






1. Hadoop概述
| 1 | remoteDesktop | tcp://cpolard.26.tcp.cpolar.top:11013 | tcp | tcp://127.0.0.1:3389 | 2024年05月20日 00时03分16秒 |
| 2 | website | http | 2024年05月20日 00时03分15秒 | ||
| 3 | website | https | 2024年05月20日 00时03分15秒 |
1.1 Hadoop是什么
Hadoop 是一个开源的分布式系统基础框架,旨在处理大规模数据集的存储和处理。这个框架最初由 Apache 软件基金会开发,在大数据领域得到广泛应用。
Hadoop 提供了一个可靠、高效的方式来存储和处理大规模数据集,其主要组件包括:
(1)Hadoop Distributed File System (HDFS):HDFS 是 Hadoop 的分布式文件系统,用于存储数据。它将大文件切分成多个块,分散存储在集群中的多个节点上,提高了数据的容错性和读写效率。
(2)MapReduce:MapReduce 是 Hadoop 的并行编程模型,用于处理大规模数据集。使用 MapReduce,用户可以编写简单、可并行化的程序,将数据处理任务分解成 Map 阶段和 Reduce 阶段,实现数据的分布式计算。
(3)YARN (Yet Another Resource Negotiator):作为 Hadoop 2.x 版本中的资源管理器,YARN 负责集群资源的管理和作业调度,使得 Hadoop 可以运行更多类型的应用程序。
(4)Hadoop Common:包含一些支持 Hadoop 各个组件的共享库和工具。
(5)Apache Hive、Apache Pig、Apache Spark 等工具:这些工具建立在 Hadoop 生态系统之上,提供了高级的数据处理和查询功能,使用户能够更轻松地操作大规模数据。
Hadoop 的设计理念是通过 横向扩展(scale-out)来处理大数据,充分利用集群中的计算和存储资源。这使得 Hadoop 成为处理海量数据、实现高可靠性和容错性的重要工具。
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop主要解决,海量数据的存储和海量数据的分析计算问题。
1.2 Hadoop的发展
Hadoop 是一个开源的分布式计算平台,用于存储和处理大规模数据集。以下是 Hadoop 的发展历史的主要里程碑:
(1)起源(2004年-2005年):
- Hadoop 最初由Doug Cutting 和 Mike Cafarella 在雅虎创建,起源于 Google 的 BigTable论文、MapReduce 论文和 Google File System 论文的启发。
- 最初是为了支持 Nutch 项目的大规模网页索引任务而开发。
(2)Apache 转移(2006年):
- Hadoop 成为 Apache 软件基金会的顶级项目。
- 分为两个主要模块:Hadoop Distributed File System(HDFS)和 MapReduce。
(3)Hadoop 的扩展(2007年-2008年):
- 随着 Hadoop 的普及,社区开始增加各种其他项目和工具,如HBase、Hive、Pig 等,从而扩展了 Hadoop 生态系统的功能。
(4)商业化(2009年-2010年):
- 越来越多的公司开始采用 Hadoop 来解决大数据存储和处理问题,包括雅虎、Facebook、Twitter 等。
- 商业公司如 Cloudera、Hortonworks、MapR 等开始提供商业化的 Hadoop 发行版和支持服务。
(5)技术进步与发展(2011年至今):
- Hadoop 生态系统迅速扩展,涵盖了越来越多的项目和技术,如YARN、Spark、Flink 等,以满足不断增长的大数据需求。
- Hadoop 也在不断演进,通过增加更多功能和改进性能来适应越来越复杂的大数据应用场景。
(6)云计算与大数据发展(近年):
- 随着云计算的普及和大数据应用的增长,Hadoop 作为大数据处理的关键基础设施之一仍然发挥着重要作用。
- 大数据、人工智能和机器学习等领域的快速发展也在推动 Hadoop 和整个大数据生态系统进一步发展和创新。
Hadoop 在大数据领域扮演着重要角色,其发展历程反映了大数据处理技术的演进和社区的协作创新。随着技术的不断进步和需求的变化,Hadoop 和相关技术仍在不断发展和改进。
1.3 Hadoop发行版本
Hadoop发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。(2006)
Cloudera内部集成了很多大数据框架,对应产品CDH。(2008)
Hortonworks文档较详细,对应产品HDP。(2011)
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP。
(1)Apache Hadoop:
- 介绍: Apache Hadoop 是 Hadoop 项目的官方版本,由 Apache 软件基金会管理和维护。它提供了包括 HDFS、MapReduce、YARN 等核心组件,广泛用于大数据存储和处理。
- 特点: Apache Hadoop 以稳定性和可靠性为特点,在开源社区得到了广泛的支持和贡献。它通常是其他发行版本的基础,提供了强大的分布式计算和存储功能。
- 官网地址:http://hadoop.apache.org
- 下载地址:https://hadoop.apache.org/releases.html
(2)Cloudera:
- 介绍: Cloudera 提供了基于 Apache Hadoop 的企业级分布式数据管理平台。除了 Apache Hadoop 的核心组件外,Cloudera 还提供了管理工具、集成服务以及安全功能,使企业可以更轻松地构建和管理大数据基础设施。
- 特点: Cloudera 提供了自己的管理和监控工具,以简化大数据集群的部署和运维。它还提供了专业的支持服务,使企业能够更安全地使用大数据技术。
- 官网地址:https://www.cloudera.com/downloads/cdh
- 下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
(3)Hortonworks:
- 介绍: Hortonworks 也是一个基于 Apache Hadoop 的大数据平台提供商,专注于开源的大数据解决方案。它提供了包括 Hadoop、Spark、Hive、HBase 等在内的一整套数据管理和分析工具。
- 特点: Hortonworks 与 Apache Hadoop 社区密切合作,致力于推动开源大数据技术的发展。它的平台通常包含了最新的 Apache Hadoop 版本和补丁,以确保用户可以获得最新的功能和性能改进。
- 官网地址:https://hortonworks.com/products/data-center/hdp/
- 下载地址:https://hortonworks.com/downloads/#data-platform
这三大发行版本在大数据领域都有自己的特点和优势,企业可以根据自身需求和使用场景选择合适的版本来构建和管理大数据基础设施。
1.4 Hadoop优势
Hadoop 在大数据领域拥有多方面的优势,使其成为一种被广泛采用的分布式计算框架。以下是 Hadoop 在大数据领域的一些优势:
(1)高可扩展性:Hadoop 可以轻松地扩展到数千台服务器,处理大规模数据集。它能够有效地管理庞大的数据量,支持水平扩展,使得企业可以根据需求扩展其计算和存储能力。
(2)高容错性(高可靠性):Hadoop 具有高度的容错性,能够在服务器故障时保持数据的可靠性和可用性。通过数据的复制和分布式存储,Hadoop 能够应对硬件故障,并确保数据持久性和系统的稳定性。
(3)成本效益:Hadoop 基于廉价的通用硬件构建,可以在成本相对较低的情况下处理大数据。与传统的存储和计算解决方案相比,Hadoop 提供了更具成本效益的选择。
(4)并行处理(高效性):Hadoop 使用 MapReduce 编程模型,能够将大规模数据集分成小块,并在多台服务器上并行处理这些数据。这种并行处理方式能够显著提高处理速度和性能。
(5)灵活性:Hadoop 可以处理各种类型和格式的数据,包括结构化数据、半结构化数据和非结构化数据。这使得 Hadoop 更具灵活性,能够适应不同类型的数据处理需求。
(6)完善的生态系统:Hadoop 生态系统包括许多附加工具和库,如Hive、Pig、Spark 等,提供了更丰富的功能和选择。用户可以根据自己的需求选择适合的工具,构建更复杂和多样化的数据处理解决方案。
这些优势使得 Hadoop 成为处理大规模数据的首选框架之一,为企业提供了强大的数据处理和分析能力,帮助他们从海量数据中获取有价值的信息和见解。
1.5 Hadoop各个版本的区别
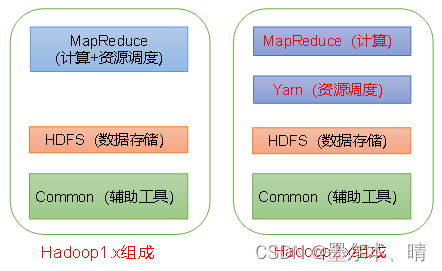
在Hadoop1.x 时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x 时代,增加了Yarn 模块,Yarn 只负责资源的调度,MapReduce 负责计算任务。
在Hadoop3.x 时代,组成上没有变化,相对于 Hadoop 2.x 引入了一些重要的新功能和改进,其中一些包括:
(1)Hadoop 3.x 的改进:
- 存储效率提升:Hadoop 3.x 引入了存储效率方面的改进,包括编码方案(EC)的改进以及数据节点存储管理的优化(块存储的管理和分配的优化:优化了数据块的分配和调度策略,以更好地利用存储资源;数据复制策略的优化:通过改进数据的复制策略,减少不必要的数据复制过程,提高数据的可靠性和可用性的同时也提高了存储效率),提高了存储效率。
- 存储策略:引入了新的存储策略,例如存储节点磁盘上数据块的复制策略的改进。
- 数据节点管理:针对数据节点管理引入了一些改进,包括改进的数据块管理策略和元数据处理。
- 容错性和稳定性:对系统容错性和稳定性进行了改进,提高了系统的可靠性。
(2)新增功能:
- Erasure Coding:引入了纠删码(Erasure Coding)功能,用于降低数据在 HDFS 上的存储成本。
- YARN资源管理器改进:包括资源管理器的性能提升、更好的资源隔离和容错机制等改进。
- 调度器改进:引入了新的调度器,如 Capacity Scheduler 改进。
- 集成新的文件系统:Hadoop 3.x 支持新的文件系统,如 Ozone 分布式对象存储,提供了更多的选择。
- HDFS改进:引入了一些HDFS的改进,如增强的缓存策略、性能优化等。
这些改进和新增功能使Hadoop 3.x在性能、存储效率、容错性和灵活性方面有了显著提升,帮助用户更好地处理和管理大数据。具体的改进和新功能还取决于您所使用的Hadoop 3.x 版本,建议查看官方文档以获取更详细的信息。
1.5.1 HDFS 架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1)NameNode:存储文件的元数据信息,如文件名、目录结构、文件属性(生成时间、副本数、文件权限等)、每个文件的块列表和块所在的DataNode等。
(2)DataNode:在本地文件系统中存储文件块数据,以及块数据的校验和。
(3)SecondaryNameNode:每隔一段时间对NameNode元数据备份(在高可用模式中不需要)。
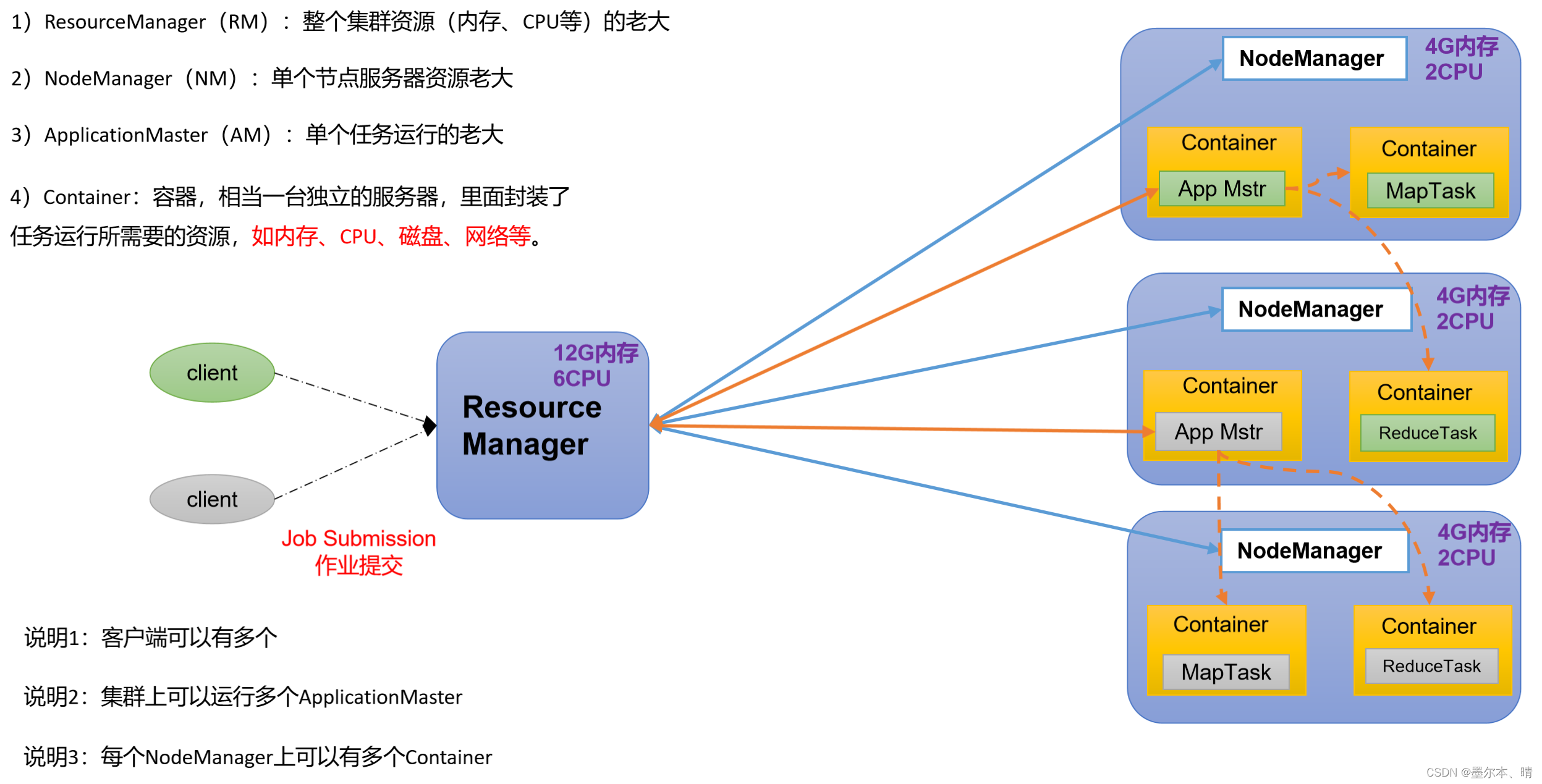
1.5.2 YARN 架构概述
Yet Another Resource Negotiator 简称YARN,另一种资源协调者,是Hadoop的资源管理器。
1.5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map 和 Reduce
(1)Map阶段并行处理输入数据;
(2)Reduce阶段对Map阶段的结果进行汇总。
1.5.4 HDFS,YARN,MR三者之间的关系
HDFS、YARN 和 MapReduce 是 Apache Hadoop 生态系统中的核心组件,它们之间有着密切的关系,各自承担着不同的角色,共同构成了 Hadoop 的分布式计算框架,三者之间的关系:
- HDFS 提供了数据存储功能,MapReduce 通过读取 HDFS 中的数据进行分布式处理。
- YARN 负责管理计算资源,并能够同时支持多种计算框架,其中包括 MapReduce。
- MapReduce 是 Hadoop 的核心计算框架之一,依赖于 HDFS 存储数据和 YARN 管理计算资源。
综合来看,HDFS 提供数据存储,YARN 管理集群资源,而 MapReduce 则是一种数据处理模型,三者共同协作构建了 Hadoop 的大数据处理基础设施。
1.6 大数据技术生态体系
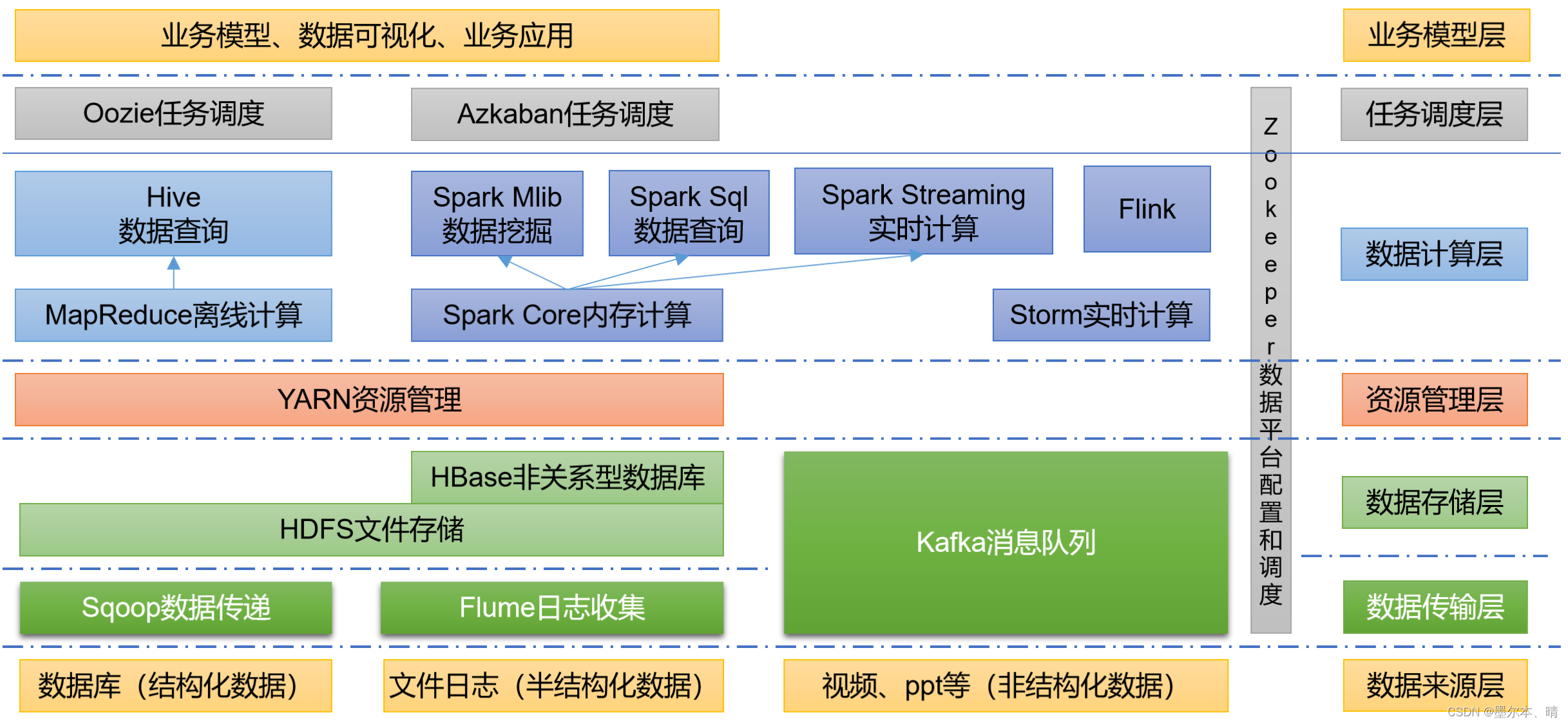
(1)Sqoop:Sqoop是一款开源的传输数据的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
(2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的组件,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
(3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
(4)Spark:Spark是一个流行的开源大数据内存计算框架,可以基于Hadoop上存储的大数据进行计算。
(5)Flink:Flink也是一个流行的开源大数据内存计算框架,主要用于实时计算的场景较多。
(6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
(7)Hbase:HBase是一个分布式的、面向列的开源数据库,HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,非常适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
2. Hadoop运行环境搭建
2.1 模版虚拟机环境准备
(1)安装模版虚拟机
系统版本:CentOS-7-x86_64-Everything-2009.iso
虚拟机网络适配器:桥接模式
分区设置:
[root@cenos01 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 960G 1.5G 958G 1% /
/dev/sda1 497M 131M 367M 27% /boot
(2)虚拟机配置
1)修改网络配置文件
[root@cenos01 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.194 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::eec:27f5:9b3f:880b prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:95:d1:87 txqueuelen 1000 (Ethernet)
RX packets 277 bytes 26862 (26.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 210 bytes 36338 (35.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@cenos01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
| TYPE="Ethernet" #网络类型(通常是Ethemet) PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" #IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|DHCP协议) DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="e83804c1-3257-4584-81bb-660665ac22f6" #随机id DEVICE="ens33" #接口名(设备,网卡) ONBOOT="yes" #系统启动的时候网络接口是否有效(yes/no) #IP地址 IPADDR=192.168.10.111 PREFIX=24 #网关 GATEWAY=192.168.10.1 #域名解析器 DNS1=8.8.8.8 |
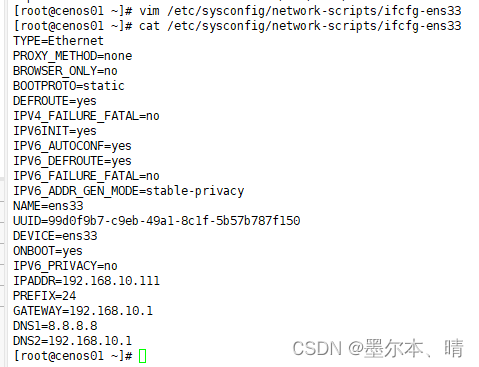
2)修改完之后,重启网络服务
- systemctl restart network 或者 service network restart 或者 systemctl restart NetworkManager
[root@cenos01 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.111 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::eec:27f5:9b3f:880b prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:95:d1:87 txqueuelen 1000 (Ethernet)
RX packets 967 bytes 85128 (83.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 651 bytes 95998 (93.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
3) 安装epel-release包:yum install -y epel-release
注:Extra Packages for Enterprise Linux 是为“红帽系” 的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于一个软件仓库,大多数rpm包在官方repository中找不到。
如果Linux安装的是最小系统,可以安装如下工具:
> net-tool:网络工具包集合,包含ifconfig 等命令:yum install -y net-tools
> vim编辑器:yum install -y vim
4)关闭防火墙:
[root@]# systemctl stop firewalld
[root@]# systemctl disable firewalld.service
5)修改主机名和 /etc/hosts 文件:
vim /etc/hostname 或者 hostnamectl set-hostname hadoop111
vim /etc/hosts -- 添加如下内容
192.168.10.110 hadoop110
192.168.10.111 hadoop111
192.168.10.112 hadoop112
192.168.10.113 hadoop113
192.168.10.114 hadoop114
192.168.10.115 hadoop115
192.168.10.116 hadoop116
192.168.10.117 hadoop117
192.168.10.118 hadoop118
6)创建seven用户,用普通用户安装hadoop
[root@hadoop100 ~]# useradd seven
[root@hadoop100 ~]# passwd seven
7)配置seven用户具有root的sudo权限,方便直接用sudo执行root权限的命令
[root@hadoop111 ~]# vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
seven ALL=(ALL) NOPASSWD:ALL
注意:seven 这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了seven具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以seven用户要放到%wheel这行下面。
8)在 /opt 目录下创建文件夹,并修改所属主和所属组
[root@hadoop111 ~]# mkdir -p /opt/module /opt/software
[root@hadoop111 ~]# ll /opt/
total 0
drwxr-xr-x. 2 root root 6 May 4 19:22 module
drwxr-xr-x. 2 root root 6 Oct 31 2018 rh
drwxr-xr-x. 2 root root 6 May 4 19:22 software
[root@hadoop111 ~]# chown -R seven:seven /opt/module/ /opt/software/
[root@hadoop111 ~]# ll /opt/
total 0
drwxr-xr-x. 2 seven seven 6 May 4 19:22 module
drwxr-xr-x. 2 root root 6 Oct 31 2018 rh
drwxr-xr-x. 2 seven seven 6 May 4 19:22 software
[root@hadoop111 ~]# 9)卸载虚拟机自带的JDK
[root@hadoop111 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
- rpm -qa:查询所安装的所有rpm软件包
- grep -i:忽略大小写
- xargs -n1:表示每次只传递一个参数
- rpm -e –nodeps:强制卸载软件
10)关闭虚拟机
2.2 克隆虚拟机
(1)利用模板虚拟机克隆出三台虚拟机:hadoop111,hadoop112,hadoop113
(2)修改克隆机的IP地址和主机名
(3)在Windows主机的hosts 文件中也添加相同的映射:C:\Windows\System32\drivers\etc\hosts
192.168.10.110 hadoop110
192.168.10.111 hadoop111
192.168.10.112 hadoop112
192.168.10.113 hadoop113
192.168.10.114 hadoop114
192.168.10.115 hadoop115
192.168.10.116 hadoop116
192.168.10.117 hadoop117
192.168.10.118 hadoop118
2.3 安装JDK和hadoop
(1)使用xftp将JDK和hadoop的安装包上传到虚拟机的 /opt/software 目录中
(2)解压安装包到 /opt/module
[seven@hadoop111 software]$ tar zxvf jdk-8u371-linux-x64.tar.gz -C /opt/module/
[seven@hadoop111 software]$ tar zxvf hadoop-3.3.6.tar.gz -C /opt/module/
(3)添加环境变量
[root@cenos01 profile.d]# vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_371
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3. 搭建Hadoop-HA集群
整个Hadoop-HA集群规划
| hadoop111 | hadoop112 | hadoop113 |
| NameNode | NameNode | |
| JorunalNode | JorunalNode | JorunalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
| ResourceManaer | ResourceManaer | |
| NodeManager | NodeManager | NodeManager |
3.1 HA 概述
(1)HA(High Availability),即高可用(7 * 24 小时不中断服务)
(2)实现高可用的关键策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
(3)NameNode主要在以下两个方面影响HDFS集群
>NameNode 服务器发生意外,如宕机,集群将无法使用,直到管理员重启服务;
>NameNode 服务器需要升级,包括软件、硬件升级,此时集群将无法使用
HDFS HA 功能通过配置多个NameNode(Active/Standby)实现在集群中对NameNode的热备来解决上述问题。
3.2 HDFS-HA 集群搭建
HDFS-HA的主要目的是消除NameNode的单点故障,需要将HDFS集群规划成以下规模:
| hadoop111 | hadoop112 | hadoop113 |
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
3.2.1 HDFS-HA 核心问题
(1)怎么保证NameNode的数据一致?
> Fsimage: 让一台NameNode生成数据,其他Standby状态的NN同步数据
> Edits: 需要引进新的模块 JournalNode来保证Edits的文件的数据一致性
(2)怎么实现同一时刻只有一台NameNode是Active,其他所有NN是Standby状态?
a. 手动分配:hdfs haadmin -transitionToActive nn1
b. 自动分配:启动时谁先在ZK中注册,谁就是Active
(3)SecondaryNameNode在HA架构中并不存在,定期合并fsimage和edits谁来做?
由Standby状态的NameNode进行
(4)如果Active状态的NameNode挂了,怎么让其他的NameNode上位?
a.手动故障转移
b.自动故障转移
3.2.2 编写集群分发脚本 xsync
(1)scp(secure copy)安全拷贝
scp可以实现服务器之间的数据拷贝,基本语法:scp -r $src_dir/$f_name $user@$hostname:$dst_dir/$f_name
-r 表示递归
案例:scp -r /opt/module/jdk1.8.0_371/ seven@hadoop112:/opt/module
(2)rsync 远程同步工具
rsync 主要用于备份和镜像,具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp的区别:用rsync 做文件复制比 scp 的速度快,rsync 只对差异文件做更新。scp是把所有文件都复制过去。
基本语法:
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
-a:归档拷贝
-v:显示复制过程
案例: rsync -av hadoop-3.3.6/ seven@hadoop103:/opt/module/hadoop-3.3.6/
(3)xsync 集群分发脚本
- 需求:循环复制文件到所有相同的节点的相同目录中
- 需求分析:rsync 实现差异化拷贝且速度快,希望在脚本在任何位置都能使用;
- 在 ~/ 目录中创建 bin目录: mkdir ~/bin
- 在 ~/bin 目录中创建 xsync 脚本
- 在 ~/bin 目录中新建 host_ips 文件,在该文件中输入以下内容:
hadoop111
hadoop112
hadoop113- xsync 脚本实现:
#!/bin/bash
#1. check param numbers
if [ $# -lt 1 ]
then
echo "Not Enough Arguement!"
echo "command example: xsync --host=hadoop112,hadoop113 /src_dir/f_name or xsync /src_dir/f_name"
exit;
fi
#2. Check if rsync command exists,if not,install it
if ! command -v rsync &> /dev/null; then
if command -v yum &> /dev/null; then
sudo yum install -y rsync
elif command -v apt-get &> /dev/null; then
sudo apt-get install -y rsync
else
echo "Cannot install rsync,please install it manually."
exit 1
fi
fi
#3. Check if --host argument is provided
if [[ "$1" == "--host="* ]]; then
#Parse hosts from argument
hosts=$(echo ${1#*=}| tr ',' '\n')
else
hosts=$(cat /home/seven/bin/host_ips)
fi
#4.Traverse through each host
for host in $hosts
do
echo ==================== $host ====================
#5.Check if file exists
# shellcheck disable=SC2068
for file in $@
do
#6.Ignore --host argument
if [[ "$file" == "--host="* ]]
then
continue
fi
if [ -e "$file" ]; then
# Get parent directory
pdir=$(cd -P $(dirname $file); pwd)
#Get file name
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done3.2.3 ssh免密登录脚本
- ssh-copy-id 复制公钥
- expect 用于自动化交互式任务的工具,可以模拟用户输入和对命令行程序的期望响应。
- 在 ~/bin 目录中创建 setup-ssh-keys.sh 文件和 password 文件,在password文件中输入密码,在脚本中输入以下内容。
#!/bin/bash
# 检查主机名列表文件是否存在
if [ ! -f "/home/seven/bin/host_ips" ]; then
echo "主机名列表文件不存在或路径错误。"
exit 1
fi
# 从密码文件中读取密码
password=$(cat /home/seven/bin/password)
# 判断expect命令是否存在,如果不存在则安装
if ! command -v expect &> /dev/null; then
if command -v yum &> /dev/null; then
sudo yum install -y expect
elif command -v apt-get &> /dev/null; then
sudo apt-get install -y expect
else
echo "Cannot install rsync,please install it manually."
exit 1
fi
fi
# 逐行读取主机名,并设置免密登录
while IFS= read -r hostname
do
# 检查是否已经存在 SSH 密钥
if [ ! -f ~/.ssh/id_rsa.pub ]; then
ssh-keygen -t rsa -b 4096 -N "" -f ~/.ssh/id_rsa
fi
# 尝试将公钥拷贝到目标主机
# 将密码传递给 ssh-copy-id 命令(使用 expect 实现自动输入密码)
expect -c "
spawn ssh-copy-id -o "StrictHostKeyChecking=no" $hostname
expect \"password:\"
send \"$password\r\"
expect eof
"
# 检查是否成功
if [ $? -eq 0 ]; then
echo "已成功将公钥拷贝到 $hostname"
else
echo "将公钥拷贝到 $hostname 失败"
fi
done < "/home/seven/bin/host_ips"3.2.4 远程调用脚本 xcall
功能:在本机执行远程主机上相应的命令
#! /bin/bash
if [ $# -lt 1 ]
then
echo "Not Enough Arguement!"
echo "command example: xcall --host=hadoop112,hadoop113 ls or xcall ls"
exit;
fi
#Check if --host argument is provided
if [[ "$1" == "--host="* ]]; then
#Parse hosts from argument
hosts=$(echo "${1#*=}"| tr ',' '\n')
for i in $hosts
do
echo --------- "$i" ----------
ssh "$i" "${@:2}"
done
else
hosts=$(cat ~/bin/host_ips)
for i in $hosts
do
echo --------- "$i" ----------
ssh "$i" "$@"
done
fi3.2.5 HDFS-HA 手动模式配置
Hadoop 配置文件说明:
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 默认配置文件 | 文件所在位置 |
| [core-default.xml] | {HADOOP_HOME}/share/hadoop/common/hadoop-common-xxx.jar/core-default.xml |
| [hdfs-default.xml] | {HADOOP_HOME}/share/hadoop/hdfs/hadoop-hdfs-xxx.jar/hdfs-default.xml |
| [yarn-default.xml] | {HADOOP_HOME}/share/hadoop/yarn/hadoop-yarn-common-xxx.jar/yarn-default.xml |
| [mapred-default.xml] | {HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-client-core-xxx.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
(3)配置集群
- core-site.xml
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生临时文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.6/tmp</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为seven -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>seven</value>
</property>
</configuration>- hdfs-site.xml
<configuration>
<!-- NameNode 数据存储目录,默认: file://${hadoop.tmp.dir}/dfs/name -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/module/hadoop-3.3.6/data/nn</value>
</property>
<!-- DataNode 数据存储目录,默认: file://${hadoop.tmp.dir}/dfs/data -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/module/hadoop-3.3.6/data/dn</value>
</property>
<!-- JournalNode 数据存储目录,默认:/tmp/hadoop/dfs/journalnode/ -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-3.3.6/data/jn</value>
</property>
<!-- 分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop111:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop112:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop111:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop112:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop111:8485;hadoop112:8485/mycluster</value>
</property>
<!-- 访问代理类:client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/seven/.ssh/id_rsa</value>
</property>
</configuration>
注: HA 中常见的现象:SB,Split Brain,闹裂现象,一个高可用集群中出现两个Master,为了防止这种现象的发生,需要配置下面的参数
| <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --><property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> |
在 /opt/module/hadoop-3.3.6/etc/hadoop/workers 中添加每个DataNode的主机名:
hadoop111
hadoop112
hadoop113
这样可以用 start-dfs.sh 脚本启动集群,否则就需要一个节点一个节点的启动DataNode。
--> 启动HDFS-HA集群
(1)分发配置文件:xsync /opt/module/hadoop-3.3.6/
(2)在各个节点上启动JournalNode服务:xcall "hdfs --daemon start journalnode"
(3)在[nn1] 上,对NameNode进行格式化,并启动
[seven@hadoop111 ~]$ hdfs namenode -format
[seven@hadoop111 ~]$ hdfs --daemon start namenode(4)在[nn2] 上同步nn1 的元数据信息:hdfs namenode -bootstrapStandby
(5)启动nn2:hdfs --daemon start namenode
(6)查看web页面的显示情况:http://hadoop111:9870, http://hadoop112:9870
注: 此时启动的NameNode均为Standby状态
(7)启动所有节点上的DataNode:hdfs --daemon start datanode
(8)将[nn1] 切换为Active:hdfs haadmin -transitionToActive nn1
(9)查看nn1是否为Active状态:hdfs haadmin -getServiceState nn1
(10)测试:
-> 手动将nn1 的NameNode进程关闭:jps 查看NameNode进程号,kill 进程号,或者 hdfs --daemon stop namenode
-> 尝试将nn2作为Active的Namenode:hdfs hsadmin -transitionToActive nn2
-> 发现会报错,需要手动将nn1的NameNode进程恢复,再次尝试才能成功:
结论:手动配置的情况下,只有Cluster中所有的NameNode进程都正常的情况下,才能设置 active
原因:手动将某个NameNode转换为Active时,需要两个NameNode的状态保持一致。这包括在转换之前,Standby NameNode已经与Active NameNode同步了最新的命名空间和块映射信息。如果某个NameNode没有完全启动或者没有与其他节点进行状态同步,可能导致数据不一致和集群的不可用状态。所以,要求所有的NameNode都启动并保持与其他节点的状态同步,是为了确保在切换过程中数据的一致性和集群的可靠性。
在手动模式中设置了隔离机制,同一时间只能有一个namenode对外提供服务,如果需要将其中某个standby 的 nn 提升为active,必须保证它可以和其他所有standby的nn能保持通信;因为如果nn2 不能与nn1联通,此时不能说明nn1是真的挂了,假如此时nn1只是和nn2的通信挂了,而与其他datanode的通信都正常;且nn1在为其他datanode 提供 namenode的服务,此时如果强行将 nn2提升为active,那么这个集群中就可能出现两个 namenode,即SB(Split Brain)-脑裂的情况。所以这就解释了为什么在手动提升一个standby的nn为active的时候,必须保证配置中所有的nn都处于启动状态。
3.2.6 HDFS-HA 自动模式
由上面的介绍可以知手动配置的方式不能实现真正的HA,因为当NameNode故障之后,需要管理员手动恢复NameNode才能再次对外提供服务。
HDFS-HA自动故障转移工作机制,需要增加两个新的组件:Zookeeper 和 ZKFailoverController(ZKFC)进程。Zookeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。
(1)配置HDFS-HA自动故障转移
-> 配置Zookeeper:[seven@hadoop111 software]$ tar zxvf apache-zookeeper-3.9.0-bin.tar.gz -C /opt/module/
->mv apache-zookeeper-3.9.0-bin/ zookeeper-3.9.0
->cd /opt/module/zookeeper-3.9.0/conf
->cp zoo_sample.cfg zoo.cfg
-> [seven@hadoop111 zookeeper-3.9.0]$ mkdir zkData
->zkData]$ touch myid -- 并写入id为1
->[seven@hadoop111 conf]$ vim zoo.cfg -- 输入以下内容:
dataDir=/opt/module/zookeeper-3.9.0/zkData
#######################cluster##########################
server.1=hadoop111:2888:3888
server.2=hadoop112:2888:3888
server.3=hadoop113:2888:3888
->分发Zookeeper: xsync /opt/module/zookeeper-3.9.0/
-> 修改hadoop112,hadoop113 中的myid 分别为2 和 3
-> 编写zk控制脚本:vim /home/seven/bin/zk.sh
#!/bin/bash
hosts=$(cat ~/bin/host_ips)
case $1 in
"start") {
for host in $hosts; do
echo "-------- start zookeeper $host --------"
ssh "$host" "/opt/module/zookeeper-3.9.0/bin/zkServer.sh start"
done
} ;;
"stop") {
for host in $hosts; do
echo "-------- stop zookeeper $host --------"
ssh "$host" "/opt/module/zookeeper-3.9.0/bin/zkServer.sh stop"
done
} ;;
"status") {
for host in $hosts; do
echo "-------- stop zookeeper $host --------"
ssh "$host" "/opt/module/zookeeper-3.9.0/bin/zkServer.sh status"
done
} ;;
esac->启动zkserver:zk.sh start
->检查运行状态:zk.sh status
[seven@hadoop111 bin]$ ./zk.sh status
-------- stop zookeeper hadoop111 --------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.9.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
-------- stop zookeeper hadoop112 --------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.9.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
-------- stop zookeeper hadoop113 --------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.9.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[seven@hadoop111 bin]$ (2)在手动配置的基础上,在hdfs-site.xml 中添加以下信息
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>(3)在core-site.xml文件中添加Zookeeper的信息
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop111:2181,hadoop112:2181,hadoop113:2181</value>
</property>
(4)修改配置文件后分发到其他节点
(5)启动Zookeeper后再初始化HA在Zookeeper中的状态:hdfs zkfc -formatZK
(5)重启hdfs服务:stop-dfs.sh / star-dfs.sh
(6)在zookeeper 中去查看NameNode选举锁节点内容:zkCli.sh -- 进入zk客户端,
get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock
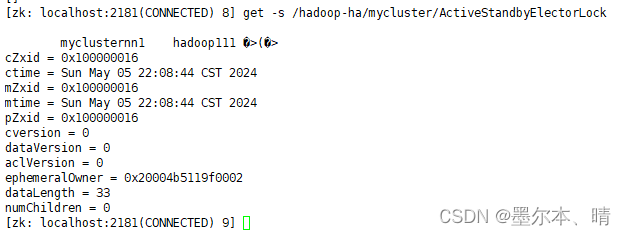
core-site.xml中管理hadoop-ha在znode的根目录
(7)验证:将active 的NameNode进程kill掉,查看是否有自动切换
3.3 YARN-HA配置
3.3.1 Yarn-HA工作机制
(1)官网文档:https://apache.github.io/hadoop/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
(2)YARN-HA工作机制
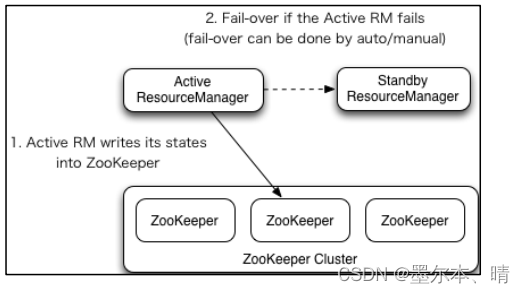
3.3.2 配置YARN-HA集群
(1)核心问题
->如果active RM 挂了,其他rm怎么将Standby RM变为Active/
- 核心原理跟hdfs一样,利用了zk的临时节点
-> 当前 RM 上有很多的计算程序在等待运行,其他的 RM 怎么将这些程序接手过来接着跑?
- RM 会将当前所有计算程序的状态存储在ZK中,其他RM变为Active之后会去读取状态信息,然后接着跑任务。
(2)具体配置
- yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop112</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop112:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop112:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop112:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop112:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop113</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop113:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop113:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop113:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop113:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop111:2181,hadoop112:2181,hadoop113:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>- 分发配置:xsync yarn-site.xml
(3)启动Yarn:start-yarn.sh
(4)查看服务状态:yarn rmadmin -getServiceState rm1
(5)去zkCli.sh 客户端查看ResourceManager选举锁节点内容:
zkCli.sh
get -s /yarn-leader-election/cluster-yarn1/ActiveStandbyElectorLock
(6)web端查看 hadoop112:8088 和 hadoop113:808 的yarn状态
(7)集群最终的状态:
[seven@hadoop111 logs]$ xcall jps
--------- hadoop111 ----------
17364 NodeManager
14087 JournalNode
17559 Jps
14280 DFSZKFailoverController
6555 QuorumPeerMain
13708 NameNode
13837 DataNode
--------- hadoop112 ----------
9040 NameNode
14515 ResourceManager
14949 Jps
9336 DFSZKFailoverController
14602 NodeManager
5803 QuorumPeerMain
9132 DataNode
9246 JournalNode
--------- hadoop113 ----------
8994 ResourceManager
7784 DataNode
6011 QuorumPeerMain
9083 NodeManager
9245 Jps
[seven@hadoop111 logs]$ 3.3.3 配置历史服务器
为了查看程序的历史运行情况,需要配置历史服务器。具体配置步骤如下:
(1)配置 mapred-site.xml,在该文件中添加如下匹配
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop111:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop111:19888</value>
</property>(2)分发配置:xsync mapred-site.xml
(3)启动历史服务器:mapred --daemon start historyserver
(4)查看历史服务器进程是否启动:jps
(5)Web查看历史服务器:http://hadoop111:19888/jobhistory
3.3.4 配置日志聚集
日志聚集概念:应用程序完成以后,将程序运行日志信息上传到HDFS系统上。
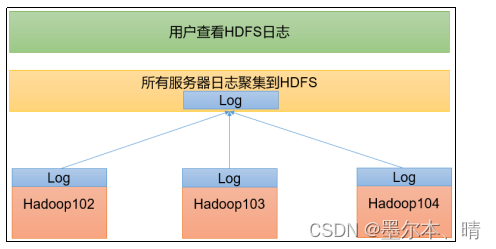
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重启NodeManager、ResourceManager和HistoryServer。
(1)配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop111:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>(2)分发配置:xsync yarn-site.xml
(3)重启NodeManager、ResourceManager和HistoryServer
3.3.5 Hadoop集群启停脚本
vim hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop111 "/opt/module/hadoop-3.3.6/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop112 "/opt/module/hadoop-3.3.6/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop111 "/opt/module/hadoop-3.3.6/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop111 "/opt/module/hadoop-3.3.6/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop112 "/opt/module/hadoop-3.3.6/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop111 "/opt/module/hadoop-3.3.6/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac4. QA
(1)在配置完HDFS-HA,需要先启动 JournalNode在格式化NameNode吗?
在配置 HDFS 的高可用性(HA)时,需要注意一些步骤的顺序,其中 JournalNode 扮演着关键的角色。在格式化 NameNode 之前,应确保 JournalNode 已经在运行。
下面是JournalNode 的一些说明:
- 启动 JournalNode:JournalNode 用于存储 NameNode 的编辑日志,以确保在主 NameNode 失效时,可以顺利地进行故障转移和恢复。因此,JournalNode 应该在格式化NameNode之前处于运行状态。
- 格式化 NameNode:在 JournalNode 正在运行并且处于可用状态后,接下来可以进行 NameNode 的格式化。格式化 NameNode 是配置 HDFS 高可用性的一部分,该步骤会初始化命名空间,并将 NameNode 的元数据写入 JournalNode。
- 配置 HDFS-HA 参数:一旦 NameNode 格式化完成,接下来配置 HDFS-HA 相关的参数,包括指定 JournalNode 的地址和配置故障转移(failover)功能。
- 启动 NameNode HA 环境:最后,启动具有 NameNode HA 配置的 HDFS 集群。此时,JournalNode 将持续记录 NameNode 的编辑日志,以确保主备 NameNode 之间的数据同步。

















 2857
2857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









