







python基础笔记
参考文献
《Python编程:从入门到实践》
https://www.runoob.com/python/python-tutorial.html
python标准文档
PEP 8指南
Python Module of the Week
python
基础语法
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
python保留字
关键字,不能把它们用作任何标识符名称。Python库提供了keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
Python中单行注释以 #开头
多行注释可以用多个 # 号,还有'''和 """:
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠\来实现多行语句,
total = var_one + var_two + var_three + var_four
total = var_one + \
var_two + \
var_three + \
var_four
在[], {}, ()中的多行语句不需要使用反斜杠\
total = ['var_one', 'var_two', 'var_three',
'var_four', 'var_five']
数字(Number)类型
python中数字有四种类型:整数、布尔型、浮点数和复数。
- int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
- bool (布尔), 如 True。
- float (浮点数), 如 1.23、3E-2
- complex (复数), 如 1 + 2j、 1.1 + 2.2j
字符串(String)
- python中单引号和双引号使用完全相同。
- 使用三引号(‘’'或"“”)可以指定一个多行字符串。
- 转义符
\ - 反斜杠可以用来转义,使用 r 可以让反斜杠不发生转义。 如
r"this is a line with \n"则\n会显示,并不是换行。 - 字符串可以用
+运算符连接在一起,用*运算符重复。 - Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:
变量[头下标:尾下标:步长]
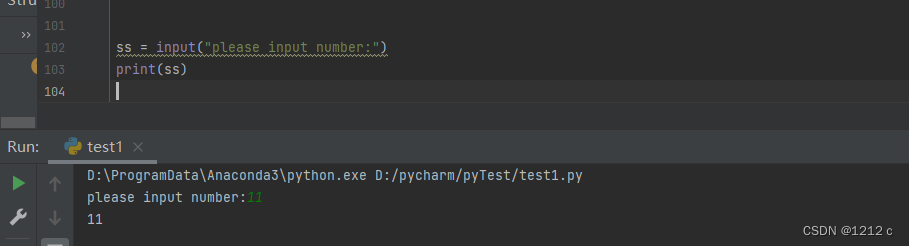
ss = 'hello world'
print(ss)
print(ss[0:-1]) # 输出第一个到倒数第二个的所有字符
print(ss[0]) # 输出第一个字符
print(ss[3:5]) # 输出第3到5个字符
print(ss[3:]) # 输出第三个字符开始的所有字符
print(ss * 2) # 输出字符串两次
print(ss + "ss") # 连接字符串
运行结果
hello world
hello worl
h
lo
lo world
hello worldhello world
hello worldss
等待用户输入
函数input()让程序暂停运行,等待用户输入一些文本。获取用户输入后,Python将其存储在一个变量中,方便使用。
函数input()接受一个参数:即要向用户显示的提示或说明,让用户知道该如何做
每当你使用函数input()时,都应指定清晰而易于明白的提示,准确地指出你希望用户提供什么样的信息——指出用户该输入任何信息的提示都行。
name = input("what is you name ? ")
print("hello " + name)

有时候,提示可能超过一行,例如,你可能需要指出获取特定输入的原因。在这种情况下,可将提示存储在一个变量中,再将该变量传递给函数input()。
创建多行字符串
prompt = "If you tell us who you are, we can personalize the messages you see."
prompt += "\nWhat is your first name? "
name = input(prompt)
print("\nHello, " + name + "!")
使用函数input()时,Python将用户输入解读为字符串
当输入需要和数字进行比较时,可使用函数int(),
>>> age = input("How old are you? ")
How old are you? 21
>>> age = int(age)
>>> age >= 18
True
Python 2.7 中获取输入应使用函数raw_input()来提示用户输入。这个函数与Python 3中的input()一样,也将输入解读为字符串。
Python 2.7也包含函数input(),但它将用户输入解读为Python代码,并尝试运行。
同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号( ; )分割
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
例
if expression :
suite
elif expression :
suite
else :
suite
print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=“”

import 与 from…import
在 python 用 import 或者 from...import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
基本数据类型
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。例如:
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为 1,从后向前赋值,三个变量被赋予相同的数值。
也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "runoob"
以上实例,两个整型对象 1 和 2 的分配给变量 a 和 b,字符串对象 “runoob” 分配给变量 c。
标准数据类型
python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
Number(数字)
Python3 支持int、float、bool、complex(复数)
内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
此外还可以用 isinstance 来判断:
>>>a = 111
>>> isinstance(a, int)
True
>>>
isinstance 和 type 的区别在于:
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。
>>> class A:
... pass
...
>>> class B(A):
... pass
...
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
在 Python2 中是没有布尔型的,Python2 用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字,但它们的值还是 1 和 0,可以和数字相加。
print(2 / 4) # 除法 得到浮点数 0.5
print(2 // 4) # 除法 得到整数 0
print(17 % 3) # 取余 2
print(2 ** 3) # 乘方 8
print(3 + True) # 4
注意:
1、Python可以同时为多个变量赋值,如a, b = 1, 2。
2、一个变量可以通过赋值指向不同类型的对象。
3、数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。
4、在混合计算时,Python会把整型转换成为浮点数。
使用函数 str()避免类型错误
需要在字符串中使用整数时,需要显式地指出你希望Python将这个整数用作字符串。
为此,可调用函数str(),它让Python将非字符串值表示为字符串
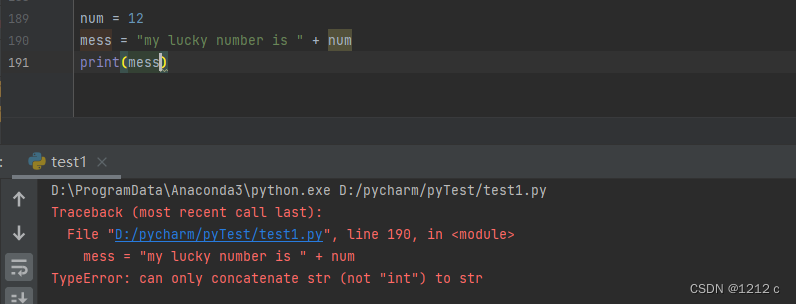
num = 12
mess = "my lucky number is " + str(num)
print(mess)
my lucky number is 12
Python 2 中的整数
在Python 2中,整数除法的结果只包含整数部分,小数部分被删除。
在Python 2中若要避免这种情况,务必确保至少有一个操作数为浮点数,这样结果也将为浮点数。
String(字符串)
python中的字符串用单引号'或双引号 " 括起来,同时使用反斜杠\转义特殊字符。
字符串的截取的语法格式如下:
变量 [头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。

>>>word = 'Python'
>>> print(word[0], word[5])
P n
>>> print(word[-1], word[-6])
n P
加号+是字符串的连接符, 星号*表示复制当前字符串,紧跟的数字为复制的次数。
ss = 'hello world'
print(ss)
print(ss[0:-1]) # 输出第一个到倒数第二个的所有字符
print(ss[0]) # 输出第一个字符
print(ss[3:5]) # 输出第3到5个字符
print(ss[3:]) # 输出第三个字符开始的所有字符
print(ss * 2) # 输出字符串两次
print(ss + "ss") # 连接字符串
运行结果
hello world
hello worl
h
lo
lo world
hello worldhello world
hello worldss
Python 使用反斜杠\转义特殊字符,如果不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
>>> print('Ru\noob')
Ru
oob
>>> print(r'Ru\noob')
Ru\noob
>>>
反斜杠\可以作为续行符,表示下一行是上一行的延续。也可以使用"""..."""或者'''...'''跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm’会导致错误
注意:
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
1. 使用方法修改字符串的大小写
方法title(),将每个单词的首字母都转化为大写。
方法是python可对数据执行的操作,在name.title()中,name后面的句点.让Python对变量name执行方法title()指定的操作。
每个方法后面都跟着一对括号,这是因为方法通常需要额外的信息来完成其工作。这种信息是在括号内提供的。函数title()不需要额外的信息,因此它后面的括号是空的。
name = "lucy lindy coco"
print(name.title())
输出
Lucy Lindy Coco
将字符串改为全部大写upper()或全部小写.lower()
name = "Lucy Lindy Coco"
print(name.upper())
print(name.lower())
LUCY LINDY COCO
lucy lindy coco
2 合并 / 拼接字符串
Python使用加号+来合并字符串。
这种合并字符串的方法称为拼接。通过拼接,可使用存储在变量中的信息来创建完整的消息。
first_name = "zhao"
last_name = "xiao ming"
full_name = first_name + " " + last_name
print(full_name)
zhao xiao ming
3 使用制表符或换行符来添加空白
空白泛指任何非打印字符,如空格、制表符和换行符。你可使用空白来组织输出,以使其更易读。
制表符:字符组合\t
换行符:字符组合\n
print("hello\nworld\n\tss")
hello
world
ss
4 删除空白
方法rstrip()能够找出字符串末尾多余的空白并删除。但这种删除只是暂时的,要永久删除这个字符串中的空白,必须将删除操作的结果存回到变量中。
方法lstrip()能够剔除字符串开头的空白
方法strip()能够同时剔除字符串两端的空白
5 使用字符串时避免语法错误
语法错误是一种时不时会遇到的错误。程序中包含非法的Python代码时,就会导致语法错误。
例如,在用单引号括起的字符串中,如果包含撇号,就将导致错误。这是因为这会导致Python将第一个单引号和撇号之间的内容视为一个字符串,进而将余下的文本视为Python代码,从而引发错误。
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表由一系列按特定顺序排列的元素组成。可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号[]之间、用逗号分隔开的元素列表。
鉴于列表通常包含多个元素,给列表指定一个表示复数的名称(如letters、digits或names)。
1 列表截取,访问列表元素
要访问列表的任何元素,只需将该元素的位置或索引告诉Python即可。
要访问列表元素,可指出列表的名称,再指出元素的索引,并将其放在方括号内
第一个列表元素的索引为0,而不是1。
list_error = ['aa', 'bb', 'cc']
print(list_error[0])
print(list_error[-1]) # 访问最后一个列表元素
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。

加号 + 是列表连接运算符,星号*是重复操作。
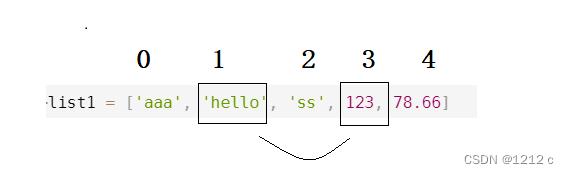
list1 = ['aaa', 'hello', 'ss', 123, 78.66]
list2 = ['bbb', 'ccc']
>>>print(list1)
['aaa', 'hello', 'ss', 123, 78.66]
>>>print(list1[0])
aaa
>>>print(list1[1:3])
['hello', 'ss']
>>>print(list1[2:])
['ss', 123, 78.66]
>>>print(list1 * 2)
['aaa', 'hello', 'ss', 123, 78.66, 'aaa', 'hello', 'ss', 123, 78.66]
>>>print(list1 + list2)
['aaa', 'hello', 'ss', 123, 78.66, 'bbb', 'ccc']
Python 列表截取可以接收第三个参数,参数作用是截取的步长,在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串:
>>>list1 = ['aaa', 'hello', 'ss', 123, 78.66]
>>>print(list1[1:4:2])
['hello', 123]
如果第三个参数为负数,表示逆向读取,以下实例用于翻转字符串:
def reverseWords(input):
# 通过空格将字符串分隔符,把各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1,2,3,4],
# list[0]=1, list[1]=2 ,而 -1 表示最后一个元素 list[-1]=4 ( 与 list[3]=4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长,-1 表示逆向
inputWords=inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like runoob'
rw = reverseWords(input)
print(rw)
输出结果为:
runoob like I
2 修改列表元素
与字符串不一样的是,列表中的元素可以改变
>>>list1 = ['aaa', 'hello', 'ss', 123, 78.66]
>>>list1[0] = 1
>>>print(list1)
[1, 'hello', 'ss', 123, 78.66]
3 在列表中添加元素
- 在列表末尾添加元素
append()
list_error = ['aa', 'bb', 'cc']
list_error.append("dd")
list_error.append("ee")
print(list_error)
['aa', 'bb', 'cc', 'dd', 'ee']
方法append()让动态地创建列表易如反掌。
可以先创建一个空列表,再使用一系列的append()语句添加元素。
这种创建列表的方式极其常见,因为经常要等程序运行后,你才知道用户要在程序中存储哪些数据。为控制用户,可首先创建一个空列表,用于存储用户将要输入的值,然后将用户提供的每个新值附加到列表中。
- 在列表中插入元素
insert()
使用方法insert()可在列表的任何位置添加新元素。需要指定新元素的索引和值。
list_test = ['aa', 'bb', 'cc']
list_test.insert(0, "ss")
print(list_test)
['ss', 'aa', 'bb', 'cc']
4 在列表中删除元素
- 使用
del语句删除元素
如果知道要删除的元素在列表中的位置,可使用del语句
list_test = ['ss', 'aa', 'bb', 'cc']
del list_test[2]
print(list_test)
['ss', 'aa', 'cc']
使用del可删除任何位置处的列表元素,条件是知道其索引
使用del语句将值从列表中删除后,就无法再访问它了
- 使用方法
pop()删除元素
有时候,你要将元素从列表中删除,并接着使用它的值。
方法pop()可删除列表末尾的元素,并让你能够接着使用它。
list_test = ['ss', 'aa', 'bb', 'cc']
pop_n = list_test.pop()
print(list_test)
print(pop_n)
['ss', 'aa', 'bb']
cc
- 弹出列表中任何位置处的元素
实际上,你可以使用pop()来删除列表中任何位置的元素,只需在括号中指定要删除的元素的索引即可。
list_test = ['ss', 'aa', 'bb', 'cc']
pop_n = list_test.pop(1)
print(list_test)
print(pop_n)
['ss', 'bb', 'cc']
aa
如果你不确定该使用del语句还是pop()方法,下面是一个简单的判断标准:如果你要从列表中删除一个元素,且不再以任何方式使用它,就使用del语句;如果你要在删除元素后还能继续使用它,就使用方法pop()。
- 根据值删除元素
不知道要从列表中删除的值所处的位置。只知道要删除的元素的值,可使用方法remove()。
使用remove()从列表中删除元素时,也可接着使用它的值。
list_test = ['ss', 'aa', 'bb', 'cc']
re_num = "aa"
list_test.remove(re_num)
print(list_test)
print(re_num)
['ss', 'bb', 'cc']
aa
方法remove()只删除第一个指定的值。如果要删除的值可能在列表中出现多次,就需要使用循环来判断是否删除了所有这样的值。
5 组织列表
1 使用方法 sort()对列表进行永久性排序
字母顺序排列
list_test = ['ss', 'aa', 'bb', 'cc']
list_test.sort()
print(list_test)
['aa', 'bb', 'cc', 'ss']
按与字母顺序相反的顺序排列列表元素,只需向sort()方法传递参数reverse=True。
list_test = ['ss', 'aa', 'bb', 'cc']
list_test.sort(reverse=True)
print(list_test)
['ss', 'cc', 'bb', 'aa']
2 使用函数 sorted()对列表进行临时排序
要保留列表元素原来的排列顺序,同时以特定的顺序呈现它们,可使用函数sorted()。
list_test = ['ss', 'aa', 'bb', 'cc']
print(list_test)
print(sorted(list_test))
print(list_test)
['ss', 'aa', 'bb', 'cc']
['aa', 'bb', 'cc', 'ss']
['ss', 'aa', 'bb', 'cc']
调用函数sorted()后,列表元素的排列顺序并没有变。如果你要按与字母顺序相反的顺序显示列表,也可向函数sorted()传递参数reverse=True。
list_test = ['ss', 'aa', 'bb', 'cc']
print(list_test)
print(sorted(list_test, reverse=True))
print(list_test)
['ss', 'aa', 'bb', 'cc']
['ss', 'cc', 'bb', 'aa']
['ss', 'aa', 'bb', 'cc']
3 倒着打印列表
要反转列表元素的排列顺序,可使用方法reverse()。
reverse()不是指按与字母顺序相反的顺序排列列表元素,而只是反转列表元素的排列顺序
方法reverse()永久性地修改列表元素的排列顺序,但可随时恢复到原来的排列顺序,因为只需对列表再次调用reverse()即可。
list_test = ['ss', 'aa', 'bb', 'cc']
print(list_test)
list_test.reverse()
print(list_test)
['ss', 'aa', 'bb', 'cc']
['cc', 'bb', 'aa', 'ss']
4 确定列表的长度
函数len()
list_test = ['ss', 'aa', 'bb', 'cc']
print(len(list_test)) # 4
6 数字列表
1 使用 range()创建数字列表
使用函数list(),将range()的结果直接转换为列表。
如果将range()作为list()的参数,输出将为一个数字列表
numbers = list(range(1,6))
print(numbers)
[1, 2, 3, 4, 5]
使用函数range()时,指定步长
numbers = list(range(1, 10, 2))
print(numbers)
[1, 3, 5, 7, 9]
创建一个列表,其中包含前10个整数(即1~10)的平方呢
squares = []
for value in range(1, 11):
square = value ** 2
squares.append(square)
print(squares)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
为让这些代码更简洁,可不使用临时变量square,而直接将每个计算得到的值附加到列表末尾:
squares = []
for value in range(1, 11):
squares.append(value ** 2)
print(squares)
2 对数字列表执行简单的统计计算
min():列表元素最小值
max():列表元素最大值
sum():列表元素和
digits = [1, 4, 9, 16, 25, 36, 49, 64, 81, 0]
print(min(digits))
print(max(digits))
print(sum(digits))
0
81
285
3 列表解析
列表解析将for循环和创建新元素的代码合并成一行,并自动附加新元素。
squares = [value**2 for value in range(1,11)]
print(squares)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
首先指定一个描述性的列表名,如squares;
然后,指定一个左方括号,并定义一个表达式,用于生成你要存储到列表中的值。
在这个示例中,表达式为value**2,它计算平方值。
接下来,编写一个for循环,用于给表达式提供值,再加上右方括号。
在这个示例中,for循环为for value in range(1,11),它将值1~10提供给表达式value**2。请注意,这里的for语句末尾没有冒号。
7 复制列表
要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引[:]
first_list = [1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
copy_list = first_list[:]
print(copy_list)
copy_list.append("1")
first_list.append("2")
print(copy_list)
print(first_list)
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000, '1']
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000, '2']
不使用切片,直接进行复制是一种错误的方法。不能得到两个列表。
first_list = [1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
copy_list = first_list
print(copy_list)
copy_list.append("1")
first_list.append("2")
print(copy_list)
print(first_list)
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000, '1', '2']
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000, '1', '2']
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。Python将不能修改的值称为不可变的,而不可变的列表被称为元组
如果需要存储的一组值在程序的整个生命周期内都不变,可使用元组。
元组中的元素类型也可以不相同。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
string、list 和 tuple 都属于 sequence(序列)。
虽然不能修改元组的元素,但可以给存储元组的变量赋值。因此,如果要修改前述矩形的尺
寸,可重新定义整个元组。
foods_tuple = ('apple', 'rice', 'cake', 'ice cream', 'hot pot')
for food in foods_tuple:
print(food)
print("---")
foods_tuple = ('pear', 'coffee', 'cake', 'ice cream', 'hot pot')
for food in foods_tuple:
print(food)
apple
rice
cake
ice cream
hot pot
---
pear
coffee
cake
ice cream
hot pot
Set(集合)
集合是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号{ }或者 set() 函数创建集合,注意:创建一个空集合必须用set()而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
实例
#!/usr/bin/python3
student = {'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'}
print(student) # 输出集合,重复的元素被自动去掉
# 成员测试
if 'Rose' in student :
print('Rose 在集合中')
else :
print('Rose 不在集合中')
结果
{'Mary', 'Jim', 'Rose', 'Jack', 'Tom'}
Rose 在集合中
set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
结果
{'b', 'a', 'c', 'r', 'd'}
{'b', 'd', 'r'}
{'l', 'r', 'a', 'c', 'z', 'm', 'b', 'd'}
{'a', 'c'}
{'l', 'r', 'z', 'm', 'b', 'd'}
Dictionary(字典)
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
dict1 = {}
dict1['one'] = '111test'
dict1['two'] = '222test'
print(dict1)
dictTest = {1: 'red', 2: 'yellow', 3: 'blue', 4: 'green'}
print(dictTest[2]) # 输出键为2的值
print(dictTest) # 输出字典
print(dictTest.keys()) # 输出所有的键
print(dictTest.values()) # 输出所有的值
{‘one’: ‘111test’, ‘two’: ‘222test’}
yellow
{1: ‘red’, 2: ‘yellow’, 3: ‘blue’, 4: ‘green’}
dict_keys([1, 2, 3, 4])
dict_values([‘red’, ‘yellow’, ‘blue’, ‘green’])
构造函数 dict() 可以直接从键值对序列中构建字典如下:
>>>dict([('test1', 1), ('test2', 2), ('test3', 3)])
{'test1': 1, 'test2': 2, 'test3': 3}
>>>{x :x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>>dict(xxx=1, yyy=2, zzz=3)
{'xxx': 1, 'yyy': 2, 'zzz': 3}
另外,字典类型也有一些内置的函数,例如**clear()、keys()、values()**等。
注意:
1、字典是一种映射类型,它的元素是键值对。
2、字典的关键字必须为不可变类型,且不能重复。
3、创建空字典使用 { }。
修改字典中的值
要修改字典中的值,依次指定字典名、用方括号括起的键以及与该键相关联的新值
people_1 = {"first_name": "zhang", "last_name": "si si", "city": "beijing"}
people_1["city"] = "xian"
删除键—值对
对于字典中不再需要的信息,可使用del语句将相应的键—值对彻底删除。使用del语句时,必须指定字典名和要删除的键。
people_1 = {"first_name": "zhang", "last_name": "si si", "city": "beijing"}
del people_1['city']
print(people_1)
{'first_name': 'zhang', 'last_name': 'si si'}
在前面的示例中,字典存储的是一个对象(游戏中的一个外星人)的多种信息
但也可以使用字典来存储众多对象的同一种信息。
favorite_languages = {
'jen': 'python',
'sarah': 'c',
'edward': 'ruby',
'phil': 'python',
}
遍历字典
for语句包含字典名和方法items(),它返回一个键值对列表。
接下来,for循环依次将每个键值对存储到指定的两个变量中。
我们使用这两个变量来打印每个键及其相关联的值。
第一条print语句中的\n确保在输出每个键—值对前都插入一个空行
for key, value in dir_word.items():
print("\nkey: ", key)
print("value: ", value)
key: select
value: 选择
key: if
value: 如果
key: and
value: 并
key: print
value: 输出
key: input
value: 输入
注意,即便遍历字典时,键—值对的返回顺序也与存储顺序不同。Python不关心键—值对的存
储顺序,而只跟踪键和值之间的关联关系。
遍历字典中的所有键
在不需要使用字典中的值时,方法keys()很有用。keys()获取字典中的键
dir_word = {"select": "选择", "if": "如果", "and": "并", "print": "输出", "input": "输入"}
for key in dir_word.keys():
print(key)
select
if
and
print
input
在这种循环中,可使用当前键来访问与之相关联的值
dir_word = {"select": "选择", "if": "如果", "and": "并", "print": "输出", "input": "输入"}
for key in dir_word:
print(key)
print(dir_word[key]) # 使用当前键来访问与之相关联的值
方法keys()并非只能用于遍历;实际上,它返回一个列表,其中包含字典中的所有键
遍历字典时,会默认遍历所有的键。
因此,如果将上述代码中的for key in dir_word.keys():替换为for key in dir_word:输出将不变。
按顺序遍历字典中的所有键:是在for循环中对返回的键进行排序
dir_word = {"select": "选择", "if": "如果", "and": "并", "print": "输出", "input": "输入"}
for key in sorted(dir_word.keys()):
print(key)
and
if
input
print
select
遍历字典中的所有值,方法values(),它返回一个值列表,而不包含任何键。
dir_word = {"select": "选择", "if": "如果", "and": "并", "print": "输出", "input": "输入"}
for value in dir_word.values(): # 这条for语句提取字典中的每个值
print(value)
选择
如果
并
输出
输入
这种做法提取字典中所有的值,而没有考虑是否重复。涉及的值很少时,这也许不是问题,
但如果被调查者很多,最终的列表可能包含大量的重复项。为剔除重复项,可使用集合set()。
集合类似于列表,但每个元素都必须是独一无二的
dir_word = {"select": "选择", "if": "如果", "and": "并", "&": "并", "input": "输入"}
for value in set(dir_word.values()):
print(value)
如果
输入
并
选择
添加键值对
dir_word = {"select": "选择", "if": "如果", "and": "并", "&": "并", "input": "输入"}
dir_word["or"] = "或者"
dir_word['for'] = "循环"
for key,value in dir_word.items():
print(key + ":" + value)
select:选择
if:如果
and:并
&:并
input:输入
or:或者
for:循环
字典列表(将字典存储在列表中
将字典存储在列表中
创建一个列表,列表中每个元素都是一个字典
经常需要在列表中包含大量的字典,而其中每个字典都包含特定对象的众多信息
lvcha = {'ke ji': 'ci ci'}
xiaobai = {'bianmu': 'bob'}
dahuang = {"jinmao": "zhang"}
pets = [lvcha, xiaobai, dahuang]
print(pets)
for pet in pets:
# print(pet)
for type, owner in pet.items():
print(type + " : " + owner)
在字典中存储列表
将列表存储在字典中
每当需要在字典中将一个键关联到多个值时,都可以在字典中嵌套一个列表。
favorite_places = {'ss': ['xi an', 'hang zhou', 'tian jin'],
'coco': ['beijing', 'shang hai', 'xia men'],
'bob': ['jinan', 'he nan']}
for people, places in favorite_places.items():
print(people + " 's favorite city is ")
for place in places:
print(place)
Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。

脚本式编程
在Linux/Unix系统中,你可以在脚本顶部添加以下命令让Python脚本可以像SHELL脚本一样可直接执行:
#! /usr/bin/env python3
然后修改脚本权限,使其有执行权限,命令如下:
chmod +x hello.py
执行以下命令:
./hello.py
运算符
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
- 运算符优先级

Python位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100 #与运算符 11为1 其余为0
a|b = 0011 1101 # 或运算符 00为0 其余为1
a^b = 0011 0001 # 异或运算符 相异为1 相同为0
~a = 1100 0011 # 取反运算符 1变0 0变1





Python身份运算符
身份运算符用于比较两个对象的存储单元


is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
b=a与b=a[:]的区别
b=a将两者指向同一个对象
而b=a[:]会创建一个新的与a完全相同的对象,但是与a并不指向同一对象。
在计算机中,不同的对象即不同的内存地址。
可理解为:b=a将创建a与b两个快捷方式并指向同一文件;
而b=a[:]先将a指向的文件复制一份作为副本,然后创建一个指向该副本的快捷方式b。
二者不同表现为当两者指向同一对象时,改变其中任意一个,都会改变对象的值,也就是同时改变a,b的值。


条件语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
Python 编程中 if 语句用于控制程序的执行,基本形式为:
if-else结构非常适合用于要让Python执行两种操作之一的情形。
if 判断条件:
执行语句……
else:
执行语句……
其中"判断条件"成立时(非零),则执行后面的语句,而执行内容可以多行,以缩进来区分表示同一范围。
else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
当经常需要检查超过两个的情形,为此可使用Python提供的if-elif-else结构。Python只执行if-elif-else结构中的一个代码块,它依次检查每个条件测试,直到遇到通过了的条件测试。测试通过后,Python将执行紧跟在它后面的代码,并跳过余下的测试。
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……
由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时:
使用 or (或),表示两个条件有一个成立时判断条件成功;
使用 **and (与)**时,表示只有两个条件同时成立的情况下,判断条件才成功。
如果你只想执行一个代码块,就使用if-elif-else结构;如果要运行多个代码块,就使用一系列独立的if语句。
检查特定值是否包含在列表中
要判断特定的值是否已包含在列表中,可使用关键字in。
判断特定的值未包含在列表中,可使用关键字not in
foods_list = ['apple', 'rice', 'cake', 'ice cream', 'hot pot']
print('banana' in foods_list)
print('banana' not in foods_list)
False
True
循环语句
Python 提供了 for 循环和 while 循环(在 Python 中没有 do…while 循环):

while循环语句
for循环用于针对集合中的每个元素都一个代码块,而while循环不断地运行,直到指定的条件不满足为止
while 判断条件(condition):
执行语句(statements)……

如果条件判断语句永远为 true,循环将会无限的执行下去
在 python 中,while … else 在循环条件为 false 时执行 else 语句块:
在循环语句中,我们让程序在满足指定条件时就执行特定的任务(比如停止运行),但在复杂程序中,很多不同的事件都会导致程序停止运行。
在要求很多条件都满足才继续运行的程序中,可定义一个变量,用于判断整个程序是否处于活动状态。
这个变量被称为标志,充当了程序的交通信号灯。你可让程序在标志为True时继续运行,并在任何事件导致标志的值为False时让程序停止运行。
这样,在while语句中就只需检查一个条件:标志的当前值是否为True,并将所有测试(是否发生了应将标志设置为False的事件)都放在其他地方,从而让程序变得更为整洁
要立即退出while循环,不再运行循环中余下的代码,也不管条件测试的结果如何,可使用break语句。
break语句用于控制程序流程,可使用它来控制哪些代码行将执行,哪些代码行不执行,从而让程序按你的要求执行你要执行的代码。
要返回到循环开头,并根据条件测试结果决定是否继续执行循环,可使用continue语句。
continue语句,让Python忽略余下的代码,并返回到循环的开头。
for循环是一种遍历列表的有效方式,但在for循环中不应修改列表,否则将导致Python难以跟踪其中的元素。
**要在遍历列表的同时对其进行修改,可使用while循环。**通过将while循环同列表和字典结合起来使用,可收集、存储并组织大量输入,供以后查看和显示。
# 首先,创建一个待验证用户列表
# 和一个用于存储已验证用户的空列表
unconfirmed_users = ['alice', 'brian', 'candace']
confirmed_users = []
# 验证每个用户,直到没有未验证用户为止
# 将每个经过验证的列表都移到已验证用户列表中
while unconfirmed_users:
current_user = unconfirmed_users.pop()
print("Verifying user: " + current_user.title())
confirmed_users.append(current_user)
# 显示所有已验证的用户
print("\nThe following users have been confirmed:")
for confirmed_user in confirmed_users:
print(confirmed_user.title())
由于Candace位于列表unconfirmed_users末尾,因此其名字将首先被删除、存储到变量current_user中并加入到列表confirmed_users中
Verifying user: Candace
Verifying user: Brian
Verifying user: Alice
The following users have been confirmed:
Candace
Brian
Alice
删除列表中含有的多个值
pets = ['dog', 'cat', 'dog', 'goldfish', 'cat', 'rabbit', 'cat']
print(pets)
while 'cat' in pets:
pets.remove('cat')
print(pets)
使用用户输入来填充字典
可使用while循环提示用户输入任意数量的信息
responses = {}
# 设置一个标志,指出调查是否继续
polling_active = True
while polling_active:
# 提示输入被调查者的名字和回答
name = input("\nWhat is your name? ")
response = input("Which mountain would you like to climb someday? ")
# 将答卷存储在字典中
responses[name] = response
# 看看是否还有人要参与调查
repeat = input("Would you like to let another person respond? (yes/ no) ")
if repeat == 'no':
polling_active = False
# 调查结束,显示结果
print("\n--- Poll Results ---")
for name, response in responses.items():
print(name + " would like to climb " + response + ".")
for 循环语句
for iterating_var in sequence:
statements(s)


以上实例我们使用了内置函数 len() 和 range(),函数 len() 返回列表的长度,即元素的个数。 range返回一个序列的数。

在for循环中直接更改列表中元素的值不会起作用,要使用range来修改,最好还是用while来修改吧。
有效
def make_great(magic_names):
for i in range(0, len(magic_names)):
magic_names[i] = "the great " + magic_names[i]
return magic_names
无效
def make_great(magic_names):
for magic_name in magic_names:
magic_name = 'the great ' + magic_name
return magic_names
函数
1 定义函数
def func1(a):
print(a)
def func2(b):
return b
if __name__ == '__main__':
func1(1)
x = func2(2)
print(x)
2 传递实参
函数定义中可能包含多个形参,因此函数调用中也可能包含多个实参。向函数传递实参的方式很多,可使用位置实参,这要求实参的顺序与形参的顺序相同;也可使用关键字实参,其中每个实参都由变量名和值组成;还可使用列表和字典。
2.1 位置实参
调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。为此,最简单的关联方式是基于实参的顺序。这种关联方式被称为位置实参。
def describe_pet(animal_type, pet_name):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet('hamster', 'harry')
2.2 关键字实参
关键字实参是传递给函数的名称—值对。
直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆。
无需考虑函数调用中的实参顺序,还清楚地指出了函数调用中各个值的用途。
describe_pet(animal_type='hamster', pet_name='harry')
2.3 默认值
编写函数时,可给每个形参指定默认值。
在调用函数中给形参提供了实参时,Python将使用指定的实参值;否则,将使用形参的默认值。
因此,给形参指定默认值后,可在函数调用中省略相应的实参。
def describe_pet(pet_name, animal_type='dog'):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
注意:使用默认值时,在形参列表中必须先列出没有默认值的形参,再列出有默认值的实参。这样Python才能够正确地解读位置实参。
3 返回值
函数并非总是直接显示输出,相反,它可以处理一些数据,并返回一个或一组值。函数返回的值被称为返回值。在函数中,可使用return语句将值返回到调用函数的代码行。
返回值让你能够将程序的大部分繁重工作移到函数中去完成,从而简化主程序.
调用返回值的函数时,需要提供一个变量,用于存储返回的值。
3.1 返回简单值
def get_formatted_name(first_name, last_name):
"""返回整洁的名字"""
full_name = first_name.title() + ' ' + last_name
return full_name
name = get_formatted_name("zhang", "ss")
print(name)
3.2 让实参变成可选的
有时候,需要让实参变成可选的,这样使用函数的人就只需在必要时才提供额外的信息。可使用默认值来让实参变成可选的。
def get_formatted_name(first_name, last_name, middle_name=''):
"""返回整洁的名字"""
if middle_name:
full_name = first_name.title() + ' ' + middle_name + ' ' + last_name
else:
full_name = first_name.title() + ' ' + last_name
return full_name
name = get_formatted_name("zhang", "ss")
print(name)
name2 = get_formatted_name("zhang", "ss", 'mid')
print(name2)
3.3 返回字典
函数可返回任何类型的值,包括列表和字典等较复杂的数据结构.
接受简单的文本信息,将其放在一个更合适的数据结构中,让你不仅能打印这些信息,还能以其他方式处理它们
def city_country(city, country):
dire = {'cityKey': city, 'countryKey': country}
return dire
str1 = city_country('beijing', 'China')
print(str1)
{'cityKey': 'beijing', 'countryKey': 'China'}
3.4 结合使用函数和 while 循环
def make_album(singer, album, song_num=''):
if song_num:
dire = {'name': singer, 'album_name': album, 'num': song_num}
else:
dire = {'name': singer, 'album_name': album}
return dire
while True:
print("(enter 'q' at any time to quit)")
Singer = input("please input singer name: ")
if Singer == 'q':
break
Album = input("please input album name: ")
if Album == 'q':
break
ss = make_album(Singer, Album)
print(ss)
4 传递列表
向函数传递列表很有用,这种列表包含的可能是名字、数字或更复杂的对象(如字典)。将列表传递给函数后,函数就能直接访问其内容.
4.1 在函数中修改列表
将列表传递给函数后,函数就可对其进行修改。在函数中对这个列表所做的任何修改都是永久性的,这让你能够高效地处理大量的数据。
def print_models(unprinted_designs, completed_models):
"""
模拟打印每个设计,直到没有未打印的设计为止
打印每个设计后,都将其移到列表completed_models中
"""
while unprinted_designs:
current_design = unprinted_designs.pop()
# 模拟根据设计制作3D打印模型的过程
print("Printing model: " + current_design)
completed_models.append(current_design)
def show_completed_models(completed_models):
"""显示打印好的所有模型"""
print("\nThe following models have been printed:")
for completed_model in completed_models:
print(completed_model)
unprinted_designs = ['iphone case', 'robot pendant', 'dodecahedron']
completed_models = []
print_models(unprinted_designs, completed_models)
show_completed_models(completed_models)
for循环是一种遍历列表的有效方式,但在for循环中不应修改列表,否则将导致Python难以跟踪其中的元素。要在遍历列表的同时对其进行修改,可使用while循环。通过将while循环同列表和字典结合起来使用,可收集、存储并组织大量输入,供以后查看和显示。
在for循环中直接更改列表中元素的值不会起作用,要使用range来修改
有效
def make_great(magic_names):
for i in range(0, len(magic_names)):
magic_names[i] = "the great " + magic_names[i]
return magic_names
无效
def make_great(magic_names):
for magic_name in magic_names:
magic_name = 'the great ' + magic_name
return magic_names
4.2 禁止函数修改列表
向函数传递列表的副本而不是原件;这样函数所做的任何修改都只影响副本,不影响原件.
切片表示法[:]创建列表的副本
function_name(list_name[:])
print_models(unprinted_designs[:], completed_models)
5 传递任意数量的实参
有时候,预先不知道函数需要接受多少个实参,好在Python允许函数从调用语句中收集任意数量的实参。
def make_pizza(*toppings):
"""打印顾客点的所有配料"""
print(toppings)
make_pizza('pepperoni')
make_pizza('mushrooms', 'green peppers', 'extra cheese')
形参名*toppings中的星号让Python创建一个名为toppings的空元组,并将收到的所有值都封
装到这个元组中
5.1 结合使用位置实参和任意数量实参
如果要让函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后。Python先匹配位置实参和关键字实参,再将余下的实参都收集到最后一个形参中。
5.2 使用任意数量的关键字实参
有时候,需要接受任意数量的实参,但预先不知道传递给函数的会是什么样的信息。
在这种情况下,可将函数编写成能够接受任意数量的键—值对——调用语句提供了多少就接受多少。
一个这样的示例是创建用户简介:你知道你将收到有关用户的信息,但不确定会是什么样的信息。
def build_profile(first, last, **user_info):
"""创建一个字典,其中包含我们知道的有关用户的一切"""
profile = {}
profile['first_name'] = first
profile['last_name'] = last
for key, value in user_info.items():
profile[key] = value
return profile
user_profile = build_profile('albert', 'einstein', location='princeton', field='physics')
print(user_profile)
形参**user_info中的两个星号让Python创建一个名为user_info的空字典,并将收到的所有名称-值对都封装到这个字典中。
6 将函数存储在模块中
函数的优点之一是,使用它们可将代码块与主程序分离。通过给函数指定描述性名称,可让主程序容易理解得多。你还可以更进一步,将函数存储在被称为模块的独立文件中,再将模块导入到主程序中。
import语句允许在当前运行的程序文件中使用模块中的代码。
6.1 导入整个模块
模块是扩展名为.py的文件,包含要导入到程序中的代码


要调用被导入的模块中的函数,可指定导入的模块的名称pizza和函数名make_pizza(),并用句点分隔它们
6.2 导入特定的函数
from module_name import function_name
from module_name import function_0, function_1,function_2
6.3 使用 as 给函数指定别名
from pizza import make_pizza as mp
6.4 使用 as 给模块指定别名
import pizza as p
6.5 导入模块中的所有函数
from pizza import *
模块
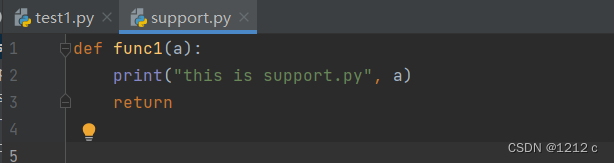
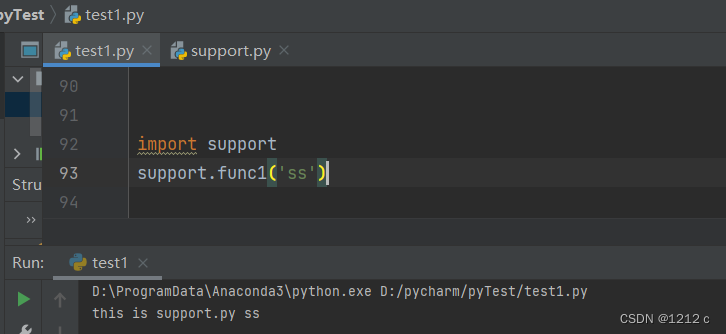
from support import func1
support.func1('ss')
Python中的包
Python中的包包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
包就是文件夹,但该文件夹下必须存在__init__.py文件, 该文件的内容可以为空。__init__.py 用于标识当前文件夹是一个包。
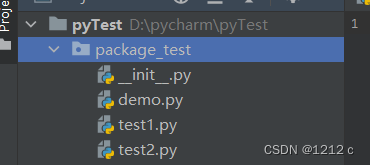
考虑一个在 package_test 目录下的 test1.py、test2.py、__init__.py 文件,demo.py 为测试调用包的代码,目录结构如下:



类
1 创建和使用类
1.1 创建类
根据约定,在Python中,首字母大写的名称指的是类。
- 方法
__init__()
类中的函数称为方法。__init__()是一个特殊的方法,每当根据类创建新实例时,Python都会自动运行它。
__init__()形参self必不可少,还必须位于其他形参的前面。Python调用这个__init__()方法来创建Dog实例时,将自动传入实参self。每个与类相关联的方法调用都自动传递实参self,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。
class Dog():
"""一次模拟小狗的简单尝试"""
def __init__(self, name, age):
"""初始化属性name和age"""
self.name = name
self.age = age # 像这样可通过实例访问的变量称为属性。
def sit(self):
"""模拟小狗蹲下"""
print(self.name.title() + " is now sitting.")
def roll_over(self):
"""模拟小狗打滚"""
print(self.name.title() + "rolled over !")
my_dog = Dog('coco', 6)
print("my dog's name is " + my_dog.name.title() + ".")
print("my dog is " + str(my_dog.age) + " years old.")
my_dog.sit()
my_dog.roll_over()
1.2 根据类创建实例
根据类来创建对象被称为实例化
__init__()并未显式地包含return语句,但Python自动返回一个表示这个的实例
通常可以认为首字母大写的名称(如Dog)指的是类,而小写的名称(如my_dog)指的是根据类创建的实例。
- 访问属性
要访问实例的属性,可使用句点表示法
my_dog.name
- 调用方法
my_dog.sit()
my_dog.roll_over()
2 使用类和实例
2.1 Car 类
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self, make, model, year):
"""初始化描述汽车的属性"""
self.make = make
self.model = model
self.year = year
def get_descriptive_name(self):
"""返回整洁的描述性信息"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
my_new_car = Car('audi', 'a4', 2016)
print(my_new_car.get_descriptive_name())
2.2 给属性指定默认值
类中的每个属性都必须有初始值,哪怕这个值是0或空字符串。在有些情况下,如设置默认值时,在方法__init__()内指定这种初始值是可行的;如果你对某个属性这样做了,就无需包含为它提供初始值的形参。
class Car():
def __init__(self, make, model, year):
"""初始化描述汽车的属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def read_odometer(self):
"""打印一条指出汽车里程的消息"""
print("This car has " + str(self.odometer_reading) + " miles on it.")
2.3 修改属性的值
可以以三种不同的方式修改属性的值:
-
直接通过实例进行修改;
-
通过方法进行设置;
-
通过方法进行递增(增加特定的值)
-
直接修改属性的值
通过实例直接访问它。
my_new_car.odometer_reading = 23
- 通过方法修改属性的值
class Car():
--snip--
def update_odometer(self, mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
def read_odometer(self):
"""打印一条指出汽车里程的消息"""
print("This car has " + str(self.odometer_reading) + " miles on it.")
my_new_car = Car('audi', 'a4', 2016)
print(my_new_car.get_descriptive_name())
my_new_car.update_odometer(23)
my_new_car.read_odometer()
2016 Audi A4
This car has 23 miles on it.
- 通过方法对属性的值进行递增
有时候需要将属性值递增特定的量,而不是将其设置为全新的值
class Car():
--snip--
def update_odometer(self, mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
def increment_odometer(self, miles):
"""将里程表读数增加指定的量"""
self.odometer_reading += miles
my_used_car = Car('subaru', 'outback', 2013)
print(my_used_car.get_descriptive_name())
my_used_car.update_odometer(23500)
my_used_car.read_odometer()
my_used_car.increment_odometer(100)
my_used_car.read_odometer()
2013 Subaru Outback
This car has 23500 miles on it.
This car has 23600 miles on it.
继承
编写类时,并非总是要从空白开始。如果你要编写的类是另一个现成类的特殊版本,可使用继承。
一个类继承另一个类时,它将自动获得另一个类的所有属性和方法;原有的类称为父类,而新类称为子类。子类继承了其父类的所有属性和方法,同时还可以定义自己的属性和方法。
1 子类的方法__init__()
创建子类的实例时,Python首先需要完成的任务是给父类的所有属性赋值。为此,子类的方法__init__()需要父类施以援手。
class ElectricCar(Car):
"""电动汽车"""
def __init__(self, make, model, year, test1):
"""初始化父类的属性"""
super().__init__(make, model, year)
创建子类时,父类必须包含在当前文件中,且位于子类前面
定义子类时,必须在括号内指定父类的名称。
方法__init__()接受创建Car实例所需的信息
super()是一个特殊函数,帮助Python将父类和子类关联起来,父类也称为超类(superclass),名称super因此而得名。
2 给子类定义属性和方法
让一个类继承另一个类后,可添加区分子类和父类所需的新属性和方法。
class ElectricCar(Car):
"""电动汽车"""
def __init__(self, make, model, year, test1):
"""
初始化父类的属性
在初始化电动汽车的特有属性
"""
super().__init__(make, model, year)
self.battery_size = 70 # 电池容量
def describe_battery(self):
"""打印一条描述电瓶容量的消息"""
print("This car has a " + str(self.battery_size) + "-kWh battery.")
my_tesla = ElectricCar('tesla', 'model s', 2016)
my_tesla.describe_battery()
3 重写父类的方法
对于父类的方法,只要它不符合子类模拟的实物的行为,都可对其进行重写,它与要重写的父类方法同名。这样,Python将不会考虑这个父类方法,而只关注你在子类中定义的相应方法。
4 将实例用作属性
使用代码模拟实物时,你可能会发现自己给类添加的细节越来越多:属性和方法清单以及文件都越来越长。在这种情况下,可能需要将类的一部分作为一个独立的类提取出来。你可以将大型类拆分成多个协同工作的小类。
class Battery():
"""模拟电动汽车电瓶"""
def __init__(self, battery_size=70):
"""初始化电瓶属性"""
self.battery_size = battery_size
def describe_battery(self):
"""打印一条电瓶容量的消息"""
print("This car has a " + str(self.battery_size) + "-kwh battery.")
class ElectricCar(Car):
"""电动汽车"""
def __init__(self, make, model, year):
"""
初始化父类的属性
在初始化电动汽车的特有属性
"""
super().__init__(make, model, year)
# self.battery_size = 70 # 电池容量
self.battery = Battery() # 将一个Battery实例用作ElectricCar类的一个属性
def describe_battery(self):
"""打印一条描述电瓶容量的消息"""
print("This car has a " + str(self.battery_size) + "-kwh battery.")
my_tesla.battery.describe_battery()
在ElectricCar类中,我们添加了一个名为self.battery的属性。这行代码让Python创建一个新的Battery实例,并将该实例存储在属性self.battery中。每当方法__init__()被调用时,都将执行该操作;因此现在每个ElectricCar实例都包含一个自动创建的Battery实例。
5 导入类
Python允许你将类存储在模块中,然后在主程序中导入所需的模块。
文件I/O
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。
读取键盘输入raw_input、input。不过raw_input在python3中已被删除
python3 里 input() 默认接收到的是 str 类型。
input函数
打开和关闭文件
open 函数
先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读
(r)。 - buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
fo = open('qq.txt', 'w')
print(fo.name) # 文件名
print(fo.closed) # 是否已关闭
print(fo.mode) # 访问模式
close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
fo.close()
write()方法
write()方法可将任何字符串写入一个打开的文件。write()方法不会在字符串的结尾添加换行符(‘\n’).
read()方法
从一个打开的文件中读取一个字符串。
fo = open('qq.txt', 'r+')
fo.write(" ss like ")
ss = fo.read(100)
print(ss)
fo.close()
重命名和删除文件
Python的os模块提供了执行文件处理操作的方法,比如重命名和删除文件。
rename() 方法
需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
os.rename('qq.txt', 'aa.txt')
remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
目录
所有文件都包含在各个不同的目录下,os模块能帮你创建,删除和更改目录。
mkdir()方法
使用os模块的mkdir()方法在当前目录下创建新的目录。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")

getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')
1 从文件中读取数据
1.1 读取整个文件
函数open()。要以任何方式使用文件——哪怕仅仅是打印其内容,都得先打开文件,这样才能访问它。函数open()接受一个参数:要打开的文件的名称。Python在当前执行的文件所在的目录中查找指定的文件。
关键字with在不再需要访问文件后将其关闭
with open('pi_digits.txt') as file_object:
contents = file_object.read()
print(contents)
相比于原始文件,该输出唯一不同的地方是末尾多了一个空行。为何会多出这个空行呢?因为read()到达文件末尾时返回一个空字符串,而将这个空字符串显示出来时就是一个空行。要删除多出来的空行,可在print语句中使用rstrip()
1.2 逐行读取
在这个文件中,每行的末尾都有一个看不见的换行符,而print语句也会加上一个换行符,因此每行末尾都有两个换行符:一个来自文件,另一个来自print语句。要消除这些多余的空白行,可在print语句中使用rstrip():
filename = r'D:\pycharm\pyTest\pi_digits.txt'
with open(filename) as file_object:
for line in file_object:
print(line.rstrip())
1.3 创建一个包含文件各行内容的列表
使用关键字with时,open()返回的文件对象只在with代码块内可用。如果要在with代码块外访问文件的内容,可在with代码块内将文件的各行存储在一个列表中,并在with代码块外使用该列表
readlines()从文件中读取每一行,并将其存储在一个列表中;
该列表被存储到变量lines中;在with代码块外,我们依然可以使用这个变量。
filename = r'D:\pycharm\pyTest\pi_digits.txt'
with open(filename) as file_object:
lines = file_object.readlines() # 方法 readlines() 从文件中读取每一行,并将其存储在一个列表中
for line in lines:
print(line.rstrip())
1.4 使用文件的内容
filename = 'pi_30_digits.txt'
with open(filename) as file_object:
lines = file_object.readlines()
pi_string = ''
for line in lines:
pi_string += line.strip()
print(pi_string)
print(len(pi_string))
读取文本文件时,Python将其中的所有文本都解读为字符串。
如果你读取的是数字,并要将其作为数值使用,就必须使用函数int()将其转换为整数,或使用函数float()将其转换为浮点数
2 写入文件
保存数据的最简单的方式之一是将其写入到文件中。
2.1 写入空文件
如果你要写入的文件不存在,函数open()将自动创建它。然而,以写入(‘w’)模式打开文件时千万要小心,因为如果指定的文件已经存在,Python将在返回文件对象前清空该文件。
filename = "D:\pycharm\pyTest\progrom.txt"
with open(filename, 'w') as file_object:
file_object.write("hello world")
2.2 附加到文件
如果要给文件添加内容,而不是覆盖原有的内容,可以附加模式打开文件。以附加模式打开文件时,Python不会在返回文件对象前清空文件,而你写入到文件的行都将添加到文件末尾。如果指定的文件不存在,Python将为你创建一个空文件
filename = "D:\pycharm\pyTest\progrom.txt"
with open(filename, 'a') as file_object:
file_object.write("hello world")
异常
Python使用被称为异常的特殊对象来管理程序执行期间发生的错误。
每当发生让Python不知所措的错误时,它都会创建一个异常对象。
如果你编写了处理该异常的代码,程序将继续运行;如果你未对异常进行处理,程序将停止,并显示一个traceback,其中包含有关异常的报告。
异常是使用try-except代码块处理的。try-except代码块让Python执行指定的操作,同时告诉Python发生异常时怎么办。使用了try-except代码块时,即便出现异常,程序也将继续运行:显示你编写的友好的错误消息,而不是令用户迷惑的traceback。
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
大致语法和Java差不多
try:
<语句> #运行别的代码
except <异常的名字>:
<语句> #如果在try部份引发了'name'异常
else:
<语句> #如果没有异常发生
try:
fo = open('qq.txt', 'w')
fo.write("this is a test file used test Exception")
except IOError:
print("Error ! can not find file or read file error")
else:
print("write success~")
fo.close()
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
fo = open('qq.txt', 'r')
fo.write("this is a test file used test Exception")
except IOError:
print("Error ! can not find file or read file error")
else:
print("write success~")
finally:
print("this in a finally")
print("不论异常是否发生都会执行,可以用于文件关闭等")
fo.close()
不处理异常
并非每次捕获到异常时都需要告诉用户,有时候你希望程序在发生异常时一声不吭,就像什么都没有发生一样继续运行。需要在except代码块中明确地告诉Python什么都不要做。
Python有一个pass语句,可在代码块中使用它来让Python什么都不要做:
def count_words(filename):
"""计算一个文件大致包含多少个单词"""
try:
--snip--
except FileNotFoundError:
pass
pass语句还充当了占位符,它提醒你在程序的某个地方什么都没有做,并且以后也许要在这里做些什么。
json
很多程序都要求用户输入某种信息,如让用户存储游戏首选项或提供要可视化的数据。程序都把用户提供的信息存储在列表和字典等数据结构中。用户关闭程序时,几乎总是要保存他们提供的信息;一种简单的方式是使用模块json来存储数据。
模块json让你能够将简单的Python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。你还可以使用json在Python程序之间分享数据。
json.dump
存储数据为文件
函数json.dump()接受两个实参:要存储的数据以及可用于存储数据的文件对象。
import json
numbers =[1,3,4,5,7,2,4]
filename = "../numbers.json"
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
json.load()
将文件中存的读取到内存
import json
filename = "../numbers.json"
with open(filename, 'w') as f_obj:
numbers = json.load(f_obj)
print(numbers)
保存和读取用户生成的数据
用户首次运行程序时被提示输入自己的名字,这样再次运行程序时就记住他了
import json
filename = "../name.json"
try:
with open(filename) as f_obj:
username = json.load(f_obj)
except FileNotFoundError:
username = input("what's your name ?")
with open(filename, 'w') as f_obj:
json.dump(username, f_obj)
print("i remember you " + username)
else:
print("welcome " + username)
重构
将代码划分为一系列完成具体工作的函数,这样的过程被称为重构。重构让代码更清晰、更易于理解、更容易扩展。
import json
def get_stored_username():
"""如果存储了用户名,就获取它"""
filename = "../name.json"
try:
with open(filename) as f_obj:
username = json.load(f_obj)
except FileNotFoundError:
return None
else:
return username
def get_new_username():
"""提示用户输入用户名"""
username = input("what's your name ?")
filename = "../name.json"
with open(filename, 'w') as f_obj:
json.dump(username, f_obj)
return username
def greet_user():
"""问候用户 并指出名字"""
username = get_stored_username()
if username:
print("welcome " + username)
else:
username = get_new_username()
print("i remember you " + username)
greet_user()
测试代码
1 测试函数
Python标准库中的模块unittest提供了代码测试工具。
单元测试用于核实函数的某个方面没有问题;测试用例是一组单元测试,这些单元测试一起核实函数在各种情形下的行为都符合要求。
良好的测试用例考虑到了函数可能收到的各种输入,包含针对所有这些情形的测试。全覆盖式测试用例包含一整套单元测试,涵盖了各种可能的函数使用方式。
要为函数编写测试用例,可先导入模块unittest以及要测试的函数,再创建一个继承unittest.TestCase的类,并编写一系列方法对函数行为的不同方面进行测试

首先,我们导入了模块unittest和要测试的函数get_formatted_ name()。在1处,我们创建了一个名为NamesTestCase的类,用于包含一系列针对get_formatted_name()的单元测试。你可随便给这个类命名,但最好让它看起来与要测试的函数相关,并包含字样Test。这个类必须继承unittest.TestCase类,这样Python才知道如何运行你编写的测试。
运行test_name_function.py时,所有以test_打头的方法都将自动运行
unittest类最有用的功能之一:一个断言方法。断言方法用来核实得到的结果是否与期望的结果一致。
2 测试类

只能在继承unittest.TestCase的类中使用这些方法

# test_survey.py
import unittest
from survey import AnonymousSurvey
class TestAnonmyousSurvey(unittest.TestCase):
"""针对AnonymousSurvey类的测试"""
def test_store_single_response(self):
"""测试单个答案会被妥善地存储"""
question = "What language did you first learn to speak?"
my_survey = AnonymousSurvey(question)
my_survey.store_response('English')
self.assertIn('English', my_survey.responses)
def test_store_three_responses(self):
"""测试三个答案会被妥善地存储"""
question = "What language did you first learn to speak?"
my_survey = AnonymousSurvey(question)
responses = ['English', 'Spanish', 'Mandarin']
for response in responses:
my_survey.store_response(response)
for response in responses:
self.assertIn(response, my_survey.responses)
if __name__ == '__main__':
unittest.main()
setUp()方法
在前面的test_survey.py中,我们在每个测试方法中都创建了一个AnonymousSurvey实例,并在每个方法中都创建了答案。unittest.TestCase类包含方法setUp(),让我们只需创建这些对象一次,并在每个测试方法中使用它们。如果你在TestCase类中包含了方法setUp(),Python将先运行它,再运行各个以test_打头的方法。
import unittest
from chapter11.survey import AnonymousSurvey
class TestAnonymousSurvey(unittest.TestCase):
def setUp(self):
"""创建一个调查对象和一组答案,供使用的测试方法使用"""
question = "what language did you first learn to speak?"
self.my_survey = AnonymousSurvey(question)
self.responses = ['english', 'chinese', 'japanese']
def test_store_single_response(self):
self.my_survey.store_response(self.responses[0])
self.assertIn(self.responses[0], self.my_survey.responses)
def test_store_three_response(self):
for response in self.responses:
self.my_survey.store_response(response)
for response in self.responses:
self.assertIn(response, self.my_survey.responses)
if __name__ == '__main__':
unittest.main()














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









