







目录
深入理解分布式事务③ ---->分布式事务基础(MySQL 中锁的分类 ->悲观锁、乐观锁、读锁(共享锁)、写锁(排他锁)、表锁、行锁、页面锁、间隙锁、临键锁、死锁)案例演示及详解
书接上文说道,MySQL 使用 锁 和 MVCC 机制实现了事务隔离级别。
MySQL 默认的 【可重复读】这个事务隔离级别就使用了 MVCC 机制。
深入理解分布式事务④ ---->分布式事务基础(MySQL 存储引擎 InnoDB 中的 MVCC 原理------>对数据进行增、删、改、查时,对数据的版本号进行分析)详解
InnoDB 存储引擎中的 MVCC 原理
在 MVCC 机制中,每个连接到数据库的读操作,在某个瞬间看到的都是数据库中数据的一个快照,而写操作的事务提交之前,读操作是看不到这些数据的变化的。
MVCC 机制能够大大提升数据库的读写性能,很多数据库厂商的事务性存储引擎都实现了 MVCC 机制,包含 MySQL、Oracle、PostgreSQL 等。虽然不同数据库实现 MVCC 机制的细节不同,但大多实现了非阻塞的读操作,写操作也只会锁定必要的数据行。
从本质上讲,MVCC 机制保存了数据库中数据在某个时间点上的数据快照,这意味着同一个读操作的事务,按照相同的条件查询数据,无论查询多少次,结果都是一样的。从另一个角度来讲,这也意味着不同的事务在同一时刻看到的同一张表的数据可能不同。
在 InnoDB 存储引擎中,MVCC 机制是通过在每行数据表记录后面保存两个隐藏的列来实现的,一个列用来保存行的创建版本号,另一个列用来保存行的过期版本号。每当有一个新的事物执行时,版本号就会自动递增。事务开始时刻的版本号作为事务的版本号,用于和查询到的每行记录的版本号做对比。
接下来,演示下在可重复读事务隔离级别下,MVCC 机制是如何完成增删改查操作的。
查询操作
在查询操作中, InnoDB 存储引擎会根据下面两个条件检查每行记录。
1、InnoDB 存储引擎只会查找不晚于(也就是早于)当前事务版本的数据行,也就是说,InnoDB 存储引擎只会查找版本号小于或者等于当前事务版本的数据行。这些数据行要么在事务开始前就已经存在,要么就是事务本身插入或者更新的数据行。
2、数据行删除的版本要么还没有被定义,要么大于当前事务的版本号,只有这样才能确保事务读取到的行,在事务开始之前没有被删除。
这里需要注意的是,只有符合上面两个条件的数据行,才会被返回作为查询的结果数据。
例如:
存在 事务A 和 事务B 两个事务,事务A 中存在两条相同的 select 语句,事务B 中存在一条 update 语句。
事务A 中的第一条 select 语句在 事务B 提交之前执行,第二条 select 语句在 事务B 提交后执行。
事务A 如下所示:
# 开启事务
start transaction;
# 在事务B提交之前执行
select * from account where id = 1;
# 在事务B提交之后执行
select * from account where id = 1;
# 提交事务
commit;
事务B 如下所示:
# 开启事务
start transaction;
# 修改数据
update account set balance = balance + 1000 where id = 1 ;
# 提交事务
commit;
如果不使用 MVCC 机制,则事务A 中的第一条 select 语句读取到的数据是修改之前的数据,而第二条 select 语句读取的是修改后的数据,两次读取的数据不一致。
演示不使用 MVCC 机制
演示:把 MySQL 的 InnoDB 默认的事务隔离级别从【可重复读】改成【读已提交】。
# 设置当前终端的事务隔离级别设置为 read committed 读已提交
set session transaction isolation level read committed;
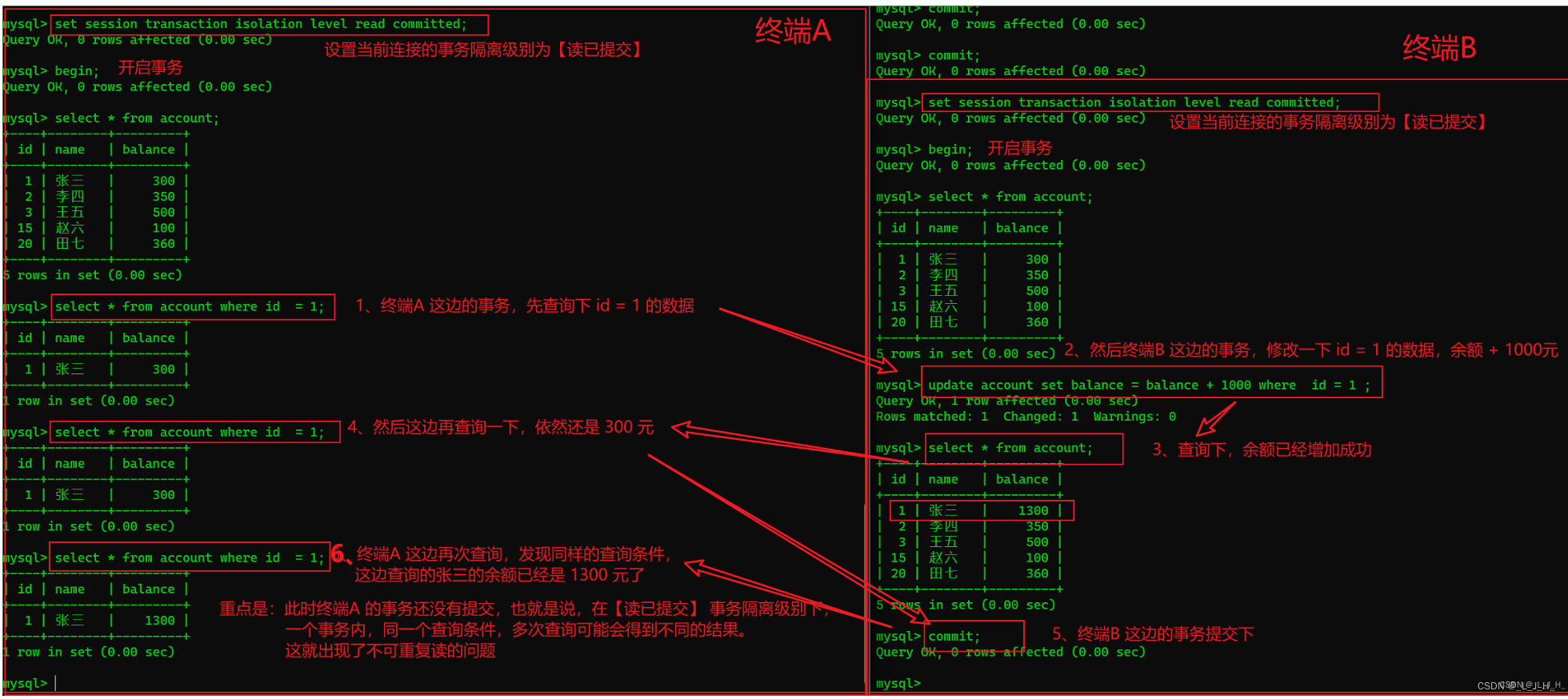
如果把【读已提交】改成【读未提交】,那么上面的例子,终端B 那边只要修改 id = 1 的数据,且不需要提交事务,终端A 这边同样的查询语句,也能查到的张三的余额是 1300 元了。
这里就不再演示了,详细的可以看这篇:MySQL 的 4 种事务隔离级别【读未提交、读已提交、可重复读、串行化】的最佳实践演示
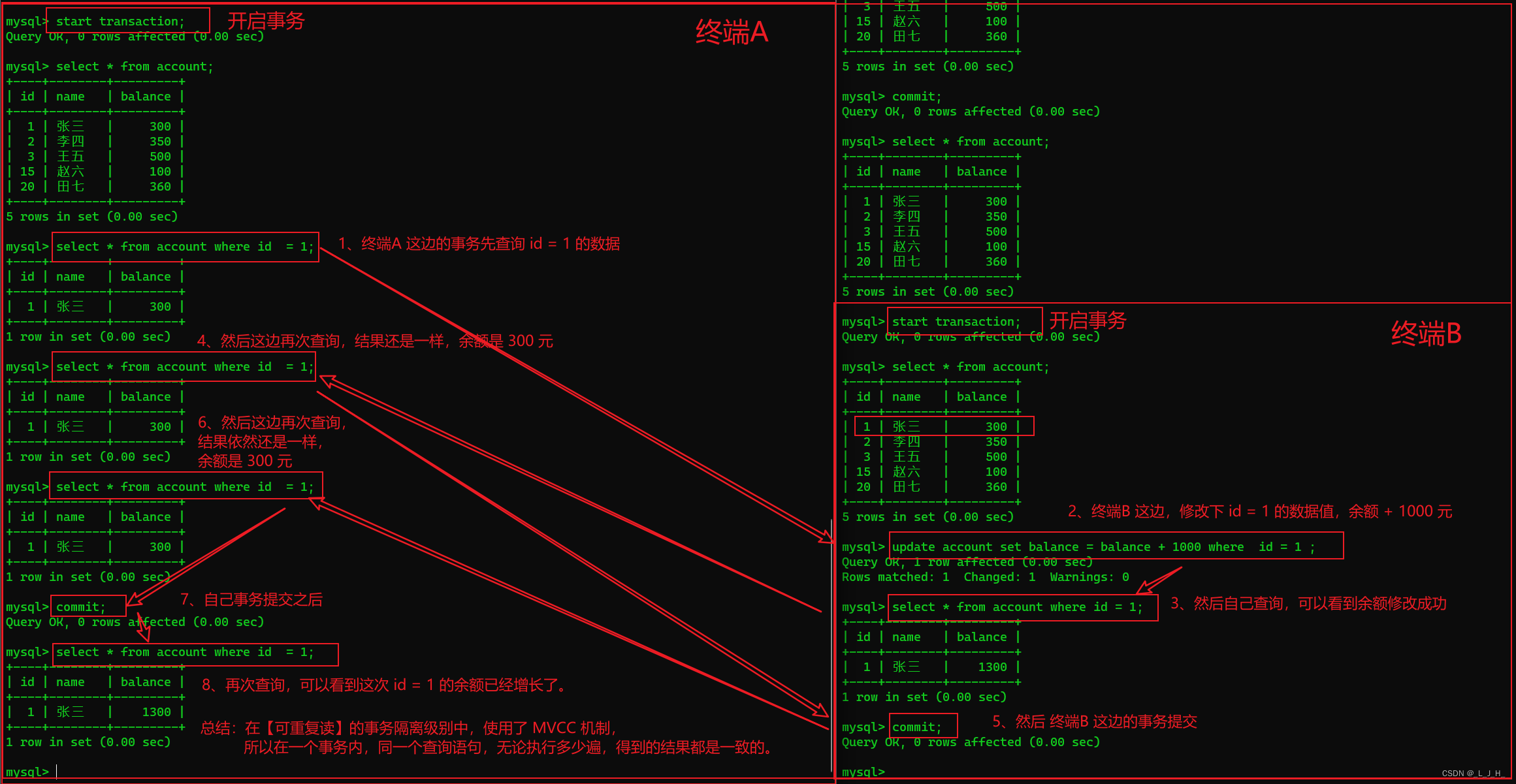
演示使用 MVCC 机制
MySQL 的 InnoDB 默认的事务隔离级别就是【可重复读】,这个级别就使用到了 MVCC 机制。
如果使用了 MVCC 机制。则无论事务B如何修改数据,事务A 中的两条 select 语句查询出来的结果始终是一致的。
插入操作
在插入操作中,InnoDB 存储引擎会将新插入的每一行记录的当前系统版本号保存为行版本号
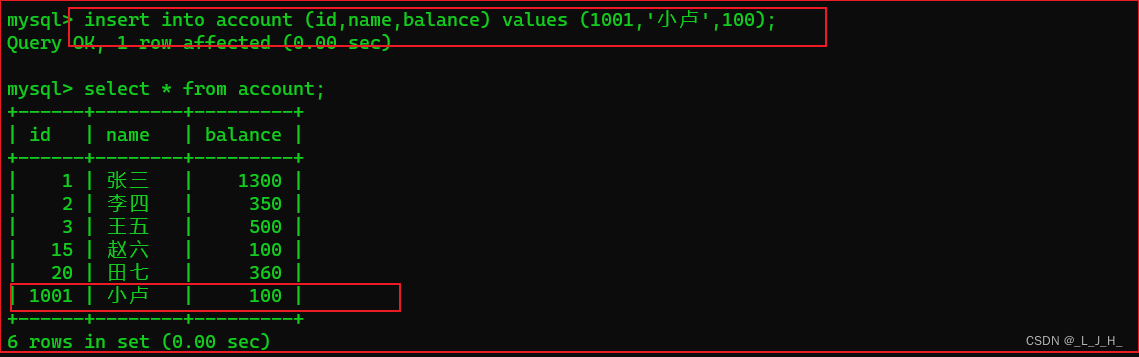
例如向 account 数据表中插入一条数据,同时假设 MVCC 的两个版本号分别为【create_version】和【delete_version】。
【create_version】代表创建行的版本号;【delete_version】代表删除行的版本号。为了更好的展示效果,再增加一个描述事务版本号的字段【trans_id】。向 account 数据表插入数据的 SQL 语句如下所示。
insert into account (id,name,balance) values (1001,'小卢',100);
上面说的假设有两个版本号字段名叫这个,所以对应的版本号信息如下所示:
注意: 在 MySQL 中,实际上没有直接的命令可以查看数据行的版本号,所以画这个图用来描述 MVCC 机制中,每行数据的版本号大概是这样实现的:
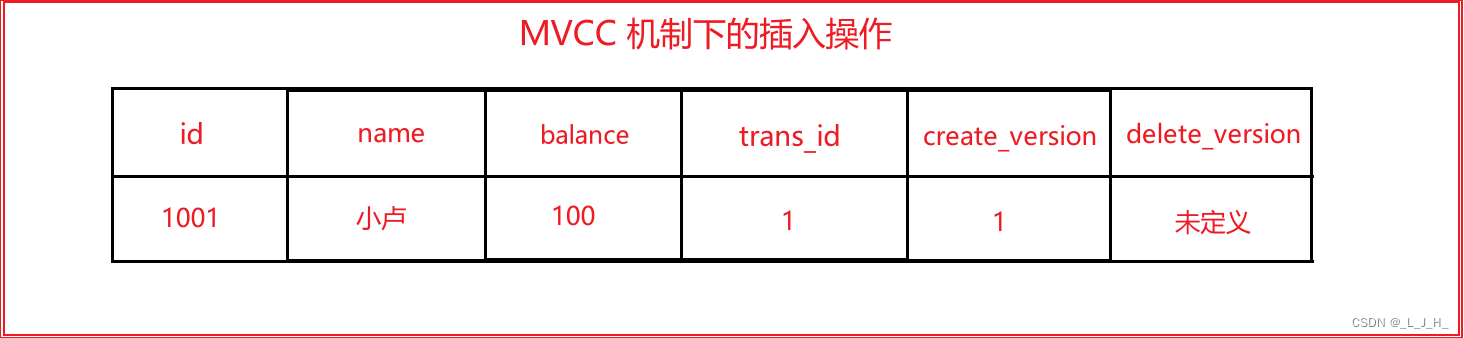
可以看出,当向数据表中新增记录时,需要设置保存行的版本号,而删除行的版本号未定义。
在 MySQL 中,实际上没有直接的命令可以查看数据行的版本号。MVCC 是 MySQL 内部实现的一种机制,对于普通用户来说,通常是不可见的。版本号是在 MySQL 内部用于管理并发事务的一种标识,用户一般无法直接查看它。
更新操作
在更新操作中,InnoDB 存储引擎会插入一行新纪录,并保存当前系统的版本号作为新纪录行的版本号,同时保存当前系统的版本号到原来的数据行作为删除标识。
例如,将 account 数据表中 id 为 1001 的用户的账户余额增加 100 元,SQL 语句如下:
update account set balance = balance + 100 where id = 1001 ;
结合上面的插入操作来看这里的更新操作:
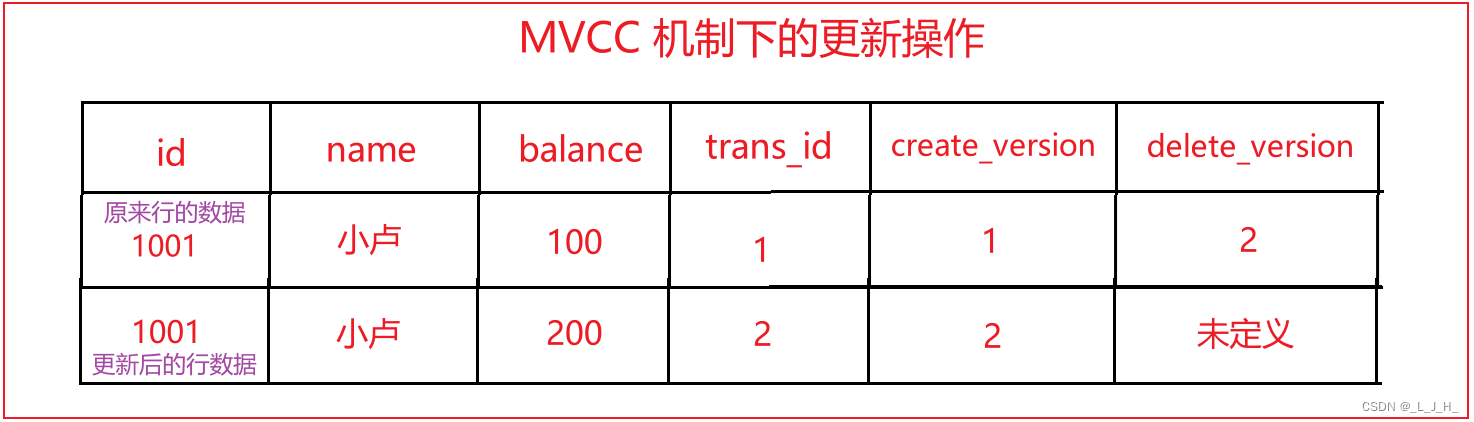
可以看出,执行更新操作时,MVCC 机制是先将原来的数据复制一份,将 balance 字段的值增加 100 后,再将 create_version 字段的值设置为当前系统的版本号,而 delete_version 字段的值未定义。
除此之外,MVCC 机制还会将原来行的 delete_version 字段的值设置为当前的系统版本号,以标识原来行被删除。
删除操作
在删除操作中,InnoDB 存储引擎会保存删除的每一个行记录当前的系统版本号,作为行删除标识。
(在执行删除操作时,InnoDB 存储引擎不会立即从数据库中物理删除行记录,而是会给删除的每一行记录标记一个当前的系统版本号,将其作为行删除标识。)
对应的版本号信息如下图:
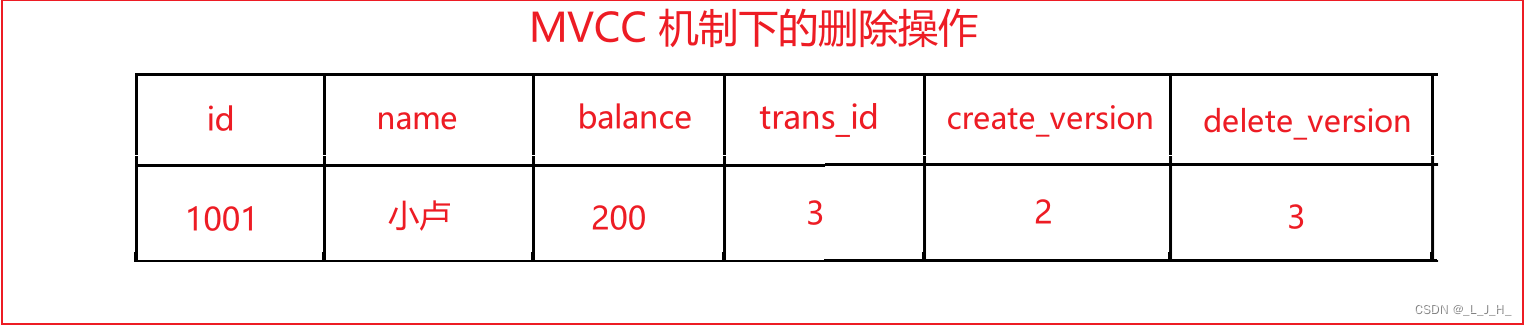
可以看出,当删除数据表中的数据行时,MVCC 机制会将当前系统的版本号写入被删除数据行的删除版本字段 delete_version 中,以此来标识当前数据行已经被删除。

















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











