






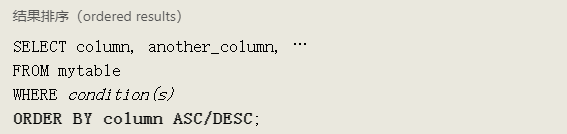
SQL





如果要的数据是从3-4,那么offset就应该是2
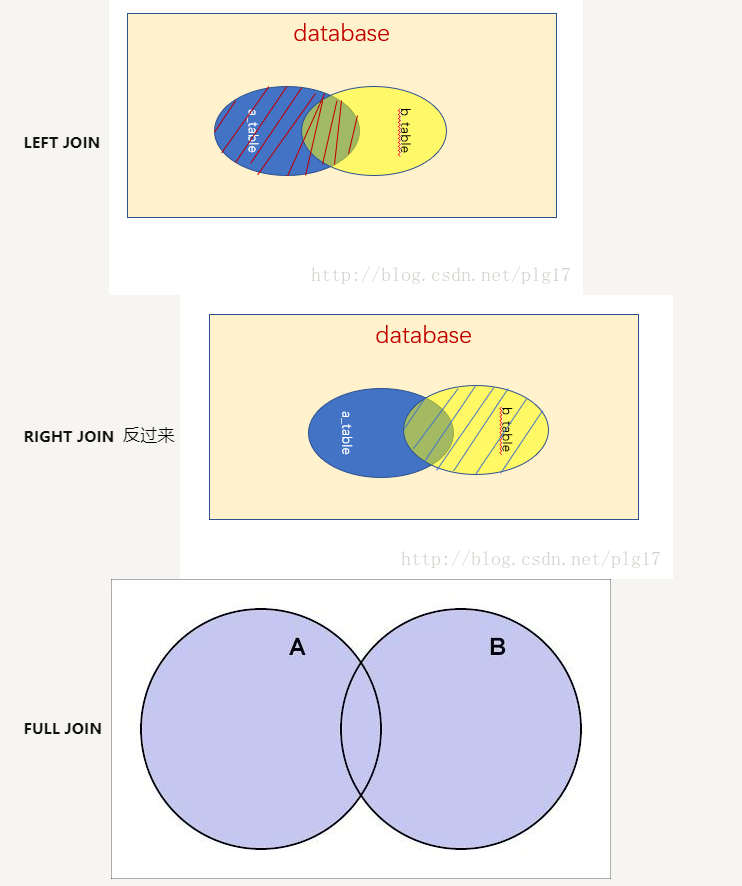
在用join进行多表联合查询时,inner join是将两个表合并后将主键相同的数据保留下来,比如A表,B表,B表中没有主键全乎的数据,那么A表中的那些数据就会丢掉。、
left join,right join full join

使用特殊字null
之前我们已经接触过NULL. 在数据库中,NULL表达的是 "无"的概念,或者说没有东西。因为 NULL的存在,我们需要在编写SQL时考虑到某个属性列可能是 NULL的情况, 这种特殊性会造成编写SQL的复杂性,所以没有必要的情况下,我们应该尽量减少 NULL的使用,让数据中尽可能少出现 NULL的情况。
如果某个字段你没有填写到数据库,很可能就会出现NULL 。所有一个常见的方式就是为字段设置默认值,比如 数字的默认值设置为0,字符串设置为 ""字符串. 但是在一些NULL 表示它本来含义的场景,需要注意是否设置默认值还是保持NULL。 (f比如, 当你计算一些行的平均值的时候,如果是0会参与计算导致平均值差错,是NULL则不会参与计算).
还有一些情况很难避免 NULL 的出现, 比如之前说的 outer-joining 多表连接,A和B有数据差异时,必须用 NULL 来填充。这种情况,可以用IS NULL和 IS NOT NULL 来选在某个字段是否等于 NULL.

在查询中使用表达式
之前我们在SQL中的出现col_name(属性名)的 地方,我们都只是写上col_name自身。其实在SQL中可以用col_name的地方,都可以用表达式 来指定对属性进行一定的计算或处理。举个例子:假设有一个col_name是出生日期,现在要求SQL返回当前的年龄,这就可以用一个时间计算表达式对 出生日期做计算得到年龄。表达式可以对 数字运算,对字符串运算,也可以在表达式中只包含常量不包含col_name(如:SELECT 1+1)

当我们用表达式对col属性计算时,很多事可以在SQL内完成,这让SQL更加灵活,但表达式如果长了则很难一下子读懂。所以SQL提供了AS关键字, 来给表达式取一个别名.类似于 import tensorflow as tf


也可以用于给表等取别名。
在查询中统计数据
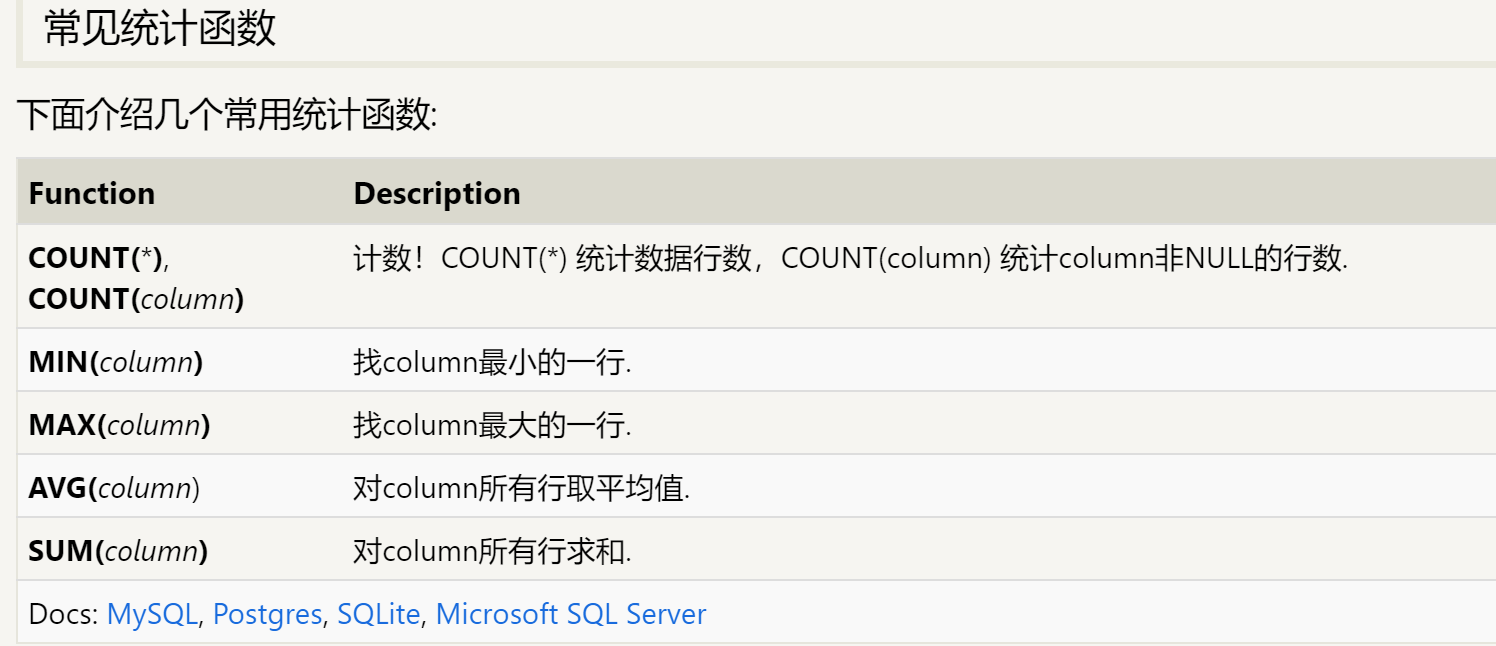
SQL默认支持一组统计表达式,他们可以完成数据统计,如:计数,求平均等。 以Movies表数据为例,这些统计表达式可以帮我们回答以下问题:“Pixar公司生产了多少电影?”, 或 “每一年的票房冠军是谁?”.

常用函数
分组统计
GROUP BY 数据分组语法可以按某个col_name对数据进行分组,如:GROUP BY Year指对数据按年份分组, 相同年份的分到一个组里。如果把统计函数和GROUP BY结合,那统计结果就是对分组内的数据统计了.
GROUP BY 分组结果的数据条数,就是分组数量,比如:GROUP BY Year,全部数据里有几年,就返回几条数据, 不管是否应用了统计函数.

先对数据用where来筛选数据,再将结果用group by分组,如果还需要对分好组的数据进行筛选 就可以用having语法来解决

完整的select查询语法

--select中还能套select
SELECT(select(Domestic_sales+International_sales)as total_sale FROM movies
left join Boxoffice on movies.id = Boxoffice.movie_id
order by total_sale desc limit 1)-
( Domestic_sales+International_sales)as sub_sale,title FROM movies
left join Boxoffice
on movies.id = Boxoffice.movie_id
count(*)记得搞一下
一个语句全部完成后才能有;
select 查询列时,列名不区分大小写
表示一个字符串的时候(中间有空格)用双引号""
SELECT * FROM movies
ORDER BY title
limit 5 offset 5
//这里offset 5 从5开始,5不算。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









