_id, f.title, count(*) num_copies
-> FROM film f
-> INNER JOIN inventory i
-> ON f.film_id = i.film_id
-> GROUP BY f.film_id, f.title;
+---------+-----------------------------+------------+
| film_id | title | num_copies |
+---------+-----------------------------+------------+
| 1 | ACADEMY DINOSAUR | 8 |
| 2 | ACE GOLDFINGER | 3 |
| 3 | ADAPTATION HOLES | 4 |
| 4 | AFFAIR PREJUDICE | 7 |
...
| 13 | ALI FOREVER | 4 |
| 15 | ALIEN CENTER | 6 |
...
| 997 | YOUTH KICK | 2 |
| 998 | ZHIVAGO CORE | 2 |
| 999 | ZOOLANDER FICTION | 5 |
| 1000 | ZORRO ARK | 8 |
+---------+-----------------------------+------------+
958 rows in set (0.02 sec)
你可能以为该查询能返回1,000行(一部电影一行),但只返回了958行。这是因为查询使用的是内连接,只返回满足连接条件的行。
如果希望查询返回所有的1,000部电影,而不管在inventory数据表中有没有对应的行,那么可以使用外连接,使连接条件成为可选的:
mysql> SELECT f.film_id, f.title, count(i.inventory_id) num_copies
-> FROM film f
-> LEFT OUTER JOIN inventory i
-> ON f.film_id = i.film_id
-> GROUP BY f.film_id, f.title;
+---------+-----------------------------+------------+
| film_id | title | num_copies |
+---------+-----------------------------+------------+
| 1 | ACADEMY DINOSAUR | 8 |
| 2 | ACE GOLDFINGER | 3 |
| 3 | ADAPTATION HOLES | 4 |
| 4 | AFFAIR PREJUDICE | 7 |
...
| 13 | ALI FOREVER | 4 |
| 14 | ALICE FANTASIA | 0 |
| 15 | ALIEN CENTER | 6 |
...
| 997 | YOUTH KICK | 2 |
| 998 | ZHIVAGO CORE | 2 |
| 999 | ZOOLANDER FICTION | 5 |
| 1000 | ZORRO ARK | 8 |
+---------+-----------------------------+------------+
1000 rows in set (0.01 sec)
下面描述了对该查询的改动:
- 连接定义从inner改为left outer,指示服务器包含该连接左侧数据表(在本例中为film)的所有行,如果连接成功,再包含该连接右侧数据表(inventory)的列;
- num_copies列的定义从count(*)改为count(i.inventory_id),后者统计inventory. inventory_id列值为非null的数量。
接下来,为了清晰地观察inner连接和outer连接的不同,我们删除group by子句,过滤掉大多数行。下列查询使用inner连接和过滤条件返回部分电影对应的行:
mysql> SELECT f.film_id, f.title, i.inventory_id
-> FROM film f
-> INNER JOIN inventory i
-> ON f.film_id = i.film_id
-> WHERE f.film_id BETWEEN 13 AND 15;
+---------+--------------+--------------+
| film_id | title | inventory_id |
+---------+--------------+--------------+
| 13 | ALI FOREVER | 67 |
| 13 | ALI FOREVER | 68 |
| 13 | ALI FOREVER | 69 |
| 13 | ALI FOREVER | 70 |
| 15 | ALIEN CENTER | 71 |
| 15 | ALIEN CENTER | 72 |
| 15 | ALIEN CENTER | 73 |
| 15 | ALIEN CENTER | 74 |
| 15 | ALIEN CENTER | 75 |
| 15 | ALIEN CENTER | 76 |
+---------+--------------+--------------+
10 rows in set (0.00 sec)
下面使用outer连接实现相同的查询:
mysql> SELECT f.film_id, f.title, i.inventory_id
-> FROM film f
-> LEFT OUTER JOIN inventory i
-> ON f.film_id = i.film_id
-> WHERE f.film_id BETWEEN 13 AND 15;
+---------+----------------+--------------+
| film_id | title | inventory_id |
+---------+----------------+--------------+
| 13 | ALI FOREVER | 67 |
| 13 | ALI FOREVER | 68 |
| 13 | ALI FOREVER | 69 |
| 13 | ALI FOREVER | 70 |
| 14 | ALICE FANTASIA | NULL |
| 15 | ALIEN CENTER | 71 |
| 15 | ALIEN CENTER | 72 |
| 15 | ALIEN CENTER | 73 |
| 15 | ALIEN CENTER | 74 |
| 15 | ALIEN CENTER | 75 |
| 15 | ALIEN CENTER | 76 |
+---------+----------------+--------------+
11 rows in set (0.00 sec)
这个示例演示了outer连接如何在不限制查询返回的行数的情况下添加列值。如果不满足连接条件(就像本例中的Alice Fantasia),从外连接数据表中检索出的列值均为null。
10.1.1 左外连接与右外连接
在10.1节的外连接示例中指定的是left outer join。关键字left指明该连接左侧的数据表决定结果集的行数(结果集的行数等于左侧数据表查询的行数),而连接右侧的数据表只负责提供与之匹配的列值。也可以指定right outer join,由连接右侧的数据表决定结果集的行数(结果集的行数等于右侧数据表查询的行数),连接左侧的数据表提供列值。
下面使用right outer join代替left outer join,改写10.1节中最后一个查询:
mysql> SELECT f.film_id, f.title, i.inventory_id
-> FROM inventory i
-> RIGHT OUTER JOIN film f
-> ON f.film_id = i.film_id
-> WHERE f.film_id BETWEEN 13 AND 15;
+---------+----------------+--------------+
| film_id | title | inventory_id |
+---------+----------------+--------------+
| 13 | ALI FOREVER | 67 |
| 13 | ALI FOREVER | 68 |
| 13 | ALI FOREVER | 69 |
| 13 | ALI FOREVER | 70 |
| 14 | ALICE FANTASIA | NULL |
| 15 | ALIEN CENTER | 71 |
| 15 | ALIEN CENTER | 72 |
| 15 | ALIEN CENTER | 73 |
| 15 | ALIEN CENTER | 74 |
| 15 | ALIEN CENTER | 75 |
| 15 | ALIEN CENTER | 76 |
+---------+----------------+--------------+
11 rows in set (0.00 sec)
如果想要通过数据表A和B的外连接得到结果为A中的所有行和B中的匹配列,可以指定A left outer join B或者B right outer join A
因为很少(如果有的话)会遇到右外连接,而且也不是所有的数据库服务器都支持这种连接,因此推荐使用左外连接。outer关键字是可选的,你可以使用A left join B来代替,不过出于清晰性的考虑,最好还是加上outer。
10.1.2 三路外连接
有些情况下可能想要将一个数据表与另外两个数据表进行外连接。例如,可以扩展10.1.1节的查询,加入rental数据表的数据:
mysql> SELECT f.film_id, f.title, i.inventory_id, r.rental_date
-> FROM film f
-> LEFT OUTER JOIN inventory i
-> ON f.film_id = i.film_id
-> LEFT OUTER JOIN rental r
-> ON i.inventory_id = r.inventory_id
-> WHERE f.film_id BETWEEN 13 AND 15;
+---------+----------------+--------------+---------------------+
| film_id | title | inventory_id | rental_date |
+---------+----------------+--------------+---------------------+
| 13 | ALI FOREVER | 67 | 2005-07-31 18:11:17 |
| 13 | ALI FOREVER | 67 | 2005-08-22 21:59:29 |
| 13 | ALI FOREVER | 68 | 2005-07-28 15:26:20 |
| 13 | ALI FOREVER | 68 | 2005-08-23 05:02:31 |
| 13 | ALI FOREVER | 69 | 2005-08-01 23:36:10 |
| 13 | ALI FOREVER | 69 | 2005-08-22 02:12:44 |
| 13 | ALI FOREVER | 70 | 2005-07-12 10:51:09 |
| 13 | ALI FOREVER | 70 | 2005-07-29 01:29:51 |
| 13 | ALI FOREVER | 70 | 2006-02-14 15:16:03 |
| 14 | ALICE FANTASIA | NULL | NULL |
| 15 | ALIEN CENTER | 71 | 2005-05-28 02:06:37 |
| 15 | ALIEN CENTER | 71 | 2005-06-17 16:40:03 |
| 15 | ALIEN CENTER | 71 | 2005-07-11 05:47:08 |
| 15 | ALIEN CENTER | 71 | 2005-08-02 13:58:55 |
| 15 | ALIEN CENTER | 71 | 2005-08-23 05:13:09 |
| 15 | ALIEN CENTER | 72 | 2005-05-27 22:49:27 |
| 15 | ALIEN CENTER | 72 | 2005-06-19 13:29:28 |
| 15 | ALIEN CENTER | 72 | 2005-07-07 23:05:53 |
| 15 | ALIEN CENTER | 72 | 2005-08-01 05:55:13 |
| 15 | ALIEN CENTER | 72 | 2005-08-20 15:11:48 |
| 15 | ALIEN CENTER | 73 | 2005-07-06 15:51:58 |
| 15 | ALIEN CENTER | 73 | 2005-07-30 14:48:24 |
| 15 | ALIEN CENTER | 73 | 2005-08-20 22:32:11 |
| 15 | ALIEN CENTER | 74 | 2005-07-27 00:15:18 |
| 15 | ALIEN CENTER | 74 | 2005-08-23 19:21:22 |
| 15 | ALIEN CENTER | 75 | 2005-07-09 02:58:41 |
| 15 | ALIEN CENTER | 75 | 2005-07-29 23:52:01 |
| 15 | ALIEN CENTER | 75 | 2005-08-18 21:55:01 |
| 15 | ALIEN CENTER | 76 | 2005-06-15 08:01:29 |
| 15 | ALIEN CENTER | 76 | 2005-07-07 18:31:50 |
| 15 | ALIEN CENTER | 76 | 2005-08-01 01:49:36 |
| 15 | ALIEN CENTER | 76 | 2005-08-17 07:26:47 |
+---------+----------------+--------------+---------------------+
32 rows in set (0.01 sec)
10.2 交叉连接
在第5章中介绍了笛卡儿积的概念,本质上它就是在未指定任何连接条件的情况下的多数据表连接的结果。笛卡儿积经常会偶然用到(比如,忘记在from子句中添加连接条件),但是使用频率并不高。如果确实打算生成两个数据表的笛卡儿积,应该指定交叉连接(cross join),例如:
mysql> SELECT c.name category_name, l.name language_name
-> FROM category c
-> CROSS JOIN language l;
+---------------+---------------+
| category_name | language_name |
+---------------+---------------+
| Action | English |
| Action | Italian |
| Action | Japanese |
| Action | Mandarin |
| Action | French |
| Action | German |
| Animation | English |
| Animation | Italian |
| Animation | Japanese |
| Animation | Mandarin |
| Animation | French |
| Animation | German |
...
| Sports | English |
| Sports | Italian |
| Sports | Japanese |
| Sports | Mandarin |
| Sports | French |
| Sports | German |
| Travel | English |
| Travel | Italian |
| Travel | Japanese |
| Travel | Mandarin |
| Travel | French |
| Travel | German |
+---------------+---------------+
96 rows in set (0.00 sec)
那么交叉连接又有什么用处呢?大多数SQL相关书籍会先描述什么是交叉连接,然后告知交叉连接没有很多用处,但我想分享一个非常适合使用交叉连接的场景。
第9章中讨论过如何使用子查询加工数据表,演示了如何构建与其他数据表连接的3行数据表。下面是该示例中的加工后的数据表:
mysql> SELECT 'Small Fry' name, 0 low_limit, 74.99 high_limit
-> UNION ALL
-> SELECT 'Average Joes' name, 75 low_limit, 149.99 high_limit
-> UNION ALL
-> SELECT 'Heavy Hitters' name, 150 low_limit, 9999999.99 high_limit;
+---------------+-----------+------------+
| name | low_limit | high_limit |
+---------------+-----------+------------+
| Small Fry | 0 | 74.99 |
| Average Joes | 75 | 149.99 |
| Heavy Hitters | 150 | 9999999.99 |
+---------------+-----------+------------+
3 rows in set (0.00 sec)
假设你打算编写查询,为2020年的每一天生成一行,但是数据库中没有包含每天一行的数据表。如果使用第9章中的方法,你可能会这样做:
SELECT '2020-01-01' dt
UNION ALL
SELECT '2020-01-02' dt
UNION ALL
SELECT '2020-01-03' dt
UNION ALL
...
...
...
SELECT '2020-12-29' dt
UNION ALL
SELECT '2020-12-30' dt
UNION ALL
SELECT '2020-12-31' dt
更好的方法是下面的例子:
mysql> SELECT ones.num + tens.num + hundreds.num
-> FROM
-> (SELECT 0 num UNION ALL
-> SELECT 1 num UNION ALL
-> SELECT 2 num UNION ALL
-> SELECT 3 num UNION ALL
-> SELECT 4 num UNION ALL
-> SELECT 5 num UNION ALL
-> SELECT 6 num UNION ALL
-> SELECT 7 num UNION ALL
-> SELECT 8 num UNION ALL
-> SELECT 9 num) ones
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 10 num UNION ALL
-> SELECT 20 num UNION ALL
-> SELECT 30 num UNION ALL
-> SELECT 40 num UNION ALL
-> SELECT 50 num UNION ALL
-> SELECT 60 num UNION ALL
-> SELECT 70 num UNION ALL
-> SELECT 80 num UNION ALL
-> SELECT 90 num) tens
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 100 num UNION ALL
-> SELECT 200 num UNION ALL
-> SELECT 300 num) hundreds;
+------------------------------------+
| ones.num + tens.num + hundreds.num |
+------------------------------------+
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
...
...
...
| 391 |
| 392 |
| 393 |
| 394 |
| 395 |
| 396 |
| 397 |
| 398 |
| 399 |
+------------------------------------+
400 rows in set (0.00 sec)
如果生成{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}、{0, 10, 20, 30, 40, 50, 60, 70, 80, 90}和{0,100, 200, 300}这3个集合的笛卡儿积,并将这3列的值相加,就可以得到包含0~399的所有数值的400行结果集。可是这个行数超过了生成2020年天数集合所需的366行,消除这些额外的行很容易,随后将展示具体方法。
下一步是将数值集合转换为日期集合。为此,使用date_add()函数将结果集中的数值与2020年1月1日相加,然后添加过滤条件来排除2021年的所有日期:
mysql> SELECT DATE_ADD('2020-01-01',
-> INTERVAL (ones.num + tens.num + hundreds.num) DAY) dt
-> FROM
-> (SELECT 0 num UNION ALL
-> SELECT 1 num UNION ALL
-> SELECT 2 num UNION ALL
-> SELECT 3 num UNION ALL
-> SELECT 4 num UNION ALL
-> SELECT 5 num UNION ALL
-> SELECT 6 num UNION ALL
-> SELECT 7 num UNION ALL
-> SELECT 8 num UNION ALL
-> SELECT 9 num) ones
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 10 num UNION ALL
-> SELECT 20 num UNION ALL
-> SELECT 30 num UNION ALL
-> SELECT 40 num UNION ALL
-> SELECT 50 num UNION ALL
-> SELECT 60 num UNION ALL
-> SELECT 70 num UNION ALL
-> SELECT 80 num UNION ALL
-> SELECT 90 num) tens
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 100 num UNION ALL
-> SELECT 200 num UNION ALL
-> SELECT 300 num) hundreds
-> WHERE DATE_ADD('2020-01-01',
-> INTERVAL (ones.num + tens.num + hundreds.num) DAY) < '2021-01-01'
-> ORDER BY 1;
+------------+
| dt |
+------------+
| 2020-01-01 |
| 2020-01-02 |
| 2020-01-03 |
| 2020-01-04 |
| 2020-01-05 |
| 2020-01-06 |
| 2020-01-07 |
| 2020-01-08 |
...
...
...
| 2020-02-26 |
| 2020-02-27 |
| 2020-02-28 |
| 2020-02-29 |
| 2020-03-01 |
| 2020-03-02 |
| 2020-03-03 |
...
...
...
| 2020-12-24 |
| 2020-12-25 |
| 2020-12-26 |
| 2020-12-27 |
| 2020-12-28 |
| 2020-12-29 |
| 2020-12-30 |
| 2020-12-31 |
+------------+
366 rows in set (0.03 sec)
现在已经能构造出2020年中的每一天,这有什么用处呢?你可能会被要求生成一份报表,以展示2020年的每一天以及每一天的电影租借数量。该报表需要包含一年中的每一天,包括没有电影借出的天数。该查询如下所示(使用2005年的数据来匹配rental数据表中的数据):
mysql> SELECT days.dt, COUNT(r.rental_id) num_rentals
-> FROM rental r
-> RIGHT OUTER JOIN
-> (SELECT DATE_ADD('2005-01-01',
-> INTERVAL (ones.num + tens.num + hundreds.num) DAY) dt
-> FROM
-> (SELECT 0 num UNION ALL
-> SELECT 1 num UNION ALL
-> SELECT 2 num UNION ALL
-> SELECT 3 num UNION ALL
-> SELECT 4 num UNION ALL
-> SELECT 5 num UNION ALL
-> SELECT 6 num UNION ALL
-> SELECT 7 num UNION ALL
-> SELECT 8 num UNION ALL
-> SELECT 9 num) ones
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 10 num UNION ALL
-> SELECT 20 num UNION ALL
-> SELECT 30 num UNION ALL
-> SELECT 40 num UNION ALL
-> SELECT 50 num UNION ALL
-> SELECT 60 num UNION ALL
-> SELECT 70 num UNION ALL
-> SELECT 80 num UNION ALL
-> SELECT 90 num) tens
-> CROSS JOIN
-> (SELECT 0 num UNION ALL
-> SELECT 100 num UNION ALL
-> SELECT 200 num UNION ALL
-> SELECT 300 num) hundreds
-> WHERE DATE_ADD('2005-01-01',
-> INTERVAL (ones.num + tens.num + hundreds.num) DAY)
-> < '2006-01-01'
-> ) days
-> ON days.dt = date(r.rental_date)
-> GROUP BY days.dt
-> ORDER BY 1;
+------------+-------------+
| dt | num_rentals |
+------------+-------------+
| 2005-01-01 | 0 |
| 2005-01-02 | 0 |
| 2005-01-03 | 0 |
| 2005-01-04 | 0 |
...
| 2005-05-23 | 0 |
| 2005-05-24 | 8 |
| 2005-05-25 | 137 |
| 2005-05-26 | 174 |
| 2005-05-27 | 166 |
| 2005-05-28 | 196 |
| 2005-05-29 | 154 |
| 2005-05-30 | 158 |
| 2005-05-31 | 163 |
| 2005-06-01 | 0 |
...
| 2005-06-13 | 0 |
| 2005-06-14 | 16 |
| 2005-06-15 | 348 |
| 2005-06-16 | 324 |
| 2005-06-17 | 325 |
| 2005-06-18 | 344 |
| 2005-06-19 | 348 |
| 2005-06-20 | 331 |
| 2005-06-21 | 275 |
| 2005-06-22 | 0 |
...
| 2005-12-27 | 0 |
| 2005-12-28 | 0 |
| 2005-12-29 | 0 |
| 2005-12-30 | 0 |
| 2005-12-31 | 0 |
+------------+-------------+
365 rows in set (8.99 sec)
这是到目前为止本书中最有趣的查询之一,因为其中涉及交叉连接、外连接、日期函数、分组、集合运算(union all)和聚合函数(count())。当然,这并不是对于该问题的最优雅的解决方法,但它可以作为一个示例,说明只要有一点创造力,再加上对语言的深刻把握,你甚至可以将交叉连接这个很少被用到的特性变成你的SQL工具箱中的得力工具。
10.3 自然连接
你可以选择一种连接类型,其允许命名要连接的数据表,但是由数据库服务器决定需要什么样的连接条件。这种连接类型被称为自然连接(natural join),它依靠多个数据表之间相同的列名来推断适合的连接条件。例如,rental数据表包含customer_id列,该列是customer数据表的外键,customer数据表的主键名也是customer_id。因此,可以尝试编写查询,使用自然连接来连接这两个数据表:
mysql> SELECT c.first_name, c.last_name, date(r.rental_date)
-> FROM customer c
-> NATURAL JOIN rental r;
Empty set (0.04 sec)
因为指定了自然连接,所以数据库服务器检查数据表定义并添加了连接条件r.customer_id = c.customer_id。在本例中,这么做没有问题,但在Sakila数据库中(书中的示例数据库),所有的数据表都包含last_update列,以指明每行最后被修改的时间,因此,数据库服务器也会添加连接条件r.last_update = c.last_update,这会造成查询没有返回任何数据。
解决该问题的唯一方法是使用子查询来限制其中至少一个数据表的列:
mysql> SELECT cust.first_name, cust.last_name, date(r.rental_date)
-> FROM
-> (SELECT customer_id, first_name, last_name
-> FROM customer
-> ) cust
-> NATURAL JOIN rental r;
+------------+-----------+---------------------+
| first_name | last_name | date(r.rental_date) |
+------------+-----------+---------------------+
| MARY | SMITH | 2005-05-25 |
| MARY | SMITH | 2005-05-28 |
| MARY | SMITH | 2005-06-15 |
| MARY | SMITH | 2005-06-15 |
| MARY | SMITH | 2005-06-15 |
| MARY | SMITH | 2005-06-16 |
| MARY | SMITH | 2005-06-18 |
| MARY | SMITH | 2005-06-18 |
...
| AUSTIN | CINTRON | 2005-08-21 |
| AUSTIN | CINTRON | 2005-08-21 |
| AUSTIN | CINTRON | 2005-08-21 |
| AUSTIN | CINTRON | 2005-08-23 |
| AUSTIN | CINTRON | 2005-08-23 |
| AUSTIN | CINTRON | 2005-08-23 |
+------------+-----------+---------------------+
16044 rows in set (0.03 sec)
那么,为了省事而不输入连接条件到底值不值得呢?绝对不值得,应该避免使用这种连接类型,而使用带有显式连接条件的内连接。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









