









论文题目:Timeception for Complex Action Recognition
大家好,今天我来介绍关于视频行为识别领域一篇文章《Timeception for Complex Action Recognition》。该文章主要聚焦于如何构建一种时序层来进行行为识别,这个时序层在文章中被称作Timeception Layer。那么提出这个时序层的出发点在哪呢?原因是传统的3D卷积采用固定的kernel size作用在复杂动作的时间范围上时,过于僵化而无法捕捉到变化,而在长的时序上建模时,过于短暂。这篇文章的新颖之处在于:
- 引入一个Timeception Layer,有效地学习1024个timestamps的分钟长动作范围,比最佳相关工作长8倍。
- 引入多尺度时间核来解释动作成分持续时间的巨大变化。
- 使用temporal-only卷积,这比时空卷积更适合复杂的动作。
接下来,我将从一下几个方面对这篇文章进行阐述,首先介绍文章中提及的一些基本概念;接着阐述行为识别时序方面相关工作;紧接着介绍文章的方法部分,这是文章的核心;最后阐述相关的实验。
首先介绍一些基本概念,这些概念也是作者创作这篇文章的初衷。下面粗体是对这些概念的解释。具体概念形象化,请看图1。在最近的文献中,行为识别主要关注于short-range行为变化,如数据集HMDB-51,UCF-101和Kinetics,很少有研究关注long-
单一行为(one actions):时间短,动作均匀,动作行为在时间上是一致的。比如:跳(jumping),切黄瓜(cut a cucumber)。
复杂行为(complex actions):由多个单一动作构成,在时间上和顺序上,这些单一动作呈现出巨大的变化,复杂行为需要花费很多时间来展开。在构成的均匀性方面,复杂的动作需要全部取样,不漏检关键部位。比如:打扫房间,做饭等行为。
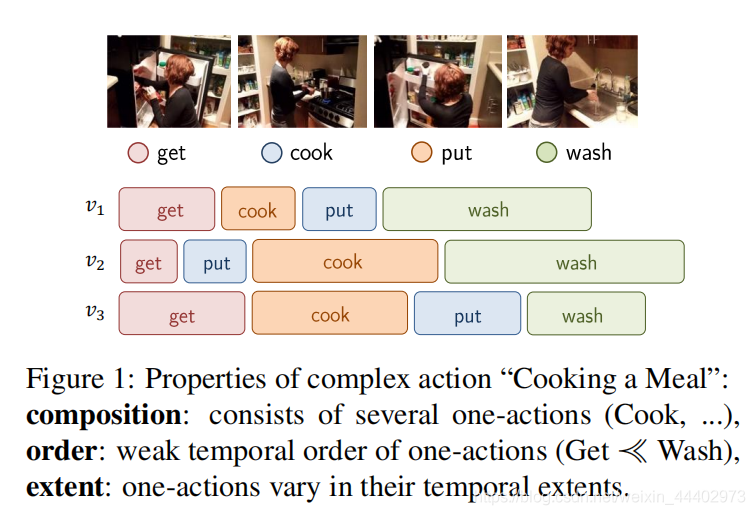
图1 复杂行为的属性图
range和complex actions,比如数据集Charades和EventNet。而这篇文章的关注点就是long-range和complex actions。当然,我提到的这些数据集都是我们做行为识别研究所需要实验的beachmark数据集,需要的可以自行下载。
接下来阐述行为识别时序方面相关工作。有传统机器学习方法,比如广泛使用的方法是statistical pooling:max and average pooling, attention pooling , rank pooling , dynamic images and context gating ,举几个例子。除了statistical pooling之外,还使用vector aggregation。使用扩展VLAD从视频帧提取的局部卷积特征。统计池和向量聚合的缺点是完全忽略了时间这一重要的视觉线索。不过目前使用最多的就是深度学习的方法,从捕获时序信息角度来看,可以分为三类:
Short-range Action Recognition
很少有研究使用2D CNNs通过动作的帧级分类来学习深层的外观特征。其他方式使用浅层运动特征补充深层外观特征,如IDT。此外,辅助图像表示与RGB信号融合:如使用光流通道,使用动态图像。三维CNN是二维CNN的自然演化。C3D提出了3D CNNs来捕获序列中8帧的时空模式。同样的,I3D扩展了ImageNetV pretrained 2D CNN的卷积核来对3D CNN进行训练,虽然在短距离视频序列(几秒)中有效,但3D卷积的计算代价太高,无法处理一分钟长的视频。
Long-range Action Recognition
为了学习long-range时间模式,在CNN特征图的基础上使用CRF来模拟人类活动。为了学习视频范围的表示,TRN学习几个视频片段之间的关系。TSN学习长视频中的时间结构。而LTC认为不同的时间分辨率可以替代更大的时间窗口。non-local networks提出了128个时间步长的深度卷积网络。所有上述方法都成功地建模了128个时间步(4-5秒)的时间足迹,在这项工作中,作者同时处理了1024个时间步的长时间依赖的复杂动作。
Convolution Decomposition
CNN成功地学习了空间和时空动作概念,但是现有的卷积在计算中变得更重,特别是在通道数目可以增长到2K的较高层。为了控制计算复杂度,一些工作提出了2D和3D卷积的分解。Xception认为,可分离的二维卷积与典型的二维卷积一样有效。类似地,S3D考虑可分离的2 +1D卷积以减少典型的3D卷积的复杂性。ResNet在应用昂贵的3×3 2D空间卷积之前,使用1×1 2D卷积来减小通道尺寸。ShuffleNet通过通道shuffle而不是1×1 2D卷积在交叉信道相关上建模。ResNeXt提出了分组卷积,而Inception则主张使用不同大小的多尺度空间核来分解大型二维空间核。
在这篇文章中,作者提出了将时空三维卷积分解为可分离的深度时间卷积的方法,这更适合于2+1D卷积的long-range时间建模。此外,为了考虑时间范围的差异,文章提出了使用多尺度核的时间卷积。
经过上面介绍,相信各位已经理解了本文创作的出发点。接下来,我来介绍本文的重点方法部分。为了设计好的时空CNNs,作者提出了几个原则:
(1)Subspace Modularity(子空间模块化):在深度网络级联的情况下,分解应该是模块化的,这样子空间之间应该保留后续层中各自子空间的性质。即,在空间卷积和时间卷积的级联之后,空间卷积和时间卷积的又一个级联是可能的和有意义的
(2)Subspace Balance(子空间平衡):分解应确保子空间之间保持平衡,并在不同层中进行参数化。即,增加为一个特定子空间建模的参数数量应该以减少另一个子空间的参数数量为代价。一个典型的例子是传统的2D-CNN,它在扩展语义信道子空间的同时减少了空间子空间。
(3)Subspace Effificiency(子空间效率):在为特定任务设计分解时,应该确保可用参数预算的大部分专用于与任务直接相关的子空间。这是TL(Timeception Layer)设计的关键。
接下来介绍TL层,TL(Timeception Layer)层要达到的目标:学习整个视频中单一动作之间可能存在的long range依赖关系,以及一个长达1000个时间步的帧序列;其次,能够容忍整个视频中单一动作的时间范围的变化。最后提出的TL层在CNN之后,这个CNN可以是空间2D CNN,也可以short-range时空CNN。下面对TL层如何达到设计目标的相关探索进行介绍:
Long-range Temporal Dependencies
为了建模整个视频中的one-action之间的长时间依赖关系,需要考虑两种sequences,一种是通过堆叠多个时序层来学习抽象和复杂的时空特征表示;二是时序层上花费的代价是高效的。为了使Timeception层在时间上具有成本效益,根据上面提到的子空间重要性的第三设计原则(Subspace Effificiency),作者选择了较长的时序窗口来对空间和语义复杂度进行平衡,具体地说,提出了T×1×1×1(T为时序卷积感受野)的可分离时序卷积(temporal-only),该可分离时序卷积只关注在时间维度上建模,而忽略空间信息。因此,Timeception层完全依赖于前面的CNN提取的空间信息。与此同时,temporal-only时序卷积核具有一些性质,即,每个核只作用于一个通道。由于核不扩展到通道子空间,因此它们学习泛型和抽象的、而不是语义特定的时间组合。通过一个接一个地叠加仅时序卷积(temporal-only),long-range时空模式中的语义子空间被忽略了,为此,在temporal-only卷积之前进行通道分组操作和在temporal-only卷积之后的信道shuffle操作。通道分组的目的是编码跨通道相关性。显然,由于每组都包含一个随机的通道子集,所以并不是所有可能的相关性都被考虑在内,然而,这可以通过通道shuffle和通道concat来减轻,这样可以确保通道以不同的顺序组合在一起。因此,下一个Timeception层将对通道的不同子集进行分组。总之,通道分组和通道shuffle是比1×1 2D卷积更具成本效益的学习跨通道相关性的操作。
Tolerating Variant Temporal Extents
TL层设计的第二个目标是容忍复杂动作在时间范围内的变化。在前面的描述中,使用了长度是固定的temporal-only时序卷积核,而复杂视频中的one-action的长度可能会发生变化,为此,作者提出用多尺度的时态核来代替fixed时序卷积核。实现多尺度核有两种可能的方法,具体图2,第一种方法受Inception对图像的启发,采用K个size核,每个核的大小都不同。第二种方法受空洞卷
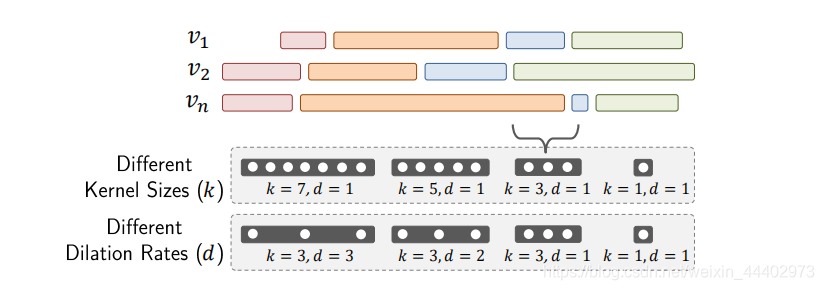
图2 通过多尺度时序卷积和空洞卷积来捕获复杂视频中的one-action的长度的变化
积。具体时序卷积模块,该卷积模块是构成TL层的关键,如图3所示,采用通道每个分组作为输入Xn,采用了5个时序卷积运算。前三个操作是核大小为k={3,5,7}的时间卷积,每个操作都保持C/N.第四个操作是一个时序最大池,步长s=1,卷积核大小
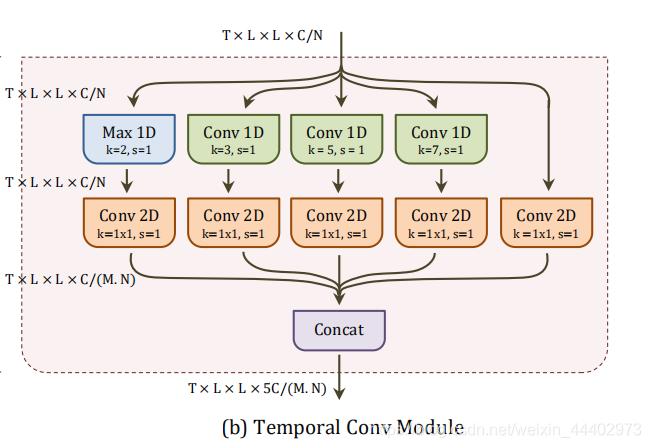
图3 时序卷积模块
k=2。它的目的是在局部时间窗口(k=2)上最大化激活,而不是卷积它们。第五个操作是使用1×1空间卷积对输入特征Xn进行简单的降维。为了保持输出的维数可控,前四个操作的输入用1×1的空间卷积缩小了一个M的因子。在通道减少之后,所有五个输出在通道维度上串联起来,从而产生TL层的最终输出。最终TL层如图4所示,TL层期望网络中前一层的输入特征X∈RT×L×L×C。然后将通道维数上的特征X划分为N个通道组Xn∈RT×L××L×[C/N]。每个通道组被时间卷积模块卷积。导致Yn∈RT×L××L×[5C/MN]。该模块将每个组的通道数扩展为5/M的因数。之后,所有分组的特征在通道维度上串联,然后随机地shuffle。最后,为了遵循子空间平衡的第二个设计原则,TL层以核大小k=2和步长s=2的时序最大池作为结束,其原因是当通道子空间在每个时间概念层后扩展5/M因子时,相应的时序子空间则收缩2个因子。
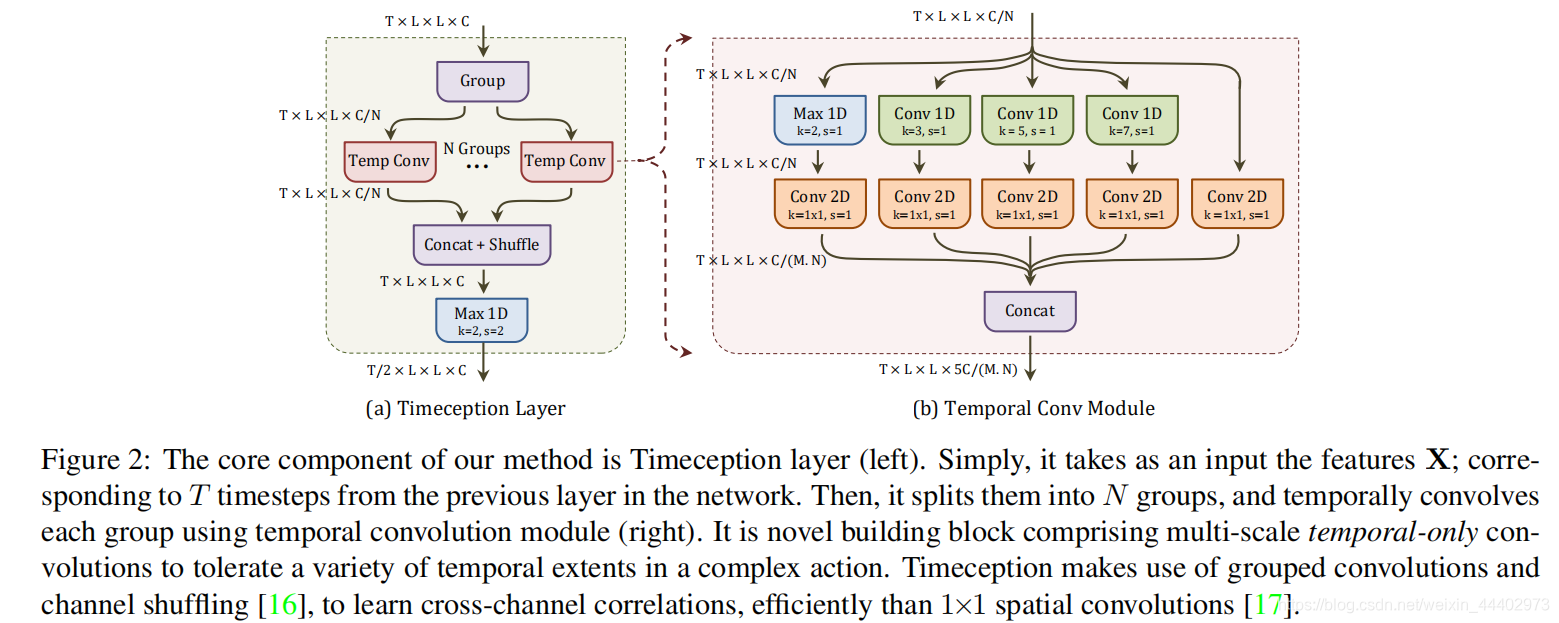
图4 时序卷积层
上面就是对TL层的详细介绍,可能表述上有问题,但是具体大家可以看看原文。为了将TL层应用于网络,作者使用了两个backbone模型,第一个是2D CNN,具体采用ResNet-152,取前res5c层来提取空间特征;第二个是3D CNN,具体采用I3D,取前mixed-5c层。分别在这些层之后添加TL层,构成最终模型。
最后是实验部分,作者验证了TL层中采用了多尺度时序卷积重要性,如图5所示。图6显示,当使用ResNet和I3D作为主干架

图5 多尺度时序卷积和fixed实验对比
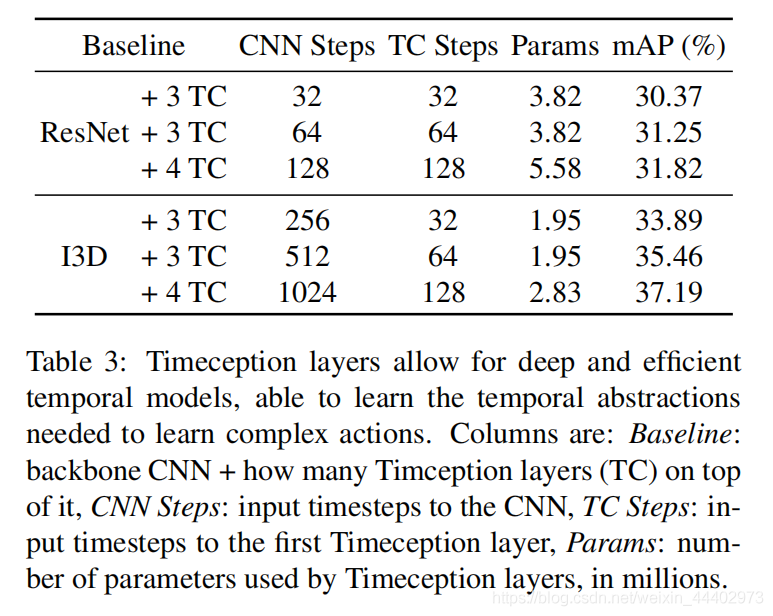
图6 不同基模型+不同CNNstep+不同TC steps对比
构时,堆叠的TL层可以提高精度。由于这些模型之间唯一的变化是Timeception Layers的数量,作者推断Timeception Layers已经成功地学习了时序抽象。第二,尽管叠加了越来越多的TL层,但参数的数量是可控的。有趣的是,在I3D处理1024个时间步时使用4个TL层需要ResNet处理128个时间步所需的一半参数。原因是ResNet返回的特征图数量是I3D(2048v.s.1024)的两倍。可以得出结论是TL层采用深的时序和高效的模型,能够学习复杂动作所需的long-range时间抽象。图7显示了采用TL层模型和state of the art模型对比。

图 7 模型对比














 9651
9651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









