







一、简介
- 一个非监督的机器学习算法
- 主要用于数据的降维
- 通过降维,可以发现更便于人类理解的特征
- 其他特征:可视化;去噪

- 从二维降到一维
二、问题
- 保留原有样本的特征?
- 如何找到这个让样本间距最大的轴
- 如何定义样本间间距
- 使用方差



三、主成分分析法
-
第一步:将样例的均值归为0
-
所有的样本减去样本的均值
-
得到的新样本的均值为0
-


-
由于进行了demean处理,其均值为0,可以转化为下图方差公式



-
如何使用梯度上升法?





四、求数据的前N个主成分


import numpy as np
class PCA:
def __init__(self, n_components):
"""初始化PCA"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""获得数据集X的前n个主成分"""
assert self.n_components <= X.shape[1], \
"n_components must not be greater than the feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
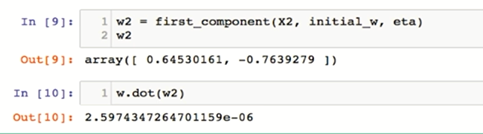
def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
# 求第一主成分
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
self.components_[i,:] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""将给定的X,映射到各个主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""将给定的X,反向映射回原来的特征空间"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
-
主成分分析之后各第几主成分互相垂直

-
高维数据向低维数据映射

-
低维数据向高维数据转换


from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)


- 方差

- 每个主成分的方差




五、MNIST
import numpy as np
from sklearn.datasets import fetch_mldata # 从官方网站下载数据集
mnist = fetch_mldata('MNIST original')
X,y = mnist['data'],mnist['target']
from sklearn.datasets.base import get_data_home
print (get_data_home()) # 如我的电脑上的目录为: C:\Users\95232\scikit_learn_data

X_train = np.array(X[:60000],dtype=float)
y_train = np.array(y[:60000],dtype=float)
X_test = np.array(X[60000:],dtype=float)
y_test = np.array(X[60000:],dtype=float)

from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
%time knn_clf.fit(X_train,y_train)

%time knn_clf.score(X_test,y_test)
- 使用PCA降维
from sklearn.decomposition import PCA
pca = PCA(0.9)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
knn_clf = KNeighborsClassifier()
%time knn_clf.fit(X_train_reduction,y_train)
X_test_reduction = pca.transform(X_test)
%time knn_clf.score(X_test_reduction,y_test)
可能由于数据维度太多,KNN算法计算量太大,并不能进行很好的预测分类,并不能得出结果

- 但是理论上是,PCA降维后比未降维前的数据,预测准确率更高。
- 原因是PCA降维算法有个降噪的强大功能
六、使用PCA降噪
- 手写识别的例子降噪
from sklearn import datasets
digits = datasets.load_digits()
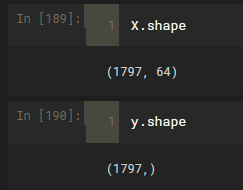
X = digits.data
y = digits.target
设置噪音值
noisy_digits = X + np.random.normal(0,4,size = X.shape)
和X值链接
example_digits = noisy_digits[y==0,:][:10]
for num in range(1,10):
X_num = noisy_digits[y==num,:][:10]
example_digits = np.vstack([example_digits,X_num])
# vstack链接在一起
绘制图像
def plot_digits(data):
fig,axes = plt.subplots(10,10,figsize=(10,10),
subplot_kw = {'xticks':[],'yticks':[]},
gridspec_kw = dict(hspace=0.1,wspace=0.1))
for i,ax in enumerate(axes.flat):
ax.imshow(data[i].reshape(8,8),
cmap='binary',interpolation='nearest',
clim = (0,16))
plt.show()
plot_digits(example_digits)

PCA降噪
pca = PCA(0.5)
pca.fit(noisy_digits)

pca.n_components_
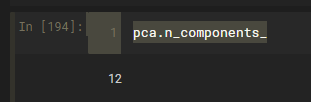
降到了12维
components = pca.transform(example_digits)
components #降维后的结果

绘制由降维的数据转化为原始维度的数据
filtered_digits = pca.inverse_transform(components)
# 转化未降维之前的数值,不过去过了噪音值
plot_digits(filtered_digits)

从图中可以明显看出噪音点降低了
七、特征脸

import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people()

faces.keys()

random_indexes = np.random.permutation(len(faces.data))
X = faces.data[random_indexes]


def plot_faces(data):
fig,axes = plt.subplots(6,6,figsize=(10,10),
subplot_kw = {'xticks':[],'yticks':[]},
gridspec_kw = dict(hspace=0.1,wspace=0.1))
for i,ax in enumerate(axes.flat):
ax.imshow(faces[i].reshape(62,47),
cmap='bone')
plt.show()
plot_faces(example_faces)




== PCA降维==















 65万+
65万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









