







- 创建分区表 按年月分区:
create table if not exists p_test(
id int ,
name string
)
partitioned by (year string,month string)
row format delimited fields terminated by '\t';
此时查看hdfs的目录 只能发现有p_test的表名,没有分区内的情况,说明需要添加分区或者添加数据;
- 测试添加分区:
alter table p_test add partition(year='2019',month='201805') location '/user/hive/warehouse/hive_test.db/p_test/201805/20180509';
查看hdfs结果和hive表
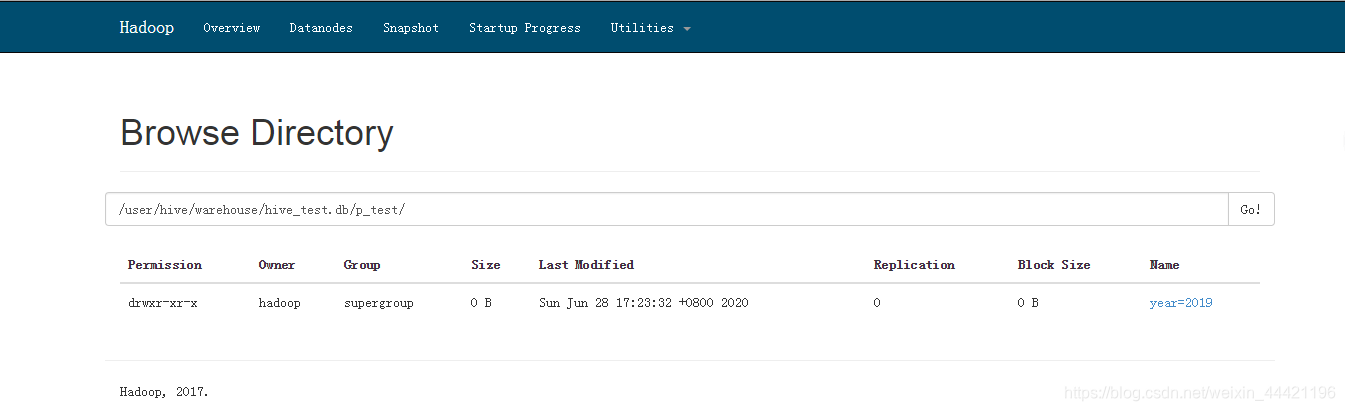
发现分区已经加上了,但是没有数据;
- 测试直接向分区表中写数据;
insert into table p_test partition(year ,month) select 1,"lisa", "2019" as year, "201905" as month from dept limit 1 ;
发现报错:
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
此时应该设置为 非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
再运行插入数据语句,不再报错:
但是发现 此过程耗时极长:(插入一条数据 ,耗时了好几分钟!)
谁知mr的模式为本地模式:
SET mapreduce.framework.name=local;
再测试一次插入速度:
insert into table p_test partition(year ,month) select 2,"linda", "2020" as year, "201906" as month from dept limit 1 ;
现在速度快了很多!
0.7版本后Hive开始支持任务执行选择本地模式(local mode)。大多数的Hadoop job是需要hadoop提供的完整的可扩展性来处理大数据的。不过,有时hive的输入数据量是非常小的。在这种情况下,为查询出发执行任务的时间消耗可能会比实际job的执行时间要多的多。对于大多数这种情况,hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间会明显被缩短。
如此一来,对数据量比较小的操作,就可以在本地执行,这样要比提交任务到集群执行效率要快很多。
3.1 去hdfs上查看目录发现已经有了两个年的目录:
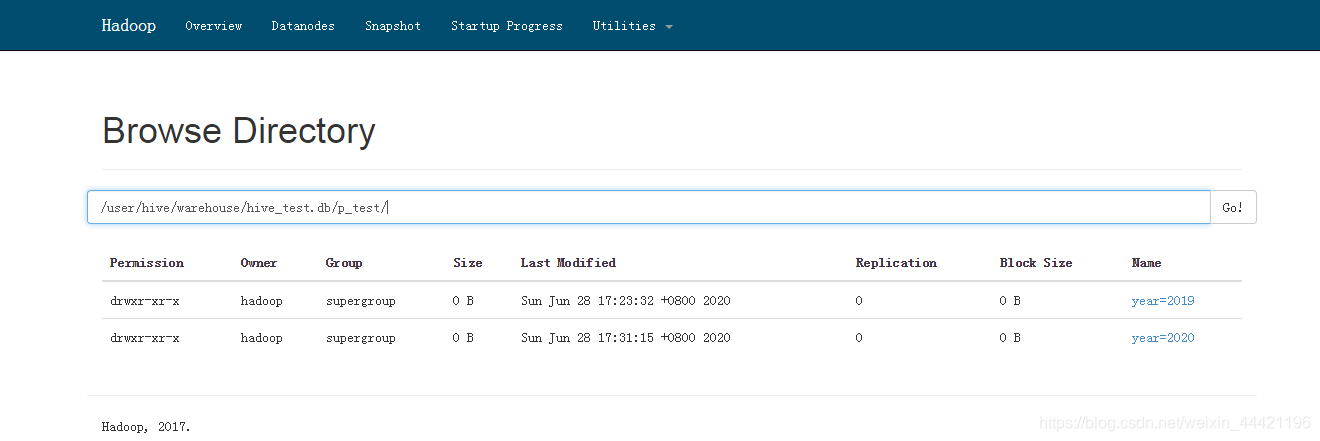
去hive中对 p_test 使用语句查看:
show partitions p_test;
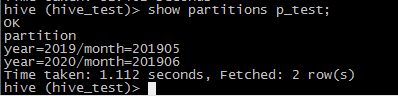
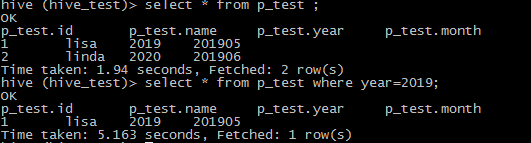
测试完成!
- 同时,我们在hive中同样可以使用sparksql的方式去实现hive语句;
也需要知道在spark中如何操作分区表,不多说直接上代码:
使用spark直接创建分区表(表存在则追加,无则创建):
package BigData
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Partiton {
def main(args: Array[String]): Unit = {
/**
* 创建hive的分区表,使用直接创建的方式
*/
val spark = SparkSession
.builder()
.appName("SparkHive")
.master("local")
.config("spark.sql.parquet.writeLegacyFormat", true)
.enableHiveSupport()
.getOrCreate()
val data = Array(("001", "张三", "2018", "201801"), ("002", "李四", "2017", "201701"), ("003", "网二", "2016", "201601")).toSeq
val df = spark.createDataFrame(data)
.toDF("id", "name", "year", "month")
//创建临时表
df.createOrReplaceTempView("temp_table")
spark.sql("use hive_test")
// 创建分区表,可以将append改为overwrite,这样如果表已存在会删掉之前的表,新建表
df.write.mode(SaveMode.Append).partitionBy("year","month").saveAsTable("p_test_spark")
}
}
注意:
如果用命令行创建的hive表,会根据hive的hive.default.fileformat,这个配置来规定hive文件的格式,其中fileformat一般有4中,分别是TextFile、SequenceFile、RCFile、ORC。默认情况下,不指定的话,是TextFile。建表语句最后加上stored as TextFile 或者stored as RCFile就可以指定格式了。
但是sparksql 的df 默认的format是parquet + snappy 所以不符合格式,所以就会报错;
解决spark和hive建表格式的问题
1)
加入将format设置为Hive以后,无论hive建表的时候,使用的fileformat使用的是哪一种,都是不会报错。
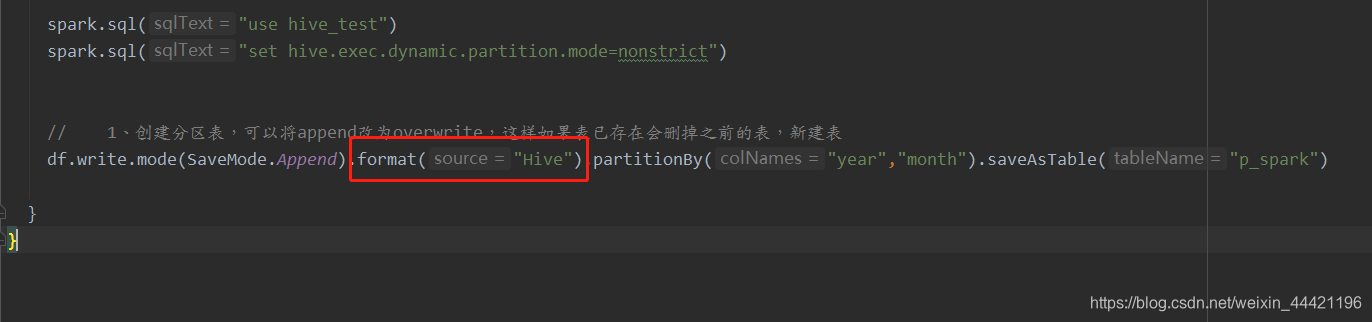
去检查该表的数据类型仍然是 text:
show create table p_spark;
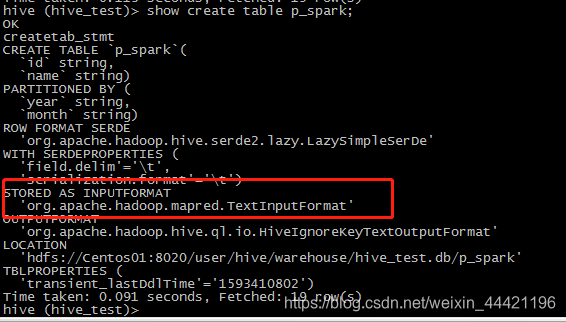
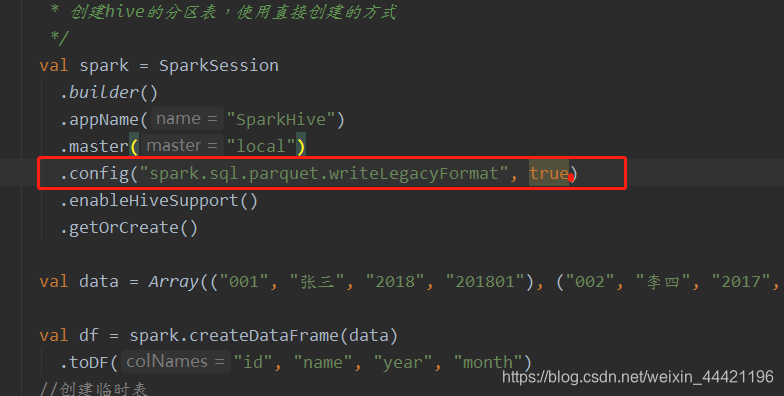
因此 config中的设置可以作为创建hive表的指定的数据格式:














 2462
2462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









