






Operator官方文档:https://kubernetes.io/zh-cn/docs/concepts/extend-kubernetes/operator/
Kubebuilder官方文档:https://cloudnative.to/kubebuilder/cronjob-tutorial/basic-project.html
思考:
k8s中如何部署服务或者扩展资源?
yaml,helm,api
CRD
operator
Operator模式
Operator介绍
Kubernetes 是一个高度可扩展的系统,它可扩展的功能包括kubectl、APIServer、K8资源、Controller 、Scheduler 、CNI 、CSI 、CRI ,虽然它的扩展点这么多,但是一般来说我们接触的比较多的还是CR、CRD、准入控制,其他扩展功能也有大批的开源组件可供使用。这次讲的Operator就会涉及到CR、CRD、准入控制。
Operator:
Kubernetes 的 Operator 模式概念允许你在不修改Kubernetes自身代码的情况下, 通过为一个或多个自定义资源关联控制器来扩展集群的能力。
Operator 是 Kubernetes API 的客户端, 充当自定义资源的控制器。
Operator模式 = 操作对象(CRD) + 控制逻辑(controller)
Operator 遵循k8的理念,它利用自定义资源管理应用及其组件,Operator模式会封装你编写的任务自动化代码。
Operator 常见使用范围包括:
- 按需部署应用
- 获取/还原应用状态的备份
- 处理应用代码的升级以及相关改动。例如,数据库 schema 或额外的配置设置
- 发布一个 service,要求不支持 Kubernetes API 的应用也能发现它
- 模拟整个或部分集群中的故障以测试其稳定性
- 在没有内部成员选举程序的情况下,为分布式应用选择首领角色
从 Operator 理念的提出到现在已经有了很多工具可以帮助我们快速低成本的开发,其中最常用的就是operator-sdk 和 kubebuilder,我们这个系列选用 kubebuilder。
除了我们自己开发之外还可以在 https://operatorhub.io/ 上找到别人开发的现成的 Operator 进行使用
Operator出现的初衷就是用来解放运维人员的,如今Operator也越来越受到云原生运维开发人员的青睐。
下面示意图对使用Operator和不使用Operator进行了对比:
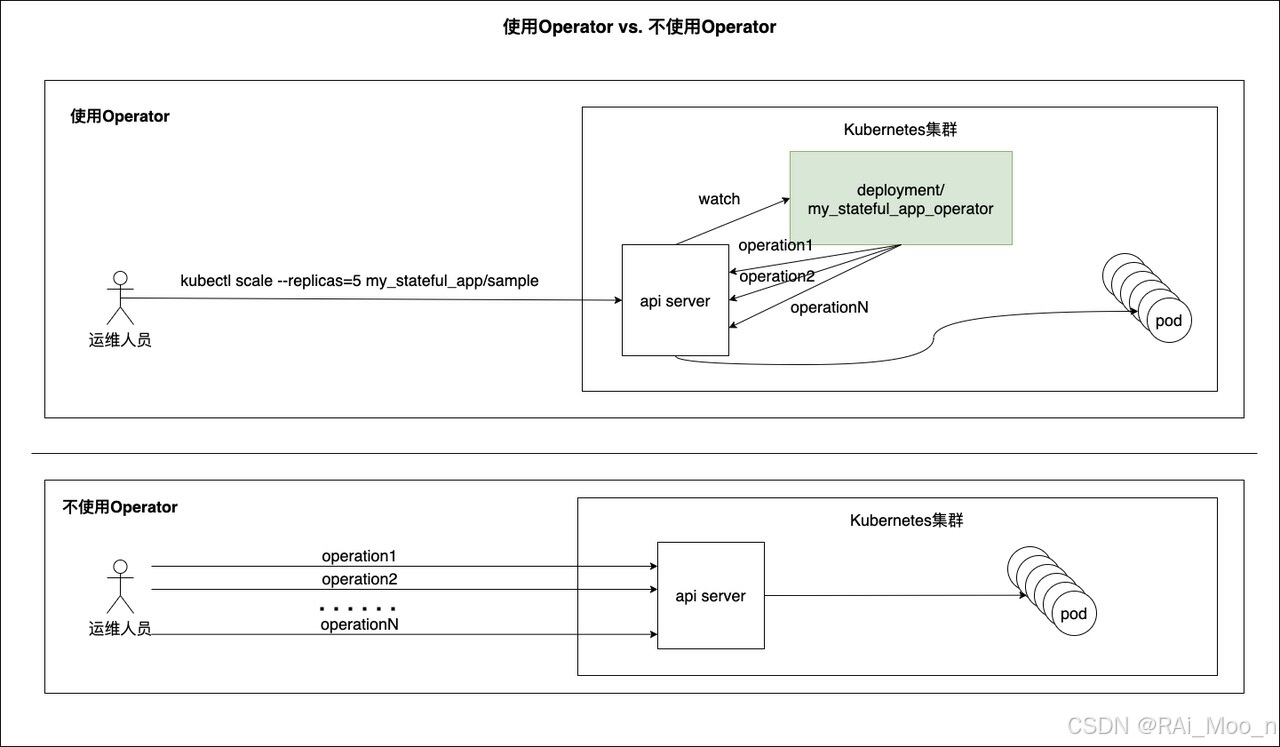
通过这张图,能很明显地感受到operator的优点。
我们看到在使用operator的情况下,对有状态应用的伸缩操作(或其他复杂操作),运维人员仅需一个命令就可以进行操作,运维人员也无需知道有状态应用的伸缩操作的原理是什么。
在没有使用operator的情况下,运维人员需要对有状态应用的伸缩的操作步骤很熟悉,并按顺序执行一个个命令并检查响应,如果遇到失败报错还要重试,直到操作成功。
Operator虽然好用,但是还是需要一定的基础积累。比如如下几个方面:
- 首先,你要对k8s比较了解,而k8s自从开源以来,版本迭代、新feature日益复杂,理解起来还是有一定难度的
- 手撸operator,几乎无人这么做,大多数人一般都会选择现成的开发框架和工具,比如kubebuilder、operator framework sdk等;
- operator的实现也有高低之分。operator framework就提出了一个包含五个等级的operator能力模型。使用Go开发高级能力的operator也需要对client-go这个官方库有深入的了解。

Client-go
如果我们需要对k8中的资源进行crud时,需要通过api接口进行操作。但是我们不需要自己去调用各种api来实现,官方有开源的SDK来供我们使用,即client-go。所以operator要使用client-go。
client-go提供四种客户端对象来和apiserver进行交互:
- RESTClient:最基础的客户端对象,它只对HTTP请求进行了封装,是RESTFul风格的API。这个对象使用起来并不方便,因为很多参数都要人为来设置。于是client-go基于RESTClient又实现了三种新的客户端对象
- ClientSet:把Resource和Version也封装好了,一个资源就是一个客户端,多个资源就对应了多个客户端,所以ClientSet就是多个客户端的集合了,不过ClientSet只能访问内置资源,访问不了自定义资源
- DynamicClient:是一种动态客户端,它可以动态的指定资源的组、版本和资源。因此它可以对任意K8资源进行RESTful操作,包括自定义资源。它封装了 RESTClient,所以同样提供 RESTClient 的各种方法。该类型的官方例子:https://github.com/kubernetes/client-go/tree/master/examples/dynamic-create-update-delete-deployment。
- DiscoveryClient:用于发现k8的API Server支持的Group、Version、Resources等信息;
Informer
informer不仅是使用operator需要学习的,更是k8中最核心的机制。
我们去获取集群中的资源对象以及当集群中存在大量资源数据时,每次从apiServer获取都会占用大量内存资源,client-go使用informer机制来解决。
Informer在初始化的时先通过List去从k8 API中取出资源的全部object对象,并同时缓存,然后通过Watch的机制去监控资源。
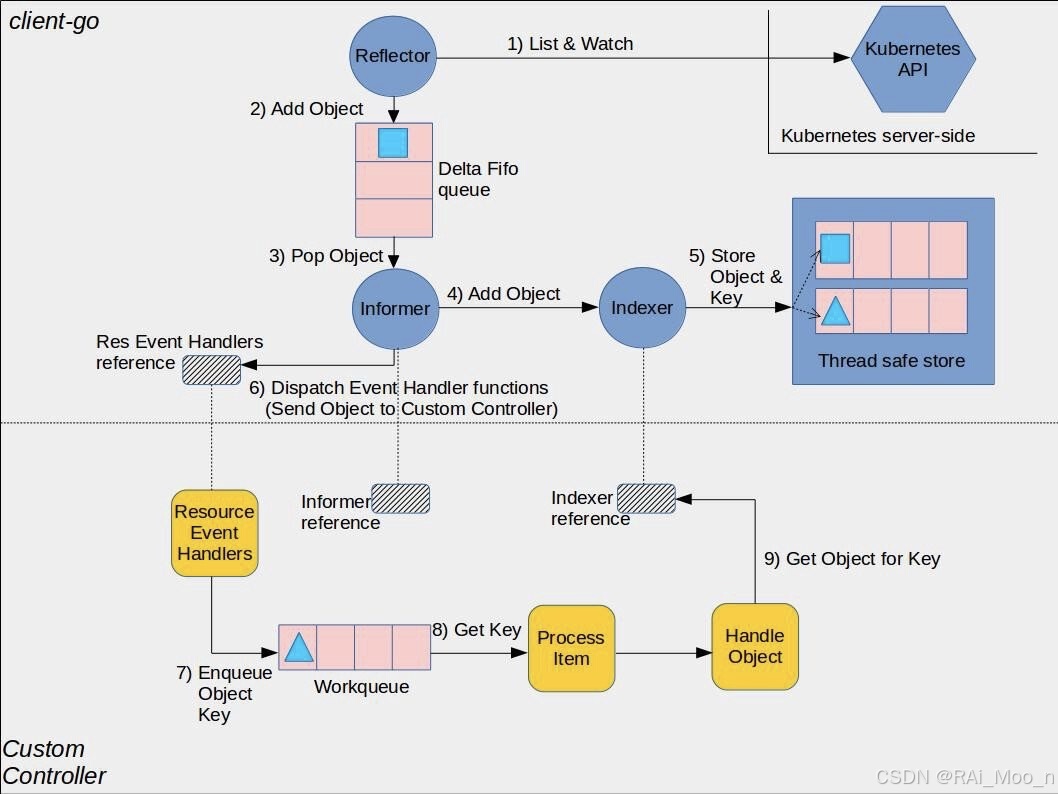
Reflector(反射器): 定义在/tools/cache包内的Reflector类型中的reflector,它Watch着k8 API 以获取指定的资源类型,当watch的资源发生变化时,触发相应的变更事件。例如Add 事件、Update 事件、Delete 事件,然后将其资源对象存放到本地缓存也就是DeltaFIFO中 DeltaFIFO: DeltaFIFO是一个生产者消费者队列,生产者是Reflector,消费者是pop函数,Delta是一个资源对象存储,它可以保存资源对象的操作类型,如 Add 操作类型、Update 操作类型、Delete 操作类型、Sync 操作类型等 Indexer: Indexer是client-go用来存储资源对象并自带索引功能的本地存储,Informer从DeltaFIFO中将消费出来的资源对象存储至Indexer。以此,我们便可从Indexer中读取数据,而无需从apiserver读取 WorkQueue:DeltaIFIFO收到事件后会先将事件存储在自己的数据结构中,然后直接操作Store中存储的数据,更新完 store 后DeltaIFIFO 会将该事件 pop 到WorkQueue中,Controller收到WorkQueue中的事件会根据对应的类型触发对应的回调函数(这是在控制器代码中创建的队列,用于将对象的分发与处理解耦)
比如删除一个 Pod,一个Informer的执行流程是怎样的:
- 首先初始化Informer,Reflector通过List接口获取所有的Pod对象
- Reflector拿到所有Pod后,将全部Pod放到Store(本地缓存)中
- 如果有人调用Lister的List/Get方法获取Pod,那么Lister直接从Store中去拿数据
- Informer初始化完成后,Reflector开始Watch Pod相关的事件
- 此时如果我们删除一个pod,那么Reflector会监听到这个事件,然后将这个事件发送到DeltaFIFO中
- DeltaFIFO首先先将这个事件存储在一个队列中,然后去操作Store中的数据,删除其中的Pod
- DeltaFIFO然后pop这个事件到事件处理器(资源事件处理器)中进行处理
- LocalStore会周期性地把所有的Pod信息重新放回DeltaFIFO中
如果只停留在上述的八股文中,你可能永远无法真正理解。那这里就留个小问题,为什么informer不直接去list/watch k8 api呢?
代码demo
首先,保证本地HOME目录有配置kubernetes集群的配置文件,然后执行go run client-go.go运行下面的代码
package main
import (
"flag"
"fmt"
"os"
"path/filepath"
"time"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
var kubeconfig *string
if home := homeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "(optional) absolute path to the kubeconfig file")
} else {
kubeconfig = flag.String("kubeconfig", "", "absolute path to the kubeconfig file")
}
flag.Parse()
// uses the current context in kubeconfig
config, err := clientcmd.BuildConfigFromFlags("", *kubeconfig)
if err != nil {
panic(err.Error())
}
// creates the clientset
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
for {
pods, err := clientset.CoreV1().Pods("").List(metav1.ListOptions{})
if err != nil {
panic(err.Error())
}
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
time.Sleep(10 * time.Second)
}
}
func homeDir() string {
if h := os.Getenv("HOME"); h != "" {
return h
}
return os.Getenv("USERPROFILE") // windows
}
Kubebuilder
Kubernetes resource、resource type、API和controller介绍
Kubernetes发展到今天,其本质已经显现:
- Kubernetes就是一个“数据库”(数据持久化在etcd中);
- API就是“sql语句”;
- API采用Restful风格, resource type是API的endpoint;
- 每一类resource(即Resource Type)是一张“表”,Resource Type的spec对应“表结构”信息(schema);
- 每张“表”里的一行记录就是一个resource,即该表对应的Resource Type的一个实例;
- Kubernetes这个“数据库”内置了很多“表”,比如Pod、Deployment、DaemonSet、ReplicaSet等;
下面是一个Kubernetes API与resource关系的示意图:
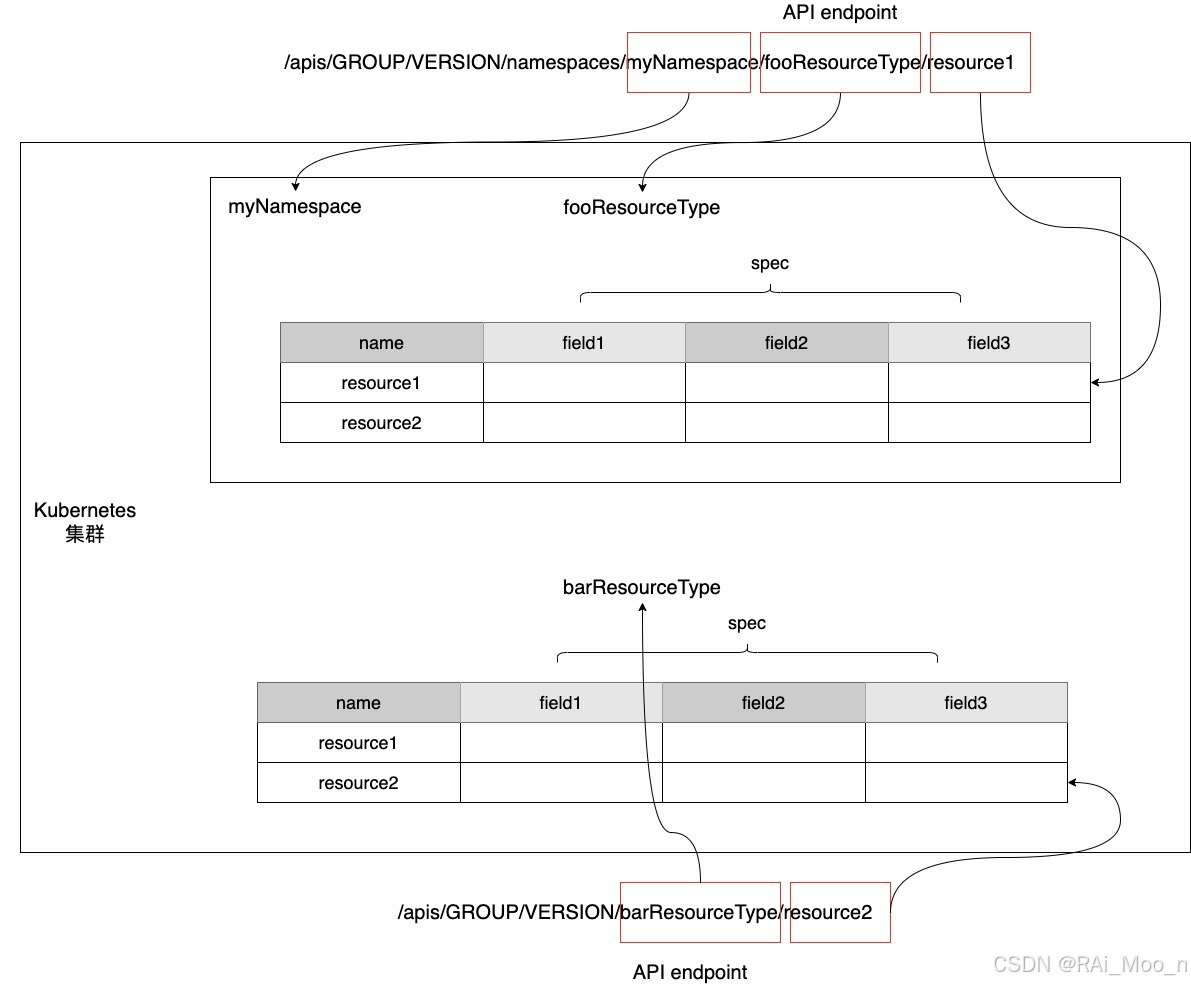
k8并非真的只是一个“数据库”,它是服务编排和容器调度的平台标准,它的基本调度单元是Pod(也是一个resource type)。那么Pod又是如何被创建、更新和删除的呢?这就离不开controller了。每一类resource type都有自己对应的controller。以pod这个resource type为例,它的controller为ReplicasSet的实例。
controller的运行逻辑如下图所示:
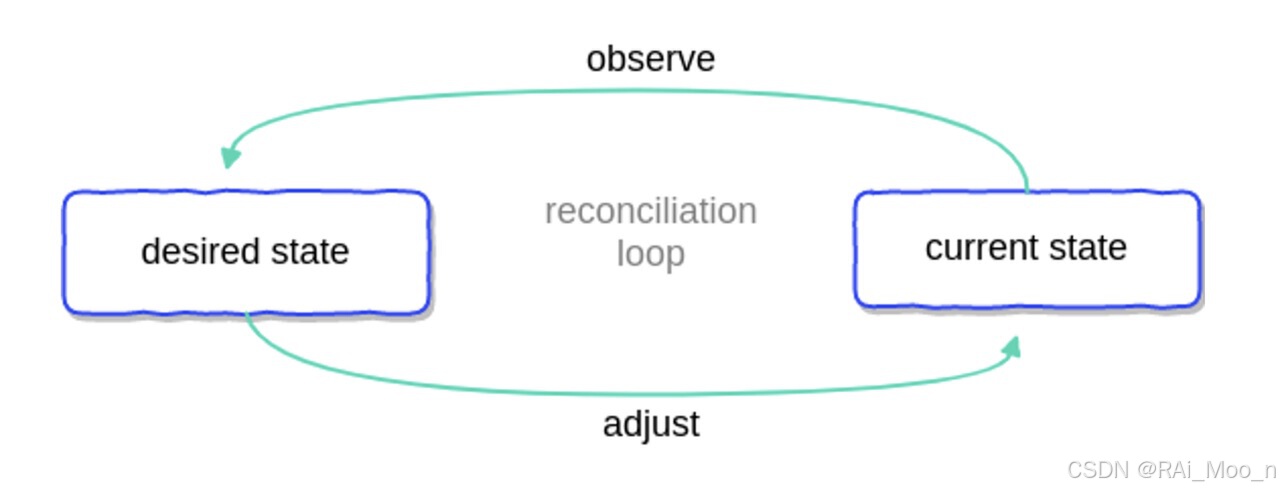
controller一旦启动,将尝试获得resource的当前状态,并与存储在k8s中的resource的期望状态(desired state,即spec)做比对,如果不一致,controller就会调用相应API进行调整,尽力使得current state与期望状态达成一致。这个达成一致的过程被称为协调(reconciliation)
GV & GVK & GVR
- GV: Api Group & Version
- GVK: Group Version Kind
-
GVR: Group Version Resource
Resource是Kind的对象标识,一般来Kind和Resource是1:1的,但是有时候存在1:n的关系,不过对于Operator来说都是1:1的关系
用下面这个例子解释就非常简单,相信大家对k8有一点入门的了解就清楚了。
apiVersion: apps/v1 # 这个是GV,G是apps,V是v1
kind: Deployment # 这个就是Kind
sepc: # 加上下放的spec就是 Resource了
...通过GVK,k8就能找到你到底要创建什么类型的资源,根据你定义的Spec创建好资源之后就成为了Resource,也就是GVR。GVK/GVR就是k8资源的坐标,是我们对资源进行crud的基础。
Schema
每种资源的都需要有对应的Scheme,Scheme结构体包含gvkToType和typeToGVK的字段映射关系,APIServer根据Scheme来进行资源的序列化和反序列化。
- Schema定义了自定义资源的字段、验证规则、默认值等,确保数据的一致性和合法性。
Schema和CRD的联系:
- 功能:Scheme主要用于类型管理和序列化/反序列化,而CRD用于定义和扩展k8 API。
- 使用场景:Scheme是Kubebuilder项目内部使用的,用于确保控制器和API服务器之间的类型一致性;CRD是k8集群中的资源,用于定义自定义资源的结构和行为。
-
实现方式:Scheme是通过Go代码定义和管理的,而CRD是通过YAML定义并应用到k8集群中的。在 Kubebuilder 项目中:
- Scheme 通常在
pkg/apis/目录下定义,包含了所有自定义资源(CR)的Go结构体和相应的类型信息。 - CRD是通过代码生成工具自动生成的。用户在定义自定义资源的Go结构体后,Kubebuilder会生成相应的 CRD YAML文件,用户可以将这些文件应用到k8集群中。
- Scheme 通常在
// schema定义了资源的参数模型,并通过序列化方式转化为CRD等配置,存储至etcd中
// 此处为定义instance的schema
type Instance struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata"`
Spec InstanceSpec `json:"spec"`
Status InstanceStatus `json:"status,omitempty"`
}
type InstanceSpec struct {
RegionID string `json:"regionID"`
ZoneID string `json:"zoneID"`
VpcID string `json:"vpcID"`
SubnetID string `json:"subnetID"`
}# 此处为crd内容
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
...
spec:
names:
...
versions:
name: v1alpha1
schema:
openAPIV3Schema:
description: Instance is a specification for a Instance Instance resource
properties:
apiVersion:
description: 'APIVersion defines the versioned schema of this representation
of an object. Servers should convert recognized schemas to the latest
internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources'
type: string
kind:
description: 'Kind is a string value representing the REST resource this
object represents. Servers may infer this from the endpoint the client
submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds'
type: string
metadata:
type: object
spec:
description: Spec defines the desired state of Instance
properties:
regionID:
description: RegionID is the location that the Instance lives in.
type: string
subnetID:
description: SubnetID is the id of VPC subnet
type: string
vpcID:
description: VpcID is the id of user VPC
type: string
zoneID:
description: ZoneID is the id of target available-zone
type: string
required:
- regionID
- subnetID
- vpcID
- zoneID
type: object
status:
...
required:
- metadata
- spec
type: object
served: true
storage: true
subresources: {}
status:
...Manager
每个进程会有一个Manager,这是核心组件,kubebuilder会在main函数中创建Manger,其主要负责
- metrics的暴露
- webhook证书
- 初始化共享的cache
- 初始化共享的clients 用于和APIServer进行通信
- 所有的Controller的运行
Cache
Kubebuilder的内部组件。负责同步Controller关心的资源,其核心是GVK->Informer的映射,一般我们的Get和List操作都会从Cache中获取数据。
Cache是一个本地缓存,用于存储k8集群中的对象。这样可以减少对API Server的频繁请求,提高性能。
Client
Controller工作中需要对对资源进行CURD,CURD操作封装到Client中来进行,其中的写操作(增删改)直接访问 APIServer,其中的读操作(查)对接的是本地的 Cache。
Controller
Controller 使用client-go包里的informer模式工作,向APIServer watch GVK下对应的GVR,一个Manager可能会有多个Controller,每个Controller负责对一种资源进行调谐,我们一般只需要实现Reconcile方法就行。
Webhook
Webhook就是我们准入控制实现的地方了,主要是有两类接口,一个是MutatingAdmissionWebhook需要实现Defaulter接口,一个是ValidatingAdmissionWebhook需要实现Validator接口。
- Manager启动并管理Controller和Webhook。
- Controller使用Cache和Client来监听和操作资源。
- Webhook可以在资源创建或更新时进行验证和变更,确保资源符合预期。
- Schema定义了资源的结构和验证规则,供Controller和Webhook使用。

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









