







串的存储结构
顺序存储结构
-
顺序串的定义
#def MAXLEN 255 typedef struct { char ch[MAXLEN+1]; int length; //表示串的长度 }SString;注意:串的存储内容必须是字符型
链式存储结构
传统链式存储结构存在存储密度低的缺点,为了克服这种缺点,在串的存储中,使用一个结点存储多个字符的方式来提高存储密度。形成的存储结构叫块链结构。
-
块链存储结构的定义
typedef Chunk{ char ch[Chunk]; struct Chunk *next; } typedef strct{ Chunk *head,*tail; //串的头指针和尾指针 int curlen; //串的当前长度 }Lstring; //字符串的块链结构
实际使用过程当中,由于对于串的操作多为查找、匹配等操作,删除和增加的操作不多。因此, 在存储结构上顺序存储结构使用更多。以下,所有介绍基于串的顺序存储结构。
串的模式匹配算法
- 算法目的:确定主串中所含子串(模式串)第一次出现的位置(定位)
- 算法应用:搜索引擎、拼写检查、语言翻译、数据压缩
- 算法种类:
- BF算法,暴力匹配
- KMP算法(特点:速度快)
BF算法
int Index_BF(SString S,SString T)
{
int i=1,j=1;
while(i<=S.length&&j<=T.length)
{
if(S.ch[i]==T.ch[j])
{
++i;
++j;
}
else i=i-j+2;j=1;
}
if(j>=T.length) return i-T.length; //匹配成功返回串的位置
else return 0; //匹配不成功0
}
KMP算法
算法思想:利用已经部分匹配的结果而加快模式串的滑动速度。主串S的指针i不必回溯。
BF算法的时间效率为O(m*n),而KMP算法可以提高到O(m+n)。
int Index_KMP(SString S,SString T)
{
int i=1,j=1;
while(i<=S.length&&j<=T.length)
{
if(S.ch[i]==T.ch[j])
{
++i;
++j;
}
j=next[j]; //i不变j后退
}
if(j>=T.length) return i-T.length; //匹配成功返回串的位置
else return 0; //匹配不成功0
}
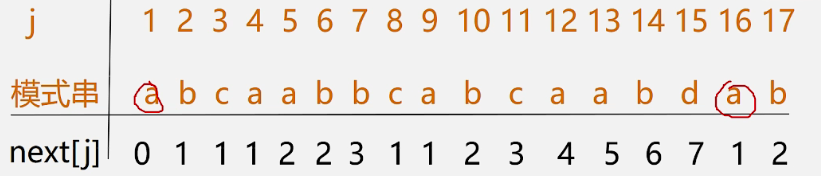
//------------计算Next[j]的方法--------------------//
void get_next(SString T,int &next[])
{
i=1;next[1]=0;j=0;
while(i<T.length)
{
if (j==||T.chi[i]==T.ch[j])
{
++i;++j;
next[i]=j;
}
else
j=next[j];
}
}
//------------计算NextVal[j]的方法--------------------//
void get_nextval(SString T,int &nextval[])
{
i=1;nextval[1]=0;j=0;
while(i<T.length)
{
if (j==||T.chi[i]==T.ch[j])
{
++i;++j;
if(T.ch[i]!=T.ch[j])
nextval[i]=j;
else nextval[i]=nextval[ij];
}
else
j=nextval[j];
}
}


















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









