






go语言
基础语法

也需要主程序的入口:


执行Go程序:注意要是使用命令行来运行go程序记得要先进入程序文件保存的目录中。
同时注意 { 不能单独放在一行,
package main
import "fmt"
func main()
{//报错,{不能在单独的行上
fmt.Println("hello,world")
}
不需要每个语句使用;来结束,每一行代表一个语句的结束。
标识符
用来命名变量,类型等程序实体。标识符由一个或多个字母(包含大小写)数字(0-9)和下划线_组成的序列。第一个必须是字母或者下划线,不能是数字。
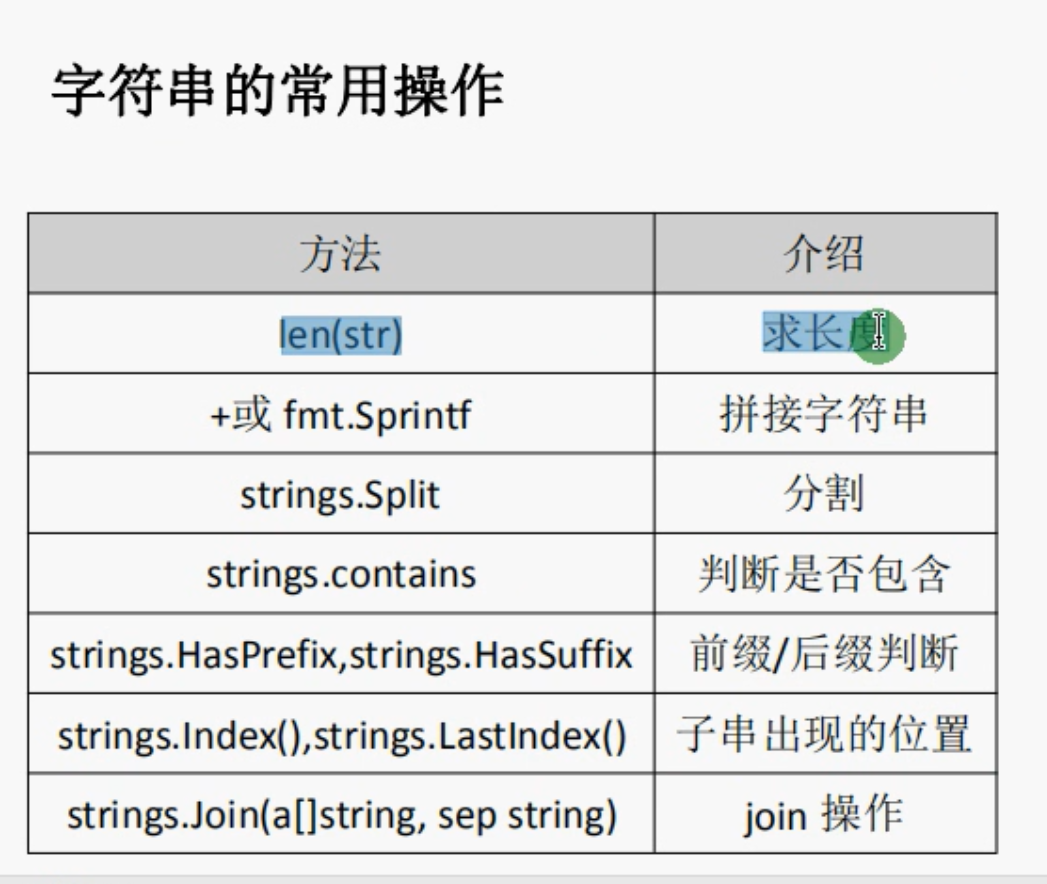
字符串的连接
Go语言字符串可以通过+实现
字符串转义符
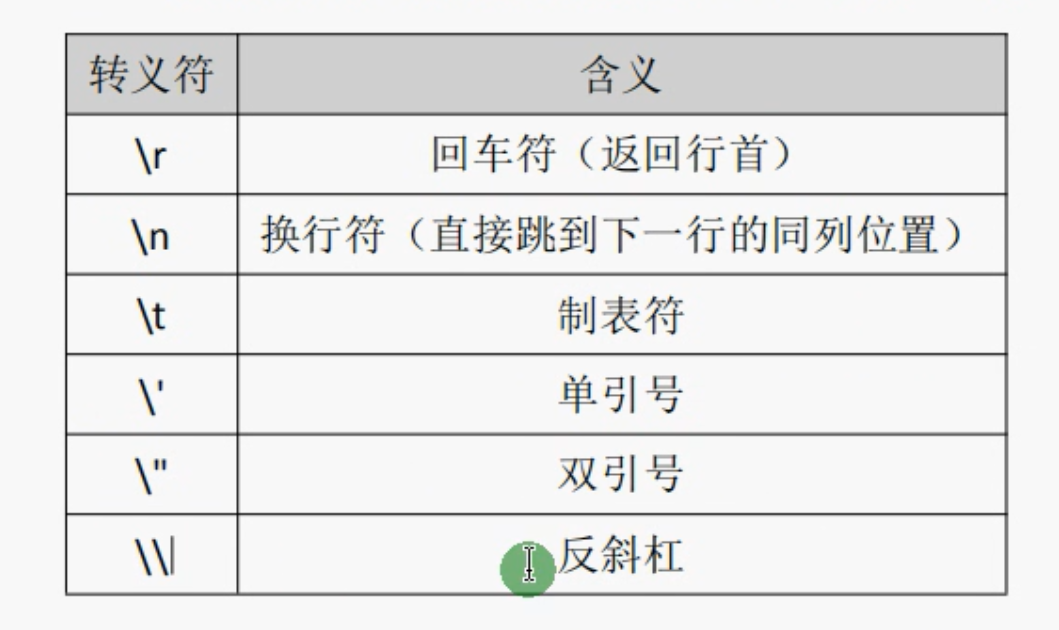
多行字符串,用反引号``
str := `dj
jgj
jjjj
jjj`
fmt.Println(str)
//输出按照格式输出
jgj
jjjj
jjj
用到fmt,strings都得import包在开头。
str := "12-34-565-3"
a3 := strings.Split(str, "-")
fmt.Println(a3)
//输出:[12 34 565 3]
sr := strings.Join(a3, "*")
fmt.Println(sr)
//输出:12*34*565*3
关键字
数据类型
在Go编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需的内存大小不同的数据,编程的时候用大数据就申请大内存,可以充分利用内存。
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔类型:布尔型的值只可以是常量true,false |
| 2 | 数字类型:整型int,浮点型float32,float64,go语言支持整型和浮点型,并且支持复数,位运算用补码的形式 |
| 3 | 字符串类型:字符串就是一串固定长度的字符连接起来的字符序列。go的字符串由单个字节连接起来的。 |
| 4 | 派生类型:指针,数组,结构化,channel,函数,切片,接口,map |
布尔类型
没什么说的,就是true and false
注意:
1.布尔类型变量的默认值为false。 没有赋值的情况下。int默认为0,float也为0
2.Go语言中不允许将整型强制转换为布尔型.
3.布尔型无法参与数值运算,也无法与其他类型进行转换。
整型
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8 无符号 8 位整型 (0 到 255) |
| 2 | uint16 无符号 16 位整型 (0 到 65535) |
| 3 | uint32 无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64 无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8 有符号 8 位整型 (-128 到 127) |
| 6 | int16 有符号 16 位整型 (-32768 到 32767) |
| 7 | int32 有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64 |
var w int8 = 43
int类型转换
var a1 int32 = 10
var a2 int64 = 21
fmt.Println(int64(a1 + a2)) //把32位转成64位
利用unsafe.Sizeof(n1) 来返回n1变量占用的字节数。是unsafe包的一个函数。
浮点型
| 序号 | 类型和描述 |
|---|---|
| 1 | float32 IEEE-754 32位浮点型数 |
| 2 | float64 IEEE-754 64位浮点型数 //默认是这个 |
| 3 | complex64 32 位实数和虚数 |
| 4 | complex128 64 位实数和虚数 |
科学计数法
var f1 = 1.14e2 //表示1.14*10^2
golang中有float精度丢失问题。
int类型转换成float,float类型转换成int
a1 := 333
a2 := float64(a1)
fmt.Printf("a1的类型是%T,a2的类型是%T",a1,a2) //输出是int float
n1 := 3.33
n2 := int(n1)
fmt.Printf(n1,n2) //输出是3.33,3 自动舍弃了小数部分。
字符的类型:

一个汉字占用3个字节
注意:Sprintf 使用中需要注意转换的格式
int为%d
float为%f
bool为%t
byte为%c
通过strcov,把其他类型转成string
i := 43
sre := strconv.FormatInt(int64(i), 10)
fmt.Printf("值:%v 类型:%T", sre, sre)
///输出:值:43 类型:string
//FormatFloat函数参数
//参数 1:要转换的值
//参数2:格式化类型'f'(-ddd.dddd)、
//'b'(-ddddptddd,指数为二进制)、e'(-d.ddddetdd,十进制指数)、
//'E'(-d.ddddE+dd,十进制指数)、g'(指数很大时用'e'格式,否则'f'格式)、
//'G'(指数很大时用'E'格式,否则'f'格式)。
//参数3:保留的小数点-1(不对小数点格式化)
//参数4:格式化的类型传入6432
var i float32 = 3.23245
sre := strconv.FormatFloat(float64(i), 'f', 6, 32)
fmt.Printf("值:%v 类型:%T", sre, sre)
遇到包不能使用就在终端写入go get xxx
复合类型
Go语言变量
go语言变量名由字母,数字,下划线组成,其中首个字符不能是数字。变量一旦定义就一定要使用,否则报错。
声明变量的一般形式是使用关键字var:
var 变量名 type //一个变量
var 变量名,变量名 type //多个变量
//实例
package main
import "fmt"
func main(){
var a string = "runood"
fmt.Println(a)
var b,c int = 1,2
fmt.Println(b,c)
var (
d = "zehang"
e = 3
)
fmt.Println(d,e)
}
也可以用类型推导方式定义变量:这种方式也是推荐用法。
变量名 := 表达式,这种只能用于声明局部变量、不能用于全局变量
a := 10
b := 20
fmt.Printf("a=%v a的类型是%T",a,a)//输出结果就是a=10 a的类型是int
变量如果未初始化,则为空。
fmt包一般是打印的包
快速注释用快捷键ctrl+/
初始化三种方法(推荐第三种)
var a1 string
a1 = "dfdf"
var a2 string = "dfgg"
var username = "张三"
fmt.Println(username)
go语言中的变量需要声明后才能使用,同一作用域内不支持重复声明。
匿名变量 在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量。
匿名变量用一个下划线_来表示
//定义一个方法
func getUserinfo(string,int){ //返回值的类型
return "zhangsan",20
}
var username,_ = getUserinfo()//这里忽略了age,直接就用_来表示。
fmt.Println(username)
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。
变量的命名是区分大小写的。
变量命名一般采用驼峰命名方法
maxAge:小驼峰 表示私有
MaxAge:大驼峰 表示公有
Go语言中的常量
常量用const关键字来定义。不仅可以是数字还能是字符串,而且只要一声明就无法改变了,和变量完全不同。
多个常量可以一起声明
const(
A = "A"
B = 23
)
fmt.Println(A,B)
const 同时声明多个变量时,如果省略了值则表示和上面一行的值相同
const(
n1 = 200
n2
n3
)
//这里n2,n3等于n1
iota是go语言中的计数器,自增
iota在const关键字中出现时将被重置为0
const(
n1 = iota //0
_ //1
n2 = 100 //100 可以插队
n3 = iota //2
n4 //3
)
运算符
算数运算符
+相加
-相减
*相乘
/相除
%求余=被除数-(被除数/除数)*除数
1、除法注意:如果运算的数都是整数,那么除后,去掉小数部分,保留整数部分。如果是float类型则保存小数部分
2、取余注意 余数=被除数-(被除数/除数)*除数
3、注意:++(自增)和–(自减)在Go语言中是单独的语句,并不是运算符。不能用于赋值。只有i++,没有++i

逻辑运算符

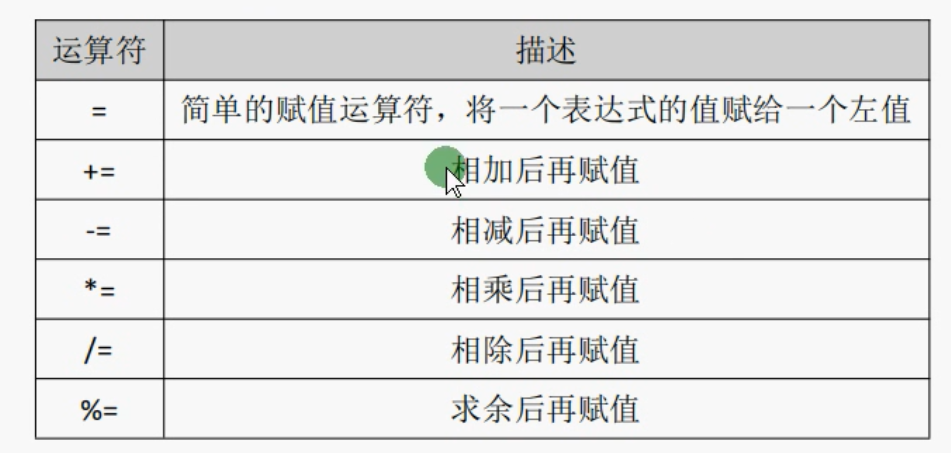
赋值运算符
除法一定要多注意
位运算符
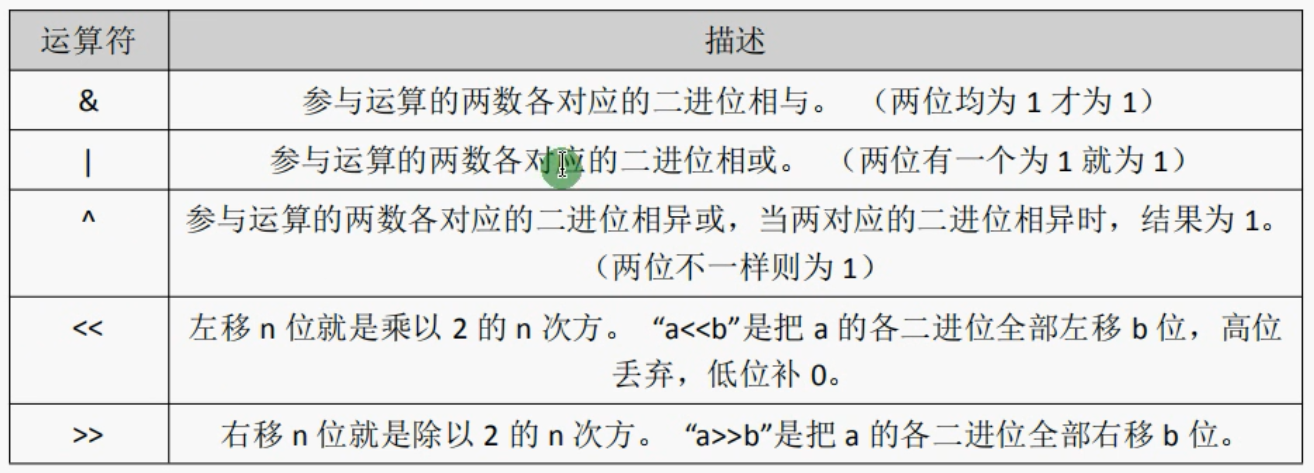
注意这里前两个,不是逻辑运算符,只是对数的二进制进行与或运算。
if条件语句
两种写法
age := 30
if age >20{
fmt.Println("成年人")
}
//第二种
if age := 32; age>20{
fmt.Println("成年人")
}
两种写法的区别:
第一种:age是全局变量,第二种是局部变量
var score = 94
if score >= 90{
fmt.Println("A")
}else if score >75{
fmt.Pirntln("b")
}else{
fmt.Println("c")
}
//第二种写法
if score := 75; score >= 90{
fmt.Println("A")
}else if score >75{
fmt.Pirntln("b")
}else{
fmt.Println("c")
}
要注意的细节:
- if语句中的{}是一定不能省略的,就算只有一条语句
- 大括号的左括号不能放在下一行
循环语句
for 初始语句;条件语句;结束语句{
循环体语句
}
//一次执行顺序
1.初始语句
2.条件语句
3.循环体语句
4.结束语句
//打印1-10的数字
//第一种
for i := 1; i <= 10; i++{
fmt.Println(i)
}
//第二种
i := 1
for i<= 10{
fmt.Println(i)
i++
}
for循环的初始语句和结束语句都能省略,
还有一种无限循环类似于while语句。
for{
循环体语句
}
//要配合if语句和break跳出循环
for{
if i <=10{
fmt.Println(i)
}else{
break
}
i++
}
for range语句
var arr = []string{"php","java","node","golang"}
for key,valu := range arr {
fmt.Printf("第%v种编程语言",key,"名字为:",valu)
}
switch语句
break,continue,goto语句
break
for i := 0; i <= 10; i++{
if i == 2{
break
}
fmt.Println(i)
}
//输出
0
1
//这就说明直接跳出了整个循环,而和continue不同。
还有结合label的用法,可以跳出多重循环
label(名字随便起):(冒号是必须)
for i := 0; i <= 2;i++{
for j := 0; j <= 5;j++{
fmt.Printf("i的值:%v,j的值:\n",i,j)
if j == 3{
break label
}
}
}
continue
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。
for i := 0; i <= 2; i++ {
for j := 0; j <= 5; j++ {
if j == 3 {
continue
}
fmt.Printf("i的值:%v,j的值:%v\n", i, j)
}
}
//输出
i的值:0,j的值:0
i的值:0,j的值:1
i的值:0,j的值:2 //缺了三
i的值:0,j的值:4
i的值:0,j的值:5
i的值:1,j的值:0
i的值:1,j的值:1
i的值:1,j的值:2
i的值:1,j的值:4
i的值:1,j的值:5
i的值:2,j的值:0
i的值:2,j的值:1
i的值:2,j的值:2
i的值:2,j的值:4
i的值:2,j的值:5
结合label的用法
label2:
for i := 0; i <= 2; i++ {
for j := 0; j <= 5; j++ {
if j == 3 {
continue label2
}
fmt.Printf("i的值:%v,j的值:%v\n", i, j)
}
}
//输出
i的值:0,j的值:0
i的值:0,j的值:1
i的值:0,j的值:2
i的值:1,j的值:0
i的值:1,j的值:1
i的值:1,j的值:2
i的值:2,j的值:0
i的值:2,j的值:1
i的值:2,j的值:2
//这里就跳出了整个循环,然后j在2后面的数也不循环了,然后继续下面的循环。
goto语句
goto语句通过标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。Go语言中使用goto语句能简化-些代码的实现过程。
var n = 39
if n >= 20 {
fmt.Printf("cnianren")
fmt.Printf("cnianren")
goto label4
fmt.Printf("cn")//没有执行
fmt.Printf("cnia")//没有执行
}
label4
fmt.Printf("anren")
fmt.Printf("cnian")
//输出
cnianren
cnianren
anren
cnian
数组
数组的定义
var 数组变量名 [元素数量]元素类型
var a [3]int
var b [5]int
var c [3]string
fmt.Printf("a数组的类型%T,b数组的类型%T,c数组的类型%T", a, b, c)
//输出
a数组的类型[3]int,b数组的类型[5]int,c数组的类型[3]string
数组的长度一旦定义就不能改变了
如果要改变就用切片
//数组的初始化方法
//第一种
var a [3]int
a[0] = 4
//第二种
var b = [4]int{3,4,5,7}
fmt.Println(b)
第三种定义数组的方式
var c = [...]int{3,4,56,564,75,4323,56}
//...三个点代表数组长度可以同推导的方式获得。 但是这样也是确定数量的数组,也同样不能直接添加新元素
//改变数组的值
c[1] = 345
fmt.Println(c)
//输出
[3 345 56 564 75 4323 56]
第四种定义数组的方式
d := [...]int{0:2,4:5,6:44} //根据下表来定义数组,没有写出的小标所对应的值为0
fmt.Println(d)
//输出
[2 0 0 0 5 0 44]
数组的循环遍历
d := [...]int{0:2,4:5,6:44}
for k,v := range d {
fmt.Println(k,v)
}
值类型,引用类型
值类型:数组是值类型,赋值和传参会复制整个数组。因此改变副本的值,不会改变本身的值
引用类型:因此改变副本的值,会改变本身的值
arr1 = [...]int{2,32,5,6,75}
arr2 = arr1
//这时是将开辟了新内存然后拷贝了一份arr1,将这个数组给了arr2,这时改变arr1不会影响arr2的值
引用类型:
//切片
arr1 = []int{2,32,5,6,75}
arr2 = arr1
//这里是用了指针的概念。当将arr1赋值给arr2时,没有开辟新的内存空间,而是将arr2的指针指向了arr1所对应的内存空间,如果arr1改变了那么arr2也会改变。
数组是值类型,切片是引用类型
切片
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
数组和slice之间有着紧密的联系。一个slice是一个轻量级的数据结构,提供了访问数组子序列(或者全部)元素的功能,而且slice的底层确实引用一个数组对象。
切片是一个引用类型
一个slice由三个部分构成:指针、长度和容量。指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
声明切片类型的基本语法如下:
var name []T //name:切片的名字 T:元素类型
和数组类似,只是是引用型
//定义方式
var arr1 = []int{2,32,5,6,75} //将中括号里的元素个数省略了
var arr3 = []int{2:33,3:43,5:76}
fmt.Printf("%v - %T - 长度:%v",arr3,arr3,arr3)
关于切片的长度和容量
s := []int{2,3,4,5,68,99}
b := s[1:3]
fmt.Printf("长度%d 容量%d\n",len(b),cap(b)) //长度2,容量5,从底层切片开始,要看s,从1到最后一个99
切片的本质就是对底层数组的封装,包含三个信息:底层数组的指针,切片的长度,切片的容量(cap)
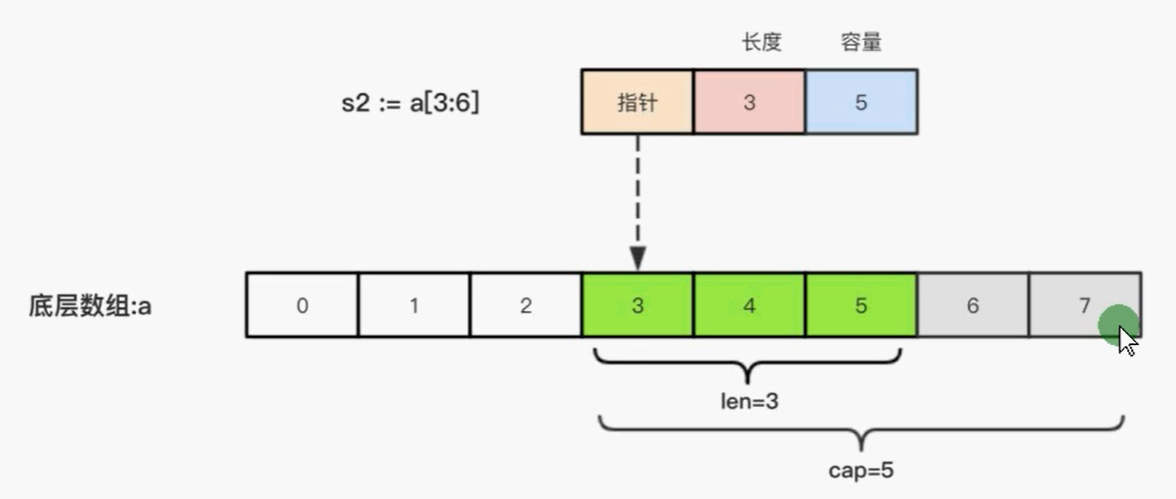
go语言中没法通过下标来对切片进行扩容。
要扩容就要用到append()方法。
var sliceA []int
sliceA = append(sliceA,12)
sliceA = append(sliceA,12,34,645,87,37) //一次传入多个数据
sliceB := []int{23,45,87,90}
sliceA = append(sliceA,sliceB...)//将sliceB合并到sliceA中,记得一定要加三个点
利用copy函数来复制切片
sliceA := []int{23,54,6,34}
sliceB := make([]int,4,4)
copy(sliceB,sliceA) //将切片A复制给B
make来创建切片
我们上面都是基于数组来创建的切片,如果需要动态的创建一一个切片,我们就需要使用内置的make()函数,格式如下:
make([]T,size,cap)
其中:
3.T:切片的元素类型
4.size:切片中元素的数量
5.cap:切片的容量
举个例子:
多维数组
一般是二维数组
//定义方式
var.arr.=[3][2]string{
{"北京","上海"},
{"广州","深圳"},
{"成都","重庆"},
}
//二维数组的遍历
for _,v1 := range arr{
for _,v2 := range v1{
fmt.Println(v2)
}
}
//也可以用推导法,但是只能在第一维写...
var.arr.=[...][2]string{
{"北京","上海"},
{"广州","深圳"},
{"成都","重庆"},
}
当你声明了一个变量却没有赋值时,golang中会自动给你的变量赋值一个默认零值。下面是每种类型对应的默认零值

排序
选择排序
for i := 0; i < len(sliceA); i++ {
for j := i + 1; j < len(sliceA); j++ {
if sliceA[i] > sliceA[j] {
t := sliceA[j]
sliceA[j] = sliceA[i]
sliceA[i] = t
}
}
}
fmt.Println(sliceA)
//第一轮:第一个和后面的每一个做对比,大的和小的换位置。
//第二轮:第二个和后面每一个做对比,再换位置,以此类推。
冒泡排序
for i := 0; i < len(sliceA); i++ {
for j := 0; j < len(sliceA)-i-1; j++ { //这个位置的-1一定要注意,当最后一个和j+1做对比是就会超过range。
if sliceA[j] > sliceA[j+1] {
temp := sliceA[j]
sliceA[j] = sliceA[j+1]
sliceA[j+1] = temp
}
}
}
排序函数(已封装)sort函数
升序
sort.Ints(intList)
sosrt.Float64s(float8list)
降序
sort . Sort (sort . Reverse(sort . IntSlice(intList)))
sort . Sort(sort . Reverse(sort . F1oat64S1ice(float8List)))
sort . Sort(sort. Reverse(sort . StringSlice(stringList)))|
fmt . Printf("%v\n%v\n%v\n", intList, float8List, stringList)
Map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
Go语言中map的定义语法如下所示:
map[KeyType]ValueType
//KeyType:键的类型
//ValueType:键所对应的值得类型。
-
利用make创建map类型的数据
var userinfo = make(map[string]string) userinfo["username"] = "hejj" userinfo["age"] = "29" userinfo["sex"] = "male" -
map也支持在声明的时候填充元素
var userinfo = map[string]string{ "username":"hejj", "age":"23", "sex":"male", //最后这个逗号也要写。切记 } -
直接填
userinfo := map[string]string{ "username":"hejj", "age":"23", "sex":"male", //最后这个逗号也要写。切记 } -
定义一个元素为map类型的切片
var userinfo = make([]map[string]string,3,3)//这个地方就是创建一个切片,元素是map,3,3分别是长度和容量。 if userinfo[0] = make(map[string]string){ userinfo[0]["name"] = "zhangashna" userinfo[0]["age"] = "20" userinfo[0]["sex"] = "male" } -
定义值为切片类型的map
var userinfo = make(map[string][]string) userinfo["hobby"] = []string{"睡觉","打球"}
函数
Go语言中定义函数用func关键字,具体格式如下所示:
func name(参数 参数类型)(返回值类型){
函数体
}
//求两个数的和
func sumFn(x int,y int)int{ //如果前后两个变量的类型相同就可以(x,y int)
sun := x+y
return sum
}
func main(){
sum1 = sumFn(12,3)
}
函数的可变参数,可变参数是指函数的参数数量不固定。go语言中的可变参数通过在参数后加…来表示。
func sumFn(x ...int)int{
sum := 0
for _,value := range x{
sum += value
}
return sum
}
如果return返回多个值则返回值类型要用()括起来,比如(int, int),表示两个返回值。
在函数的返回值类型那里可以直接定义返回值的名字
func cls(x int,y int)(sum int,sub int){
sum = x+y //这里就没有冒号了 已经定义好了
sub = x-y
return sum,sub
}
//如果只想要他们的和就可以这样
a,_ := cls(12,3)
自定义方法类型
//定义什么方法类型都可以
type calc func(int, int) int
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
func cal(x, y int, opfunc calc) int {
return opfunc(x, y)
}
//将calc定义为函数类型,这样演示了将函数当做参数传进函数中,其实直接传入也是可以的。
suu := cal(2, 4, add)
fmt.Println(suu)
匿名函数
就是没有名字的方法,必须要执行,要么自执行,要么赋给一个变量。
格式
func(参数)(返回值类型){
函数体
}
匿名函数可以放在一个函数里,比如你的方法就不能放在主函数里面,就必须定义在外面。但是匿名函数可以。
//匿名自执行函数
func (x,y int)int{
fmt.Println(x+y)
}(19,23) //42
//匿名函数
f := func(x,y int)int{
return x+y
}
fmt.Println(f(12,23))
闭包
闭包可以理解为“定义在一个函数内部的函数”。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。或者说是函数和其引用环境的组合体。
全局变量特点:
- 常驻内存
- 全局引用,污染全局
局部变量的特点:
- 不常驻内存
- 局部引用,不污染全局
闭包:
- 可以让一个变量常驻内存
- 可以让一个变量不污染全局
闭包是指有权访问另一个函数作用域中的变量的函数。
创建闭包的常见的方式就是在一个函数内部创建另一个函数,通过另一个函数访问这个函数的局部变量,然后返回那个函数
注意:由于闭包里作用域返回的局部变量资源不会被立刻销毁回收,所以可能会占用更多的内存。过度使用闭包会导致性能下降,建议在非常有必要的时候才使用闭包。
闭包的写法:一个函数里面嵌套一个函数,最后返回里面的函数。
func adder() func() int {
var i = 10
return func() int {
return i + 1
}
}
//不一样的来了
func add2()func()int {
i := 10
return func() int{
i++
return i
}
}
//这里的i就被改变了
func main(){
var a = adder()//有括号代表要执行这个函数,方法执行后的返回值赋值给这个a,这里是将那个匿名函数赋值给了a,a现在是一个函数,闭包的目的可能就是将i保留到内存但是不污染全局
fmt.Println(a())//a后面有括号就是运行a所代表的那个函数。这里return的是i+1,所以并没有改变i的值 所以每次调用返回值都一样
}
defer语句?
Go语言中的defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行。
用于函数最后释放资源和释放锁。
举个例子:
defer fmt.Println(a1())
defer fmt.Println(a1())
fmt.Println(a1())
fmt.Println(a1())//本来是11,12,13,14,现在的执行顺序是13,14,12,11
defer func(){
fmt.Println("aa")
fmt.Println("bb")
}()//一定要是自执行函数,否则就会因为没有调用该函数而报错
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET 指令执行前。具体如下图所示:
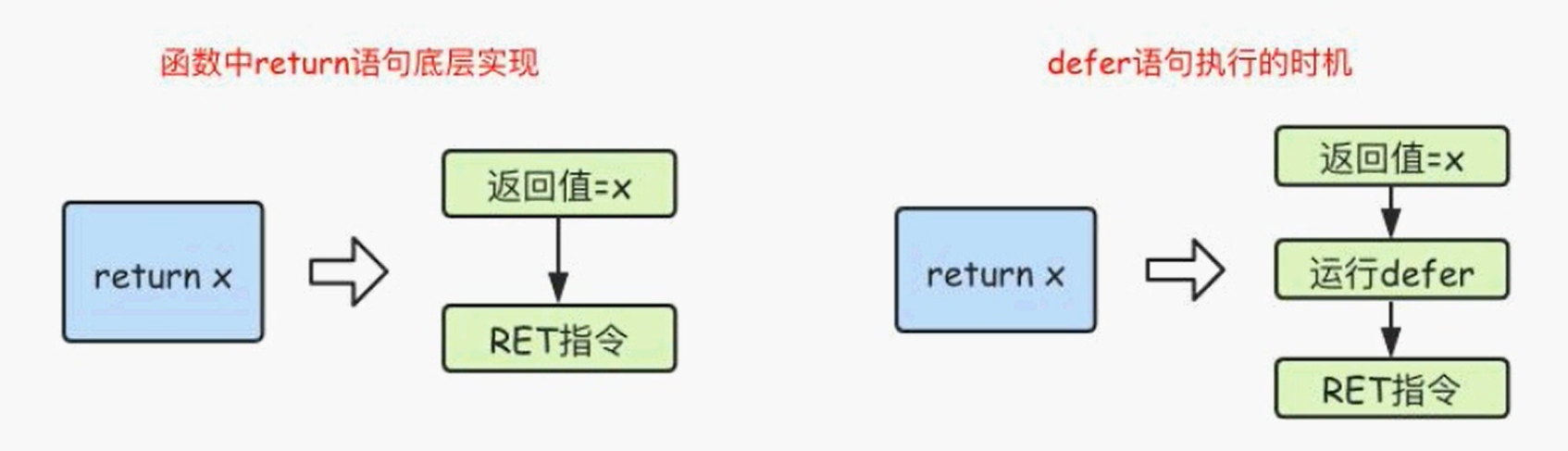
func main() {
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}
$ go run main.go
block ends
main ends
defer runs
提示:defer注册要延迟执行的函数时该函数所有的参数都需要确定其值
panic和recover
Go语言中目前(Go1.12)是没有异常机制,但是使用panic/recover模式来处理错误。
panic可以在任何地方引发,但recover只有在defer调用的函数中有效。首 先来看一个例子:
func fn1() {
fmt.Println("开始")
}
func fn2() {
panic("抛出一个异常")
}
func fn3() {
fmt.Println("结束")
}
func main() {
fn1()
fn2()
fn3()
}
//输出
开始
panic: 抛出一个异常
goroutine 1 [running]:
main.fn2(...)
d:/go_demo/src/itying/package/io_package.go:10
main.main()
d:/go_demo/src/itying/package/io_package.go:17 +0xa5
exit status 2
//程序到panic就终止了,不会再往下执行
为了遇到panic也能继续执行程序,就利用defer语句以及recover来继续。
func fn1() {
fmt.Println("开始")
}
func fn2() {
defer func() {
err := recover()
if err != nil {
fmt.Println("err:", err)
}
}()
panic("抛出一个异常")
}
func fn3() {
fmt.Println("结束")
}
func main() {
fn1()
fn2()
fn3()
}
//输出
开始
err: 抛出一个异常
结束
panic和recover的结合使用。可用于异常处理
panic就是规定的具体的error,当程序中你不写panic,如果程序确实有问题,他也会抛出异常,你就可以用defer/recover来继续程序。
package main
import "fmt"
func fn1() {
fmt.Println("开始")
}
func fn2(a, b int) int {
defer func() {
err := recover()
if err != nil {
fmt.Println("err:", err)
}
}()
return a / b
}
func fn3() {
fmt.Println("结束")
}
func main() {
fn1()
fn2(10, 0)
fn3()
}
time包
timeojb := time.Now()
str := timeojb.Format("2006-01-02 03:04:05")//利用Format来格式化时间输出,括号里的就是模板,你写成啥样输出就是啥样。这里的小时,如果是03则是12小时制如果是15则是24小时制。
fmt.Println(str)
获取时间戳
时间戳:自1970年1月1日到当前时间的总毫秒数。被称为Unix的时间戳。
timeobj := time.now()//这是直接获取的正常时间表示
Unixtime := timeobj.Unix //获取时间戳
//将时间戳转换为正常的时间格式
timeojb := time.Now()
unixTime := timeojb.Unix()
fmt.Println(unixTime)
timejj := time.Unix(1600431189, 0)//两个参数,1:时间戳毫秒数2:纳秒数
str := timejj.Format("2006-01-02 15:04:05")
fmt.Println(str)
//输出
1600431482
2020-09-18 20:13:09
//将日期字符串转换成时间戳
var str = "2020-09-18 20:22:20"
var temp = "2006-01-02 15:04:05"
timeobj := time.ParseInLocation(temp,str,tiem.Local)
fmt.Println(timeobj)
fmt.Println(timeobj.Unix)
时间计时器
ticker := tiem.NewTricker(time.Second)
指针
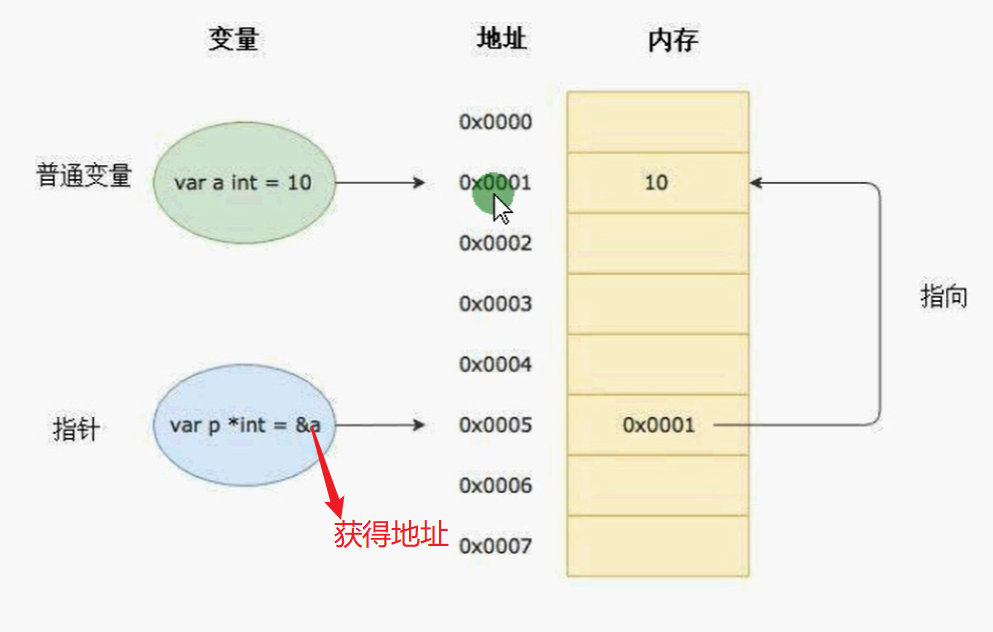
指针:也是一个变量,但是它是一个特殊的变量,它存储的数据不是一个普通的值,而是一个变量的内存地址。
*int代表是指针类型
通过*p来取得这个10值,根据地址取值,根据&来取地址
golang里面都有对应的内存地址,指针也是一个变量,所以它也有它的地址。
取出地址所对应得变量的值
a := 10
p := &a //p指针变量 类型 *int
// *p :表示取出p这个变量对应的内存地址的值
fmt.Println(p) //a的地址
fmt.Println(*p) //*p表示打印a对应的值 10
*p = 30 //改变p这个变量对应的内存地址的值
指针变量弄了以后就变成了引用类型。
func fn1(x int){
x = 20
}
func fn2(x *int){
*x = 40
}
func main(){
var a = 5
fn1(a)
fmt.Println(a) //5 这里将值赋给了x,x再改变 对a没有影响
fn2(&a)
fmt.Println(a) //40 这里直接改了a的地址里面的值,这就
}
对于引用类型,必须用make来为其开辟内存空间。
new函数分配内存
new是一个内置的函数,它的函数签名如下:
func new(Type) *Type
//其中Type表示类型,new函数只接受一个参数,这个参数是一个类型
//*Type表示类型指针,new函数返回一个指向该类型内存地址的指针
为变量分配内存的主要由new和make函数,new函数不常用,主要是得到一个指针类型,并且该指针对应的值为该类型的零值。
要给引用类型赋值,必须先给他们开辟空间。
var a = *int
b = new(int)
*b = 100
fmt.Println(*b) //100

golang的结构体
type
通过type关键字来定义自定义类型
type myInt int //将myInt定义为int类型,通过type关键字的定义,myInt就是一种新的类型,它具有int的特性
类型别名
type myInt = int //这叫类型别名,myInt只是Type的别名,本质上是同一个类型,只是换了个名字 这时候打印出的类型还是int
结构体 struct
结构体可以描述现实生活中的任何事物,生活中的任何事物都可以当做结构体对象
我们可以把客观事物封装成结构体:
汽车
汽车有属性:颜色 大小 重量 发动机 轮胎 、、、
汽车行为 也叫方法: run
使用type和struct关键字来定义结构体,具体代码格式如下:
type 类型名 struct {
字段名 字段类型
字段名 字段类型
}
//类型名:表示自定义结构体的名称,在同一个包内不能重复
//字段名:表示结构体字段名。结构体中的字段名必须唯一
//字段类型:表示结构体字段的具体类型,那些结构类型。
type Person struct{
name string
age int
sex string
}
//要是引用结构体就必须将其实例化
结构体实例化方法
方法一
只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段。
方法 结构体名字大写表示公有,其他包也能使用,小写表示私有,只能这个包使用
var 结构体实例 结构体类型
//实例
var p1 Person //实例化Person结构体
p1.name = "张三"
p1.age = 20
p1.sex = "male"
fmt.Printf("值:%v 类型:%T",p1,p1)//值:{张三 20 male} 类型:main.Person
fmt.Printf("值:%#v 类型:%T", p1, p1)//值:main.Person{name:"张三", age:20, sex:"male"} 类型:main.Person
//推荐使用%#来打印信息
方法二
利用new关键字来实例化
var p2 = new(Person)
p2.name = "lisi"
p2.age = 20
p2.sex = "male"
fmt.Printf("值:%#v 类型:%T", p2, p2)
//值:&main.Person{name:"lisi", age:20, sex:"male"} 类型:*main.Person
//打印的结果来看p2是一个结构体指针
注意:在golang中支持对结构体指针直接使用.来访问结构体成员。其实底层是(*p2).name = "lisi"
方法三
利用将结构体的地址赋给一个变量的方式
p3 = &Person{
p3.name = "zhansan"
p3.age = 23
p3.sex = "male"
}
方法四
键值对来实例化
// 用的多
p4 := Person{
name:"zhangwu",
city:"beijing",
age:12,
}//逗号一定要加
方法⑤
p4 := &Person{
name:"zhangwu",
city:"beijing",
age:12,
}//表示返回的是指针变量
如果不传值就用默认值
方法6
p4 := &Person{
"zhangwu",
"beijing",
12,
}//顺序要一一对应和结构体里的字段
值类型:改变变量副本值的时候,不会改变变量本身的值(数组,基本数据类型,结构体)
引用类型:改变变量副本值的时候,会改变变量本身的值(切片,map)
结构体方法定义
go语言中,没有类的概念但是可以给类型(结构体,自定义类型)定义方法。所谓方法就是定义了接受者的函数。接受者的概念类似于其他预言者中的this(java)或者self(python)
接受者变量:接受者中的参数变量名在命名时,官方建议使用接受者类型名的第一个小写字母,而不是self,this之类的命名。比如Person的接受变量应该命名为p
接受者类型:和参数类型类似,可以是指针类型也可以是非指针类型
方法名,参数列表,返回参数:和函数定义相同。
func (接受者变量 接受者类型) 方法名(参数列表)(返回参数){
函数体
}
type Person struct {
Name string
Age int
Sex string
Height int
}
//定义方法
func (p Person) PrintInfo() {
fmt.Printf("姓名:%v 年龄:%v",p.Name,p.Age)
}
func main(){
var p1 = Person{
Name: "何敬健"
Age: 25
Sex: "male"
}
}//实例化变量
要改变结构中的数据,必须用指针变量来修改对应的值,否则修改不了原值
func (p *Person) Setinfo(name string, age int){ //这里用的是指针变量来修改原值
p.Name = name
p.Age = age
}
golang中结构体实例相互独立
给任意类型添加方法
在Go语言中,接受者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。可以对自定义类型来自定义方法。 比如下面的例子
type myInt int
func (m myInt) SayHello(){
fmt.Println("hello,我是一个int。")
}
结构体的匿名字段:
结构体允许其成员字段在声明时没有字段名,只有类型。这种没有名字的字段就称为匿名字段
匿名字段默认采用类型名作为字段名,结构体要求字段名称必须唯一,因此一个结构体中
type Person struct{
string
int //类型不能重复,比如再来一个int就会报错
}
func main(){
p := Person{
"张三",
20,
}
}
type Person struct {
Name string
age int
Hobby []string
info map[string]string
}
func main() {
var p Person
p.Name = "何敬健"
p.age = 25
p.Hobby = make([]string, 3, 6)
p.Hobby[0] = "大连区"
p.Hobby[1] = "对我"
p.info = make(map[string]string)
p.info["address"] = "北京"
p.info["phone"] = "2134r35r4"
fmt.Printf("%#v", p)
fmt.Printf("%v",p.Hobby)
}
//输出
main.Person{Name:"何敬健", age:25, Hobby:[]string{"大连区", "对我", ""}, info:map[string]string{"address":"北京", "phone":"2134r35r4"}}
//输出
[大连区 对我 ]
结构体嵌套
利用结构体的嵌套实现了继承
type User struct {
Username string
Password string
Address Address //表示User结构体嵌套Address结构体 这里可以只写Address 表示类型,匿名结构体
}
type Address struct{
Name string
Phont string
City string
}
func main(){
var u User
u.Username = "itman"
u.Password = "23r453"
u.Address.Name = "hejj" //这里也可以直接u.Name来进行修改,先在结构体中找,在结构体里找不到name就会在嵌套结构体中找,如果嵌套两个结构体,都包含相同的字段名,则程序报错。
fmt.Printf("%#v", u)
}
//输出
main.User{Username:"itman", Password:"23r453", Address:main.Address{Name:"hhhh", Phont:"", City:""}}
结构体的嵌套
利用结构体的嵌套来实现继承,go中叫嵌入(embed)
type Animal struct {
Name string
Age int
}
func (a Animal) run() {
fmt.Printf("%v在运动\n", a.Name)
}
type Dog struct {
comeForm string
Animal //这里的嵌套就可以叫做继承
}
func (d Dog) wangwang() {
fmt.Printf("%v 在汪汪叫", d.Name)
}
func main() {
var d = Dog{
comeForm: "中国",
Animal: Animal{
Name: "huaidan",
},
}
d.run()
d.wangwang()
}
golang和json格式的相互转化
Golang要给APP或者小程序提供Api接口数据,需要涉及到结构体和json之间的相互转换。
Golang-JSON序列化就是把结构体数据转化成JSON格式的字符串,golang-json的反序列化是指把json数据转化为golang中的结构体对象
golang中的序列化和反序列化主要通过"encoding/json"包中的json.Marshal()–转成json,json.Unmarshal()–转成结构体
在定义结构体的字段名时,首字母一定要大写,要是公开的
type Person struct {
Name string
Age int
ID int
Gender string //如果首字母为小写 则为私有属性,json包无法访问。
}
type Student struct {
Grade string
Person
}
func main() {
var s1 = Student{
Person: Person{
Name: "hejj",
Age: 2,
ID: 123413,
Gender: "男",
},
Grade: "三年级",
}
fmt.Printf("%#v\n", s1)
jsonByte,err := json.Marshal(s1)//转化为json格式的字符串,第二个参数为error
jsonStr := string(jsonByte) //将byte类型转成string类型
if err != nil{
fmt.Println(err)
}else{
fmt.Printf("%v\n", jsonStr)
}
var str = `{"Grade":"nan","Name":"hejj","Age":2,"ID":123413,"Gender":"三年级"}`
var s2 Student
err := json.Unmarshal([]byte(str), &s2) //将json转化成结构体,注意各个参数的含义。这里要用s1的地址才能改
if err != nil {
fmt.Println(err)
}
fmt.Printf("%#v\n", s2)
fmt.Println(s2.Name)//获取Name的内容
}
结构体标签Tag
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来,tag在结构体字段的后方定义,有一对反引号包裹起来,具体格式如下
`key1:"value" key2:"value"`
结构体tag是由一个或多个键值对组成。键与值使用冒号隔离,值用双引号括起来。同一个结构体字段可以设置多个键值对tag,不同的键值对之间使用空格分隔。
注意:为结构体编写tag时一定要遵守规则,不然就算有错,也不会报错,容错能力很差。注意不要在键与值之间添加空格。
type Student struct {
Id int
Name string
Age int
Gender string
}
type Class struct {
Title string
Student []Student //注意类型是student
}
func main() {
var c = Class{
Title: "01班",
Student: make([]Student,0, 50),//注意类型,除此之外 这里的长度应该是0,因为后续还要往里面添加元素,容量可以不写 就默认容量了。
}
for i := 0; i <= 10; i++ { //这里i := 冒号别忘了,一句一句之间是分号;
s := Student{
Id: i,
Name: fmt.Sprint("stu_", i), //字符串拼接的方法
Gender: "name",
}
c.Student = append(c.Student, s)
}
fmt.Printf("%#v", c)
}
golang中的包
包(package)是多个Go源码的集合,是一种高级的代码复用方案,go语言为我们提供了很多内置包,如fmt,strconv,strings,sort,errors,time,encoding/json,os,io等。
golang中的包可以分为三种:1. 系统内置包 2. 自定义包 3. 第三方包
系统内置包:Golang语言给我们提供的内置包,引入后可以直接使用,如fmt、strconv、strings、sort、errors、time、encoding/json、OS、io 等。
**自定义包:**开发者自己写的包
**第三方包:**属于自定义包的–种,需要下载安装到本地后才可以使用,如前面给大家介绍的
"github.com/shopspring/decimal"包解决float精度丢失问题。
自定义包
包(package)是多个Go源码的集合,一-个包可以简单理解为一一个存放多个.go文件的文件夹。该文件夹下面的所有go文件都要在代码的第一行添加如下代码,声明该文件归属的包。
package 包名
注意事项:
●一个文件夹下面直接包含的文件只能归属一个package,同样-一个package的文件不能在多个文件夹下。
●包名可以不和文件夹的名字–样,包名不能包含-符号。
●包名为main的包为应用程序的入口包,这种包编译后会得到一个可执行文件,而编译不包含main包的源代码则不会得到可执行文件。
//首先在项目的路径下在命令行中输入来初始化项目
go mod init iting//iting是项目名
//然后就可以创建包文件-自定义的
package calc//calc这个文件夹下的文件都属于一个包,一个包下面不同的文件的方法不能相同
var aa = 23
var Age = 4
func Add(x, y int) int { //必须首字母大写,这是公有的方法,小写的话就只能在这个包里使用
return x + y
}
func Sub(x, y int) int {
return x - y
}
package main //package一定要放在最上面
import (
"fmt"
"itying/calc"
T "itying/calc" //这里calc是文件夹,还能创建包别名,利用在这个前面写上他的别名就可以
//引入的时候直接就T.sub这样
)
func main() {
sum := calc.Add(12, 3)
fmt.Println(sum)
//fmt.Println(calc.aa)
fmt.Println(T.Age)
}
//这是main方法的文件
//匿名导入包
import _"packageName"
在main包中init函数优先于main函数。

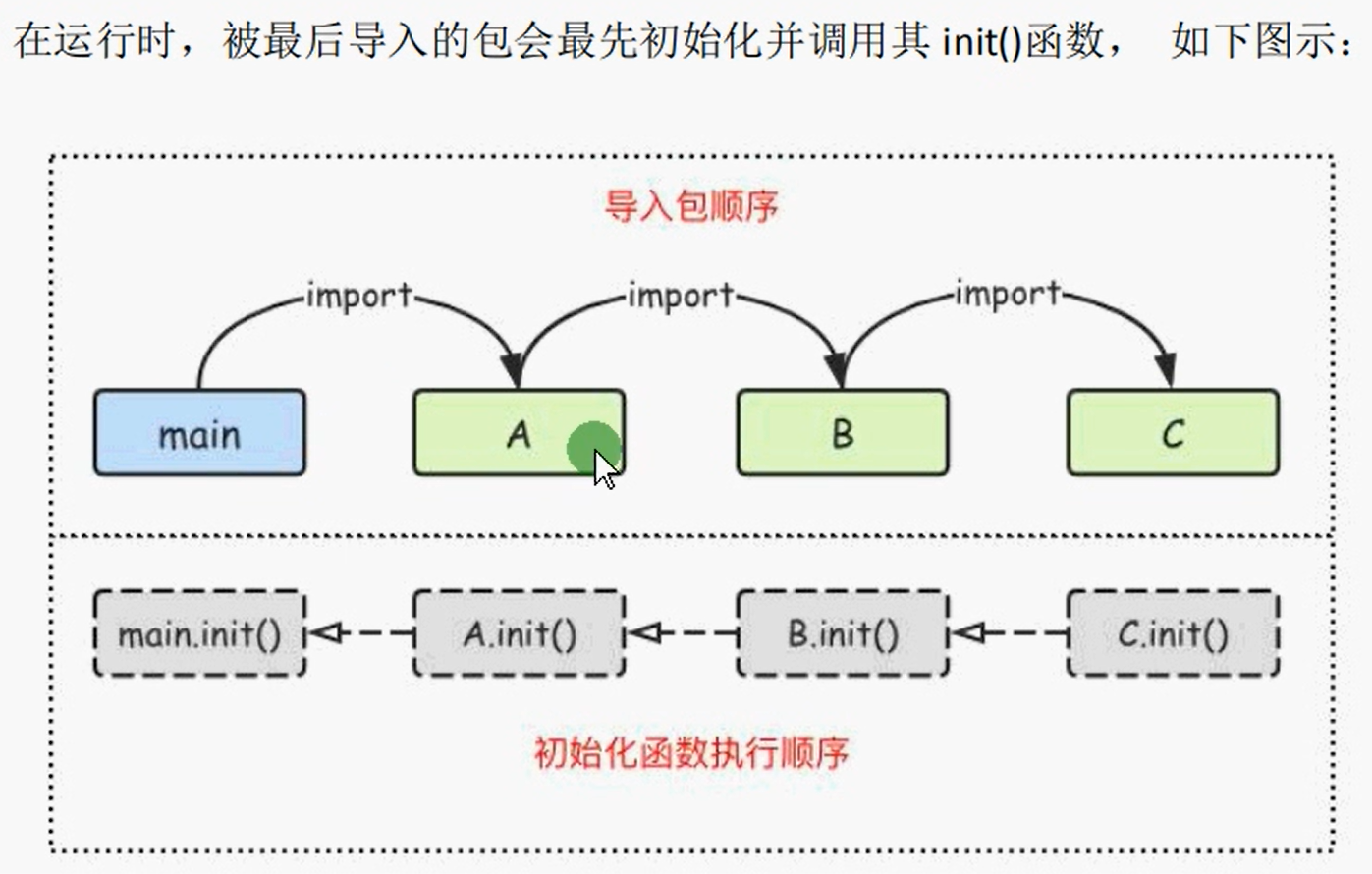
导入第三方包
在golang的1.11版本以后就不需要一定在GOPATH的路径下创建工程了,只需要利用go mod init nameOfProject来创建gomod包管理工具。
在自定义包时,先创建包名的目录,在目录下创建同名(建议同名)的包文件,在导入时要写好相对路径(写到包文件的所在目录即可),自定义的包,在开头要写上package tools就表示这个.go 文件是属于tools包的。
引入后就可以利用nameOfPackage.method来调用包中的方法。同一个包(一个目录)下可以有多个.go文件,无论在哪个.go文件下都能直接调用。
import
"mqtt "github.com/eclipse/paho.mqtt.golang"
// 这里mqtt就是这个包的别名 在调用时 mqtt.nameOfMethod 也可以调用
import _ "github.com/eclipse/paho.mqtt.golang" // 匿名导入一个包,表示不用包里的内容,但是包会参与文件编译。
golang中的接口
在Golang中接口(interface)是一种类型,一种抽象的类型。接口(interface)是一组函数method的集合,Golang 中的接口不能包含任何变量。类似于生活中的接口–USB接口,是一种标准。接口就是一种类型。
在Golang中接口中的所有方法都没有方法体,接口定义了一个对象的行为规范,只定义规范不实现。接口体现了程序设计的多态和高内聚低耦合的思想
Golang中的接口也是一种数据类型,不需要显示实现。只需要一个变量含有接口类型中的所有方法,那么这个变量就实现了这个接口。
Golang中每个接口由数个方法组成,接口的定义格式如下:
type 接口名 interface{ //建议接口名后面跟er表示是接口名,当有一个方法时,就可以用加er的方式来命名。
方法名1(参数列表1)返回值列表1
方法名2(参数列表2)返回值类别2
...
}
定义Usb接口
type Usber interface {
start()
stop()
}
type Phone struct {
name string
}
func (p Phone) start() {
fmt.Println(p.name, "启动")
}
func (p Phone) stop() {
fmt.Println(p.name, "关机")
}
func (p Phone) run (){
}//可以有比接口中多的方法,但是接口里规定的那些方法必须要有。
func main() {
p1 := Phone{
name: "华为手机",
}
var b Usber
b = p1
b.start()
}
空接口
Golang中的接口可以不定义任何方法,没有定义任何方法的接口就是空接口。空接口表示没有任何约束,因此任何类型变量都可以实现空接口。
可以用空接口表示任意数据类型
type A interface {
var a interface{}//空接口可以接收任意类型
s := "你好,golang"
a = s
a = 23
a = true
func show(a interface{}) {
fmt.Printf("值为:%v,类型为:%T\n", a, a)
}
func main() {
show(20)
show("hfejg")
slice := []int{1, 3, 45, 7}
show(slice)
}
//输出
值为:20,类型为:int
值为:hfejg,类型为:string
值为:[1 3 45 7],类型为:[]int
利用空接口来定义map类型,使得map可以接收任意类型的value,但是对于切片类型不支持对下标的索引
var m1 = make(map[sting]interface{})
m1["username"] = "zhagnsan"
m1[age] = 12
m1[married] = true
利用空接口来定义切片类型,使得切片可以接收任意类型的元素
var s1 = make([]interface{}{"何敬健",25,true})
类型断言
一个接口值(简称接口值)是由一个具体的类型和具体类型的值两部分组成的。这两部分分别称为接口的动态类型和动态值。
如果想要判断接口中值的类型,就要使用类型断言语法格式为
x.(T)
//x:表示类型为interface{}的变量
//T:表示断言x可能是的类型
var a interface{}
a = "nih"
v, ok := a.(string) //这里返回的v是string类型的nih,ok是布尔类型,是否是括号里的类型
if ok {
fmt.Printf("a的类型是string,值是:%v", v)
} else {
fmt.Println("failtojudge")
}
//输出
a的类型是string,值是:nih
当需要断言很多次时,就可以结合switch语句来实现
注意:x.(type)只能结合switch语句使用
func justifyType(x interface{}) {
switch x.(type) {
case int:
fmt.Println("int类型")
case string:
fmt.Println("string类型")
case bool:
fmt.Println("bool类型")
default:
fmt.Println("传入错误。。。")
}
}
func main() {
var a interface{} = "何敬健"
justifyType(a)
justifyType("woegh")//直接传入也可以
}
还可以用于判断别的类型,在非空接口的结合使用
if _, ok := usb.(Phone);ok{
usb.start()
}else{
usb.stop()
}
结构体值接收者和指针接收者实现接口的区别
当结构体中的方法是值接受者时,实例化后的结构体指针类型和结构体值类型都能赋值给接口变量。
func (p Phone) Start(){
}
func main(){
phone1 := Phone{ //或者这里可以这么写
//phone1 := &Phone
name: "虾米手机"
}
var p1 Usber = phone1
p1.Start()
}
当结构体中的方法是指针类型接收者时,实例化后的结构体指针类型可以赋值给接口变量。结构体值类型没法赋值给接口变量。
func (p *Phone) Start(){
}
func main(){
phone1 := &Phone{ //这里只能这么写
name: "虾米手机",
}
var p1 Usber = phone1
p1.Start()
}
遇到一个问题(记录一下)
package main //package一定要放在最上面
import (
"fmt"
)
type Animaler interface {
SetName(string)
GetName() string //这里之前没有规定个数,导致后面的结构体没能实现接口所以造成报错,所以必须按照接口的约定来实现。
/*{
"message": "cannot use d1 (type *Dog) as type Animaler in assignment:\n\t*Dog does not implement Animaler (wrong type for GetName method)\n\t\thave GetName() string\n\t\twant GetName()",
"source": "go",
"startLineNumber": 36,
"startColumn": 6,
"endLineNumber": 36,
"endColumn": 22*/
}
}
type Dog struct {
Name string
}
func (d *Dog) SetName(name string) {
d.Name = name
}
func (d Dog) GetName() string {
return d.Name
}
type Cat struct {
Name string
}
func (c *Cat) SetName(name string) {
c.Name = name
}
func (c Cat) GetName() string {
return c.Name
}
func main() {
d1 := &Dog{
Name: "泰迪",
}
var d2 Animaler = d1
// var d2 Animaler
// d2 = d1
fmt.Println(d2.GetName())
c1 := &Cat{
Name: "kity",
}
var c Animaler = c1
c.SetName("wangwang")
fmt.Println(c.GetName())
}
一个结构体实现多个接口
package main //package一定要放在最上面
import (
"fmt"
)
type Animaler1 interface {
SetName(string)
}
type Animaler2 interface {
GetName() string
}
type Dog struct {
Name string
}
func (d *Dog) SetName(name string) {
d.Name = name
}
func (d Dog) GetName() string {
return d.Name
}
func main() {
d1 := &Dog{
Name: "泰迪",
}
var d2 Animaler1 = d1 //这里就实现了多个接口
var d3 Animaler2 = d1
d2.SetName("旺财")
fmt.Println(d3.GetName())
}
接口嵌套
接口和接口间可以通过嵌套创造出新的接口
type SayInterface interface{
say()
}
type MoveInterface interface{
move()
}
type Animal interface{ //实现了接口嵌套
SayInterface
MoveInterface
}
空接口以及断言的实现细节
*需求:将map中的slice,结构体中的元素取出,因为value是interface类型,不能通过下标来取
思路:通过空接口以及类型断言来将value的类型由interface转成slice和结构体,再通过下标来取值。
*/
package main //package一定要放在最上面
import (
"fmt"
)
type Address struct {
place string
phone int
}
func main() {
var userinfo = make(map[string]interface{})//空接口类型
userinfo["name"] = "何敬健"
userinfo["age"] = 25
userinfo["hobby"] = []string{"篮球", "足球", "game", "reading"}
var address = Address{
place: "新疆",
phone: 18945,
}
userinfo["address"] = address
// fmt.Println(userinfo["address"].phone) //userinfo["address"].phone undefined (type interface {} is interface with no methods)
var address1, _ = userinfo["address"].(Address) //转了一下类型
fmt.Println(address1.phone, address1.place)
var hobby1, _ = userinfo["hobby"].([]string)
fmt.Println(hobby1[1])
}
//输出
18945 新疆
足球
interface的多态
type Item interface {
Name() string
Price() float64
}
type VegBurger struct {
}
func (r *VegBurger) Name() string{
return "vegburger"
}
func (r *VegBurger) Price() float64{
return 1.5
}
type ChickenBurger struct {
}
func (r *ChickenBurger) Name() string{
return "chickenburger"
}
func (r *ChickenBurger) Price() float64{
return 5.5
}
go语言中的并发与并行
进程,线程,并行,并发
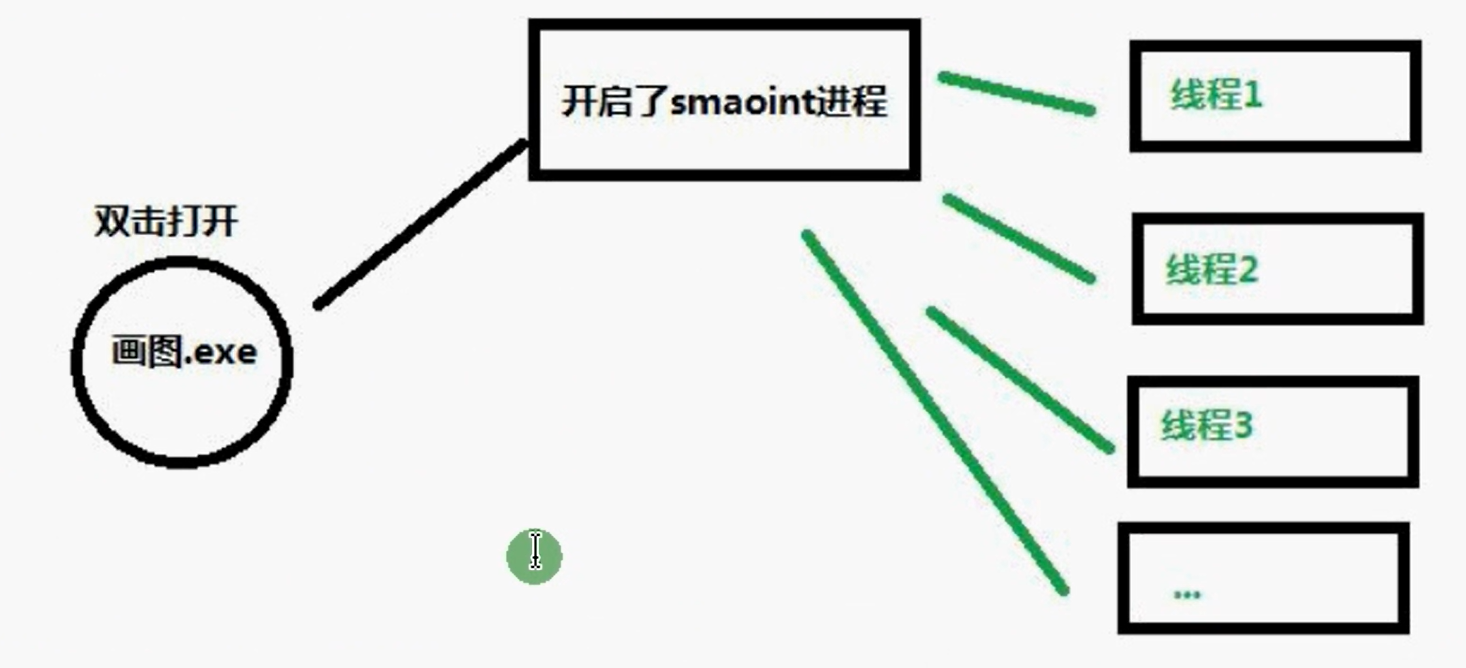
**进程(Process)**就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位,进程是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间。一个进程至少有5种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
通俗的讲进程就是一个正在执行的程序。
线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
一个进程可以创建多个线程,同一个进程中的多个线程可以并发执行,一个程序要运行的话至少有一个进程。
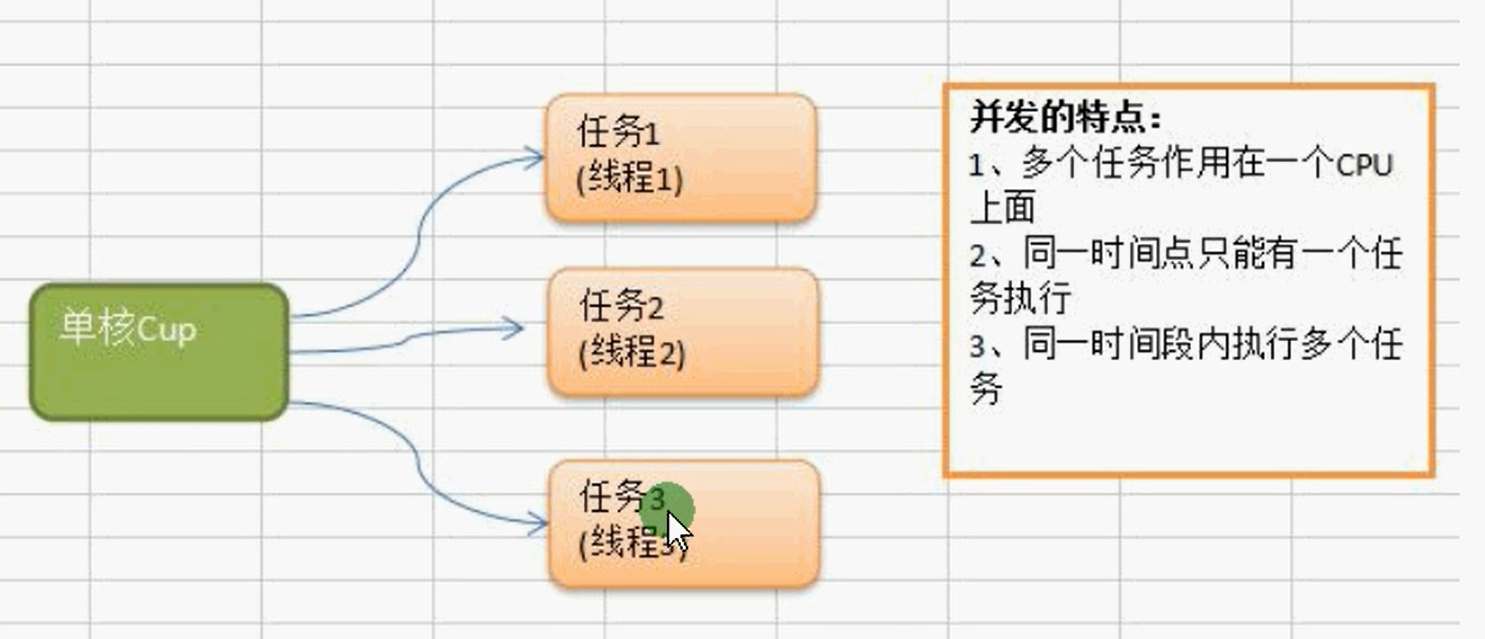
**并发:**多个线程同时竞争-一个位置,竞争到的才可以执行,每一个时间段只有一个线程在执行。
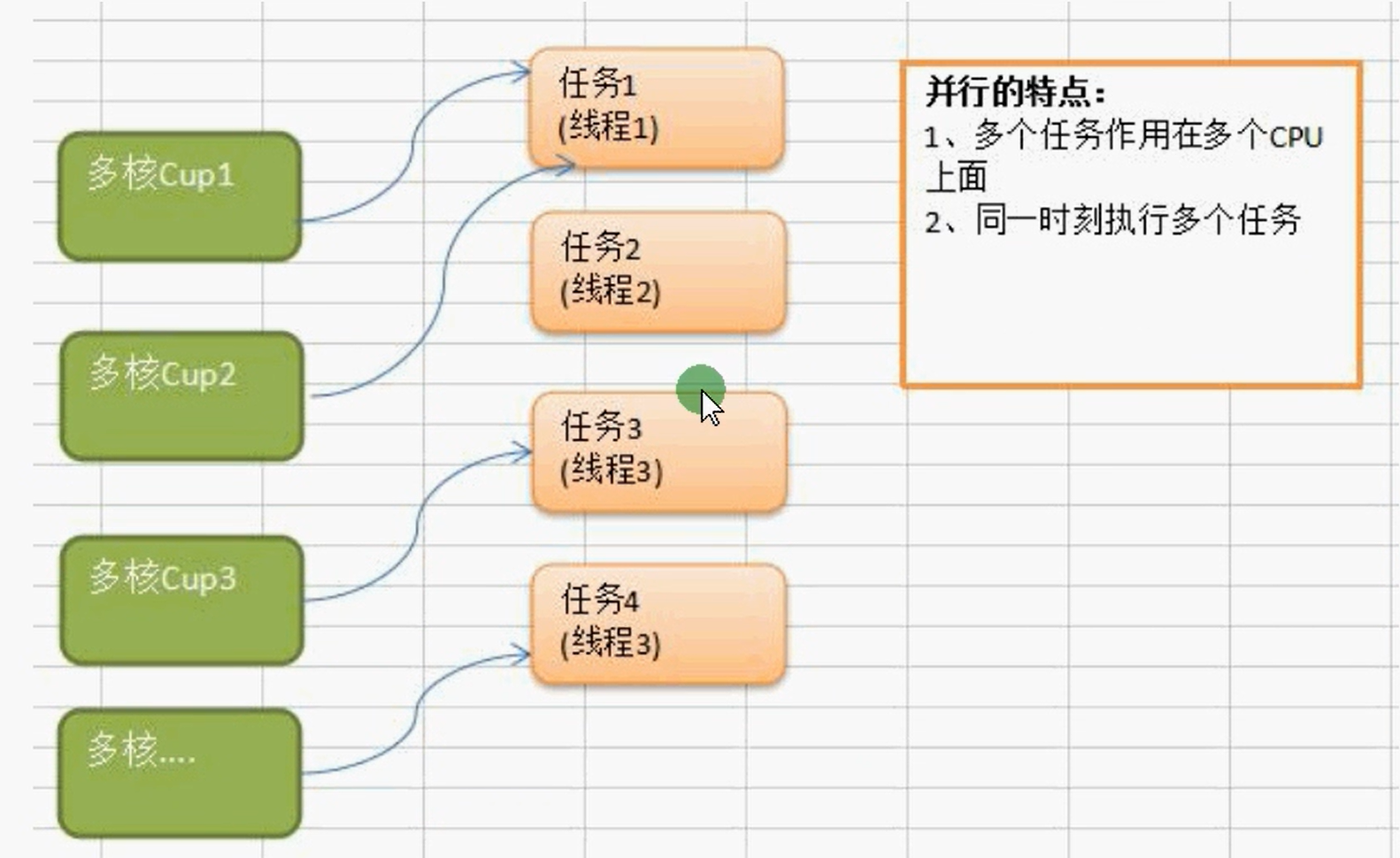
**并行:**多个线程可以同时执行,每一一个时间段,可以有多个线程同时执行。
通俗的讲多线程程序在单核CPU上面运行就是并发,多线程程序在多核CUP上运行就是并行,如果线程数大于CPU核数,则多线程程序在多个CPU上面运行既有并行又有并发
并发
并行
golang中的主线程:(可以理解为线程/也可以理解为进程),在一个Golang程序的主线程上可以起多个协程。Golang 中多协程可以实现并行或者并发。
**协程:**可以理解为用户级线程,这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的。Golang 的一大特色 就是从语言层面原生支持协程,在函数或者方法前面加go关键字就可创建一个协程。可以说Golang中的协程就是goroutine。
多协程和多线程:Golang中每个goroutine(协程)默认占用内存远比java,c的线程少。OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB左右),一个goroutine占用内存非常小,只有2KB左右,多协程goroutine切换调度开销方面远比线程要少。
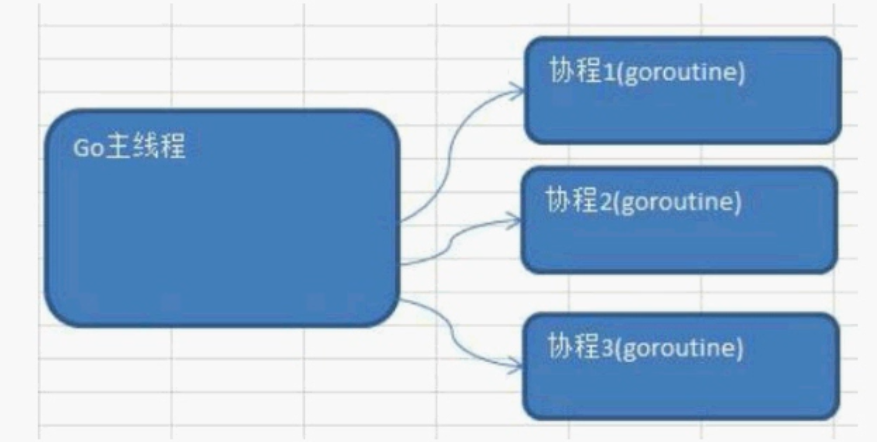
实现并行
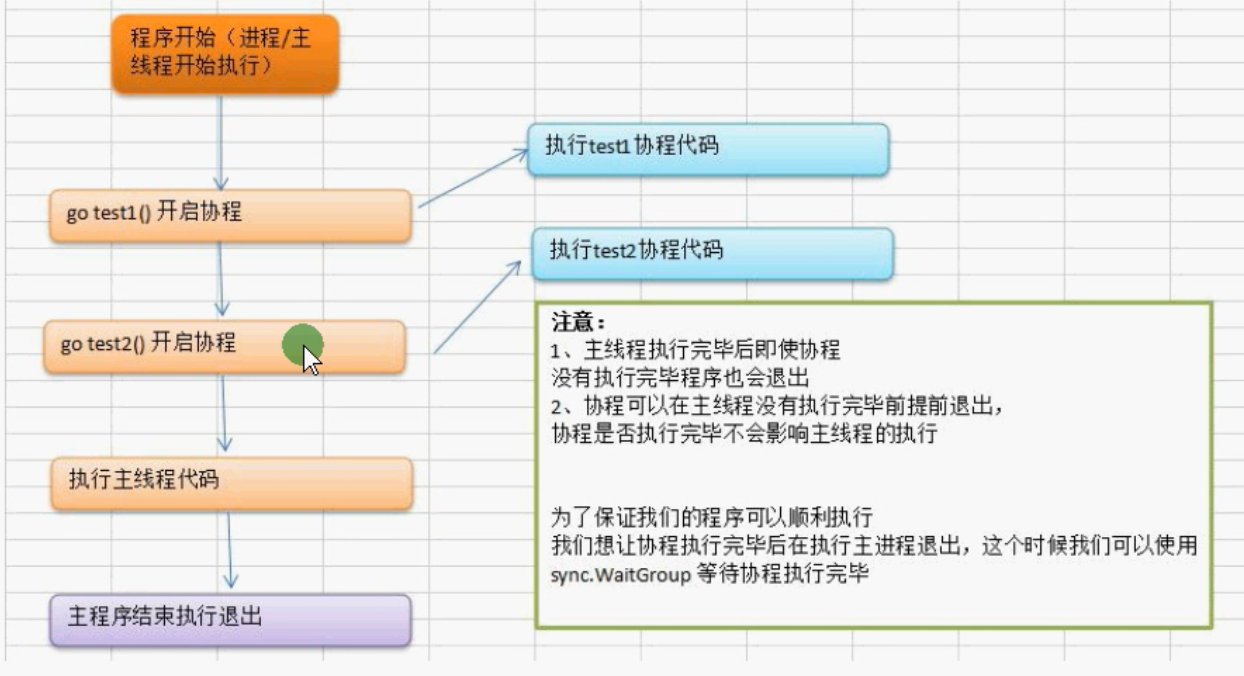
如果主程序先完成,就会立马退出程序,不等协程,如果协程先完成了,主程序会继续执行。
使用sync.waitGroup来实现主线程等待协程执行完毕。
var wg sync.WaitGroup //包太长,用wg表示
func test1() {
for i := 0; i <= 10; i++ {
fmt.Println("你好,wangjialie", i)
time.Sleep(time.Millisecond * 100)
}
wg.Done()
}
func test2() {
for i := 0; i <= 10; i++ {
fmt.Println("你好,何敬健", i)
time.Sleep(time.Millisecond * 100)
}
wg.Done()//协程计数器减一
}
func main() {
wg.Add(1)//协程计数器加一
go test1()
wg.Add(1)
go test2()
wg.Wait()
fmt.Println("结束")
}
开启多个协程
var wg sync.WaitGroup
func test(num int) {
defer wg.Done()//当完成一个协程时,标记减一
for i := 1; i <= 5; i++ {
fmt.Printf("这是打印的第(%v)协程的第%v条数据\n", num, i)
time.Sleep(time.Millisecond * 100)//这个暂停是放在这儿的,放在主程序中就会按照顺序执行
}
}
func main() {
for i := 1; i <= 6; i++ {
wg.Add(1)//当开启一个协程时,标记加一
go test(i)
}
wg.Wait()//这里主程序等待协程完成
fmt.Print("关闭")
}
Channel管道
管道是Go语言在语言级别上提供的goroutine间的通讯方式,我们可以使用channel在多个goroutine之间传递消息。如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一一个goroutine发送特定值到另一个goroutine的通信机制。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
Go语言中的管道(channel)是-种特殊的类型。管道像–个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每-一个管道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
channel 类型
channel是一种类型,一种引用类型。声明管道类型的格式如下:
var 变量 chan 元素类型
//举几个例子
var ch1 chan int //chan 和int这些类型都是一起的才能定义类型。
var ch2 chan bool
var ch3 chan []string //声明一个传递int切片的管道
channel创建
声明的管道后需要使用make函数初始化之后才能使用
创建管道的格式
make(chan 元素类型,容量)
channel的操作
管道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号
现在我们先使用以下语句定义一个管道:
ch1 := make(chan int,3)
发送(将数据放入管道)
ch1 <- 10 //将10发送到管道
ch1 <- 12
ch1 <- 13
接收(从管道取值)
x := <- ch1
<- ch1 //从管道取值但是忽略结果
//打印管道的地址,容量,长度
fmt.printf("值为:%v,容量为%v,长度为:%v",x,cap(x),len(x))
//输出
管道是引用数据类型
管道阻塞:表示数据送入管道的数量超过了管道的容量或者取得数据多于管道容量也会报错all goroutines are asleep - deadlock!
关闭管道
close(ch1)
可以利用for range来遍历管道,注意:管道没有key
for val := range ch1{
fmt.Println(val)
}//当用for range来遍历管道时,往管道里传完数据后要关闭管道,通过for循环来遍历时可以不用关闭
func main() {
ch2 := make(chan int, 10)
for i := 1; i <= 10; i++ {
ch2 <- i
}
close(ch2) //没有关闭就会报错 deadlock
for val := range ch2 {
fmt.Println(val)
}
}
单向管道
当限制管道在函数中只能发送或只能接受数据时就变成了单向管道
var ch1 chan<-int//只写管道
ch1 = make(chan int,3)
ch1 := make(chan<-int,3)
var ch2 <-chan int//只读管道
ch2 = make(chan int,3)
ch2 := make(<-chan int,3)
channel 和goroutine结合使用
这里首先讲一下sync.WaitGroup的用法,她的作用主要是在多个协程时,主程序很快就会运行结束,这就导致其他的协程还未结束,主程序就结束了。因此采用这个来使主程序等待其他协程结束后再结束
WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。Add(n) 把计数器设置为n ,Done() 每次把计数器-1 ,wait() 会阻塞代码的运行,直到计数器地值减为0。
package main //package一定要放在最上面
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func Write(ch chan int) {
for i := 1; i <= 10; i++ {
ch <- i
fmt.Printf("写入第%v条数据成功\n", i)
time.Sleep(time.Millisecond * 100)
}
close(ch)//记得关闭
wg.Done()//写在for循环外面
}
func Read(ch chan int) {
for val := range ch {
fmt.Printf("读取%v数据成功", val)
time.Sleep(time.Millisecond * 100)
}
wg.Done()
}
func main() {
ch := make(chan int, 10)
go Write(ch)
wg.Add(1)
go Read(ch)
wg.Add(1)
wg.Wait()
fmt.Println("结束")
}
package main //package一定要放在最上面
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func putNum(intChan chan int) {
for i := 2; i <= 120; i++ {
intChan <- i
}
close(intChan)
wg.Done()
}
func primNum(intChan chan int, primeChan chan int, exitChan chan bool) {
for val := range intChan {
falge := true
for i := 2; i < val; i++ {
if val%i == 0 {
falge = false
break //很重要,是素数就跳出内循环
}
}
if falge {
primeChan <- val
}
}
exitChan <- true
wg.Done()
}
func printPrime(primeChan chan int) {
for num := range primeChan {
fmt.Println(num)
}
wg.Done()
}
func main() {
start := time.Now().Unix()
intChan := make(chan int, 500)
primeChan := make(chan int, 50000)
exitChan := make(chan bool, 16)
//存放数字的协程
wg.Add(1)
go putNum(intChan)
//存放素数的协程
for i := 0; i < 16; i++ {
wg.Add(1)
go primNum(intChan, primeChan, exitChan)
}
//打印素数的协程
wg.Add(1)
go printPrime(primeChan)
//判断exitchan是否存满值
wg.Add(1)
go func() {
for i := 0; i < 16; i++ {
<-exitChan
}
close(primeChan)
wg.Done()
}() //匿名函数别忘了写括号
wg.Wait()
end := time.Now().Unix()
fmt.Println(end-start, "毫秒")
}
//输出
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
101
103
107
109
113
0 毫秒 //这里代码有问题 不应该是0
select多路复用
在某些场景下我们需要同时从多个通道接收数据。这个时候就可以用到golang中给我们提供的select多路复用。
通常情况通道在接收数据时,如果没有数据可以接收将会发生阻塞。使用select取数据不用关闭通道。
比如说下面代码来实现从多个通道接受数据的时候就会发生阻塞:
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 20)
for i := 1; i <= 20; i++ {
intChan <- i
}
preChan := make(chan string, 20)
for i := 1; i <= 20; i++ {
preChan <- "hello" + fmt.Sprintf("%d", i)
}
for { //这里是一个死循环,没有条件,所以要注意跳出
select {
case v := <-intChan:
fmt.Printf("从intchan中取出数据%v\n", v)
case v := <-preChan:
fmt.Printf("从prechan中取出数据%v\n", v)
default:
fmt.Println("数据已取完\n")
return//这里就是跳出的
}
}
}
Goroutine Recover解决协程中出现的Panic
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup //这里记得定义某个类型时,不用等号
func sayHello() {
for i := 1; i <= 10; i++ {
fmt.Println("hello,world")
}
wg.Done()
}
func test() {
//这里我们使用defer + recover来处理panic
defer func() {
if err := recover(); err != nil {
fmt.Println("test函数发生错误", err)
}
}()// 自执行函数
var myMap map[string]int
myMap["hej"] = 123 //error
wg.Done()
}
func main() {
wg.Add(1)
go sayHello()
wg.Add(1)
go test()
wg.Wait()
}
Golang中并发安全和锁
互斥锁
互斥锁是传统并发编程中对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex 类型只有两个公开的指针方法,Lock 和Unlock。Lock 锁定当前的共享资源,Unlock进行解锁。
读互斥锁
互斥锁的本质是当一个goroutine访问的时候,其他goroutine都不能访问。这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行执行变成了串行执行。
其实,当我们对一个不会变化的数据只做“读”操作的话,是不存在资源竞争的问题的。因为数据是不变的,不管怎么读取,多少goroutine同时读取,都是可以的。
所以问题不是出在“读”上,主要是修改,也就是“写”。修改的数据要同步,这样其他goroutine才可以感知到。所以真正的互斥应该是读取和修改、修改和修改之间,读和读是I没有互斥操作的必要的。
因此,衍生出另外-种锁,叫做读写锁。
读写锁可以让多个读操作并发,同时读取,但是对于写操作是完全互斥的。也就是说,当一个goroutine进行写操作的时候,其他goroutine既不能进行读操作,也不能进行写操作。
反射
有时我们需要写一一个函数,这个函数有能力统–处理各种值类型,而这些类型可能无法共享同一个接口,也可能布局未知,也有可能这个类型在我们设计函数时还不存在,这个时候我们就可以用到反射。
1、空接口可以存储任意类型的变量,那我们如何知道这个空接口保存数据的类型是什么?
值是什么呢?
1、可以使用类型断言
2、可以使用反射实现,也就是在程序运行时动态的获取-一个变量的类型信息和值信息。
2、把结构体序列化成json字符串,自定义结构体Tab标签的时候就用到了反射
反射:指在程序运行期间对程序本身进行访问和修改的能力。正常情况程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分。在运行程序时,程序无法获取自身的信息。支持反射的语言可以在程序编译期将变量的反射信息,如字段名称、类型信息、结构体信息等整合到可执行文件中,并给程序提供接口访问反射信息,这样就可以在程序运行期获取类型的反射信息,并且有能力修改它们。
Go可以实现的功能:
1、反射可以在程序运行期间动态的获取变量的各种信息,比如变量的类型类别
2、如果是结构体,通过反射还可以获取结构体本身的信息,比如结构体的字段、结构体的方法。
3、通过反射,可以修改变量的值,可以调用关联的方法,
Go语言中的变量是分为两部分的:
类型信息:预先定义好的元信息。
值信息:程序运行过程中可动态变化的。
在Go语言的反射机制中,任何接口值都由是-个具体类型和具体类型的值两部分组成的。
在Go语言中反射的相关功能由内置的reflect包提供,任意接口值在反射中都可以理解为由reflect.Type和reflect.Value两部分组成,并且reflect包提供了reflect.TypeOf 和reflect.ValueOf两个重要函数来获取任意对象的Value和Type。
通过反射获得任意变量的类型
在反射中关于类型还划分为两种:类型(Type)和种类(Kind)。因为在Go语言中我们可以使用type关键字构造很多自定义类型,而种类(Kind)就是指底层的类型,但在反射中,当需要区分指针、结构体等大品种的类型时,就会用到种类(Kind)。举个例子,我们定义了两个指针类型和两个结构体类型,通过反射查看它们的类型和种类。
type myint int
type Person struct{
name string
age int
}
func reflectType(x interface{}) {
v := reflect.TypeOf(x) //通过reflect.TypeOf来获取变量的类型
fmt.Println(v)
//fmt.Printf("获取的类型%v,类型名称%v,类型种类%v\n", v, v.Name(), v.Kind())
}
func main() {
a := 2
b := true
c := "hejj"
d := 234.55
var e myint = 23
var hejj = Person{
name:"何敬健",
age: 24
}
reflectType(a)
reflectType(b)
reflectType(c)
reflectType(d)
reflectType(hejj)
reflectType(e)
}
//输出
int
bool
string
float64
main.Person
main.myint
//输出
获取的类型int,类型名称int,类型种类int
获取的类型bool,类型名称bool,类型种类bool
获取的类型string,类型名称string,类型种类string
获取的类型float64,类型名称float64,类型种类float64
获取的类型main.flll,类型名称flll,类型种类struct
获取的类型main.myint,类型名称myint,类型种类int
Golang 文件
读取文件

方法一:利用file.Read()
package main
import (
"fmt"
"io"
"os"
)
func main() {
//打开文件
file, err := os.Open("D:/go_demo/src/itying/calc/calc.go") //记得地址的双引号,相对地址的话是"./文件名"
defer file.Close() //读取文件后一定要记得关闭,否则内存外溢
if err != nil {
fmt.Println("读取失败")
return
}
//读取文件
var strSlice []byte //用来存放读取的数据
var tempSlice = make([]byte, 128)
for {//通过for循环来将全部字节读完
n, err := file.Read(tempSlice)
if err == io.EOF { //表示读取完毕
fmt.Println("读取完毕")
break //这个很重要,读取完毕要跳出整个循环
}
if err != nil {
fmt.Println("读取失败")
return
}
fmt.Printf("读取到了%v个字节", n)
strSlice = append(strSlice, tempSlice[:n]...)//这里有一个读取范围[:n],避免了读到最后出现少读的情况,记得三个点
}
fmt.Println(string(strSlice))//这里将slice类型转成string类型
}
方法二:利用bufio来读取文件
利用bufio来读取数据
var fileStr string
//打开文件
file, err := os.Open("D:/demo3.txt")
defer file.Close()
if err != nil {
fmt.Println("文件打开失败")
return
}
//读文件
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF {
fileStr += str
break
}
if err != nil {
fmt.Println("读取文件失败")
return
}
fileStr += str
}
fmt.Println(fileStr)
方法三:利用ioutil来读取数据
利用“ioutil”来一下子整个读取数据,前两种是读取大的数据文件,最后这种读取小的数据文件,一两百兆可以
byteStr, err := ioutil.ReadFile("D:/demo3.txt") //这里接收的两个参数,一个是byte类型
if err != nil {
fmt.Println("err", "读取文件失败")
return
}
fmt.Println(string(byteStr)) //这里需要进行转换
写入文件
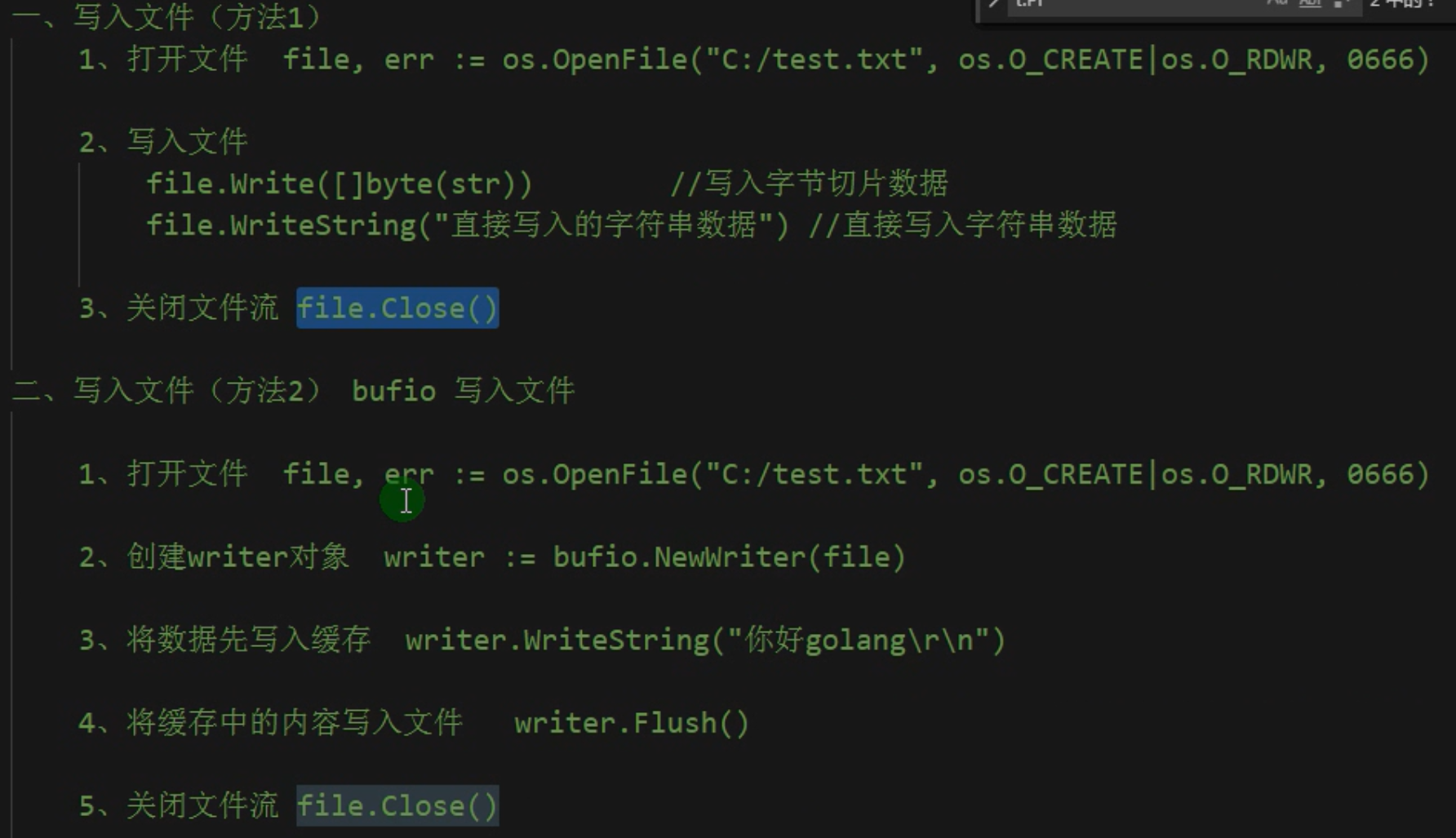

方法一
file, err := os.OpenFile("D:/demo3.txt", os.O_WRONLY|os.O_TRUNC, 0666)
defer file.Close()
if err != nil {
fmt.Println("打开文件失败")
return
}
for i := 1; i <= 10; i++ {
file.WriteString("写入数据喽" + strconv.Itoa(i) + "\r\n") //这个/\r\n必须要写
}
方法二
//打开文件
file, err := os.OpenFile("D:/demo3.txt", os.O_RDWR|os.O_TRUNC, 0666)//这里的0666别忘了
defer file.Close()//关闭文件
if err != nil {
fmt.Println("打开文件失败")
return
}
//写入内容,分为三步
write := bufio.NewWriter(file)
write.WriteString("你好,golang")
write.Flush() //将缓存中的内容写入文件
方法三
str := "hello,golang"
err := ioutil.WriteFile("D:/demo3.txt", []byte(str), 0666)//这里第二个参数必须是byte类型的切片
if err != nil {
fmt.Println("fail")
return
}
复制文件
func copy(srcFile string, desFile string) (err error) {
byteStr, err1 := ioutil.ReadFile(srcFile) //这里的第一个参数是byte类型的切片
if err1 != nil {
return err1
}
err2 := ioutil.WriteFile(desFile, byteStr, 0666)
if err2 != nil {
return err2
}
return nil
}
func main() {
src := "D:/demo3.txt"
des := "D:/demo.txt"//不能搞c盘里的文件
err := copy(src, des)
if err != nil {
fmt.Println(err)
}
}
采用数据流的方法来复制文件
func copy(srcFile string, desFile string) (err error) {
//打开文件
file1, err1 := os.Open(srcFile)//open只能用来读取文件用
defer file1.Close()//记得关闭
file2, err2 := os.OpenFile(desFile, os.O_CREATE|os.O_WRONLY, 0666)
defer file2.Close()
if err1 != nil {
return err1
}
if err2 != nil {
return err2
}
//读取和写入文件
for {
//读取文件
var tempSlice = make([]byte, 128)
_, e1 := file1.Read(tempSlice)
if e1 == io.EOF {
break
}
if e1 != nil {
fmt.Println("读取文件失败")
return e1
}
//写入文件
_, e2 := file2.Write(tempSlice)
if e2 != nil {
fmt.Println("写入文件失败")
return e2
}
}
return nil
}
func main() {
src := "D:/demo3.txt"
des := "D:/demo4.txt"
err := copy(src, des)
if err != nil {
fmt.Println(err)
}
}
创建目录
//创建一级目录
OS.Mkdir("./abc",0666)
//创建多级目录
err := os.MkdirAll("./dir1/dir2/dir3",0666)
if err != nil{
fmt.Println(err)
}
删除文件或目录
err := os.Remove("aaa.txt")//("./aaa")删除文件夹
if err != nil{
fmt.Println(err)
}
//一次删除多个目录
err := os.RemoveAll("dir1")//多级目录全部删除,包括其中的文件
if err != nil{
fmt.Println(err)
文件的重命名
err := os.Rename("aaa.txt","bbb.txt")//第一个是现有的,第二个是要改的名字
if err != nil{
fmt.Println(err)
fmt包
上一章我们有提到fmt格式化I/O,这一章我们就详细来说说。在fmt包,有关格式化输入输出的方法就两大类:Scan 和 Print ,分别在scan.go 和 print.go 文件中。
print.go文件中定义了如下函数:
func Printf(format string, a ...interface{}) (n int, err error)
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
func Sprintf(format string, a ...interface{}) string
func Print(a ...interface{}) (n int, err error)
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
func Sprint(a ...interface{}) string
func Println(a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
func Sprintln(a ...interface{}) string
这9个函数,按照两个维度来说明,基本上可以说明白了。当然这两个维度是我个人为了记忆而分,并不是官方的说法。
一:如果把”Print”理解为核心关键字,那么后面跟的后缀有”f”和”ln”以及””,着重的是内容输出的结果;
如果后缀是”f”, 则指定了format
如果后缀是”ln”, 则有换行符
Println、Fprintln、Sprintln 输出内容时会加上换行符;Print、Fprint、Sprint 输出内容时不加上换行符;Printf、Fprintf、Sprintf 按照指定格式化文本输出内容。
二:如果把”Print”理解为核心关键字,那么前面的前缀有”F”和”S”以及””,着重的是输出内容的来源;
如果前缀是”F”, 则指定了io.Writer
如果前缀是”S”, 则是输出到字符串
Print、Printf、Println 输出内容到标准输出os.Stdout;
Fprint、Fprintf、Fprintln 输出内容到指定的io.Writer;
Sprint、Sprintf、Sprintln 输出内容到字符串。
scan.go文件中定义了如下函数:
func Scanf(format string, a ...interface{}) (n int, err error)
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
func Sscanf(str string, format string, a ...interface{}) (n int, err error)
func Scan(a ...interface{}) (n int, err error)
func Fscan(r io.Reader, a ...interface{}) (n int, err error)
func Sscan(str string, a ...interface{}) (n int, err error)
func Scanln(a ...interface{}) (n int, err error)
func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
func Sscanln(str string, a ...interface{}) (n int, err error)
这9个函数可以扫描格式化文本以生成值。同样也可以按照两个维度来说明。
一:如果把”Scan”理解为核心关键字,那么后面跟的后缀有”f”和”ln”以及””,着重的是输入内容的结果;
如果后缀是”f”, 则指定了format
如果后缀是”ln”, 则有换行符
Scanln、Fscanln、Sscanln 读取到换行时停止,并要求一次提供一行所有条目;
Scan、Fscan、Sscan 读取内容时不关注换行;
Scanf、Fscanf、Sscanf 根据格式化文本读取。
二:如果把”Scan”理解为核心关键字,那么前面的前缀有”F”和”S”以及””,着重的是输入内容的来源;
如果前缀是”F”, 则指定了io.Reader
如果前缀是”S”, 则是从字符串读取
Scan、Scanf、Scanln 从标准输入os.Stdin读取文本;
Fscan、Fscanf、Fscanln 从指定的io.Reader接口读取文本;
Sscan、Sscanf、Sscanln 从一个参数字符串读取文本。
格式化verb应用
在应用上,我们主要讲讲格式化verb ,fmt包中格式化的主要功能函数都在format.go文件中。
我们先来了解下有哪些verb:
通用:
%v 值的默认格式表示。当输出结构体时,扩展标志(%+v)会添加字段名
%#v 值的Go语法表示
%T 值的类型的Go语法表示
%% 百分号
布尔值:
%t 单词true或false
整数:
%b 表示为二进制
%c 该值对应的unicode码值
%d 表示为十进制
%o 表示为八进制
%q 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示
%x 表示为十六进制,使用a-f
%X 表示为十六进制,使用A-F
%U 表示为Unicode格式:U+1234,等价于"U+%04X"
浮点数、复数的两个组分:
%b 无小数部分、二进制指数的科学计数法,如-123456p-78;参见strconv.FormatFloat
%e 科学计数法,如-1234.456e+78
%E 科学计数法,如-1234.456E+78
%f 有小数部分 但无指数部分,如123.456
%F 等价于%f
%g 根据实际情况采用%e或%f格式(以获得 更简洁、准确的输出)
%G 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出)
字符串和[]byte:
%s 直接输出字符串或者[]byte
%q 该值对应的双引号括起来的Go语法字符串字面值,必要时会采用安全的转义表示
%x 每个字节用两字符十六进制数表示(使用a-f)
%X 每个字节用两字符十六进制数表示(使用A-F)
指针:
%p 表示为十六进制,并加上前导的0x
宽度通过一个紧跟在百分号后面的十进制数指定,如果未指定宽度,则表示值时除必需之外不作填充。精度通过(可能有的)宽度后跟点号后跟的十进制数指定。如果未指定精度,会使用默认精度;如果点号后没有跟数字,表示精度为0。举例如下:
%f: 默认宽度,默认精度
%9f 宽度9,默认精度
%.2f 默认宽度,精度2
%9.2f 宽度9,精度2
%9.f 宽度9,精度0
对于整数,宽度和精度都设置输出总长度。采用精度时表示右对齐并用0填充,而宽度默认表示用空格填充。
对于浮点数,宽度设置输出总长度;精度设置小数部分长度(如果有的话),除了%g/%G,此时精度设置总的数字个数。例如,对数字123.45,格式%6.2f 输出123.45;格式%.4g输出123.5。%e和%f的默认精度是6,%g的默认精度是可以将该值区分出来需要的最小数字个数。
对复数,宽度和精度会分别用于实部和虚部,结果用小括号包裹。因此%f用于1.2+3.4i输出(1.200000+3.400000i)。
其它flag:
+ 总是输出数值的正负号;对%q(%+q)会生成全部是ASCII字符的输出(通过转义);
- 在输出右边填充空白而不是默认的左边(即从默认的右对齐切换为左对齐);
# 切换格式:
八进制数前加0(%#o),十六进制数前加0x(%#x)或0X(%#X),指针去掉前面的 0x(%#p);
对%q(%#q),如果strconv.CanBackquote返回真会输出反引号括起来的未转义字符串;
对%U(%#U),如果字符是可打印的,会在输出Unicode格式、空格、单引号括起来 的go字面值;
' ' 对数值,正数前加空格而负数前加负号;
对字符串采用%x或%X时(% x或% X)会给各打印的字节之间加空格;
0 使用0而不是空格填充,对于数值类型会把填充的0放在正负号后面;
verb会忽略不支持的flag。
下面我们用一个程序来演示下:
package main
import (
"fmt"
"os"
)
type User struct {
name string
age int
}
var valF float64 = 32.9983
var valI int = 89
var valS string = "Go is an open source programming language that makes it easy to build simple, reliable, and efficient software."
var valB bool = true
func main() {
p := User{"John", 28}
fmt.Printf("Printf struct %%v : %v\n", p)
fmt.Printf("Printf struct %%+v : %+v\n", p)
fmt.Printf("Printf struct %%#v : %#v\n", p)
fmt.Printf("Printf struct %%T : %T\n", p)
fmt.Printf("Printf struct %%p : %p\n", &p)
fmt.Printf("Printf float64 %%v : %v\n", valF)
fmt.Printf("Printf float64 %%+v : %+v\n", valF)
fmt.Printf("Printf float64 %%#v : %#v\n", valF)
fmt.Printf("Printf float64 %%T : %T\n", valF)
fmt.Printf("Printf float64 %%f : %f\n", valF)
fmt.Printf("Printf float64 %%4.3f : %4.3f\n", valF)
fmt.Printf("Printf float64 %%8.3f : %8.3f\n", valF)
fmt.Printf("Printf float64 %%-8.3f : %-8.3f\n", valF)
fmt.Printf("Printf float64 %%e : %e\n", valF)
fmt.Printf("Printf float64 %%E : %E\n", valF)
fmt.Printf("Printf int %%v : %v\n", valI)
fmt.Printf("Printf int %%+v : %+v\n", valI)
fmt.Printf("Printf int %%#v : %#v\n", valI)
fmt.Printf("Printf int %%T : %T\n", valI)
fmt.Printf("Printf int %%d : %d\n", valI)
fmt.Printf("Printf int %%8d : %8d\n", valI)
fmt.Printf("Printf int %%-8d : %-8d\n", valI)
fmt.Printf("Printf int %%b : %b\n", valI)
fmt.Printf("Printf int %%c : %c\n", valI)
fmt.Printf("Printf int %%o : %o\n", valI)
fmt.Printf("Printf int %%U : %U\n", valI)
fmt.Printf("Printf int %%q : %q\n", valI)
fmt.Printf("Printf int %%x : %x\n", valI)
fmt.Printf("Printf string %%v : %v\n", valS)
fmt.Printf("Printf string %%+v : %+v\n", valS)
fmt.Printf("Printf string %%#v : %#v\n", valS)
fmt.Printf("Printf string %%T : %T\n", valS)
fmt.Printf("Printf string %%x : %x\n", valS)
fmt.Printf("Printf string %%X : %X\n", valS)
fmt.Printf("Printf string %%s : %s\n", valS)
fmt.Printf("Printf string %%200s : %200s\n", valS)
fmt.Printf("Printf string %%-200s : %-200s\n", valS)
fmt.Printf("Printf string %%q : %q\n", valS)
fmt.Printf("Printf bool %%v : %v\n", valB)
fmt.Printf("Printf bool %%+v : %+v\n", valB)
fmt.Printf("Printf bool %%#v : %#v\n", valB)
fmt.Printf("Printf bool %%T : %T\n", valB)
fmt.Printf("Printf bool %%t : %t\n", valB)
s := fmt.Sprintf("a %s", "string")
fmt.Println(s)
fmt.Fprintf(os.Stderr, "an %s\n", "error")
}
我们主要通过fmt.Printf来理解这些flag 的含义,这对我们今后的开发有较强的实际作用。至于其他函数,我就不一一举例,有兴趣可以进一步研究。
查缺补漏
*和&的区别 :
-
& 是取地址符号 , 即取得某个变量的地址 , 如 ; &a。存放地址的变量称为指针变量
-
*是指针运算符 , 可以表示一个变量是指针类型 , 也可以表示一个指针变量所指向的存储单元 , 也就是这个地址所存储的值,如果用这个改变,则改变了这个地址所在的值,用其他的赋值之类的语句,则地址所对应的值未改变。
举例:int a = 68 ,系统为变量a分配的首地址为0X065FDF4H,声明空指针long *p = NULL,p=&a是存放变量a地址的指针变量,即p=&a中存放的值为0x065FDF4H(a的值为68,&a的值为0x065FDF4H)。
三个点的用法
总结:
- 函数可变数量参数 定义函数的时候不知道具体参数的个数,可以在参数类型前面加…
- 通过append合并两个slice时,在第二个slice后加…
- 在数组中 中括号里加… 就可以使数组的元素个数自动扩展。















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









