







继上一篇的博客scrapy准备工作完成后,今天正式开始scrapy的爬虫项目
ps:先看上一篇博客
scrapy项目----------爬取hao123影视
一、分析各文件含义
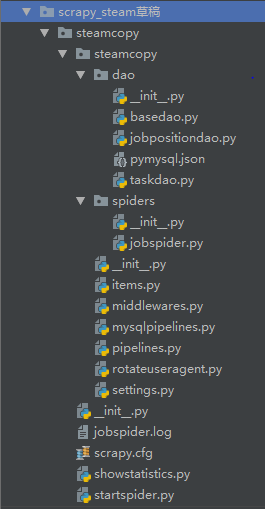
---->所有的__init__.py文件
无实意,内部没有内容,主要用于同一目录下的文件间的互相调用,下面的‘代码实现’中会提到!
---->dao包是手动添加的,里面的文件主要用于与数据库连接
–>basedao.py文件,连接数据库的万金油文件,可直接使用,与pymysql.json文件联用。
–>jobpositiondao.py文件,主要用于创建主要表和详情表(扩展,添加其他方法,sql语句(select),在showstatistics.py文件中可实现,而不存入数据库中),用basedao.py里的方法。
–>pymysql.json文件,连接数据库的具体信息,端口,密码,用户名,ip之类的,只需要改改内容即可。
–>taskdao.py文件,主要用于创建任务表,用basedao.py里的方法。
---->spiders包是自动生成的
–>jobspider.py文件是主程序文件,信息爬取的代码写在此文件里
---->底层steamcopy包
–>items.py文件,是保存爬取到的数据的容器,使用方法与字典类似,将定义字典items,将各key值(要爬取的数据名)通过scrapy.Field()定义。
–>middlewares.py文件,自动生成的,不需要改,在settings.py文件中打开,后面设置代理头的时候还需要将原端口关闭,设置新的。(settings.py文件中详解)
–>mysqlpipelines.py文件,通道,用于将爬取的数据存入数据库,大体结构复制的pipelines.py文件,在settings.py文件中打开pipelines的开关,添加此文件。(settings.py文件中详解)
–>pipelines.py文件,通道,将数据通过控制台输出,可直接看,在settings.py文件中打开。
–>rotateuseragent.py文件,创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求,防止被封ip,手动添加(可直接使用)
–>settings.py文件,项目的设置文件,内部含已定义的,打开,该添加的添加。(第一步就应该先配置此文件)
---->外层steamcopy包
–>jobspider.log文件,日志文件,将日志信息打印在此,需要在settings.py文件中设置
–>scrapy.cfg文件,项目的配置文件,主要用于连接settings.py文件和主程序文件,是自动生成的,不需要修改。
–>showstatistics.py文件,手动添加的,实现某sql语句,sql语句是在jobpositiondao.py文件中定义的某方法,直接调用可输出。(不进入数据库,可以不写)
–>startspider.py文件,是爬虫启动脚本,设置完后就不用在cmd输入scrapy crawl jobspider来启动了。
二、各文件代码实现
---->basedao.py
import pymysql
import json
import os
class basedao(): #dao:database access object的缩写,主要用于数据库方面的代码应用
def __init__(self, configFile='pymysql.json'):
self.__connection = None
self.__cursor = None
self.__config = json.load(open(os.path.dirname(__file__) + os.sep + configFile, 'r')) # 通过json配置获得数据的连接配置信息(地址用相对的)
print(self.__config)
pass
# 专门用来获取数据库连接的函数方法
def getConnection(self):
if self.__connection: #如果有连接对象
return self.__connection #直接返回连接对象,
try:
self.__connection = pymysql.connect(**self.__config)#不然,创建新的连接对象
return self.__connection
except pymysql.MySQLError as e:
print("Exception:"+str(e))
pass
pass
#用于执行sql语句的通用方法(增删改查) #sql注入的问题
def execute(self,sql,params):
try:
self.__cursor = self.getConnection().cursor()
result = self.__cursor.execute(sql,params)
return result
#print(result) 查的话,需要输出,其他的result是int整数(是修改成功的条数)
except (pymysql.MySQLError,pymysql.DatabaseError,Exception)as e:
print("出现数据库访问异常" + str(e))
self.rollback() #回滚
pass
pass
#一般在select的sql语句时用
def fetch(self):
if self.__cursor:
return self.__cursor.fetchall()
pass
#提交事务,每个sql语句都需要提交然后运行,紧接着close
def commit(self):
if self.__connection:
self.__connection.commit()
pass
#回滚,出错的话就返回之前的状态
def rollback(self):
if self.__connection:
self.__connection.rollback()
pass
#获取最后一行的id标识(用于主要表与详情表的1对1关系)
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
pass
#关闭(只要打开了就需要关闭,否则很快数据库就会报错)
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









