








什么是SPA
(single-page application),是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换打断用户体验,在单页应用中,所有必要的代码(HTML、JavaScript和CSS)都通过单个页面的加载而检索。
一个杯子,早上装的牛奶,中午装的白开水,晚上装的是茶,杯子始终没有改变,而是装的东西在变

二、SPA和MPA的区别
多页应用在MPA中,每个页面都是一个主页面,都是独立的,当我们在访问另一个页面的时候,都需要重新加载html、css、js文件,公共文件则根据需求按需加载如下图
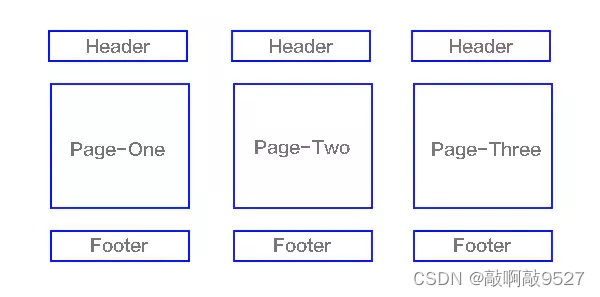
单页应用与多页应用的区别
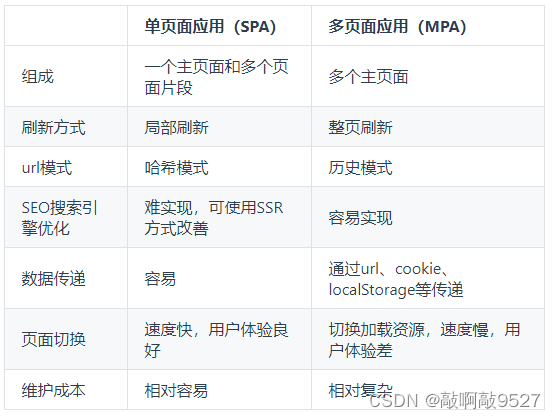
单页应用优缺点
优点:
- 具有桌面应用的
即时性、网站的可移植性和可访问性 - 用户体验好、快,内容的改变不需要重新加载整个页面
- 良好的前后端分离,
分工更明确
缺点:
-不利于搜索引擎的抓取
- 首次渲染速度相对较慢
实现一个SPA
原理
- 监听地址栏中 hash变化驱动界面变化
- 用 pushsate 记录浏览器的历史,驱动界面发送变化

实现
hash 模式
核心通过监听url中的hash来进行路由跳转
// 定义Router
class Router{
constructor(){
this.routes = {};//存放路由path及callback
this.currentUrl = '';
//监听路由change调用相对应的路由回调
window.addEventListener('hashchange',this.refresh,false);
window.addEventListener('load',this.refresh,false);
}
route(path,callback){
this.routes[path] = callback;
}
push(path){
this.routes[path] && this.routes[path]()
}
}
//使用 router
window.miniRouter = new Router();
miniRouter.route('/',()=>console.log('page1))
miniRouter.route('/page2',()=>console.log('page2'))
miniRouter.push('/')
miniRouter.push('/page2')
history模式
history 模式核心借用 HTML5 history api,api 提供了丰富的 router 相关属性先了解一个几个相关的api
- history.pushState 浏览器历史纪录添加记录
- history.replaceState修改浏览器历史纪录中当前纪录
- history.popState 当 history 发生变化时触发
class Router{
constructor(){
this.routes = {};
}
init(path){
history.replaceState({path:path},null,path);
this.routes[path]&&this.routes[path]();
}
route(path,callback){
this.routes[path] = callback;
}
push(path){
history.pushState({path:path},null,path);
this.routes[path] && this.routes[path]();
}
listerPopState(){
window.addEventListener('popstate',e=>{
const path = e.state && e.state.path;
this.routers[path] && this.routers[path]()
})
}
}
// 使用
window.miniRouter = new Router();
miniRouter.route('/',()=>console.log('page1'))
miniRouter.route('/page2',()=>console.log('page2'))
//跳转
miniRouter.push('/page2')// page2
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
















 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









